【扩散模型】LCM LoRA:一个通用的Stable Diffusion加速模块
潜在一致性模型:[2310.04378] Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference (arxiv.org)
原文:Paper page - Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference (huggingface.co)
简介:LCM 只需 4,000 个训练步骤(约 32 个 A100 GPU/小时)即可从任何预训练的稳定扩散 (SD) 中提取出来,只需 2~4 个步骤甚至一步即可生成高质量的 768 x 768 分辨率图像,从而显着加速文本转换 -图像生成。
潜在一致性模型
介绍
潜在扩散模型(Latent Diffusion models, ldm)在高分辨率图像合成方面取得了显著的成果。然而,迭代采样过程计算量大,导致生成速度慢。受一致性模型的启发,我们提出了潜在一致性模型(Latent Consistency Models, lcm),能够在任何预训练的ldm上以最小的步骤进行快速推理,包括稳定扩散。
原理:将引导反向扩散过程视为求解增强概率流ODE (PF-ODE), lcm设计用于直接预测潜在空间中此类ODE的解,从而减少了多次迭代的需要,并允许快速,高保真采样。有效地从预训练的无分类器引导扩散模型中提取,高质量的768×768 2 ~ 4步LCM仅需32 A100 GPU小时即可进行训练。此外,引入了潜在一致性微调(LCF),这是一种针对自定义图像数据集微调LCF的新方法。
一致性模型(CMs):作为一种新型生成模型显示出巨大的潜力,可以在保持生成质量的同时加快采样速度。一致性模型采用一致性映射,直接将ODE轨迹中的任意点映射到原点,实现快速一步生成。可以通过提取预训练的扩散模型或作为独立的生成模型进行训练。
原理
潜在空间中的一致性蒸馏
在诸如稳定扩散(Stable Diffusion, SD)(Rombach et al, 2022)等大规模扩散模型中,利用图像的潜在空间有效地提高了图像生成质量并减少了计算负载。在SD中,首先训练一个自编码器(E, D)来将高维图像数据压缩为低维潜在向量 𝑧=𝐸(𝑥)z=E(x),然后解码以重建图像 𝑥ˆ=𝐷(𝑧)xˆ=D(z)。在潜在空间中训练扩散模型与基于像素的模型相比,大大降低了计算成本并加快了推理过程;潜在扩散模型(LDMs)使得在笔记本电脑的GPU上生成高分辨率图像成为可能。
对于潜在一致性模型(LCMs),我们利用潜在空间的一致性蒸馏优势,与一致性模型(CMs)(Song et al, 2023)中使用的像素空间形成对比。这种方法被称为潜在一致性蒸馏(LCD),应用于预训练的SD,允许在1至4步内合成高分辨率的768×768图像。我们专注于条件生成。回顾一下逆扩散过程的PF-ODE:

其中𝑧𝑡是图像潜在变量,𝜖𝜃(𝑧𝑡,𝑐,𝑡) 是噪声预测模型,𝑐 是给定的条件(例如文本)。通过从 𝑇 到 0 解决 PF-ODE 可以抽取样本。为了执行潜在一致性蒸馏(LCD),我们引入一致性函数 𝑓𝜃:(𝑧𝑡,𝑐,𝑡)→𝑧0,直接预测 𝑡=0 时 PF-ODE 的解(公式8)。通过噪声预测模型 𝜖^𝜃参数化 𝑓𝜃,如下所示:

其中 𝑐skip(0)=1,𝑐out(0)=0,且 𝜖^𝜃(𝑧,𝑐,𝑡) 是噪声预测模型,其初始参数与教师扩散模型相同。假设有一个高效的ODE求解器 Ψ(𝑧𝑡,𝑡,𝑠,𝑐),用于近似积分公式8的右侧,从时间 𝑡 到 𝑠。在实际操作中,可以使用DDIM,DPM-Solver或DPM-Solver++ 作为 Ψ(⋅,⋅,⋅,⋅)。
只在训练/蒸馏中使用这些求解器,而不是在推理中。潜在一致性模型(LCM)旨在通过最小化一致性蒸馏损失来预测PF-ODE的解:

通过求解增强的PF-ODE进行单阶段引导蒸馏
无分类器引导(Classifier-free guidance, CFG)对于在稳定扩散(SD)中合成高质量的文本对齐图像至关重要,通常需要大于6的CFG比例 𝜔。因此,将CFG集成到蒸馏方法中变得不可或缺。之前的方法 Guided-Distill引入了一个两阶段蒸馏以支持从引导扩散模型中进行少步采样。然而,这种方法计算密集估计,2步推理至少需要45个A100 GPU天)。相比之下,潜在一致性模型(LCM)仅需要32个A100 GPU小时的训练时间来进行2步推理,如图1所示。此外,两阶段引导蒸馏可能导致累积误差,导致性能不佳。相反,LCM通过求解增强的PF-ODE采用高效的单阶段引导蒸馏。回顾在逆扩散过程中使用的CFG:

其中用条件噪声和无条件噪声的线性组合代替原有的噪声预测,ω称为引导标度。为了从引导逆向过程中采样,我们需要求解以下增广的PF-ODE(即,与ω相关的项增广):

为了有效地进行一级导向蒸馏,我们引入增广一致性函数fθ:(zt, ω, c, t)→z0来直接预测t = 0时增广PF-ODE (Eq. 13)的解。我们以与Eq. 9相同的方式参数化fθ,除了λ θ(z, c, t)被λ ϵθ(z, ω, c, t)取代,这是一个用与教师扩散模型相同的参数初始化的噪声预测模型,但还包含额外的可训练参数,用于ω的调节。一致性损失与Eq. 10相同,只是我们使用增广一致性函数fθ(zt, ω, c, t)。


跳过时间步加速蒸馏
离散扩散模型通常通过长时间步长计划 {𝑡𝑖}𝑖(也称为离散化计划或时间计划)训练噪声预测模型,以实现高质量的生成结果。例如,稳定扩散(SD)有一个长度为1000的时间计划。然而,直接将潜在一致性蒸馏(LCD)应用于具有如此长时间计划的SD可能会有问题。模型需要在所有1000个时间步长上进行采样,而一致性损失试图使LCM模型 𝑓𝜃(𝑧𝑡𝑛+1,𝑐,𝑡𝑛+1) 的预测与在相同轨迹上下一步 𝑓𝜃(𝑧𝑡𝑛,𝑐,𝑡𝑛) 的预测对齐。由于 𝑡𝑛 − 𝑡𝑛+1 很小,𝑧𝑡𝑛 和 𝑧𝑡𝑛+1(因此 𝑓𝜃(𝑧𝑡𝑛+1,𝑐,𝑡𝑛+1)和 𝑓𝜃(𝑧𝑡𝑛,𝑐,𝑡𝑛))已经彼此接近,导致一致性损失很小,因此收敛速度慢。
为了解决这个问题,我们引入了跳步方法(SKIPPING-STEP),大大缩短了时间计划的长度(从数千缩短到几十),以实现快速收敛,同时保持生成质量。
一致性模型(CMs)使用EDM连续时间计划,并使用欧拉或Heun求解器作为数值连续PF-ODE求解器。对于LCMs,为了适应稳定扩散中的离散时间计划,我们使用DDIM,DPM-Solver或DPM-Solver++作为ODE求解器。
现在,我们介绍潜在一致性蒸馏(LCD)中的跳步方法。与确保相邻时间步长 𝑡𝑛+1→𝑡𝑛 之间的一致性不同,LCMs旨在确保当前时间步长和相隔 𝑘 步的时间步长 𝑡𝑛+𝑘→𝑡𝑛之间的一致性。注意,设置 𝑘=1k=1 会恢复到中的原始计划,导致收敛速度慢,而非常大的 𝑘 可能会导致ODE求解器的大近似误差。在我们的主要实验中,我们设置 𝑘=20,将时间计划的长度从数千减少到几十。第5.2节的结果显示了不同 k 值的效果,并揭示跳步方法在加速LCD过程中的重要性。具体来说,公式14中的一致性蒸馏损失被修改为确保从 𝑡𝑛+𝑘 到 𝑡𝑛 的一致性:

上述推导类似于公式15。对于LCM,我们在此使用三种可能的ODE求解器:DDIM (Song et al, 2020a)、DPM-Solver (Lu et al, 2022a)、DPM-Solver++。

