Face_recognition实现人脸识别
这里写自定义目录标题
- 欢迎使用Markdown编辑器
- 一、安装人脸识别库face_recognition
- 1.1 安装cmake
- 1.2 安装dlib库
- 1.3 安装face_recognition
- 二、3个常用的人脸识别案例
- 2.1 识别并绘制人脸框
- 2.2 提取并绘制人脸关键点
- 2.3 人脸匹配及标注
欢迎使用Markdown编辑器
本文基于face_recognition库实现图像人脸识别,下面将介绍如何安装face_recognition库,并细述3个常用的人脸识别案例。
一、安装人脸识别库face_recognition
Face_recognition的安装不同于其他package,它需要依赖dlib库(dlib库的安装又依赖于cmake库),所以装face_recognition之前需要先安装前二者,整个安装过程还是挺耗费时间精力的。我的python环境是python3.7+Anaconda。
1.1 安装cmake
pip install cmake -i https://pypi.tuna.tsinghua.edu.cn/simple/
借助清华源的资源安装,通常下载速度会比较快,且不会中断。
1.2 安装dlib库
dlib-19.17.99-cp37-cp37m-win_amd64.whl 密码 79rt
下载后直接安装该whl文件
pip install dlib-19.17.99-cp37-cp37m-win_amd64.whl
直接在线pip install dlib,不知为何会报错,所以从网站上下载好安装包进行离线安装。
1.3 安装face_recognition
pip install face_recognition -i https://pypi.tuna.tsinghua.edu.cn/simple/
二、3个常用的人脸识别案例
本章主要介绍face_recognition下3个常用的人脸识别方法及案例,它们所依赖的库函数如下:
import os
import face_recognition as fr
from PIL import Image, ImageDraw, ImageFont
import matplotlib.pyplot as plt
import dlib
import numpy as np
2.1 识别并绘制人脸框
 其中,face_locations(img, number_of_times_to_upsample=1, model=“hog”) 方法为实现该demo的关键,该方法用于提取图像img中的人脸特征并返回所有人脸框坐标list。
其中,face_locations(img, number_of_times_to_upsample=1, model=“hog”) 方法为实现该demo的关键,该方法用于提取图像img中的人脸特征并返回所有人脸框坐标list。
def draw_face_rect(self):self.img = fr.load_image_file(pic) # 读图#(1)识别人脸框所在坐标faces = fr.face_locations(self.img) # 也可使用cnn识别# faces = fr.face_locations(self.img, number_of_times_to_upsample=0, model="cnn")#(2)创建展示结果的图像pil_img = Image.fromarray(self.img)draw = ImageDraw.Draw(pil_img)#(3)依次绘制人脸框for face in faces:top, right, bottom, left = facedraw.rectangle(((left, top), (right, bottom)), outline=(0,255,0))del drawplt.imshow(pil_img)plt.axis('off')plt.show()
- 入参img,必填,输入要求为图像阵列形式(numpy array);
- 入参number_of_times_to_upsample,default为1,设定上采样检测人脸的次数,数值越大越便于检测到更小的人脸;
- 入参model,default为’hog’,选择人脸检测模型。‘hog’即Histogram of Oriented Gradient(方向梯度直方图),它通过计算和统计图像局部区域的梯度方向直方图来构成特征,该方法精度略低但性能更快(仅使用CPU时);也可选用’cnn’ 即(卷积神经网络),cnn作为深度学习模型具有更高的识别精度,当然如果有GPU或CUDA环境加速的话更好;
- 返回值,人脸框坐标list,表示为[face_1, face_2, …face_n],其中每张人脸框包含的元组信息face_i = (top, right, bottom, left),即依次是人脸框的上、右、下、左坐标。
注意: 图2中还有好些没能识别到的人脸,个人感觉有两个原因:其一,人脸占比太小,脸部特征不明显导致无法提取到,比如右上角的双胞胎;另一,脸部肤色、亮度、细节等不符合正常人脸特征导致算法不认为是人脸,比如绿巨人和左下角的独眼。
2.2 提取并绘制人脸关键点

