14-52 剑和诗人26 - RAG 和 VectorDB 简介
检索增强生成 (RAG) 和 VectorDB 是自然语言处理 (NLP) 中的两个重要概念,它们正在突破 AI 系统所能实现的界限。
在这篇博文中,我将深入探讨 RAG,探索其工作原理、应用、优势和局限性。
我们还将研究 VectorDB,这是一种专用于向量存储的数据库,是许多 RAG 实现不可或缺的一部分。

最后,您将清楚地了解:
- RAG 是什么,它如何结合检索和生成,以及这种混合方法为何如此强大
- RAG 模型的实际应用,如问答、摘要和对话系统
- 使用 REALM 和 ORQA 等数据集训练高性能 RAG 模型的方法
- VectorDB,它如何高效存储向量,以及如何增强 RAG
- RAG 的当前创新和未来令人兴奋的研究领域
什么是检索增强生成 (RAG)?
检索增强生成指的是一种先进的自然语言处理技术,它结合了检索模型和生成模型。
检索模型是响应某些查询或上下文从数据集合中选择相关知识的系统。例如,返回与搜索查询最相关的网页的搜索引擎可视为简单检索模型。
相比之下,生成模型能够利用语言生成功能生成全新的文本。例如机器翻译系统或对话聊天机器人。
传统上,NLP 系统要么使用纯基于检索的方法,要么使用纯生成方法。RAG将这两种方法结合在一起。
RAG 背后的关键思想是,获取和调节相关背景知识可以显著提高下游 NLP 任务的生成模型性能。
例如,由 RAG 提供支持的对话系统可以首先检索与对话上下文相关的段落或文档。然后在响应生成过程中将这些检索到的段落提供给生成式 seq2seq 模型,从而生成更有知识性、更细致入微且更相关的响应。
RAG 范式使模型具有出色的检索能力,可以收集相关信息,并结合出色的自然语言生成能力,可以生成流畅、类似人类的文本。这种混合方法在从开放域问答到对话系统等任务上取得了最先进的成果。
在接下来的部分中,我们将详细探讨 RAG 模型的工作原理,以及 NLP 这一新兴子领域的创新应用、最新进展和有前景的未来研究方向。
RAG 模型如何工作?架构概述
检索增强生成模型的关键组成部分是:
- 检索系统:从知识源或数据库中提取相关段落或文档。可以是稀疏向量搜索、密集嵌入或全文搜索。
- 重新排序器:对检索到的段落进行重新排序。通常在查询/上下文和段落之间使用交叉注意力。提高相关性。
- 生成模型:Seq2seq 语言模型,使用交叉注意功能整合检索到的段落。生成最终输出。
以下是处理输入查询的典型高级 RAG 管道:
1. 输入查询
输入查询可以是搜索查询、问答问题、对话话语或其他文本。
2. 检索系统
检索系统从知识源中选择与查询相关的前 k 个段落或文档。这是通过语义密集向量搜索或 TF-IDF 等稀疏方法实现的。
3. 重新排序
可选的重新排序步骤会过滤并重新排序检索到的 k 个段落,以挑选与查询最相关的段落。通常使用交叉注意模块。
4. 融入生成模型
重新排序后的前 m 个段落与原始查询连接在一起。此组合表示被输入到生成式 seq2seq 模型中。
5. 生成输出
seq2seq 模型在解码输出文本时会关注检索到的段落,无论是答案、对话响应还是其他生成的文本。
这种外部知识的增强使得 RAG 模型比以前没有利用外部信息的检索机制的纯生成模型有了显着的提升。
现在让我们探索一些领先的 RAG 算法,例如 REALM、ORQA 和 RAG Token,它们以创新的方式实例化这种高级架构。
REALM:开创性的 RAG 算法
REALM 是RE检索增强语言模型 (RE Trieval Augmented Language M odel)的缩写,是开创性的 RAG 算法之一,证明了该方法在问答方面早期的有效性。
REALM 增强了作为核心生成模块的标准 T5 语言模型,使其能够以轻量、高效的方式整合从维基百科检索到的证据段落。
它引入了两项有影响力的架构创新:
1. 开放检索
开放检索是指从封闭领域、规模有限的知识源转向对海量语料库(如整个维基百科(超过 210 亿个单词))进行开放式检索。扩展到如此庞大、不断发展的知识源具有挑战性,但影响深远。
2. 后期互动
传统上,在诸如密集段落检索之类的先前工作中,检索到的证据段落会与输入问题预先连接起来,以创建单一的组合表示。
相比之下,REALM 引入了后期交互,其中输入问题和证据段落是独立编码的,无需先进行连接。联合交互仅在编码器交叉注意层内稍后发生。
这种更有效的方法可以避免早期的瓶颈,并且还可以灵活地为后续的注意层提供多少段落。
