OCR text detect
主干网络
VoVNet:实时目标检测的新backbone网络_vovnet pytorch-CSDN博客
DenseNet:
arxiv.org/pdf/1608.06993
-
密集连接:
- DenseNet 的核心思想是将网络中的每一层与其前面的所有层直接连接。对于一个 L 层的网络,DenseNet 具有 L(L+1)/2 个直接连接,而传统卷积网络只有 L 个连接。
- 这种密集连接模式可以缓解梯度消失问题,增强特征传播,鼓励特征重用,并显著减少参数数量46。
-
复合函数:
- 每一层实现一个非线性变换 𝐻𝑙(⋅)Hl(⋅),通常由批量归一化(BN)、ReLU 激活函数和 3x3 卷积组成46。
-
过渡层:
- DenseNet 通过多个密集块(Dense Block)组成,每个密集块之间通过过渡层(Transition Layer)连接。过渡层通常包括 1x1 卷积和 2x2 平均池化46。
-
增长率:
- 增长率(Growth Rate)是指每一层输出的特征图数量。DenseNet 可以具有非常窄的层,例如 k=12。增长率控制每一层向全局状态贡献的新信息的数量46。
-
瓶颈层和压缩:
- 为了提高计算效率,DenseNet 在每个 3x3 卷积之前引入了 1x1 卷积作为瓶颈层(Bottleneck Layer)。此外,DenseNet 通过在过渡层减少特征图数量来进一步提高模型的紧凑性46。
VoVNetv1:
arxiv.org/pdf/1904.09730
oVNet(Variationally Connected Network)是一种高效的卷积神经网络架构,旨在解决 DenseNet 中密集连接导致的高内存访问成本和能耗问题。VoVNet 通过引入 OSA(One-Shot Aggregation)模块来优化特征提取过程,提高了网络的效率和性能。
主要特点
-
OSA 模块:
- OSA 模块是 VoVNet 的核心组件。与 DenseNet 的逐层密集连接不同,OSA 模块在最后一次性聚合所有前面层的特征。这种设计减少了中间特征的冗余,提高了计算效率5455。
- 每个 OSA 模块内部包含多个 3x3 卷积层,最后通过拼接操作将特征聚合。
-
网络结构:
- VoVNet 由多个 OSA 模块组成,通常分为多个阶段(stages)。每个阶段的最后会采用一个 stride 为 2 的 3x3 最大池化层进行降采样,模型最终的输出步长为 3254。
- VoVNet 的初始部分是一个由 3 个 3x3 卷积层构成的 stem block,然后是 4 个阶段的 OSA 模块54。
-
优化和改进:
- VoVNetV2 在 VoVNet 的基础上进行了改进,引入了残差连接(Residual Connection)和有效的 Squeeze-Excitation(eSE)模块5556。
- 残差连接帮助缓解了深层网络的优化问题,使得 VoVNet 可以训练更深的网络55。
- eSE 模块通过避免通道维度的减少,保持了通道信息,提高了模型性能55。

VoVNetv2:1911.06667 (arxiv.org)
OSA 模块全称为 "One-Shot Aggregation" 模块

PP-HGNet:
HGNet 作者针对 GPU 设备,对目前 GPU 友好的网络做了分析和归纳,尽可能多的使用 3x3 标准卷积(计算密度最高)。在此将 VOVNet 作为基准模型,将主要的有利于 GPU 推理的改进点进行融合。从而得到一个有利于 GPU 推理的骨干网络,同样速度下,精度大幅超越其他 CNN 或者 VisionTransformer 模型。
PP-HGNet 骨干网络的整体结构如下:

其中,PP-HGNet是由多个HG-Block组成,HG-Block的细节如下:
PP-HGNet 和 VoVNet 之间:
-
基础模型:
- PP-HGNet 是在 VoVNet 的基础上开发的模型。VoVNet 是一种卷积神经网络架构,旨在通过引入多尺度特征融合来提高模型的性能和效率。
- PP-HGNet 继承了 VoVNet 的基本结构,并在此基础上进行了优化和改进2627。
-
优化和改进:
- PP-HGNet 使用了可学习的下采样层(LDS Layer),这是一种新的下采样方法,可以在减少计算负载的同时增加感受野。
- PP-HGNet 还融合了 ResNet_vd 等模型的优点,进一步提高了模型的性能26。
- 在 GPU 平台上,PP-HGNet 通过使用 3x3 标准卷积(计算密度最高)和其他有利于 GPU 推理的改进点,显著提高了推理速度和精度
PP-HGHetv2
PP-HGNetV2 是 PP-HGNetV1 的改进版本,在多个方面进行了优化和增强,以提高模型的性能和效率。以下是 PP-HGNetV2 和 PP-HGNetV1 的主要区别:
1. 改进的 Stem 部分
- PP-HGNetV1:使用标准的卷积层进行初始特征提取。
- PP-HGNetV2:堆叠更多的 2x2 卷积核以学习更丰富的局部特征,并使用更小的通道数以提升大分辨率任务如目标检测、语义分割等的推理速度。
2. 优化的卷积层
- PP-HGNetV1:使用标准的卷积层进行特征提取。
- PP-HGNetV2:替换了靠后 stage 的较冗余的标准卷积层该为 Pointwise Convolution (PW) + Depthwise Convolution (DW)5x5 组合,在获得更大感受野的同时减少了网络的参数量,并进一步提升了精度。
3. LearnableAffineBlock 模块
- PP-HGNetV1:没有此模块。
- PP-HGNetV2:增加了 LearnableAffineBlock 模块,可以在增加极少参数量的同时大幅提升较小模型的精度,对推理时间无损。
4. 重构的 Stage 分布
- PP-HGNetV1:原有的 stage 分布。
- PP-HGNetV2:重构了网络的 stage 分布,使其涵盖了从 B0-B6 不同量级的模型,从而满足不同任务的需求。
5. SSLD 预训练权重
- PP-HGNetV1:使用标准的预训练权重。
- PP-HGNetV2:提供了精度更高、泛化能力更强的 SSLD 预训练权重,在下游任务中表现更佳。
6. 性能和效率
- PP-HGNetV1:在相同速度下,精度高于 ResNet34-D 模型 3.8 个百分点,高于 ResNet50-D 模型 2.4 个百分点。
- PP-HGNetV2:在相同速度下,精度进一步提升,并且在使用百度自研 SSLD 蒸馏策略后,超越 ResNet50-D 模型 4.7 个百分点。
MobileNets
 图图1 标准卷积和深度可分离卷积
图图1 标准卷积和深度可分离卷积
MobileNetV1将普通卷积替换为深度卷积和逐点卷积。普通卷积的卷积核是直接用在所有的输入通道上,而深度卷积分为两部分进行计算,首先按照通道分别对特征图分别进行卷积,并将输出特征图进行拼接,随后使用逐点卷积进行通道卷积得到特征图,逐点卷积是卷积核为1x1的卷积,通道数和输入特征图一致。理论上如果MobileNetV1采用3x3卷积核,那么深度可分离卷积相较普通卷积可以降低大约9倍的计算量。
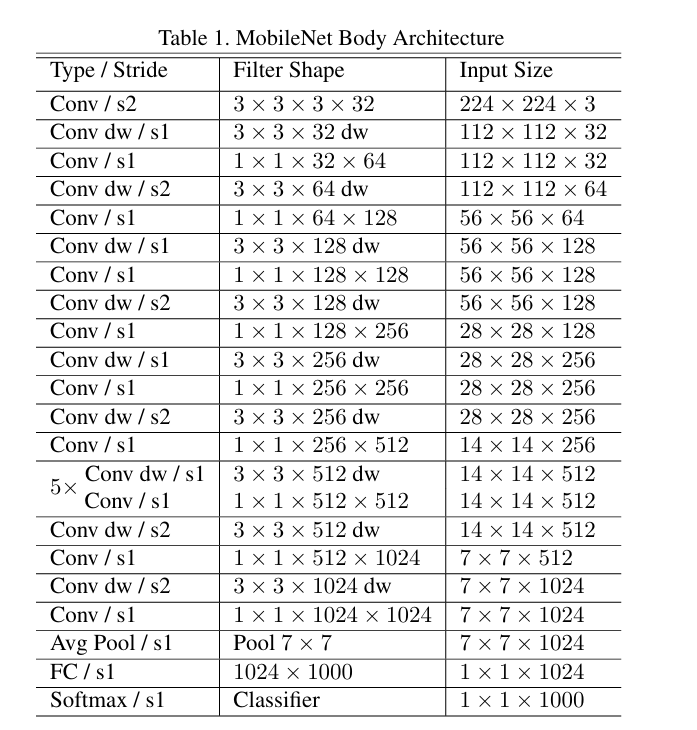
MobileNetV2
普通的残差结构先用1x1的卷积降维,再升维的操作。在MobileNetV2却是相反的操作,原因是将残差块替换为了深度可分离卷积之后,参数减少,提取的特征也相对减少,如果再进行压缩的话,能提取的特征就更少了,MobileNetV2为了避免特征减少需要先扩张高维,再经过深度可分离卷积提取特征,随后将卷积提取的特征降到低维。因此残差结构是先升维,再降维的操作。由于ReLU6激活函数对于低维的信息可能会造成比较大的瞬损失,对于高维的特征信息造成的损失很小。所以使用一个线性的激活函数避免特征损失。
通过下图可以看出,左侧为ResNet中的残差结构,其结构为1x1卷积降维->3x3卷积->1x1卷积升维;右侧为MobileNetV2中的倒残差结构,其结构为1x1卷积升维->3x3DW卷积->1x1卷积降维。V2先使用1x1进行升维的原因也是前面所说的高维信息通过ReLU激活函数后丢失的信息更少。

需要注意的是只有当s=1,即步长为1时,才有shortcut连接,步长为2是没有的
在使用 MobileNetV1时,DW 部分的卷积核容易失效,即卷积核内数值大部分为零。作者认为这是 ReLU 引起的,在变换过程中,需要将低维信息映射到高维空间,再经 ReLU 重新映射回低维空间。若输出的维度相对较高,则变换过程中信息损失较小;若输出的维度相对较低,则变换过程中信息损失很大,如下图所示深度学习基础--Bottleneck(瓶颈) Architectures_a bottleneck architecture-CSDN博客:


需要注意的是步距s,当有多个bottleneck,s只针对第一个bottleneck,后面s都为1。
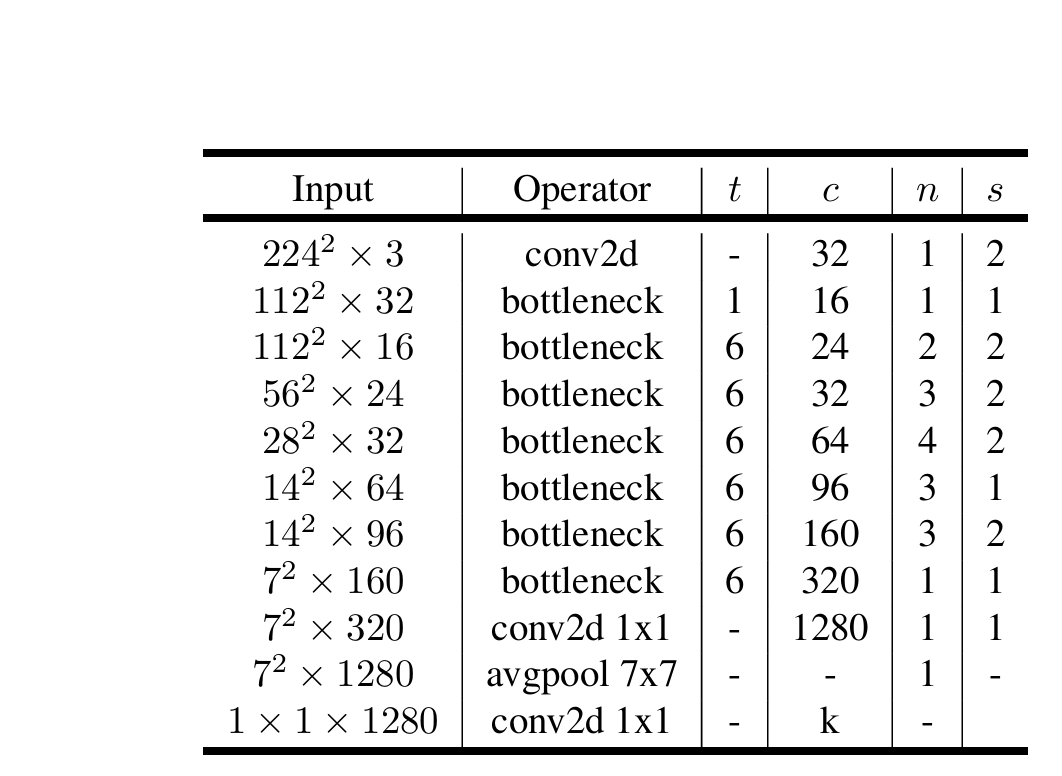
MobileNetV3
MobileNetV3进一步使用AutoML技术用更少的FLOPs获得了更好的性能。在残差中加入了 SE 模块,即注意力机制;更新了激活函数。该函数具有无上界、有下界、平滑、非单调的特点,在深层模型上优于ReLU。但是,由于sigmoid函数计算复杂(sigmoid(x) = (1 + exp(-x))^(-1)),所以V3改用近似函数来逼近swish,这使其变得更硬(hard)。作者选择了ReLU6作为这个近似函数,有两个原因:1、在几乎所有的软件和硬件框架上都可以使用ReLU6的优化实现;2、ReLU6能在特定模式下消除由于近似sigmoid的不同实现而带来的潜在的数值精度损失。
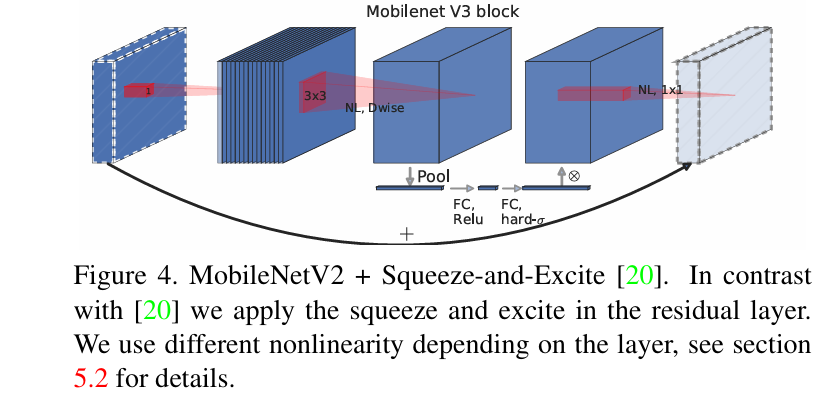
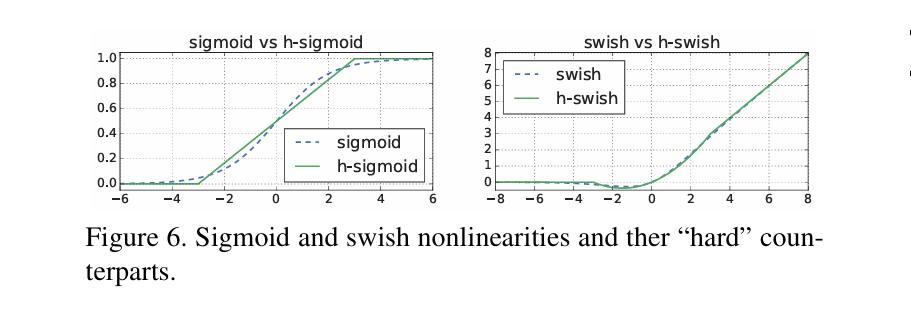
高层网络使用5x5卷积是为了捕获更大范围的空间信息,这有助于提高网络的感知能力和特征提取效果3。此外,5x5卷积还可以帮助网络更好地理解图像中的全局结构和上下文信息,从而提升网络的性能和准确性
详细且通俗讲解轻量级神经网络——MobileNets【V1、V2、V3】-云社区-华为云 (huaweicloud.com)
PP-LCNet
PP-LCNet是Mobilenetv1的变体,同时吸收Mobilenetv3中高层使用5X5卷积,卷积中使用SEnet和激活函数使用h-swish

