【Python学习笔记】调参工具Optuna + 泰坦尼克号案例
【Python学习笔记】调参工具Optuna&泰坦尼克号案例
背景前摇:(省流可不看)
最近找了份AI标注师的实习,但是全程都在做文本相关的活,本质上还是拧螺丝,就想着学点调参、部署什么的技能增加一些竞争力,以后简历也好包装。
当然找教程首选B站大学了,果然让我搜到了一个好评众多的免费调参工具Optuna。
另外顺便提一句,我做的实习是内容安全方向的文本标注(人话:保证训练集的内容是政治正确的),但我之前看别的视频学习Yolo5做口罩和人脸识别的时候了解到有一款免费的图像标注工具很好用,我自己亲手测试过,安装和使用都很便捷,而且没有任何广告和累赘,主打一个简洁高效。
工具名称:LabelImg
导师之前分享的一篇公众号文章介绍的很全面:
https://mp.weixin.qq.com/s/AE_rJwd9cKQkUGFGD6EfAg
公众号传送门

————————————————————————————————————————————
正文:关于Optuna及学习过程
**视频教程链接:**https://www.bilibili.com/list/watchlater?oid=832000670&bvid=BV1c34y1G7E8&spm_id_from=333.1007.top_right_bar_window_view_later.content.click
B站大神的视频

安装方式:

Anaconda应该也可通过conda安装,我这图省事就直接按视频里面那样pip安装了。
————————————————————————————————————————————
大神使用的Kaggle案例链接:
https://www.kaggle.com/code/yunsuxiaozi/learn-to-use-the-optuna/notebook
传送门

虽然复制粘贴很爽,但为了保持手感+感受细节,建议有时间的还是慢慢手写一遍,哪怕是照着敲,都比直接复制粘贴要好。初学一门技能的时候,慢就是快。
同样,如果电脑上有Anaconda的话,建议建一个专门的虚拟环境来测试Optuna,防止出现冲突现象。
————————————————————————————————————————————
CSDN大神的conda虚拟环境搭建以及jupyter虚拟环境配置教程:
https://blog.csdn.net/fanstering/article/details/123459665
如果没有Anaconda可以跳过此步骤
建立虚拟环境这一步我之前已经很熟了,环境和Optuna包明明install装好了,Jupyter一运行还在报没有Optuna这个库,按照这位大神的教程装了个nb_conda以后问题就解决了。


————————————————————————————————————————————
然后进入熟悉的写代码环节,首先导入需要的几个Python库,缺什么装什么。pip install 或者conda install 都可,有Anaconda的建议后者。
如果他报了一个鬼迷日眼的错误的话: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.read
zhebu
不要怕,只是需要把Jupyter升级一下。


我做完了前三步以后,重新刷新运行这步程序就没事了。

————————————————————————————————

数据集下载链接:https://www.kaggle.com/competitions/titanic/data?select=train.csv
传送门


total_df['Embarked_is_nan']=(total_df['Embarked']!=total_df['Embarked'])
这行代码建了一个新列 ‘Embarked_is_nan’,用于标记 ‘Embarked’ 列中的空值(NaN)。如果 ‘Embarked’ 列中的元素不是它自己(即元素是 NaN),则新列的对应位置将被设为 True。
这种写法我还是第一次见。
keys=['Pclass','Sex','SibSp','Parch']
for key in keys:values=np.unique(train_df[key].values)if len(values)<10 and key!="Survived":print(f"key:{key},values:{values}") key_target=train_df['Survived'].groupby([train_df[key]]).mean()keys=key_target.keys().valuestarget=key_target.valueskey_target=pd.DataFrame({key:keys,key+"_target":target})total_df=pd.merge(total_df,key_target,on=key,how="left")
total_df.head()
这一段代码有点复杂,首先筛选了四个重要特征[‘Pclass’,‘Sex’,‘SibSp’,‘Parch’],存储在keys列表里,这些列被认为可能与乘客的生存情况有关。
然后逐个遍历该列表,看看每个特征在训练集里的数量有多少不重复的值values。
如果某个关键列的唯一值数量len(values)少于10个,代码会进一步分析这个列与生存情况的关系。
(我有点疑惑的是为什么要强调 key!=“Survived”,这个keys列表里本来也没有“Survived”这个取值啊??)
打印出来发现四个属性都满足条件:

key_target=train_df['Survived'].groupby([train_df[key]]).mean()
这一步在训练集train_df当中,代码计算了keys这个列表中,每个唯一值对应的’Survived’列的平均生存率。

