【RAG探索第3讲】LlamaIndex的API调用与本地部署实战
原文链接:【RAG探索第3讲】LlamaIndex的API调用与本地部署实战
今天是2024年7月5日,星期五,天气晴,北京。 RAG的文章也看不少了,今天给大家带来一个llamaindex的实战。分为两个部分,调用ChatGLM的API来用llamaindex和本地部署qwen1.5使用llamaindex。
- LlamaIndex框架调用ChatGLM4 API实现RAG检索
概述
LlamaIndex 是一个“数据框架”,可帮助您构建 LLM 应用程序。它提供以下工具:
(1)提供数据连接器来获取您现有的数据源和数据格式(API、PDF、文档、SQL 等)。
(2)提供构建数据(索引、图表)的方法,以便这些数据可以轻松地与 LLM 一起使用。
(3)为您的数据提供高级检索/查询接口:输入任何 LLM 输入提示,获取检索到的上下文和知识增强输出。
(4)允许轻松与外部应用程序框架集成(例如 LangChain、Flask、Docker、ChatGPT 等)。
LlamaIndex官网:https://github.com/run-llama/llama_index

智谱API的获取
官网:https://open.bigmodel.cn

点击右上角的开发工作台

点击查看API key

可在上端开发文档中的接口指南了解该API的使用(这里采用的是langchain框架调用API接口)

2.实践
本次运行需要通过HuggingFace连接嵌入模型,推荐在本地部署。
(1)创建test.py文件,将以下代码粘进去
from langchain_openai import ChatOpenAI
import jwt
import time
from langchain_core.messages import HumanMessage
from llama_index.core import GPTVectorStoreIndex, SimpleDirectoryReaderfrom llama_index.embeddings.huggingface import HuggingFaceEmbedding
zhipuai_api_key = "你的智谱API"def generate_token(apikey: str, exp_seconds: int):try:id, secret = apikey.split(".")except Exception as e:raise Exception("invalid apikey", e)payload = {"api_key": id,"exp": int(round(time.time() * 1000)) + exp_seconds * 1000,"timestamp": int(round(time.time() * 1000)),}return jwt.encode(payload,secret,algorithm="HS256",headers={"alg": "HS256", "sign_type": "SIGN"},)class ChatZhiPuAI(ChatOpenAI):def __init__(self, model_name):super().__init__(model_name=model_name, openai_api_key=generate_token(zhipuai_api_key, 10),openai_api_base="https://open.bigmodel.cn/api/paas/v4")def invoke(self, question):messages = [HumanMessage(content=question),]return super().invoke(messages)# 加载数据,需确认数据目录的正确性
documents = SimpleDirectoryReader('data').load_data()
#输出加载后的数据
print("documents:",documents)
# 实例化BAAI/bge-small-en-v1.5模型
baai_embedding = HuggingFaceEmbedding(model_name="BAAI/bge-small-en-v1.5")# 使用 BAAI/bge-small-en-v1.5 模型初始化GPTVectorStoreIndex
index = GPTVectorStoreIndex.from_documents(documents, embed_model=baai_embedding)chatglm = ChatZhiPuAI(model_name="glm-4")
query_engine = index.as_query_engine(llm=chatglm)
response = query_engine.query("你的问题")
print(response)
(2)在test的同等目录下创建一个data文件夹用于存放加载的数据,作者这里在data文件夹中放入的是.txt文件用于导入。
(3)运行即可以下为展示结果
数据信息:

输出信息:

由此可见,运行成功,输出信息来源于输入的数据。
3. 遇到的Bug以及解决办法
(1)
ImportError: cannot import name 'LangSmithParams' from 'langchain_core.language_models.chat_models'
经查询:是langchain-openai包损坏,本人出现Bug是包的版本是0.1.13
解决办法: 卸载当前包 pip unstall langchain-openai,安装0.1.7即pip install langchain-openai==0.1.7
参考链接:https://github.com/langchain-ai/langchain/issues/22333
(2)
ModuleNotFoundError: No module named 'llama_index.llms.fireworks'
解决办法:安装该包:pip install llama_index.llms.fireworks
安装失败的话换源试试,本人这里采用的是清华源
但是呢,肯定会有很多人想问,如果我不想用API,或者由于某些原因没办法获得足够的API该怎么办呢?下面提供一种不需要使用官方API,直接部署就可以使用的方法,并以qwen1.5为例子进行展示。
本地部署llamaindex+qwen1.5
本地部署Qwen1.5使用LlamaIndex框架实现RAG
- 介绍
LlamaIndex官网:https://github.com/run-llama/llama_index
LlamaIndex官网提供了调用OpenAI和Llama的API构建向量存储索引。 - 实践
(1)依赖包
pip install llama-index
pip install llama-index-llms-huggingface
pip install llama-index-embeddings-huggingface
pip install llama-index ipywidgets
(2)下载Qwen1.5以及嵌入模型
嵌入模型:
git clone https://www.modelscope.cn/AI-ModelScope/bge-small-zh-v1.5.git
Qwen1.5:
git clone https://www.modelscope.cn/qwen/Qwen1.5-4B-Chat.git
(3)创建data文件夹并在文件夹内放入相应的数据。本文采取txt格式,信息来自百度百科。

(4)创建demo.py文件夹并将下列代码粘如
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core import PromptTemplate
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import SimpleDirectoryReader
from llama_index.core import VectorStoreIndex
from llama_index.core import Settings
import os
# os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'# Model names (make sure you have access on HF)
LLAMA2_13B_CHAT = "/home/data/aaa/llamaindex/Qwen1.5-7B-Chat"selected_model = LLAMA2_13B_CHATSYSTEM_PROMPT = """You are an AI assistant that answers questions in a friendly manner, based on the given source documents. Here are some rules you always follow:
- Generate human readable output, avoid creating output with gibberish text.
- Generate only the requested output, don't include any other language before or after the requested output.
- Never say thank you, that you are happy to help, that you are an AI agent, etc. Just answer directly.
- Generate professional language typically used in business documents in North America.
- Never generate offensive or foul language.
"""query_wrapper_prompt = PromptTemplate("[INST]<<SYS>>\n" + SYSTEM_PROMPT + "<</SYS>>\n\n{query_str}[/INST] "
)# Load model and tokenizer with device map
device = "cuda" if torch.cuda.is_available() else "cpu"tokenizer = AutoTokenizer.from_pretrained(selected_model)
model = AutoModelForCausalLM.from_pretrained(selected_model, device_map="auto")llm = HuggingFaceLLM(context_window=4096,max_new_tokens=128, # Further reduce the number of new tokens generatedgenerate_kwargs={"temperature": 0, # Adjusted temperature for more varied responses"do_sample": True, # Enable sampling for more varied responses},query_wrapper_prompt=query_wrapper_prompt,tokenizer_name=selected_model,model_name=selected_model,device_map="auto"
)embed_model = HuggingFaceEmbedding(model_name="/home/data/aaa/llamaindex/bge-small-zh-v1.5")Settings.llm = llm
Settings.embed_model = embed_model# Load documents
documents = SimpleDirectoryReader("/home/data/aaa/llamaindex/data").load_data()print("载入的数据-------------")
# print(documents)
print("---------------------")index = VectorStoreIndex.from_documents(documents)# Set Logging to DEBUG for more detailed outputs
query_engine = index.as_query_engine()# Function to clear cache
def clear_cache():if torch.cuda.is_available():torch.cuda.empty_cache()clear_cache()response = query_engine.query("问题?")print("回答---------------")
print(response)clear_cache()
注:记得修改模型和数据路径
(4)输出结果


