【Scrapy】 Scrapy 爬虫框架
准我快乐地重饰演某段美丽故事主人
饰演你旧年共寻梦的恋人
再去做没流着情泪的伊人
假装再有从前演过的戏份
重饰演某段美丽故事主人
饰演你旧年共寻梦的恋人
你纵是未明白仍夜深一人
穿起你那无言毛衣当跟你接近
🎵 陈慧娴《傻女》
Scrapy 是一个用于提取网页数据的开源和协作爬虫框架。它是由 Python 编写的,设计用于高效地从网站中提取数据。Scrapy 提供了一种简单、灵活和可扩展的方式来创建网页爬虫,并且在处理复杂网站时特别强大。
1. 为什么选择 Scrapy?
-
高效的数据提取
Scrapy 使用 Twisted 异步网络库来处理网络请求,这使得它能够以非常高效的方式同时处理多个请求。与其他同步爬虫框架相比,Scrapy 能够更快速地抓取大量数据。 -
灵活的架构
Scrapy 采用模块化设计,使得用户可以根据需求轻松扩展和自定义。无论是简单的数据提取任务还是复杂的分布式爬虫系统,Scrapy 都能胜任。 -
丰富的社区支持
Scrapy 拥有一个活跃的开发者社区和大量的扩展插件。用户可以利用现有的插件来增强爬虫的功能,而无需从头开始编写代码。
2. Scrapy 的核心组件
Scrapy 框架由多个组件构成,每个组件在数据提取过程中扮演着不同的角色。
-
Spiders
Spider 是 Scrapy 中最基本的爬虫类,定义了如何从一个或多个网站抓取信息。用户需要继承 Scrapy 的 Spider 类并实现 parse 方法来定义抓取逻辑。 -
Item
Item 是一种容器,用于存储从网页中提取的数据。类似于 Python 的字典,但提供了更多的验证和序列化功能。 -
Item Pipeline
Item Pipeline 是处理和存储 Item 的一系列组件。用户可以在 Pipeline 中对提取的数据进行清洗、验证和持久化。 -
Downloader Middleware
Downloader Middleware 是一组钩子,可以在 Scrapy 发出请求和接收响应时进行处理。用户可以通过中间件修改请求头、设置代理等。 -
Scheduler
Scheduler 负责接收从引擎发来的请求,并将它们加入队列,以便后续调度。它确保每个请求都能被高效地处理,并支持请求优先级。
#3. 安装和创建项目
- 安装 Scrapy
在开始使用 Scrapy 之前,需要先安装它。可以使用以下命令安装 Scrapy:
pip install scrapy
- 创建 Scrapy 项目
安装完成后,可以通过以下命令创建一个新的 Scrapy 项目:
scrapy startproject myproject
这个命令会创建一个名为 myproject 的目录结构,其中包含 Scrapy 项目的基本文件。
4. 编写第一个 Spider
创建项目后,可以开始编写第一个 Spider。以下是一个简单的 Spider 示例,它从一个网站抓取标题信息。
import scrapyclass MySpider(scrapy.Spider):name = 'myspider'start_urls = ['http://example.com']def parse(self, response):for title in response.css('title::text'):yield {'title': title.get()}
将这个 Spider 保存为 myspider.py,然后在项目目录中运行以下命令启动爬虫:
scrapy crawl myspider
5. 数据处理和存储
提取的数据可以通过 Item Pipeline 进行处理和存储。以下是一个简单的 Pipeline 示例,它将数据保存到 JSON 文件中。
import jsonclass JsonWriterPipeline:def open_spider(self, spider):self.file = open('items.json', 'w')def close_spider(self, spider):self.file.close()def process_item(self, item, spider):line = json.dumps(dict(item)) + "\n"self.file.write(line)return item
在 settings.py 中启用这个 Pipeline:
ITEM_PIPELINES = {'myproject.pipelines.JsonWriterPipeline': 300,
}
6. 高级功能
Scrapy 还支持许多高级功能,如分布式爬取、数据去重、自动处理Cookies、支持HTTP/2等。用户可以通过编写和配置中间件、扩展等来充分利用这些高级功能。
结论
Scrapy 是一个功能强大且灵活的爬虫框架,适用于从简单到复杂的各种数据提取任务。通过掌握 Scrapy 的核心组件和功能,用户可以高效地构建和维护爬虫项目,并从中获得大量有价值的数据。
相关文章:

【Scrapy】 Scrapy 爬虫框架
准我快乐地重饰演某段美丽故事主人 饰演你旧年共寻梦的恋人 再去做没流着情泪的伊人 假装再有从前演过的戏份 重饰演某段美丽故事主人 饰演你旧年共寻梦的恋人 你纵是未明白仍夜深一人 穿起你那无言毛衣当跟你接近 🎵 陈慧娴《傻女》 Scrapy 是…...