让我们来看看 REALM 架构的 4 个主要步骤:
1. 输入问题
自然语言问题,例如“亚历山大·弗莱明出生在哪里?”。
2. 检索相关段落
使用 BM25 进行稀疏向量索引检索,根据问题嵌入获取前 k 个维基百科段落。
3. 独立编码
问题和证据段落首先由 RoBERTa 分别编码,不进行连接。
4. 联合语境化
编码向量通过交叉注意层进行交互,产生最终的语境化表示,为输出文本生成提供动力。
这些架构创新使 REALM 在具有挑战性的 Natural Questions 基准上以 17 F1 点的优势超越了之前的开放检索问答 SOTA。这确立了 RAG 和 REALM 作为一个关键的新方向,并引发了一系列采用 RAG 范式的后续研究。接下来,我们将探索一些基于 REALM 的衍生作品。
ORQA:优化的 RAG 架构
ORQA 模型(优化检索问答)基于 REALM 的后期交互概念,通过优化的编码方案进一步推动了 RAG的问答功能。
ORQA 通过使用以下方式专门处理单独的文本编码:
- 针对问题表征进行优化的BERT 编码器
- REALM 编码器针对证据段落进行了优化
输入由各自的编码器并行编码,通过交叉注意融合,然后由 T5 模型解码为基于证据的答案跨度选择。
其他优化包括:
- 在检索器和编码器之间添加重新排序器,以提升最相关的段落
- 每段文本采用多向量表示,以捕捉不同的粒度
- 通过段落选择和跨度预测进行多任务微调
这使得问题和证据段落的编码效率和准确性显著提高。例如,在经过良好基准测试的 Natural Questions 数据集上,ORQA 获得了 88.1 的全新最佳 F1 分数。
接下来,我们将探讨如何将 RAG 改编成采用代币级方法的统一框架。
RAG Token:统一文本和知识检索
RAG Token 代表了 RAG 模型的另一种演变,将其重新表述为单个序列到序列任务。
它将检索内容框定为特殊标记,而不是单独的段落。具体来说:
- 检索器模块输出一组知识元组(主题、关系、对象)
- 每个元组都作为
[RAGTOKEN]标记嵌入到输入序列中 - 最终输入序列送入 T5 编码器-解码器模型
因此,RAG Token 不会检索完整段落,而是将外部知识提炼为简洁的主题-关系-对象三元组。这样就可以扩展到庞大的知识图谱作为检索源。
例如,考虑输入问题:“第一辆自行车是什么时候发明的?”
检索器可能输出知识元组:
(Bicycle,,)invented_on_date1817
嵌入到序列中如下:
When was the first [RAGTOKEN] Bicycle [/RAGTOKEN] invented [RAGTOKEN] invented_on_date 1817 [/RAGTOKEN] ?
这种基于标记的方法允许对文本语料库检索和知识进行联合训练
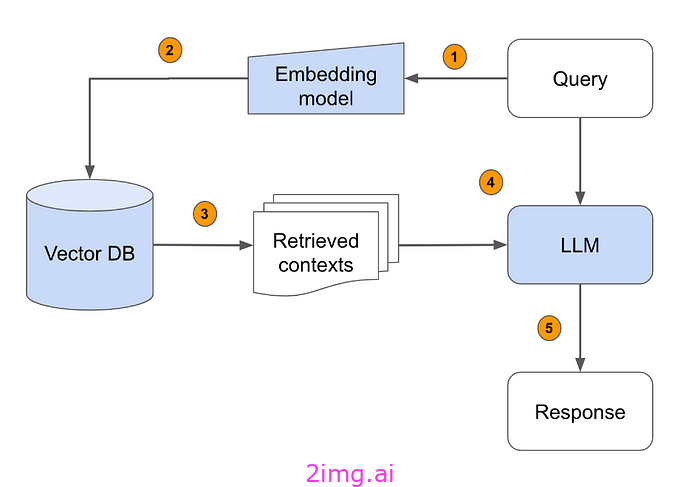
为什么高效的向量存储对 RAG 很重要?
支持检索增强生成模型功能的一个关键方面是矢量数据库,它存储嵌入以便在初始检索阶段进行快速语义搜索。
为了使 RAG 模型扩展到包含数十亿文本段落的庞大语料库,有效地索引和查询向量表示至关重要。
这正是高度优化的向量数据库(如 Weaviate、Chroma、FAISS、Vespa 或 Pinecone)发挥作用的地方。它们允许存储数十亿个文本或文档向量,以进行低延迟相似性搜索。
具体来说,这些矢量数据库擅长于:
高效索引:利用倒排索引、聚类树、量化算法等先进数据结构来压缩向量空间并实现 GPU 加速。
近似最近邻搜索:使用散列、HNSW 图或乘积量化来快速返回近似最近匹配,而不是详尽而昂贵的向量计算。
云和基础设施优化:利用跨区域的分布式计算集群、负载平衡、缓存热向量和复杂的查询路由算法。如果没有这些大规模向量数据库作为基础,RAG 模型将因检索速度慢且成本高昂而无法实现。快速向量查询允许段落编码器和解码器成为性能瓶颈,而不是搜索延迟本身。
接下来,我们将深入研究支持最先进 RAG 实现的流行矢量数据库。
VectorDB:高性能向量相似性搜索
VectorDB 是一个超快向量数据库的示例,专为支持 RAG 模型 (Chen et al. 2021) 等神经搜索应用程序而构建。
它专注于向量存储和近似最近邻 (ANN) 检索,没有任何不必要的花哨功能。这种精益的范围使其能够实现无与伦比的查询速度和可扩展性。
VectorDB提供的主要功能包括:
向量存储:显然,主要目的是专门针对密集向量而非更一般的变量进行高效存储。数据类型针对浮点进行了优化。
GPU 加速:利用 GPU 核心进行大规模并行处理,并利用 Faiss 等库执行超快速索引和搜索计算。
分布式架构:跨多台机器和服务器进行扩展,以划分向量空间,同时仍允许统一访问。即使有数万亿个向量,也能保持效率。
云原生:完全托管的云服务,消除了服务器配置和网络复杂性。根据查询负载动态自动扩展。
REST API:简单的 API 端点,如vectorDB.search可以vectorDB.insert从任何应用程序执行向量操作,而无需集成数据库客户端。
最新算法:不断试验并集成最先进的 ANN 算法(如 HNSW、IVF、OPQ),以最大限度地提高准确性和速度。这些功能组合在一个专为向量相似性搜索量身定制的高度精简的软件包中,可以大规模扩展以支持包含多达数万亿个嵌入的下一代 RAG 模型。
现在让我们了解一下利用 VectorDB 实现尖端 RAG 的具体架构模式。
示例-松果:专为神经信息检索而构建
Pinecone 是另一个领先的矢量数据库,它从头开始设计,旨在实现超快速矢量相似性搜索,为神经搜索管道提供支持。它具有许多之前介绍过的相同功能,例如高效的矢量存储、GPU 加速、分布式架构和简单的 API。
此外,Pinecone 还推出了一些独特的创新:
向量存储架构: Pinecone 使用列存储与行存储相结合的混合存储模型。列存储保存向量以实现最大压缩和编码效率。行存储包含元数据。这种双重架构优化可使插入和查询速度提高几个数量级。
可重新配置的指标:支持在不同的相似性指标(如余弦、L2 和点积)之间切换。这提供了灵活性,可以动态更改评分函数,而无需重新索引或更改模型。对于实验很有用。
让我们分析一下利用 Pinecone 优势的示例工作流程:
1. 标题和摘要向量
将研究论文的标题和摘要文本编码为密集向量。这允许对关键概念进行语义搜索。
2. 多矢量场
将标题和摘要的单独向量索引到不同的向量字段中,以允许细粒度查询。
3. 查询标题向量
根据标题向量相似度搜索,显示与查询最相关的研究论文。
我们可以看到,像 Pinecone 这样的专用向量存储能够创建复杂的 RAG 管道,从而能够利用最先进的神经编码与超高效的 ANN 搜索。
采用 VectorDB 的高级 RAG 架构
以下是一个高级 RAG 管道示例,它利用 VectorDB 的优势实现低延迟、超可扩展向量搜索:
1. 嵌入文本
第一步是为所有我们希望检索的文本生成向量嵌入。这包括维基百科等语料库、新闻档案、期刊论文或任何文档集合。强大的语义编码器(如 SBERT(句子 BERT))非常适合创建高质量的文档和段落向量。
2. 将向量插入VectorDB Cloud
所有这些数十亿个编码向量都被高效地插入到托管的 VectorDB 云中。这为覆盖整个向量空间的统一索引提供了支持。
3. 输入问题
当输入问题到达时,它会通过 SBERT 进行编码以创建密集的向量表示。
例如:“胰岛素是什么时候发现的?” -> [0.73, 1.19, 0.42, …]
4.从 VectorDB 中检索相似向量
该问题向量被输入到 VectorDB 的vectorDB.searchAPI 调用中,以获取前 k 个最相似的段落向量。
得益于 ANN 近似和 GPU 加速,结果可在几毫秒内返回。
5. 解读段落
然后可以访问和解码与检索到的向量相对应的段落文本。最相关的段落将成为下游 RAG 任务的输入证据。
该架构提供了一个高度可扩展且低延迟的语义搜索系统,为解决开放域问答等任务的下一代 RAG 模型提供支持。接下来,我们将分析 VectorDB 为最先进的 RAG 实现提供支持的具体性能指标和基准。
VectorDB 性能基准
VectorDB 提供卓越的性能,可以轻松扩展以支持领先的 RAG 模型。以下是标准生产部署的一些基准:
索引速度
- 每小时插入 4.8 亿个以上载体
- 1 天内索引了 120 多亿个向量
- 实现对巨型语料库的迭代再训练
查询延迟
- 典型搜索时间为 10-25 毫秒
- 第 99 百分位延迟约为 50 毫秒
- 最大延迟为 100 毫秒
查询吞吐量
- 每台机器每秒 62,000 次搜索
- 与集群大小线性扩展
- 通过自动扩展轻松处理峰值负载
索引容量
- 每个集群 5 万亿向量容量
- 多集群设置中的数十万亿
- 索引大小没有实际限制
簇的大小
- 每个集群最多 60 台服务器
- 多区域功能
- 无限的水平可扩展性
