论文复现-基于决策树算法构建银行贷款审批预测模型(金融风控场景)
作者Toby,来源公众号:Python风控模型,基于决策树算法构建银行贷款审批预测模型
目录
1.金融风控论文复现
2.项目背景介绍
3.决策树介绍
4.数据集介绍
5.合规风险提醒
6.技术工具
7.实验过程
7.1导入数据
7.2数据预处理
7.3数据可视化
7.4特征工程
7.5构建模型
7.6模型评估
8.总结
1.金融风控论文复现
今天发现有篇经典期刊下载量非常大,有5000多条。Toby老师尝试简单复现一下。



2.项目背景介绍
银行贷款审批预测模型是一种基于机器学习算法的应用,旨在帮助银行提高贷款审批的效率和准确性。该模型利用客户的个人信息、财务状况和贷款申请信息等数据,预测客户的贷款审批结果,即是否批准该客户的贷款申请。
背景介绍:在传统的银行贷款审批流程中,工作人员需要手动审核客户提交的贷款申请资料,这一过程既费时又容易出错。为了提高审批效率、降低风险,许多银行开始引入机器学习模型来辅助贷款审批决策。这些模型可以根据历史数据和客户信息,快速而准确地预测贷款的批准结果,帮助银行更好地管理风险,提高贷款审批的效率和客户体验。
银行贷款审批预测模型的建立需要一定数量的历史贷款数据和客户信息作为训练集,以便模型学习客户的贷款偿还行为和审批决策规律。通过合理地处理和分析这些数据,建立起贷款审批预测模型,银行可以实现更智能化、高效化的贷款审批流程,为客户提供更优质的金融服务。

3.决策树算法介绍
决策树是一种常用的机器学习算法,在分类和回归问题中都有广泛的应用。它通过一系列的规则和条件对数据进行划分,最终形成一棵树状的结构,每个节点表示一个特征属性的判断条件,每个叶子节点表示一个分类结果或回归数值。
下面是决策树算法的主要特点和工作流程:
特点:
-
简单直观:决策树易于解释和理解,可以帮助人们了解数据特征之间的关系。
-
非参数方法:决策树在建模过程中不需要假设数据的分布,适用于各种类型的数据。
-
可处理多类别问题:决策树可以处理多类别分类问题,也可以用于回归问题。
工作流程:
-
特征选择:根据不同的特征属性选择一个最优的特征进行数据划分。
-
数据划分:根据特征的取值将数据集划分成不同的子集。
-
递归构建:对每个子集递归地重复上述过程,直到满足停止条件(如节点中的样本都属于同一类别)。
-
剪枝:为了避免过拟合,可以通过剪枝手段对决策树进行优化。
决策树算法通过树状结构直观地描述了数据特征之间的关系,可以有效地处理分类和回归问题。然而,决策树算法也存在容易过拟合的问题,因此在实际应用中常常需要进行适当的调参和优化以提高模型的泛化能力。
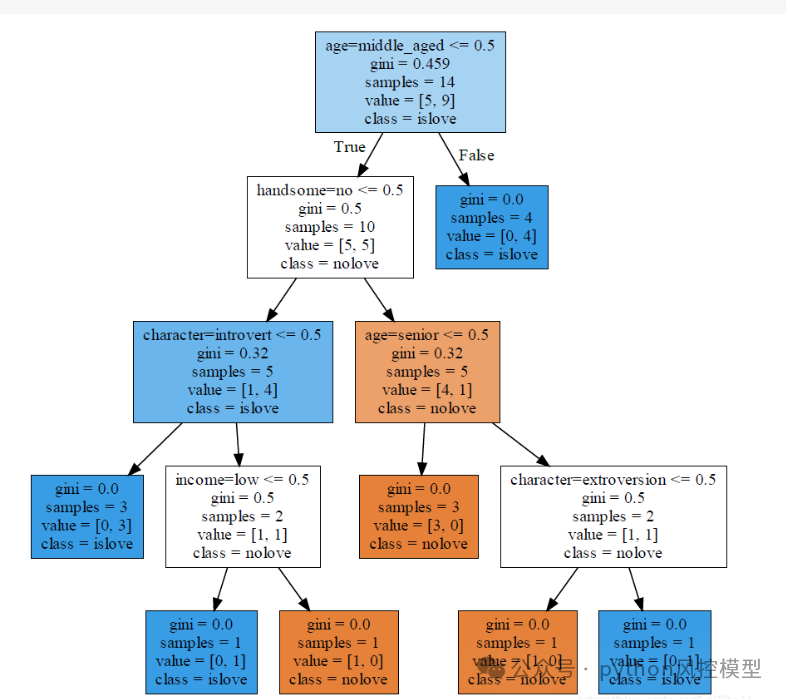
4.数据集介绍
"Property Loan"(房屋贷款)数据集通常用于贷款审批预测模型的训练和测试。该数据集包含了一些客户的个人信息和贷款申请信息,以及最终的贷款批准结果,是一个典型的二分类问题数据集。
通常,"Property Loan"数据集可能包含以下类型的特征信息:
-
Gender(性别):客户的性别,可以是男性或女性。
-
Marital Status(婚姻状况):客户的婚姻状况,如已婚、未婚、离异等。
-
Applicant Income(申请人收入):申请人的收入水平。
-
Loan Amount(贷款金额):客户申请的贷款金额。
-
Credit History(信用历史):客户的信用历史记录,通常是二分类特征,表示有或没有信用记录。
-
Property Area(房产所在区域):房产所在的区域,如城市、郊区等。
同时,数据集中的标签(Label)通常是 Loan Approval Status(贷款批准状态),即客户的贷款申请是否最终被批准。
通过"Property Loan"数据集,银行可以利用客户的个人信息和贷款申请信息,训练贷款审批预测模型,实现快速有效地预测客户的贷款审批结果。这有助于提高银行的运营效率,降低风险,并为客户提供更高效的金融服务体验。
5.合规风险提醒
根据巴塞尔协议和国内金融办法规。各位建模人员请注意,对于敏感的金融数据和贷款审批模型的构建,需要遵守相关的法律和规定,并确保数据隐私和安全。建议在实际操作中谨慎处理和使用这些数据,以保护客户的隐私和信息安全。
6.技术工具
Python版本:4
代码编辑器:jupyter notebook/spyder/miniconda
具体安装流程,请参考Toby老师之前文章《Anaconda下载和安装指南》