总结
本讲内容介绍了LlamaIndex框架的两种使用方法:通过API调用和本地部署,具体包括以下几个方面:
- LlamaIndex框架调用ChatGLM4 API实现RAG检索 LlamaIndex是一个帮助构建LLM应用程序的数据框架,提供数据连接器、数据构建方法、高级检索接口以及与外部应用集成的功能。
获取智谱API的步骤及代码示例,包括API key的生成、数据加载和模型实例化。
遇到的常见错误及解决方法,如包版本问题和模块缺失问题。 - 本地部署LlamaIndex+Qwen1.5实现RAG 提供了本地部署所需的依赖包和下载模型的步骤。
通过创建示例代码文件,实现了LlamaIndex与Qwen1.5模型的结合,展示了从数据加载到查询响应的完整流程。
强调了修改模型和数据路径的重要性,并展示了运行结果。
合著作者:USTB-zmh
相关阅读
【RAG探索第3讲】LlamaIndex的API调用与本地部署实战
【RAG探索第2讲】大模型与知识图谱的融合之路:优势互补与协同发展
【RAG探索第1讲】通过大模型读取外部文档的创新探索与自适应策略
大模型名词扫盲贴
RAG实战-QAnything
提升大型语言模型性能的新方法:Query Rewriting技术解析
一文带你学会关键词提取算法—TextRank 和 FastTextRank实践
相关文章:
【RAG探索第3讲】LlamaIndex的API调用与本地部署实战
原文链接:【RAG探索第3讲】LlamaIndex的API调用与本地部署实战 今天是2024年7月5日,星期五,天气晴,北京。 RAG的文章也看不少了,今天给大家带来一个llamaindex的实战。分为两个部分,调用ChatGLM的API来用l…...

C# —— 日期对象
DateTime 时间类 存储时间对象 可以获取当前时间 DateTime now DateTime.Now;// 获取当前时间 Console.WriteLine("年:" now.Year);//2023 Console.WriteLine("月:" now.Month);//9 Console.WriteLine("日:" now.Day);//12 Console.WriteLi…...
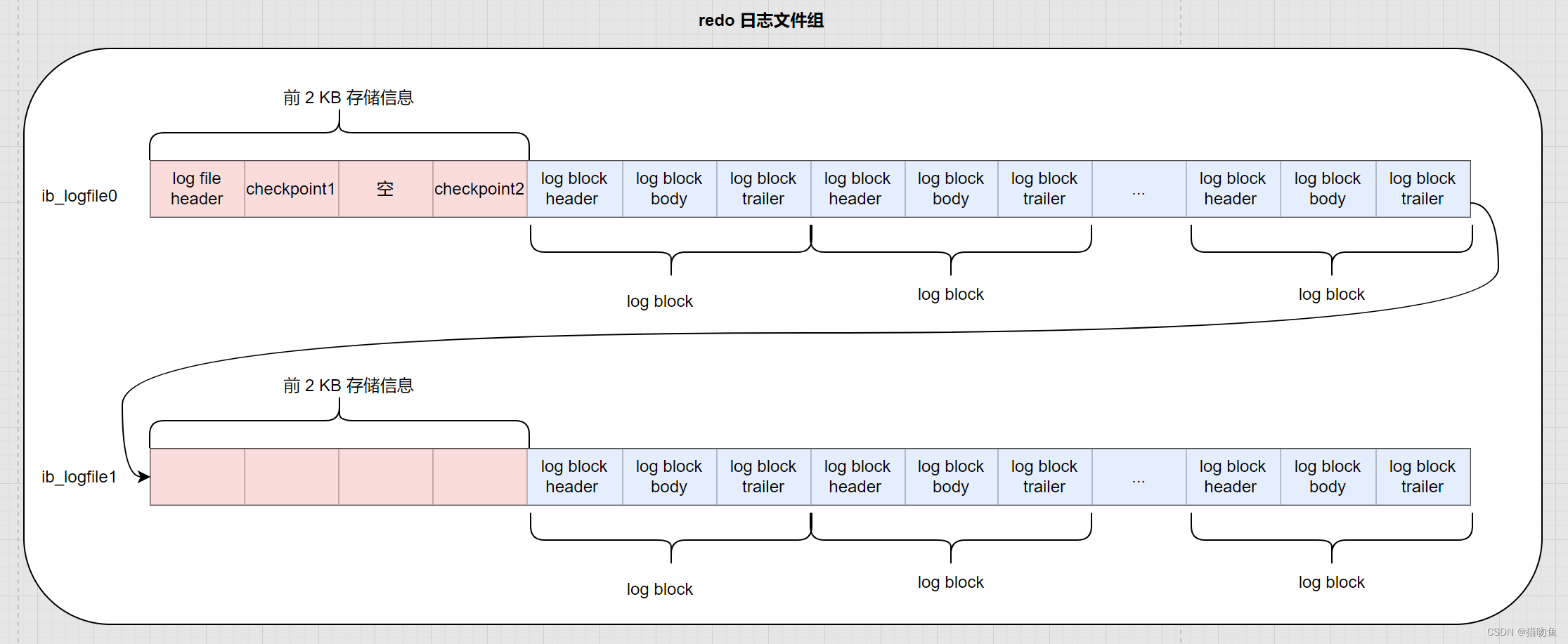
【MySQL04】【 redo 日志】
文章目录 一、前言二、redo 日志1. redo 日志格式2. Mini-Transaction2.1 以组的形式写入 redo 日志2.2 Mini-Transaction (MTR)概念 3. redo 日志写入过程3.1 redo 日志缓冲区3.3 redo 日志写入 log buffer 4. redo 日志文件4.1 redo 日志刷盘机制4.2 r…...