LCM-LoRA
原理
在使用原始 LCM 蒸馏时,每个模型都需要单独蒸馏。而 LCM LoRA 的核心思想是只对少量适配器 (即 LoRA 层) 进行训练,而不用对完整模型进行训练。推理时,可将生成的 LoRA 用于同一模型的任何微调版本,而无需对每个版本都进行蒸馏。训练自己的 LoRA流程如下:
- 从 Hub 中选择一个教师模型。如: 你可以使用 SDXL (base),或其任何微调版或 dreambooth 微调版。
- 在该模型上 训练 LCM LoRA 模型。LoRA 是一种参数高效的微调 (PEFT),其实现成本比全模型微调要便宜得多。
- 将 LoRA 与任何 SDXL 模型和 LCM 调度器一起组成一个pipeline,进行推理。就这样!用这个流水线,你只需几步推理即可生成高质量的图像。
推理
根据使用 LCM LoRA 4 步完成 SDXL 推理 (huggingface.co) 的说明进行推理。给出的使用说明只进行了T2I的示例,不知道Talking face生成的结果如何,首先尝试直接使用了SD-v1.5的预训练权重:latent-consistency/lcm-lora-sdv1-5 · Hugging Face
生成一段14s的视频,原模型用时:15min

使用LCM-LoRA后:
首先有一个diffusers库版本不匹配的问题,anipotrait使用的diffusers==0.24.0,而必须的load_lora_weights函数在新版本diffusers,更新库后编译报错
训练
参考:使用 LCM LoRA 4 步完成 SDXL 推理 (huggingface.co)
Stable Diffusion 1.5 训练脚本:diffusers/examples/consistency_distillation/README.md at main · huggingface/diffusers (github.com)
使用时,先加载微调后的模型,然后加载适合 Stable Diffusion v1.5 的 LCM LoRA 权重:
from diffusers import DiffusionPipeline, LCMScheduler
import torchmodel_id = "wavymulder/collage-diffusion"
lcm_lora_id = "latent-consistency/lcm-lora-sdv1-5"pipe = DiffusionPipeline.from_pretrained(model_id, variant="fp16")
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
pipe.load_lora_weights(lcm_lora_id)
pipe.to(device="cuda", dtype=torch.float16)prompt = "collage style kid sits looking at the night sky, full of stars"generator = torch.Generator(device=pipe.device).manual_seed(1337)
images = pipe(prompt=prompt,generator=generator,negative_prompt=negative_prompt,num_inference_steps=4,guidance_scale=1,
).images[0]
images
- 使用 Stable Diffusion v1.5 模型去实例化一个标准的 diffusion pipeline。
- 应用 LCM-LoRA。
- 将调度器改为 LCMScheduler,这是 LCM 模型使用的调度器。
其他SD优化方案:diffusers SD推理加速方案的调研实践总结-CSDN博客
相关文章:
【扩散模型】LCM LoRA:一个通用的Stable Diffusion加速模块
潜在一致性模型:[2310.04378] Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference (arxiv.org) 原文:Paper page - Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference (…...

【PYG】pytorch中size和shape有什么不同
一般使用tensor.shape打印维度信息,因为简单直接 在 PyTorch 中,size 和 shape 都用于获取张量的维度信息,但它们之间有细微的区别。下面是它们的定义和用法: size: size 是一个方法(size())和…...

备份服务器出错怎么办?
在企业的日常运营中,备份服务器扮演着至关重要的角色,它确保了数据的安全和业务的连续性。然而,备份服务器也可能遇到各种问题,如备份失败、数据损坏或备份系统故障等。这些问题可能导致数据丢失或业务中断,给企业带来…...

数据库(表)
要求如下: 一:数据库 1,登录数据库 mysql -uroot -p123123 2,创建数据库zoo create database zoo; Query OK, 1 row affected (0.01 sec) 3,修改字符集 mysql> use zoo;---先进入数据库zoo Database changed …...

Feign-未完成
Feign Java中如何实现接口调用?即如何发起http请求 前三种方式比较麻烦,在发起请求前,需要将Java对象进行序列化转为json格式的数据,才能发送,然后进行响应时,还需要把json数据进行反序列化成java对象。 …...

# [0705] Task06 DDPG 算法、PPO 算法、SAC 算法【理论 only】
easy-rl PDF版本 笔记整理 P5、P10 - P12 joyrl 比对 补充 P11 - P13 OpenAI 文档整理 ⭐ https://spinningup.openai.com/en/latest/index.html 最新版PDF下载 地址:https://github.com/datawhalechina/easy-rl/releases 国内地址(推荐国内读者使用): 链…...