检测结果如上,其中红点代表face_recognition能提取到的人脸关键点(眼、眉、鼻、嘴、面部轮廓),实现代码如下
def draw_face_landmarks(self):face_marks = fr.face_landmarks(self.img)pil_img = Image.fromarray(self.img)draw = ImageDraw.Draw(pil_img)for face_mark in face_marks:for key in face_mark.keys():for pt in face_mark[key]:draw.ellipse(((pt[0]-4, pt[1]-4),(pt[0]+4, pt[1]+4)), outline=(255,0,0), width=6)del drawplt.imshow(pil_img)plt.axis('off')plt.show()
- 入参img,必填,输入要求为图像阵列形式(numpy array);
- 入参face_locations,default为None,表示可选择性的提供人脸坐标list用于check;
- 入参model,default为"large",用于选择"large"或"small"模型。其中"small"模型速度更快但是仅返回5个关键点;
- 返回值,所有人脸的关键点list。其中每张人脸landmarks为一个字典,具体键和值如下:
{"chin": points[0:17],
"left_eyebrow": points[17:22],
"right_eyebrow": points[22:27],
"nose_bridge": points[27:31],
"nose_tip": points[31:36],
"left_eye": points[36:42],
"right_eye": points[42:48],
"top_lip": points[48:55] + [points[64]] + [points[63]] + [points[62]] + [points[61]] + [points[60]],
"bottom_lip": points[54:60] + [points[48]] + [points[60]] + [points[67]] + [points[66]] + [points[65]] + [points[64]]}
其中face_landmarks(face_image, face_locations=None, model=“large”)方法为实现该demo的关键,该方法用于提取图像img中的人脸特征并返回所有人脸的关键点list.
2.3 人脸匹配及标注

检测结果如上,其中绿框代表算法识别到的人脸,框底部还标注了每个人物的名称(绿巨人一如既往地没识别出来),实现代码如下
def match_faces(self):faces = fr.face_locations(self.img)face_encodings = fr.face_encodings(self.img, faces)self.load_known_faces()pil_img = Image.fromarray(self.img)draw = ImageDraw.Draw(pil_img)for (top, right, bottom, left), cur_encoding in zip(faces, face_encodings):# matches = fr.compare_faces(self.encoding_list, cur_encoding) name = 'unknown'# 计算已知人脸和未知人脸特征向量的距离,距离越小表示两张人脸为同一个人的可能性越大distances = fr.face_distance(self.encoding_list, cur_encoding)match_index = np.argmin(distances)if matches[match_index]:name = self.name_list[match_index]# 绘制匹配到的人脸信息draw.rectangle(((left, top), (right, bottom)), outline=(0, 255, 0))text_width, text_height = draw.textsize(name)font = ImageFont.truetype('arial.ttf', 20)draw.rectangle(((left, bottom - text_height - 10), (right, bottom)), fill=(0, 0, 255), outline=(0, 255, 0))draw.text((left + 5, bottom - text_height - 10), name, fill=(255, 255, 255, 255), font=font)del drawplt.imshow(pil_img)plt.axis('off')plt.show()
其中,face_encodings()、compare_faces()、face_distance()三个方法的释义如下:
(1) face_encodings()
完整形式为face_encodings(face_image, known_face_locations=None, num_jitters=1, model=“small”),用于提取图像face_image中的人脸特征,并返回每张人脸的128维人脸编码组成的list;
-
入参face_image,必填,输入要求为图像阵列形式(numpy array);
-
入参known_face_locations,default为None,表示可选择性的提供人脸坐标list用于check;
-
入参num_jitters,default为1,表示在计算人脸编码时需要重新采样计算的次数。数值越大采样次数越多、结果越精确,但是耗时越久;
-
返回值为所有人脸的128维人脸编码组成的list。
(2) compare_faces()
完整形式为compare_faces(known_face_encodings, face_encoding_to_check, tolerance=0.6),用于比较待确认的face_encoding与已知的known_face_encodings列表中各元素的匹配程度,并返回对应长度的布尔列表;
-
入参known_face_encodings,已知的人脸编码列表,本文在self.load_known_faces()方法中读取得到;
-
入参face_encoding_to_check,待check的人脸编码;
-
入参tolerance,default为0.6,定义两张人脸之间距离数值为多少时可用于表示图像匹配,通常数值越小表明匹配越严格,0.6为经验最优值;
-
返回值为待确认的face_encoding与已知的人脸编码列表中各元素的match结果列表,形式如[False, False, True, False, False]。
(3)face_distance()
完整形式为face_distance(face_encodings, face_to_compare),同compare_faces(),用于比较待比较的face_encoding与已知的face_encodings列表中各元素的匹配程度,并返回对应长度的数值列表;
-
入参face_encodings,已知的人脸编码列表;
-
入参face_to_compare,待check的人脸编码;
-
返回值为待确认的face_encoding与已知的人脸编码列表中各元素的match结果列表,形式如[0.79155519 0.74486473 0.45825189 0.78371348 0.99910555],各元素值范围为[0,1]。
相关文章:
Face_recognition实现人脸识别
这里写自定义目录标题 欢迎使用Markdown编辑器一、安装人脸识别库face_recognition1.1 安装cmake1.2 安装dlib库1.3 安装face_recognition 二、3个常用的人脸识别案例2.1 识别并绘制人脸框2.2 提取并绘制人脸关键点2.3 人脸匹配及标注 欢迎使用Markdown编辑器 本文基于face_re…...

