如何分辨AI生成的内容?AI生成内容检测工具对比实验
检测人工智能生成的文本对各个领域的组织都提出了挑战,包括学术界和新闻界等。生成式AI与大语言模型根据短描述来进行内容生成的能力,产生了一个问题:这篇文章/内容/作业/图像到底是由人类创作的,还是AI创作的?虽然 LLM 在改进文本方面发挥着无价的作用,但我们也必须承认这种演变给智力生产概念带来的问题。作为人类,我们依靠线索来评估文本的可信度。然而,随着 LLM 驱动的文本生成,越来越难以确定文本是否源自人类,以及它是否呈现了准确或有偏见的想法和陈述。
人工智能在文本生成方面的进步使得区分人类编写的内容和机器生成的内容变得越来越困难。这对依赖准确的标注数据进行机器学习训练和自然语言处理任务的公司构成了重大挑战。市场上有各种人工智能检测器,包括 Open AI 于 2023 年初发布的现已撤回的人工智能检测器。然而,它未能达到预期,仅捕获了 26% 的人工智能生成文本,仅在六个月后就退役了。最近的研究还揭示了人工智能检测器对非母语人士的偏见。这些复杂性凸显了人工智能检测的难度,强调了与其他检测器的区别。
目前市场上可用的解决方案使用基于文本的方法,通过对合成和真实的人类书写文本进行训练后分析词汇、语义或语法线索来检测人工智能生成的文本。正如 Appen 数据科学家 Arjun Patel 和 Phoebe Liu 所描述的那样,这些解决方案在检测 LLM 生成的文本方面存在缺陷,因为 LLM 生成的文本通常与人类书写的内容非常相似。此外,当前的检测方法容易出现误报和漏报。因此,未被发现的人工智能生成的文本被标记为真实可靠的风险进一步加剧了人们对数据准确性和可信度的担忧。

