Pandas 入门 15 题
Pandas 入门 15 题
- 1. 相关知识点
- 1.1 修改DataFrame列名
- 1.2 获取行列数
- 1.3 显示前n行
- 1.4 条件数据选取值
- 1.5 创建新列
- 1.6 删去重复的行
- 1.7 删除空值的数据
- 1.9 修改列名
- 1.10 修改数据类型
- 1.11 填充缺失值
- 1.12 数据上下合并
- 1.13 pivot_table透视表的使用
- 1.14 melt透视表的使用
- 1.15 条件查询及排序
- 2. 题目
- 2.1 从表中创建 DataFrame((Pandas 数据结构)
- 2.2 获取 DataFrame 的大小(数据检验)
- 2.3 显示前三行(数据检验)
- 2.4 数据选取(数据选取)
- 2.5 创建新列(数据选取)
- 2.6 删去重复的行(数据清理)
- 2.7 删去丢失的数据(数据清理)
- 2.8 修改列(数据清理)
- 2.9 重命名列(数据清理)
- 2.10 改变数据类型(数据清理)
- 2.11 填充缺失值(数据清理)
- 1.12 重塑数据:连结(表格重塑)
- 1.13 数据重塑:透视(表格重塑)
- 2.14 重塑数据:融合(表格重塑)
- 2.15 方法链(高级技巧)
1. 相关知识点
1.1 修改DataFrame列名
data=pd.DataFrame(student_data,columns=['student_id','age'])
1.2 获取行列数
players.shape
1.3 显示前n行
employees.head(n)
1.4 条件数据选取值
students.loc[students['student_id']==101,['name','age']]
students[students['student_id']==101][['name','age']]
students.query('`student_id`==101')[['name','age']]
1.5 创建新列
- 处理数据的时候,根据已知列得到新的列,可以考虑使用
pandas.DataFrame.assign()函数 - 使用assign函数不会改变原数据,而是返回一个新的DataFrame对象,包含所有现有列和新生成的列
- 注意:assign和apply函数的主要区别在于前者不改变原数据,apply函数是在原数据的基础上添加新列
employees['bonus']=employees['salary'].apply(lambda x:x*2)
employees=employees.assign(bonus=employees.salary*2)
employees['bonus']=employees['salary']*2
1.6 删去重复的行
customers.drop_duplicates(subset=['email'],keep='first')
1.7 删除空值的数据
# axis=0代表行
students.dropna(subset=['name'],how='any', axis=0,inplace = False)
1.9 修改列名
data=data.rename(columns={'Dest':'iata_code','index':'from'})
students.columns=['student_id','first_name','last_name','age_in_years']
1.10 修改数据类型
students['grade']=students['grade'].astype('int')
1.11 填充缺失值
products['quantity'].fillna(0,inplace=True)# products.replace({'quantity':{# None:0# }},inplace=True)
1.12 数据上下合并
df1._append(df2)
# pd.concat([df1,df2],axis=0)
1.13 pivot_table透视表的使用
weather.pivot_table(index='month',values='temperature',columns='city',aggfunc='sum')
1.14 melt透视表的使用
- df.pivot() 将长数据集转换成宽数据集,df.melt() 则是将宽数据集变成长数据集
pd.melt(report,id_vars['product'],var_name='quarter',value_name='sales')
1.15 条件查询及排序
animals[animals['weight'] > 100].sort_values(by='weight', ascending=False)
2. 题目
2.1 从表中创建 DataFrame((Pandas 数据结构)


import pandas as pddef createDataframe(student_data: List[List[int]]) -> pd.DataFrame: data=pd.DataFrame(student_data,columns=['student_id','age'])return data
student_data=[[1,15],[2,11],[3,11],[4,20]]print(createDataframe(student_data))
2.2 获取 DataFrame 的大小(数据检验)


import pandas as pddef getDataframeSize(players: pd.DataFrame) -> List[int]:return list(players.shape)
2.3 显示前三行(数据检验)


import pandas as pddef selectFirstRows(employees: pd.DataFrame) -> pd.DataFrame:return employees.head(3)
2.4 数据选取(数据选取)


import pandas as pddef selectData(students: pd.DataFrame) -> pd.DataFrame:return students.loc[students['student_id']==101,['name','age']]# return students[students['student_id']==101][['name','age']]# return students.query('`student_id`==101')[['name','age']]
2.5 创建新列(数据选取)



