DepthAnything(2): 基于ONNXRuntime在ARM(aarch64)平台部署DepthAnything
DepthAnything(1): 先跑一跑Depth Anything_depth anything离线怎么跑-CSDN博客
目录
1. 写在前面
2. 安装推理组件
3. 生成ONNX
4. 准备ONNXRuntime库
5. API介绍
6. 例程
1. 写在前面
DepthAnything是一种能在任何情况下处理任何图像的简单却又强大的深度估计模型。
2. 安装推理组件
针对有GPU加持的场景,以NVIDIA显卡为例,首先需要安装GPU驱动。
然后再安装CUDA、cuDNN和ONNX Runtime,一般情况下,在有显卡的系统中,我们选择GPU版本。
进入如下链接,可以查看CUDA、cuDNN、ONNX Runtime库的版本对应关系。
NVIDIA - CUDA | onnxruntime
如下所示,ONNX Runtime与CUDA、cuDNN的版本需要匹配,否则可能出现我发调用GPU进行推理。

针对没有GPU的场景,我们使用CPU进行推理。可直接下载相应平台的onnx-runtime库。
3. 生成ONNX
使用DepthAnything训练工程下的export_onnx.py文件导出ONNX模型。
注意,导出的时候,需要注意分辨率,DepthAnything到处分辨率必须是14的整数倍。
另外,如果导出分辨率过小,可能会导致识别的深度图失效,因此一般建议导出时,分辨率选择518*518。
导出onnx模型参考代码如下。
import argparseimport torchfrom onnx import load_model, save_modelfrom onnxruntime.tools.symbolic_shape_infer import SymbolicShapeInferencefrom depth_anything.dpt import DPT_DINOv2def parse_args() -> argparse.Namespace:parser = argparse.ArgumentParser()parser.add_argument("--model",type=str,choices=["s", "b", "l"],required=True,help="Model size variant. Available options: 's', 'b', 'l'.",)parser.add_argument("--output",type=str,default=None,required=False,help="Path to save the ONNX model.",)return parser.parse_args()def export_onnx(model: str, input: str, output: str = None):# Handle argsif output is None:output = f"weights/depth_anything_vit{model}14_ori.onnx"# Device for tracing (use whichever has enough free memory)device = torch.device("cpu")# Sample image for tracing (dimensions don't matter)image = torch.rand(1, 3, 518, 518).to(device) # [SAI-KEY] 必须是14的倍数# Load model paramsif model == "s":depth_anything = DPT_DINOv2(encoder="vits", features=64, out_channels=[48, 96, 192, 384])elif model == "b":depth_anything = DPT_DINOv2(encoder="vitb", features=128, out_channels=[96, 192, 384, 768])else: # model == "l"depth_anything = DPT_DINOv2(encoder="vitl", features=256, out_channels=[256, 512, 1024, 1024])weights = torch.load(input)depth_anything.to(device).load_state_dict(weights)depth_anything.eval()torch.onnx.export(depth_anything,image,output,input_names=["image"], # 列表,如果有多个输入,应按照顺序,依次output_names=["depth"],opset_version=12,)save_model(SymbolicShapeInference.infer_shapes(load_model(output), auto_merge=True),output,)if __name__ == "__main__":export_onnx("l", "/2T/001_AI/8001_DepthAnything/003_Models/checkpoints/depth_anything_vitl14.pth", "/2T/001_AI/8001_DepthAnything/003_Models/checkpoints/depth_anything_vitl14.onnx")4. 准备ONNXRuntime库
登录链接https://github.com/microsoft/onnxruntime/releases下载相应的ONNX Runtime推理库。如下所示,可选择linux、windows、osx系统下的库,以及选择x86或aarch64架构的库。需要说明的是,aarch64目前仅支持CPU版本。