Open3D 点云CPD算法配准(粗配准)
目录 一、概述 二、代码实现 2.1关键函数 2.2完整代码 三、实现效果 3.1原始点云 3.2配准后点云 一、概述 在Open3D中,CPD(Coherent Point Drift,一致性点漂移)算法是一种经典的点云配准方法,适用于无序点云的非…...
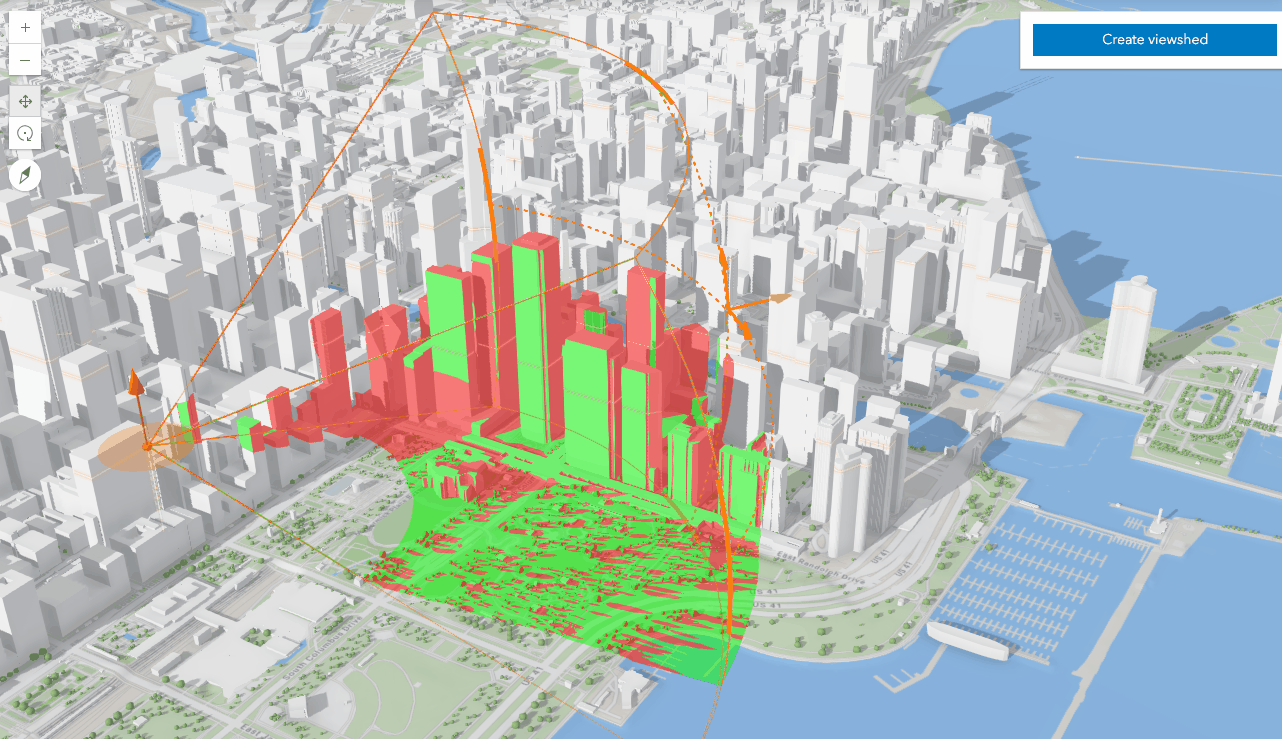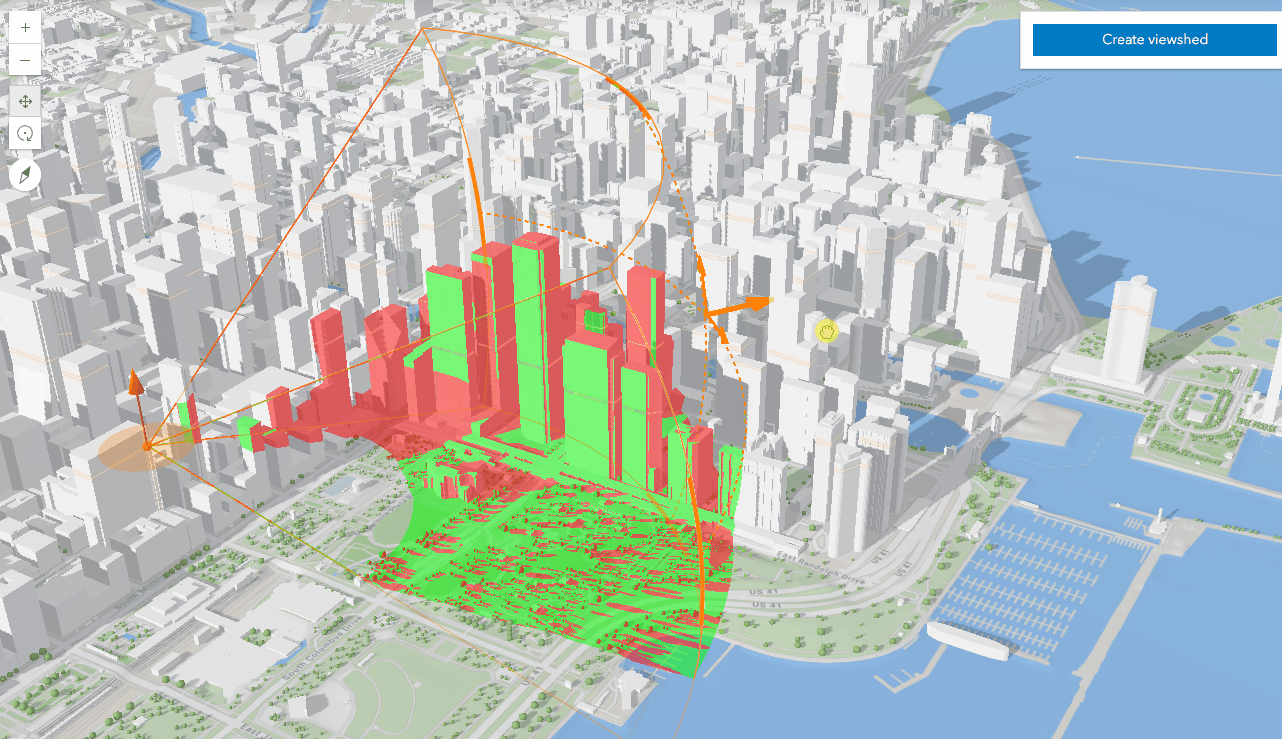