BiLSTM模型实现
# 本段代码构建类BiLSTM, 完成初始化和网络结构的搭建
# 总共3层: 词嵌入层, 双向LSTM层, 全连接线性层
# 本段代码构建类BiLSTM, 完成初始化和网络结构的搭建
# 总共3层: 词嵌入层, 双向LSTM层, 全连接线性层
import torch
import torch.nn as nn# 本函数实现将中文文本映射为数字化张量
def sentence_map(sentence_list, char_to_id, max_length):"""将句子中的每一个字符映射到码表中:param sentence_list: 待映射的句子,类型为字符串或列表:param char_to_id: 码表,类型为字典,格式为格式为{"字1": 1, "字2": 2},例如:码表与id对照:char_to_id = {"双": 0, "肺": 1, "见": 2, "多": 3, "发": 4, "斑": 5, "片": 6,"状": 7, "稍": 8, "高": 9, "密": 10, "度": 11, "影": 12, "。": 13}:param max_length::return: 每一个字对应的编码,类型为tensor"""# 字符串按照逆序进行排序,不是必须操作sentence_list.sort(key=lambda c:len(c), reverse = True)# 定义句子映射列表sentence_map_list = []for sentence in sentence_list:# 生成句子中每个字对应的id列表sentence_id_list =[char_to_id[c] for c in sentence]# 计算所要填充0的长度padding = [0] * (max_length-len(sentence))# 组合sentence_map_list.append(sentence_id_list)# 返回句子映射集合,转为标量return torch.tensor(sentence_map_list, dtype= torch.long)class BiLSTM(nn.Module):"""BiLSTM模型定义"""def __init__(self, vocab_size, tag_to_id, input_feature_size, hidden_size,batch_size, sentence_length, num_layers=1, batch_first=True):"""description: 模型初始化:param vocab_size: 所有句子包含字符大小:param tag_to_id: 标签与 id 对照:param input_feature_size: 字嵌入维度( 即LSTM输入层维度 input_size ):param hidden_size: 隐藏层向量维度:param batch_size: 批训练大小:param sentence_length 句子长度:param num_layers: 堆叠 LSTM 层数:param batch_first: 是否将batch_size放置到矩阵的第一维度"""# 类继承初始化函数super(BiLSTM, self).__init__()# 设置标签与id对照self.tag_to_id = tag_to_id# 设置标签大小, 对应BiLSTM最终输出分数矩阵宽度self.tag_size = len(tag_to_id)# 设定LSTM输入特征大小, 对应词嵌入的维度大小self.embedding_size = input_feature_size# 设置隐藏层维度, 若为双向时想要得到同样大小的向量, 需要除以2self.hidden_size = hidden_size // 2# 设置批次大小, 对应每个批次的样本条数, 可以理解为输入张量的第一个维度self.batch_size = batch_size# 设定句子长度self.sentence_length = sentence_length# 设定是否将batch_size放置到矩阵的第一维度, 取值True, 或Falseself.batch_first = batch_first# 设置网络的LSTM层数self.num_layers = num_layers"""构建词嵌入层: 字向量, 维度为总单词数量与词嵌入维度参数: 总体字库的单词数量, 每个字被嵌入的维度"""self.embedding = nn.Embedding(vocab_size, self.embedding_size)self.bilstm = nn.LSTM(input_size=input_feature_size,hidden_size=self.hidden_size,num_layers=num_layers,bidirectional=True,batch_first=batch_first)# 构建全连接线性层: 将BiLSTM的输出层进行线性变换self.linear = nn.Linear(hidden_size, self.tag_size)print("=" * 100)
# 参数1:码表与id对照
char_to_id = {"双": 0, "肺": 1, "见": 2, "多": 3, "发": 4, "斑": 5, "片": 6,"状": 7, "稍": 8, "高": 9, "密": 10, "度": 11, "影": 12, "。": 13}# 参数2:标签码表对照
tag_to_id = {"O": 0, "B-dis": 1, "I-dis": 2, "B-sym": 3, "I-sym": 4}
# 参数3:字向量维度
EMBEDDING_DIM = 200
# 参数4:隐层维度
HIDDEN_DIM = 100
# 参数5:批次大小
BATCH_SIZE = 8
# 参数6:句子长度
SENTENCE_LENGTH = 20
# 参数7:堆叠 LSTM 层数
NUM_LAYERS = 1# 初始化模型
"""
model = BiLSTM(vocab_size=len(char_to_id),tag_to_id=tag_to_id,input_feature_size=EMBEDDING_DIM,hidden_size=HIDDEN_DIM,batch_size= BATCH_SIZE,sentence_length= SENTENCE_LENGTH,num_layers=NUM_LAYERS)print(model)
"""相关文章:

BiLSTM模型实现
# 本段代码构建类BiLSTM, 完成初始化和网络结构的搭建 # 总共3层: 词嵌入层, 双向LSTM层, 全连接线性层 # 本段代码构建类BiLSTM, 完成初始化和网络结构的搭建 # 总共3层: 词嵌入层, 双向LSTM层, 全连接线性层 import torch import torch.nn as nn# 本函数实现将中文文本映射为…...

linux内核源码学习所需基础
1.面向对象的思想,尤其是oopc的实现方式。 2.设计模式。 这两点需要内核源码学习者不仅要会c和汇编,还要接触一门面向对象的语言,比如c++/java/python等等任意一门都行,起码要了解面向对象的思想。 另外li…...
)
Java并发编程-AQS详解及案例实战(上篇)
文章目录 AQS概述AQS 的核心概念AQS 的工作原理AQS 的灵活性使用场景使用指南使用示例AQS的本质:为啥叫做异步队列同步器AQS的核心机制“异步队列”的含义“同步器”的含义总结加锁失败的时候如何借助AQS异步入队阻塞等待AQS的锁队列加锁失败时的处理流程异步入队的机制总结Ree…...

第11章 规划过程组(二)(11.8排列活动顺序)
第11章 规划过程组(二)11.8排列活动顺序,在第三版教材第391页; 文字图片音频方式 第一个知识点:主要输出 1、项目进度网络图 如图11-20 项目进度网络图示例 带有多个紧前活动的活动代表路径汇聚,而带有…...

DP学习——观察者模式
学而时习之,温故而知新。 敌人出招(使用场景) 多个对象依赖一个对象的状态改变,当业务中有这样的关系时你出什么招? 你出招 这个时候就要用观察者模式这招了! 2个角色 分为啥主题和观察者角色。 我觉…...
如何利用GPT-4o生成有趣的梗图
文章目录 如何利用GPT-4o生成有趣的梗图一、引言二、使用GPT-4o生成梗图1. 提供主题2. 调用工具3. 获取图片实际案例输入输出 三、更多功能1. 创意和灵感2. 梗图知识 四、总结 如何利用GPT-4o生成有趣的梗图 梗图,作为互联网文化的一部分,已经成为了我们…...

深入理解 KVO
在 iOS 中,KVO(Key-Value Observing)是一个强大的观察机制,它的底层实现相对复杂。KVO 利用 Objective-C 的动态特性,为对象的属性提供观察能力。 KVO 的底层实现 1. 动态子类化 当一个对象的属性被添加观察者时&am…...

当需要对大量数据进行排序操作时,怎样优化内存使用和性能?
文章目录 一、选择合适的排序算法1. 快速排序2. 归并排序3. 堆排序 二、数据结构优化1. 使用索引2. 压缩数据3. 分块排序 三、外部排序1. 多路归并排序 四、利用多核和并行计算1. 多线程排序2. 使用并行流 五、性能调优技巧1. 避免不必要的内存复制2. 缓存友好性3. 基准测试和性…...

kubernetes集群部署:node节点部署和cri-docker运行时安装(四)
安装前准备 同《kubernetes集群部署:环境准备及master节点部署(二)》 安装cri-docker 在 Kubernetes 1.20 版本之前,Docker 是 Kubernetes 默认的容器运行时。然而,Kubernetes 社区决定在 Kubernetes 1.20 及以后的…...

第五十章 Web Service URL 汇总
文章目录 第五十章 Web Service URL 汇总Web 服务 URLWeb 服务的端点WSDL 使用受密码保护的 WSDL URL 第五十章 Web Service URL 汇总 本主题总结了与 IRIS 数据平台 Web 服务相关的 URL。 Web 服务 URL 与 IRIS Web 服务相关的 URL 如下: Web 服务的端点 http…...

动态白色小幽灵404网站源码
动态白色小幽灵404网站源码,页面时单页HTML源码,将代码放到空白的html里面,鼠标双击html即可查看效果,或者上传到服务器,错误页重定向这个界面即可,喜欢的朋友可以拿去使用 <!DOCTYPE html> <ht…...

axios的使用,处理请求和响应,axios拦截器
1、axios官网 https://www.axios-http.cn/docs/interceptors 2、安装 npm install axios 3、在onMouunted钩子函数中使用axios来发送请求,接受响应 4.出现的问题: (1) 但是如果发送请求请求时间过长,回出现请求待处…...

visual studio 2017增加.cu文件
右击项目名称,选择生成依赖项>生成自定义把CUDA11.3target勾选上; 把带有cuda代码的.cpp文件和.cu文件右击属性>项类型>选择CUDA C/C 右击项目名称,C/C>命令行添加/D _CRT_SECURE_NO_WARNINGS; 选择CUDA C/C>命…...

linux 管道符 |
在Linux中,管道符(|)是一个非常重要的概念,它允许你将一个命令的输出作为另一个命令的输入。这种机制使得Linux命令可以非常灵活地进行组合,从而执行复杂的任务。 管道符的基本用法 假设你有两个命令:com…...

