《昇思25天学习打卡营第14天|计算机视觉-ShuffleNet图像分类》
FCN图像语义分割&ResNet50迁移学习&ResNet50图像分类
当前案例不支持在GPU设备上静态图模式运行,其他模式运行皆支持。
ShuffleNet网络介绍
ShuffleNetV1是旷视科技提出的一种计算高效的CNN模型,和MobileNet, SqueezeNet等一样主要应用在移动端,所以模型的设计目标就是利用有限的计算资源来达到最好的模型精度。ShuffleNetV1的设计核心是引入了两种操作:Pointwise Group Convolution和Channel Shuffle,这在保持精度的同时大大降低了模型的计算量。因此,ShuffleNetV1和MobileNet类似,都是通过设计更高效的网络结构来实现模型的压缩和加速。
了解ShuffleNet更多详细内容,详见论文ShuffleNet。
如下图所示,ShuffleNet在保持不低的准确率的前提下,将参数量几乎降低到了最小,因此其运算速度较快,单位参数量对模型准确率的贡献非常高。

图片来源:Bianco S, Cadene R, Celona L, et al. Benchmark analysis of representative deep neural network architectures[J]. IEEE access, 2018, 6: 64270-64277.
模型架构
ShuffleNet最显著的特点在于对不同通道进行重排来解决Group Convolution带来的弊端。通过对ResNet的Bottleneck单元进行改进,在较小的计算量的情况下达到了较高的准确率。
Pointwise Group Convolution
Group Convolution(分组卷积)原理如下图所示,相比于普通的卷积操作,分组卷积的情况下,每一组的卷积核大小为in_channels/g*k*k,一共有g组,所有组共有(in_channels/g*k*k)*out_channels个参数,是正常卷积参数的1/g。分组卷积中,每个卷积核只处理输入特征图的一部分通道,其优点在于参数量会有所降低,但输出通道数仍等于卷积核的数量。

