Go 依赖注入设计模式
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。

-
推荐:「stormsha的主页」👈,持续学习,不断总结,共同进步,为了踏实,做好当下事儿~
-
专栏导航
- Python系列: Python面试题合集,剑指大厂
- Git系列: Git操作技巧
- GO系列: 记录博主学习GO语言的笔记,该笔记专栏尽量写的试用所有入门GO语言的初学者
- 数据库系列: 详细总结了常用数据库 mysql 技术点,以及工作中遇到的 mysql 问题等
- 运维系列: 总结好用的命令,高效开发
- 算法与数据结构系列: 总结数据结构和算法,不同类型针对性训练,提升编程思维
非常期待和您一起在这个小小的网络世界里共同探索、学习和成长。💝💝💝 ✨✨ 欢迎订阅本专栏 ✨✨
💖The Start💖点点关注,收藏不迷路💖📒文章目录
- 依赖注入的基本概念
- Go 语言中实现依赖注入的挑战
- 手动实现依赖注入
- 使用反射进行依赖注入
- 使用第三方库
- 使用 Wire
- 使用 Dig
- 总结

在软件开发中,依赖注入(Dependency Injection, DI)是一种设计模式,它允许开发者将依赖关系从组件中解耦出来,从而提高代码的模块化和可测试性。Go 语言以其简洁和高效著称,但原生并不支持依赖注入。然而,这并没有阻止开发者在 Go 中实现依赖注入。本文将探讨在 Go 中实现依赖注入的一些技巧
依赖注入的基本概念
在深入讨论 Go 中的实现技巧之前,我们先简要回顾一下依赖注入的基本概念。依赖注入是一种编程模式,它允许开发者将组件所需的依赖项以参数的形式传递给组件,而不是让组件自己创建或查找这些依赖项。这通常通过构造函数、方法调用或属性赋值实现。
Go 语言中实现依赖注入的挑战
Go 语言的类型系统和编译时特性使得它在某些方面不适合原生实现依赖注入。例如,Go 没有接口默认方法,这限制了依赖注入框架的灵活性。此外,Go 的编译器不会自动处理依赖项的注入,这意味着开发者需要手动管理依赖关系。
手动实现依赖注入
尽管 Go 没有原生支持,但开发者可以通过手动方式实现依赖注入。以下是一种简单的手动实现方法:
- 定义接口:首先定义一个接口来描述依赖项的行为。
- 实现接口:为不同的依赖项提供具体的实现。
- 构造函数注入:在组件的构造函数中接受依赖项作为参数。
package mainimport "fmt"// 定义一个数据库操作的接口
type Database interface {Query(query string) string
}// 实现数据库接口
type MySQL struct{}func (m *MySQL) Query(query string) string {return fmt.Sprintf("Executing query on MySQL: %s", query)
}// 需要数据库依赖的组件
type DataProcessor struct {db Database
}func NewDataProcessor(db Database) *DataProcessor {return &DataProcessor{db: db}
}func main() {db := &MySQL{}processor := NewDataProcessor(db)fmt.Println(processor.db.Query("SELECT * FROM users"))
}
使用反射进行依赖注入
Go 的 reflect 包提供了一种在运行时检查和调用类型信息的能力。利用反射,我们可以在一定程度上实现依赖注入:
- 使用标签:在结构体字段上使用标签来指定依赖项。
- 反射注入:通过反射遍历结构体的字段,并根据标签注入依赖项。
package mainimport ("fmt""reflect"
)type DependencyInjector struct {dependencies map[string]interface{}
}func NewDependencyInjector() *DependencyInjector {return &DependencyInjector{dependencies: make(map[string]interface{}),}
}func (di *DependencyInjector) Provide(name string, dependency interface{}) {di.dependencies[name] = dependency
}func (di *DependencyInjector) Inject(target interface{}) {t := reflect.TypeOf(target)v := reflect.ValueOf(target)for i := 0; i < t.NumField(); i++ {field := t.Field(i)depName := field.Tag.Get("inject")if depName != "" {if dep, ok := di.dependencies[depName]; ok {fieldValue := v.Elem().Field(i)fieldValue.Set(reflect.ValueOf(dep))}}}
}// 示例使用
type Service struct {DB Database `inject:"db"`
}func main() {injector := NewDependencyInjector()injector.Provide("db", &MySQL{})service := Service{}injector.Inject(&service)fmt.Println(service.DB.Query("SELECT * FROM users"))
}
使用第三方库
虽然手动实现和反射方法可以工作,但它们可能不够灵活或效率低下。幸运的是,有第三方库可以帮助我们在 Go 中实现依赖注入,例如 wire 和 dig。
- Wire:一个代码生成工具,它分析代码并生成所需的注入代码。
- Dig:一个轻量级的依赖注入容器,它使用标签来管理依赖关系。
使用 Wire
Wire 通过分析 Go 代码中的构造函数来自动生成依赖注入的代码。使用 Wire,你只需要定义你的组件和它们的依赖关系,然后 Wire 会生成一个 wire_gen.go 文件,其中包含了所有必要的注入逻辑。
使用 Dig
Dig 是一个更现代的依赖注入库,它使用 Go 的标签系统来识别和注入依赖项。Dig 允许你定义依赖项的生命周期,并提供了一个简单的 API 来管理依赖项的注入。
总结
依赖注入是一种强大的设计模式,可以帮助开发者编写更干净、更模块化的代码。虽然 Go 语言没有原生支持依赖注入,但通过手动实现、使用反射或利用第三方库,我们仍然可以在 Go 中有效地使用这一模式。选择哪种方法取决于你的具体需求和偏好,但无论如何,依赖注入都是提升 Go 开发效率的一个有力工具。
🔥🔥🔥道阻且长,行则将至,让我们一起加油吧!🌙🌙🌙
| 💖The End💖点点关注,收藏不迷路💖 |
相关文章:
Go 依赖注入设计模式
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「stormsha的主页」…...

