文献翻译与阅读《Integration Approaches for Heterogeneous Big Data: A Survey》
CYBERNETICS AND INFORMATION TECHNOLOGIES’24
论文原文下载地址:原文下载
目录
1 引言
2 大数据概述
3 大数据的异构性
4 讨论整合方法
4.1 大数据仓库(BDW)
4.2 大数据联盟(BDF)
5 DW 和 DF 方法的比较、分析和结论
5.1 BDW:
优点:
缺点
5.2 BDF:
优点:
缺点:
5.3 建议
1 引言
背景:数字技术的发展和各种来源数据的涌入,使处理异构大数据成为企业的一项重要任务[1],而这一任务的核心需要能够合并和评估这些数据,以获得更深入的洞察力和有效的决策[1]。
传统的数据管理方法:无法处理异构数据,也无法处理各种数据源、格式和质量[1]。
因此,企业需要利用先进的数据管理技术[1],采用综合方法。
本文:
- 指出了相关的数据属性,如速度、数量、真实性、多样性和价值
- 举例说明了数据源的异构性,如传感器数据、社交媒体和医疗保健信息。
- 探讨了 现代企业 在管理异构大数据方面 面临的挑战和机遇。
- 提出了异构大数据整合的两种方法:数据仓库和数据联盟。讨论了它们作为整合、管理和分析异构大数据的策略各自的优缺点。
- 对各种大数据的管理进行了调查。深入分析了处理异构大数据的复杂性和可能性。
- 对于希望了解和充分利用异构大数据管理所带来的挑战和机遇的研究人员、专业人士和决策者来说,这是一个资源库,可帮助其做出明智决策和实现商业成功。
2 大数据概述
大数据是指:组织目前正在处理的大量有组织且非结构化数据。
大数据产生来源:传感器、电子商务交易和社交媒体。
随着技术的发展,大数据的产生越来越多,有必要使用更先进的技术对其进行存储、处理和分析。
大数据的主要特征,包括5V:
- Volume [ˈvɒljuːm]:数据量。处理和存储方案有:使用分布式系统和云存储。
- 优势:捕获大规模数据
- 局限:未考虑数据的实用性或质量
- Velocity [vəˈlɒsəti]:数据生成、采集和处理的速度。在实时情况下数据产生的速度很快,必须快速检查这些数据。处理数据方法有:使用流处理和实时分析。
- 优势:捕捉数据处理速度
- 局限:未考虑数据的实用性或质量
- variety [vəˈraɪəti]:数据形式和来源的多样性。大数据包括结构化数据、半结构化数据和非结构化数据。处理数据方法有:自然语言处理和计算机视觉。有人指出,在处理一系列数据格式时,有可能总是得到不准确的结果。
- 优势:捕捉数据的多样性
- 局限:未考虑数据的实用性或质量
- Veracity [vəˈræsəti]:数据的可信度和准确性。确保数据质量和准确性、完整性、可靠性和一致性,要保证数据的可靠性具有很大挑战。处理数据方法有:数据标准化和剖析等现代数据验证和清理流程。文献[36]提出了一种解决方案,可有效处理真实性问题,并显著减少大数据发生的次数。
- 优势:掌握数据的质量和可靠性
- 局限:难以客观衡量
- Value [ˈvæljuː]:数据的商业价值或影响。组织可以通过研究数据发现隐藏的模式和联系。开发 BDAC 能带来更好的决策和结果[39]。要想从数据中获得有意义的见解,分析数据方法有:预测建模和机器学习。分析数据工具和技术有Hadoop、Spark 和 NoSQL 数据库。
- 优势:捕捉数据的有用性
- 局限:难以客观衡量
应用领域:教育、医疗保健、金融、零售、电信和旅游。
庞大的数据集规模与异质性可能性的增加直接相关[62],这种关系是大数据的一个非常重要的方面。
3 大数据的异构性
异构大数据概念:社交媒体数据、传感器数据、金融数据、医疗数据、客户数据、供应链数据、人力资源数据、环境数据、教育数据、交通数据和制造数据等种类繁多的数据被称为异构大数据。
数据来源:结构化、非结构化和多媒体格式等。
处理异构数据的好处:
- 可以全面了解当前的问题
- 根据分析这些不同数据集所获得的见解做出更好的决策[67, 68]。
在处理异构数据时,对来自多种不同格式、结构和模型的数据进行整合是一项挑战[64-66]:
- 要有效管理和分析异构数据,就必须掌握数据管理领域的专门技能、知识和先进技术[67, 69]。
- 在同时管理众多数据类型时,有可能获得不准确的结果[34]。解决因数据集异构性而产生的任何质量问题变得至关重要。
有几项研究强调,为了获得有价值的见解,从而取得商业成功和竞争优势,必须采取综合方法(数据的整合、预处理、分析、管理和语义整合)来释放各种数据源的全部潜力。