1-3分钟爆款视频素材在哪找啊?这9个热门爆款素材网站分享给你
在如今快节奏的时代,短视频已成为吸引观众注意力的黄金手段。然而,要制作出1-3分钟的爆款视频,除了创意和剪辑技巧外,选择合适的素材至关重要。那么,哪里可以找到那些能让你的视频脱颖而出的爆款素材呢?不用…...

武汉免费 【FPGA实战训练】 Vivado入门与设计师资课程
一.背景介绍 当今高度数字化和智能化的工业领域,对高效、灵活且可靠的技术解决方案的需求日益迫切。随着工业 4.0 时代的到来,工业生产过程正经历着前所未有的变革,从传统的机械化、自动化逐步迈向智能化和信息化。在这一背景下&…...
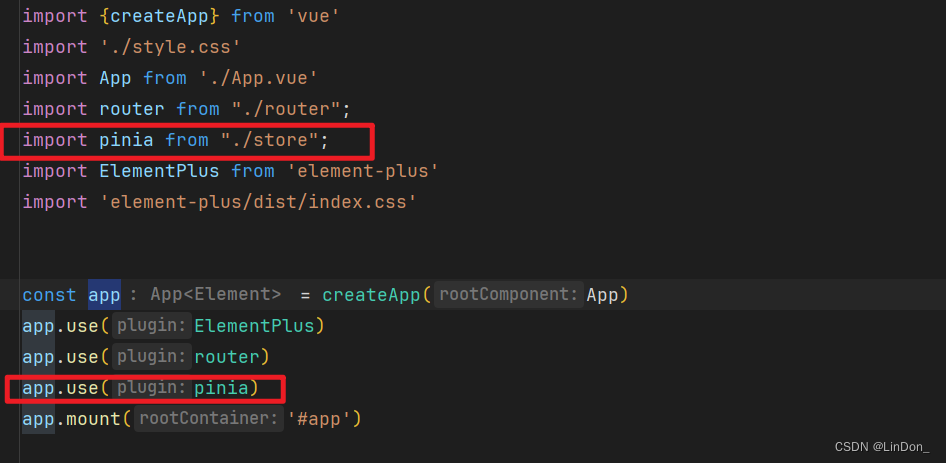
【vite创建项目】
搭建vue3tsvitepinia框架 一、安装vite并创建项目1、用vite构建项目2、配置vite3、找不到模块 “path“ 或其相对应的类型声明。 二、安装element-plus1、安装element-plus2、引入框架 三、安装sass sass-loader1、安装sass 四、安装vue-router-next 路由1、安装vue-router42搭…...

