GPT-4从0到1搭建一个Agent简介

GPT-4从0到1搭建一个Agent简介
1. 引言
在人工智能领域,Agent是一种能够感知环境并采取行动以实现特定目标的系统。本文将简单介绍如何基于GPT-4搭建一个Agent。
2. Agent的基本原理
Agent的核心是感知-行动循环(Perception-Action Loop),该循环可以描述如下:
- 感知:Agent通过传感器获取环境信息。
- 决策:基于感知到的信息和内部状态,Agent选择一个行动。
- 行动:Agent通过执行器作用于环境。
这可以用下列公式表示:
a t = π ( s t ) a_t = \pi(s_t) at=π(st)
其中:
- a t a_t at 表示在时间 t t t 采取的行动。
- π \pi π 表示策略函数。
- s t s_t st 表示在时间 t t t 的状态。
3. 基于GPT-4的Agent架构
GPT-4 是一种强大的语言模型,可以用于构建智能Agent。其主要步骤包括:
- 输入处理:接收并处理输入。
- 决策生成:基于输入生成响应或行动。
- 输出执行:执行或输出响应。
4. 环境搭建
4.1 安装必要的库
pip install openai
4.2 初始化GPT-4
import openaiopenai.api_key = 'YOUR_API_KEY'def generate_response(prompt):response = openai.Completion.create(engine="gpt-4",prompt=prompt,max_tokens=150)return response.choices[0].text.strip()
5. 感知模块
感知模块用于接收环境信息。在这个例子中,我们假设环境信息是自然语言描述。
def perceive_environment(input_text):# 处理输入文本,将其转换为状态描述state = {"description": input_text}return state
6. 决策模块
决策模块基于当前状态生成行动。在这里,我们使用GPT-4生成响应作为行动。
def decide_action(state):prompt = f"Based on the following state: {state['description']}, what should the agent do next?"action = generate_response(prompt)return action
7. 行动模块
行动模块负责执行决策。在这个例子中,我们简单地打印生成的响应。
def act(action):print(f"Agent action: {action}")
8. 整合与执行
将上述模块整合在一起,形成完整的Agent。
def run_agent(input_text):state = perceive_environment(input_text)action = decide_action(state)act(action)# 示例执行
input_text = "The room is dark and you hear strange noises."
run_agent(input_text)
9. 深度解析
9.1 感知-决策-行动循环的数学模型
在强化学习中,这一过程可以形式化为马尔可夫决策过程(MDP),用以下四元组表示:
⟨ S , A , P , R ⟩ \langle S, A, P, R \rangle ⟨S,A,P,R⟩
其中:
- S S S 是状态空间。
- A A A 是行动空间。
- P P P 是状态转移概率函数 P ( s ′ ∣ s , a ) P(s'|s, a) P(s′∣s,a)。
- R R R 是奖励函数 R ( s , a ) R(s, a) R(s,a)。
对于每一个状态 s t s_t st 和行动 a t a_t at,目标是最大化预期回报:
G t = ∑ k = 0 ∞ γ k r t + k G_t = \sum_{k=0}^{\infty} \gamma^k r_{t+k} Gt=k=0∑∞γkrt+k
其中:
- γ \gamma γ 是折扣因子。
- r t r_t rt 是在时间 t t t 收到的即时奖励。
在我们构建的基于GPT-4的Agent中,GPT-4充当策略函数 π \pi π,即:
π ( s t ) = GPT-4 ( s t ) \pi(s_t) = \text{GPT-4}(s_t) π(st)=GPT-4(st)
9.2 感知模块细节
感知模块不仅仅是将输入文本转化为状态描述。在实际应用中,可能需要对输入文本进行预处理,如分词、实体识别、情感分析等,以提取更有用的信息。
def perceive_environment(input_text):# 进行分词和预处理words = input_text.split()entities = extract_entities(input_text) # 伪代码,假设有一个提取实体的函数sentiment = analyze_sentiment(input_text) # 伪代码,假设有一个分析情感的函数state = {"description": input_text,"words": words,"entities": entities,"sentiment": sentiment}return state
9.3 决策模块细节
在决策模块中,我们可以引入更多上下文信息,提高GPT-4生成响应的准确性。
def decide_action(state):# 将状态信息整合成一个完整的提示prompt = (f"Based on the following state:\n"f"Description: {state['description']}\n"f"Words: {state['words']}\n"f"Entities: {state['entities']}\n"f"Sentiment: {state['sentiment']}\n""What should the agent do next?")action = generate_response(prompt)return action
10. 深度学习与强化学习结合
尽管GPT-4非常强大,但它是基于语言模型的,而不是传统的强化学习模型。然而,我们可以将其与强化学习方法结合,创建更强大的智能体。
10.1 强化学习背景
强化学习(Reinforcement Learning, RL)是机器学习的一个重要分支,其核心思想是智能体通过与环境的交互来学习最优策略。智能体在每个时间步接收到环境的状态,并选择一个行动,环境反馈给智能体一个奖励值和新的状态。智能体的目标是最大化累积奖励。
10.2 强化学习与GPT-4结合
我们可以将GPT-4生成的响应作为智能体的策略输出,然后通过强化学习的方法来调整和优化GPT-4的提示输入,从而提高智能体的整体表现。
import randomclass RLAgent:def __init__(self, environment):self.environment = environmentself.q_table = {} # Q-table初始化为空def perceive(self):return self.environment.get_state()def decide(self, state):if state not in self.q_table:self.q_table[state] = {}if random.random() < 0.1: # 10%的探索率action = self.environment.random_action()else:action = max(self.q_table[state], key=self.q_table[state].get, default=self.environment.random_action())return actiondef act(self, action):next_state, reward = self.environment.step(action)return next_state, rewarddef learn(self, state, action, reward, next_state):if state not in self.q_table:self.q_table[state] = {}if action not in self.q_table[state]:self.q_table[state][action] = 0max_next_q = max(self.q_table[next_state].values(), default=0)self.q_table[state][action] += 0.1 * (reward + 0.99 * max_next_q - self.q_table[state][action])# 假设有一个定义好的环境类
environment = Environment()
agent = RLAgent(environment)for episode in range(1000):state = agent.perceive()done = Falsewhile not done:action = agent.decide(state)next_state, reward = agent.act(action)agent.learn(state, action, reward, next_state)state = next_stateif environment.is_terminal(state):done = True
11. 总结
本文详细介绍了如何基于GPT-4从0到1构建一个Agent,包括感知、决策和行动模块的实现,以及如何将GPT-4与强化学习方法结合,进一步优化智能体的表现。通过具体的代码示例,展示了Agent的基本架构和工作原理。希望对各位在构建智能Agent方面有所帮助。
参考资料
- OpenAI GPT-4 API文档
- 强化学习:马尔可夫决策过程(MDP)理论
相关文章:
GPT-4从0到1搭建一个Agent简介
GPT-4从0到1搭建一个Agent简介 1. 引言 在人工智能领域,Agent是一种能够感知环境并采取行动以实现特定目标的系统。本文将简单介绍如何基于GPT-4搭建一个Agent。 2. Agent的基本原理 Agent的核心是感知-行动循环(Perception-Action Loop)…...