图片来源:Huang G, Liu S, Van der Maaten L, et al. Condensenet: An efficient densenet using learned group convolutions[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 2752-2761.
Depthwise Convolution(深度可分离卷积)将组数g分为和输入通道相等的in_channels,然后对每一个in_channels做卷积操作,每个卷积核只处理一个通道,记卷积核大小为1*k*k,则卷积核参数量为:in_channels*k*k,得到的feature maps通道数与输入通道数相等;
Pointwise Group Convolution(逐点分组卷积)在分组卷积的基础上,令每一组的卷积核大小为 1 × 1 1\times 1 1×1,卷积核参数量为(in_channels/g*1*1)*out_channels。
from mindspore import nn
import mindspore.ops as ops
from mindspore import Tensorclass GroupConv(nn.Cell):def __init__(self, in_channels, out_channels, kernel_size,stride, pad_mode="pad", pad=0, groups=1, has_bias=False):super(GroupConv, self).__init__()self.groups = groupsself.convs = nn.CellList()for _ in range(groups):self.convs.append(nn.Conv2d(in_channels // groups, out_channels // groups,kernel_size=kernel_size, stride=stride, has_bias=has_bias,padding=pad, pad_mode=pad_mode, group=1, weight_init='xavier_uniform'))def construct(self, x):features = ops.split(x, split_size_or_sections=int(len(x[0]) // self.groups), axis=1)outputs = ()for i in range(self.groups):outputs = outputs + (self.convs[i](features[i].astype("float32")),)out = ops.cat(outputs, axis=1)return out
Channel Shuffle
Group Convolution的弊端在于不同组别的通道无法进行信息交流,堆积GConv层后一个问题是不同组之间的特征图是不通信的,这就好像分成了g个互不相干的道路,每一个人各走各的,这可能会降低网络的特征提取能力。这也是Xception,MobileNet等网络采用密集的1x1卷积(Dense Pointwise Convolution)的原因。
为了解决不同组别通道“近亲繁殖”的问题,ShuffleNet优化了大量密集的1x1卷积(在使用的情况下计算量占用率达到了惊人的93.4%),引入Channel Shuffle机制(通道重排)。这项操作直观上表现为将不同分组通道均匀分散重组,使网络在下一层能处理不同组别通道的信息。
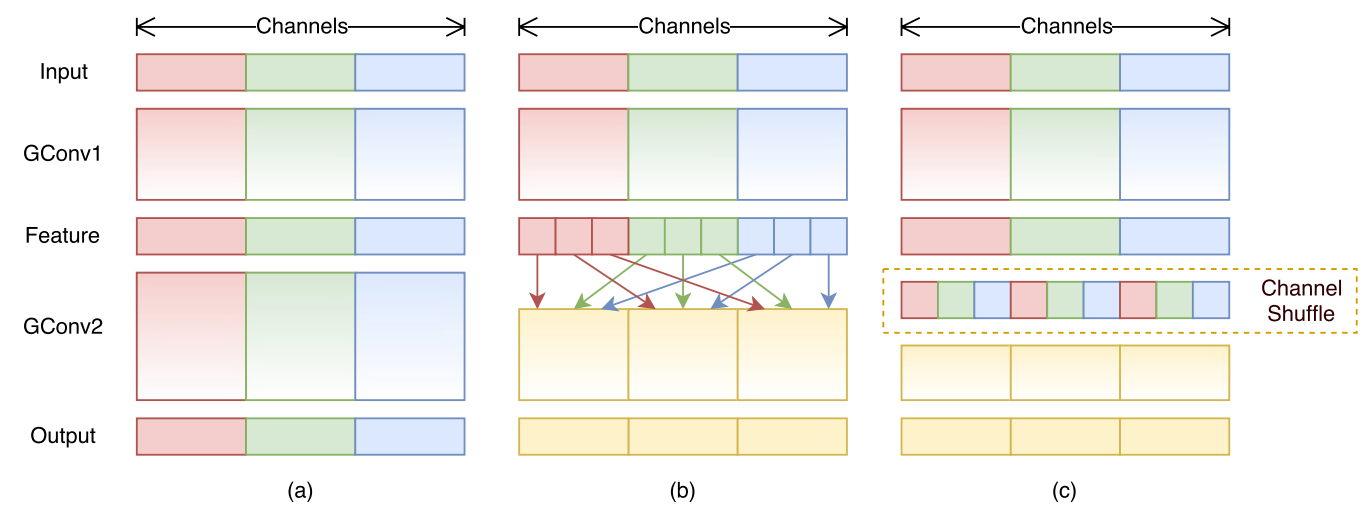
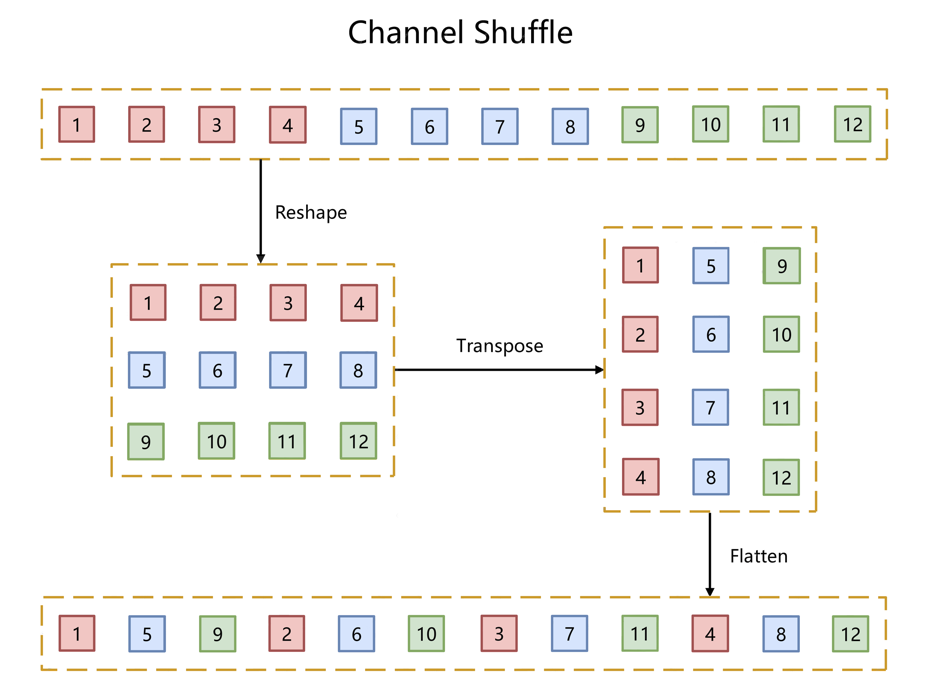
如下图所示,对于g组,每组有n个通道的特征图,首先reshape成g行n列的矩阵,再将矩阵转置成n行g列,最后进行flatten操作,得到新的排列。这些操作都是可微分可导的且计算简单,在解决了信息交互的同时符合了ShuffleNet轻量级网络设计的轻量特征。
为了阅读方便,将Channel Shuffle的代码实现放在下方ShuffleNet模块的代码中。
ShuffleNet模块
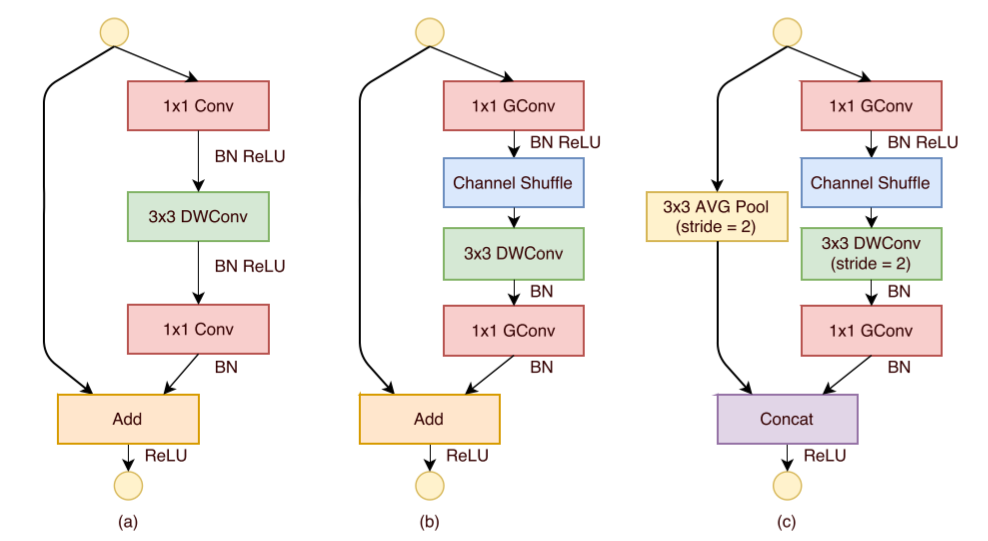
如下图所示,ShuffleNet对ResNet中的Bottleneck结构进行由(a)到(b), ©的更改:
-
将开始和最后的 1 × 1 1\times 1 1×1卷积模块(降维、升维)改成Point Wise Group Convolution;
-
为了进行不同通道的信息交流,再降维之后进行Channel Shuffle;
-
降采样模块中, 3 × 3 3 \times 3 3×3 Depth Wise Convolution的步长设置为2,长宽降为原来的一般,因此shortcut中采用步长为2的 3 × 3 3\times 3 3×3平均池化,并把相加改成拼接。
class ShuffleV1Block(nn.Cell):def __init__(self, inp, oup, group, first_group, mid_channels, ksize, stride):super(ShuffleV1Block, self).__init__()self.stride = stridepad = ksize // 2self.group = groupif stride == 2:outputs = oup - inpelse:outputs = oupself.relu = nn.ReLU()branch_main_1 = [GroupConv(in_channels=inp, out_channels=mid_channels,kernel_size=1, stride=1, pad_mode="pad", pad=0,groups=1 if first_group else group),nn.BatchNorm2d(mid_channels),nn.ReLU(),]branch_main_2 = [nn.Conv2d(mid_channels, mid_channels, kernel_size=ksize, stride=stride,pad_mode='pad', padding=pad, group=mid_channels,weight_init='xavier_uniform', has_bias=False),nn.BatchNorm2d(mid_channels),GroupConv(in_channels=mid_channels, out_channels=outputs,kernel_size=1, stride=1, pad_mode="pad", pad=0,groups=group),nn.BatchNorm2d(outputs),]self.branch_main_1 = nn.SequentialCell(branch_main_1)self.branch_main_2 = nn.SequentialCell(branch_main_2)if stride == 2:self.branch_proj = nn.AvgPool2d(kernel_size=3, stride=2, pad_mode='same')def construct(self, old_x):left = old_xright = old_xout = old_xright = self.branch_main_1(right)if self.group > 1:right = self.channel_shuffle(right)right = self.branch_main_2(right)if self.stride == 1:out = self.relu(left + right)elif self.stride == 2:left = self.branch_proj(left)out = ops.cat((left, right), 1)out = self.relu(out)return outdef channel_shuffle(self, x):batchsize, num_channels, height, width = ops.shape(x)group_channels = num_channels // self.groupx = ops.reshape(x, (batchsize, group_channels, self.group, height, width))x = ops.transpose(x, (0, 2, 1, 3, 4))x = ops.reshape(x, (batchsize, num_channels, height, width))return x
构建ShuffleNet网络
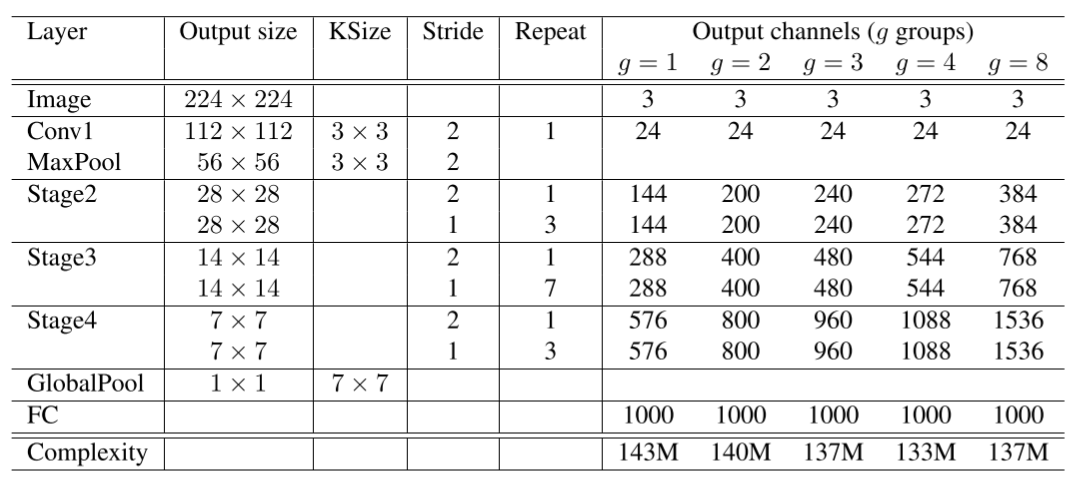
ShuffleNet网络结构如下图所示,以输入图像 224 × 224 224 \times 224 224×224,组数3(g = 3)为例,首先通过数量24,卷积核大小为 3 × 3 3 \times 3 3×3,stride为2的卷积层,输出特征图大小为 112 × 112 112 \times 112 112×112,channel为24;然后通过stride为2的最大池化层,输出特征图大小为 56 × 56 56 \times 56 56×56,channel数不变;再堆叠3个ShuffleNet模块(Stage2, Stage3, Stage4),三个模块分别重复4次、8次、4次,其中每个模块开始先经过一次下采样模块(上图©),使特征图长宽减半,channel翻倍(Stage2的下采样模块除外,将channel数从24变为240);随后经过全局平均池化,输出大小为 1 × 1 × 960 1 \times 1 \times 960 1×1×960,再经过全连接层和softmax,得到分类概率。
class ShuffleNetV1(nn.Cell):def __init__(self, n_class=1000, model_size='2.0x', group=3):super(ShuffleNetV1, self).__init__()print('model size is ', model_size)self.stage_repeats = [4, 8, 4]self.model_size = model_sizeif group == 3:if model_size == '0.5x':self.stage_out_channels = [-1, 12, 120, 240, 480]elif model_size == '1.0x':self.stage_out_channels = [-1, 24, 240, 480, 960]elif model_size == '1.5x':self.stage_out_channels = [-1, 24, 360, 720, 1440]elif model_size == '2.0x':self.stage_out_channels = [-1, 48, 480, 960, 1920]else:raise NotImplementedErrorelif group == 8:if model_size == '0.5x':self.stage_out_channels = [-1, 16, 192, 384, 768]elif model_size == '1.0x':self.stage_out_channels = [-1, 24, 384, 768, 1536]elif model_size == '1.5x':self.stage_out_channels = [-1, 24, 576, 1152, 2304]elif model_size == '2.0x':self.stage_out_channels = [-1, 48, 768, 1536, 3072]else:raise NotImplementedErrorinput_channel = self.stage_out_channels[1]self.first_conv = nn.SequentialCell(nn.Conv2d(3, input_channel, 3, 2, 'pad', 1, weight_init='xavier_uniform', has_bias=False),nn.BatchNorm2d(input_channel),nn.ReLU(),)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, pad_mode='same')features = []for idxstage in range(len(self.stage_repeats)):numrepeat = self.stage_repeats[idxstage]output_channel = self.stage_out_channels[idxstage + 2]for i in range(numrepeat):stride = 2 if i == 0 else 1first_group = idxstage == 0 and i == 0features.append(ShuffleV1Block(input_channel, output_channel,group=group, first_group=first_group,mid_channels=output_channel // 4, ksize=3, stride=stride))input_channel = output_channelself.features = nn.SequentialCell(features)self.globalpool = nn.AvgPool2d(7)self.classifier = nn.Dense(self.stage_out_channels[-1], n_class)def construct(self, x):x = self.first_conv(x)x = self.maxpool(x)x = self.features(x)x = self.globalpool(x)x = ops.reshape(x, (-1, self.stage_out_channels[-1]))x = self.classifier(x)return x
