python -- 批量读取多个文件,并将每个文件中相同变量累加
python – 批量读取多个文件,并将每个文件中相同变量累加
情况描述
- 现有多个nc文件,位于同一个文件夹中,如下所示
- 每个文件中都有相同的变量,想要读取每个文件中的变量然后将其加起来
- 意思就是说:
文件1中的变量+文件2中的变量+文件3中的变量+....
解决思路
1、先将所有的文件名所包含的路径读取到一个list
2、对于list进行循环读取,读取每个文件中相同的变量
3、先打开第一个文件中的变量,将后续文件中的变量累加到第一个文件中命名的变量
4、将结果写入到新的nc文件中并进行保存
对于第一个步骤,读取一个目录下所有指定类型的文件,我们可以通过glob函数来完成
对于第二个步骤,读取nc文件可以通过netcdf、xarray(任选一个)来完成
对于第三个步骤,直接写个循环就完事了
最后一个步骤使用to_netcdf()函数来完成
下面给出一个手把手的代码示例:
代码示例 – 以xarray库读取
1、导入库
import xarray as xr
import glob
2、读取所有文件
path = 'file_locate_path'
这里的路径,改为你自己文件所在的路径,注意在python中路径直接应该是反斜线/
例如我这里文件都在I盘下的ice文件夹,关于批量读取文件的教程,可以看我之前分享的教程,非常详细了:
1、批量读取相同格式文件(多个文件夹/单个文件夹)—nc文件为例
2、批量处理nc文件-字符串拼接文件,有规律文件名
3、批量读取地转流速日资料绘制气候态年平均海表流场(填色为流速)
## 获得文件路径列表
path = r'I:/ice/'
file_list = glob.glob(path+'*nc')
读取完,如果你使用的是spyder这个编辑器的话,可以在变量栏中看到如下内容:

点开这个file_list,(或者使用命令行的话,可以在命令行中输入file_list),我这里,文件夹下一共有43个文件:
就是上面这一个样子,每个文件的路径加上文件的名称,这一步就没问题啦~~
读取第一个文件的变量
打开第一个文件并读取变量
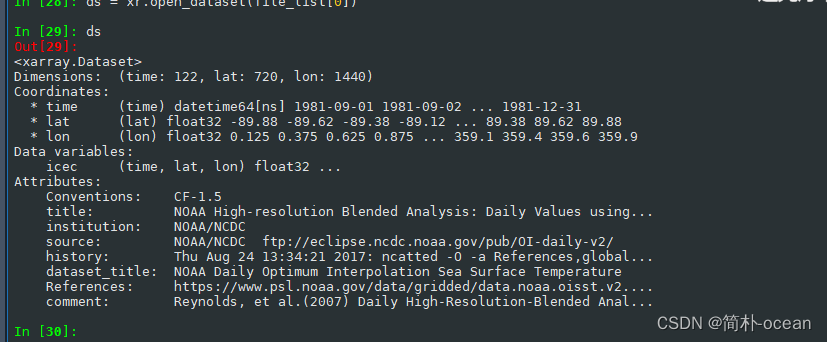
ds = xr.open_dataset(file_list[0])
可以简单看一下文件信息,以及变量名称,我们这里的变量名称为:icec,这个变量包含3个维度,时间(time)、纬度(lat)、经度(lon)。可以发现,每个变量都有122个time。还是挺大的。
对于上一步不熟悉的的,可以看看我之前的一个读取nc的教程:
手把手教你读取nc文件
ps:
为了节省计算时间,我这里仅做展示,取43个文件中的前10个文件,以及每个变量的第一个时刻进行累加。参考的朋友们这一步可以跳过
file_list = file_list[0:10] # 取文件前10个为例
# 打开第一个文件并读取变量
ds = xr.open_dataset(file_list[0])
var_name = 'icec'
# 取变量的第一个时刻
temp_sum = ds[var_name][0]循环打开剩余的文件进行累加
# 依次打开剩余文件并将temp变量累加到temp_sum中
for file in file_list[1:]:print(file)ds = xr.open_dataset(file)temp_sum += ds[var_name][0]
写入新的文件
# 将结果写入新的netCDF文件
temp_sum.to_netcdf('temp_sum.nc')
示例2-以netcdf库读取:
大致过程都类似,就不展示具体细节了,根据需要进行更改就行
import netCDF4 as ncpath = r'I:/ice/'
file_list = glob.glob(path+'*nc')
# 定义文件列表和变量名var_name = 'icec'# 打开第一个文件并读取变量
with nc.Dataset(file_list[0], 'r') as f:temp_sum = f.variables[var_name][:][0]# 依次打开剩余文件并将temp变量累加到temp_sum中
for file in file_list[1:]:with nc.Dataset(file, 'r') as f:temp_sum += f.variables[var_name][:][0]# 将结果写入新的netCDF文件
with nc.Dataset('temp_sum.nc', 'w') as f:# 创建一个新变量temp_sum_var = f.createVariable(var_name, temp_sum.dtype, ('time', 'lon', 'lat'))# 将累加结果写入变量temp_sum_var[:] = temp_sum
示例3–使用并行计算来加速计算过程
import dask.array as da
import dask.distributed as dd# 定义文件列表和变量名
## 获得文件路径列表
path = r'I:/ice/'
file_list = glob.glob(path+'*nc')file_list = file_list[0:10] # 取文件前10个为例# 创建Dask客户端
client = dd.Client()
var_name = 'icec'
# 使用Dask读取文件和变量
ds = xr.open_mfdataset(file_list, parallel=True)[var_name]# 将数据分块
chunks = {'time': len(ds.time)//40, 'lon': ds.lon.size, 'lat': ds.lat.size}
ds = ds.chunk(chunks)# 计算变量的累加和
temp_sum = da.sum(ds, axis=0)# 将结果写入新的netCDF文件
temp_sum.to_dataset(name=var_name).to_netcdf('temp_sum.nc')
相关文章:
python -- 批量读取多个文件,并将每个文件中相同变量累加
python – 批量读取多个文件,并将每个文件中相同变量累加 情况描述 现有多个nc文件,位于同一个文件夹中,如下所示每个文件中都有相同的变量,想要读取每个文件中的变量然后将其加起来意思就是说: 文件1中的变量文件2中…...

低代码开发流程是怎么样的?
低代码开发流程是怎么样的?现在很多文章都在下功夫宣传what(低代码是什么)、why(为什么要用低代码),但是很少有文章能够系统讨论how(怎么用低代码)的问题。 所以我花3天的时间准备了…...

任何时候都不要在 for 循环中删除 List 集合元素!!!
首先说结论:无论什么场景,都不要对List使用for循环的同时,删除List集合元素,因为这么做就是不对的。 阿里开发手册也明确说明禁止使用foreach删除、增加List元素。 正确删除元素的方式是使用迭代器(Iteratorÿ…...