不同系统的库,引入方式也不同。
例如,下载onnxruntime-linux-aarch64-1.18.1.tgz库,解压后可以将其中lib文件夹下的libonnxruntime.so和libonnxruntime.so.1.18.1复制到/usr/lib路径下。
include头文件可移动可不移动,也可重命名后,加入到工程中。如果需要添加到工程中,需要注意Makefile中的包含项。
如果是下载的windows平台的库,一般是include文件和dll链接库,按照不同IDE的引入方式来就可以。
5. API介绍
本小节简单介绍几个API,具体使用可以参照后续小节的例程加以探索和理解。
(1)Ort::Env(ORT_LOGGING_LEVEL_WARNING, "depthAnything_mono");
ORT_LOGGING_LEVEL_VERBOSE:最详细的日志信息,包括所有信息。
ORT_LOGGING_LEVEL_INFO:一般的信息,例如模型加载和推理进度。
ORT_LOGGING_LEVEL_WARNING:警告级别的日志,例如潜在的问题或性能下降,仅输出警告日志。
ORT_LOGGING_LEVEL_ERROR:错误级别的日志,例如无法恢复的错误。
ORT_LOGGING_LEVEL_FATAL:致命错误,通常是程序无法继续执行的错误。
(2)OrtSessionOptionsAppendExecutionProvider_CUDA(session_options, 0); ///< 相当于指定执行后端,如果不指定,则默认使用CPU
参数1:
参数2:设备号
(3)GetInputCount()和GetOutputCount()
获得输入和输出的数量。
(4)GetInputTypeInfo(i)
获取第i个输入的信息。
(5)GetShape()
获取输入或输出的shape信息。
6. 例程
以下例程以DepthAnything利用ONNXRuntime与OpenCV实现对一张图片的深度估计、并将结果存储到本地。
#include <assert.h>#include <vector>#include <ctime>#include <iostream>#include <chrono>#include <onnxruntime_cxx_api.h>#include <opencv2/core.hpp>#include <opencv2/imgproc.hpp>#include <opencv2/highgui.hpp>#include <opencv2/videoio.hpp>using namespace cv;using namespace std;int input_width = 518;int input_height = 518;class DepthAnything{public:DepthAnything(std::string onnx_model_path);std::vector<float> predict(std::vector<float>& input_data, int batch_size = 1, int index = 0);cv::Mat predict(cv::Mat& input_tensor, int batch_size = 1, int index = 0);private:Ort::Env env;Ort::Session session;Ort::AllocatorWithDefaultOptions allocator;std::vector<const char*>input_node_names = {"image"}; ///< 生成onnx时的输入节点名std::vector<const char*>output_node_names = {"depth"}; ///< 生成onnx时的输出节点名std::vector<int64_t> input_node_dims;std::vector<int64_t> output_node_dims;};DepthAnything::DepthAnything(std::string onnx_model_path) :session(nullptr), env(nullptr){/** 初始化ORT环境. */this->env = Ort::Env(ORT_LOGGING_LEVEL_WARNING, "DepthAnything_ORT");/** 初始化ORT会话选项. */Ort::SessionOptions session_options;// session_options.SetInterOpNumThreads(1);session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_BASIC); ///< ORT_ENABLE_ALL/** 初始化ORT会话. */this->session = Ort::Session(env, onnx_model_path.data(), session_options);/** 输入输出节点数量. */size_t num_input_nodes = session.GetInputCount();size_t num_output_nodes = session.GetOutputCount();for (int i = 0; i < num_input_nodes; i++){Ort::TypeInfo type_info = session.GetInputTypeInfo(i);auto tensor_info = type_info.GetTensorTypeAndShapeInfo();ONNXTensorElementDataType type = tensor_info.GetElementType();this->input_node_dims = tensor_info.GetShape();for(int i=0; i<this->input_node_dims.size(); i++){printf("shape[%d]: %d\n", i, this->input_node_dims[i]);}}for (int i = 0; i < num_output_nodes; i++){Ort::TypeInfo type_info = session.GetOutputTypeInfo(i);auto tensor_info = type_info.GetTensorTypeAndShapeInfo();ONNXTensorElementDataType type = tensor_info.GetElementType();this->output_node_dims = tensor_info.GetShape();}}std::vector<float> DepthAnything::predict(std::vector<float>& input_tensor_values, int batch_size, int index){this->input_node_dims[0] = batch_size;this->output_node_dims[0] = batch_size;float* floatarr = nullptr;std::vector<const char*>output_node_names;if (index != -1){output_node_names = { this->output_node_names[index] };}else{output_node_names = this->output_node_names;}this->input_node_dims[0] = batch_size;auto input_tensor_size = input_tensor_values.size();/** 创建Tensor对象. */auto memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault); ///< 创建CPU内存信息Ort::Value input_tensor = Ort::Value::CreateTensor<float>(memory_info, input_tensor_values.data(), input_tensor_size, input_node_dims.data(), 