import pandas as pddef createBonusColumn(employees: pd.DataFrame) -> pd.DataFrame:employees['bonus']=employees['salary'].apply(lambda x:x*2)# employees=employees.assign(bonus=employees.salary*2)# employees['bonus']=employees['salary']*2return employees
2.6 删去重复的行(数据清理)


import pandas as pddef dropDuplicateEmails(customers: pd.DataFrame) -> pd.DataFrame:return customers.drop_duplicates(subset=['email'],keep='first')
2.7 删去丢失的数据(数据清理)


import pandas as pddef dropMissingData(students: pd.DataFrame) -> pd.DataFrame:# axis=0代表行return students.dropna(subset=['name'],how='any', axis=0,inplace = False)
2.8 修改列(数据清理)


import pandas as pddef modifySalaryColumn(employees: pd.DataFrame) -> pd.DataFrame:employees=employees.assign(salary=employees.salary*2)# employees['salary']=employees['salary'].apply(lambda x:x*2)# employees['salary']=employees['salary']*2return employees
2.9 重命名列(数据清理)


import pandas as pddef renameColumns(students: pd.DataFrame) -> pd.DataFrame:students.columns=['student_id','first_name','last_name','age_in_years']# dic={# 'id':'student_id',# 'first':'first_name',# 'last':'last_name',# 'age':'age_in_years'}# students=students.rename(columns=dic)return students
2.10 改变数据类型(数据清理)


import pandas as pddef changeDatatype(students: pd.DataFrame) -> pd.DataFrame:students['grade']=students['grade'].astype('int')return students
2.11 填充缺失值(数据清理)


import pandas as pddef fillMissingValues(products: pd.DataFrame) -> pd.DataFrame:products['quantity'].fillna(0,inplace=True)# products['quantity']=products['quantity'].fillna(0)# products.replace({'quantity':{# None:0# }},inplace=True)return products
1.12 重塑数据:连结(表格重塑)



import pandas as pddef concatenateTables(df1: pd.DataFrame, df2: pd.DataFrame) -> pd.DataFrame:return df1._append(df2)# return pd.concat([df1,df2],axis=0)
1.13 数据重塑:透视(表格重塑)



import pandas as pddef pivotTable(weather: pd.DataFrame) -> pd.DataFrame:return weather.pivot_table(index='month',values='temperature',columns='city',aggfunc='sum')# return weather.set_index(['month','city']).unstack()['temperature
2.14 重塑数据:融合(表格重塑)


import pandas as pddef meltTable(report: pd.DataFrame) -> pd.DataFrame:report=pd.melt(report,id_vars=['product'],var_name='quarter',value_name='sales')return report
2.15 方法链(高级技巧)