最优化方法 运筹学【】
1.无约束 常用公式 线搜索准则:求步长 精确线搜索(argmin) 最速下降:sd:线性收敛 2.算法 SD dk:付梯度-g newton dk:Gkd-g 二阶收敛,步长为1 阻尼牛顿:步长用先搜…...

探索 WebKit 的动感世界:设备方向和运动支持全解析
探索 WebKit 的动感世界:设备方向和运动支持全解析 随着移动设备的普及,网页应用对设备方向和运动的感知需求日益增长。WebKit 作为众多流行移动浏览器的渲染引擎,提供了对设备方向和运动的全面支持,使得 Web 应用能够根据设备的…...

高考假期预习指南
IT专业入门,高考假期预习指南 对于希望进入IT行业的学生来说,假期是学习信息技术的最佳时机。 在信息化快速发展的时代,IT行业的发展前景广阔,但高技能要求使新生可能感到迷茫。 建议新生制定详细的学习计划,包括了解…...

Spring Boot 事件监听机制工作原理
前言: 我们知道在 Spring 、Spring Boot 的启动源码中都大量的使用了事件监听机制,也就是我们说的的监听器,监听器的实现基于观察者模式,也就是我们所说的发布订阅模式,这种模式可以在一定程度上实现代码的解耦&#…...

【AI大模型】驱动的未来:穿戴设备如何革新血液、皮肤检测与营养健康管理
文章目录 1. 引言2. 现状与挑战3. AI大模型与穿戴设备概述4. 数据采集与预处理4.1 数据集成与增强4.2 数据清洗与异常检测 5. 模型架构与训练5.1 高级模型架构5.2 模型训练与调优 6. 个性化营养建议系统6.1 营养建议生成优化6.2 用户反馈与系统优化 7. 关键血液成分与健康状况评…...

【FFmpeg】avcodec_open2函数
目录 1. avcodec_open21.1 编解码器的预初始化(ff_encode_preinit & ff_decode_preinit)1.2 编解码器的初始化(init)1.3 释放编解码器(ff_codec_close) FFmpeg相关记录: 示例工程ÿ…...

matlab:对带参数a关于x的方程求解
题目 讲解 简洁对各个式子的内部含义用浅显易懂的话语总结出来了,耐心体会 f(a) (x)exp(x)x^ax^(sqrt(x))-100;%因为下面的fzero的第一个数需要一个fun,所以这里有两个句柄,第一个a是输入的,第二个x是需要被解出的 A0:0.1:2;%创…...
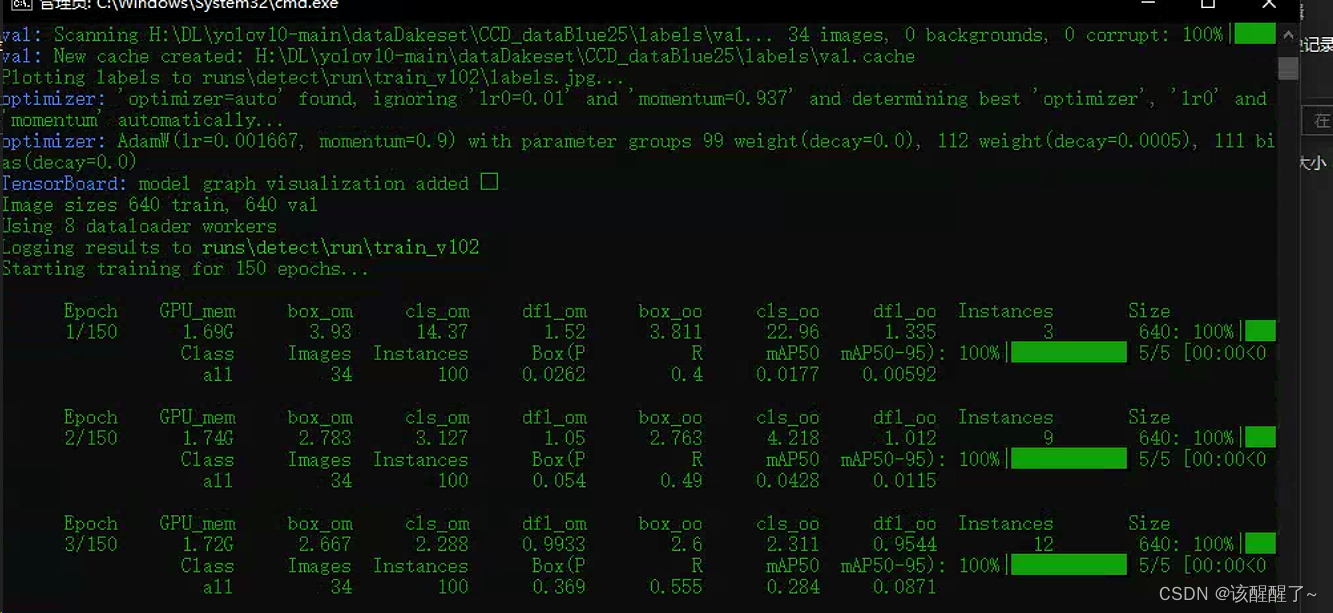
Yolov10训练,转化onnx,推理
yolov10对于大目标的效果好,小目标不好 一、如果你训练过yolov5,yolov8,的话那么你可以直接用之前的环境就行 目录 一、如果你训练过yolov5,yolov8,的话那么你可以直接用之前的环境就行 二、配置好后就可以配置文件…...