模型训练和评估
采用CIFAR-10数据集对ShuffleNet进行预训练。
训练集准备与加载
采用CIFAR-10数据集对ShuffleNet进行预训练。CIFAR-10共有60000张32*32的彩色图像,均匀地分为10个类别,其中50000张图片作为训练集,10000图片作为测试集。如下示例使用mindspore.dataset.Cifar10Dataset接口下载并加载CIFAR-10的训练集。目前仅支持二进制版本(CIFAR-10 binary version)。
from download import download
import mindspore as ms
from mindspore.dataset import Cifar10Dataset
from mindspore.dataset import vision, transformsurl = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/cifar-10-binary.tar.gz"download(url, "./dataset", kind="tar.gz", replace=True)def get_dataset(train_dataset_path, batch_size, usage):image_trans = []if usage == "train":image_trans = [vision.RandomCrop((32, 32), (4, 4, 4, 4)),vision.RandomHorizontalFlip(prob=0.5),vision.Resize((224, 224)),vision.Rescale(1.0 / 255.0, 0.0),vision.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]),vision.HWC2CHW()]elif usage == "test":image_trans = [vision.Resize((224, 224)),vision.Rescale(1.0 / 255.0, 0.0),vision.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]),vision.HWC2CHW()]label_trans = transforms.TypeCast(ms.int32)dataset = Cifar10Dataset(train_dataset_path, usage=usage, shuffle=True)dataset = dataset.map(image_trans, 'image')dataset = dataset.map(label_trans, 'label')dataset = dataset.batch(batch_size, drop_remainder=True)return datasetdataset = get_dataset("./dataset/cifar-10-batches-bin", 128, "train")
batches_per_epoch = dataset.get_dataset_size()
模型训练
本节用随机初始化的参数做预训练。首先调用ShuffleNetV1定义网络,参数量选择"2.0x",并定义损失函数为交叉熵损失,学习率经过4轮的warmup后采用余弦退火,优化器采用Momentum。最后用train.model中的Model接口将模型、损失函数、优化器封装在model中,并用model.train()对网络进行训练。将ModelCheckpoint、CheckpointConfig、TimeMonitor和LossMonitor传入回调函数中,将会打印训练的轮数、损失和时间,并将ckpt文件保存在当前目录下。
import time
import mindspore
import numpy as np
from mindspore import Tensor, nn
from mindspore.train import ModelCheckpoint, CheckpointConfig, TimeMonitor, LossMonitor, Model, Top1CategoricalAccuracy, Top5CategoricalAccuracydef train():mindspore.set_context(mode=mindspore.PYNATIVE_MODE, device_target="Ascend")net = ShuffleNetV1(model_size="2.0x", n_class=10)loss = nn.CrossEntropyLoss(weight=None, reduction='mean', label_smoothing=0.1)min_lr = 0.0005base_lr = 0.05lr_scheduler = mindspore.nn.cosine_decay_lr(min_lr,base_lr,batches_per_epoch*250,batches_per_epoch,decay_epoch=250)lr = Tensor(lr_scheduler[-1])optimizer = nn.Momentum(params=net.trainable_params(), learning_rate=lr, momentum=0.9, weight_decay=0.00004, loss_scale=1024)loss_scale_manager = ms.amp.FixedLossScaleManager(1024, drop_overflow_update=False)model = Model(net, loss_fn=loss, optimizer=optimizer, amp_level="O3", loss_scale_manager=loss_scale_manager)callback = [TimeMonitor(), LossMonitor()]save_ckpt_path = "./"config_ckpt = CheckpointConfig(save_checkpoint_steps=batches_per_epoch, keep_checkpoint_max=5)ckpt_callback = ModelCheckpoint("shufflenetv1", directory=save_ckpt_path, config=config_ckpt)callback += [ckpt_callback]print("============== Starting Training ==============")start_time = time.time()# 由于时间原因,epoch = 5,可根据需求进行调整model.train(5, dataset, callbacks=callback)use_time = time.time() - start_timehour = str(int(use_time // 60 // 60))minute = str(int(use_time // 60 % 60))second = str(int(use_time % 60))print("total time:" + hour + "h " + minute + "m " + second + "s")print("============== Train Success ==============")if __name__ == '__main__':train()
