【深度学习入门篇 ②】Pytorch完成线性回归!
🍊嗨,大家好,我是小森( ﹡ˆoˆ﹡ )! 易编橙·终身成长社群创始团队嘉宾,橙似锦计划领衔成员、阿里云专家博主、腾讯云内容共创官、CSDN人工智能领域优质创作者 。
易编橙:一个帮助编程小伙伴少走弯路的终身成长社群!
上一部分我们自己通过torch的方法完成反向传播和参数更新,在Pytorch中预设了一些更加灵活简单的对象,让我们来构造模型、定义损失,优化损失等;那么接下来,我们一起来了解一下其中常用的API!

nn.Module
nn.Module 是 PyTorch 框架中用于构建所有神经网络模型的基类。在 PyTorch 中,几乎所有的神经网络模块(如层、卷积层、池化层、全连接层等)都继承自 nn.Module。这个类提供了构建复杂网络所需的基本功能,如参数管理、模块嵌套、模型的前向传播等。
当我们自定义网络的时候,有两个方法需要特别注意:
-
__init__需要调用super方法,继承父类的属性和方法 -
farward方法必须实现,用来定义我们的网络的向前计算的过程
用前面的y = wx+b的模型举例如下:
from torch import nn
class Lr(nn.Module):def __init__(self):super(Lr, self).__init__() # 继承父类init的参数self.linear = nn.Linear(1, 1) def forward(self, x):out = self.linear(x)return out-
nn.Linear为torch预定义好的线性模型,也被称为全链接层,传入的参数为输入的数量,输出的数量(in_features, out_features),是不算(batch_size的列数) nn.Module定义了__call__方法,实现的就是调用forward方法,即Lr的实例,能够直接被传入参数调用,实际上调用的是forward方法并传入参数__init__方法里面的内容就是类创建的时候,跟着自动创建的部分。- 与之对应的就是
__del__方法,在对象被销毁时执行一些清理操作。
# 实例化模型
model = Lr()
# 传入数据,计算结果
predict = model(x)
优化器类
优化器(optimizer),可以理解为torch为我们封装的用来进行更新参数的方法,比如常见的随机梯度下降(stochastic gradient descent,SGD)。
优化器类都是由torch.optim提供的,例如
-
torch.optim.SGD(参数,学习率) -
torch.optim.Adam(参数,学习率)
注意:
-
参数可以使用
model.parameters()来获取,获取模型中所有requires_grad=True的参数
optimizer = optim.SGD(model.parameters(), lr=1e-3) # 实例化
optimizer.zero_grad() # 梯度置为0
loss.backward() # 计算梯度
optimizer.step() # 更新参数的值损失函数
-
均方误差:
nn.MSELoss(),常用于回归问题 -
交叉熵损失:
nn.CrossEntropyLoss(),常用于分类问题
model = Lr() # 实例化模型
criterion = nn.MSELoss() # 实例化损失函数
optimizer = optim.SGD(model.parameters(), lr=1e-3) # 实例化优化器类
for i in range(100):y_predict = model(x_true) # 预测值loss = criterion(y_true,y_predict) # 调用损失函数传入真实值和预测值,得到损失optimizer.zero_grad() loss.backward() # 计算梯度optimizer.step() # 更新参数的值
线性回归代码!
import torch
from torch import nn
from torch import optim
import numpy as np
from matplotlib import pyplot as pltx = torch.rand([50,1])
y = x*3 + 0.8# 自定义线性回归模型
class Lr(nn.Module):def __init__(self):super(Lr,self).__init__()self.linear = nn.Linear(1,1)def forward(self, x): # 模型的传播过程out = self.linear(x)return out# 实例化模型,loss,和优化器
model = Lr()
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=1e-3)
#训练模型
for i in range(30000):out = model(x) loss = criterion(y,out) optimizer.zero_grad() loss.backward() optimizer.step() if (i+1) % 20 == 0:print('Epoch[{}/{}], loss: {:.6f}'.format(i,30000,loss.data))# 模型评估模式,之前说过的
model.eval()
predict = model(x)
predict = predict.data.numpy()
plt.scatter(x.data.numpy(),y.data.numpy(),c="r")
plt.plot(x.data.numpy(),predict)
plt.show()
- 可以看出经过30000次训练后(相当于看书,一遍遍的回归学习),基本就可以拟合预期直线了