import pandas as pddef findHeavyAnimals(animals: pd.DataFrame) -> pd.DataFrame:animals = animals[animals['weight'] > 100].sort_values(by='weight', ascending=False)return animals[['name']]
相关文章:
Pandas 入门 15 题
Pandas 入门 15 题 1. 相关知识点1.1 修改DataFrame列名1.2 获取行列数1.3 显示前n行1.4 条件数据选取值1.5 创建新列1.6 删去重复的行1.7 删除空值的数据1.9 修改列名1.10 修改数据类型1.11 填充缺失值1.12 数据上下合并1.13 pivot_table透视表的使用1.14 melt透视表的使用1.1…...
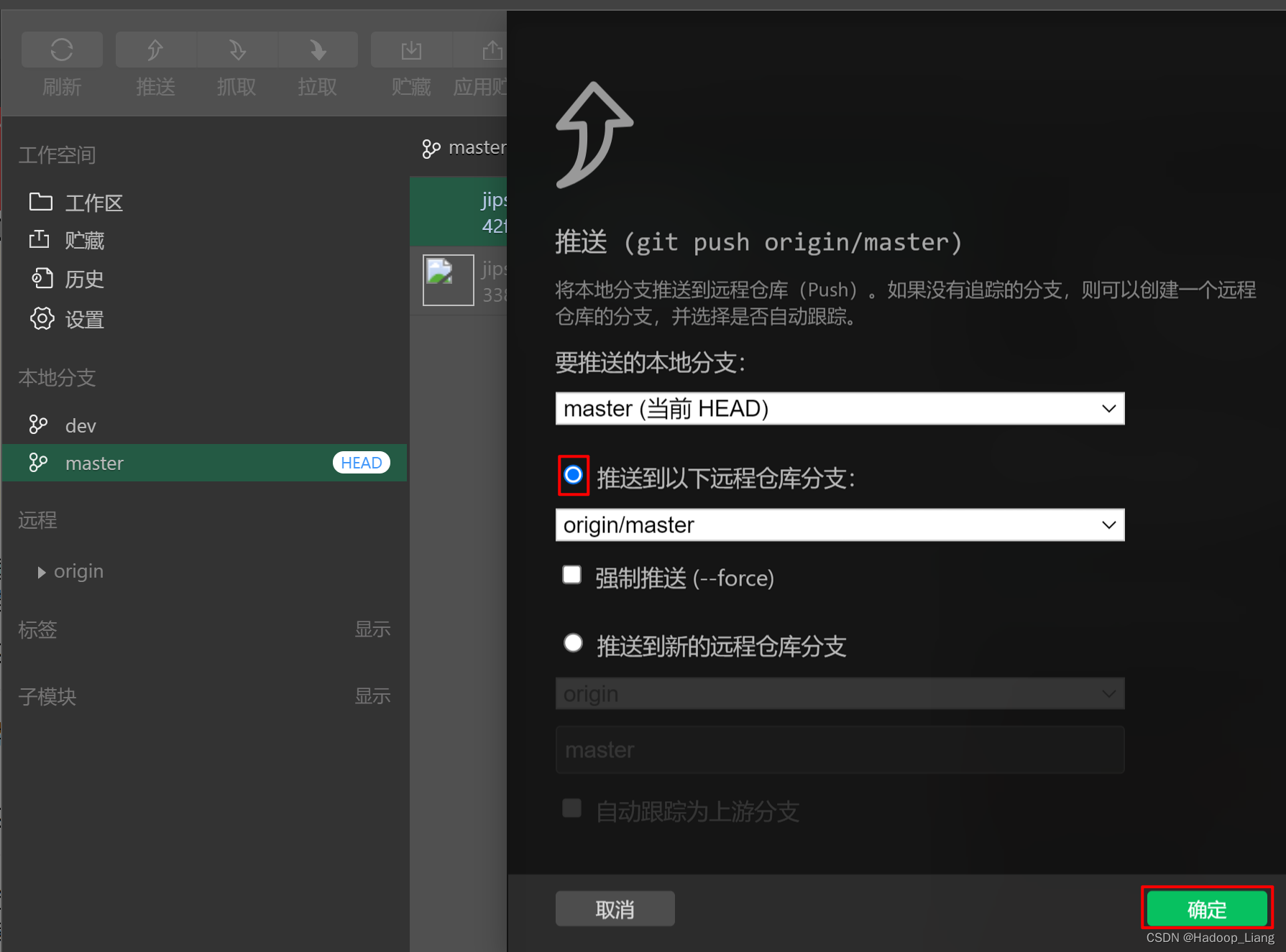
使用微信开发者工具连接gitee
编写代码 打开微信开发者工具 编写小程序代码 提交代码 在微信开发者工具提交代码到gitee仓库的步骤: 1.在gitee创建仓库,得到仓库url 2.微信开发者工具设置远程仓库 点击版本管理-->点击设置-->网络和认证-->认证方式选择 使用用户名和…...

论文复现-基于决策树算法构建银行贷款审批预测模型(金融风控场景)
作者Toby,来源公众号:Python风控模型,基于决策树算法构建银行贷款审批预测模型 目录 1.金融风控论文复现 2.项目背景介绍 3.决策树介绍 4.数据集介绍 5.合规风险提醒 6.技术工具 7.实验过程 7.1导入数据 7.2数据预处理 7.3数据可…...
)
力扣225题解析:使用队列实现栈的三种解法(Java实现)
引言 在算法和数据结构中,如何用队列实现栈是一个常见的面试题和实际应用问题。本文将探讨力扣上的第225题,通过不同的方法来实现这一功能,并分析各种方法的优劣和适用场景。 问题介绍 力扣225题目要求我们使用队列实现栈的下列操作&#…...