koa+Vite+vue3+ts+pinia构建项目
一、 初始化构建项目 npm create vite myProject -- --template vue-ts 注:Vite 需要 Node.js 版本 14.18,16。然而,有些模板需要依赖更高的 Node 版本才能正常运行,当你的包管理器发出警告时,请注意升级你的 Node 版…...
k8s-yaml文件
文章目录一、K8S支持的文件格式1、yaml和json的主要区别2、YAML语言格式二、YAML1、查看 API 资源版本标签2、编写资源配置清单2.1 编写 nginx-test.yaml 资源配置清单2.2 创建资源对象2.3 查看创建的pod资源3、创建service服务对外提供访问并测试3.1 编写nginx-svc-test.yaml文…...
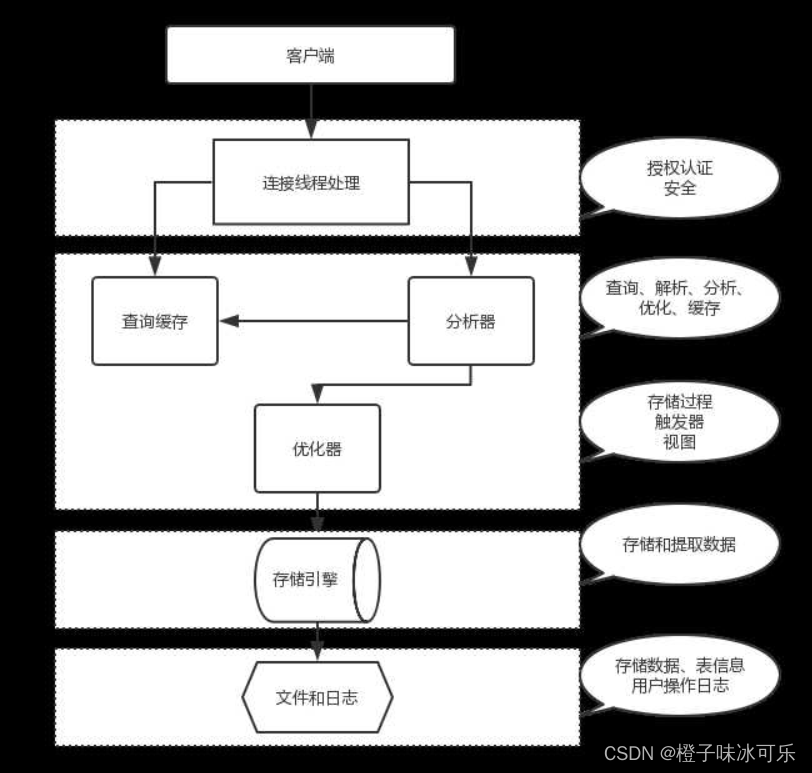
存储引擎
目录 ❤ MySQL存储引擎 什么是存储引擎? MySQL支持哪个存储引擎? ❤ 各种存储引擎的特性 概述 各种存储引擎的特性 各种搜索引擎介绍 ❤ 常用存储引擎及适用场景 ❤ 存储引擎在mysql中的使用 存储引擎相关sql语句 指定存储引擎建表 在建表时指定 在配置文件中…...

Go中 channel的使用
文章目录背景channel 简介使用说明声明发送和接受数据关闭channel使用示例背景 使用 sync 包和 context 包的工具可以实现多个协程之间互相协作, 但是没有一种很好的方式解决多个协程之间通信的问题. golang 作者 Rob Pike 说过一句话,不要通过共享内存来通信&…...

【C++】string OJ练习
文章目录1. 仅仅反转字母思路分析代码实现2. 字符串中的第一个唯一字符题目分析代码实现3. 《剑指offer》——替换空格解法一:寻找替换思路分析代码实现优化解法二:空间换时间思路分析代码实现4.字符串最后一个单词的长度思路分析代码实现5. 字符串相加思…...
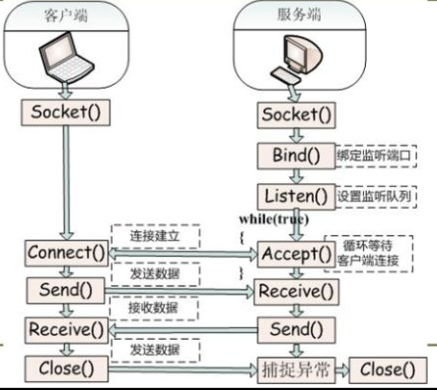
进程间通信IPC
进程间通信IPC (InterProcess Communication) 一、进程间通信的概念 每个进程各自有不同的用户地址空间,任何一个进程的全局变量在另一个进程中都看不到,所以进程之间要交换数据必须通过内核,在内核中开辟一块缓冲区,进程1把数据…...
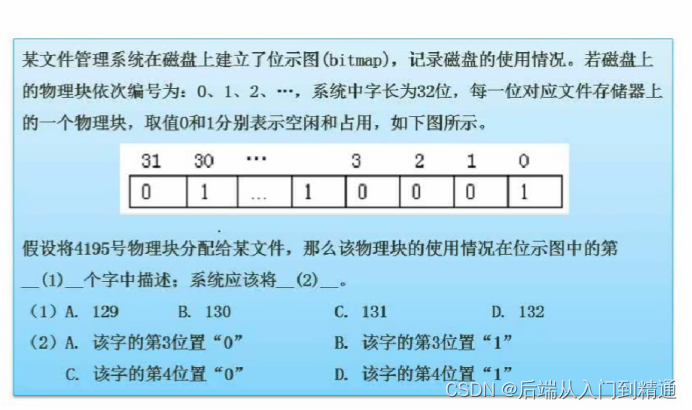
操作系统-页面淘汰算法(下)-软件设计(二十六)
操作系统-PV操作(上)-软件设计(二十五)https://blog.csdn.net/ke1ying/article/details/129476031 存储管理-分区存储组织 问:计算机系统内存大小为128k,当前系统分配情况如图,那么作业4再次申…...
)
23种设计模式-责任链模式(Android开发实际应用场景介绍)
什么是责任链模式 责任链模式是一种行为型设计模式,它的核心思想是将请求从一系列处理者中传递,直到其中一个处理者能够处理它为止。在这个过程中,请求可以被任何一个处理者处理,也可以被拒绝,直到有一个处理者能够处…...