7.建模实验过程
以下是一个简单的示例代码,展示了如何使用Python中的scikit-learn库构建决策树模型进行银行贷款审批预测:
7.1导入数据
# 导入必要的库import pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.metrics import accuracy_score# 读取包含客户信息和贷款审批结果的数据集data = pd.read_csv('loan_data.csv')
7.2描述性统计
通过以上代码,您可以轻松地获取"Property Loan"数据集的基本描述性统计信息,包括各个数值型特征的统计指标(如均值、方差、最大值、最小值等)以及类别型特征的频数统计。
import pandas as pd# 假设数据集已加载到名为 property_loan_data 的 DataFrame 中# 显示数据集的基本统计信息print(property_loan_data.describe())# 计算每个类别型特征的频数categorical_features = ['Gender', 'Marital Status', 'Credit History', 'Property Area']for feature in categorical_features:print(property_loan_data[feature].value_counts())
7.3数据预处理
对于"Property Loan"数据集的数据预处理,常见的步骤包括缺失值处理、特征编码、数据标准化等。以下是一个简单的数据预处理示例代码,假设您已经加载了"Property Loan"数据集到名为property_loan_data的DataFrame中:
import pandas as pdfrom sklearn.preprocessing import LabelEncoderfrom sklearn.impute import SimpleImputerfrom sklearn.preprocessing import StandardScaler# 假设数据集已加载到名为 property_loan_data 的 DataFrame 中# 处理缺失值imputer = SimpleImputer(strategy='mean') # 使用均值填充缺失值property_loan_data['Loan Amount'] = imputer.fit_transform(property_loan_data[['Loan Amount']])# 特征编码label_encoder = LabelEncoder()property_loan_data['Gender'] = label_encoder.fit_transform(property_loan_data['Gender'])property_loan_data['Marital Status'] = label_encoder.fit_transform(property_loan_data['Marital Status'])property_loan_data['Property Area'] = label_encoder.fit_transform(property_loan_data['Property Area'])# 数据标准化scaler = StandardScaler()property_loan_data[['Applicant Income', 'Loan Amount']] = scaler.fit_transform(property_loan_data[['Applicant Income', 'Loan Amount']])# 打印处理后的数据集print(property_loan_data.head())
在这段代码中,我们演示了如何使用SimpleImputer处理缺失值、使用LabelEncoder进行特征编码、以及使用StandardScaler进行数据标准化。这些步骤有助于准备数据用于机器学习模型的训练。
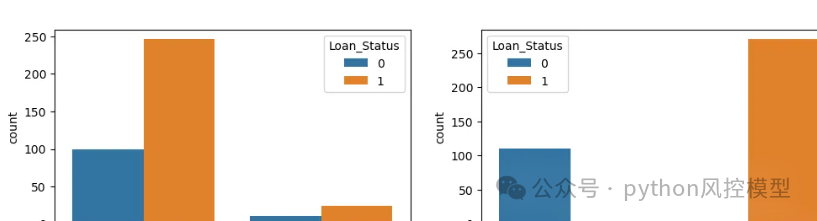
7.4数据可视化
以下是一个简单的用于可视化"Property Loan"(房屋贷款)数据集的Python代码示例,借助matplotlib和seaborn库来实现数据可视化:
import pandas as pdimport matplotlib.pyplot as pltimport seaborn as sns# 假设数据集已加载到名为 property_loan_data 的 DataFrame 中# 柱状图示例:显示贷款批准状态的分布sns.countplot(x='Loan Approval Status', data=property_loan_data)plt.title('Loan Approval Status Distribution')plt.show()# 散点图示例:显示申请人收入与贷款金额之间的关系plt.figure(figsize=(8, 6))sns.scatterplot(x='Applicant Income', y='Loan Amount', hue='Loan Approval Status', data=property_loan_data)plt.title('Applicant Income vs. Loan Amount')plt.xlabel('Applicant Income')plt.ylabel('Loan Amount')plt.show()# 箱线图示例:显示贷款金额在不同贷款批准状态下的分布plt.figure(figsize=(8, 6))sns.boxplot(x='Loan Approval Status', y='Loan Amount', data=property_loan_data)plt.title('Loan Amount Distribution by Loan Approval Status')plt.xlabel('Loan Approval Status')plt.ylabel('Loan Amount')plt.show()
这些示例代码将帮助您快速可视化"Property Loan"数据集中的一些重要特征和关系,有助于更好地理解数据和可能的模式。