这些令人印象深刻的数字使得构建复杂的 RAG 模型成为可能,该模型利用包含数万亿个文本嵌入的存储库进行训练和推理。VectorDB 等定制向量存储提供的规模和速度组合为基于 RAG 的应用程序开辟了新的可能性。
接下来我们来分析一些基于矢量数据库的实际RAG用例。
高效向量搜索助力 RAG 用例
专用数据库提供的可扩展低延迟向量查询为 RAG 模型开辟了许多实际用例,而这些用例以前如果没有这个基础就是不可能的。
开放领域问答
通过索引维基百科、新闻、市场数据提要和科学论文实现实时 QA。
对话系统
对话机器人通过索引对话日志提供知识性、情境化的响应。
文本生成
创意写作工具,可以吸收小说/故事并根据用户提示帮助生成详细内容。
搜索引擎
对语料库元数据进行语义搜索,返回智能汇总结果。
智能内容推荐
建议与用户行为和偏好相匹配的相关内容,并附带解释。
自动助理
帮助台机器人通过识别相关手册和文档为复杂的技术产品提供故障排除。
上下文广告
智能广告活动将广告创意和登录页面与详细的用户网页浏览历史记录和会话上下文相匹配。
这些展示了向量检索为解决消费者和企业应用的 RAG 模型提供的一小部分可能性。
在接下来的部分中,我们将分析 RAG 系统的优势和劣势、当前的创新以及这个快速发展的领域未来研究的有希望的方向。
RAG 模型的优势
检索增强生成模型与以前的纯神经语言生成方法相比有几个引人注目的优势:
1. 准确的事实回应
通过根据检索到的证据段落来调节文本生成,RAG 模型可以产生具有更高事实正确性和更少幻觉的输出。
2. 可扩展至大型存储库
像 VectorDB 这样的专用存储允许对包含数万亿个示例的语料库进行 RAG 训练/推理,这是以前不可能实现的。
3.速度和效率
与早期的融合模型相比,最新 RAG 网络中的架构优化可以实现更快的索引、检索和解码。
4.适用于许多领域
高精度和可扩展性开辟了许多有前景的领域,例如开放式 QA、企业搜索、上下文推荐。
然而,RAG 方法仍然存在一些弱点和需要改进的地方。接下来我们讨论主要挑战。
当前 RAG 系统的局限性
虽然代表了当前最先进的技术,但现代 RAG 算法仍然存在一些明显的局限性:
1. 检索回忆
初始检索模块在检索隐藏在大量未标记语料库中的某些相关内容时,通常会受到回忆能力限制的影响。
2.缺乏推理能力
大多数 RAG 技术都严重依赖数据,缺乏逻辑和符号推理。因此,它们很难解决复杂的构图问题。
3. 难以处理歧义
检索步骤通常只假设一个有效答案或上下文。因此,当今的 RAG 模型无法很好地处理模棱两可、主观或细微的响应。
4. 大型训练集的必要性
尽管通过自我监督利用未标记的文本有所帮助,但大多数 RAG 方法仍然需要大量人工标记的数据集,而这些数据集在某些小众领域可能很少。
全球各地的研究人员都在积极探索解决这些开放性挑战的方法。接下来我们分析一些有前景的创新方向。
RAG 的最新创新
最近,对 RAG 架构的研究出现了爆炸式增长,因为它代表了 NLP 的关键进步。以下是一些表明快速进步的前沿创新:
多步推理
链接多个检索和生成循环以模拟复杂推理 (Asai 等人,2022)。每个循环都会重新表述上下文。
双编码器
使用一个针对问题进行优化的编码器,另一个针对证据段落进行优化的编码器可以提高性能(Lee 等人,2021 年)。
离散段落表示
检索完整的离散段落而不是提炼的三元组可以保留原始文本,从而提高准确性(Izacard 等人,2021 年)。
信心评分
一些 RAG 网络现在生成校准的置信度分数来估计生成文本的确定性(Thayaparan 等人,2022 年)。
数据增强
自动扰动示例和挖掘难反例可提高模型鲁棒性(Lewis 等人,2022 年)。
这些创新正在以惊人的速度推动能力的发展。在下一节中,我们将推测长期发展中具有影响力的方向。
RAG 的未来展望与研究
展望未来 5 年以上的前景,以下是 RAG 算法持续研究的一些特别有前景的方向:
与知识库更紧密的集成
更多地利用精选的知识图谱和本体来提高推理能力。
多元化检索证据
不要仅仅检索最匹配的内容;有意获取不同的冲突段落来模拟辩论。
对话反馈模型
用户循环允许澄清模棱两可的问题以改善检索和基础。
低资源领域适应
使技术更容易转移到缺乏大型训练语料库的专业垂直领域。
可解释性和可阐释性
对产生输出的表面证据和解释,以提高透明度。
说到 RAG 在语言 AI 转型方面的潜力,我们确实才刚刚起步。随着计算资源、模型技术和向量搜索能力方面的障碍不断突破,未来十年必将是创新加速的十年。