【笔记】太久不用redis忘记怎么后台登陆了
!首先启动虚拟机linux的centos7 2.启动finalshell 我的redis启动在根目录用 redis-server redis.conf --启动 systemctl status redis --查看redis状态 是否active redis-cli -h centos的ip地址 -p 你要用的redis端口号(默认为6379) -a 你…...
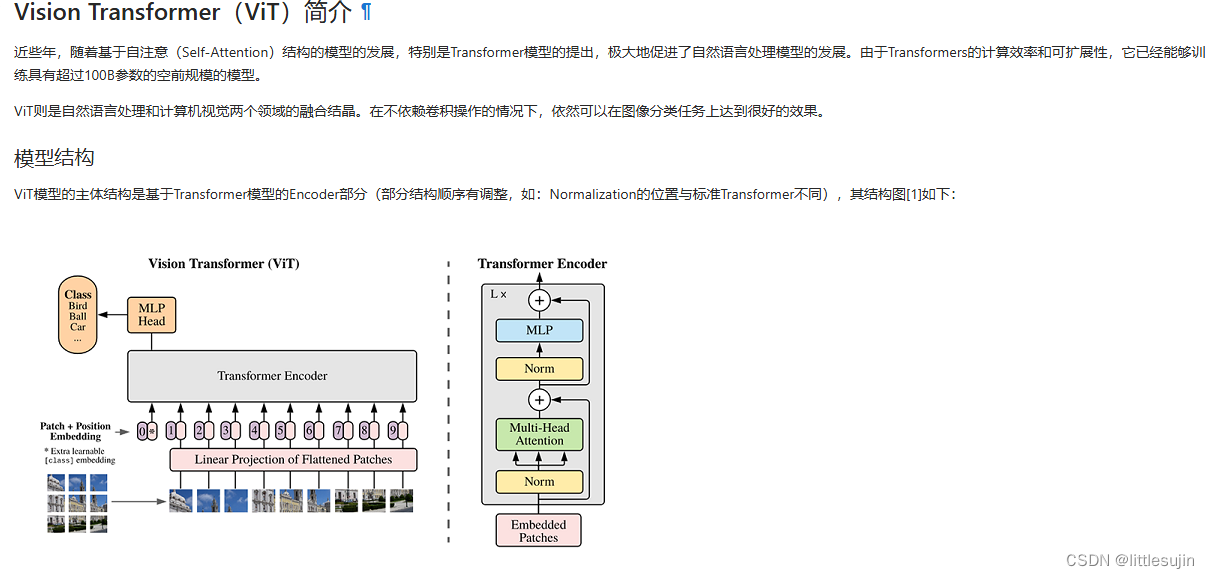
昇思25天打卡营-mindspore-ML- Day14-VisionTransformer图像分类
今天学习了Vision Transformer图像分类,这是一种基于Transformer模型的图像分类方法,它不依赖卷积操作,而是通过自注意力机制捕捉图像块之间的空间关系,从而实现图像分类。 基本原理: 图像分块: 将原始图像划分为多个…...

微信环境内H5网页,用开放标签wx-open-launch-app打开app
一、微信公众号后台配置安全域名 准备一个认证通过的公众号,打开公众号后台 1、设置与开发 2、公众号设置 3、功能设置 4、配置js接口安全域名 二、微信开放平台,将公众号与APP关联 打开微信开放平台后台 1、管理中心 2、公众号 3、选择一个需要操作…...

【c++基础】高精度数不进位加法
高精度数不进位加法 谈及数字即可想到运算,那么高精度数怎么运算呢?今天来系统介绍一下高精度数的加法。 思考一下加法运算,我们可以简单将加法运算这样区分: 有无进位。位数是否相同。 这篇文章我们就来讨论一下无进位的高精度…...