由图可见,key_target这个dataframe的值每次循环都随着关键属性的值变化,比如在处理到key = Pclass的时候,key_target的键就是1,2,3,值就是对应的平均生存率;处理到key = sex的时候,key_target的键是‘Female’和‘Male’,值同样是对应的平均生存率。
后续的步骤有一些复杂,画个word表格配合理解一下:
keys里面一共四个属性,每次就拿其中一个来说事,最后把四个属性的数据都存在total_df里面汇总并返回。
这是拿PClass说事的情况,PClass有三个值:1/2/3,针对每个值计算了平均存活率,并保存在key_target中。
然后取出了key_target的键存在keys列表(是的没错这个列表也叫keys……,但此时里面的值应该是PClass的1/2/3这三个取值)里面,值存在target列表里面(即0.629630,0.472826,0.242363这三个数字),然后人为给键和值这两列取名字,键这一列还叫PClass,值这一列比较有个性,要叫‘PClass_target’。

以此类推,后面三个属性的key_target都是这套路,但是total_df这张表一直在扩大。

(male这里是word超界,图截掉了,后面单独补了一块)
直到最后total_df变为一张大表:

说实话,对于一个主要目的是教人怎么使用调参工具的Optuna案例来说,原作者这一步写的逻辑真的很给我增加了理解负担……
我让Kimi把这段代码改写成了一个更加清晰简单的版本,这样不容易混淆这么多满屏的key和target:

这部分不是调参步骤的重点,如果实在搞不明白可以跳过。————————————————————————————————————————————
使用平均值填充缺失值,这学到的数据处理常见步骤,标记一下。

补充:之前上数据分析与Tableau可视化这门课的时候,老师分享的一个帖子专门介绍了很多数据缺失的类型和处理方法:https://towardsdatascience.com/all-about-missing-data-handling-b94b8b5d2184
添加链接描述
帖子是全英文,需要注册登录一下观看。
————————————————————————————————————————————
有了属性更多更全面的数据集total_df以后,按照之前的长度再划分回训练集和测试集。

————————————————————————————————————————————

这里提到训练集和测试集的比例为8:2,即4:1,是一个很常见的划分比例。
原作者这里应该是把test和valid看作一个东西,所以命名没有特别刻意区分。

但实际上这两个概念并不是完全一样(但我看到有时候确实区分得不严格),这里我统一采用了全是test_X和test_y的写法。


————————————————————————————————————————————
导入LGBM回归器,虽然泰坦尼克号数据集用于分类问题(预测一位乘客能否生还)较多,但原作者在这里把他视作回归问题处理。我考虑到作为入门来说,选择数据集简单熟悉、有视频解说的教程容易上手一些,所以没有纠结回归还是分类问题的细节。后续熟练了流程的话可以网上找更多复杂和规范的数据来练习。
补充学习链接:《LGBMRegressor 参数设置 lgbmclassifier参数》
https://blog.51cto.com/u_12219/10333606
添加链接描述
(话说这帖子里不是有LGBM分类器么,为什么作者在视频里要专门提到当回归问题处理呢?)
————————————————————————————————————————————
RMSE作为损失函数,即评估指标,是**计算均方根误差(Root Mean Square Error)**的Python函数,越小越好。

