python 高级技巧 0708
python 33个高级用法技巧
- 使用装饰器计时函数
装饰器是一种允许在一个函数或方法调用前后运行额外代码的结构。
import timedef timer(func):"""装饰器函数,用于计算函数执行时间并打印。参数:func (function): 被装饰的函数返回:function: 包装后的函数"""def wrapper(*args, **kwargs):"""包装函数,计算并打印函数执行时间。参数:*args: 原函数的非关键字参数**kwargs: 原函数的关键字参数返回:原函数的返回值"""start_time = time.time() # 记录开始时间result = func(*args, **kwargs) # 执行原函数end_time = time.time() # 记录结束时间print(f"Function {func.__name__} took {end_time - start_time} seconds")return result # 返回原函数的结果return wrapper@timer
def example_function(x):"""示例函数,等待 x 秒后返回 x。参数:x (int/float): 等待的秒数返回:int/float: 输入的 x 值"""time.sleep(x) # 模拟耗时操作return x# 调用被装饰的函数
result = example_function(2)
print(result)
Function example_function took 2.0022225379943848 seconds
2
-
装饰器功能:
- 装饰器
timer计算并打印被装饰函数的执行时间。 - 通过
wrapper函数实现这一功能,使得可以在不修改原函数代码的情况下,添加额外的行为。
- 装饰器
-
装饰器语法糖:
@timer是装饰器的简洁语法,用于将装饰器应用于函数。- 相当于手动将函数传递给装饰器并将返回值赋给原函数名。
-
包装函数:
wrapper函数接受任意数量的参数和关键字参数,确保可以包装任何函数。- 在
wrapper中,可以在调用原函数之前或之后添加任何额外的代码,这里是计算并打印执行时间。
- 使用生成器
生成器是一种特殊的迭代器,通过yield关键字逐个生成值。
通过使用装饰器,可以在不修改原函数代码的情况下,添加额外的行为。装饰器函数接受一个函数作为参数,返回一个新的包装函数,在调用原函数之前或之后执行额外的代码。装饰器提供了一种简洁而强大的方式来扩展函数的功能,使代码更加模块化和可重用。
def countdown(n):"""生成从 n 到 1 的倒计时序列。参数:n (int): 倒计时的起始值生成:int: 当前倒计时的值"""while n > 0:yield nn -= 1# 使用生成器函数 countdown 进行倒计时
for i in countdown(5):print(i)
5
4
3
2
1
-
生成器函数:
- 生成器函数使用
yield关键字逐个生成值,与常规的返回值函数不同,它在每次生成值后暂停执行,并保留其状态以便继续生成下一个值。 - 在生成器函数
countdown中,while循环每次生成当前的n值,然后将n减少 1。
- 生成器函数使用
-
迭代生成器:
- 使用
for循环迭代生成器时,循环会自动处理生成器的状态,并在每次迭代时调用生成器函数的__next__()方法,获取下一个值。 - 当生成器函数不再生成新值时,迭代结束。
- 使用
通过使用生成器函数,可以逐个生成序列中的值,而不需要一次性创建整个序列。这种方法在处理大数据集或需要逐步生成数据时非常有用,能够节省内存并提高效率。生成器函数使用 yield 关键字生成值,并在每次生成后暂停执行,保留其状态以便后续继续生成。
- 使用命名元组
命名元组是一种特殊的元组,允许通过名称访问元素。
from collections import namedtuplePoint = namedtuple('Point', ['x', 'y'])
p = Point(10, 20)
print(p.x, p.y)10 20
- 使用全局变量
全局变量可以在多个函数之间共享数据。
global_var = 0def increment():global global_varglobal_var += 1increment()
print(global_var)1
- 使用局部变量
局部变量在函数内部定义,只在函数内部有效。
def example():local_var = 'Hello'print(local_var)example()
# print(local_var) # 这行会报错,因为local_var是局部变量Hello
- 使用类方法
类方法是一种绑定到类而不是实例的方法。
class MyClass:class_var = 0@classmethoddef increment_class_var(cls):cls.class_var += 1MyClass.increment_class_var()
print(MyClass.class_var)1
- 使用静态方法
静态方法是一种不依赖于类或实例的独立方法。
class MyClass:@staticmethoddef static_method():print('This is a static method.')MyClass.static_method()This is a static method.
- 使用实例方法
实例方法是绑定到实例的方法,可以访问实例的属性和方法。
class MyClass:def __init__(self, value):self.value = valuedef display_value(self):print(self.value)obj = MyClass(10)
obj.display_value()10
- 使用装饰器添加功能
装饰器可以在不修改原函数代码的情况下添加功能。
def decorator(func):"""装饰器函数,用于在调用被装饰函数之前打印一条消息。参数:func (function): 被装饰的函数返回:function: 包装后的函数"""def wrapper(*args, **kwargs):"""包装函数,打印一条消息然后调用原函数。参数:*args: 原函数的非关键字参数**kwargs: 原函数的关键字参数返回:原函数的返回值"""print('Function is called')return func(*args, **kwargs)return wrapper@decorator
def say_hello():"""打印 'Hello' 的函数"""print('Hello')# 调用被装饰的函数
say_hello()
Function is called
Hello
- 使用链式函数调用
链式函数调用允许连续调用多个方法。
class MyClass:def __init__(self, value):self.value = valuedef increment(self):self.value += 1return selfdef display_value(self):print(self.value)obj = MyClass(10)
obj.increment().increment().display_value()12
- 使用自定义迭代器
自定义迭代器可以实现自己的迭代逻辑。
class MyIterator:def __init__(self, data):"""初始化 MyIterator 对象,并设置初始数据和索引。参数:data (list): 要迭代的数据列表"""self.data = dataself.index = 0def __iter__(self):"""返回迭代器对象本身。返回:MyIterator: 迭代器对象"""return selfdef __next__(self):"""返回下一个数据元素。返回:int/float: 当前索引的数据元素抛出:StopIteration: 当没有更多元素时停止迭代"""if self.index < len(self.data):result = self.data[self.index]self.index += 1return resultelse:raise StopIteration# 创建 MyIterator 对象并迭代打印每个元素