AI生成内容检测的挑战
由于以下几种因素,研究人员在检测人工智能生成的文本方面正面临重大挑战:
- 大语言模型 (LLM) 性能的提升与使用新示例训练 AI 检测器之间的不断竞争,需要频繁地重新训练检测器。
- 大语言模型(LLM)的普及度不断提高,从商业产品到开源模型。
- 捕捉人类使用文本生成工具的真实数据集稀缺,以及对注释提交中人工智能生成文本的普遍性的理解有限。
- 缺乏标准化指标来评估此类模型。
- 第三方模型所采用的防止对抗性攻击的方法缺乏透明度。
设定正确的指标
在确定任何事物的有效性时,主要的挑战是确定正确的指标。根据所选的指标,即使某件事不符合预期的使用要求,也可能被视为成功。了解不同的指标并仔细选择真正反映您目标的指标对于准确评估成功至关重要。
尽管模型准确度通常被视为评估性能的关键指标,但它可能会误导人们判断模型是否有效。在处理不平衡数据集或成本敏感性很重要时尤其如此。例如,如果将一段文本误认为是由人工智能生成的,而实际上它是由人类编写的,可能会对人类作者产生严重而有害的影响。模型准确度通常表示为正确预测占总预测数的百分比。在处理不平衡数据集时,有可能实现高准确率,但假阳性率也会很高。这正是人工智能检测器被认为不可靠的原因。
我们的期望是,我们的人群总体上是诚实的,并且在被要求不要使用外部 LLM 进行内容生成时倾向于遵循指示。这意味着我们的人群主要由善意的个人组成,但也有一些坏人。因此,使用准确率高但误报率也高的模型是有害的,因为它可能会破坏我们的贡献者对 Appen 的信任。
除了准确度之外,还可以使用各种指标,例如曲线下面积、假阳性、真阳性等等。确定最有意义的指标在很大程度上取决于 AI 检测器的具体用例和上下文。这就是为什么定义指标通常需要产品和数据科学团队之间的协作,因为这对于满足业务需求至关重要。
在 Appen,我们采取保守的方法,并优先考虑一个指标,即如果 AI 检测器不会对人类(尤其是所分析文本的作者)产生负面影响,则该指标被视为有效。我们的目标是评估 AI 检测器将文本错误地识别为 AI 生成的频率,而这些文本实际上是由人类撰写的。这在我们以人为本的方法中非常重要,因为被错误地标记为 AI 生成的作者几乎没有或根本没有办法挑战这一预测。因此,我们仔细检查了误报率,它表示错误地将人类生成的文本识别为 AI 生成的文本的比例。
Appen 的 AI 检测基准测试实验
最近,Appen 数据科学家Phoebe Liu和Arjun Patel与 Appen 高级产品经理Alice Desthuilliers合作,进行了一项实验,以评估不同市场解决方案的有效性。得益于 Appen 的专业知识和致力于策划有目的的人群并通过精心设计的任务收集高质量的人工数据,这项实验成为了现实。利用我们自己的众包团队,Appen 能够根据不同的基准评估各种 AI 检测器的性能。该实验旨在确定 AI 检测器将人工生成的文本错误地归类为 AI 生成的频率。
[研究人员评估了四种流行的市场解决方案:OpenAI 已撤回的 AI 检测器作为对照、商业解决方案、开源解决方案和澳鹏内部开发的基于机器学习的模型。这些模型中的每一个都基于 Appen 的高质量数据进行了测试。然后将结果与预定义的 95% 准确度基线,高效 AI 检测器的预期性能,进行对比。实验得出的结论是,目前的市场解决方案均未达到此基准,所有模型的误报率均高于 10%,即将10%的人工撰写内容判断为AI生成。]
人群标准
为了开展我们的 AI 检测实验,Appen 团队组建了一支由 24 名贡献者组成的团队,他们的英语水平以美国英语为母语或接近母语。这些贡献者居住在美国或菲律宾。多亏了这个团队,我们才得以创建控制数据集。
任务
在实验中,Appen 团队安排了两种不同的任务:
- 人类撰写组:在没有任何外部帮助的情况下对提示做出响应。
- 人工智能组:使用 ChatGPT 等生成式人工智能来响应提示。
在执行每项任务之前,团队都会对参与实验的人员进行一次培训,以确保参与者理解方法并正确执行任务。实验采用的所有提示都是从开源 Dolly 数据集中精心挑选出来的。
对于第一组,团队要求参与者在澳鹏数据标注平台中从头撰写针对prompt的回应,并保证长度超过150字(大多数AI生成内容检测器所需的内容长度),注意不出现错字,并给出正确的答案。整体而言,我们希望参与者扮演一个乐于助人的助手,对问题做出客观细致的回复。
第二组参与者可以选择自己喜欢的生成式AI应用,团队也与他们分享了网上公开的生成式AI使用指南。
结果
Patel、Liu 和 Desthuilliers 通过 7 个作业的组合生成了总共 636 个提示-响应对数据集。其中,334 对是使用生成式AI 工具创建的,而 302 对是由人类写作的。