训练好的模型保存在当前目录的shufflenetv1-5_390.ckpt中,用作评估。
模型评估
在CIFAR-10的测试集上对模型进行评估。
设置好评估模型的路径后加载数据集,并设置Top 1, Top 5的评估标准,最后用model.eval()接口对模型进行评估。
from mindspore import load_checkpoint, load_param_into_netdef test():mindspore.set_context(mode=mindspore.GRAPH_MODE, device_target="Ascend")dataset = get_dataset("./dataset/cifar-10-batches-bin", 128, "test")net = ShuffleNetV1(model_size="2.0x", n_class=10)param_dict = load_checkpoint("shufflenetv1-5_390.ckpt")load_param_into_net(net, param_dict)net.set_train(False)loss = nn.CrossEntropyLoss(weight=None, reduction='mean', label_smoothing=0.1)eval_metrics = {'Loss': nn.Loss(), 'Top_1_Acc': Top1CategoricalAccuracy(),'Top_5_Acc': Top5CategoricalAccuracy()}model = Model(net, loss_fn=loss, metrics=eval_metrics)start_time = time.time()res = model.eval(dataset, dataset_sink_mode=False)use_time = time.time() - start_timehour = str(int(use_time // 60 // 60))minute = str(int(use_time // 60 % 60))second = str(int(use_time % 60))log = "result:" + str(res) + ", ckpt:'" + "./shufflenetv1-5_390.ckpt" \+ "', time: " + hour + "h " + minute + "m " + second + "s"print(log)filename = './eval_log.txt'with open(filename, 'a') as file_object:file_object.write(log + '\n')if __name__ == '__main__':test()
输出:
result:{'Loss': 1.5808131725360186, 'Top_1_Acc': 0.5034054487179487, 'Top_5_Acc': 0.9389022435897436}, ckpt:'./shufflenetv1-5_390.ckpt', time: 0h 1m 37s
模型预测
在CIFAR-10的测试集上对模型进行预测,并将预测结果可视化。
import mindspore
import matplotlib.pyplot as plt
import mindspore.dataset as dsnet = ShuffleNetV1(model_size="2.0x", n_class=10)
show_lst = []
param_dict = load_checkpoint("shufflenetv1-5_390.ckpt")
load_param_into_net(net, param_dict)
model = Model(net)
dataset_predict = ds.Cifar10Dataset(dataset_dir="./dataset/cifar-10-batches-bin", shuffle=False, usage="train")
dataset_show = ds.Cifar10Dataset(dataset_dir="./dataset/cifar-10-batches-bin", shuffle=False, usage="train")
dataset_show = dataset_show.batch(16)
show_images_lst = next(dataset_show.create_dict_iterator())["image"].asnumpy()
image_trans = [vision.RandomCrop((32, 32), (4, 4, 4, 4)),vision.RandomHorizontalFlip(prob=0.5),vision.Resize((224, 224)),vision.Rescale(1.0 / 255.0, 0.0),vision.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]),vision.HWC2CHW()]
dataset_predict = dataset_predict.map(image_trans, 'image')
dataset_predict = dataset_predict.batch(16)
class_dict = {0:"airplane", 1:"automobile", 2:"bird", 3:"cat", 4:"deer", 5:"dog", 6:"frog", 7:"horse", 8:"ship", 9:"truck"}
# 推理效果展示(上方为预测的结果,下方为推理效果图片)
plt.figure(figsize=(16, 5))
predict_data = next(dataset_predict.create_dict_iterator())
output = model.predict(ms.Tensor(predict_data['image']))
pred = np.argmax(output.asnumpy(), axis=1)
index = 0
for image in show_images_lst:plt.subplot(2, 8, index+1)plt.title('{}'.format(class_dict[pred[index]]))index += 1plt.imshow(image)plt.axis("off")
plt.show()