GPU上运行代码
当模型太大,或者参数太多的情况下,为了加快训练速度,经常会使用GPU来进行训练
此时我们的代码需要稍作调整:
1.判断GPU是否可用torch.cuda.is_available()
torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
device(type='cuda', index=0) # 使用GPU2.把模型参数和input数据转化为cuda的支持类型
model.to(device)
x.to(device)3.在GPU上计算结果也为cuda的数据类型,需要转化为numpy或者torch的cpu的tensor类型
predict = predict.cpu().detach().numpy() predict.cpu()将predict张量从可能的其他设备(如GPU)移动到CPU上predict.detach().detach()方法会返回一个新的张量,这个张量不再与原始计算图相关联,即它不会参与后续的梯度计算。.numpy()方法将张量转换为NumPy数组。
GPU代码:
import torch
from torch import nn
from torch import optim
import numpy as np
from matplotlib import pyplot as plt
import timex = torch.rand([50,1])
y = x*3 + 0.8class Lr(nn.Module):def __init__(self):super(Lr,self).__init__()self.linear = nn.Linear(1,1)def forward(self, x):out = self.linear(x)return outdevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
x,y = x.to(device),y.to(device)model = Lr().to(device)
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=1e-3)for i in range(300):out = model(x)loss = criterion(y,out)optimizer.zero_grad()loss.backward()optimizer.step()if (i+1) % 20 == 0:print('Epoch[{}/{}], loss: {:.6f}'.format(i,30000,loss.data))model.eval()
predict = model(x)
predict = predict.cpu().detach().numpy()
plt.scatter(x.cpu().data.numpy(),y.cpu().data.numpy(),c="r")
plt.plot(x.cpu().data.numpy(),predict,)
plt.show()
💯常见的优化算法
在大多数情况下,我们关注的是最小化损失函数,因为它衡量了模型预测与真实标签之间的差异。
梯度下降算法(batch gradient descent BGD)
每次迭代都需要把所有样本都送入,这样的好处是每次迭代都顾及了全部的样本,做的是全局最优化,但是有可能达到局部最优。
随机梯度下降法 (Stochastic gradient descent SGD)
针对梯度下降算法训练速度过慢的缺点,提出了随机梯度下降算法,随机梯度下降算法算法是从样本中随机抽出一组,训练后按梯度更新一次,然后再抽取一组,再更新一次,在样本量及其大的情况下,可能不用训练完所有的样本就可以获得一个损失值在可接受范围之内的模型了。
小批量梯度下降 (Mini-batch gradient descent MBGD)
SGD相对来说要快很多,但是也有存在问题,由于单个样本的训练可能会带来很多噪声,使得SGD并不是每次迭代都向着整体最优化方向,因此在刚开始训练时可能收敛得很快,但是训练一段时间后就会变得很慢。在此基础上又提出了小批量梯度下降法,它是每次从样本中随机抽取一小批进行训练,而不是一组,这样即保证了效果又保证的速度。
AdaGrad
AdaGrad算法就是将每一个参数的每一次迭代的梯度取平方累加后在开方,用全局学习率除以这个数,作为学习率的动态更新,从而达到自适应学习率的效果
Adam
Adam(Adaptive Moment Estimation)算法是将Momentum算法和RMSProp算法结合起来使用的一种算法,能够达到防止梯度的摆幅多大,同时还能够加开收敛速度。
相关文章:
【深度学习入门篇 ②】Pytorch完成线性回归!
🍊嗨,大家好,我是小森( ﹡ˆoˆ﹡ )! 易编橙终身成长社群创始团队嘉宾,橙似锦计划领衔成员、阿里云专家博主、腾讯云内容共创官、CSDN人工智能领域优质创作者 。 易编橙:一个帮助编程小…...