4); ///< 创建输入张量/** 执行推理. */auto output_tensors = session.Run(Ort::RunOptions{ nullptr }, input_node_names.data(), &input_tensor, 1, output_node_names.data(), 1);assert(output_tensors.size() == 1 && output_tensors.front().IsTensor());floatarr = output_tensors[0].GetTensorMutableData<float>(); ///< 获取输出张量int64_t output_tensor_size = 1;for (auto& it : this->output_node_dims){output_tensor_size *= it;}std::vector<float>results(output_tensor_size);for (unsigned i = 0; i < output_tensor_size; i++){results[i] = floatarr[i];}return results;}cv::Mat DepthAnything::predict(cv::Mat& input_tensor, int batch_size, int index){int input_tensor_size = input_tensor.cols * input_tensor.rows * 3;std::size_t counter = 0;std::vector<float>input_data(input_tensor_size);std::vector<float>output_data;/** 转换RGB Planar, 归一化. */for (unsigned k = 0; k < 3; k++){for (unsigned i = 0; i < input_tensor.rows; i++){for (unsigned j = 0; j < input_tensor.cols; j++){input_data[counter++] = static_cast<float>(input_tensor.at<cv::Vec3b>(i, j)[k]) / 255.0;}}}/** 推理. */output_data = this->predict(input_data);/** 后处理. */cv::Mat output_tensor(output_data);output_tensor =output_tensor.reshape(1, {input_width, input_height});double minVal, maxVal;cv::minMaxLoc(output_tensor, &minVal, &maxVal); ///< 获取最大值、最小值.output_tensor.convertTo(output_tensor, CV_32F); ///< 转换数据类型,float32类型.if (minVal != maxVal) {output_tensor = (output_tensor - minVal) / (maxVal - minVal);}output_tensor *= 255.0;output_tensor.convertTo(output_tensor, CV_8UC1); ///< 转单通道(灰度图).cv::applyColorMap(output_tensor, output_tensor, cv::COLORMAP_HOT); ///< 伪彩映射.return output_tensor;}std::chrono::time_point<std::chrono::high_resolution_clock> tic;std::chrono::time_point<std::chrono::high_resolution_clock> toc;std::chrono::milliseconds elapsed;int main(int argc, char* argv[]){std::string model_path = "/zqpe/8001_DepthAnything_OnnxRuntime/out/bin/depth_anything_vits14.onnx";std::string image_path = "/zqpe/8001_DepthAnything_OnnxRuntime/out/bin/204995.jpg";printf("Construct depth anything inference engine.\n");tic = std::chrono::high_resolution_clock::now();DepthAnything model(model_path);toc = std::chrono::high_resolution_clock::now();elapsed = std::chrono::duration_cast<std::chrono::milliseconds>(toc - tic);printf("Construct depth anything inference engine, takes %ld ms\n", elapsed.count());printf("Prepare sample.\n");tic = std::chrono::high_resolution_clock::now();cv::Mat image = cv::imread(image_path);auto ori_h = image.cols;auto ori_w = image.rows;// cv::imshow("image", image);cv::cvtColor(image, image, cv::COLOR_BGR2RGB);cv::resize(image, image, {input_width, input_height}, 0.0, 0.0, cv::INTER_CUBIC);toc = std::chrono::high_resolution_clock::now();elapsed = std::chrono::duration_cast<std::chrono::milliseconds>(toc - tic);printf("Prepare sample, takes %ld ms\n", elapsed.count());cv::Mat result;// while(1){printf("Do inference.\n");tic = std::chrono::high_resolution_clock::now();result = model.predict(image);toc = std::chrono::high_resolution_clock::now();elapsed = std::chrono::duration_cast<std::chrono::milliseconds>(toc - tic);printf("Do inference, takes %ld ms\n", elapsed.count());// }cv::resize(result, result, {ori_h, ori_w}, 0.0, 0.0, cv::INTER_CUBIC);printf("Save result.\n");int pos = image_path.rfind(".");image_path.insert(pos, "_depth");cv::imwrite(image_path, result);}相关文章:
DepthAnything(2): 基于ONNXRuntime在ARM(aarch64)平台部署DepthAnything
DepthAnything(1): 先跑一跑Depth Anything_depth anything离线怎么跑-CSDN博客 目录 1. 写在前面 2. 安装推理组件 3. 生成ONNX 4. 准备ONNXRuntime库 5. API介绍 6. 例程 1. 写在前面 DepthAnything是一种能在任何情况下处理任何图像的简单却又强大的深度估计模型。 …...