4 讨论整合方法
数据集成概念:是指合并和组合来自不同来源和格式的数据,以创建统一、无缝视图的过程[104, 105]。
整合来自程序、数据库和文件系统的数据会给这一过程带来挑战[106]。
整合数据的困难:大量数据来自不同来源,结构各异,且不断变化[107, 108]。
整合数据的挑战:
- 连接记录
- 映射模式
- 融合数据 [109]
- 提取、组合和交换信息以创建全面综合视图等任务
数据集成是一种程序性机制,好处:
- 为组织内部用户使用和访问数据提供便利,提高可访问性,促进对信息的理解
- 防止任何潜在的丢失、确保数据的完整性和质量。
- 有助于将存储在单个数据源中的数据更改与多个额外数据源持续同步[111]。
现有工作:
- [114]:在工业物联网应用领域,提出了一种实时大数据集成解决方案,以解决物联网设备产生的数据异构问题。所提出的解决方案可管理多样化和异构存储库中的数据提取、处理和存储。
- [115]:提出了一种强调数据集成系统特征的方法,但没具体说明不同数据库之间的更新传播控制。使用了两种方法整合数据的解决方案:
- 基于全局数据模式,即使用统一模式整合多个数据库中的数据;
- 基于 “对等”网络概念,即通过对等网络传播更新。
- [116]:强调了数据迁移过程中的数据完整性,并介绍了分类查询语言(CQL),将其作为一种可理解的语言,用于数据传输和与复杂模式的交互。但未提及数据流集成。强调了合并异构数据集工具的必要性。
- [71]:提出了一个框架,可实现对物联网设备和传感器生成的数据进行监控,并将其与历史数据进行整合。方法以 SQL 为基础,旨在提高拥有不同数据模型的分布式数据存储库的可访问性和利用率。此外,该框架还能让用户将物联网(IoT)设备和传感器生成的数据与已有的历史数据集无缝合并,从而增强数据的可访问性和利用率。
- [117-121]:对数据整合的最新方法进行了调查,以解决大数据带来的问题。
- [122]:利用更先进的索引技术实时处理高速数据,使数据更易于分析是个挑战。
- [117]:提出了几个数据集成问题:
- 模式异构,当各种数据源使用不同的模式表示同一主题时,就会出现这种情况。
- 数据冲突,可能是由于数据不完整、数据不正确和过时的数据造成。
- [123]:利用人工智能技术自动合并来自许多来源(结构化或非结构化)的大量数据。旨在根据数据的元数据分析数据,以验证数据的相似性和可行的整合程度。采用了集成模块,其结构具有适应性,便于维护、部署和根据需要集成新的数据模型。
整合方法:包括数据仓库、数据映射和数据联盟[124]。数据仓库和数据联盟是两种主流方案[125]。
4.1 大数据仓库(BDW)
与数据仓库(DW)相比,大数据仓库(BDW)代表着一种进步。
BDW:一种已被采用的用于整合大数据源的方法。包括为转换和加载的多个来源的数据建立一个存储库。
-
- 优点:有助于将多个来源的数据整合到一个数据库中,便于访问和分析
- 为便于整合来自多个来源的异构数据:建立一个强大的分布式数据仓库平台。
传统DW:更适合于有组织的历史数据分析,难以进行横向扩展,因此要确保做到这一点颇具挑战性[128]。
实施 BDW 系统耗时且昂贵的原因是:需要仔细考虑以下几个方面:
- 数据建模
- 复杂的映射
- 复杂的转换程序
现有工作:
- [129, 130]:开发了一种定制 BDW 架构,旨在管理异构数据,实现有效的大数据处理。
- [131, 132]:BDWs 更容易横向发展,并能实时分析数据。
- [133]:提出了一种基于时空 BDW 的干旱数据管理架构。为了将数据加载到 Hadoop 系统中,并行使用了 Apache Flume,以加快数据摄取并提高整个系统的效率。
- [134]:提出了一种支持大数据分析的 BDW 架构,该架构能够自动或半自动地适应需求变化或数据扩展。
- [126]指出,以互补的方式利用 Hadoop、Apache Spark、Data Lake 和 Delta Lake 等大数据技术和工具,可有效增强和支持现有的 DW 系统。
这种集成不仅增强了可扩展性,还有助于降低传统 DW 架构的建设成本。
数据仓库的概念:是一种完善成熟的管理范式,得到了广泛认可方法论的支持。
大数据领域仍处于发展阶段,虽已有几种方法试图处理部分问题,但大数据的全面集成解决方案尚未完全实现。