总结和关键要点
在这次广泛深入的研究中,我们探索了检索增强生成的新兴世界,以及它如何通过将神经搜索与条件文本生成相结合来彻底改变自然语言处理。
主要亮点包括:
- RAG结合了检索器和生成器的优势,实现了巨大的知识规模和准确、流畅的输出。
- REALM率先将检索到的证据附加到编码器-解码器模型中,在 QA 上实现了 SOTA。
- ORQA等后续工作进一步优化了架构细节,以提高速度和准确性。
- VectorDB提供专用的矢量搜索云,支持大规模超低延迟段落检索,从而实现高级 RAG 实施。
- 实际用例包括开放域 QA 到智能推荐和上下文广告。
- 虽然已经取得了巨大的进展,但在多步推理、稳健性和低资源领域适应方面仍然有很大的创新前景。
RAG 等令人难以置信的模型技术与矢量相似性搜索的专用基础设施相结合,解锁了改变游戏规则的全新 NLP 应用。能够在这个变革领域的前沿工作真是令人兴奋!
相关文章:
14-52 剑和诗人26 - RAG 和 VectorDB 简介
检索增强生成 (RAG) 和 VectorDB 是自然语言处理 (NLP) 中的两个重要概念,它们正在突破 AI 系统所能实现的界限。 在这篇博文中,我将深入探讨 RAG,探索其工作原理、应用、优势和局限性。 我们还将研究 VectorDB,这是一种专用于向…...