JAVA简单封装UserUtil
目录 思路 一、TokenFilterConfiguration 二、FilterConfig 三、TokenContextHolder 四、TokenUtil 五、UserUtil 思路 配置Token过滤器(TokenFilterConfiguration):实现一个Token过滤器配置,用于拦截HTTP请求,从请求头中提取Token&…...

【TOOLS】Chrome扩展开发
Chrome Extension Development 1. 入门教程 入门案例,可以访问【 谷歌插件官网官方文档 】查看官方入门教程,这里主要讲解大概步骤 Chrome Extenson 没有固定的脚手架,所以项目的搭建需要根据开发者自己根据需求搭建项目(例如通过…...

分享WPF的UI开源库
文章目录 前言一、HandyControl二、AduSkin三、Adonis UI四、Panuon.WPF.UI五、LayUI-WPF六、MahApps.Metro七、MaterialDesignInXamlToolkit八、FluentWPF九、DMSkin总结 前言 分享WPF的UI开源库。 一、HandyControl HandyControl是一套WPF控件库,它几乎重写了所…...
[ACM独立出版]2024年虚拟现实、图像和信号处理国际学术会议(ICVISP 2024)
最新消息ICVISP 2024-已通过ACM出版申请投稿免费参会,口头汇报或海报展示(可获得相应证明证书) ————————————————————————————————————————— [ACM独立出版]2024年虚拟现实、图像和信号处理国际学术会议(ICVI…...

JVM:类加载器
文章目录 一、什么是类加载器二、类加载器的应用场景三、类加载器的分类1、分类2、启动类加载器3、Java中的默认类加载器(1)扩展类加载器(2)应用程序类加载器(3)arthas中类加载器相关的功能 四、双亲委派机…...

支持向量机 (support vector machine,SVM)
支持向量机 (support vector machine,SVM) flyfish 支持向量机是一种用于分类和回归的机器学习模型。在分类任务中,SVM试图找到一个最佳的分隔超平面,使得不同类别的数据点在空间中被尽可能宽的间隔分开。 超平面方…...

宝塔面板以www用户运行composer
方式一 执行命令时指定www用户 sudo -u www composer update方式二 在网站配置中的composer选项卡中选择配置运行...

昇思25天打卡营-mindspore-ML- Day24-基于 MindSpore 实现 BERT 对话情绪识别
学习笔记:基于MindSpore实现BERT对话情绪识别 算法原理 BERT(Bidirectional Encoder Representations from Transformers)是由Google于2018年开发的一种预训练语言表示模型。BERT的核心原理是通过在大量文本上预训练深度双向表示࿰…...

【精品资料】模块化数据中心解决方案(33页PPT)
引言:模块化数据中心解决方案是一种创新的数据中心设计和部署策略,旨在提高数据中心的灵活性、可扩展性和效率。这种方案通过将数据中心的基础设施、计算、存储和网络资源封装到标准化的模块中,实现了快速部署、易于管理和高效运维的目标 方案…...