Socket+Select+Epoll笔记
讲到epoll,就必须了解Socket,上篇博客写了Socket的基本使用方法,步骤主要为创建一个socketsocket是进程之间通信的,那么进程通信如何找到这个socket呢?当然是端口号,所以socket就要和端口号进行绑定&#x…...

git查看最近修改的文件
git log --name-status 每次修改的文件列表, 显示状态 git log --name-only 每次修改的文件列表 git log --stat 每次修改的文件列表, 及文件修改的统计 git whatchanged 每次修改的文件列表 git whatchanged --stat 每次修改的文件列表, 及文件修改的统计 git show 显示最…...
】堆排序(二))
【算法基础(四)】堆排序(二)
堆排序(二) 把数组从零开始连续的一段 完全二叉树 size i 左 son 2*11 i 右 son 2*12 父 (i-1) / 2 堆是完全二叉树,分为大根堆和小根堆 在完全二叉树里,每一棵子数最大的值是头节点的值,就是大根堆 同理&…...

C++类型转换
C语言的转换是在变量前加类型名进行转换的,比如double pi 3.14;int a (int) pi;对于指针也是如此double* dptr πint* iptr (int*)dptr;虽然c兼容了C语言的转型方式,但是也做了很多限制,比如向上类型转换,在c中建议使用…...