7.5数据划分
# 提取特征和目标变量X = data.drop('Loan_Status', axis=1)y = data['Loan_Status']# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
7.6建模
# 构建决策树分类器模型clf = DecisionTreeClassifier()clf.fit(X_train, y_train)
7.7预测
# 在测试集上进行预测y_pred = clf.predict(X_test)
7.8模型验证
# 评估模型准确率accuracy = accuracy_score(y_test, y_pred)print('模型准确率: {:.2f}%'.format(accuracy * 100))
在这段代码中,首先我们导入了需要的库,并读取包含客户信息和贷款审批结果的数据集。然后提取特征和目标变量,并进行训练集和测试集的划分。接着我们构建了决策树分类器模型,并在测试集上进行预测,最后通过准确率评估模型的性能。

混淆矩阵结果
模型准确率整体还不错,有0.82,对逾期的f1分数达到0.89,非常高。当然这是前期快速预测模型的实验结论。Toby老师通过后期模型调优可以显著提升模型性能。

confusionMatrix混淆矩阵是统计学里比较难懂概念。混淆矩阵包含accuracy,recall,precision,f-measure四个指标。
为了让各位学员不再混淆,我用一图读懂混淆矩阵包含accuracy,recall(也叫sensitivity),precision,f-measure四个指标。