为了评估性能,Appen 的数据科学和产品团队选择了几种广为使用且以宣传的功效而闻名的 API,其中包括:
- Sapling AI
- GPTZero (句子级和文档级)
- OpenAI GPT2 Detector,这是OpenAI 的一个早期模型,作为基准
每个模型都经过 5 倍分层交叉验证进行评估。综合考虑准确率、f1 分数、假阳性率(False positive rate, FPR)和真阳性率(True positive rate, TPR)等指标,实验结果如下:
| 准确率 | F1 | 假阳性率 | 真阳性率 | |
|---|---|---|---|---|
| sapling | 0.62 | 0.71 | 0.67 | 0.90 |
| GPTZero | 0.70 | 0.70 | 0.26 | 0.66 |
| GPTZero文档级 | 0.61 | 0.71 | 0.73 | 0.91 |
| OpenAI GPT2 | 0.51 | 0.31 | 0.16 | 0.21 |
结果显示,虽然某些模型在某些指标上的表现优于其他模型,但所评估的所有 AI 检测工具均未达到 95% 准确率的预期基准。事实上,实验四个工具的误报率在 16.67% 到 70% 之间,这凸显了 AI 生成内容检测技术需要进一步改进。
与 OpenAI 撤回的 AI 检测模型的比较
请记住,OpenAI 发布了 ChatGPT 分类器,据报道,该分类器的真实阳性率 (TPR) 为 26%,假阳性率 (FPR) 为 9%。虽然这个模型后来被撤回,我们无法使用我们的控制数据集对其进行评估,但值得注意的是,它是少数几个声称可以在现实世界数据上运行的模型之一,来自一家顶级 LLM 公司。如果有人知道人工智能生成的内容应该是什么,那就是 OpenAI!
为了确保 FPR 保持在 9% 以下,我们重新计算了在我们的数据上观察到的每个模型的最佳 TPR,并使用不同的阈值进行优化。这有助于我们衡量这些付费第三方 API 与 OpenAI 的免费撤回模型相比的改进。为此,Appen 数据科学团队测试了 API,以实现低于 9% 的误报率,并尝试使用不同的阈值找到实现的最佳真实阳性率。
| 假阳性率FPR | 真阳性率TPR | |
|---|---|---|
| sapling | 0.07 | 0.05 |
| GPTZero文档级 | 0.07 | 0.15 |
| OpenAI GPT2 | 0.08 | 0.15 |
我们初步调查发现,所有第三方模型都达不到 OpenAI 撤回的分类器的标准。该分类器的真阳性率为 26%,假阳性率为 9%。在所有模型中,GPTZero 的表现最为出色,真阳性率为 13%,假阳性率为 8%。虽然某些模型的真阳性率非常高,在某些情况下甚至超过 91%,但假阳性率却高得惊人,尤其是表现最好的 GPTZero 模型,高达 73%。这些高假阳性率对贡献者构成了重大风险,导致 OpenAI 撤回了他们最新的分类器。
Patel 表示:“尽量减少误报对于维护系统的信任和确保公平至关重要。虽然真阳性对于发现实际作弊情况很重要,但优先减少误报有助于在准确性和尽量减少对无辜者的伤害之间取得微妙的平衡。”
有趣的是,句子级 GPTZero 模型在我们的观察中缺失。这是因为该模型未能在我们的数据集上实现如此低的假阳性率。Sapling 模型面临类似的问题,因为它必须像 AI 一样预测所有实例才能满足假阳性率要求。只有 GPTZero 文档级分类器表现良好,与已退役的 OpenAI 检测器相比,其假阳性率降低了 3 个百分点。然而,该模型识别出的真阳性比 OpenAI 的解决方案要少。
这可能表明人工智能检测技术中最小化假阳性和最大化真阳性之间的权衡。
努力打造更安全、更道德的数字环境
我们的研究强调了使用现有技术检测 AI 生成内容所面临的挑战。虽然第三方 API 已显示出令人鼓舞的结果,但它们仍未达到预期并有效地以高精度识别 AI 生成的文本。需要进一步改进以确保这些系统能够准确有效地识别 AI 生成的内容并防止有害或欺骗性信息。
随着人工智能技术的不断发展,检测方法需要不断重新评估和更新,以跟上人工智能生成文本不断发展的格局。我们必须保持开放的心态,拥抱新技术,同时保持谨慎和警惕,确保负责任地使用这些技术。有效检测和监管人工智能生成内容的旅程可能充满挑战,但这是朝着在当今世界更负责任、更合乎道德地使用人工智能迈出的重要一步。
相关文章:
如何分辨AI生成的内容?AI生成内容检测工具对比实验
检测人工智能生成的文本对各个领域的组织都提出了挑战,包括学术界和新闻界等。生成式AI与大语言模型根据短描述来进行内容生成的能力,产生了一个问题:这篇文章/内容/作业/图像到底是由人类创作的,还是AI创作的?虽然 LL…...