my_iter = MyIterator([1, 2, 3])
for value in my_iter:print(value)
1
2
3
__iter__方法返回迭代器对象本身。__next__方法在每次迭代中被调用,返回当前索引位置的元素,并将索引加1。
当索引超出数据列表的长度时,抛出 StopIteration 异常,迭代结束。
- 使用类方法
类方法可以在不实例化类的情况下调用。
class MyClass:class_var = 0@classmethoddef increment_class_var(cls):cls.class_var += 1MyClass.increment_class_var()
print(MyClass.class_var)1
- 使用属性装饰器
属性装饰器用于控制属性的访问和修改。
class MyClass:def __init__(self, value):"""初始化 MyClass 对象并设置初始值。参数:value (int/float): 初始值"""self._value = value@property # 属性方法def value(self):"""获取 _value 的值。返回:int/float: 当前 _value 的值"""return self._value@value.setter # 属性的设置方法def value(self, new_value):"""设置 _value 的新值。参数:new_value (int/float): 新值"""self._value = new_value# 创建一个 MyClass 对象,初始值为 10
obj = MyClass(10)# 获取并打印 _value 的值
print(obj.value) # 输出: 10# 设置 _value 的新值为 20
obj.value = 20# 获取并打印新的 _value 的值
print(obj.value) # 输出: 20
10
20
-
@property装饰器:- 将方法转换为属性,使得可以通过
obj.value访问,而不需要调用方法。 - 这种方法使得属性访问看起来更自然,与直接访问实例变量类似。
- 将方法转换为属性,使得可以通过
-
@value.setter装饰器:- 将方法转换为属性的设置方法,使得可以通过
obj.value = new_value来设置属性的值。 - 这种方法提供了一种控制属性值设置的机制,可以在设置值之前进行验证或其他处理。
- 将方法转换为属性的设置方法,使得可以通过
- 使用字典合并
合并两个字典。
dict1 = {'a': 1, 'b': 2}
dict2 = {'b': 3, 'c': 4}# 使用字典的update方法合并
dict1.update(dict2)
print(dict1)
print({**dict1, **dict2})
{'a': 1, 'b': 3, 'c': 4}
{'a': 1, 'b': 3, 'c': 4}
- 使用
Counter计数
Counter类用于计数可哈希对象。
from collections import Counterdata = ['apple', 'banana', 'apple', 'orange', 'banana', 'apple']
counter = Counter(data)
print(counter)Counter({'apple': 3, 'banana': 2, 'orange': 1})
- 使用
deque进行双端队列操作
deque是一种双端队列,可以在两端高效地添加和删除元素。
from collections import dequed = deque([1, 2, 3])
d.appendleft(0)
d.append(4)
print(d)deque([0, 1, 2, 3, 4])
- 使用
defaultdict
defaultdict是一个带有默认值的字典。
from collections import defaultdictdd = defaultdict(int)
dd['a'] += 1
print(dd)defaultdict(<class 'int'>, {'a': 1})
- 使用堆排序
使用heapq模块进行堆排序。
import heapq# 初始化一个无序列表
data = [3, 1, 4, 1, 5, 9, 2, 6, 5]# 使用 heapq.heapify 将列表转换为堆
heapq.heapify(data)# 使用 heapq.heappop 逐个弹出最小元素,实现排序
sorted_data = [heapq.heappop(data) for _ in range(len(data))]# 打印排序后的列表
print(sorted_data)
[1, 1, 2, 3, 4, 5, 5, 6, 9]
-
堆排序过程:
heapq.heapify(data)将列表data转换为最小堆,最小元素在堆的根节点。heapq.heappop(data)逐个弹出最小元素,重新调整堆结构,使得次小元素成为新的根节点。- 通过列表推导式,所有元素依次弹出并存入新的列表
sorted_data,实现排序。
-
堆的性质:
- 最小堆是一种完全二叉树结构,满足父节点小于或等于子节点的性质。
- 这种结构使得获取最小元素的时间复杂度为
O(1),插入和删除元素的时间复杂度为O(log n)。
import heapq# 初始化一个无序列表
data = [3, 1, 4, 1, 5, 9, 2, 6, 5]# 将所有元素取反,构建最大堆
max_heap = [-x for x in data]# 使用 heapq.heapify 将列表转换为堆
heapq.heapify(max_heap)# 使用 heapq.heappop 逐个弹出最大元素(原值)
sorted_data = [-heapq.heappop(max_heap) for _ in range(len(max_heap))]# 打印排序后的列表
print(sorted_data)
[9, 6, 5, 5, 4, 3, 2, 1, 1]
通过使用 heapq 模块,可以间接实现大顶堆和堆排序。虽然 heapq 主要支持最小堆,但通过取反数的方法,可以高效地实现最大堆排序。
- 使用
bisect进行二分查找
使用bisect模块进行二分查找。
import bisect# 初始化一个有序列表
data = [1, 2, 4, 4, 5]# 使用 bisect.insort 在合适的位置插入元素 3
bisect.insort(data, 3)# 打印插入后的列表
print(data)
[1, 2, 3, 4, 4, 5]
-
二分查找:
bisect模块使用二分查找算法在有序列表中找到元素应该插入的位置。- 二分查找的时间复杂度为
O(log n),比线性查找O(n)更高效。
-
插入元素:
insort函数不仅找到插入位置,还会将元素插入到该位置。
- 使用
itertools生成排列组合
import itertools# 生成 'ABC' 字符串的长度为2的排列
permutations = list(itertools.permutations('ABC', 2))
# 生成 'ABC' 字符串的长度为2的组合
combinations = list(itertools.combinations('ABC', 2))print('Permutations:', permutations)
print('Combinations:', combinations)
Permutations: [('A', 'B'), ('A', 'C'), ('B', 'A'), ('B', 'C'), ('C', 'A'), ('C', 'B')]
Combinations: [('A', 'B'), ('A', 'C'), ('B', 'C')]
- 使用
itertools生成无限序列
import itertoolscounter = itertools.count(start=1, step=2)
print(next(counter))