docker镜像源配置
docker默认的镜像源,走的是国外网络,下载速度感人,修改镜像源,进入/etc/docker/ cd /etc/docker 编辑文件daemon.json(没有就直接创建),内容: {"registry-mirrors": ["https://q7ta64ip.…...
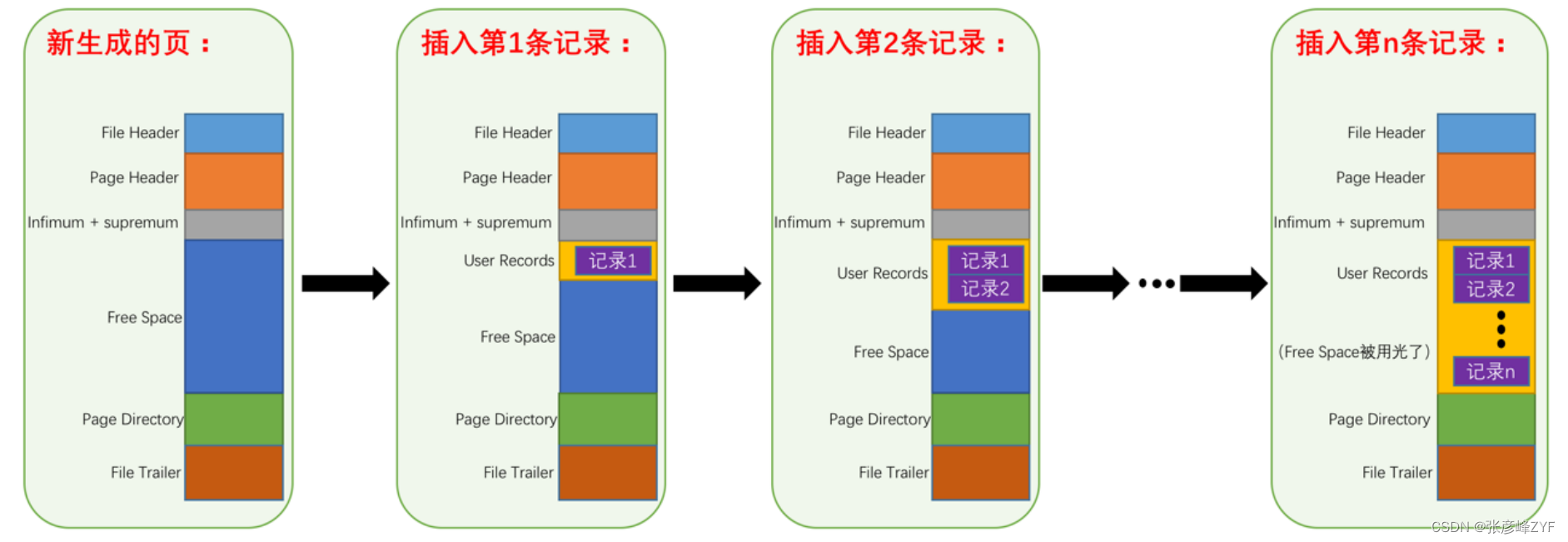
解读InnoDB数据库索引页与数据行的紧密关联
目录 一、快速走进索引页结构 (一)整体展示说明 (二)内容说明 File Header(文件头部) Page Header(页面头部) Infimum Supremum(最小记录和最大记录) …...