相关文章:
《昇思25天学习打卡营第14天|计算机视觉-ShuffleNet图像分类》
FCN图像语义分割&ResNet50迁移学习&ResNet50图像分类 当前案例不支持在GPU设备上静态图模式运行,其他模式运行皆支持。 ShuffleNet网络介绍 ShuffleNetV1是旷视科技提出的一种计算高效的CNN模型,和MobileNet, SqueezeNet等一样主要应用在移动端…...

将字符串写入结构体变量中
将字符串写入结构体变量中,主要涉及到结构体中字符数组(或指针)的使用。 一、使用字符数组 假设你有一个结构体,它包含一个字符数组来存储字符串: #include <stdio.h> #include <string.h> // 用于st…...

iPhone 16 Pro系列将标配潜望镜头:已开始生产,支持5倍变焦
ChatGPT狂飙160天,世界已经不是之前的样子。 更多资源欢迎关注 7月6日消息,据DigiTimes最新报道,苹果将在iPhone 16 Pro中引入iPhone 15 Pro Max同款5倍光学变焦四棱镜潜望镜头。 报道称,目前苹果已经将模组订单交至大立光电和玉…...

PG在还没有pg_class的时候怎么访问基础系统表?
在没有pg_class的时候,数据库怎么访问系统表?这个问题可以分成两个阶段来看: 数据库簇初始化,此时一个database都没有,所以怎么构造和访问pg_class等系统表是一个问题私有内存初始化系统表。PG的系统表信息是放在back…...