Android线性布局的概念与属性
线性布局(LinearLayout)是Android中最简单的布局方式,线性布局方式会使得所有在其内部的控件或子布局按一条水平或垂直的线排列。如图所示,图a是纵向线性布局示意图,图b是横向线性布局示意图。 a)纵向线性布局示意图 …...

java反射介绍
Java反射API允许你在运行时检查和修改程序的行为。这意味着你可以动态地创建对象、查看类的字段、方法和构造函数,甚至调用它们。这是一个强大的特性,但也应该谨慎使用,因为它可以破坏封装性。 以下是使用Java反射的一些常见用途:…...
Spring中@Transactional的实现和原理
这篇文章写的很详细了,引自脚本之家 Java中SpringBoot的Transactional原理_java_脚本之家...

华为仓颉可以取代 Java 吗?
大家好,我是君哥。 在最近的华为开发者大会上,华为亮相了仓颉编程语言,这是华为历经 5 年,投入大量研发成本沉淀的一门编程语言。 1 仓颉简介 按照官方报告,仓颉编程语言是一款面向全场景智能的新一代编程语言&#…...

性能测试相关理解(一)
根据学习全栈测试博主的课程做的笔记 一、说明 若未特别说明,涉及术语都是jmeter来说,线程数,就是jmeter线程组中的线程数 二、软件性能是什么 1、用户关注:响应时间 2、业务/产品关注:响应时间、支持多少并发数、…...
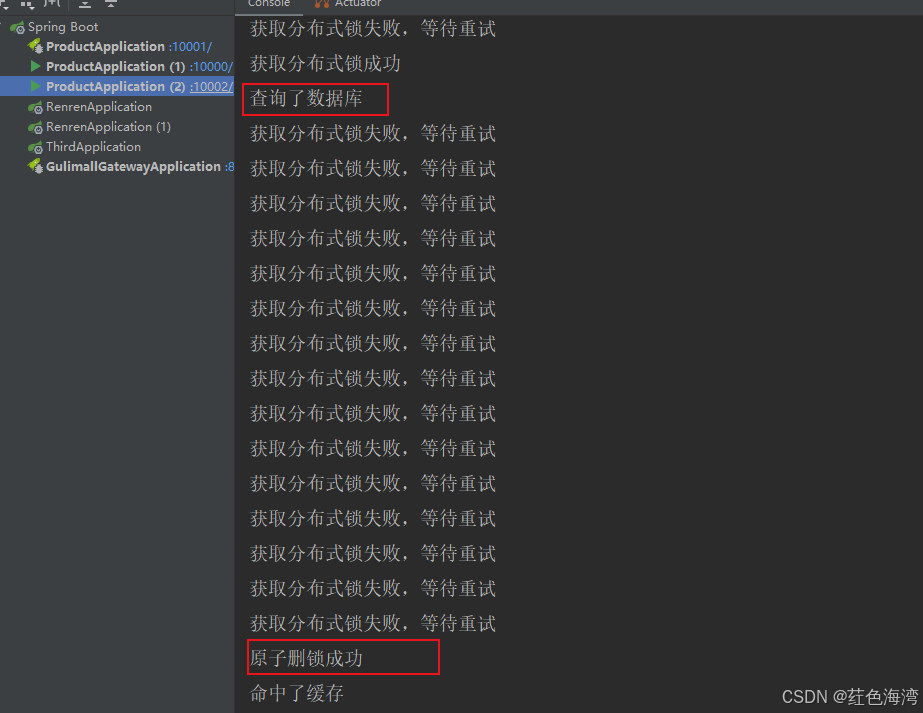
缓存-分布式锁-原理和基本使用
分布式锁原理和使用 自旋 public Map<String, List<Catelog2Vo>> getCatalogJsonFromDBWithRedisLock() {Boolean b redisTemplate.opsForValue().setIfAbsent(Lock, Lock, Duration.ofMinutes(1));if (!b) {int i 10;while (i > 0) {Object result redisTe…...