Syslog 管理工具
Syslog常被称为系统日志或系统记录,是一种用来在互联网协议(TCP/IP)的网上中传递记录档消息的标准,常用来指涉实际的Syslog 协议,或者那些提交syslog消息的应用程序或数据库。 系统日志协议(Syslog&#x…...

硅纪元AI应用推荐 | 百度橙篇成新宠,能写万字长文
“硅纪元AI应用推荐”栏目,为您精选最新、最实用的人工智能应用,无论您是AI发烧友还是新手,都能在这里找到提升生活和工作的利器。与我们一起探索AI的无限可能,开启智慧新时代! 百度橙篇,作为百度公司在202…...

Codeforces Round 954 (Div. 3)
🚀欢迎来到本文🚀 🍉个人简介:陈童学哦,彩笔ACMer一枚。 🏀所属专栏:Codeforces 本文用于记录回顾本彩笔的解题思路便于加深理解。 📢📢📢传送阵 A. X Axis解…...

【Django】报错‘staticfiles‘ is not a registered tag library
错误截图 错误原因总结 在django3.x版本中staticfiles被static替换了,所以这地方换位static即可完美运行 错误解决...
LeetCode 算法:二叉树的最近公共祖先 III c++
原题链接🔗:二叉树的最近公共祖先 难度:中等⭐️⭐️ 题目 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点…...

Windows CMD 命令汇总表
Windows CMD 命令汇总表 Windows CMD 命令汇总表目录操作磁盘操作文件操作其他命令FTP 命令高级系统命令批处理命令网络命令安全和权限命令 Windows CMD 命令指南目录操作MD - 创建子目录CD - 切换当前目录RD - 删除子目录DIR - 显示目录内容PATH - 设置可执行文件的搜索路径TR…...

【python+appium】自动化测试
pythonappium自动化测试系列就要告一段落了,本篇博客咱们做个小结。 首先想要说明一下,APP自动化测试可能很多公司不用,但也是大部分自动化测试工程师、高级测试工程师岗位招聘信息上要求的,所以为了更好的待遇,我们还…...
vue 数据类型
文章目录 ref 创建:基本类型的响应式数据reactive 创建:对象类型的响应式数据ref 创建:对象类型的响应式数据ref 对比 reactive将一个响应式对象中的每一个属性,转换为ref对象(toRefs 与 toRef)computed (根据计算进行修改) ref 创…...
)
MySQL(基础篇)
DDL (Data Definition Language) 数据定义语言,用来定义数据库对象(数据库,表, 字段) DML (Data Manipulation Languag) 数据操作语言,用来对数据库表中的数据进行增删改 DQL (Data Query Language) 数据查询语言,用…...
springboot中通过jwt令牌校验以及前端token请求头进行登录拦截实战
前言 大家从b站大学学习的项目侧重点好像都在基础功能的实现上,反而一个项目最根本的登录拦截请求接口都不会写,怎么拦截?为什么拦截?只知道用户登录时我后端会返回一个token,这个token是怎么生成的,我把它…...

从零开始开发视频美颜SDK:实现直播美颜效果
因此,开发一款从零开始的视频美颜SDK,不仅可以节省成本,还能根据具体需求进行个性化调整。本文将介绍从零开始开发视频美颜SDK的关键步骤和实现思路。 一、需求分析与技术选型 在开发一款视频美颜SDK之前,首先需要进行详细的需求…...