4.2 大数据联盟(BDF)
大数据联盟是指:将分散在不同地点的数据源的数据进行组合和分析,以创建统一视图,从而进行高级分析和决策的过程[135]。
与将数据整合到一个地方的方法不同,BDF 的目的:将数据保留在其来源中,使其易于在这些来源之间进行探索和分析。
BDF适用场景:数据所有者关注隐私、安全和控制,BDF避免了存储的需要,而存储可能具有挑战性或不可取[136]。
BDF如何有效解决了访问不同数据源的难题:通过将不同数据源映射到 RDF(S)/OWL 本体或关系模式等单一模式中,允许在这种统一模式上运行 SPARQL 或 SQL 等查询 [135]。
现代数据管理系统通常包含:联合查询应答工具 [137]。
联合查询回答的主要目标:创建一种从数据源访问数据的一致方式,而无需在中央存储库中重复数据。
实现这一目标的方法:使用针对联盟内数据源的子查询,并根据预定义规则评估其结果。
跨异构大数据源的数据联盟 在研究和行业中 都是一个活跃的领域。然而,数据联盟系统仍然需要一个基础和既定原则[135]。
现有工作:
- [138] 基于本体的数据访问(OBDA):使用 Spark、Presto 和 OBDA 框架将数据源中的数据结合起来,这样就可以使用 SPARQL 进行查询,利用本体术语持续访问数据类型。
- [139] FEDSA,一种针对执法场景中的查询需求而设计的数据联合解决方案。有助于收集和探索信息。
- [140]:提出了一个框架,其重点是在物联网(IoT)背景下分析数据。这种方法考虑到了物联网系统网络,每个系统都有自己独特的数据模型。
5 DW 和 DF 方法的比较、分析和结论
5.1 BDW:
-
优点:
- 专为管理海量数据集而设计,可扩展性强,
- 可通过横向和纵向扩展选项来处理数据增长。
- 具有实时分析功能,有助于基于数据做出决策。
-
缺点
- 过程非常复杂,要求很高,
- 原因:它需要整合各种来源的数据、进行巨大的数据转换和建模,以确保数据完整性和稳健的管理,这需要付出巨大的努力和额外的实施成本。
5.2 BDF:
-
优点:
- 可以减少数据转换的需要
- 原因:可以从多个来源获取数据,创建一个虚拟的数据画面,而无需进行物理整合。由于它是虚拟的,不需要存储,因此可以降低基础设施的成本。
-
缺点:
- 执行需要从不同来源获取数据的查询时可能会遇到一些困难。


5.3 建议
企业需要:
- 根据各自的目标和预算限制,在这两种数据管理战略之间做出选择。
- 考虑所需的大数据类型,包括
- 基础设施要求
- 实时分析能力
- 可扩展性
- 集成性
- 复杂性
- 实施成本
相关文章:
文献翻译与阅读《Integration Approaches for Heterogeneous Big Data: A Survey》
CYBERNETICS AND INFORMATION TECHNOLOGIES’24 论文原文下载地址:原文下载 目录 1 引言 2 大数据概述 3 大数据的异构性 4 讨论整合方法 4.1 大数据仓库(BDW) 4.2 大数据联盟(BDF) 5 DW 和 DF 方法的比较、分…...