判断国内ip
php代码 //是否国内ip function isChinaIP($ip) {saveLog("---isChinaIP----------");$url "https://searchplugin.csdn.net/api/v1/ip/get?ip".$ip;// 发送HTTP请求$response file_get_contents($url);$utf8String mb_convert_encoding($response, &…...
)
linux修改内核实现禁止被ping(随手记)
概述 Linux默认允许被ping。其主要决定因素为: 内核参数防火墙(iptables/firewall) 以上的决定因素是与的关系,即需要均满足。 因此,修改linux禁被ping有以上两种方法可以实现。 修改内核文件使禁ping 1. 临时生…...
mac M1安装 VSCode
最近在学黑马程序员Java最新AI若依框架项目开发,里面前端用的是Visual Studio Code 所以我也就下载安装了一下,系统是M1芯片的,安装过程还是有点坑的写下来大家注意一下 1.在appstore中下载 2.在系统终端中输入 clang 显示如下图 那么在终端输…...
代码随想录算法训练营第二十七天 |56. 合并区间 738.单调递增的数字 968.监控二叉树 (可跳过)
56. 合并区间 以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。 示例 1: 输入:in…...

网络基础:IS-IS协议
IS-IS(Intermediate System to Intermediate System)是一种链路状态路由协议,最初由 ISO(International Organization for Standardization)为 CLNS(Connectionless Network Service)网络设计。…...

Java面试八股之如何提高MySQL的insert性能
如何提高MySQL的insert性能 提高MySQL的INSERT性能可以通过多种策略实现,以下是一些常见的优化技巧: 批量插入: 而不是逐条插入,可以使用单个INSERT语句插入多行数据。例如: INSERT INTO table_name (col1, col2) V…...

【密码学】什么是密码?什么是密码学?
一、密码的定义 根据《中华人民共和国密码法》对密码的定义如下: 密码是指采用特定变换的方法对信息等进行加密保护、安全认证的技术、产品和服务。 二、密码学的定义 密码学是研究编制密码和破译密码的技术科学。由定义可以知道密码学分为两个主要分支&#x…...

k8s record 20240703
1. containerd 它不用于直接和开发人员互动,在这方面不和docker竞争 containerd的用时最短,性能最好。 containerd 是容器的生命周期管理,容器的网络管理等等,真正让容器运行需要runC containerd 是一个独立的容器运行时&am…...

Ansible常用模块
华子目录 Ansible四个命令模块1.组成2.特点3.区别3.1command、shell模块3.2raw模块 4.command模块4.1参数表4.2free_form参数 5.shell模块5.1作用5.2例如 6.script模块6.1示例 7.raw模块7.1参数7.2示例 文件操作模块1.file模块1.1参数1.2示例 2.copy模块2.1参数 Ansible四个命令…...