Clion中怎么切换不同的程序运行
如下图,比如这个文件夹下面有那么多的项目: 那么我想切换不同的项目运行怎么办呢?如果想通过下图的Edit Configurations来设置是不行的: 解决办法: 如下图,选中项目的CMakeLists.txt,右键再点击…...

【C++初阶】C++入门(下)
【C初阶】C入门(下) 🥕个人主页:开敲🍉 🥕所属专栏:C🥭 🌼文章目录🌼 6. 引用 6.1 引用的概念 6.2 引用特性 6.3 常引用 6.4 使用场景 6.5 传值、传引用效率…...

【3】迁移学习模型
【3】迁移学习模型 文章目录 前言一、安装相关模块二、训练代码2.1. 管理预训练模型2.2. 模型训练代码2.3. 可视化结果2.4. 类别函数 总结 前言 主要简述一下训练代码 三叶青图像识别研究简概 一、安装相关模块 #xingyun的笔记本 print(xingyun的笔记本) %pip install d2l %…...

【工具分享】FOFA——网络空间测绘搜索引擎
文章目录 FOFA介绍FOFA语法其他引擎 FOFA介绍 FOFA官网:https://fofa.info/ FOFA(Fingerprinting Organizations with Advanced Tools)是一款网络空间测绘的搜索引擎,它专注于帮助用户收集和分析互联网上的设备和服务信息。FOFA…...

[嵌入式 C 语言] 按位与、或、取反、异或
若协议中如下图所示: 注意: 长度为1,表示1个字节,也就是0xFF,也就是 1111 1111 (这里0xFF只是单纯表示一个数,也可以是其他数,这里需要注意的是1个字节的意思) 一、按位…...

Android --- 运行时Fragment如何获取Activity中的数据,又如何将数据传递到Activity中呢?
1.通过 getActivity() 方法获取 Activity 实例: 在 Fragment 中,可以通过 getActivity() 方法获取当前 Fragment 所依附的 Activity 实例。然后可以调用 Activity 的公共方法或者直接访问 Activity 的字段来获取数据。 // 在 Fragment 中获取 Activity…...
-- Java8 stream的 orElse(null) 和 orElseGet(null))
Java后端开发(十三)-- Java8 stream的 orElse(null) 和 orElseGet(null)
orElse(null)表示如果一个都没找到返回null。【orElse()中可以塞默认值。如果找不到就会返回orElse中你自己设置的默认值。】 orElseGet(null)表示如果一个都没找到返回null。【orElseGet()中可以塞默认值。如果找不到就会返回orElseGet中你自己设置的默认值。】 区别就…...

L2 LangGraph_Components
参考自https://www.deeplearning.ai/short-courses/ai-agents-in-langgraph,以下为代码的实现。 这里用LangGraph把L1的ReAct_Agent实现,可以看出用LangGraph流程化了很多。 LangGraph Components import os from dotenv import load_dotenv, find_do…...

09.C2W4.Word Embeddings with Neural Networks
往期文章请点这里 目录 OverviewBasic Word RepresentationsIntegersOne-hot vectors Word EmbeddingsMeaning as vectorsWord embedding vectors Word embedding processWord Embedding MethodsBasic word embedding methodsAdvanced word embedding methods Continuous Bag-…...
硅谷甄选二(登录)
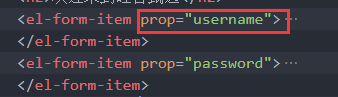
一、登录路由静态组件 src\views\login\index.vue <template><div class"login_container"><!-- Layout 布局 --><el-row><el-col :span"12" :xs"0"></el-col><el-col :span"12" :xs"2…...

scipy库中,不同应用滤波函数的区别,以及FIR滤波器和IIR滤波器的区别
一、在 Python 中,有多种函数可以用于应用 FIR/IIR 滤波器,每个函数的使用场景和特点各不相同。以下是一些常用的 FIR /IIR滤波器应用函数及其区别: from scipy.signal import lfiltery lfilter(fir_coeff, 1.0, x)from scipy.signal impo…...