使用React复刻ThreeJS官网示例——keyframes动画
最近在看three.js相关的东西,想着学习一下threejs给的examples。源码是用html结合js写的,恰好最近也在学习react,就用react框架学习一下。 本文参考的是threeJs给的第一个示例 three.js examples (threejs.org) 一、下载threeJS源码 通常我们…...
嵌入式linux面试1
1. linux 1.1. Window系统和Linux系统的区别 linux区分大小写windows在dos(磁盘操作系统)界面命令下不区分大小写; 1.2. 文件格式区分 windows用扩展名区分文件;如.exe代表执行文件,.txt代表文本文件,.…...

智能交通(3)——Learning Phase Competition for Traffic Signal Control
论文分享 https://dl.acm.org/doi/pdf/10.1145/3357384.3357900https://dl.acm.org/doi/pdf/10.1145/3357384.3357900 论文代码 https://github.com/gjzheng93/frap-pubhttps://github.com/gjzheng93/frap-pub 摘要 越来越多可用的城市数据和先进的学习技术使人们能够提…...

【扩散模型】LCM LoRA:一个通用的Stable Diffusion加速模块
潜在一致性模型:[2310.04378] Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference (arxiv.org) 原文:Paper page - Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference (…...

【PYG】pytorch中size和shape有什么不同
一般使用tensor.shape打印维度信息,因为简单直接 在 PyTorch 中,size 和 shape 都用于获取张量的维度信息,但它们之间有细微的区别。下面是它们的定义和用法: size: size 是一个方法(size())和…...

备份服务器出错怎么办?
在企业的日常运营中,备份服务器扮演着至关重要的角色,它确保了数据的安全和业务的连续性。然而,备份服务器也可能遇到各种问题,如备份失败、数据损坏或备份系统故障等。这些问题可能导致数据丢失或业务中断,给企业带来…...

数据库(表)
要求如下: 一:数据库 1,登录数据库 mysql -uroot -p123123 2,创建数据库zoo create database zoo; Query OK, 1 row affected (0.01 sec) 3,修改字符集 mysql> use zoo;---先进入数据库zoo Database changed …...

Feign-未完成
Feign Java中如何实现接口调用?即如何发起http请求 前三种方式比较麻烦,在发起请求前,需要将Java对象进行序列化转为json格式的数据,才能发送,然后进行响应时,还需要把json数据进行反序列化成java对象。 …...

# [0705] Task06 DDPG 算法、PPO 算法、SAC 算法【理论 only】
easy-rl PDF版本 笔记整理 P5、P10 - P12 joyrl 比对 补充 P11 - P13 OpenAI 文档整理 ⭐ https://spinningup.openai.com/en/latest/index.html 最新版PDF下载 地址:https://github.com/datawhalechina/easy-rl/releases 国内地址(推荐国内读者使用): 链…...