UnityHub 无法添加模块问题
文章目录 1.问题描述2.问题解决 1.问题描述 在Hub中无法添加模块 2.问题解决 1、点击设置 2、设置版本安装位置 可以发现installs的安装位置路径设置不是unity安装位置,这里我们更改成自己电脑unity安装位置的上一级路径 添加模块正常:...

python04——类(基础new)
类其实也是一种封装的思想,类就是把变量、方法等封装在一起,然后可以通过不同的实例化对其进行调用操作。 1.类的定义 class 类名: 变量a def __init__ (self,参数2,参数2...):初始化函数!!&…...
聚合2、递归)
【Python百日进阶-Web开发-Peewee】Day296 - 查询示例(五)聚合2、递归
文章目录 14.6.13 列出每个指定设施的预订总小时数 List the total hours booked per named facility14.6.14 列出每位会员在 2012 年 9 月 1 日之后的首次预订 List each member’s first booking after September 1st 201214.6.15 生成成员名称列表,每行包含成员总数 Produc…...

闲话银行家舍入法,以及在程序中如何实现
前言 相信对于四舍五入的舍入法,大家都耳熟能详,但对于银行家舍入法,可能就会比较少接触了! 可是在金融界,银行家舍入法可是大名鼎鼎的主角之一,主要应用于金融领域和涉及货币计算的场合。 那么…...
)
最短路径算法(算法篇)
算法之最短路径算法 最短路径算法 概念: 考查最短路径问题,可能会输入一个赋权图(也就是边带有权的图),则一条路径的v1v2…vN的值就是对路径的边的权求和,这叫做赋权路径长,如果是无权路径长就是单纯的路径上的边数。…...

昇思25天学习打卡营第11天 | LLM原理和实践:基于MindSpore实现BERT对话情绪识别
1. 基于MindSpore实现BERT对话情绪识别 1.1 环境配置 # 实验环境已经预装了mindspore2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号 !pip uninstall mindspore -y !pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore2.2…...

反向散射技术(backscatter communication)
智能反射表面辅助的反向散射通信系统研究综述(知网) 1 反向散射通信技术优势和应用场景 反向散射通信技术通过被动射频技术发送信号,不需要一定配有主动射频单元,被认为是构建绿色节能、低成本、可灵活部署的未来物联网规模化应用关键技术之一,是实现“…...

致远CopyFile文件复制漏洞
复现版本 V8.0SP2 漏洞范围 V5&G6_V6.1至V8.0SP2全系列版本、V5&G6&N_V8.1至V8.1SP2全系列版本。 漏洞复现 上传文件 POST /seeyon/ajax.do?methodajaxAction&managerNameportalCssManager&rnd57507 HTTP/1.1 Accept: */* Content-Type: applicatio…...

MySQL 创建数据库
MySQL 创建数据库 在当今的数据驱动世界中,数据库是任何应用程序的核心组成部分。MySQL,作为一个流行的开源关系数据库管理系统,因其可靠性、易用性和强大的功能而广受欢迎。本文将详细介绍如何在MySQL中创建数据库,包括基础知识和最佳实践。 什么是MySQL数据库? MySQL…...

AbyssFish单连通周期边界多孔结构2D软件
软件介绍 AbyssFish单连通周期边界多孔结构2D软件(以下简称软件)可用于生成具备周期性边界条件的单连通域多孔结构PNG图片,软件可设置生成模型的尺寸、孔隙率、孔隙尺寸、孔喉尺寸等参数,并且具备孔隙形态控制功能。 软件生成的…...

Linux驱动开发-03字符设备驱动框架搭建
一、字符设备驱动开发步骤 驱动模块的加载和卸载(将驱动编译模块,insmod加载驱动运行)字符设备注册与注销(我们的驱动实际上是去操作底层的硬件,所以需要向系统注册一个设备,告诉Linux系统,我有…...

Zynq系列FPGA实现SDI视频编解码+图像缩放+多路视频拼接,基于GTX高速接口,提供8套工程源码和技术支持
目录 1、前言工程概述免责声明 2、相关方案推荐本博已有的 SDI 编解码方案本博已有的FPGA图像缩放方案本方案的无缩放应用本方案在Xilinx--Kintex系列FPGA上的应用 3、详细设计方案设计原理框图SDI 输入设备Gv8601a 均衡器GTX 解串与串化SMPTE SD/HD/3G SDI IP核BT1120转RGB自研…...

VS2019使用C#写窗体程序技巧(1)
1、打开串口 private void button1_Click(object sender, EventArgs e){myPort cmb1.Text;mybaud Convert.ToInt32(cmb2.Text, 10);databit 8;parity Parity.None;stopBit StopBits.One;textBox9.Text "2";try{sp new SerialPort(myPort, mybaud, parity, dat…...

Python爬虫-requests模块
前戏: 1.你是否在夜深人静的时候,想看一些会让你更睡不着的图片却苦于没有资源... 2.你是否在节假日出行高峰的时候,想快速抢购火车票成功..。 3.你是否在网上购物的时候,想快速且精准的定位到口碑质量最好的商品. …...