简谈设计模式之建造者模式
建造者模式是一种创建型设计模式, 旨在将复杂对象的构建过程与其表示分离, 使同样的构建过程可以构建不同的表示. 建造者模式主要用于以下情况: 需要创建的对象非常复杂: 这个对象由多个部分组成, 且这些部分需要一步步地构建不同的表示: 通过相同的构建过程可以生成不同的表示…...

力扣 hot100 -- 动态规划(下)
目录 💻最长递增子序列 AC 动态规划 AC 动态规划(贪心) 二分 🏠乘积最大子数组 AC 动规 AC 用 0 分割 🐬分割等和子集 AC 二维DP AC 一维DP ⚾最长有效括号 AC 栈 哨兵 💻最长递增子序列 300. 最长递增子序列…...
【计算机毕业设计】018基于weixin小程序实习记录
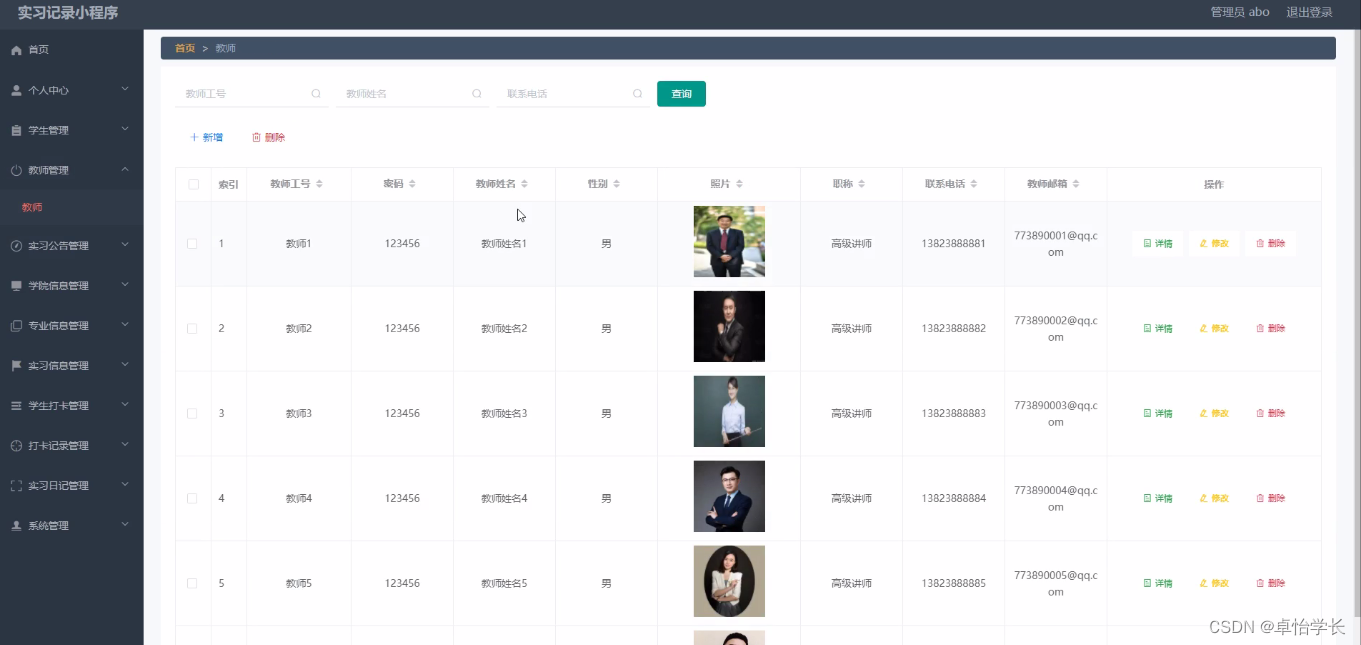
🙊作者简介:拥有多年开发工作经验,分享技术代码帮助学生学习,独立完成自己的项目或者毕业设计。 代码可以私聊博主获取。🌹赠送计算机毕业设计600个选题excel文件,帮助大学选题。赠送开题报告模板ÿ…...