应用最优化方法及MATLAB实现——第3章代码实现
一、概述 在阅读最优方法及MATLAB实现后,想着将书中提供的代码自己手敲一遍,来提高自己对书中内容理解程度,巩固一下。 这部分内容主要针对第3章的内容,将其所有代码实现均手敲一遍,中间部分代码自己根据其公式有些许的…...

django的增删改查,排序,分组等常用的ORM操作
Django 的 ORM(对象关系映射)提供了一种方便的方式来与数据库进行交互。 1. Django模型 在 myapp/models.py 中定义一个示例模型:python from django.db import modelsclass Person(models.Model):name models.CharField(max_length100)age…...

Leetcode Java学习记录——树、二叉树、二叉搜索树
文章目录 树的定义树的遍历中序遍历代码 二叉搜索树 常见二维数据结构:树/图 树和图的区别就在于有没有环。 树的定义 public class TreeNode{public int val;public TreeNode left,right;public TreeNode(int val){this.val val;this.left null;this.right nu…...

华为HCIP Datacom H12-821 卷30
1.单选题 以下关于OSPF协议报文说法错误的是? A、OSPF报文采用UDP报文封装并且端口号是89 B、OSPF所有报文的头部格式相同 C、OSPF协议使用五种报文完成路由信息的传递 D、OSPF所有报文头部都携带了Router-ID字段 正确答案:A 解析: OSPF用IP报文直接封装协议报文,…...
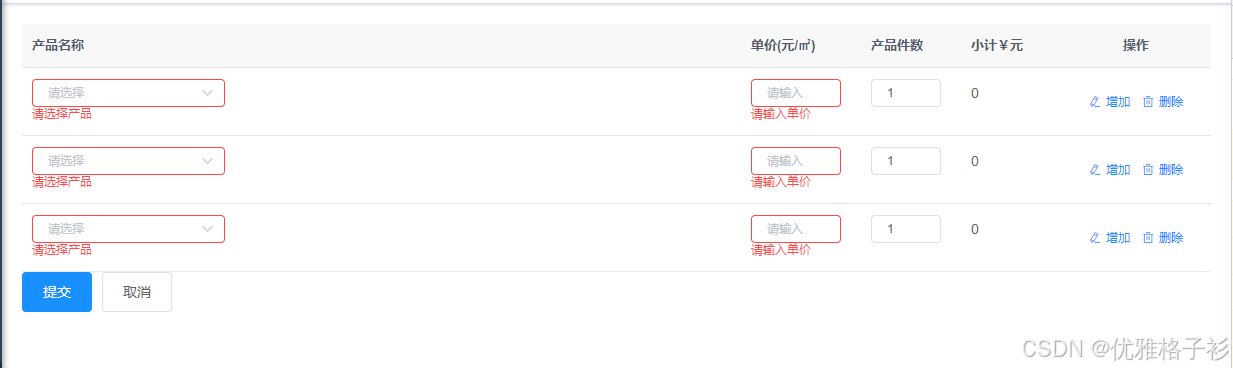
element el-table实现表格动态增加/删除/编辑表格行,带校验规则
本篇文章记录el-table增加一行可编辑的数据列,进行增删改。 1.增加空白行 直接在页面mounted时对form里面的table列表增加一行数据,直接使用push() 方法增加一列数据这个时候也可以设置一些默认值。比如案例里面的 产品件数 。 mounted() {this.$nextTi…...