N6 word2vec文本分类
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊# 前言 前言 上周学习了训练word2vec模型,这周进行相关实战 1. 导入所需库和设备配置 import torch import torch.nn as nn import torchvision …...
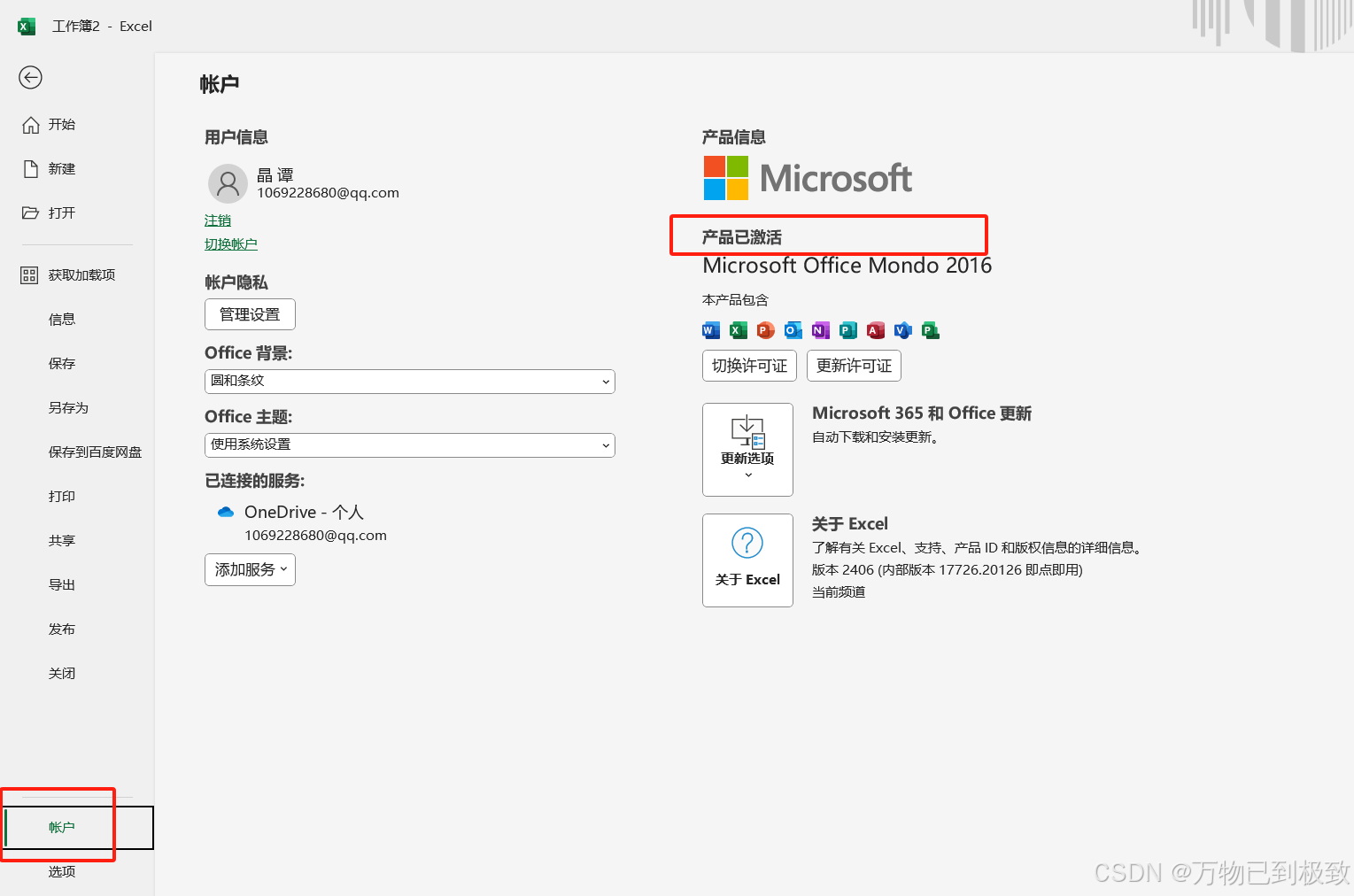
excel、word、ppt 下载安装步骤整理
请按照我的步骤开始操作,注意以下截图红框标记处(往往都是需要点击的地方) 第一步:下载 首先进入office下载网址: otp.landian.vip 然后点击下载 拉到下方 下载站点(这里根据自己的需要选择下载&#x…...