以数据编织,重构数据管理新范式
大数据产业创新服务媒体 ——聚焦数据 改变商业 人工智能几乎统一了全球最顶尖科技公司的认知:这个时代,除了AI,没有第二条路可走。 人工智能的技术逻辑颇有一种“暴力美学”,它依托于海量大数据和超高算力的训练和推理ÿ…...

在linux x86服务器安装jdk
安装JDK(Java Development Kit)在Linux x86 服务器上可以按照以下步骤进行操作。以下步骤假设你有root权限或者sudo权限。 1. 下载JDK安装包 首先,你需要从Oracle官网或者OpenJDK官网下载JDK的安装包。可以选择对应的版本,比如J…...

2024智慧竞技游戏俱乐部线下面临倒闭?
在2024年的中国,智慧竞技游戏俱乐部如雨后春笋般在二三线城市中兴起,它们不仅是年轻人娱乐的场所,更是智慧与技巧的较量场。然而,随着疫情的冲击,这些俱乐部面临着前所未有的挑战。本文将通过一个小镇上的故事…...

jmeter分布式(四)
一、gui jmeter的gui主要用来调试脚本 1、先gui创建脚本 先做一个脚本 演示:如何做混合场景的脚本? 用211的业务比例 ①启动数据库服务 数据库服务:包括mysql、redis mysql端口默认3306 netstat -lntp | grep 3306处于监听状态…...

如何解决手机游戏因IP代理被封禁无法正常游戏的问题?
在当前的网络环境下,许多手机游戏为了维护游戏的公平性和安全性,会采取措施对使用IP代理的玩家进行封禁,导致他们无法正常访问游戏。这种情况对于一些需要使用IP代理的用户来说可能显得很棘手,但实际上有几种技术性的解决方案可以…...

windows10 安装Anaconda
文章目录 1. 下载2. 安装3. 配置环境变量4. 检查是否安装成功 1. 下载 官网下载 https://www.anaconda.com/download 下载的最新版本,要求python的版本也高一些 清华大学开源软件镜像站 https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/ 所有版本在这个网…...

[图解]SysML和EA建模住宅安全系统-14-黑盒系统规约
1 00:00:02,320 --> 00:00:07,610 接下来,我们看下一步指定黑盒系统需求 2 00:00:08,790 --> 00:00:10,490 就是说,把这个系统 3 00:00:11,880 --> 00:00:15,810 我们的目标系统,ESS,看成黑盒 4 00:00:18,030 --> …...

frp内网穿透xtcp安全点对点p2p部署记录打洞失败解决方法
环境 一、有公网IP、nas主机(需要穿透里面的服务)、安卓手机、frps-0.58.1、frpc-0.59.0(群晖NAS套件)、安卓版frpc-0.56.0 二、两端frpc必须要有一端nat网络类型不是非对称nat 开始 有公网的主机上配置frps.toml bindPort 7000nas主机端frpc.toml配…...