neck
1. FPN(Feature Pyramid Network)
FPN是一种常用的neck架构,广泛应用于目标检测和分割任务中。其主要思想是通过自顶向下的路径和横向连接,融合来自不同尺度的特征图,从而生成多尺度的特征表示。
主要特点:
多尺度特征融合:通过在不同尺度上融合特征图,使得网络能够更好地检测不同大小的目标。.
自顶向下路径:从高层次特征向低层次特征传播,增强了低层次特征的表达能力。
横向连接:在自顶向下路径中添加横向连接,以保证不同尺度特征的有效融合。.
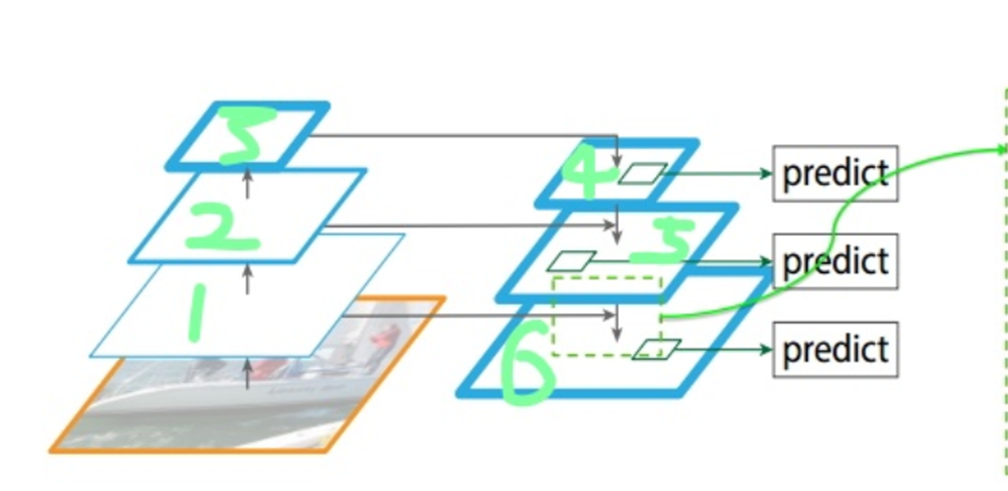
2.PANet (Path Aggregation Network)
PANet是对FPN的改进,进一步增强了特征融合的能力,特别是在细粒度特征上的表现。
主要特点:
增强的特征融合路径:增加了自底向上的路径,使得信息不仅从高层次特征传递到低层次特征也能从低层次特征传递到高层次特征。
自适应特征池化:通过自适应的特征池化操作,进一步提升了特征融合的效果
Head
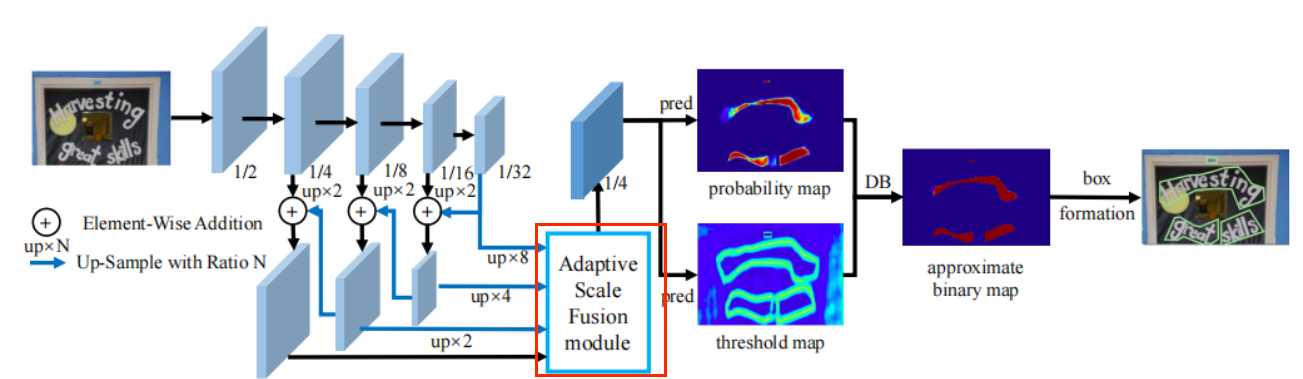
DBNet:Real-time Scene Text Detection with Differentiable BinarizationReal-time Scene Text Detection with Differentiable Binarization
DBNet(Differentiable Binarization Network)是一种用于实时场景文本检测的高效算法,通过引入可微分二值化模块来优化分割预测结果。以下是对 DBNet 的详细介绍:

主要特点
-
可微分二值化(Differentiable Binarization, DB):
- DBNet 的核心思想是将二值化过程引入到网络中,使其成为可微分的部分,从而在训练过程中自适应地学习二值化阈值。这种设计不仅简化了后处理过程,还提高了文本检测的性能。
-
高效的文本检测:
- DBNet 在多个场景文本检测数据集上表现出色,包括水平文本、多方向文本和曲形文本。其检测效果和速度均优于其他算法。
-
轻量级网络:
- 即使使用轻量级的 ResNet-18 作为主干网络,DBNet 也能取得很好的检测效果,这使得它在检测精度和效率之间找到了理想的折衷方案。
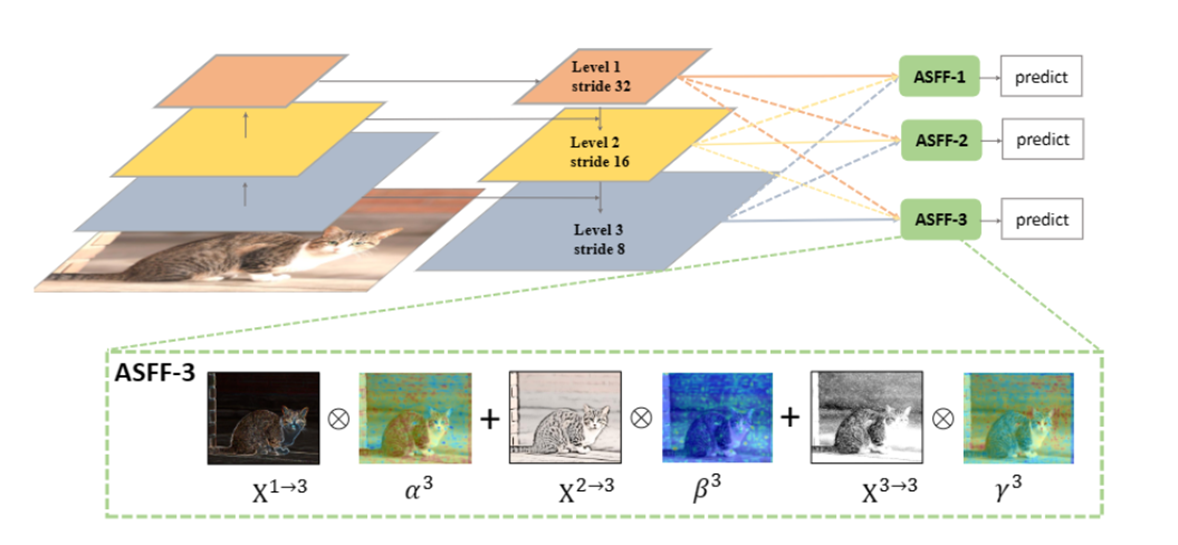
DBNet++:Real-Time Scene Text Detection with Differentiable Binarization and Adaptive Scale Fusion
-
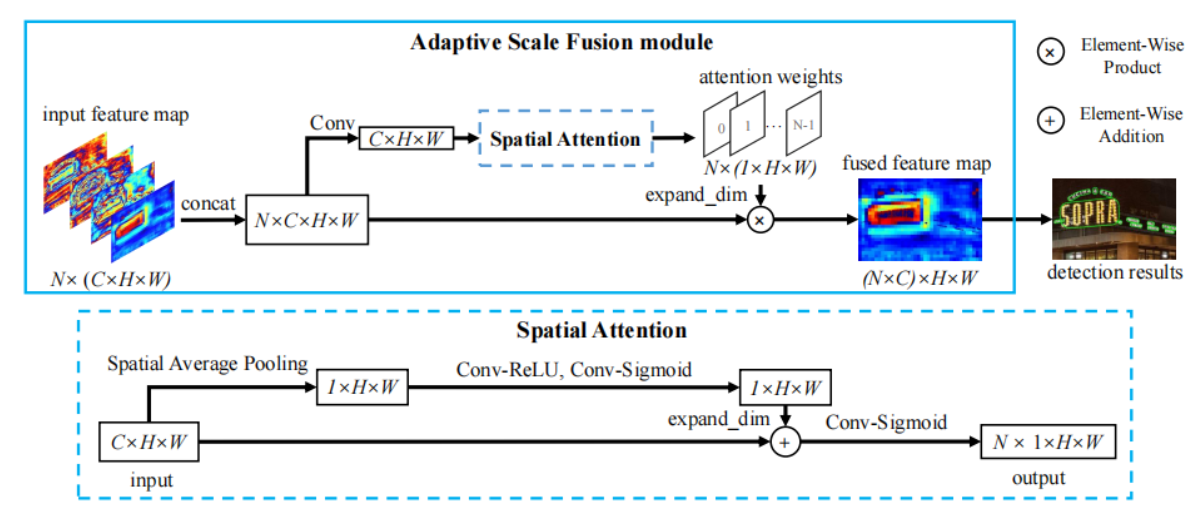
自适应多尺度融合(Adaptive Scale Fusion, ASF)模块:
- ASF 模块用于动态聚合多尺度特征图,通过引入空间注意力机制,使得融合后的特征更加鲁棒。
- ASF 是一个逐层注意力模块,能够在空间维度学习不同尺度和不同空间位置的权重,达到尺度鲁棒的特征融合。
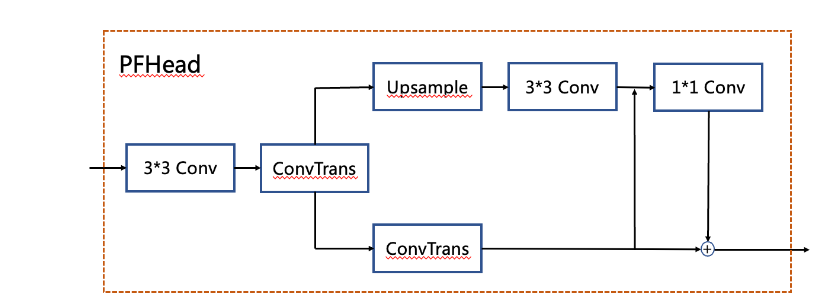
PFhead:多分支融合Head结构
PFhead结构如下图所示,PFHead在经过第一个转置卷积后,分别进行上采样和转置卷积,上采样的输出通过3x3卷积得到输出结果,然后和转置卷积的分支的结果级联并经过1x1卷积层,最后1x1卷积的结果和转置卷积的结果相加得到最后输出的概率图。PP-OCRv4学生检测模型使用PFhead,hmean从76.22%增加到76.97%。
PaddleOCR/ppocr/modeling/heads/det_db_head.py at main · PaddlePaddle/PaddleOCR · GitHub
class DBHead(nn.Layer):"""Differentiable Binarization (DB) for text detection:see https://arxiv.org/abs/1911.08947args:params(dict): super parameters for build DB network"""def __init__(self, in_channels, k=50, **kwargs):super(DBHead, self).__init__()self.k = kself.binarize = Head(in_channels, **kwargs)self.thresh = Head(in_channels, **kwargs)def step_function(self, x, y):return paddle.reciprocal(1 + paddle.exp(-self.k * (x - y)))def forward(self, x, targets=None):shrink_maps = self.binarize(x)if not self.training:return {"maps": shrink_maps}threshold_maps = self.thresh(x)binary_maps = self.step_function(shrink_maps, threshold_maps)y = paddle.concat([shrink_maps, threshold_maps, binary_maps], axis=1)return {"maps": y}class LocalModule(nn.Layer):def __init__(self, in_c, mid_c, use_distance=True):super(self.