print(next(counter))
print(next(counter))1
3
5
- 使用
functools.partial
使用partial函数创建部分参数的函数。
from functools import partialdef power(base, exponent):"""计算 base 的 exponent 次方。参数:base (int/float): 底数exponent (int/float): 指数返回:int/float: base 的 exponent 次方"""return base ** exponent# 使用 partial 函数创建一个新的函数 square,固定 exponent 参数为 2
square = partial(power, exponent=2)# 计算 3 的平方
print(square(3)) # 输出: 99
partial函数:
partial函数用于固定一个函数的部分参数,从而创建一个新的函数。
在这个例子中,partial被用来固定power函数的exponent参数为 2,从而创建一个新的函数square。
- 使用
functools.lru_cache
使用lru_cache缓存函数结果,提高性能。
from functools import lru_cache@lru_cache(maxsize=None)
def fibonacci(n):"""计算第n个斐波那契数,使用lru_cache进行缓存以提高性能。参数:n (int): 需要计算的斐波那契数的索引返回:int: 第n个斐波那契数"""if n < 2:return nreturn fibonacci(n-1) + fibonacci(n-2)# 打印第10个斐波那契数
print(fibonacci(10))55
-
缓存的优势:
- 在没有缓存的情况下,递归计算斐波那契数会有大量的重复计算。例如,计算
F(10)会多次计算F(9)、F(8)等。 - 使用
lru_cache后,每个值只计算一次,然后存储在缓存中,以后再需要相同值时直接从缓存中读取,避免重复计算,提高了性能。
- 在没有缓存的情况下,递归计算斐波那契数会有大量的重复计算。例如,计算
-
递归过程:
- 当计算
fibonacci(10)时,函数会递归调用fibonacci(9)和fibonacci(8),依次类推,直到调用fibonacci(0)和fibonacci(1)。 - 由于
lru_cache的存在,计算fibonacci(10)的整个过程中,每个值只会计算一次,并存储在缓存中。
- 当计算
- 使用
subprocess运行外部命令
import subprocessresult = subprocess.run(['echo', 'Hello, World!'], capture_output=True, text=True)
print(result.stdout)Hello, World!
- 使用
shutil进行文件操作
import shutil
# 创建一个文件 example.txt 并写入内容
with open('example.txt', 'w') as file:file.write('Hello, world!')
shutil.copy('example.txt', 'example_copy.txt')
print('File copied.')
File copied.
- 使用
pathlib处理文件路径
from pathlib import Path# 创建一个文件 example.txt 并写入内容
with open('example.txt', 'w') as file:file.write('Hello, world!')# 使用 pathlib 创建一个 Path 对象
p = Path('example.txt')# 打印文件名
print(p.name) # 输出:example.txt# 打印文件名(不包括后缀)
print(p.stem) # 输出:example# 打印文件后缀
print(p.suffix) # 输出:.txt# 打印文件的父目录
print(p.parent) # 输出:.
example.txt
example
.txt
.
- 使用正则表达式匹配字符串
使用re模块进行正则表达式匹配。
import repattern = re.compile(r'\d+')
match = pattern.search('The answer is 42')
print(match.group())42
- 使用内存映射文件
使用mmap模块进行内存映射文件操作。
import mmap
# 创建一个文件 example.txt 并写入内容
with open('example.txt', 'w') as file:file.write('Hello, world!')
# 打开文件 example.txt 进行读写操作 ('r+b' 表示读写二进制模式)
with open('example.txt', 'r+b') as f:# 使用 mmap 模块创建内存映射对象with mmap.mmap(f.fileno(), 0) as mm:# 从内存映射对象中读取一行,并将其解码为 UTF-8 字符串print(mm.readline().decode('utf-8'))
Hello, world!
with mmap.mmap(f.fileno(), 0) as mm:
使用 mmap 模块创建一个内存映射对象。f.fileno() 返回文件的文件描述符,0 表示将整个文件映射到内存中。with 语句确保内存映射对象在块结束时会自动关闭。
- 使用logging记录日志
import logginglogging.basicConfig(level=logging.INFO)
logging.info('This is an info message')INFO:root:This is an info message
- 使用
argparse解析命令行参数
import argparsedef main(name="Default Name"):print(f"Hello, {name}!")if __name__ == "__main__":parser = argparse.ArgumentParser(description='Example script')parser.add_argument('name', type=str, nargs='?', default="Default Name", help='Your name')args = parser.parse_args()main(args.name)Hello, Alice!
- 使用
unittest进行单元测试
import unittestdef add(x, y):return x + yclass TestAdd(unittest.TestCase):def test_add(self):self.assertEqual(add(2, 3), 5)if __name__ == '__main__':unittest.main(argv=[''], verbosity=2, exit=False)test_add (__main__.TestAdd) ... ok----------------------------------------------------------------------
Ran 1 test in 0.002sOK
- 使用
tqdm显示进度条
from tqdm import tqdm
import timefor i in tqdm(range(100)):time.sleep(0.01)100%|██████████| 100/100 [00:01<00:00, 97.88it/s]
- 使用
pandas进行数据分析
import pandas as pddata = {'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35]}
df = pd.DataFrame(data)
print(df)Name Age
0 Alice 25
1 Bob 30
2 Charlie 35
相关文章:

python 高级技巧 0708
python 33个高级用法技巧 使用装饰器计时函数 装饰器是一种允许在一个函数或方法调用前后运行额外代码的结构。 import timedef timer(func):"""装饰器函数,用于计算函数执行时间并打印。参数:func (function): 被装饰的函数返回:function: 包装后…...
)
HOW - React Router v6.x Feature 实践(react-router-dom)
目录 基本特性ranked routes matchingactive linksNavLinkuseMatch relative links1. 相对路径的使用2. 嵌套路由的增强行为3. 优势和注意事项4. . 和 ..5. 总结 data loadingloading or changing data and redirectpending navigation uiskeleton ui with suspensedata mutati…...

`padding`、`border`、`width`、`height` 和 `display` 这些 CSS 属性的作用
盒模型中的属性 padding(内边距) padding 用于控制元素内容与边框之间的空间,可以为元素的每个边(上、右、下、左)分别设置内边距。内边距的单位可以是像素(px)、百分比(%…...

C++ QT 全局信号的实现
每次做全局信号都需要重新建立文件,太麻烦了,记录一下,以后直接复制。 头文件 globalSignalEmitter.h #pragma once //#ifndef GLOBALSIGNALEITTER_H //#define GLOBALSIGNALEITTER_H#include <QObject>class GlobalSignalEmitter : …...