网络协议与标准
协议: 语法 ;计算机的算法,二进制 语义 ;不要有出现歧义的 同步 ; 同步还原信息,收发同步 标准: ISO(国际标准化组织) IEEE(电气和电子工程师学会) 局域网技术 一.协议…...
154. 寻找旋转排序数组中的最小值 II(困难)
154. 寻找旋转排序数组中的最小值 II 1. 题目描述2.详细题解3.代码实现3.1 Python3.2 Java 1. 题目描述 题目中转:154. 寻找旋转排序数组中的最小值 II 2.详细题解 该题是153. 寻找旋转排序数组中的最小值的进阶题,在153. 寻找旋转排序数组中的最小值…...

5、MP4解复用---AAC+H264
MP4 MP4同样是一种容器格式,是由一个一个Box组成,每个Box又分为Header与Data,Data又包含很多子Box,具体的MP4文件结构也看过,内部Box结构比较复杂,一般不写MP4解释器的话,Box结构不用了解太细&a…...

计算样本之间的相似度
文章目录 前言一、距离度量1.1 欧几里得距离(Euclidean Distance)1.2 曼哈顿距离(Manhattan Distance)1.3 切比雪夫距离(Chebyshev Distance)1.4 闵可夫斯基距离(Minkowski Distance)…...

2-5 softmax 回归的简洁实现
我们发现通过深度学习框架的高级API能够使实现线性回归变得更加容易。 同样,通过深度学习框架的高级API也能更方便地实现softmax回归模型。 本节如在上节中一样, 继续使用Fashion-MNIST数据集,并保持批量大小为256。 import torch from torc…...

我 17 岁创业,今年 20 岁,月入 70 万,全靠低代码
想象一下,当你还在高中的课桌前埋头苦读时,有人告诉你三年后你将成为一家年收入超过 100 万美元的科技公司的创始人。 听起来是不是像天方夜谭? 但对于 20 岁的小伙子 Jacob Klug 来说,这就是他的真实人生。 在大多数同龄人还在为…...

【Python】已解决:urllib.error.HTTPError: HTTP Error 403: Forbidden
文章目录 一、分析问题背景二、可能出错的原因三、错误代码示例四、正确代码示例五、注意事项 已解决:urllib.error.HTTPError: HTTP Error 403: Forbidden 一、分析问题背景 在使用Python的urllib库中的urlopen或urlretrieve函数下载文件时,有时会遇到…...

昇思12天
FCN图像语义分割 1. 主题和背景 FCN是由UC Berkeley的Jonathan Long等人于2015年提出的,用于实现图像的像素级预测。 2. 语义分割的定义和重要性 语义分割是图像处理和机器视觉中的关键技术,旨在对图像中的每个像素进行分类。它在很多领域有重要应用…...

【postgresql】 基础知识学习
PostgreSQL是一个高度可扩展的开源对象关系型数据库管理系统(ORDBMS),它以其强大的功能、灵活性和可靠性而闻名。 官网地址:https://www.postgresql.org/ 中文社区:文档目录/Document Index: 世界上功能最强大的开源…...

按键控制LED流水灯模式定时器时钟
目录 1.定时器 2. STC89C52定时器资源 3.定时器框图 4. 定时器工作模式 5.中断系统 1)介绍 2)流程图:编辑 3)STC89C52中断资源 4)定时器和中断系统 5)定时器的相关寄存器 6.按键控制LED流水灯模…...

【Docker安装】OpenEuler系统下部署Docker环境
【Docker安装】OpenEuler系统下部署Docker环境 前言一、本次实践介绍1.1 本次实践规划1.2 本次实践简介二、检查本地环境2.1 检查操作系统版本2.2 检查内核版本2.3 检查yum仓库三、卸载Docker四、部署Docker环境4.1 配置yum仓库4.2 检查可用yum仓库4.3 安装Docker4.4 检查Docke…...

小程序 使用 UI 组件 Vant Weapp 、vant组件样式覆盖
注意:使用vant 包,需要把app.json 中 的"style:v2" 这句去掉 不然会出现样式混乱的问题 Vant Weapp组件库的使用 参考官网 vant官网 Vant Weapp 组件样式覆盖 Vant Weapp 基于微信小程序的机制,为开发者提供了 3 种修改组件样式…...
前端弄一个变量实现点击次数在前端页面实时更新)
(接上一篇)前端弄一个变量实现点击次数在前端页面实时更新
实现点击次数在前端页面实时更新,确实需要在前端维护一个变量来存储当前的点击次数。这个变量通常在Vue组件的data选项中定义,并在组件的生命周期方法或事件处理函数中更新。 以下是实现这一功能的基本步骤: 定义变量:在Vue组件的…...