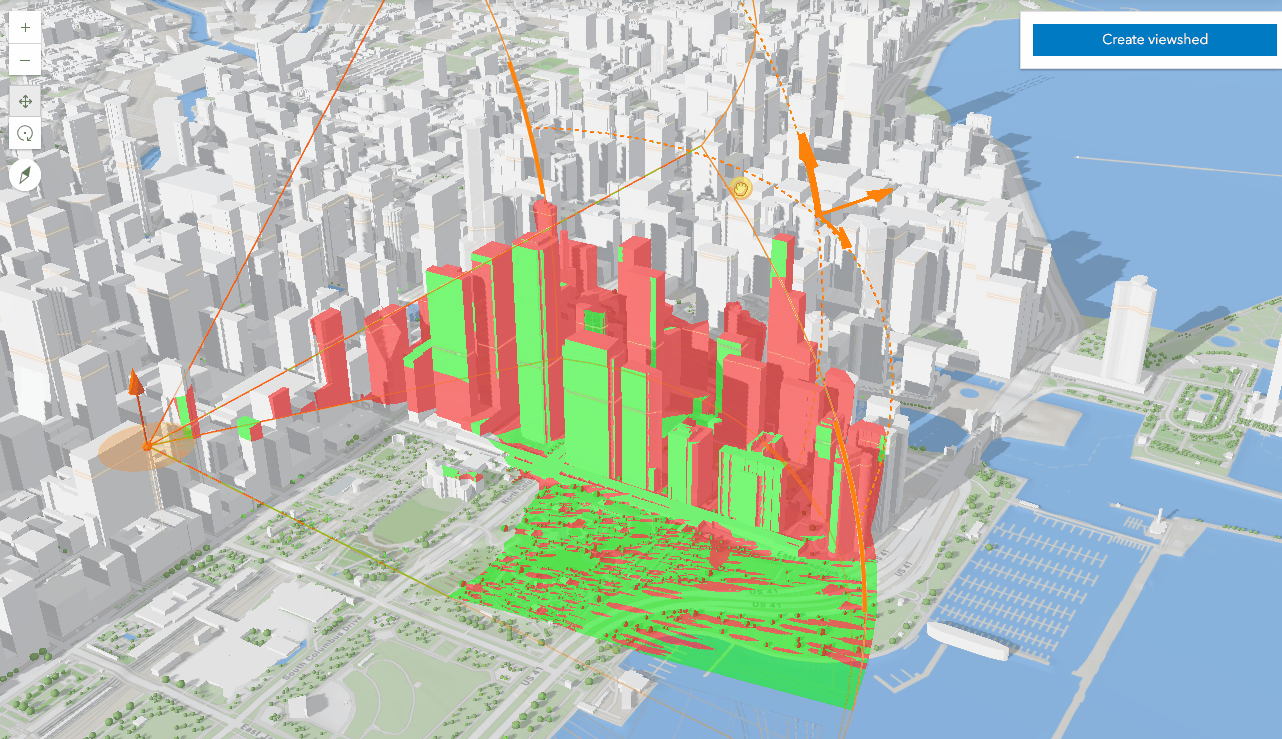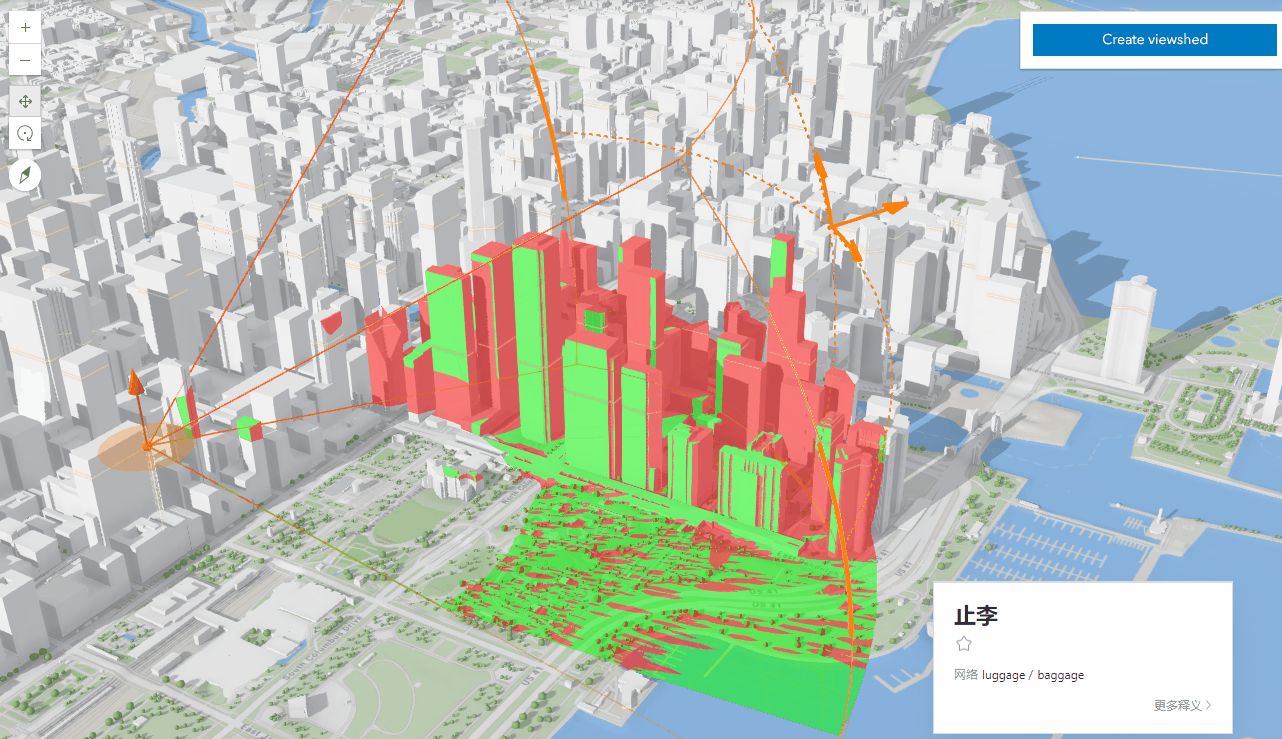
04-ArcGIS For JavaScript的可视域分析功能
文章目录 综述代码实现代码解析结果 综述 在数字孪生或者实景三维的项目中,视频融合和可视域分析,一直都是热点问题。Cesium中,支持对阴影的后处理操作,通过重新编写GLSL代码就能实现视域和视频融合的功能。ArcGIS之前支持的可视…...