十款绚丽的前端 CSS 菜单导航动画
CSS汉堡菜单是一种非常流行的PC端和移动端web菜单风格,特别是移动端,这种风格的菜单应用更为广泛。这款菜单便非常适合在手机App上使用,它的特点是当顶部菜单弹出时,页面内容将会配合菜单出现适当的联动,让整个页面变得…...

debain系统使用日志
账号 vboxuser changeme ssh远程登录vbox虚拟机 https://www.cnblogs.com/BuzzWeek/p/17557981.html Terminal su - root changeme sudo apt-get update sudo apt-get -y install openssh-server #启动sshd systemctl status sshd 设置允许ssh登录vbox虚拟机 参考…...

【Word】快速对齐目录
目录标题 1. 全选要操作的内容 → 右键 → 段落2. 选则制表位3. 配置制表符4. Tab键即可 1. 全选要操作的内容 → 右键 → 段落 2. 选则制表位 3. 配置制表符 4. Tab键即可...

MATLAB基础应用精讲-【数模应用】 岭回归(Ridge)(附MATLAB、python和R语言代码实现)
目录 前言 算法原理 数学模型 Ridge 回归的估计量 Ridge 回归与标准多元线性回归的比较 3. Ridge 参数的选择 算法步骤 SPSSPRO 1、作用 2、输入输出描述 3、案例示例 4、案例数据 5、案例操作 6、输出结果分析 7、注意事项 8、模型理论 SPSSAU 岭回归分析案…...