Keil MDK6要来了,将嵌入式软件开发水平带到新高度,支持跨平台(2023-03-11)
注:这个是MDK6,不是MDK5 AC6,属于下一代MDK视频版: https://www.bilibili.com/video/BV16s4y157WF Keil MDK6要来了,将嵌入式软件开发水平带到新高度,支持跨平台一年一度的全球顶级嵌入式会展Embedded Wor…...
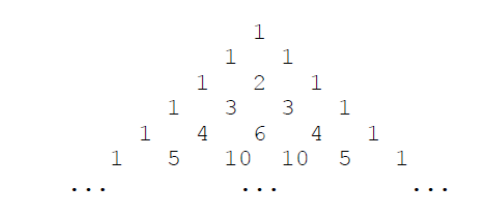
蓝桥杯刷题第九天
题目描述本题为填空题,只需要算出结果后,在代码中使用输出语句将所填结果输出即可。素数就是不能再进行等分的整数。比如7,11。而 9 不是素数,因为它可以平分为 3 等份。一般认为最小的素数是2,接着是 3,5&…...
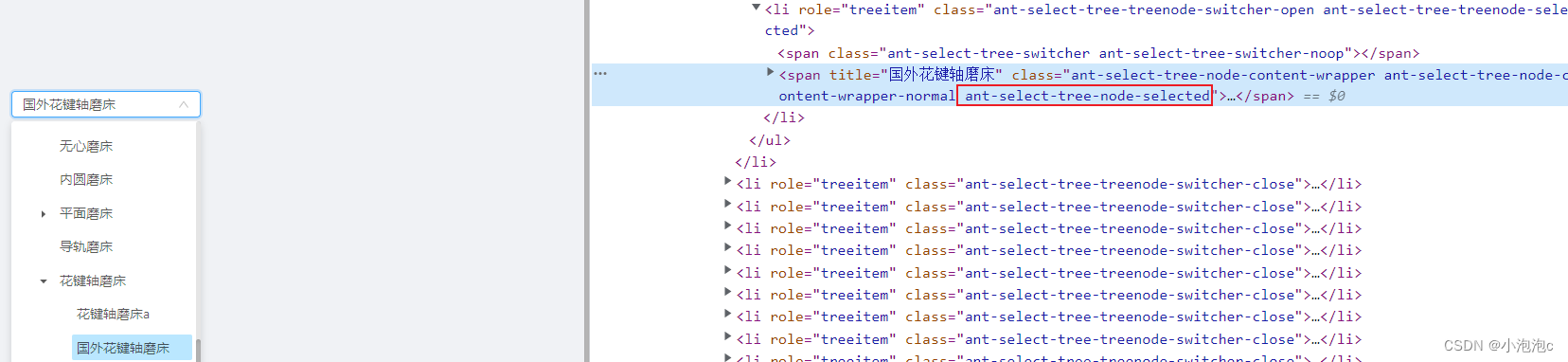
a-tree-select 基本使用,下拉框高度和宽度设置、回显时滚动条定位解决。
目录一、基本使用1. 界面效果2. 代码实现3. 问题1:下拉框占满整个屏幕4. 问题4:菜单内容过长时,下拉菜单宽度无限变宽。二、数据回显、滚动条定位1. 界面效果2. 代码实现2.1 获取默认展开节点2.1.1 代码实现2.1.2 说明2.2 设置滚动条定位2.2.…...
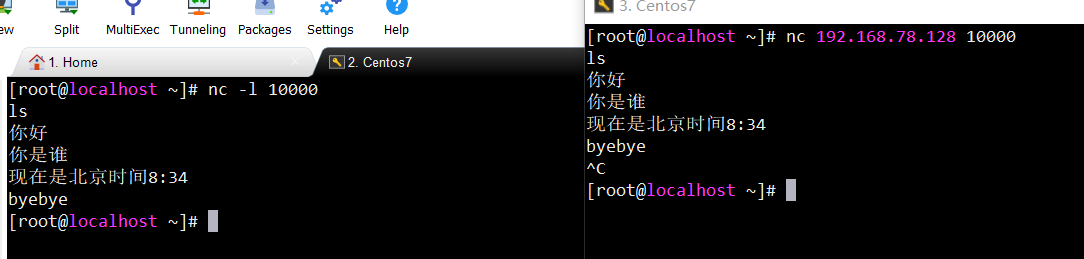
【Linux】之nc命令(连接与扫描指定端口、监测服务端口的使用情况)解析、详解实例、邮件告警
🍁博主简介 🏅云计算领域优质创作者 🏅华为云开发者社区专家博主 🏅阿里云开发者社区专家博主 💊交流社区:运维交流社区 欢迎大家的加入! 文章目录nc命令简介nc命令的安装nc命令语法格式…...
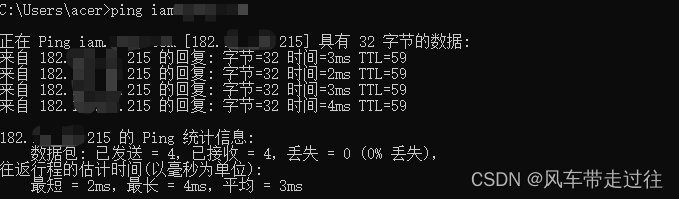
cdn简单配置
cdn配置域名接入CDN编辑CDN配置本地修改hosts文件,绕过公网解析域名接入CDN 添加CDN域名以及回源配置 编辑CDN配置 默认后端端口是80,如果测试发现无法访问,则可能是443或其它 如果域名在CDN后端有https强制跳转,后端端口一定是44…...
)
手把手教你用Arduino+ELM327读取OBD-II数据(附代码和常见故障码解析)
用Arduino与ELM327打造智能车载数据监控系统 在创客圈子里,车辆数据监控一直是个既实用又有趣的领域。想象一下,用不到200元的硬件成本,就能实时读取发动机转速、油耗数据甚至诊断车辆潜在故障——这正是Arduino与ELM327组合带来的可能性。不…...