如果MySQL出现 “Too many connections“ 错误,该如何解决?
当你想要连接MySQL时出现"Too many connections" 报错的情况下,该如何解决才能如愿以偿呢?都是哥们儿,就教你两招吧! 1.不想重启数据库的情况下 你可以尝试采取以下方法来解决: 增加连接数限制:…...

论文阅读:Rethinking Interpretability in the Era of Large Language Models
Rethinking Interpretability in the Era of Large Language Models 《Rethinking Interpretability in the Era of Large Language Models》由Chandan Singh、Jeevana Priya Inala、Michel Galley、Rich Caruana和Jianfeng Gao撰写,探讨了在大型语言模型ÿ…...

C++/Qt 信号槽机制详解
文章目录 C++/Qt 信号槽机制详解一、信号和槽的基本概念1. 信号2. 槽3. 连接二、信号和槽的基本使用1. 信号和槽的声明和定义2. 连接信号和槽三、信号和槽的工作原理1. MOC(Meta-Object Compiler)2. 事件循环3. 连接类型四、信号和槽的高级应用1. 自定义信号和槽2. Lambda 表…...

duplicate key value violates unique constraint
duplicate key value violates unique constraint 遇到的问题 你在尝试向数据库表 goods 插入新记录时,收到了 duplicate key value violates unique constraint 的错误。尽管你确认数据库中没有与尝试插入的 id 相同的记录,但错误依旧存在。进一步的调…...

YOLOv10改进 | EIoU、SIoU、WIoU、DIoU、FocusIoU等二十余种损失函数
一、本文介绍 这篇文章介绍了YOLOv10的重大改进,特别是在损失函数方面的创新。它不仅包括了多种IoU损失函数的改进和变体,如SIoU、WIoU、GIoU、DIoU、EIOU、CIoU,还融合了“Focus”思想,创造了一系列新的损失函数。这些组合形式的…...

docker nginx mysql redis
启动没有数据卷的nginx docker run -d -p 86:80 --name my-nginx nginx把/etc/nginx中的配置复制到宿主机 docker cp my-nginx:/etc/nginx /home/nginxlkl把/html 中的文件复制到宿主机 docker cp my-nginx:/etc/nginx /home/nginxlkl删除当前镜像 docker rm -f my-nginx重新起…...

Linux系统(CentOS)安装iptables防火墙
1,先检查是否安装了iptables 检查安装文件-执行命令:rpm -qa|grep iptables 检查安装文件-执行命令:service iptables status 2,如果安装了就卸装(iptables-1.4.21-35.el7.x86_64 是上面命令查出来的版本) 执行命令:…...