更多相关知识请参考Toby老师之前写的文章《confusion matrix混淆矩阵图谱
》
8.总结
银行贷款审批预测模型项目总结如下:
-
项目背景: 该项目旨在开发一个贷款审批预测模型,以帮助银行更高效地评估贷款申请,并降低坏账率。
-
数据收集与清洗: 数据集包括贷款申请人的个人信息、财务信息等。在收集数据后,进行数据清洗工作,处理缺失值和异常值。
-
特征工程: 对数据进行特征工程处理,包括特征选择、特征变换等,以提取对预测目标最有影响的特征。
-
模型选择与训练: 选择合适的机器学习模型,如逻辑回归、随机森林等,进行模型训练,并通过交叉验证进行参数调优。
-
模型评估与调优: 使用评价指标如准确率、精确率、召回率、F1值等对模型进行评估,根据评估结果进行模型调优。
-
部署与监控: 将训练好的模型部署至实际环境中,与银行的贷款系统进行集成,并建立监控机制,定期检查模型性能。
-
结果展示与总结: 展示模型的预测结果,对模型的准确性和稳定性进行总结,并提出后续优化建议和改进方向。
通过以上步骤,银行可以借助贷款审批预测模型提升审批效率,降低风险,提高客户体验。Toby老师利用Property Loan数据集为大家演示了一下大致流程。以后有时间再继续优化丰富此文章。
版权声明:文章来自公众号(python风控模型),未经许可,不得抄袭。遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
相关文章:
论文复现-基于决策树算法构建银行贷款审批预测模型(金融风控场景)
作者Toby,来源公众号:Python风控模型,基于决策树算法构建银行贷款审批预测模型 目录 1.金融风控论文复现 2.项目背景介绍 3.决策树介绍 4.数据集介绍 5.合规风险提醒 6.技术工具 7.实验过程 7.1导入数据 7.2数据预处理 7.3数据可…...
)
力扣225题解析:使用队列实现栈的三种解法(Java实现)
引言 在算法和数据结构中,如何用队列实现栈是一个常见的面试题和实际应用问题。本文将探讨力扣上的第225题,通过不同的方法来实现这一功能,并分析各种方法的优劣和适用场景。 问题介绍 力扣225题目要求我们使用队列实现栈的下列操作&#…...

网络协议与标准
协议: 语法 ;计算机的算法,二进制 语义 ;不要有出现歧义的 同步 ; 同步还原信息,收发同步 标准: ISO(国际标准化组织) IEEE(电气和电子工程师学会) 局域网技术 一.协议…...
154. 寻找旋转排序数组中的最小值 II(困难)
154. 寻找旋转排序数组中的最小值 II 1. 题目描述2.详细题解3.代码实现3.1 Python3.2 Java 1. 题目描述 题目中转:154. 寻找旋转排序数组中的最小值 II 2.详细题解 该题是153. 寻找旋转排序数组中的最小值的进阶题,在153. 寻找旋转排序数组中的最小值…...

5、MP4解复用---AAC+H264
MP4 MP4同样是一种容器格式,是由一个一个Box组成,每个Box又分为Header与Data,Data又包含很多子Box,具体的MP4文件结构也看过,内部Box结构比较复杂,一般不写MP4解释器的话,Box结构不用了解太细&a…...

计算样本之间的相似度
文章目录 前言一、距离度量1.1 欧几里得距离(Euclidean Distance)1.2 曼哈顿距离(Manhattan Distance)1.3 切比雪夫距离(Chebyshev Distance)1.4 闵可夫斯基距离(Minkowski Distance)…...

2-5 softmax 回归的简洁实现
我们发现通过深度学习框架的高级API能够使实现线性回归变得更加容易。 同样,通过深度学习框架的高级API也能更方便地实现softmax回归模型。 本节如在上节中一样, 继续使用Fashion-MNIST数据集,并保持批量大小为256。 import torch from torc…...

我 17 岁创业,今年 20 岁,月入 70 万,全靠低代码
想象一下,当你还在高中的课桌前埋头苦读时,有人告诉你三年后你将成为一家年收入超过 100 万美元的科技公司的创始人。 听起来是不是像天方夜谭? 但对于 20 岁的小伙子 Jacob Klug 来说,这就是他的真实人生。 在大多数同龄人还在为…...