Android - SIP 协议
SIP 代表(会话发起协议)。 它是一种协议,可让应用程序轻松设置呼出和呼入语音呼叫,而无需直接管理会话、传输级通信或音频记录或回放。 SIP 应用程序 SIP 的一些常见应用是。 视频会议即时消息 开发要求 以下是开发 SIP 应用程序的要求 − Android 操作系…...
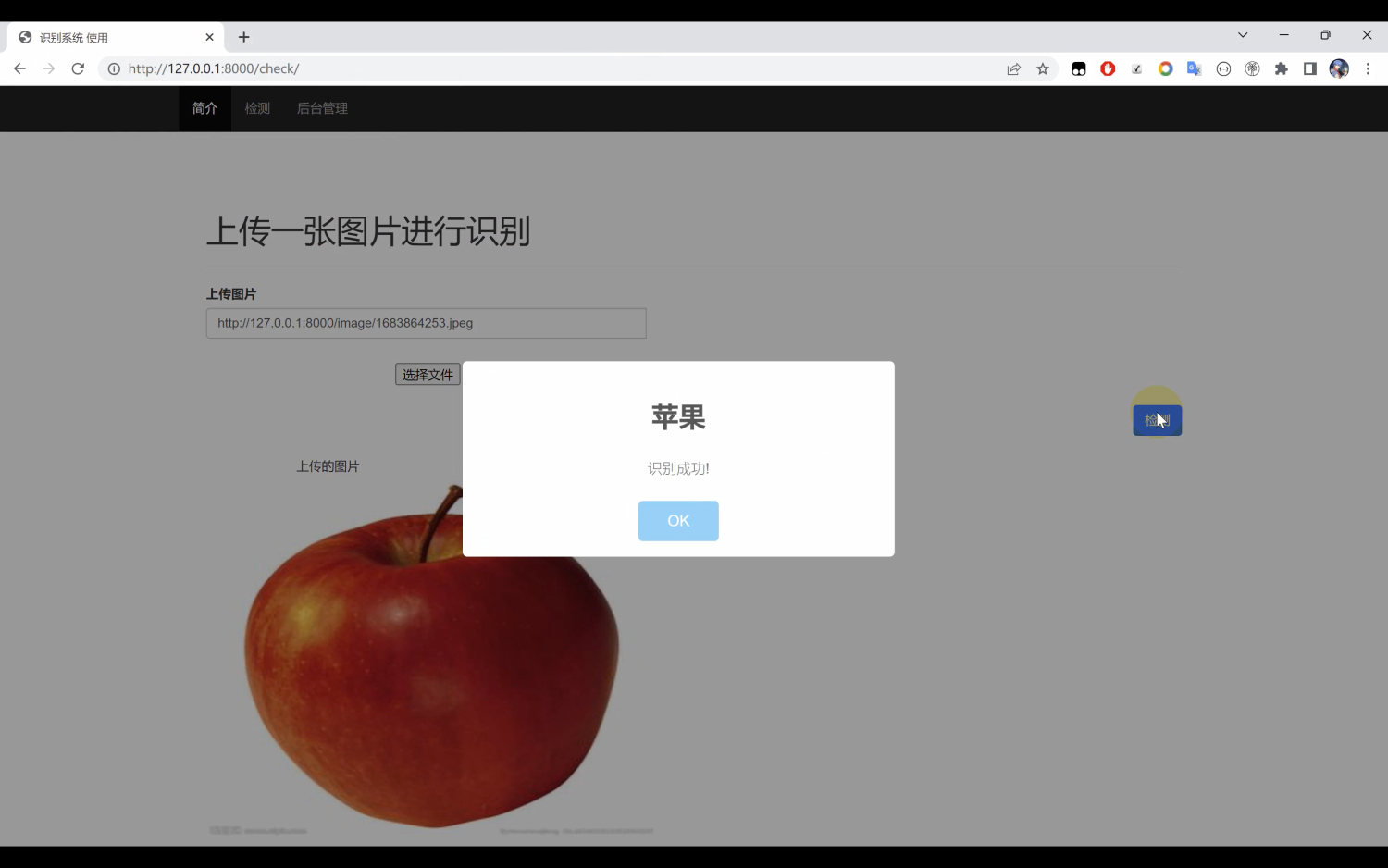
Python结合MobileNetV2:图像识别分类系统实战
一、目录 算法模型介绍模型使用训练模型评估项目扩展 二、算法模型介绍 图像识别是计算机视觉领域的重要研究方向,它在人脸识别、物体检测、图像分类等领域有着广泛的应用。随着移动设备的普及和计算资源的限制,设计高效的图像识别算法变得尤为重要。…...