————————————————————————————————————————————
根据原作者视频的讲解设置任务objective的参数:
具体参数名称、含义、建议值可以参考上面那个《LGBMRegressor 参数设置 lgbmclassifier参数》补充学习贴。
def objective(trial):param = {'metric':'rmse','random_state':trial.suggest_int('random_state', 2023, 2023), #随机种子固定,所以设置为2023-2023'n_estimators':trial.suggest_int('n_estimators', 50, 300), #迭代器数量 50-300 的整数'reg_alpha':trial.suggest_loguniform('reg_alpha', 1e-3, 10.0),'reg_lambda':trial.suggest_loguniform('reg_lambda', 1e-3, 10.0), #对数正态分布的建议值'colsample_bytree':trial.suggest_float('colsample_bytree', 0.5, 1), #浮点数'subsample':trial.suggest_float('subsample', 0.5, 1),'learning_rate':trial.suggest_float('learning_rate', 1e-4, 0.1, log = True),'num_leaves':trial.suggest_int('num_leaves', 8, 64), #整数'min_child_samples':trial.suggest_int('min_child_smaples', 1, 100), }model = LGBMRegressor(**param) #调用模型model.fit(train_X, train_y, eval_set = [(test_X, test_y)], early_stopping_rounds = 100, verbose = False) #拟合preds = model.predict(test_X) #计算测试集的损失rmse = RMSE(test_y, preds)return rmse
————————————————————————————————————————————
关键代码:调用Optuna,创建一个学习任务,指定让损失最小,设置任务名称:
#创建的研究命名,找最小值
study = optuna.create_study(direction = 'minimize', study_name = 'Optimize boosting hpyerparameters') #创建了一个Optuna研究对象,用于优化超参数。
#关键代码:调用Optuna,创建一个学习任务,指定让损失最小,设置任务名称。
#目标函数,尝试的次数
study.optimize(objective, n_trials = 100) #将设定好参数的object任务传进来,尝试一百次
#输出最佳的参数
print('Best Trial: ',study.best_trial.params) #找到最佳参数 tudy.best_trial 表示在所有尝试中损失最小的那次试验,params 是一个字典,包含了那次试验中使用的超参数。
lgbm_params = study.best_trial.params #这行代码将最佳参数赋值给 lgbm_params 变量。这样可以将这些参数用于LightGBM模型或其他需要这些超参数的模型。

————————————————————————————————————————————
思路没问题,但我们遇到一个奇怪的报错:fit() got an unexpected keyword argument ‘early_stopping_rounds’:

Kimi的方法试了还是报错,所以,多半又不是该我们背锅。

StackFlow的大神们提供了两个解决方案:
https://stackoverflow.com/questions/76895269/lgbmclassifier-fit-got-an-unexpected-keyword-argument-early-stopping-rounds
传送门


注意最好用pip install的方式,conda install好像装不上。

但我发现并没有什么用……还是报一样的错误,不认识early_stopping_rounds,甚至删掉以后还不认识后面一个参数verbose……
按照前面那个补充的参数帖子改也不行,看来这信息更新有亿点点滞后啊……


————————————————————————————————————————————
顺便搜的过程中还发现一个易错点:这个early_stopping_rounds好像最大也只能顶到100。
https://blog.csdn.net/YangTinTin/article/details/120708391
传送门

————————————————————————————————————————————
我在网上手动搜了一圈加上询问Kimi,暂时还没有找到很有效的替代方案。鉴于我们主要是希望尝试一下Optuna的使用过程,所以先把这俩惹麻烦的参数删去。
model.fit(train_X, train_y, eval_set=[(test_X, test_y)]) #拟合
完整objective代码:
def objective(trial):param = {'metric':'rmse','random_state':trial.suggest_int('random_state', 2023, 2023), #随机种子固定,所以设置为2023-2023'n_estimators':trial.suggest_int('n_estimators', 50, 300), #迭代器数量 50-300 的整数'reg_alpha':trial.suggest_loguniform('reg_alpha', 1e-3, 10.0),'reg_lambda':trial.suggest_loguniform('reg_lambda', 1e-3, 10.0), #对数正态分布的建议值'colsample_bytree':trial.suggest_float('colsample_bytree', 0.5, 1), #浮点数'subsample':trial.suggest_float('subsample', 0.5, 1),'learning_rate':trial.suggest_float('learning_rate', 1e-4, 0.1, log = True),'num_leaves':trial.suggest_int('num_leaves', 8, 64), #整数'min_child_samples':trial.suggest_int('min_child_smaples', 1, 100), }model = LGBMRegressor(**param) #调用模型model.fit(train_X, train_y, eval_set=[(test_X, test_y)]) #拟合preds = model.predict(test_X) #计算测试集的损失rmse = RMSE(test_y, preds)return rmse
然后就可以得到Best_Trial了:

————————————————————————————————————————————
类似的,原UP还用了xgboost和catboost类似方法来找最佳参数。
不难看出,三个不同的方法主要区别是选用的参数param,以及model指定的函数方法。
XGBoost:


XGBoost结果:

————————————————————————————————————————————
CatBoost:


CatBoost结果:

————————————————————————————————————————————
最后使用K折交叉验证得到最佳结果:
交叉验证也是个机器学习常用词。

def accuracy(y_true, y_pred):return np.sum(y_true == y_pred)/len(y_true)




kf 是一个 KFold 对象,它是 scikit-learn 库中用于实现 K 折交叉验证的工具。KFold 将数据集分成 n_splits 个子集,每个子集轮流作为验证集,其余的作为训练集。
for train_index, valid_index in kf.split(x): 这行代码会迭代 KFold 对象,每次迭代返回两个数组:train_index 和 valid_index。train_index 包含了用于训练的数据点的索引,而 valid_index 包含了用于验证的数据点的索引。根据索引到全集X,y里面就能取到每一次的训练集和验证集数据,这个过程好比全班打乱,每次随机抽学号喊几个同学一组。
————————————————————————————————————————————
现在又遇到一个常见bug,虽然我不太知道这是怎么产生的,不知道是不是又该Python背锅。(因为之前X,y数据集的shape和作者是一模一样的,后面按道理也没有另外对他们做什么操作……)



遇到问题不要怕,改!这把要相信Kimi!(顺便一提,我实习的这家做人工智能的公司员工他们自己也用的Kimi,所以Kimi还是比较可信的,而且还免费!!)

别忘了同时把early_stopping_rounds和verbose这俩参数毙了,免得又惹出报错。

这一块代码比较长,重复差不多的地方有点多,注意不要写漏写错了。
from sklearn.model_selection import KFold #在机器学习库中导入k折交叉验证的函数
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
from catboost import CatBoostRegressor def accuracy(y_true,y_pred):return np.sum(y_true==y_pred)/len(y_true)
print("start fit.")
folds = 10 #将数据分成10份
y=train_df['Survived']
X=train_df.drop(['Survived'],axis=1)train_accuracy=[]
valid_accuracy=[]
# 存储已学习模型的列表
models = []#将数据集随机打乱,并分成folds份
kf = KFold(n_splits=folds, shuffle=True, random_state=2023) #从x_train中按照9:1的比例分成训练集和验证集,并取出下标
for train_index, valid_index in kf.split(X):#根据下标取出训练集和验证集的数据x_train_cv = X.iloc[train_index]y_train_cv = y.iloc[train_index]x_valid_cv =X.iloc[valid_index]y_valid_cv = y.iloc[valid_index]model = LGBMRegressor(**lgbm_params)#模型用x_train_cv去训练,用x_train_cv和x_valid_cv一起去评估model.fit(x_train_cv, y_train_cv, eval_set = [(x_train_cv, y_train_cv), (x_valid_cv, y_valid_cv)], #early_stopping_rounds=100,#verbose = 100, #迭代100次输出一个结果)#对训练集进行预测y_pred_train = model.predict(x_train_cv) #对验证集进行预测y_pred_valid = model.predict(x_valid_cv) y_pred_train=(y_pred_train>=0.5)y_pred_valid=(y_pred_valid>=0.5)train_acc=accuracy(y_pred_train,y_train_cv)valid_acc=accuracy(y_pred_valid,y_valid_cv)train_accuracy.append(train_acc)valid_accuracy.append(valid_acc)#将model保存进列表中models.append(model)model = XGBRegressor(**xgb_params)#模型用x_train_cv去训练,用x_train_cv和x_valid_cv一起去评估model.fit(x_train_cv, y_train_cv, eval_set = [(x_train_cv, y_train_cv), (x_valid_cv, y_valid_cv)], #early_stopping_rounds=100,#verbose = 100, #迭代100次输出一个结果)#对训练集进行预测y_pred_train = model.predict(x_train_cv) #对验证集进行预测y_pred_valid = model.predict(x_valid_cv) y_pred_train=(y_pred_train>=0.5)y_pred_valid=(y_pred_valid>=0.5)train_acc=accuracy(y_pred_train,y_train_cv)valid_acc=accuracy(y_pred_valid,y_valid_cv)train_accuracy.append(train_acc)valid_accuracy.append(valid_acc)#将model保存进列表中models.append(model) model = CatBoostRegressor(**cat_params)#模型用x_train_cv去训练,用x_train_cv和x_valid_cv一起去评估model.fit(x_train_cv, y_train_cv, eval_set = [(x_train_cv, y_train_cv), (x_valid_cv, y_valid_cv)], #early_stopping_rounds=100,#verbose = 100, #迭代100次输出一个结果)#对训练集进行预测y_pred_train = model.predict(x_train_cv) #对验证集进行预测y_pred_valid = model.predict(x_valid_cv) y_pred_train=(y_pred_train>=0.5)y_pred_valid=(y_pred_valid>=0.5)train_acc=accuracy(y_pred_train,y_train_cv)valid_acc=accuracy(y_pred_valid,y_valid_cv)train_accuracy.append(train_acc)valid_accuracy.append(valid_acc)#将model保存进列表中models.append(model) print(f"train_accuracy:{train_accuracy}, valid_accuracy:{valid_accuracy}")train_accuracy=np.array(train_accuracy)
valid_accuracy=np.array(valid_accuracy)print(f"mean_train_accuracy: {np.mean(train_accuracy)}")
print(f"mean_valid_accuracy: {np.mean(valid_accuracy)}")
我跟原作者的中间输出有些不一样,不知道差距是什么造成的:


不过好在目前看来,结果还不算太差:


————————————————————————————————————————————
在测试集上测试每个模型的效果:
test_X = test_df.drop(['Survived'], axis = 1).valuespreds_test = []#用每个保存的模型都对x_test预测一次,然后取平均值
for model in models:pred = model.predict(test_X)preds_test.append(pred)
#将预测结果转换为np.array
preds_test_np = np.array(preds_test)#按行对每个模型的预测结果取平均值
test_pred= preds_test_np.mean(axis = 0 )
test_pred=(test_pred >= 0.5).astype(np.int64)
#平均预测值与 0.5 进行比较,根据比较结果(大于等于 0.5 为 True,否则为 False)将每个值转换为二进制形式(即 1 或 0),然后使用 astype(np.int64) 将布尔值转换为 64 位整数类型。
test_pred



看输出的test_pred.shape,不要看这个array长得四四方方的,看他shape还是个一维数组,拥有 418 个元素。
在 Python 中,一维数组的形状通常表示为 (N,),其中 N 是数组中的元素总数。
————————————————————————————————————————————
像test_pred=(test_pred >= 0.5).astype(np.int64) 这句用到的一样,创建新列并且通过比较大小来赋Bool值是True还是False的例子,在这个项目里还有很多:


————————————————————————————————————————————
最后保存并写入CSV文件:
submission=pd.read_csv("D:/StudyFiles/Optuna_Titanic/data/gender_submission.csv") #读取CSV文件,并将其存储在变量submission中
submission['Survived']=test_pred #更新了submission DataFrame中的'Survived'列,使其包含模型预测的生存概率或分类结果。
submission.to_csv("submission.csv",index=None) #将更新后的submission DataFrame保存为一个新的CSV文件"submission.csv"。参数index=None表示在保存CSV文件时不包括行索引。
submission.head()

————————————————————————————————————————————
我会把我的代码包发到CSDN主页,有需要的朋友欢迎自行下载,那我们下一个教程再见吧。

————————————————————————————————————————————
其他相关的学习内容:
(一)**9.1 模型调参【斯坦福21秋季:实用机器学习中文版】:**李沐老师的视频,介绍了一些关于调参的理论,不了解调参的可以看看学习一下基础知识。
https://www.bilibili.com/video/BV1vQ4y1e7LF/?spm_id_from=333.788.recommend_more_video.1&vd_source=cdfd0a0810bcc0bcdbcf373dafdf6a82
传送门
(二)这个自动调参神器简直是太强了!能完全满足机器学习和深度学习调参日常使用!初学者必备工具!:视频内容不如我跟的这个示范视频,主要就是简单讲了一下Optuna,没有实操案例。
https://www.bilibili.com/video/BV1Zs421K7Qj/?spm_id_from=333.788.recommend_more_video.6&vd_source=cdfd0a0810bcc0bcdbcf373dafdf6a82
传送门
不过我对这位UP介绍的这本书很感兴趣,因为对于我这种缺乏经验又喜欢找规律的小白来说,很希望能有一本指导手册给我介绍一些万能公式和方向。

相关文章:
【Python学习笔记】调参工具Optuna + 泰坦尼克号案例
【Python学习笔记】调参工具Optuna&泰坦尼克号案例 背景前摇:(省流可不看) 最近找了份AI标注师的实习,但是全程都在做文本相关的活,本质上还是拧螺丝,就想着学点调参、部署什么的技能增加一些竞争力&a…...