华为的服务器创新之路
华为作为全球领先的信息与通信技术解决方案供应商,其在服务器领域的创新方法不仅推动了企业自身的发展,也为整个行业的进步做出了重要贡献。以下是华为在服务器领域所采取的一些关键创新方法: 芯片级的自主创新 华为通过自主研发的“鲲鹏”处…...

对比service now和salesforce
目录 1. 核心功能和用途 2. 市场定位 3. 平台和扩展性 4. 用户界面和用户体验 5. 价格 总结 ServiceNow和Salesforce是两款广泛使用的企业软件平台,但它们的侧重点和用途有所不同。以下是对它们的详细比较: 1. 核心功能和用途 ServiceNow IT服务…...

树状数组
树状数组 树状数组的核心思想:分治。将数组以二叉树的形式进行维护区间之和。 设 a a a为原数组, t r e e tree tree为树状数组。 t r e e tree tree数组用于存储树上该结点下严格直连的子节点之和(例: t [ 1 ] a [ 1 ] , t [ 2 ] t [ 1 …...

【北京迅为】《i.MX8MM嵌入式Linux开发指南》-第一篇 嵌入式Linux入门篇-
i.MX8MM处理器采用了先进的14LPCFinFET工艺,提供更快的速度和更高的电源效率;四核Cortex-A53,单核Cortex-M4,多达五个内核 ,主频高达1.8GHz,2G DDR4内存、8G EMMC存储。千兆工业级以太网、MIPI-DSI、USB HOST、WIFI/BT…...

ansible常见问题配置好了密码还是报错
| FAILED! > { “msg”: “Using a SSH password instead of a key is not possible because Host Key checking is enabled and sshpass does not support this. Please add this host’s fingerprint to your known_hosts file to manage this host.” } 怎么解决…...
python-课程满意度计算(赛氪OJ)
[题目描述] 某个班主任对学生们学习的的课程做了一个满意度调查,一共在班级内抽取了 N 个同学,对本学期的 M 种课程进行满意度调查。他想知道,有多少门课是被所有调查到的同学都喜欢的。输入格式: 第一行输入两个整数 N , M 。 接…...

6、Redis系统-数据结构-05-整数
五、整数集合(Intset) 整数集合是 Redis 中 Set 对象的底层实现之一。当一个 Set 对象只包含整数值元素,并且元素数量不大时,就会使用整数集合这个数据结构作为底层实现。整数集合通过紧凑的内存布局和升级机制,实现了…...

STM32学习历程(day5)
EXTI外部中断 中断 中断就是在主程序运行过程中 出现了特定的中断触发条件(中断源),CPU会暂停当前的程序,去处理中断程序 处理完会返回被暂停的位置 继续运行原来的程序。 中断优先级 当有多个中断源同时申请中断时 CPU会根据…...

格蠹汇编阅读理解
一、调试工具使用方式 WinDbg常用命令: 执行 lm 命令,可以看到进程中有几个模块。执行~命令列一下线程。用!heap 命令列一下堆。执行!address 命令可以列出用户态空间中的所有区域。搜索吧!就从当前进程用户态空间的较低地址开始搜…...
的奥秘)
深入探索:scikit-learn中递归特征消除(RFE)的奥秘
深入探索:scikit-learn中递归特征消除(RFE)的奥秘 在机器学习的世界里,特征选择是一项至关重要的任务。它不仅能够提高模型的性能,还能减少模型的复杂度,避免过拟合。scikit-learn,作为Python中一个广泛使用的机器学习…...

240708_昇思学习打卡-Day20-MindNLP ChatGLM-6B StreamChat
240708_昇思学习打卡-Day20-MindNLP ChatGLM-6B StreamChat 基于MindNLP和ChatGLM-6B实现一个聊天应用,本文进行简单记录。 环境配置 %%capture captured_output # 实验环境已经预装了mindspore2.2.14,如需更换mindspore版本,可更改下面mi…...

lua入门(2) - 数据类型
前言 本文参考自: Lua 数据类型 | 菜鸟教程 (runoob.com) 希望详细了解的小伙伴还请查看上方链接: 八个基本类型 type - 函数查看数据类型: 测试程序: print(type("Hello world")) --> string print(type(10.4*3)) --> number print(t…...