适用于PyTorch 2.0.0的Ubuntu 22.04上CUDA v11.8和cuDNN 8.7安装指南
将下面内容保存为install.bash,直接用bash执行一把梭解决 #!/bin/bash### steps #### # verify the system has a cuda-capable gpu # download and install the nvidia cuda toolkit and cudnn # setup environmental variables # verify the installation ######…...

使用conda安装openturns
目录 1. 有效方法2. 整体分析使用pip安装使用conda安装验证安装安装过程中可能遇到的问题 1. 有效方法 conda install -c conda-forge openturns2. 整体分析 OpenTURNS是一个用于概率和统计分析的软件库,主要用于不确定性量化。你可以通过以下步骤在Python环境中安…...
)
保姆级教程:在CentOS 7上用达梦8搭建DCA练习环境(附ulimit、VNC、ODBC全配置)
达梦8 DCA认证实战:CentOS 7环境搭建与调优全指南 在国产数据库技术快速发展的今天,达梦数据库作为核心产品之一,其DCA认证已成为众多从业者提升竞争力的重要选择。与理论为主的认证不同,DCA更注重实际操作能力,而一个…...
)
告别网盘客户端!用Alist+RaiDrive把百度云盘变成电脑本地文件夹(保姆级图文教程)
用AlistRaiDrive实现网盘本地化管理的终极方案 你是否厌倦了电脑上安装多个网盘客户端,不仅占用系统资源,操作还繁琐割裂?每次上传下载文件都要在不同客户端间切换,效率低下。现在,通过Alist和RaiDrive的组合…...

sudo企业级应用【20260525】001篇
文章目录 一、总体设计思路 1️⃣ 设计原则 2️⃣ 日志策略(重点) 二、10 个真实生产场景(含 sudoers 配置) 🔹 Linux 系统管理(3 个) ✅ 场景 1:基础运维(用户 / 权限) ✅ 场景 2:磁盘与文件系统 ✅ 场景 3:网络与防火墙 🔹 云管理(2 个) ✅ 场景 4:云 CLI …...

SSH工具对比:新手用户和熟练运维,选型逻辑有什么不同
结论 新手用户和熟练运维在选择 SSH 工具时,关注点往往完全不同。 新手更在意的是:能不能顺利连接、界面是否直观、文件和配置是否容易找到、网站出问题时能不能快速定位。 而熟练运维更在意的是:连接效率、命令自由度、多服务器管理能力、原…...

全链路压测实战:双十一级别的流量,我是这样扛住的
作为一名在质量保障领域摸爬滚打多年的测试工程师,我深知传统的单接口压测在如今分布式架构下的无力感。当业务流量达到双十一这种脉冲式、高并发的级别时,任何一个非核心链路上的“短板”都可能引发系统性的雪崩。全链路压测不再是选择题,而…...

RevSSH反向SSH隧道:无公网IP设备的安全远程运维方案
1. 这不是又一个SSH封装工具——RevSSH解决的是“根本性连接悖论”你有没有遇到过这样的场景:一台部署在客户内网的嵌入式设备,没有公网IP,NAT穿透失败,防火墙策略死死锁住所有入向端口,连ICMP都被禁了;或者…...

OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权
OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权 【免费下载链接】firmware Alternative IP Camera firmware from an open community 项目地址: https://gitcode.com/gh_mirrors/fir/firmware 还在为网络摄像头的封闭系统而烦恼吗?想要完全掌控…...
)
ArduPilot飞行模式实战:从代码角度看Stabilize、Acro、Loiter模式如何切换(附避坑指南)
ArduPilot飞行模式深度解析:从状态机到实战避坑指南 在开源飞控领域,ArduPilot以其强大的飞行模式系统著称。不同于普通用户只需了解模式功能,开发者更需要掌握模式切换的底层机制——这直接关系到飞行安全与二次开发效率。本文将带您深入Sta…...

收藏|2026年大模型算法岗崛起!程序员小白入门高薪赛道全攻略
前些年,算法岗位一直稳居技术圈高薪行列,无数程序员争相入局,也成为计算机专业毕业生求职首选方向。 伴随大模型技术飞速迭代落地,行业就业格局迎来重大变革。如今含金量最高、人才缺口最大、长期发展潜力顶尖的岗位,已…...

AI专著生成必备工具,轻松撰写20万字专著,质量与效率双保障!
学术专著的写作是一个严谨的过程,其背后需要大量的资料和数据作为基础。搜集和整理这些资料与数据往往是写作过程中最繁琐且耗时的部分。研究人员需要广泛收集国内外的前沿文献,确保所用文献不仅具备权威性,还要与研究主题密切相关。同时&…...