【python学习】标准库之日期和时间库定义、功能、使用场景和示例
引言 datetime模块最初是由 Alex Martelli 在 Python 2.3 版本引入的,目的是为了解决之前版本中处理日期和时间时存在的限制和不便 在datetime模块出现之前,Python 主要使用time模块来处理时间相关的功能,但 time模块主要基于 Unix 纪元时间&…...

Android --- Kotlin学习之路:基础语法学习笔记
------>可读可写变量 var name: String "Hello World";------>只读变量 val name: String "Hello World"------>类型推断 val name: String "Hello World" 可以写成 val name "Hello World"------>基本数据类型 1…...
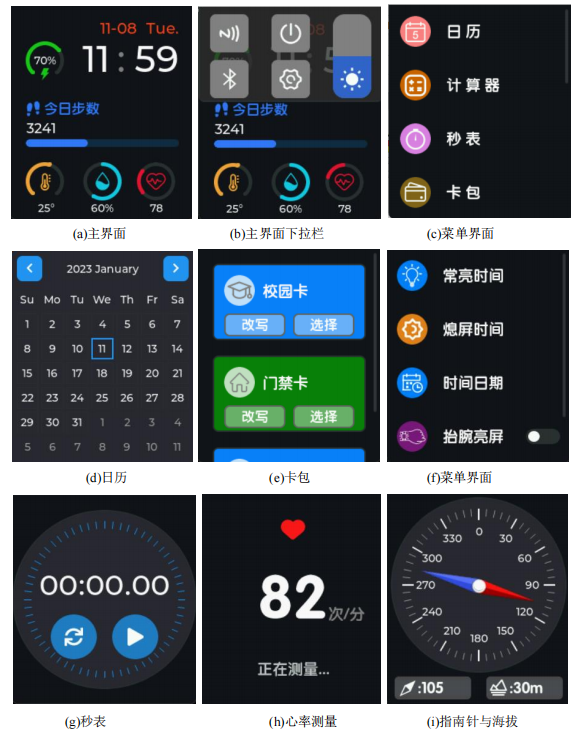
嵌入式智能手表项目实现分享
简介 这是一个基于STM32F411CUE6和FreeRTOS和LVGL的低成本的超多功能的STM32智能手表~ 推荐 如果觉得这个手表的硬件难做,又想学习相关的东西,可以试下这个新出的开发板,功能和例程demo更多!FriPi炸鸡派STM32F411开发板: 【STM32开发板】 FryPi炸鸡派 - 嘉立创EDA开源硬件平…...

`nmap`模块是一个用于与Nmap安全扫描器交互的库
在Python中,nmap模块是一个用于与Nmap安全扫描器交互的库。Nmap(Network Mapper)是一个开源工具,用于发现网络上的设备和服务。虽然Python的nmap模块可能不是官方的Nmap库(因为Nmap本身是用C/C编写的)&…...

JVM系列 | 对象的创建与存储
JVM系列 | 对象的生命周期1 对象的创建与存储 文章目录 前言对象的创建过程内存空间的分配方式方式1 | 指针碰撞方式2 | 空闲列表 线程安全问题 | 避免空间冲突的方式方式1 | 同步处理(加锁)方式2 | 本地线程分配缓存 对象的内存布局Part1 | 对象头Mark Word类型指针…...

【JavaScript 算法】快速排序:高效的排序算法
🔥 个人主页:空白诗 文章目录 一、算法原理二、算法实现三、应用场景四、优化与扩展五、总结 快速排序(Quick Sort)是一种高效的排序算法,通过分治法将数组分为较小的子数组,递归地排序子数组。快速排序通常…...