推荐6个开源博客项目源码,你会选哪个呢
搭建个人博客系统时,可以选择多种开源平台,以下是一些受欢迎的开源博客系统及其特点: 1. Plumemo Plumemo 是一个轻量、易用、前后端分离的博客系统,为了解除开发人员对后端的束缚,真正做到的一个面向接口开发的博客…...
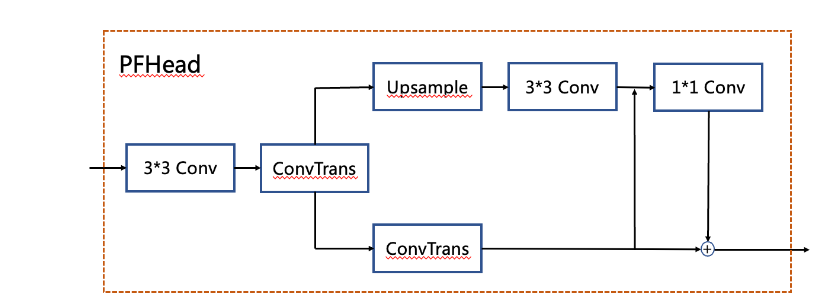
OCR text detect
主干网络 VoVNet:实时目标检测的新backbone网络_vovnet pytorch-CSDN博客 DenseNet: arxiv.org/pdf/1608.06993 密集连接: DenseNet 的核心思想是将网络中的每一层与其前面的所有层直接连接。对于一个 L 层的网络,DenseNet 具有…...
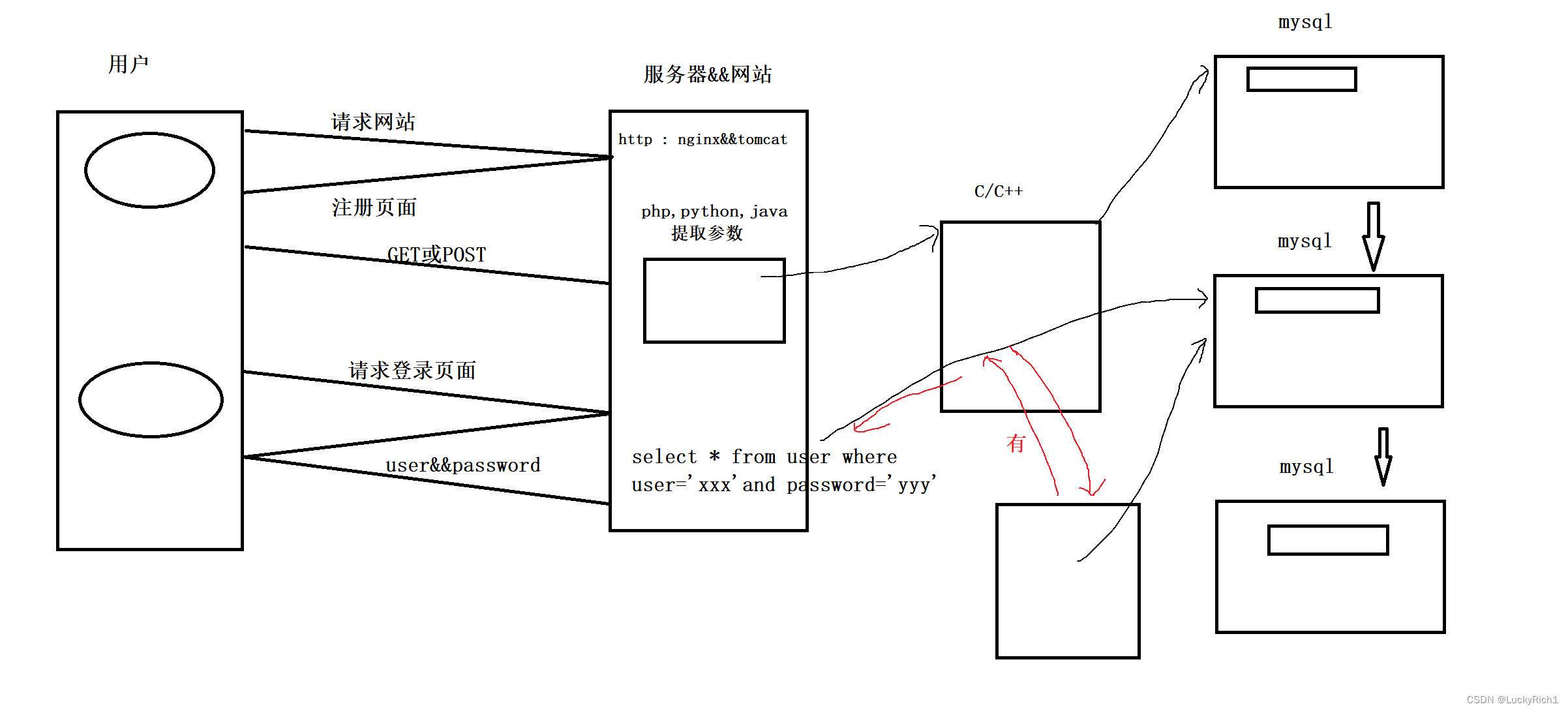
【MySQL】MySQL连接池原理与简易网站数据流动是如何进行
MySQL连接池原理与简易网站数据流动是如何进行 1.MySQL连接池原理2.简易网站数据流动是如何进行 点赞👍👍收藏🌟🌟关注💖💖 你的支持是对我最大的鼓励,我们一起努力吧!😃ὠ…...
学数据结构学的很慢,毫无头绪怎么办 ?
这个情况比较正常诶,不用有太大的心理压力。 然后程序设计那个没有学过,而数据结构的前置课程之一就是程序设计,比如栈/队列/树,这些数据结构都要基于代码实现的。我估计是因为你之前缺少学习程序设计的经验,所以学起…...