GEE代码实例教程详解:洪水灾害监测
简介 在本篇博客中,我们将使用Google Earth Engine (GEE) 进行洪水灾害监测。通过分析Sentinel-1雷达数据,我们可以识别特定时间段内的洪水变化情况。 背景知识 Sentinel-1数据集 Sentinel-1是欧洲空间局提供的雷达卫星数据集,它能够提供…...

运维锅总详解系统设计原则
本文对CAP、BASE、ACID、SOLID 原则、12-Factor 应用方法论等12种系统设计原则进行分析举例,希望对您在进行系统设计、理解系统运行背后遵循的原理有所帮助! 一、CAP、BASE、ACID简介 以下是 ACID、CAP 和 BASE 系统设计原则的详细说明及其应用举例&am…...

深度学习笔记: 最详尽解释预测系统的分类指标(精确率、召回率和 F1 值)
欢迎收藏Star我的Machine Learning Blog:https://github.com/purepisces/Wenqing-Machine_Learning_Blog。如果收藏star, 有问题可以随时与我交流, 谢谢大家! 预测系统的分类指标(精确率、召回率和 F1 值) 简介 让我们来谈谈预测系统的分类指标以及对精确率、召回…...

GEE代码实例教程详解:MODIS土地覆盖分类与面积计算