Nestjs基础
一、创建项目 1、创建 安装 Nest CLI(只需要安装一次) npm i -g nestjs/cli 进入要创建项目的目录,使用 Nest CLI 创建项目 nest new 项目名 运行项目 npm run start 开发环境下运行,自动刷新服务 npm run start:dev 2、…...

DDL:针对于数据库、数据表、数据字段的操作
数据库的操作 # 查询所有数据 SHOW DATABASE; #创建数据库 CREATE DATABASE 2404javaee; #删除数据库 DROP DATABASE 2404javaee; 数据表的操作 #创建表 CREATE TABLE s_student( name VARCHAR(64), s_sex VARCHAR(32), age INT(3), salary FLOAT(8,2), c_course VARC…...
昇思学习打卡-5-基于Mindspore实现BERT对话情绪识别
本章节学习一个基本实践–基于Mindspore实现BERT对话情绪识别 自然语言处理任务的应用很广泛,如预训练语言模型例如问答、自然语言推理、命名实体识别与文本分类、搜索引擎优化、机器翻译、语音识别与合成、情感分析、聊天机器人与虚拟助手、文本摘要与生成、信息抽…...
 List中增删改查的注意事项)
Java中 普通for循环, 增强for循环( foreach) List中增删改查的注意事项
文章目录 俩种循环遍历增加删除1 根据index删除2 根据对象删除 修改 俩种循环 Java中 普通for循环, 增强for循环( foreach) 俩种List的遍历方式有何异同,性能差异? 普通for循环(使用索引遍历): for (int…...
昇思25天学习打卡营第19天|LSTM+CRF序列标注
概述 序列标注指给定输入序列,给序列中每个Token进行标注标签的过程。序列标注问题通常用于从文本中进行信息抽取,包括分词(Word Segmentation)、词性标注(Position Tagging)、命名实体识别(Named Entity Recognition, NER)等。 条件随机场(…...