QT调节屏幕亮度
1、目标 利用QT实现调节屏幕亮度功能:在无屏幕无触控时,将屏幕亮度调低,若有触控则调到最亮。 2、调节亮度命令 目标装置使用嵌入式Linux系统,调节屏幕亮度的指令为: echo x > /sys/class/backlight/backlight/…...

实变函数精解【3】
文章目录 点集求导集 闭集参考文献 点集 求导集 例1 E { 1 / n 1 / m : n , m ∈ N } 1. lim n → ∞ ( 1 / n 1 / m ) 1 / m 2. lim n , m → ∞ ( 1 / n 1 / m ) 0 3. E ′ { 0 , 1 , 1 / 2 , 1 / 3 , . . . . } E\{1/n1/m:n,m \in N\} \\1.\lim_{n \rightar…...

JVM:SpringBoot TomcatEmbeddedWebappClassLoader
文章目录 一、介绍二、SpringBoot中TomcatEmbeddedWebappClassLoader与LaunchedURLClassLoader的关系 一、介绍 TomcatEmbeddedWebappClassLoader 是 Spring Boot 在其内嵌 Tomcat 容器中使用的一个类加载器(ClassLoader)。在 Spring Boot 应用中&#…...

蜂窝互联网接入:连接世界的无缝体验
通过Wi—Fi,人们可以方便地接入互联网,但无线局域网的覆盖范围通常只有10~100m。当我们携带笔记本电脑在外面四处移动时,并不是在所有地方都能找到可接入互联网的Wi—Fi热点,这时候蜂窝移动通信系统可以为我们提供广域…...

Sprint Boot 2 核心功能(一)
核心功能 1、配置文件 application.properties 同基础入门篇的application.properties用法一样 Spring Boot 2 入门基础 application.yaml(或application.yml) 基本语法 key: value;kv之间有空格大小写敏感使用缩进表示层级关系缩进不允…...
GitLab CI/CD实现项目自动化部署
1 GitLab CI/CD介绍 GitLab CI/CD 是 GitLab 中集成的一套用于软件开发的持续集成(Continuous Integration)、持续交付(Continuous Delivery)和持续部署(Continuous Deployment)工具。这套系统允许开发团队…...