简介 在本篇博客中,我们将使用Google Earth Engine (GEE) 对MODIS土地覆盖数据进行分析。通过MODIS/061/MCD12Q1数据集,我们可以识别不同的土地覆盖类型,并计算每种类型的总面积。 背景知识 MODIS MCD12Q1数据集 MODIS/061/MCD12Q1是NASA…...
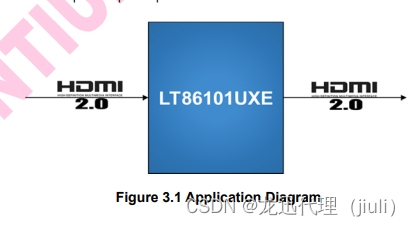
LT86101UXE 国产原装 HDMI2.0 / DVI中继器方案 分辨率 4Kx2K 用于多显示器 DVI/HDMI电缆扩展模块
1. 描述 Lontium LT86101UXE HDMI2.0 / DVI中继器特性高速中继器符合HDMI2.0/1.4规范,最大6 gbps高速数据率、自适应均衡RX输入和pre-emphasized TX输出支持长电缆应用程序,没有晶体在船上保存BOM成本,内部灵活的PCB TX巷交换路由。 LT86101UXE HDMI2.0/DVI中继器自动检测线缆损…...
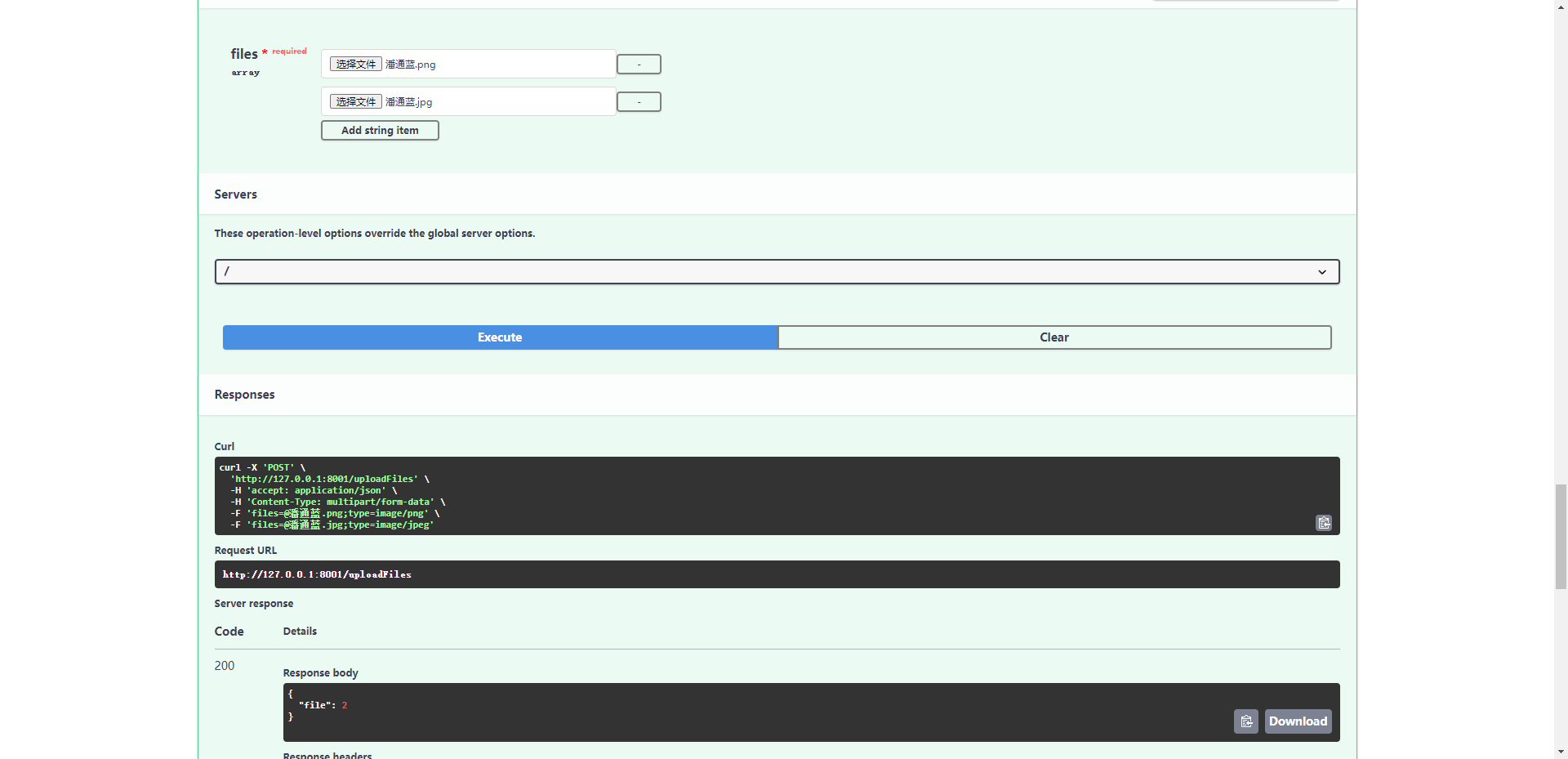
FastApi中的常见请求类型
FastApi中的常见请求类型 后端开发语言中,我钟情于node,高效的异步处理真是让我眼前一亮,同时,简单易懂的语法也让我非常倾心 但是但是,因为考虑要写一个深度学习算法的后端接口,所以不得不选用python作为…...