基于花镇电子与出门问问的第三方ASR语音识别算法在博通SOC上的实现
基于华镇电子与出门问问的第三方ASR语音识别算法在博通SOC上的实现1 ASR架构2...

基于LLM的LSP服务器llm-ls:为IDE注入AI代码补全能力
1. 项目概述:一个为IDE注入AI灵魂的LSP服务器 如果你和我一样,每天都在和代码编辑器打交道,从Vim到VSCode,从IntelliJ到Jupyter,那你一定对LSP(Language Server Protocol)不陌生。它让我们的编辑…...

3步实战:用DistroAV插件解决OBS多机位网络传输难题
3步实战:用DistroAV插件解决OBS多机位网络传输难题 【免费下载链接】obs-ndi DistroAV (formerly OBS-NDI): NDI integration for OBS Studio 项目地址: https://gitcode.com/gh_mirrors/ob/obs-ndi 还在为OBS Studio的多机位同步而烦恼?想要实现…...

2003年那颗用砂纸磨出来的“中国芯“,毁掉了之后10年国产芯片人的口碑
大家好,我是写代码的篮球球痴。最近这一个多月,我连着写了一串国产芯片创始人——严晓浪、戚肖宁、张建辉、陈志坚、朱一明、王春华。这些人的共同点是:真在干活。有的是熬了20年才把生态做出来,有的是百万年薪不要去创业…...

如何高效配置开源工具:华硕笔记本性能管理的完整解决方案
如何高效配置开源工具:华硕笔记本性能管理的完整解决方案 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook,…...

121.YOLOv8从零到一实战,猫犬检测全流程,代码带注释,零基础也能学会
摘要 YOLO(You Only Look Once)是当前工业界和学术界最主流的目标检测算法之一,其核心优势在于将目标检测任务转化为单次回归问题,实现端到端的实时检测。本文从零基础出发,系统讲解YOLO的核心原理、模型架构演进,并基于Ultralytics框架提供完整的可运行代码案例,涵盖数…...

HYMiniMall项目配置详解:从开发环境到生产环境的完整部署
HYMiniMall项目配置详解:从开发环境到生产环境的完整部署 【免费下载链接】HYMiniMall 小程序商场项目 项目地址: https://gitcode.com/gh_mirrors/hy/HYMiniMall HYMiniMall是一个功能完善的小程序商场项目,本文将详细介绍如何从开发环境到生产环…...

CES 2016行业转向:从酷炫到实用,安全与服务成核心
1. 从“酷炫”到“实用”:CES 2016的行业转向解析每年一月的拉斯维加斯,对于科技行业而言,都像是一场盛大的朝圣。CES(国际消费电子展)不仅是新品发布的舞台,更是行业风向的晴雨表。2016年的CES,…...

简单学习 --> 数据加密
加密/加盐存储在数据库里的数据都是明文的, 如果数据库被盗, 数据就被泄露了;所以要进行加密密码算法对称密码算法: 加密和解密的算法用同一个; x明文,y密文 , f() 加密算法 > y f(x) , x f(y) ; 常见: AES , DES非对称密码算法: 公钥和私钥 ; > 使用公钥进行加密 , 使…...