【Python】已解决:urllib.error.HTTPError: HTTP Error 403: Forbidden
文章目录 一、分析问题背景二、可能出错的原因三、错误代码示例四、正确代码示例五、注意事项 已解决:urllib.error.HTTPError: HTTP Error 403: Forbidden 一、分析问题背景 在使用Python的urllib库中的urlopen或urlretrieve函数下载文件时,有时会遇到…...

昇思12天
FCN图像语义分割 1. 主题和背景 FCN是由UC Berkeley的Jonathan Long等人于2015年提出的,用于实现图像的像素级预测。 2. 语义分割的定义和重要性 语义分割是图像处理和机器视觉中的关键技术,旨在对图像中的每个像素进行分类。它在很多领域有重要应用…...

【postgresql】 基础知识学习
PostgreSQL是一个高度可扩展的开源对象关系型数据库管理系统(ORDBMS),它以其强大的功能、灵活性和可靠性而闻名。 官网地址:https://www.postgresql.org/ 中文社区:文档目录/Document Index: 世界上功能最强大的开源…...

按键控制LED流水灯模式定时器时钟
目录 1.定时器 2. STC89C52定时器资源 3.定时器框图 4. 定时器工作模式 5.中断系统 1)介绍 2)流程图:编辑 3)STC89C52中断资源 4)定时器和中断系统 5)定时器的相关寄存器 6.按键控制LED流水灯模…...

【Docker安装】OpenEuler系统下部署Docker环境
【Docker安装】OpenEuler系统下部署Docker环境 前言一、本次实践介绍1.1 本次实践规划1.2 本次实践简介二、检查本地环境2.1 检查操作系统版本2.2 检查内核版本2.3 检查yum仓库三、卸载Docker四、部署Docker环境4.1 配置yum仓库4.2 检查可用yum仓库4.3 安装Docker4.4 检查Docke…...

小程序 使用 UI 组件 Vant Weapp 、vant组件样式覆盖
注意:使用vant 包,需要把app.json 中 的"style:v2" 这句去掉 不然会出现样式混乱的问题 Vant Weapp组件库的使用 参考官网 vant官网 Vant Weapp 组件样式覆盖 Vant Weapp 基于微信小程序的机制,为开发者提供了 3 种修改组件样式…...
前端弄一个变量实现点击次数在前端页面实时更新)
(接上一篇)前端弄一个变量实现点击次数在前端页面实时更新
实现点击次数在前端页面实时更新,确实需要在前端维护一个变量来存储当前的点击次数。这个变量通常在Vue组件的data选项中定义,并在组件的生命周期方法或事件处理函数中更新。 以下是实现这一功能的基本步骤: 定义变量:在Vue组件的…...

迭代器模式在金融业务中的应用及其框架实现
引言 迭代器模式(Iterator Pattern)是一种行为设计模式,它提供了一种方法顺序访问一个聚合对象中的各个元素,而又不需要暴露该对象的内部表示。在金融业务中,迭代器模式可以用于遍历复杂的数据结构,如交易…...
浏览器插件利器-allWebPluginV2.0.0.14-stable版发布
allWebPlugin简介 allWebPlugin中间件是一款为用户提供安全、可靠、便捷的浏览器插件服务的中间件产品,致力于将浏览器插件重新应用到所有浏览器。它将现有ActiveX插件直接嵌入浏览器,实现插件加载、界面显示、接口调用、事件回调等。支持谷歌、火狐等浏…...

机器学习训练之使用静态图加速
前言 MindSpore有两种运行模式:动态图模式和静态图模式。默认情况下是动态图模式,也可以手工切换为静态图模式。 动态图模式 动态图的特点是计算图的构建和计算同时发生,符合Python的解释执行方式。在调试模型时较为方便,能够实…...
数据结构速成--图
由于是速成专题,因此内容不会十分全面,只会涵盖考试重点,各学校课程要求不同 ,大家可以按照考纲复习,不全面的内容,可以看一下小编主页数据结构初阶的内容,找到对应专题详细学习一下。 目录 …...