Open3D 点云CPD算法配准(粗配准)
目录 一、概述 二、代码实现 2.1关键函数 2.2完整代码 三、实现效果 3.1原始点云 3.2配准后点云 一、概述 在Open3D中,CPD(Coherent Point Drift,一致性点漂移)算法是一种经典的点云配准方法,适用于无序点云的非…...
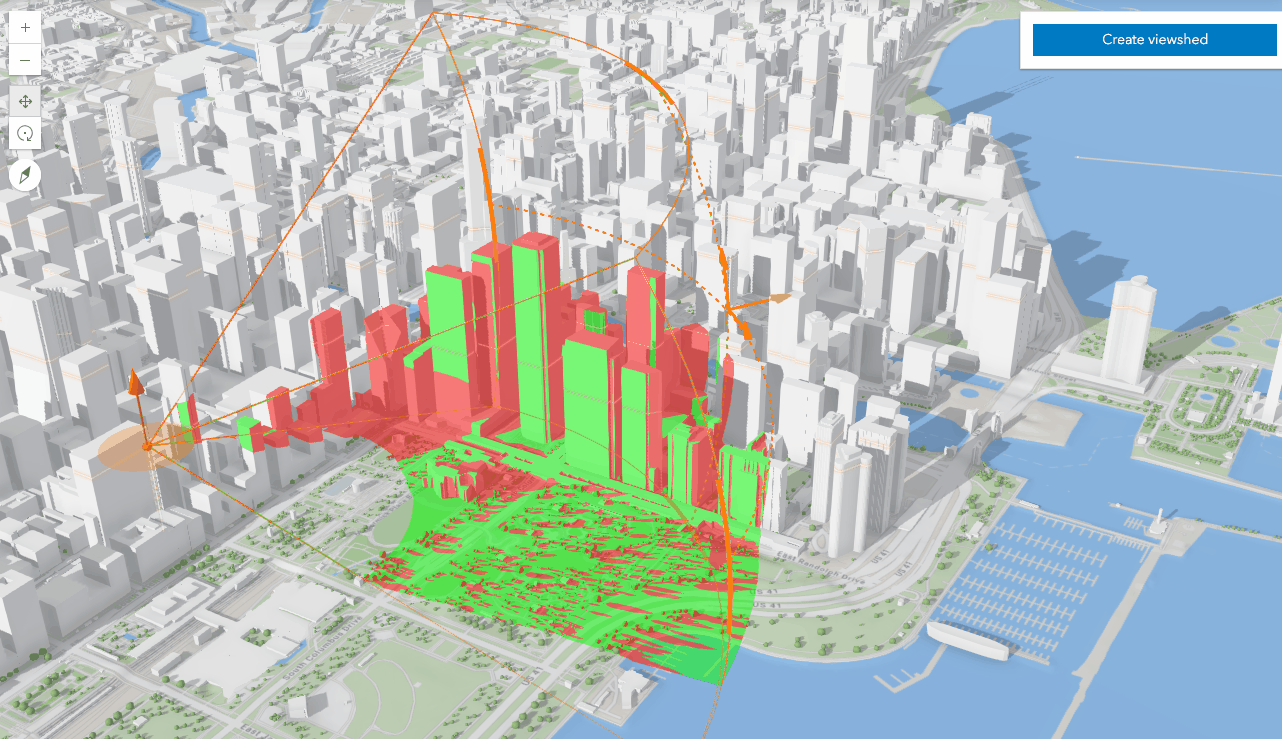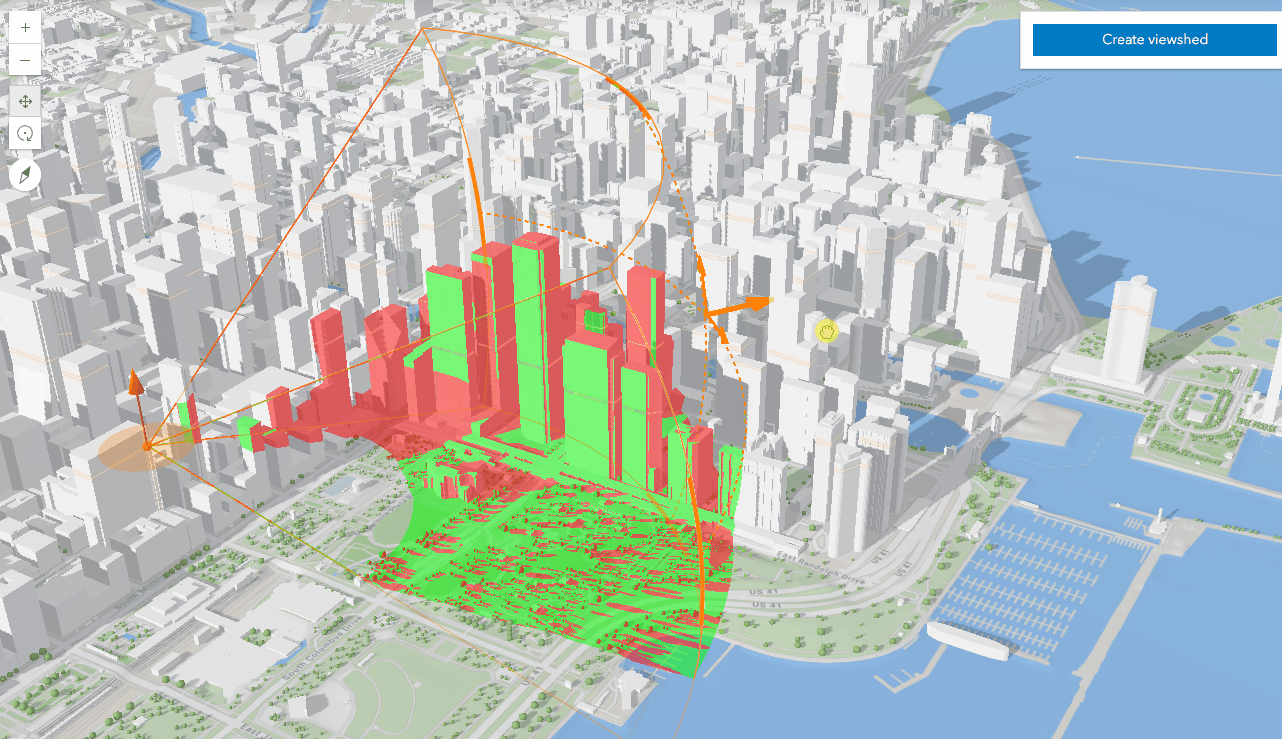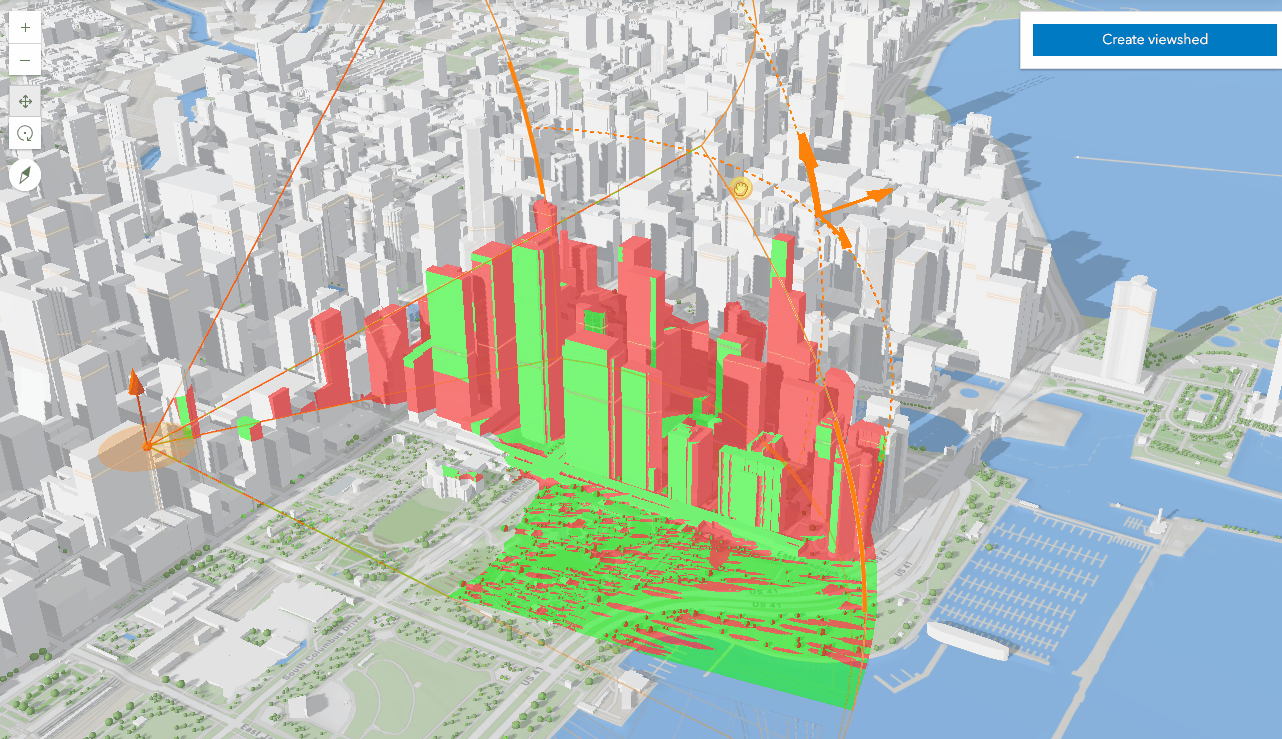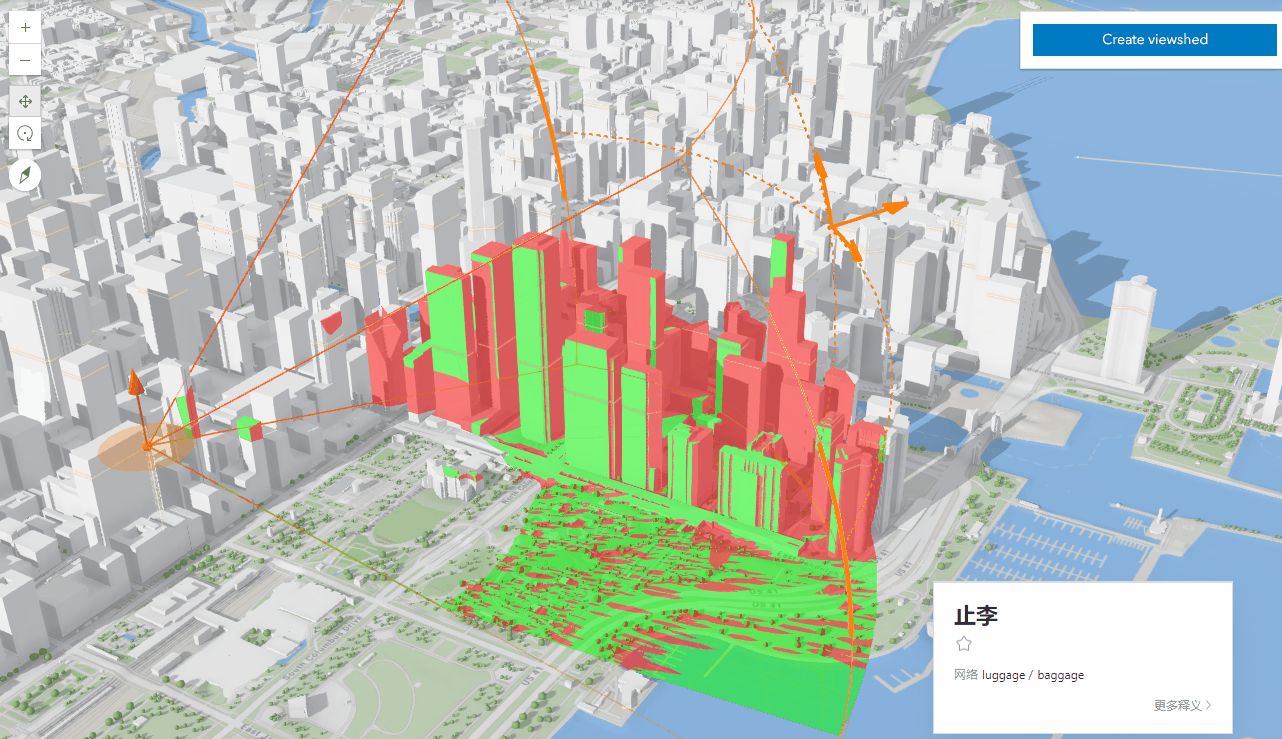
04-ArcGIS For JavaScript的可视域分析功能
文章目录 综述代码实现代码解析结果 综述 在数字孪生或者实景三维的项目中,视频融合和可视域分析,一直都是热点问题。Cesium中,支持对阴影的后处理操作,通过重新编写GLSL代码就能实现视域和视频融合的功能。ArcGIS之前支持的可视…...