服务器,云、边缘计算概念简单理解
目录 服务器,云、边缘计算概念简单理解 一、服务器 二、云计算 三、边缘计算 服务器和云之间区别 性质 可用性 弹性扩展 管理和维护 成本 应用场景 服务器,云、边缘计算概念简单理解 一、服务器 概念简单理解: 服务器是计算机网络上最重要的设备之一,它在网络…...

【Linux系列2】Cmake安装记录
方法一 1. 查看当前cmake版本 [rootlocalhost ~]# cmake -version cmake version 2.8.12.22. 进行卸载 [rootlocalhost ~]# yum remove -y cmake3. 进行安装包的下载,也可以下载好安装包后传至相应的目录 [rootlocalhost ~]# mkdir /opt/cmake [rootlocalhost ~…...

从电磁炉到户外电源:拆解单相SVPWM如何让你的逆变器更安静、更高效
从电磁炉到户外电源:单相SVPWM如何实现静音与高效的双重突破当你深夜用电磁炉煮面时,是否曾被突然的蜂鸣声吓一跳?或是发现户外电源给设备充电时,散热风扇的噪音盖过了山林鸟鸣?这些常见问题背后,隐藏着一个…...

MAX78000移植Zephyr RTOS实战:从BSP创建到AI边缘设备开发
1. 项目概述与动机作为一名长期在嵌入式边缘AI和机器人领域摸爬滚打的开发者,我最近把目光投向了一块相当有潜力的板子:Maxim Integrated(现为ADI一部分)的MAX78000FTHR开发套件。这块板子的核心——MAX78000微控制器,…...

因果推断与机器学习融合:量化分析社会运动中镇压与抗议的动态关系
1. 项目概述:当数据科学遇见社会运动如果你研究过社会运动,尤其是那些看似突然爆发、席卷全国的抗议浪潮,你可能会被一个核心问题困扰:国家机器的镇压,究竟是浇灭火焰的冷水,还是火上浇油的催化剂ÿ…...

WarcraftHelper:让魔兽争霸3在现代电脑上完美运行的关键插件
WarcraftHelper:让魔兽争霸3在现代电脑上完美运行的关键插件 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为《魔兽争霸3》这…...

告别RaiDrive广告!用开源rclone+Alist,免费把阿里云盘/百度网盘变成电脑本地硬盘
开源方案实战:用rcloneAlist打造无广告的云盘本地化体验 每次打开RaiDrive时弹出的广告窗口是否让您感到困扰?商业软件的收费模式是否让您犹豫不决?今天,我们将彻底解决这些问题。通过开源工具Alist和rclone的组合,您不…...

从XAI到HXAI:构建以人为中心的可解释AI框架与实践
1. 项目概述:从“黑箱”到“白盒”,构建可信AI的演进之路在机器学习项目里摸爬滚打了十几年,我见过太多因为模型“说不清道不明”而引发的信任危机。一个在测试集上表现完美的信用评分模型,可能因为无法向风控专家解释“为什么拒绝…...

具身智能的发展对人类社会的影响有哪些?
具身智能对人类社会影响一、经济产业层面产业重构:催生机器人、智能制造、自动驾驶新产业,重塑生产链条效率跃升:替代重复繁重劳作,工厂、农业、物流产能大幅提升就业结构变化:低端体力岗位缩减,运维、研发…...

通过Taotoken用量看板清晰追踪各模型的Token消耗情况
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken用量看板清晰追踪各模型的Token消耗情况 对于依赖大模型API进行开发的个人或团队而言,成本控制与预算规划…...

如何永久保存微信聊天记录?WeChatMsg数据管理工具完全指南
如何永久保存微信聊天记录?WeChatMsg数据管理工具完全指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/W…...

如何用YOLOv5实现FPS游戏智能瞄准:完整实战指南
如何用YOLOv5实现FPS游戏智能瞄准:完整实战指南 【免费下载链接】FPSAutomaticAiming 基于yolov5的FPS游戏AI。 项目地址: https://gitcode.com/gh_mirrors/fp/FPSAutomaticAiming 在竞技射击游戏中,精准瞄准是决定胜负的关键因素,而F…...