__class__, self).__init__()self.last_3 = ConvBNLayer(in_c + 1, mid_c, 3, 1, 1, act="relu")self.last_1 = nn.Conv2D(mid_c, 1, 1, 1, 0)def forward(self, x, init_map, distance_map):outf = paddle.concat([init_map, x], axis=1)# last Convout = self.last_1(self.last_3(outf))return outclass PFHeadLocal(DBHead):def __init__(self, in_channels, k=50, mode="small", **kwargs):super(PFHeadLocal, self).__init__(in_channels, k, **kwargs)self.mode = modeself.up_conv = nn.Upsample(scale_factor=2, mode="nearest", align_mode=1)if self.mode == "large":self.cbn_layer = LocalModule(in_channels // 4, in_channels // 4)elif self.mode == "small":self.cbn_layer = LocalModule(in_channels // 4, in_channels // 8)def forward(self, x, targets=None):shrink_maps, f = self.binarize(x, return_f=True)base_maps = shrink_mapscbn_maps = self.cbn_layer(self.up_conv(f), shrink_maps, None)cbn_maps = F.sigmoid(cbn_maps)if not self.training:return {"maps": 0.5 * (base_maps + cbn_maps), "cbn_maps": cbn_maps}threshold_maps = self.thresh(x)binary_maps = self.step_function(shrink_maps, threshold_maps)y = paddle.concat([cbn_maps, threshold_maps, binary_maps], axis=1)return {"maps": y, "distance_maps": cbn_maps, "cbn_maps": binary_maps}相关文章:
OCR text detect
主干网络 VoVNet:实时目标检测的新backbone网络_vovnet pytorch-CSDN博客 DenseNet: arxiv.org/pdf/1608.06993 密集连接: DenseNet 的核心思想是将网络中的每一层与其前面的所有层直接连接。对于一个 L 层的网络,DenseNet 具有…...
【MySQL】MySQL连接池原理与简易网站数据流动是如何进行
MySQL连接池原理与简易网站数据流动是如何进行 1.MySQL连接池原理2.简易网站数据流动是如何进行 点赞👍👍收藏🌟🌟关注💖💖 你的支持是对我最大的鼓励,我们一起努力吧!😃ὠ…...
学数据结构学的很慢,毫无头绪怎么办 ?
这个情况比较正常诶,不用有太大的心理压力。 然后程序设计那个没有学过,而数据结构的前置课程之一就是程序设计,比如栈/队列/树,这些数据结构都要基于代码实现的。我估计是因为你之前缺少学习程序设计的经验,所以学起…...