微服务: 初识 Spring Cloud
什么是微服务? 微服务就像把一个大公司拆成很多小部门,每个部门各自负责一块业务。这样一来,每个部门都可以独立工作,即使一个部门出了问题,也不会影响整个公司运作。 什么是Spring Cloud? Spring Cloud 是一套工具包&#x…...

探索InitializingBean:Spring框架中的隐藏宝藏
🌈 个人主页:danci_ 🔥 系列专栏:《设计模式》《MYSQL》 💪🏻 制定明确可量化的目标,坚持默默的做事。 ✨欢迎加入探索MYSQL索引数据结构之旅✨ 👋 Spring框架的浩瀚海洋中&#x…...

JVM专题之垃圾收集算法
标记清除算法 第一步:标记 (找出内存中需要回收的对象,并且把它们标记出来) 第二步:清除 (清除掉被标记需要回收的对象,释放出对应的内存空间) 缺点: 标记清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致以后在程序运行过程中需 要分配较大对象时,无法找到…...
2024年6月后2周重要的大语言模型论文总结:LLM进展、微调、推理和对齐
本文总结了2024年6月后两周发表的一些最重要的大语言模型论文。这些论文涵盖了塑造下一代语言模型的各种主题,从模型优化和缩放到推理、基准测试和增强性能。 LLM进展与基准 1、 BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Com…...
)
大数据面试题之数仓(1)
目录 介绍下数据仓库 数仓的基本原理 数仓架构 数据仓库分层(层级划分),每层做什么?分层的好处? 数据分层是根据什么? 数仓分层的原则与思路 知道数仓建模常用模型吗?区别、优缺点? 星型模型和雪花模型的区别?应用场景?优劣对比 数仓建模有哪些方式…...
[机器学习]-4 Transformer介绍和ChatGPT本质
Transformer Transformer是由Vaswani等人在2017年提出的一种深度学习模型架构,最初用于自然语言处理(NLP)任务,特别是机器翻译。Transformer通过自注意机制和完全基于注意力的架构,核心思想是通过注意力来捕捉输入序列…...