GPT带我学-设计模式13-策略模式
概述 策略模式 例子 你可以创建一个策略工厂(Strategy Factory)来根据传入的 orgId 动态地选择合适的策略。以下是实现示例: 首先,定义策略接口和具体策略类: public interface CardPathStrategy {String generat…...

【Linux】Ubuntu配置JDK环境、MySQL环境
一、 Ubuntu配置JDK环境 在Ubuntu系统中安装JDK 8可以通过以下步骤进行: 打开终端。更新包列表: sudo apt update安装OpenJDK 8: sudo apt install openjdk-8-jdk验证安装是否成功: java -version注:如果系统中安…...

【ElasticSearch】ES 5.6.15 向量插件支持
参考 : https://github.com/lior-k/fast-elasticsearch-vector-scoring 下载插件 安装插件 插件目录: elasticsearch/plugins, 安装后的目录如下 plugins└── vector├── elasticsearch-binary-vector-scoring-5.6.9.jar└── plugin-descriptor.properties修…...
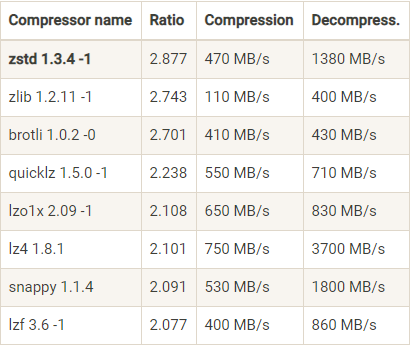
Kafka 高并发设计之数据压缩与批量消息处理
《Kafka 高性能架构设计 7 大秘诀》专栏第 6 章。 压缩,是一种用时间换空间的 trade-off 思想,用 CPU 的时间去换磁盘或者网络 I/O 传输量,用较小的 CPU 开销来换取更具性价比的磁盘占用和更少的网络 I/O 传输。 Kafka 是一个高吞吐量、可扩展…...
)
设计模式使用场景实现示例及优缺点(行为型模式——模板方法模式)
模板方法模式(Template Method Pattern) 模板方法模式(Template Method Pattern)是一种行为设计模式,它定义了一个操作中的算法的骨架,将算法的一些步骤延迟到子类中。这样可以在不改变算法的结构的前提下…...
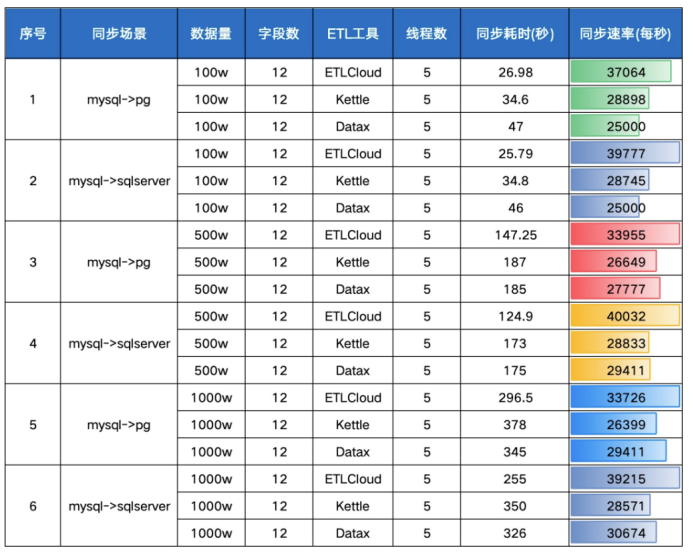
ETL数据集成丨主流ETL工具(ETLCloud、DataX、Kettle)数据传输性能大PK
目前市面上的ETL工具众多,为了方便广大企业用户在选择ETL工具时有一个更直观性能方面的参考值,我们选取了目前市面上最流行的三款ETL工具(ETLCloud、DataX、Kettle)来作为本次性能传输的代表,虽然性能测试数据有很多相…...