极验语序点选验证码识别(一)
注意,本文只提供学习的思路,严禁违反法律以及破坏信息系统等行为,本文只提供思路 极验文字点选验证码不必多说,很多小伙伴,借助标注工具或者打码平台标注完数据集后,使用开源的目标检测网络即可完成,欢迎收看我之前的文章: Pytorch利用ddddocr辅助识别点选验证码 或者使…...
什么是 HTTP POST 请求?初学者指南与示范
在现代网络开发领域,理解并应用 HTTP 请求 方法是基本的要求,其中 "POST" 方法扮演着关键角色。 理解 POST 方法 POST 方法属于 HTTP 协议的一部分,主旨在于向服务器发送数据以执行资源的创建或更新。它与 GET 方法区分开来&…...
第一次作业
任务需求:1.DMz区内的服务器,办公区仅能在办公时间内(9-18)可以访问,生产区的设备全天可以访问 2.生产区不允许访问互联网,办公区和游客区可以访问互联网 3.办公区设备10.0.2.10不允许访问DMZ区的FTP服务器和http服务器,仅能ping通…...

【机器学习】12.十大算法之一支持向量机(SVM - Support Vector Machine)算法原理讲解
【机器学习】12.十大算法之一支持向量机(SVM - Support Vector Machine)算法原理讲解 一摘要二个人简介三基本概念四支持向量与超平面4.1 超平面(Hyperplane)4.2 支持向量(Support Vectors)4.3 核技巧&…...

使用 `useAppConfig` :轻松管理应用配置
title: 使用 useAppConfig :轻松管理应用配置 date: 2024/7/11 updated: 2024/7/11 author: cmdragon excerpt: 摘要:本文介绍了Nuxt开发中useAppConfig的使用,它便于访问和管理应用配置,支持动态加载资源、环境配置切换、权限…...
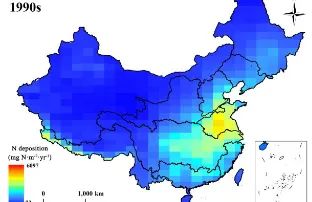
中国内陆水体氮沉降数据集(1990s-2010s)
全球大气氮沉降急剧增加对内陆水生态系统产生不良影响。中国是全球三大氮沉降热点地区之一,为了充分了解氮沉降对中国内陆水体的影响,制定合理的水污染治理方案,我们需要清楚的量化内陆水体的氮沉降通量。为此,我们利用LMDZ-OR-IN…...

qml 实现一个带动画的switch 按钮
一.效果图 》 二.qml 代码 import QtQuick 2.12 import QtQuick.Controls 2.12Switch {id: controlimplicitWidth: 42implicitHeight: 20indicator: Rectangle {id: bkRectangleanchors.fill: parentx: control.leftPaddingy: parent.height / 2 - height / 2radius: height …...
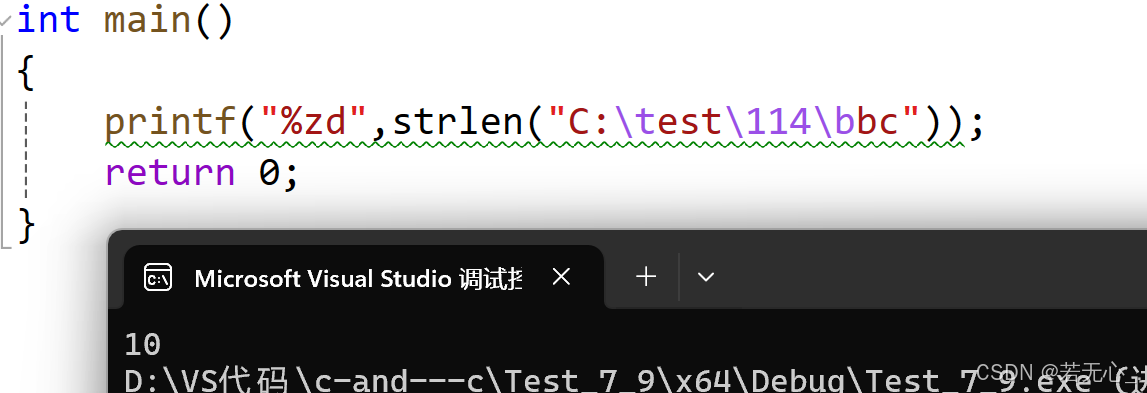
C语言基本概念
C语言是什么? 1.人与人之间 自然语言 2.人与计算机之间 计算机语言 例如C、Java、Go、Python 在计算机语言中 1.解释型语言:Python 2.编译型语言:C/C 编译和链接 C语言源代码都是文本文件.c,必须通过编译器的编译和链接器的…...