迭代器模式在金融业务中的应用及其框架实现
引言 迭代器模式(Iterator Pattern)是一种行为设计模式,它提供了一种方法顺序访问一个聚合对象中的各个元素,而又不需要暴露该对象的内部表示。在金融业务中,迭代器模式可以用于遍历复杂的数据结构,如交易…...
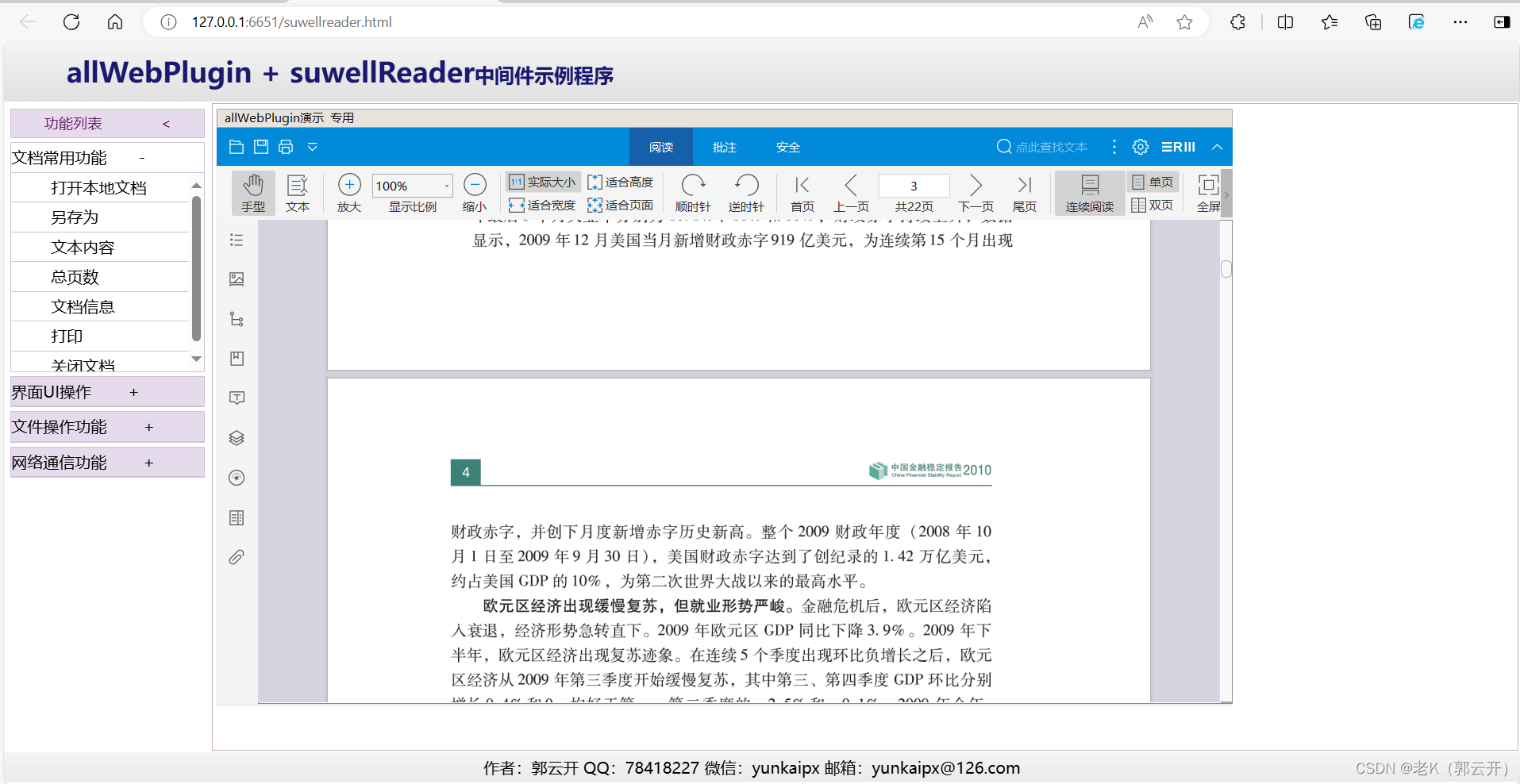
浏览器插件利器-allWebPluginV2.0.0.14-stable版发布
allWebPlugin简介 allWebPlugin中间件是一款为用户提供安全、可靠、便捷的浏览器插件服务的中间件产品,致力于将浏览器插件重新应用到所有浏览器。它将现有ActiveX插件直接嵌入浏览器,实现插件加载、界面显示、接口调用、事件回调等。支持谷歌、火狐等浏…...