Nestjs基础
一、创建项目 1、创建 安装 Nest CLI(只需要安装一次) npm i -g nestjs/cli 进入要创建项目的目录,使用 Nest CLI 创建项目 nest new 项目名 运行项目 npm run start 开发环境下运行,自动刷新服务 npm run start:dev 2、…...

DDL:针对于数据库、数据表、数据字段的操作
数据库的操作 # 查询所有数据 SHOW DATABASE; #创建数据库 CREATE DATABASE 2404javaee; #删除数据库 DROP DATABASE 2404javaee; 数据表的操作 #创建表 CREATE TABLE s_student( name VARCHAR(64), s_sex VARCHAR(32), age INT(3), salary FLOAT(8,2), c_course VARC…...
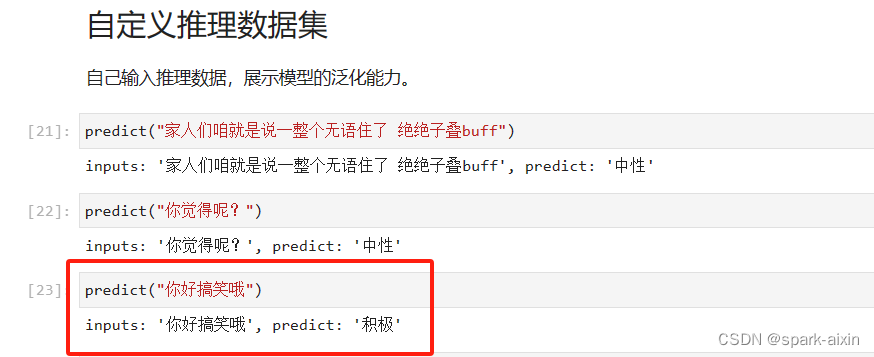
昇思学习打卡-5-基于Mindspore实现BERT对话情绪识别
本章节学习一个基本实践–基于Mindspore实现BERT对话情绪识别 自然语言处理任务的应用很广泛,如预训练语言模型例如问答、自然语言推理、命名实体识别与文本分类、搜索引擎优化、机器翻译、语音识别与合成、情感分析、聊天机器人与虚拟助手、文本摘要与生成、信息抽…...
 List中增删改查的注意事项)
Java中 普通for循环, 增强for循环( foreach) List中增删改查的注意事项
文章目录 俩种循环遍历增加删除1 根据index删除2 根据对象删除 修改 俩种循环 Java中 普通for循环, 增强for循环( foreach) 俩种List的遍历方式有何异同,性能差异? 普通for循环(使用索引遍历): for (int…...
昇思25天学习打卡营第19天|LSTM+CRF序列标注
概述 序列标注指给定输入序列,给序列中每个Token进行标注标签的过程。序列标注问题通常用于从文本中进行信息抽取,包括分词(Word Segmentation)、词性标注(Position Tagging)、命名实体识别(Named Entity Recognition, NER)等。 条件随机场(…...