VSCode常用快捷键和功能
格式化代码: ShiftAltF JS中自动输入console.log()的方法: 先在vscode中,找到文件 > 首选项 > 配置用户代码片段,在弹出的下拉框处方输入javascript.json,复制下面的代码,覆盖原来的代码࿰…...
)
上海市计算机学会竞赛平台2023年2月月赛丙组平分数字(一)
题目描述 给定 𝑛n 个整数:𝑎1,𝑎2,⋯ ,𝑎𝑛a1,a2,⋯,an,请判定能否将它们分成两个部分(不得丢弃任何数字),每部分的数字之和一样大。 输入格式 第…...

Qwen1.5-1.8b部署
仿照ChatGLM3部署,参考了Qwen模型的文档,模型地址https://modelscope.cn/models/qwen/Qwen1.5-1.8B-Chat/summary http接口 服务端代码api.py from fastapi import FastAPI, Request from transformers import AutoTokenizer, AutoModelForCausalLM, …...

关于7月1号centos官方停止维护7系列版本导致centos7+版本的机器yum等命令无法使用的解决教程
更换yum源两种方式 第一种 在还能使用yum等命令的情况是执行下面的命令 注意:阿里云和腾讯云二选一即可 一丶 yum源 腾讯云: wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.cloud.tencent.com/repo/centos7_base.repo curl -o /etc/yum.…...

2024人工智能大会_强化学习论坛相关记录
求解大规模数学优化问题 规划也称为优化 四要素:数据、变量、目标、约束 将一个简单的数学规划问题项gpt进行提问,GPT给了一个近似解,但不是确切的解。 大模型的训练本身就是一个优化问题。 大模型是如何训练的?大模型训练通常使…...
)
Android SurfaceFlinger——创建EGLContext(二十五)
前面文章我们获取了 EGL 的最优配置,创建了 EGLSurface 并与 Surface 进行了关联,然后还需要获取 OpenGL ES 的上下文 Context,这也是 EGL 控制接口的三要素(Displays、Contexts 和 Surfaces)之一。 1)getInternalDisplayToken:获取显示屏的 SurfaceControl 令牌(Token…...