昇思25天学习打卡营第12天|FCN图像语义分割
文章目录 昇思MindSpore应用实践基于MindSpore的FCN图像语义分割1、FCN 图像分割简介2、构建 FCN 模型3、数据预处理4、模型训练自定义评价指标 Metrics 5、模型推理结果 Reference 昇思MindSpore应用实践 本系列文章主要用于记录昇思25天学习打卡营的学习心得。 基于MindSpo…...

Ruby开发工具JetBrains RubyMine
链接:https://pan.quark.cn/s/6d78ff88b12eJetBrains RubyMine是一个全新的为Ruby 和 Rails开发者准备的代码编辑器 ,对于Ruby这种比较新兴的编程语言,如果你是Ruby的爱好者,不妨试试使用它作为你的开发工具。软件是建立在IntellJ…...

从COX分析到预后模型:如何用R筛选关键基因并画出发表级森林图?
从COX分析到预后模型:如何用R筛选关键基因并画出发表级森林图? 在生物信息学研究中,COX比例风险模型是分析基因与患者生存关系的重要工具。但许多研究者在完成初步分析后常陷入困惑:面对数十个候选基因,如何筛选真正有…...

【AI实战项目】项目四:文本匹配技术深度实践与应用
分享一个大牛的人工智能教程。零基础!通俗易懂!风趣幽默!希望你也加入到人工智能的队伍中来!请轻击人工智能教程https://www.captainai.net/troubleshooter 项目背景: 在智能交互与信息检索领域,…...
的“组合拳”)
城市峡谷里,你的车是怎么知道自己在哪的?聊聊INS、NHC和轮速计(ODO)的“组合拳”
城市峡谷里,你的车是怎么知道自己在哪的?聊聊INS、NHC和轮速计(ODO)的“组合拳” 想象一下,你正驾驶车辆穿梭在纽约曼哈顿的摩天大楼之间,或是穿越一条漫长的山体隧道。突然,车载导航屏幕上的定…...

车灯设计师必看:CATIA中FreeStyle模块的10个高效技巧
车灯设计师必看:CATIA中FreeStyle模块的10个高效技巧 在汽车照明系统的设计中,曲面造型的精度与美感直接决定了最终产品的市场竞争力。作为行业标准工具,CATIA的FreeStyle模块为车灯设计师提供了强大的自由曲面创建能力,但真正掌握…...
)
3ds Max模型优化指南:用Attach命令合并物体时如何避免顶点爆炸(2024版)
3ds Max模型优化指南:用Attach命令合并物体时如何避免顶点爆炸(2024版) 在影视和游戏制作流程中,模型拓扑的整洁度直接影响后续的UV展开、动画绑定和实时渲染效率。作为3ds Max用户最常用的建模命令之一,Attach看似简单…...

SPPF中的CSP结构解析
在YOLOv5/v8等目标检测模型中,SPPF 内的 CSP 结构特指 SPPFCSPC 模块或类似变体。它是一种将空间金字塔池化层(SPPF) 与跨阶段部分网络思想(CSPNet) 紧密结合的复合模块,旨在更高效地进行多尺度特征融合并提…...

OpenAI收购科技脱口秀TBPN,力图塑造AI叙事话语权
OpenAI正通过收购备受硅谷内部人士关注的科技脱口秀TBPN进军媒体行业,该节目主持人周三宣布了这一消息。联合主持人约翰库根和乔迪海斯每个工作日从洛杉矶直播TBPN节目三小时,邀请的嘉宾包括创业者、风险投资家和科技界重要人物。此次交易的财务条款未予…...

OpenClaw压力测试:千问3.5-27B持续运行48小时稳定性报告
OpenClaw压力测试:千问3.5-27B持续运行48小时稳定性报告 1. 测试背景与设计思路 上周在星图平台部署了千问3.5-27B镜像后,我决定对OpenClaw框架进行极限压力测试。这个想法源于实际需求——作为独立开发者,经常需要AI助手连续处理夜间数据抓…...

SoftSerial软件串口原理与STM32工程实践
1. SoftSerial 库深度解析:面向资源受限 MCU 的软件 UART 实现原理与工程实践1.1 背景与工程必要性在嵌入式系统开发中,UART(通用异步收发传输器)是最基础、最广泛使用的串行通信接口。然而,MCU 的硬件 UART 资源往往极…...