机器学习训练之使用静态图加速
前言 MindSpore有两种运行模式:动态图模式和静态图模式。默认情况下是动态图模式,也可以手工切换为静态图模式。 动态图模式 动态图的特点是计算图的构建和计算同时发生,符合Python的解释执行方式。在调试模型时较为方便,能够实…...

使用OpenGL纹理数组实现高精度实时Lut滤镜
之前写过的文章(使用OpenGL实现滤镜转换的一种思路_轮子初级玩家-CSDN博客),我把一整个Lut滤镜图作为单个纹理贴图,把图像原颜色采样后当作坐标,然后从lut纹理中查找出替换颜色实现滤镜功能,这是最简易的一种滤镜实现方式…...

hello-uniapp网络状态监听:提升应用健壮性的终极指南
hello-uniapp网络状态监听:提升应用健壮性的终极指南 【免费下载链接】hello-uniapp uni-app框架演示示例 项目地址: https://gitcode.com/gh_mirrors/he/hello-uniapp 在移动应用开发中,网络状态的稳定性直接影响用户体验和应用可靠性。hello-un…...

千里科技“AI+车”加速度:2025年营收增长42%、净利翻倍、新业务突破
A股上市公司重庆千里科技股份有限公司(以下简称“千里科技”)今日发布2025年年度报告,公司收入、利润双增长,“AI车”商业化实现突破。报告期内,全年实现营业收入99.99亿元,同比增长42.13%;归母…...

ArduinoAPI:mbed OS 上的轻量级 Arduino 兼容层
1. ArduinoAPI 库概述ArduinoAPI 是一个面向嵌入式开发者的轻量级兼容层库,其核心定位并非复刻 Arduino IDE 的完整生态,而是在 mbed OS 平台上提供一套语义兼容、接口简洁、可裁剪的 Arduino Core API 子集。该库不依赖 Arduino IDE 或 avr-gcc 工具链&…...

作家使用AI写小说:写作者必须接纳人工智能但我们依然珍贵
我最近在游乐场听到一段对话,这比任何分析师对泡沫的预测都更应该让AI公司高管担忧。一个男孩和一个女孩,大概10岁,正在争吵。"那是AI!那是AI!"女孩喊道。她的意思是男孩在沉溺于一种新的特殊胡言乱语&#…...

嵌入式Linux驱动开发全攻略
1. 嵌入式Linux驱动开发全景解析 从事嵌入式开发多年,我深刻体会到驱动开发是整个嵌入式系统中最为关键也最具挑战性的部分。它像一座桥梁,连接着冰冷的硬件和灵活多变的软件世界。今天,我将从实际工程角度,系统梳理嵌入式Linux驱…...

单片机驱动MOS管的原理与实战技巧
1. 单片机直接驱动MOS管的原理与风险MOS管作为现代电子设计中最常用的功率开关器件,其控制方式看似简单却暗藏玄机。作为一名经历过多次"炸管"教训的硬件工程师,我想分享一些关于单片机直接驱动MOS管的实战经验。MOS管分为NMOS和PMOS两种类型&…...

《深入理解Mybatis原理》MyBatis数据源与连接池详解
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...

果园灌溉施肥控制系统升级:博图v16西门子s7-1200PLC选型与运行效果展示
果园灌溉施肥控制系统改3 博图v16,西门子s7-1200PLC带选型表 io表 运行效果视频果园灌溉3.0版本升级用上了博图V16和西门子S7-1200 PLC,这次改造最大的亮点是把施肥和滴灌控制集成到了同一个系统里。先说个实战经验:在新疆某果园调试时&…...

优峰技术 1550nm 可调谐激光器:全光纤型分支器件检测核心光源
全光纤型分支器件是光纤通信、光纤传感网络的核心无源元件,其插入损耗、回波损耗、偏振相关损耗、分光比均匀性等关键指标,直接决定光网络传输质量与稳定性。在全光纤型分支器件检测体系中,1550nm可调谐激光器作为高精度测试光源,…...