Excel如何才能忽略隐藏行进行复制粘贴?
你有没有遇到这样的情况:数据很多,将一些数据隐藏后,进行复制粘贴,结果发现粘贴后的内容仍然将整个数据都显示出来了!那么,Excel如何才能忽略隐藏行进行复制粘贴? 打开你的Excel表格 Excel如何…...

行人越界检测 越线 越界区域 多边形IOU越界判断
行人越界判断 越界判断方式:(1)bbox中心点越界(或自定义)(2)交并比IoU判断 越界类型:(1)越线 (2)越界区域 1.越线判断 bbox中心点xc、…...

瑞芯微RK3568与RK3566芯片选型指南:从接口差异到应用场景深度解析
1. 项目概述:为何要深挖这两颗“芯”?在嵌入式开发和智能硬件选型的圈子里,瑞芯微(Rockchip)的RK3568和RK3566是近两年曝光率极高的两颗“明星”芯片。很多刚接触的朋友第一眼看去,会觉得它们很像ÿ…...

如何通过NVIDIA Profile Inspector深度优化游戏性能:解锁显卡隐藏设置的完整指南
如何通过NVIDIA Profile Inspector深度优化游戏性能:解锁显卡隐藏设置的完整指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 你是否曾经感到困惑,为什么同样的显卡配置&…...

从需求到上线仅48小时,Lovable无代码交付全流程拆解,含客户验收话术与交付Checklist
更多请点击: https://codechina.net 第一章:从需求到上线仅48小时,Lovable无代码交付全流程拆解,含客户验收话术与交付Checklist 极速交付的核心逻辑 Lovable 平台通过「场景模板 可视化逻辑编排 API 低侵入集成」三重能力压缩…...

如何永久激活IDM?免费IDM激活脚本终极指南
如何永久激活IDM?免费IDM激活脚本终极指南 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script 还在为IDM试用期到期而烦恼吗?IDM Activation …...

微生物网络分析终极指南:如何用NetCoMi轻松解锁微生物互作密码
微生物网络分析终极指南:如何用NetCoMi轻松解锁微生物互作密码 【免费下载链接】NetCoMi Network construction, analysis, and comparison for microbial compositional data 项目地址: https://gitcode.com/gh_mirrors/ne/NetCoMi 还在为复杂的微生物组数据…...

装配骨架:每一帧重新构建简笔人物,文本围绕当前姿势环绕显示
【导语:资讯介绍了装配骨架的相关情况,包括每一帧重新构建简笔人物,文本围绕当前姿势环绕显示,还有波浪动画等视觉效果及闲置状态。】简笔人物的帧构建在装配骨架的过程中,每一帧都会依据基本的排除部分重新构建一个简…...

CV产线MLOps平台:图像原生处理与硬件感知交付
1. 项目概述:这不是又一个“模型训练平台”,而是一套能真正跑通CV产线的MLOps工作流“Streamline Your Computer Vision Stack with an End-to-End MLOps Platform”——这个标题里藏着三个被太多团队长期忽视的关键事实:第一,“C…...

利用Taotoken模型广场为不同AI任务选择最佳模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken模型广场为不同AI任务选择最佳模型 在实际开发中,我们常常面临一个选择:面对内容生成、代码编…...

Unity 2D基础:2D相机Orthographic的参数调节
Unity 2D基础:2D相机Orthographic的参数调节📚 本章学习目标:深入理解2D相机Orthographic的参数调节的核心概念与实践方法,掌握关键技术要点,了解实际应用场景与最佳实践。本文属于《Unity工程师成长之路教程》Unity 2…...

从零到精通:Path of Building PoE2构建规划完全指南
从零到精通:Path of Building PoE2构建规划完全指南 【免费下载链接】PathOfBuilding-PoE2 项目地址: https://gitcode.com/GitHub_Trending/pa/PathOfBuilding-PoE2 你是否曾经在《流放之路2》中投入大量资源打造角色,却发现伤害不足、生存堪忧…...