eNSP:防火墙设置模拟公司配置(二)
实验拓扑: 实验要求(二): 7: 办公设备可以通过电信连接和移动上网(多对多NAT,并且需要保留一个公网IP) 8: 分公司通过公网移动电信,访问DMZ的http服务器 9&a…...

vue3 两个组件之间传值
Props 父组件可以通过 props 将数据传递给子组件。这是最常见的组件间通信方式 <!-- 父组件 --><template><ChildComponent :message"parentMessage" /></template><script>import ChildComponent from ./ChildComponent.vue;export…...

基于matlab的深度学习案例及基础知识专栏前言
专栏简介 内容涵盖深度学习基础知识、深度学习典型案例、深度学习工程文件、信号处理等相关内容,博客由基于matlab的深度学习案例、matlab基础知识、matlab图像基础知识和matlab信号处理基础知识四部分组成。 一、 基于matlab的深度学习案例 1.1、matlab:基于模…...

机器学习——L1 L2 范数 —>L1 L2正则化
1、L1范数和L2范数是机器学习和数据分析中经常使用的两种范数,它们之间存在多个方面的区别。 以下是关于L1范数和L2范数区别的详细解释: 一、定义差异 L1范数:也被称为曼哈顿范数,是向量元素的绝对值之和。对于一个n维向量x&am…...

大模型时代,还需要跨端framework吗?
跨端 在我近十年的大前端从业经验中,有一半是在和flutter/rn打交道。虽然,flutter和rn官方和社区已经在非常努力的优化、填坑了,但是这两者的坑还是远远高于原生开发。 但是,在锁表的大周期下,华为带着鸿蒙来了&#…...

ASP.NET Core----基础学习05----将数据传递给视图文件的五种情况
文章目录 1. 类型一:使用ViewData将数据传递给视图文件(默认视图文件)2. 类型二:自定义选择视图文件 并传递ViewData数据3. 类型三:使用ViewBag将数据传递给视图文件4. 类型四:在视图文件中使用model转化为…...
Flutter实现局部刷新的几种方式
目录 前言 1.局部刷新的重要性 1.概念 2.重要性 2.局部刷新实现的几种方式 1.使用setState方法进行局部刷新 2.使用StatefulWidget和InheritedWidget局部刷新UI 3.ValueNotifier和ValueListenableBuilder 4.StreamBuilder 5.Provider 6.GetX 7.使用GlobalKey 前言 …...
)
力扣题解(回文子串)
647. 回文子串 给你一个字符串 s ,请你统计并返回这个字符串中 回文子串 的数目。 回文字符串 是正着读和倒过来读一样的字符串。 子字符串 是字符串中的由连续字符组成的一个序列。 思路: 首先,本题要求的是数目,而且不要求没…...

对数的基本概念
概念 在数学中,对数是对求幂的逆运算,正如除法是乘法的倒数,反之亦然。这意味着一个数字的对数是必须产生过另一个固定数字(基数)的指数 如果a的x次方等于N(a > 0, 且a不等于1),那么数x叫做以a为底N的…...

C双指针滑动窗口算法
这也许是双指针技巧的最⾼境界了,如果掌握了此算法,可以解决⼀⼤类⼦字符串匹配的问题 原理 1、我们在字符串 S 中使⽤双指针中的左右指针技巧,初始化 left right 0,把索引闭区间 [left, right] 称为⼀个「窗⼝」。 2、我们先…...
WPF学习(6) -- WPF命令和通知
一 、WPF命令 1.ICommand代码 创建一个文件夹和文件 using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; using System.Windows.Input;namespace 学习.Command {public class MyCommand : ICommand{Acti…...

升级到LVGL9的一些变化(后续发现再补充)
目录 一、主要内容 二、新增内容 三、常规API变化 四、Display API(显示API) 五、其他 最近在将LVGL8的demo代码升级到LVGL9,带来不小的变化 ,收集网上的一些内容,整理如下: 一、主要内容 二、新增内容 三、常规API变化 四、Display API(显示API)...