阿里云调整全球布局关停澳洲云服务器,澳洲服务器市场如何选择稳定可靠的云服务?
近日,阿里云宣布将关停澳大利亚地域的数据中心服务,这一决定引发了全球云计算行业的广泛关注。作为阿里云的重要海外市场之一,澳洲的数据中心下架对于当地的企业和个人用户来说无疑是一个不小的挑战。那么,在阿里云调整全球布局的…...
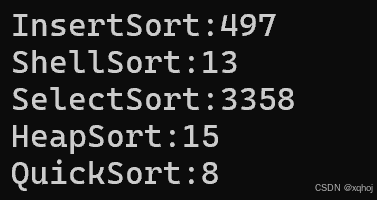
排序(二)——快速排序(QuickSort)
欢迎来到繁星的CSDN,本期内容包括快速排序(QuickSort)的递归版本和非递归版本以及优化。 一、快速排序的来历 快速排序又称Hoare排序,由霍尔 (Sir Charles Antony Richard Hoare) ,一位英国计算机科学家发明。霍尔本人是在发现冒泡排序不够快…...
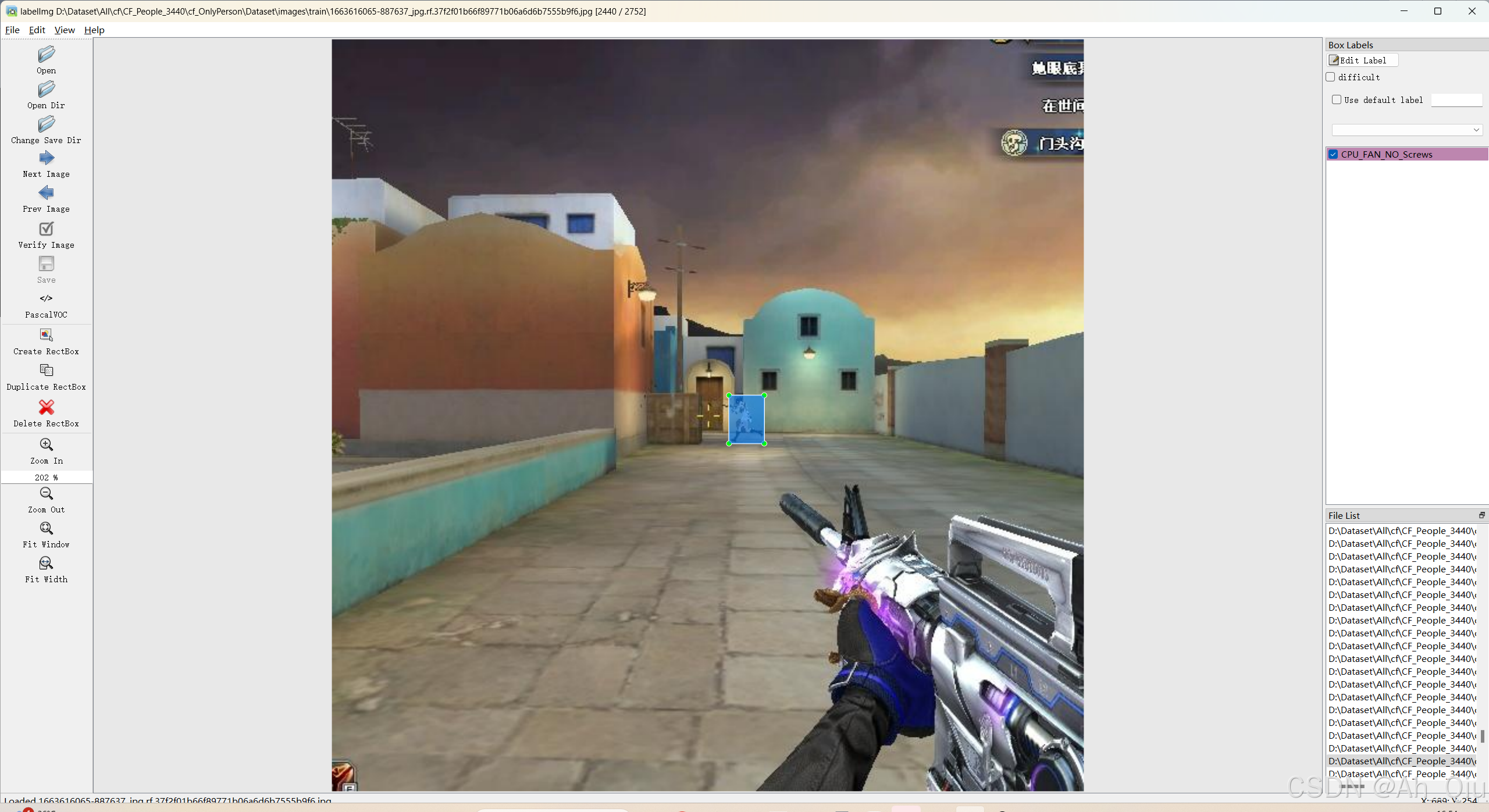
<数据集>穿越火线cf人物识别数据集<目标检测>
数据集格式:VOCYOLO格式 图片数量:3440张 标注数量(xml文件个数):3440 标注数量(txt文件个数):3440 标注类别数:1 标注类别名称:[person] 使用标注工具:labelImg 标注规则:对…...

a+=1和a=a+1的区别
文章目录 a1 和a a1的区别一、实例代码二、代码解释三、总结 a1 和a a1的区别 一、实例代码 public class Test {public static void main(String[] args) {byte a 10; // a a 1; // a (byte) (a 1);a 1;System.out.println(a);} }上面的对变量a进行加一操作时&a…...
)
设计模式使用场景实现示例及优缺点(结构型模式——桥接模式)
结构型模式 桥接模式(Bridge Pattern) 桥接模式(Bridge Pattern)是一种结构型设计模式,其主要目的是“将抽象与实现解耦,使得两者可以独立地变化”。这种模式通过提供抽象化和实现化之间的桥接结构&#…...