为什么92%的Sora 2初学者卡在第4步?——帧一致性崩塌诊断工具包+时间轴锚点校准法
更多请点击: https://kaifayun.com 第一章:Sora 2视频生成的核心原理与环境准备 Sora 2并非OpenAI官方发布的模型,而是社区基于Sora技术理念构建的开源复现与增强框架,其核心依托于时空联合建模的扩散变换器(Spacetim…...
)
从测速到配置:一套完整的cFosSpeed网络加速保姆级教程(适用于小白)
从零开始掌握cFosSpeed:网络加速全流程实战指南对于经常进行在线游戏、视频会议或大文件传输的用户来说,网络延迟和带宽利用率低下往往是影响体验的关键痛点。cFosSpeed作为一款专业的网络流量优化工具,能够显著改善这些问题,但许…...

IPD的势、道、法、术、器
目录 简介 一、势:为什么 IPD 是必然选择? 二、道:IPD 的底层哲学 三、法与术:从战略到执行的具体路径 四、器:让流程真正落地的工具与组织 不是每家公司都需要全套 IPD,但每家公司都需要 IPD 思维 简…...

百考通智能任务书:贴合你的选题,拒绝空话假大空
毕业设计任务书是高校教学管理中的关键环节,它不仅标志着研究工作的正式启动,更是后续开题、实施、论文撰写和答辩全过程的行动依据。然而,许多学生在撰写时常常因不熟悉本专业写作规范、技术表达能力有限,或缺乏权威模板参考而陷…...

浏览器 Profile 环境排查:Cookie、LocalStorage、网络出口与自动化任务配置清单
一、为什么浏览器环境经常“今天能用,明天失效”很多团队遇到登录状态丢失、页面配置异常、自动化任务失败时,会先怀疑网络、脚本或系统本身。但在实际项目里,问题经常不是单点故障,而是浏览器环境缺少稳定管理:对象常…...

6款高效降AI率工具 改写实力出众
写论文时反复检测出的AI痕迹总让你提心吊胆?别担心,这里整理了6款真正好用的论文降AI率工具,堪称应对AI生成特征的“得力助手”。它们能有效识别并消除AI生成的痕迹,改写能力出众,帮你快速降低查重率,顺利通…...

全链路压测实战:双十一级别的流量,我是这样扛住的
作为一名在质量保障领域摸爬滚打多年的测试工程师,我深知传统的单接口压测在如今分布式架构下的无力感。当业务流量达到双十一这种脉冲式、高并发的级别时,任何一个非核心链路上的“短板”都可能引发系统性的雪崩。全链路压测不再是选择题,而…...

MAX78000移植Zephyr RTOS实战:从BSP创建到AI边缘设备开发
1. 项目概述与动机作为一名长期在嵌入式边缘AI和机器人领域摸爬滚打的开发者,我最近把目光投向了一块相当有潜力的板子:Maxim Integrated(现为ADI一部分)的MAX78000FTHR开发套件。这块板子的核心——MAX78000微控制器,…...

写论文的神助攻!好用的AI写作辅助软件,逻辑清晰质量高
作为一名刚完成毕业论文的过来人,我太懂写论文的痛苦了 —— 选题迷茫、文献浩如烟海、框架混乱、逻辑不清、反复修改、查重降重反复折腾... 直到我发现了这套 AI 写作工具组合,简直是论文写作的 "开挂神器",效率直接拉满ÿ…...

武汉国电华美16875kVA串联谐振试验装置,这手活儿细
在超高压变电站和长距离电缆的现场,交流耐压试验是检验设备绝缘的“最后一关”。这位老师傅经手过不少大工程,他说,面对GIS、大型变压器这些“大块头”电容性试品,能不能顺利“过关”,往往就看串联谐振装置顶不顶得住。…...