高性能Go Web框架Volo:设计原理、核心功能与生产实践
1. 项目概述:一个高性能的Go语言Web框架最近在折腾一个需要处理高并发请求的API服务,选型时又一次把目光投向了Go生态。说实话,Go的Web框架选择不少,从轻量级的Gin、Echo,到功能更全的Beego、Iris,各有各的…...

在 GitHub Actions 中集成 Taotoken 实现大模型 API 自动化调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在 GitHub Actions 中集成 Taotoken 实现大模型 API 自动化调用 将大模型能力集成到自动化工作流中,是提升开发效率的有…...

告别时序噩梦:Vivado的report_qor_suggestions从导出RQS到导入生效全流程避坑指南
告别时序噩梦:Vivado的report_qor_suggestions从导出RQS到导入生效全流程避坑指南 在FPGA设计流程中,时序收敛问题往往成为工程师的"最后一公里"难题。当设计复杂度达到一定规模时,传统的手动优化方式不仅效率低下,还可…...

别再让CPU干苦力了!手把手教你用John The Ripper的GPU加速命令,破解效率翻倍
解锁GPU潜能:John The Ripper高效破解实战指南 在安全测试领域,哈希破解速度往往决定着项目的成败。传统CPU破解方式在面对复杂加密算法时显得力不从心,而现代GPU凭借其并行计算能力,能将破解效率提升数十倍甚至上百倍。本文将带…...

从VS2019调试到IIS部署:一个.NET Core Web API的‘完整旅程’与避坑实录
从VS2019调试到IIS部署:一个.NET Core Web API的‘完整旅程’与避坑实录 当第一次尝试将.NET Core Web API从开发环境部署到生产服务器时,许多开发者都会遇到各种预料之外的挑战。本文将以第一人称视角,详细记录我从零开始创建项目、本地调试…...

2026年光电传感器在不同检测距离中的选型方法与检测距离参数
在自动化产线、物流分拣、包装机械、电子制造等领域,光电传感器的检测距离是选型时最先映入眼帘的参数。然而,很多工程师在实际应用中会发现:标称检测距离为10米的传感器,装上后检测5米的黑色物体就不稳定了;标称0.5米…...

告别乱码困扰:3步完成GBK到UTF-8编码转换的终极指南
告别乱码困扰:3步完成GBK到UTF-8编码转换的终极指南 【免费下载链接】GBKtoUTF-8 To transcode text files from GBK to UTF-8 项目地址: https://gitcode.com/gh_mirrors/gb/GBKtoUTF-8 您是否曾遇到过这样的场景:打开一个中文文档,屏…...

抖音下载器终极指南:3步实现批量无水印下载,提升内容创作效率90%
抖音下载器终极指南:3步实现批量无水印下载,提升内容创作效率90% 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and b…...

别再手动贴图了!LOD1.3建模的智能纹理库怎么用?手把手教你配置大势智慧材质模板
LOD1.3建模革命:智能纹理库的实战配置指南 当清晨的第一缕阳光透过窗户洒在建模师的工作台上,那些曾经需要数小时手动贴图的建筑模型,如今只需几分钟就能自动完成纹理匹配。这不是未来场景,而是LOD1.3建模中智能纹理库技术带来的…...

别再乱选预处理器了!ControlNet 1.1 全模型实战指南:从线稿到3D效果,一次讲清
ControlNet 1.1 预处理器终极选择指南:从草图到成片的智能决策树 当你的手绘线稿在ControlNet中生成出扭曲的五官或崩塌的透视时,问题往往出在预处理器与模型的错配上。本文将通过200次实测对比,拆解14种核心预处理器的隐藏特性,…...