Spring——自动装配Bean
自动装配是Spring满足bean依赖的一种方式 Spring会在上下文中自动寻找,并自动给bean装配属性 在Spring中有三种装配的方式: 1. 在xml中显示配置 2. 在java中显示配置 3. 隐式的自动装配bean【重要】 测试 记得创建Cat、Dog、People类 public clas…...

云端典藏:iCloud中个人收藏品目录的智能存储方案
云端典藏:iCloud中个人收藏品目录的智能存储方案 在数字化生活不断推进的今天,个人收藏品的管理也趋向于电子化和云端化。iCloud作为苹果公司提供的云服务,为个人收藏品目录的存储和管理提供了一个安全、便捷、跨设备的解决方案。本文将详细…...

安全开发基础篇-数据溢出
上一节我们简单讲解了多语言的数据类型,我们只需要知道这个概念,并且在不同语言有不同的规矩就好。这节讲数据溢出,严格说应该是字符串溢出和整数溢出。 在软件开发中,字符串和整数溢出漏洞是常见的安全问题,它们可能…...

对比直接使用官方API与通过Taotoken调用的稳定性感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方API与通过Taotoken调用的稳定性感受 1. 引言 在构建依赖大模型能力的应用时,服务的稳定性是开发者必…...

基于Ollama与Streamlit的本地大模型智能对话应用snowChat部署指南
1. 项目概述:一个基于本地大模型的智能对话应用最近在折腾本地部署的大语言模型,发现了一个挺有意思的项目,叫snowChat。这名字听起来就挺“冷”的,但功能却很“热”——它本质上是一个让你能在自己电脑上,用本地的大模…...

为什么你的Linux桌面还缺少一个触手可及的OCR助手?
为什么你的Linux桌面还缺少一个触手可及的OCR助手? 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库…...

猫抓:创新视角下的浏览器资源嗅探技术完全指南
猫抓:创新视角下的浏览器资源嗅探技术完全指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(cat-catch)…...

煤矿智能化通信网络构建:从极端环境挑战到一体化方案实践
1. 项目概述:一次工业通信技术在传统能源领域的深度赋能实践最近刚结束的北京煤炭展,我们迈威通信的展台算是小火了一把。不少行业内的老朋友和新客户过来,聊得最多的不是我们的交换机、网关又出了什么新型号,而是“你们这套东西&…...

Windows 11 下 flash-attention 高效部署:避坑指南与预编译版本实战
1. 为什么Windows 11需要flash-attention? 在深度学习领域,Transformer模型已经成为自然语言处理、计算机视觉等任务的主流架构。而flash-attention作为优化后的自注意力实现,能够显著提升模型训练和推理效率。对于Windows 11用户而言&#…...

基于SpringBoot的广西特色水果电商平台的设计与实现
本课题的选题依据及研究意义 一、选题依据和意义 (一)选题依据 随着互联网经济的深入发展,电子商务在推动全球经济发展中发挥了重要作用。其中生鲜电商已成为农产品销售的重要渠道。广西作为我国热带水果的重要产区,对其传统水果产…...

基于HPM5E00与LAN9252的EtherCAT从站开发板全流程实战
1. 项目概述:从零到一,打造专属的 EtherCAT 从站开发板 最近在工业自动化圈子里,EtherCAT 的热度一直居高不下。它那近乎实时的通讯性能、灵活的拓扑结构,让它在运动控制、机器人、高端数控机床等领域成了“香饽饽”。但很多开发者…...

Taotoken助力初创团队以可控成本构建AI应用原型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken助力初创团队以可控成本构建AI应用原型 对于资源有限的初创团队而言,快速验证AI功能是产品创新的关键一步&…...

如何快速掌握哔哩下载姬:B站视频下载的终极免费解决方案
如何快速掌握哔哩下载姬:B站视频下载的终极免费解决方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&…...