微服务: 初识 Spring Cloud
什么是微服务? 微服务就像把一个大公司拆成很多小部门,每个部门各自负责一块业务。这样一来,每个部门都可以独立工作,即使一个部门出了问题,也不会影响整个公司运作。 什么是Spring Cloud? Spring Cloud 是一套工具包&#x…...

探索InitializingBean:Spring框架中的隐藏宝藏
🌈 个人主页:danci_ 🔥 系列专栏:《设计模式》《MYSQL》 💪🏻 制定明确可量化的目标,坚持默默的做事。 ✨欢迎加入探索MYSQL索引数据结构之旅✨ 👋 Spring框架的浩瀚海洋中&#x…...

JVM专题之垃圾收集算法
标记清除算法 第一步:标记 (找出内存中需要回收的对象,并且把它们标记出来) 第二步:清除 (清除掉被标记需要回收的对象,释放出对应的内存空间) 缺点: 标记清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致以后在程序运行过程中需 要分配较大对象时,无法找到…...
Pixel Aurora Engine开发者指南:Diffusers集成与LoRA热加载详解
Pixel Aurora Engine开发者指南:Diffusers集成与LoRA热加载详解 1. 像素极光引擎概述 Pixel Aurora Engine是一款专为像素艺术生成设计的AI绘图工作站,采用复古8-bit游戏风格界面,将现代扩散模型技术与经典像素美学完美结合。这款引擎的核心…...

5个高效步骤打造Dell G15终极散热控制中心
5个高效步骤打造Dell G15终极散热控制中心 【免费下载链接】tcc-g15 Thermal Control Center for Dell G15 - open source alternative to AWCC 项目地址: https://gitcode.com/gh_mirrors/tc/tcc-g15 为什么专业游戏玩家和工程师都在抛弃官方散热软件?在高性…...

Nomacs图像查看器:从安装到高级使用的完整指南
Nomacs图像查看器:从安装到高级使用的完整指南 【免费下载链接】nomacs nomacs is a free image viewer for windows, linux, and mac systems. 项目地址: https://gitcode.com/gh_mirrors/no/nomacs Nomacs是一款免费开源的跨平台图像查看器,支持…...

开源麻将AI分析工具:3步颠覆传统牌局决策模式
开源麻将AI分析工具:3步颠覆传统牌局决策模式 【免费下载链接】Akagi 支持雀魂、天鳳、麻雀一番街、天月麻將,能夠使用自定義的AI模型實時分析對局並給出建議,內建Mortal AI作為示例。 Supports Majsoul, Tenhou, Riichi City, Amatsuki, wit…...

智能体快速构建指南
智能体快速构建指南 基于 NVIDIA GTC 大会「Agentic AI 101」主题讲座整理 覆盖:本质认知 → 核心模块 → 落地场景 → 实操路径 一、Agentic AI 是什么?与传统 AI 的本质分野 一句话定义 传统 AI 告诉你怎么做,Agentic AI 直接帮你做完。 传…...

个人博客域名迁移说明 www.xiaoming.io
因为之前很多文章和插图都链接到了个人博客,一些读者评论和私信反馈链接有问题,图片不显示,这里特地说明如下:个人博客域名从原先的 www.hainter.com 改成了 www.xiaoming.io。例如文章中有链接 http://www.hainter.com/books 不能…...

数据科学好帮手:OpenClaw+千问3.5-35B-A3B-FP8自动化报表分析与可视化
数据科学好帮手:OpenClaw千问3.5-35B-A3B-FP8自动化报表分析与可视化 1. 为什么需要自动化数据分析 作为一名经常与数据打交道的分析师,我每天要处理大量重复性工作:清洗CSV文件、检查异常值、生成趋势图表、编写分析报告。这些工作占用了7…...

2025_NIPS_HumanoidGen: Data Generation for Bimanual Dexterous Manipulation via LLM Reasoning
文章核心总结与翻译 一、主要内容 本文提出HumanoidGen,一款基于大语言模型(LLM)推理的自动化框架,专为类人机器人双手机动操作生成任务场景与演示数据。框架通过空间标注、LLM规划、蒙特卡洛树搜索(MCTS)增强推理等模块,解决现有数据集缺乏双手机动操作场景、数据收集…...
)
C#实战:5步搞定阿里健康药品追溯码接口对接(附完整签名源码)
C#实战:5步高效对接阿里健康药品追溯码API 在医院和药店管理系统中,药品追溯功能已成为刚需。阿里健康提供的药品追溯码查询接口,能帮助医疗机构快速获取药品全流程信息。作为.NET开发者,你可能需要将这个功能集成到现有ERP系统中…...

跳棋游戏中的多重捕获实现
跳棋(Checkers)是许多棋类爱好者喜爱的一款游戏,它的规则简单,但策略深度却非常丰富。今天我们来讨论跳棋游戏中的一个复杂而有趣的功能——多重捕获的实现。在本文中,我们将深入探讨如何在JavaScript中编写一个可以检测并执行多重捕获的函数。 基本概念 在跳棋游戏中,…...