【JavaScript脚本宇宙】提升用户体验:探索 JavaScript 库中的浏览器特性支持检测
深入探讨JavaScript库:功能、配置与应用场景 前言 在现代的Web开发中,JavaScript库扮演着至关重要的角色,帮助开发人员简化代码、提高效率、实现更好的用户体验。本文将探讨几个常用的JavaScript库,包括模块加载库、数据绑定库和…...

深度学习:C++和Python如何对大图进行小目标检测
最近在医美和工业两条线来回穿梭,甚是疲倦,一会儿搞搞医美的人像美容,一会儿搞搞工业的检测,最近新接的一个项目,关于瑕疵检测的,目标图像也并不是很大吧,需要放大后,才能看见细小的…...

机器学习模型评估中的构念效度:超越基准测试分数的科学推断
1. 项目概述与核心问题在机器学习的日常研究和工程实践中,我们每天都在和各种各样的基准测试(Benchmark)打交道。无论是为了比较新提出的ResNet变体在ImageNet上的Top-1准确率,还是评估一个大型语言模型在MMLU上的常识推理能力&am…...

告别拍脑袋规划!用ArcGIS做绿道选线:如何科学量化坡度、水域、道路成本并加权计算
科学规划绿道的ArcGIS高阶技法:从成本栅格构建到最优路径生成绿道规划从来不是简单的"两点之间直线最短",而是需要综合考虑地形、生态、人文等多维因素的复杂决策过程。传统规划中常见的"拍脑袋"决策方式,往往导致建成后…...

飞书远程控机:OpenClaw配置全攻略
本文详细介绍如何通过 OpenClaw 工具对接飞书开放平台,配置智能机器人实现 Windows 电脑的远程控制。主要内容涵盖文件管理和程序启动等核心功能的实现方法,并提供完整的配置指南与常见问题解决方案。 一、使用前提说明 1. 系统要求 仅适用于 Windows…...

照着用就行:2026 最新降AIGC软件测评与推荐
2026年真正好用的AI论文降重与改写工具,核心看降重效果、去AI味、格式保留、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 …...

SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能
SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...

网络配置工具类详解
CNet 网络配置工具类详解平台:仅支持 Linux,大量使用 ioctl 系统调用一、概述 CNet 是一个 纯静态方法的网络配置工具类,封装了 Linux 下常用的网络操作:功能类别涵盖内容IP 地址读取/设置本机 IP、子网掩码网关读取/添加/删除/设…...

交流电机驱动器的三种控制模式:前沿切相、后沿切相与同步模式详解
1. 项目概述:一个能玩出花的交流电机驱动器在汽车改装、工业控制或者一些创客项目里,驱动一个交流电机听起来简单,但想让它听话地变速、正反转,甚至实现软启动和精确同步,往往就得搬出笨重又昂贵的工业变频器。今天分享…...

3分钟开启PC游戏分屏派对:NucleusCoop让单机游戏秒变多人同屏神器
3分钟开启PC游戏分屏派对:NucleusCoop让单机游戏秒变多人同屏神器 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 还在为热门PC游戏不支…...

量子纠错码VarQEC:原理、实现与硬件优化
1. 量子纠错码基础与实验背景量子纠错码(Quantum Error Correction Codes, QEC)是量子计算中保护量子信息免受噪声影响的核心技术。与经典纠错码不同,量子纠错需要应对量子态特有的退相干和纠缠特性。传统QEC如[[5,1,3]]完美码虽然理论完备&a…...

JWT弱密钥爆破实战:从HS256签名原理到CTF权限提升
1. 这不是密码学考试,而是一场“密钥猜谜”实战JWT(JSON Web Token)在现代Web系统中早已不是可选项,而是默认配置。登录成功后返回一串形如eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyX2lkIjoxMjMsIm5hbWUiOiLnlKjliYkiLCJpYX…...