UniApp 中 Web/H5 正确使用反向代理解决跨域问题
因为 Vue3 的构建工具是 Vite,所以配置 vue.config.js 是没用的(Vue2 因为使用 webpack 所以才用这个文件) 这里提供一份 vue.config.js 的示例: module.exports {devServer: {proxy: {/api: {target: http://example.com,chan…...

Redis Stream:实时数据流的处理与存储
Redis Stream:实时数据流的处理与存储 引言 在当今数据驱动的世界中,实时数据处理和存储成为了许多应用的核心需求。Redis Stream作为一种新兴的数据结构,为Redis带来了强大的流处理能力。本文将深入探讨Redis Stream的特点、使用场景以及如何高效地利用它来处理实时数据流…...

【论文阅读】-- Visual Traffic Jam Analysis Based on Trajectory Data
基于轨迹数据的可视化交通拥堵分析 摘要1 引言2 相关工作2.1 交通事件检测2.2 交通可视化2.3 传播图可视化 3 概述3.1 设计要求3.2 输入数据说明3.3 交通拥堵数据模型3.4 工作流程 4 预处理4.1 路网处理4.2 GPS数据清理4.3 地图匹配4.4 道路速度计算4.5 交通拥堵检测4.6 传播图…...

修改编译依赖openssl的libcrypto.so
由于centos7默认使用openssl1.0.2k的libcrypto.so.10共享库。即使openssl升级为3.0.11后,编译使用ldd命令查看共享库依旧会引用libcrypto.so.10。 现希望引用libcrypto.so.3,需要在生成动态链接库的CMakeLists.txt中增加如下配置,明确指定ope…...

����: �Ҳ��������������� javafx.fxml ԭ��: java.lang.ClassNotFoundException解决方法
如果你出现了这个问题,恭喜你,你应该会花很多时间去找解决方法。别问我怎么知道的... 解决方法: 出现乱码的原因:配置vm时 这些配置看似由有空格,换行,实则没有。所以解决办法就是,重新配置你…...

【C++】———— 继承
作者主页: 作者主页 本篇博客专栏:C 创作时间 :2024年7月5日 一、什么是继承? 继承的概念 定义: 继承机制就是面向对象设计中使代码可以复用的重要手段,它允许在程序员保持原有类特性的基础上进行扩展…...

Python人生重开器
Life reopens stimulator """ 作者:->yjy 所有的惊艳都曾历经平庸 """ import random import sys import time# 打印初始界面 print(------------------------------) print(| |) print(| >>人生重…...

python 高级技巧 0708
python 33个高级用法技巧 使用装饰器计时函数 装饰器是一种允许在一个函数或方法调用前后运行额外代码的结构。 import timedef timer(func):"""装饰器函数,用于计算函数执行时间并打印。参数:func (function): 被装饰的函数返回:function: 包装后…...
)
HOW - React Router v6.x Feature 实践(react-router-dom)
目录 基本特性ranked routes matchingactive linksNavLinkuseMatch relative links1. 相对路径的使用2. 嵌套路由的增强行为3. 优势和注意事项4. . 和 ..5. 总结 data loadingloading or changing data and redirectpending navigation uiskeleton ui with suspensedata mutati…...

`padding`、`border`、`width`、`height` 和 `display` 这些 CSS 属性的作用
盒模型中的属性 padding(内边距) padding 用于控制元素内容与边框之间的空间,可以为元素的每个边(上、右、下、左)分别设置内边距。内边距的单位可以是像素(px)、百分比(%…...

C++ QT 全局信号的实现
每次做全局信号都需要重新建立文件,太麻烦了,记录一下,以后直接复制。 头文件 globalSignalEmitter.h #pragma once //#ifndef GLOBALSIGNALEITTER_H //#define GLOBALSIGNALEITTER_H#include <QObject>class GlobalSignalEmitter : …...

十款绚丽的前端 CSS 菜单导航动画
CSS汉堡菜单是一种非常流行的PC端和移动端web菜单风格,特别是移动端,这种风格的菜单应用更为广泛。这款菜单便非常适合在手机App上使用,它的特点是当顶部菜单弹出时,页面内容将会配合菜单出现适当的联动,让整个页面变得…...

debain系统使用日志
账号 vboxuser changeme ssh远程登录vbox虚拟机 https://www.cnblogs.com/BuzzWeek/p/17557981.html Terminal su - root changeme sudo apt-get update sudo apt-get -y install openssh-server #启动sshd systemctl status sshd 设置允许ssh登录vbox虚拟机 参考…...