力扣之有序链表去重
删除链表中的重复元素,重复元素保留一个 p1 p2 1 -> 1 -> 2 -> 3 -> 3 -> null p1.val p2.val 那么删除 p2,注意 p1 此时保持不变 p1 p2 1 -> 2 -> 3 -> 3 -> null p1.val ! p2.val 那么 p1,p2 向后移动 p1 …...

Apache配置与应用(优化apache)
Apache配置解析(配置优化) Apache链接保持 KeepAlive:决定是否打开连接保持功能,后面接 OFF 表示关闭,接 ON 表示打开 KeepAliveTimeout:表示一次连接多次请求之间的最大间隔时间,即两次请求之间…...
怎么将3张照片合并成一张?这几种拼接方法很实用!
怎么将3张照片合并成一张?在我们丰富多彩的日常生活里,是否总爱捕捉那些稍纵即逝的美好瞬间,将它们定格为一张张珍贵的图片?然而,随着时间的推移,这些满载回忆的宝藏却可能逐渐演变成一项管理挑战ÿ…...
YOLOv10改进 | 图像去雾 | MB-TaylorFormer改善YOLOv10高分辨率和图像去雾检测(ICCV,全网独家首发)
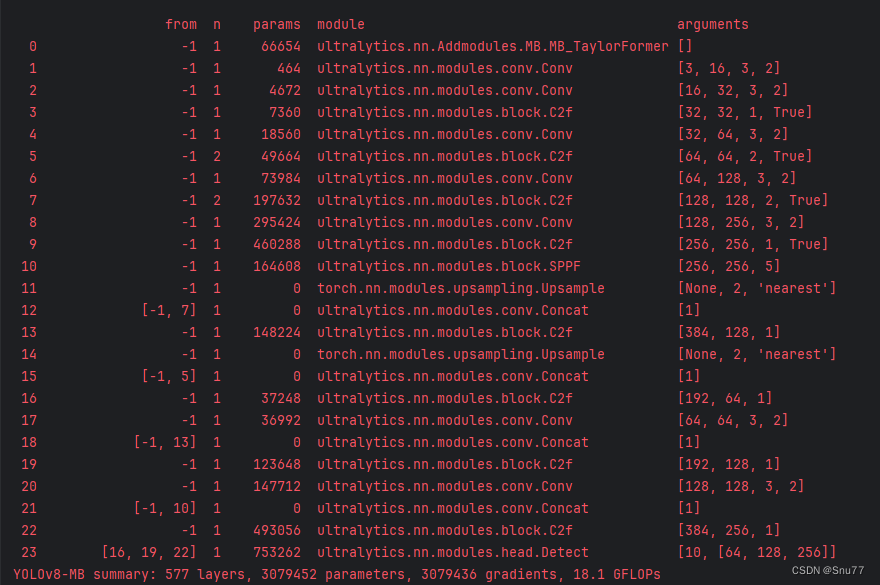
一、本文介绍 本文给大家带来的改进机制是图像去雾MB-TaylorFormer,其发布于2023年的国际计算机视觉会议(ICCV)上,可以算是一遍比较权威的图像去雾网络, MB-TaylorFormer是一种为图像去雾设计的多分支高效Transformer…...
spring boot读取yml配置注意点记录
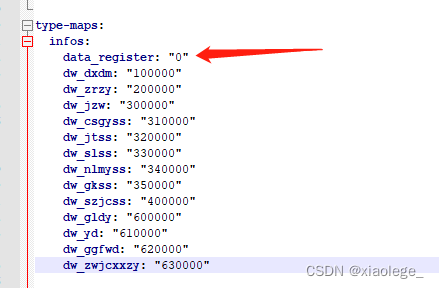
问题1:yml中配置的值加载到代码后值变了。 现场yml配置如下: type-maps:infos:data_register: 0ns_xzdy: 010000ns_zldy: 020000ns_yl: 030000ns_jzjz: 040000ns_ggglyggfwjz: 050000ns_syffyjz: 060000ns_gyjz: 070000ns_ccywljz: 080000ns_qtjz: 090…...