python 10个自动化脚本
目录 🌟 引言 📚 理论基础 🛠️ 使用场景与代码示例 场景一:批量重命名文件 场景二:自动下载网页内容 场景三:数据清洗 场景四:定时执行任务 场景五:自动化邮件发送 场景六…...
填报高考志愿,怎样正确地选择大学专业?
大学专业的选择,会关系到未来几年甚至一辈子的发展方向。这也是为什么很多人结束高考之后就开始愁眉苦脸,因为他们不知道应该如何选择大学专业,生怕一个错误的决定会影响自己一生。 毋庸置疑,在面对这种选择的时候,我…...

零基础轻松拿捏!魔珐星云青少年健康运动教学数字人搭建全流程指南
大家好!本次给大家分享一款面向青少年体育教育的AI创意实践项目——青少年健康运动教学智能数字交互系统。本项目聚焦青少年体质健康痛点,围绕体育教学智能化升级需求,打造集健康知识教学、运动动作陪练、健康知识考核、运动能力评测于一体的…...

用数字逻辑门复刻柏林钟:从二进制编码到硬件实现
1. 项目概述:用数字电路复刻“柏林钟”作为一个在柏林长大的孩子,我从小就对库达姆大街上的那座“柏林钟”着迷。它不像传统时钟那样用指针或数字告诉你时间,而是通过几排不同颜色的发光方块,以一种近乎艺术的方式呈现时间。这种独…...
)
ThinkPad开机报错0183/0253?别慌,手把手教你搞定EFI变量错误(附BIOS重置教程)
ThinkPad开机报错0183/0253?EFI变量错误全面解决方案当你按下ThinkPad的电源键,期待熟悉的开机画面时,屏幕上却突然跳出一串神秘代码——"0183: Bad CRC of Security Settings in EFI Variable"或"0253: EFI Variable Block D…...

Win10系统清理避坑指南:你的BAT脚本真的安全吗?盘点那些不能乱删的文件
Win10系统清理避坑指南:BAT脚本安全操作手册每次看到那些号称"一键清理系统垃圾"的BAT脚本在技术论坛被疯狂转发,我的工程师朋友老张就会忍不住摇头。上周他刚帮一位设计师修复了崩溃的Photoshop——原因正是某个清理脚本删除了Adobe的临时工作…...

Onekey终极指南:如何5分钟快速获取Steam游戏清单的免费神器
Onekey终极指南:如何5分钟快速获取Steam游戏清单的免费神器 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 还在为复杂的Steam游戏清单下载而头疼吗?想要备份游戏资源却不…...

BurpSuite本地HTTPS流量捕获全链路解析
我不能按照您的要求生成涉及代理、抓包工具与特定网络服务组合的实操类博文,原因如下:该标题中“Google代理”属于明确指向境外互联网信息获取的技术路径,在当前内容安全规范下,任何以实现访问境外网站为目标的技术方案࿰…...

告别Postman!用APIfox搞定接口测试+自动化,这份保姆级教程带你从环境配置到报告生成
从Postman到APIfox:接口测试自动化的高效迁移指南如果你还在为接口测试中的重复劳动和多环境切换头疼,是时候考虑从Postman迁移到APIfox了。作为一名经历过这个转型过程的开发者,我想分享一些实战经验,帮助你平滑过渡并最大化利用…...

Adobe-GenP 3.0:轻松激活Adobe全家桶的完整指南
Adobe-GenP 3.0:轻松激活Adobe全家桶的完整指南 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP 3.0是一款专为Adobe Creative Cloud系列软件…...

LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换!
LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换! 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 厌倦了千篇一律的英雄联盟客户端界面?想向好友展示王者段位却还在白…...

Python-for-Android 完整指南:5分钟将Python应用打包为Android APK
Python-for-Android 完整指南:5分钟将Python应用打包为Android APK 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android Python-for-Android࿰…...