【Word】快速对齐目录
目录标题 1. 全选要操作的内容 → 右键 → 段落2. 选则制表位3. 配置制表符4. Tab键即可 1. 全选要操作的内容 → 右键 → 段落 2. 选则制表位 3. 配置制表符 4. Tab键即可...

MATLAB基础应用精讲-【数模应用】 岭回归(Ridge)(附MATLAB、python和R语言代码实现)
目录 前言 算法原理 数学模型 Ridge 回归的估计量 Ridge 回归与标准多元线性回归的比较 3. Ridge 参数的选择 算法步骤 SPSSPRO 1、作用 2、输入输出描述 3、案例示例 4、案例数据 5、案例操作 6、输出结果分析 7、注意事项 8、模型理论 SPSSAU 岭回归分析案…...

AX-MES生产制造管理系统-总览
前言说起 MES 就不得不说 ERP,但是 ERP 大家基本上都知道,MES 就不一定了,常见的 ERP 系统包括 SAP、金蝶、用友等,ERP的流程相对来说也比较统一;MES就不同了,基本上熟悉业务流程的软件公司都可以开发并实施…...

Qwen3-Coder-30B-A3B-Instruct-FP8:终极代码模型对比分析指南
Qwen3-Coder-30B-A3B-Instruct-FP8:终极代码模型对比分析指南 【免费下载链接】Qwen3-Coder-30B-A3B-Instruct-FP8 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Coder-30B-A3B-Instruct-FP8 在当今AI代码生成领域,Qwen3-Coder-30B-…...

Kerberos身份认证原理与企业级排错实战指南
1. 这不是“另一个登录框”,而是一套精密运转的身份验证齿轮系统很多人第一次听说 Kerberos,是在公司内网登录邮箱或访问内部系统时,看到那个带小盾牌图标的弹窗——“正在使用 Kerberos 协议进行身份验证”。于是下意识觉得:“哦…...
叶绿素(CHL)数据,版本 2022.0)
Sentinel-3B OLCI 3 级全球分箱地球观测降分辨率(ERR)叶绿素(CHL)数据,版本 2022.0
Sentinel-3B OLCI Level-3 Global Binned Earth-observation Reduced Resolution (ERR) Chlorophyll (CHL) Data, version 2022.0 简介 叶绿素 a 数据集提供全球网格化的表层叶绿素 a 浓度(浮游植物生物量的替代指标)合成数据。CHL 支持时间序列和气候…...
)
用Python+OpenCV手把手实现Prewitt边缘检测(附完整代码与效果对比图)
用PythonOpenCV手把手实现Prewitt边缘检测(附完整代码与效果对比图) 边缘检测是计算机视觉中最基础也最关键的预处理步骤之一。想象一下,当你需要让计算机"看清"一张照片中的物体轮廓时,边缘检测算法就是它的"视觉…...

Rydberg原子量子门实现原理与优化技术
1. Rydberg原子平台中的量子门实现基础1.1 Rydberg原子特性与量子计算优势Rydberg原子是指外层电子被激发到高主量子数能级的原子态,这类原子具有三个关键特性使其成为量子计算的理想平台:强偶极-偶极相互作用:当两个原子同时处于Rydberg态时…...

番茄小说下载器终极指南:三步构建你的离线阅读自由王国
番茄小说下载器终极指南:三步构建你的离线阅读自由王国 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否曾在地铁里读到精彩章节时突然断网?是否在…...

Wechat2RSS:微信公众号转RSS订阅工具
文章目录Wechat2RSS:微信公众号转RSS订阅工具Wechat2RSS:微信公众号转RSS订阅工具 ttttmr开源的Wechat2RSS项目,目前在GitHub上获得1409颗Star,项目地址为https://github.com/ttttmr/Wechat2RSS。该工具的核心作用是将微信公众号…...

别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait
别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait想象你正在厨房准备一顿大餐。菜谱上写着"切菜"、"炒菜"、"装盘"等步骤,但突然发现需要同时处理多道菜品——这时候,你会本能地让家人分工…...

账务台账数据
银行里说的 “账务台账数据”,本质就是按会计规则把每笔业务逐笔、分户、分科目记下来的完整明细流水 余额 辅助信息,核心是 “可逐笔追溯、可对账、可审计” 的一套明细数据。下面用通俗、具体的方式拆开说:一、银行 “账务台账” 到底是什…...