AI编码助手安全护栏:Claude代码生成规则引擎实战指南
1. 项目概述:为AI编码助手装上“护栏”最近在折腾AI辅助编程,特别是用Claude这类大模型来写代码,效率提升确实明显。但用久了就会发现一个问题:模型生成的代码,有时候会“放飞自我”。比如,它可能会引入一些…...

oh-my-opencode:AI编程操作系统,智能体编排与哈希锚定编辑实战
1. 项目概述:一个为AI编程而生的“操作系统”如果你和我一样,在过去一年里深度使用过Claude Code、Cursor或者各种开源的AI编程工具,那你一定经历过这种痛苦:模型选型让人眼花缭乱,配置流程复杂到让人想放弃࿰…...

AI时代DevSecOps脚手架:5分钟构建安全合规的React+Supabase应用
1. 项目概述:一个为AI编码时代量身定制的DevSecOps启动器 如果你和我一样,经常用 Cursor、Lovable 这类 AI 编程工具快速构建应用原型,那你肯定遇到过这个痛点:项目跑起来了,功能也实现了,但当你准备把它变…...

PS2游戏逆向工程:从MIPS机器码到x86重编译的实践解析
1. 项目概述:一个逆向工程与代码重编译的实践最近在逆向工程和游戏修改社区里,一个名为ajitmohapatr/ps2-recomp-Agent-SKILL的项目引起了我的注意。乍一看这个标题,充满了特定领域的“黑话”——“PS2”指向了经典的PlayStation 2游戏主机&a…...
04)
【审计专栏-监督监管领域】【信息科学与工程学】【社会科学】第十篇 社会底层核心规则(核心权力、核心利益、核心资源绑定、私下运作、关键价值交换、上下博弈)04
模型046:企业复杂利益链与多方利益博弈模型 1. 模型概述 项目 内容 模型名称 企业复杂利益链与多方利益博弈模型 核心场景 一家大型建筑企业“宏建集团”中标某市的地铁延长线建设项目。项目涉及总包方(宏建)、多个分包商(土建、机电、装修等)、材料供应商、监理…...

轻量级Web代理moltron:架构解析与生产级部署实战
1. 项目概述:一个轻量级、高性能的Web代理工具在开发和运维的日常工作中,我们经常需要处理不同网络环境下的服务访问问题。比如,本地开发需要调试一个部署在内网测试环境的API,或者需要安全地访问某些仅限特定网络访问的资源。传统…...

第四部分-Docker网络与存储——18. 自定义网络
18. 自定义网络 1. 自定义网络概述 自定义网络允许用户根据需求创建具有特定配置的网络,相比默认的 bridge 网络,提供了更好的隔离性、DNS 解析和灵活性。 ┌────────────────────────────────────────────…...

Joy-Con Toolkit:开源手柄调试工具的技术实现与应用
Joy-Con Toolkit:开源手柄调试工具的技术实现与应用 【免费下载链接】jc_toolkit Joy-Con Toolkit 项目地址: https://gitcode.com/gh_mirrors/jc/jc_toolkit Joy-Con Toolkit是一款专为任天堂Switch手柄设计的开源调试工具,通过逆向工程协议实现…...

2026最权威的六大AI写作平台解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 作为智能写作工具来讲的 DeepSeek,能够高效地促进学术论文撰写效率有所提升。于选…...

Ubuntu 18.04上Qt程序报‘xcb’插件错误?别急着重装,试试这个ldd排查法
Ubuntu 18.04 Qt程序xcb插件错误排查指南:从日志分析到依赖修复 当你满怀期待地在Ubuntu 18.04上启动精心开发的Qt应用程序时,屏幕上突然跳出"Could not load the Qt platform plugin xcb"的错误提示,这种挫败感开发者都深有体会。…...