VSCode常用快捷键和功能
格式化代码: ShiftAltF JS中自动输入console.log()的方法: 先在vscode中,找到文件 > 首选项 > 配置用户代码片段,在弹出的下拉框处方输入javascript.json,复制下面的代码,覆盖原来的代码࿰…...
)
上海市计算机学会竞赛平台2023年2月月赛丙组平分数字(一)
题目描述 给定 𝑛n 个整数:𝑎1,𝑎2,⋯ ,𝑎𝑛a1,a2,⋯,an,请判定能否将它们分成两个部分(不得丢弃任何数字),每部分的数字之和一样大。 输入格式 第…...

Qwen1.5-1.8b部署
仿照ChatGLM3部署,参考了Qwen模型的文档,模型地址https://modelscope.cn/models/qwen/Qwen1.5-1.8B-Chat/summary http接口 服务端代码api.py from fastapi import FastAPI, Request from transformers import AutoTokenizer, AutoModelForCausalLM, …...

关于7月1号centos官方停止维护7系列版本导致centos7+版本的机器yum等命令无法使用的解决教程
更换yum源两种方式 第一种 在还能使用yum等命令的情况是执行下面的命令 注意:阿里云和腾讯云二选一即可 一丶 yum源 腾讯云: wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.cloud.tencent.com/repo/centos7_base.repo curl -o /etc/yum.…...

2024人工智能大会_强化学习论坛相关记录
求解大规模数学优化问题 规划也称为优化 四要素:数据、变量、目标、约束 将一个简单的数学规划问题项gpt进行提问,GPT给了一个近似解,但不是确切的解。 大模型的训练本身就是一个优化问题。 大模型是如何训练的?大模型训练通常使…...
)
Android SurfaceFlinger——创建EGLContext(二十五)
前面文章我们获取了 EGL 的最优配置,创建了 EGLSurface 并与 Surface 进行了关联,然后还需要获取 OpenGL ES 的上下文 Context,这也是 EGL 控制接口的三要素(Displays、Contexts 和 Surfaces)之一。 1)getInternalDisplayToken:获取显示屏的 SurfaceControl 令牌(Token…...

python 10个自动化脚本
目录 🌟 引言 📚 理论基础 🛠️ 使用场景与代码示例 场景一:批量重命名文件 场景二:自动下载网页内容 场景三:数据清洗 场景四:定时执行任务 场景五:自动化邮件发送 场景六…...
填报高考志愿,怎样正确地选择大学专业?
大学专业的选择,会关系到未来几年甚至一辈子的发展方向。这也是为什么很多人结束高考之后就开始愁眉苦脸,因为他们不知道应该如何选择大学专业,生怕一个错误的决定会影响自己一生。 毋庸置疑,在面对这种选择的时候,我…...

Java 使用sql查询mongodb
在现代应用开发中,关系型数据库和NoSQL数据库各有千秋。MongoDB作为一种流行的NoSQL数据库,以其灵活的文档模型和强大的扩展能力,受到广泛欢迎。然而,有时开发者可能更熟悉SQL查询语法,或者需要在现有系统中复用SQL查询…...
 同步互斥)
WIN32核心编程 - 线程操作(二) 同步互斥
公开视频 -> 链接点击跳转公开课程博客首页 -> 链接点击跳转博客主页 目录 竞态条件 CriticalSection Mutex CriticalSection & Mutex Semaphore Event 竞态条件 多线程环境下,当多个线程同时访问或者修改同一个数据时,最终结果为线程执…...

web自动化(六)unittest 四大组件实战(京东登录搜索加入购物车)
Unittest框架 Unittest框架:框架测试模块测试管理模块测试统计模块,python的内置模块 import unittest Unittest框架四大组件: 1、TestCase 测试用例 2.TestFixture 测试用例夹具 测试用例需要执行的前置和后置 3.TestSuite 测试套件 把需要执行的测试用例汇总在一…...

鸿蒙语言基础类库:【@ohos.process (获取进程相关的信息)】
获取进程相关的信息 说明: 本模块首批接口从API version 7开始支持。后续版本的新增接口,采用上角标单独标记接口的起始版本。开发前请熟悉鸿蒙开发指导文档:gitee.com/li-shizhen-skin/harmony-os/blob/master/README.md点击或者复制转到。…...

华为笔试题
文章目录 1、数的分解2、字符串判断子串 1、数的分解 给定一个正整数n,如果能够分解为m(m > 1)个连续正整数之和, 请输出所有分解中,m最小的分解。 如果给定整数无法分解为连续正整数,则输出字符串"N"。 输入描述&a…...
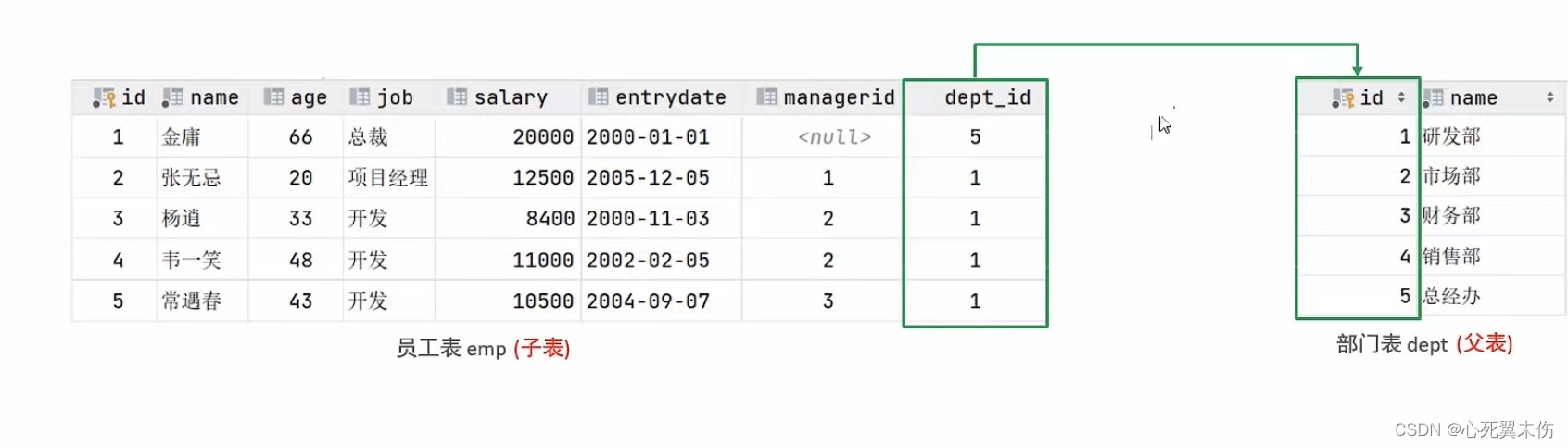
【MySQL基础篇】函数及约束
1、函数 函数是指一段可以直接被另一段程序程序调用的程序或代码。 函数 - 字符串函数 MySQL中内置了很多字符串函数,常用的几个如下: 函数功能CONCAT(S1,S2,...,Sn)字符串拼接,将S1,S2,...,Sn拼接成一个字符串LOWER(str)将字符串str全部…...