当在多线程环境中使用 C++进行编程时,怎样确保线程安全以及如何处理线程之间的同步和通信?
在C中确保线程安全性和处理线程之间的同步和通信有多种方法。下面是一些常用的技术和技巧: 互斥锁:使用互斥锁可以确保只有一个线程可以访问共享资源。在访问共享资源之前获取锁,在完成后释放锁。这可以防止多个线程同时访问同一份数据&#…...

Keil MDK许可证错误解决方案与调试技巧
1. 问题现象与背景解析 当使用Keil MDK进行嵌入式开发时,部分用户在编译或调试阶段会遇到"LICENSE: License Mapping Failed"的错误提示。这个报错通常出现在以下两种场景: 编译阶段:在Build Output窗口突然弹出红色错误提示&…...

【Claude教育内容创作黄金法则】:20年教育技术专家亲授5大不可复制的AI协同写作心法
更多请点击: https://kaifayun.com 第一章:Claude教育内容创作的范式革命 传统教育内容生产长期受限于人力密集、周期冗长与个性化不足三大瓶颈。Claude凭借其长上下文理解、结构化输出能力与教育领域微调优势,正推动一场从“经验驱动”到“…...

Unity编辑器AI增强:本地化轻量模型驱动的开发效率升级
1. 不是“接管”,而是编辑器能力的自然延伸:从Unity传统工作流说起你有没有过这样的时刻:在Unity里改完一段C#脚本,保存,切回编辑器,等几秒——然后发现Scene视图没刷新;再点一下Play࿰…...

AArch64架构下非缓存内存的指令缓存机制解析
1. AArch64架构下非缓存正常内存的指令缓存机制解析在Armv8-A和Armv9-A架构的AArch64执行状态下,关于指令缓存(Instruction Cache)如何处理非缓存(Non-cacheable)内存区域的指令访问,存在一个值得深入探讨的技术细节。这个问题直接关系到处理器对内存访问…...

翻译工具:AI跨语言执行任务
翻译工具:AI跨语言执行任务📝 本章学习目标:本章聚焦工具系统,让AI Agent具备丰富的执行能力。通过本章学习,你将全面掌握"翻译工具:AI跨语言执行任务"这一核心主题。一、引言:为什么…...
)
仅限首批200家零售企业获取:2024中国零售Agent成熟度评估矩阵V2.1(含137项能力测评项+自动生成差距报告)
更多请点击: https://codechina.net 第一章:AI Agent零售行业应用 AI Agent 正在重塑零售行业的客户体验、供应链效率与决策智能化水平。通过融合自然语言理解、多步推理、工具调用与记忆机制,AI Agent 不再是单点问答机器人,而是…...

为什么有些论文,答辩老师越听越不敢卡?
很多学生都经历过一种很明显的反差。有些同学一进答辩室, 老师状态特别紧。问题一个接一个; 追问不断; 语气越来越严肃。但还有一种情况。有些同学刚讲几分钟, 现场气氛就明显变了。老师开始点头; 追问越来越少&#x…...

前缀和与差分进阶总结 | 技巧归纳与实战应用
前缀和与差分进阶总结 | 技巧归纳与实战应用 引言 前缀和与差分是数组处理中两种重要且互补的技术。它们看似简单,却在 LeetCode 和实际工程中有着广泛的应用。前缀和将区间查询从 O(n) 优化到 O(1),差分将区间更新从 O(n) 优化到 O(1)。两者的结合使用可…...
:信息收集介绍,域名信息收集,主域名查询,ICP备案号查询,备案实体查询,工业和信息化部政务服务平台查询,怎样收集)
【Web安全】-企业资产信息收集(1):信息收集介绍,域名信息收集,主域名查询,ICP备案号查询,备案实体查询,工业和信息化部政务服务平台查询,怎样收集
🦆 个人主页:深邃- ❄️专栏传送门:《C语言》《数据结构与算法》《Web安全》 🌟Gitee仓库:《C语言》《数据结构与算法》 特此声明:本次信息收集均在日期授权时间内收集,并且都将所有人员信息打…...

原来训大模型,就像开一家小餐馆!
你是不是一直觉得,训练大语言模型是 OpenAI、百度这种大厂才能干的事?要几万张显卡,要花几个亿,普通人想都不敢想? 错了!我用自己开发机上的 8 张 H20 显卡,花了点时间,从零开始训了…...