【】AI八股-神经网络相关
Deep-Learning-Interview-Book/docs/深度学习.md at master amusi/Deep-Learning-Interview-Book GitHub 网上相关总结: 小菜鸡写一写基础深度学习的问题(复制大佬的,自己复习用) - 知乎 (zhihu.com) CV面试问题准备持续更新贴 …...

NodeJs的安装与环境变量配置
Node.js的环境变量配置主要涉及设置Node.js的安装路径、npm(Node Package Manager)的全局模块安装路径和缓存路径,以及可能需要的国内镜像源配置。以下是详细的配置步骤: 一、安装Node.js 下载Node.js安装包: 访问Nod…...

进程输入输出及终端属性学习
进程的标准输入输出 当主进程fork或exec子进程,文件描述符被继承,因此0,1,2句柄也被继承,从而使得telnet等服务,可以做到间接调用别的shell或程序。比如如果是远程登录使用的zsh,那么其会重定向到相应的pts $ ps|gre…...

关于redis集群和事务
最近为了核算项目的两个架构指标(可用性和伸缩性),需要对项目中使用的Redis数据库的集群部署进行一定程度的了解,当然顺便再学习一遍它的事务细节。 既然我在上面把Redis称之为数据库,那么在我们目前的项目里…...

DISMTools企业部署:在组织中大规模应用的最佳实践
DISMTools企业部署:在组织中大规模应用的最佳实践 【免费下载链接】DISMTools The connected place for Windows system administration 项目地址: https://gitcode.com/GitHub_Trending/di/DISMTools DISMTools是一款专为Windows系统管理设计的连接平台&…...

用数字逻辑门复刻柏林钟:从二进制编码到硬件实现
1. 项目概述:用数字电路复刻“柏林钟”作为一个在柏林长大的孩子,我从小就对库达姆大街上的那座“柏林钟”着迷。它不像传统时钟那样用指针或数字告诉你时间,而是通过几排不同颜色的发光方块,以一种近乎艺术的方式呈现时间。这种独…...

终极艾尔登法环帧率解锁指南:轻松突破60FPS限制
终极艾尔登法环帧率解锁指南:轻松突破60FPS限制 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenRing…...

FT231XQ USB串口桥接板设计解析与实战应用指南
1. 项目概述:从FT232R到FT231XQ的USB串口桥接板演进在嵌入式开发和硬件调试的日常工作中,一个可靠、小巧且功能清晰的USB转串口(UART)桥接板(Breakout Board, 简称BoB)几乎是工程师手边的标配工…...

【MySQL数据库 | 第一篇】 概述
数据库相关概念: 数据库(Database):数据库是指一组有组织的数据的集合,通过计算机程序进行管理和访问。数据库管理系统:操纵和管理数据库的大型软件SQL:操作关系型数据库的编程语言,定义了一套操作关系型数…...
)
Claude端到端测试设计:从零搭建可审计、可回放、可量化的AI服务测试流水线(含开源Schema校验工具)
更多请点击: https://codechina.net 第一章:Claude端到端测试设计 端到端测试是验证Claude模型在真实用户交互链路中行为一致性的关键手段。它覆盖从原始提示输入、上下文管理、流式响应生成,到输出解析与业务校验的全路径,确保模…...
做电影评论情感分类)
告别数据饥荒:用PyTorch手把手实现原型网络(Prototypical Networks)做电影评论情感分类
告别数据饥荒:用PyTorch手把手实现原型网络做电影评论情感分类 在自然语言处理领域,情感分析一直是热门研究方向,但现实中的开发者常面临一个尴尬困境:标注数据太少。传统深度学习方法动辄需要成千上万的标注样本,而实…...

告别CAJ格式困扰:3分钟学会用开源工具将知网文献转为PDF
告别CAJ格式困扰:3分钟学会用开源工具将知网文献转为PDF 【免费下载链接】caj2pdf Convert CAJ (China Academic Journals) files to PDF. 转换中国知网 CAJ 格式文献为 PDF。佛系转换,成功与否,皆是玄学。 项目地址: https://gitcode.com/…...

LangGraph状态机工程:构建复杂AI工作流的完整指南
传统RAG(检索增强生成)在处理简单的"单跳"问题时表现良好——“文章里提到了什么” “这个概念是什么意思”——但当问题涉及多个实体之间的关系、需要跨多个文档推理时,传统RAG就显得力不从心。GraphRAG(Graph-based R…...

别再把大模型当搜索框了:一文讲透 LLM 的基本原理、能力边界与局限性
写在前面很多人把大语言模型当成“会聊天的搜索引擎”,结果一上线就遇到幻觉、口径不稳、上下文丢失、成本失控。真正理解 LLM,要先抓住一句话:它是基于 Transformer 的概率生成模型,核心能力来自海量预训练、上下文学习与后训练对…...