YOLOv9报错:AttributeError: ‘list‘ object has no attribute ‘view‘
报错信息如下: red_distri, pred_scores torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split( AttributeError: ‘list’ object has no attribute ‘view’ 解决方法: 去yolov9/utils/loss_tal.py把167行代码更改&#…...

Bert入门-使用BERT(transformers库)对推特灾难文本二分类
Kaggle入门竞赛-对推特灾难文本二分类 这个是二月份学习的,最近整理资料所以上传到博客备份一下 数据在这里:https://www.kaggle.com/competitions/nlp-getting-started/data github(jupyter notebook):https://gith…...

【DFS(深度优先搜索)详解】看这一篇就够啦
【DFS详解】看这一篇就够啦 🍃1. 算法思想🍃2. 三种枚举方式🍃2.1 指数型枚举🍃2.2 排列型枚举🍃2.3 组合型枚举 🍃3. 剪枝优化🍃4. 图的搜索🍃5. 来几道题试试手🍃5.1 选…...

多自由度冗余空间机械臂位姿一体化规划与控制【附代码】
✨ 长期致力于空间机械臂、对偶四元数、位姿一体化、路径规划、跟踪控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于对偶四元数的冗余机械臂运…...

ESP32多任务水位监测:从Arduino到ESP-IDF的FreeRTOS实战
1. 项目概述:从Arduino到ESP-IDF的跃迁去年我在做毕业设计时,为了搭建一个ESP32的传感器节点演示程序,第一次深入使用了FreeRTOS。那段时间,我几乎天天和任务调度、队列、信号量打交道,从最初的一头雾水到后来能流畅地…...
)
别再只测accuracy!DeepSeek集成测试必须监控的5个隐性指标(P99首token延迟、context bleed率、tool-call schema漂移)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek集成测试的核心范式演进 DeepSeek大模型的工程化落地对集成测试提出了全新挑战:传统基于接口响应码与字段校验的测试范式已难以覆盖语义一致性、推理链鲁棒性、上下文敏感度等高阶质…...
Transient、QuickEye、VerifyEye傻傻分不清?一文讲透Ansys里三种眼图仿真方法的适用场景与避坑指南
Transient、QuickEye、VerifyEye深度解析:Ansys眼图仿真技术选型实战指南 在高速数字系统设计中,眼图分析是评估信号完整性的黄金标准。面对Ansys工具链中三种截然不同的眼图生成方法,工程师常常陷入选择困境——是追求精确度的传统瞬态分析&…...

FT231XQ USB串口桥接板设计解析与实战应用指南
1. 项目概述:从FT232R到FT231XQ的USB串口桥接板演进在嵌入式开发和硬件调试的日常工作中,一个可靠、小巧且功能清晰的USB转串口(UART)桥接板(Breakout Board, 简称BoB)几乎是工程师手边的标配工…...

DragonBones与Godot集成:骨骼动画的可编程化实践
1. 为什么在Godot里用DragonBones不是“锦上添花”,而是“绕不开的刚需” 去年上线一个横版动作手游Demo时,美术团队交来一套20个角色、每个角色含8套动画(待机/跑动/跳跃/攻击/受击/死亡/闪避/必杀)的Spine资源。我兴冲冲导入God…...

基于雷达与光敏传感器的低功耗智能窗防设备设计与实现
1. 项目概述:一个基于雷达与光敏的智能窗防设备几年前,我因为一次短暂的出差,家里空置了几天,回来后就一直琢磨着怎么给家里的窗户加点“动静”。市面上的智能安防摄像头固然好,但要么需要复杂的布线,要么云…...
,锁定雾浓度≤0.38的7个关键阈值参数)
【云雾效果商业级交付标准】:基于Adobe Sensei图像雾度分析报告(N=1,247张MJ生成图),锁定雾浓度≤0.38的7个关键阈值参数
更多请点击: https://intelliparadigm.com 第一章:云雾效果商业级交付标准的定义与行业意义 云雾效果在现代数字体验中已超越视觉装饰范畴,成为空间感知建模、沉浸式交互与品牌情绪传达的核心媒介。商业级交付标准并非仅关注“是否可见雾气”…...

对比按量计费与Token Plan套餐的实际成本差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按量计费与Token Plan套餐的实际成本差异 在构建和运营基于大模型的应用时,成本控制是一个核心的工程考量。Taotok…...

学了几天 Web 安全,终于搞懂什么是 XSS 了
xss的详细介绍最近开始正式学习 Web 安全。前面陆续学了:HTTPCookieSessionJWT RBAC然后发现很多地方都会提到一个东西:XSS以前一直感觉这个漏洞很抽象。网上很多文章一上来就是:<script>alert(1)</script>然后说:“弹…...