基于深度学习的电力分配
基于深度学习的电力分配是一项利用深度学习算法优化电力系统中的电力资源分配、负荷预测、故障检测和系统管理的技术。该技术旨在提高电力系统的运行效率、稳定性和可靠性。以下是关于这一领域的系统介绍: 1. 任务和目标 电力分配的主要任务是优化电力系统中的电力…...

别再只做静态模型了!用Unity 3D + WebGL打造你的第一个可交互数字孪生看板
从静态到动态:用Unity 3D WebGL构建工业级数字孪生看板实战指南 当传统工业监控系统还停留在二维图表和静态数据展示时,数字孪生技术正在重新定义设备管理的交互方式。想象一下:在浏览器中旋转查看工厂设备的实时三维模型,点击某…...

OpCore-Simplify终极指南:3分钟打造完美黑苹果EFI配置
OpCore-Simplify终极指南:3分钟打造完美黑苹果EFI配置 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 想要体验macOS的强大功能࿰…...
期刊征稿】第五届能源、电力与电气国际学术会议(ICEPET 2026))
【EI(JA)期刊征稿】第五届能源、电力与电气国际学术会议(ICEPET 2026)
【期刊征稿页面】 第五届能源、电力与电气国际学术会议(ICEPET 2026) 2026 5th International Conference on Energy, Power and Electrical Technology 重要信息 会议官网:https://ais.cn/u/E7RRVv【点击参会/投稿/了解会议详情】 会议时…...

旧设备升级指南:用OpenCore Legacy Patcher让Mac重获新生的5个实用步骤
旧设备升级指南:用OpenCore Legacy Patcher让Mac重获新生的5个实用步骤 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 随着苹果系统的不断更新&a…...

新手福音,用快马平台可视化学习apifox接口调用与测试
作为一个刚接触API开发的新手,第一次看到各种接口文档时完全摸不着头脑。直到发现了Apifox这个工具,配合InsCode(快马)平台的智能生成功能,终于找到了最适合新手的可视化学习路径。下面分享我的学习心得: 为什么选择Apifox作为入门…...

OpenClaw镜像体验:Qwen3-4B-Thinking-2507-GPT-5-Codex-Distill-GGUF云端快速测试方案
OpenClaw镜像体验:Qwen3-4B-Thinking-2507-GPT-5-Codex-Distill-GGUF云端快速测试方案 1. 为什么选择云端体验OpenClaw 第一次接触OpenClaw时,我被它的自动化能力吸引,但本地安装过程却让我望而却步。作为一个经常需要快速验证技术方案的开…...

GCC/Clang编译警告终极配置:用-Wall -Wextra提升代码质量的3个冷技巧
GCC/Clang编译警告终极配置:用-Wall -Wextra提升代码质量的3个冷技巧 在C/C开发中,编译警告常被视为"可以忽略的噪音",但经验丰富的开发者知道,这些警告往往是代码质量的早期预警系统。当你在深夜调试一个难以复现的内存…...

文脉定序从零部署:Ubuntu+Docker+NVIDIA驱动环境下BGE重排序搭建
文脉定序从零部署:UbuntuDockerNVIDIA驱动环境下BGE重排序搭建 1. 引言:为什么你的搜索结果总是不对? 你有没有遇到过这种情况?在公司的知识库里搜索一个问题,系统确实返回了一大堆文档,但最相关、最能解…...

丹青识画系统GitHub协作开发指南:从代码克隆到PR提交全流程
丹青识画系统GitHub协作开发指南:从代码克隆到PR提交全流程 你是不是也遇到过这种情况?团队里几个人一起改代码,最后合并的时候发现冲突一大堆,张三改了李四的代码,王五的提交又把功能搞坏了,光是解决这些…...

CHORD-X深度研究报告生成终端LaTeX排版集成:生成可直接编译的学术报告
CHORD-X深度研究报告生成终端LaTeX排版集成:生成可直接编译的学术报告 每次写学术报告或者技术文档,最头疼的是什么?对我而言,不是内容本身,而是最后的排版。内容写好了,却要花大量时间在Word里调整格式、…...