C++基础篇(2)
目录 前言 1.缺省参数 2.函数重载 2.1函数重载的基本规则 编辑2.2注意事项 2.3 重载解析(Overload Resolution)--补充内容 3.引用 3.1引用的概念和定义 3.2引用的特性 3.3引用的使用 3.4const引用 4.指针和引用的关系 结束语 前言 上节小编…...

c++ primer plus 第16章string 类和标准模板库,16.1.3 使用字符串
c primer plus 第16章string 类和标准模板库,16.1.3 使用字符串 c primer plus 第16章string 类和标准模板库,16.1.3 使用字符串 文章目录 c primer plus 第16章string 类和标准模板库,16.1.3 使用字符串16.1.3 使用字符串程序清单16.3 hangman.cpp 16.1.3 使用字符串 现在&a…...

使用mybatis的statementHander拦截器监控表和字段并发送钉钉消息
新建mybatis的statementHander拦截器拦截器 类 面试题: 2.实现 解析Sql时引入JSqlParser JSqlParser 是一个 SQL 语句解析器。 它将 SQL转换为可遍历的 Java 类层次结构。 <dependency><groupId>com.github.jsqlparser</groupId><artifac…...
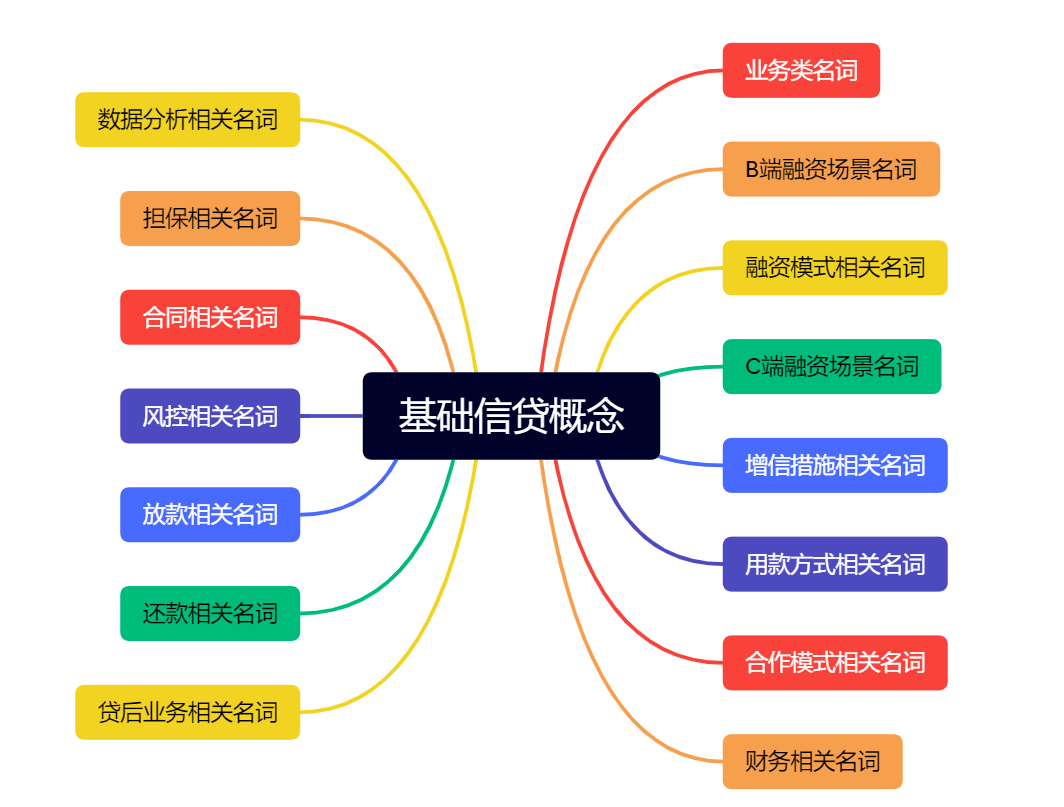
信贷系统——基础信贷概念
摘要 信贷是金融领域中的一个重要概念,指的是金融机构(如银行、信用合作社等)向个人、企业或政府提供资金的过程。在信贷过程中,金融机构向借款人提供资金,借款人则承诺在未来的某个时间点按照约定的条件和利率偿还借款。这种借款通常是在合同中明确约定的,包括贷款金额、…...
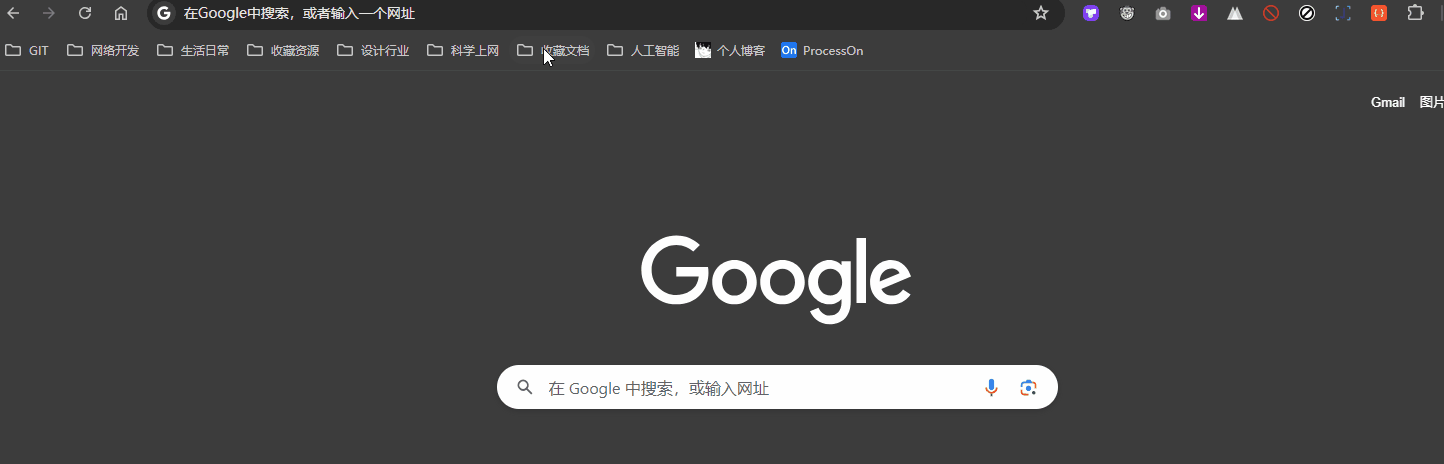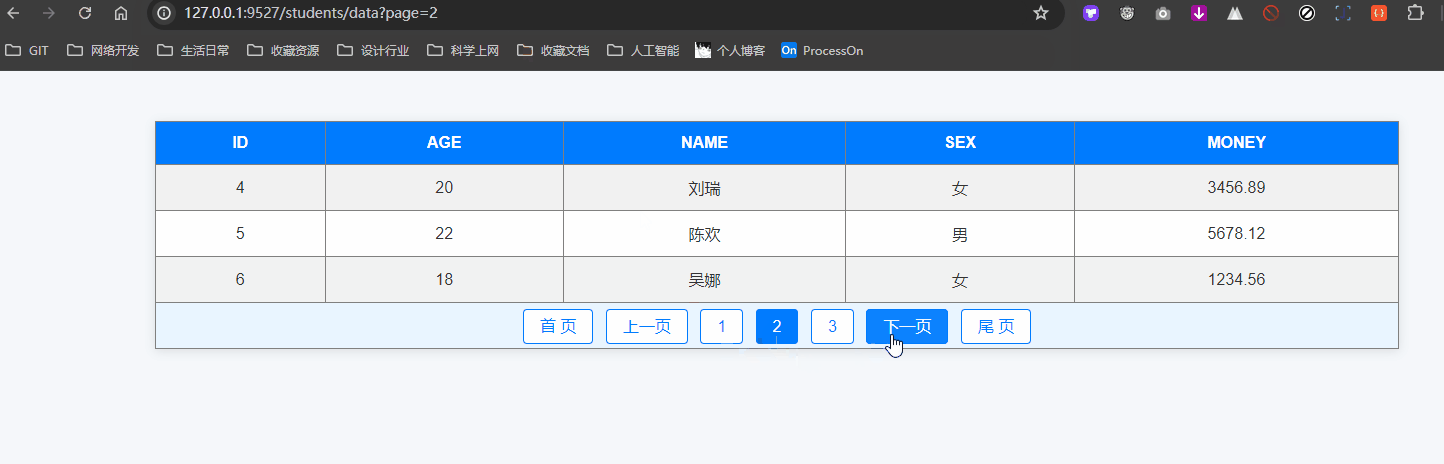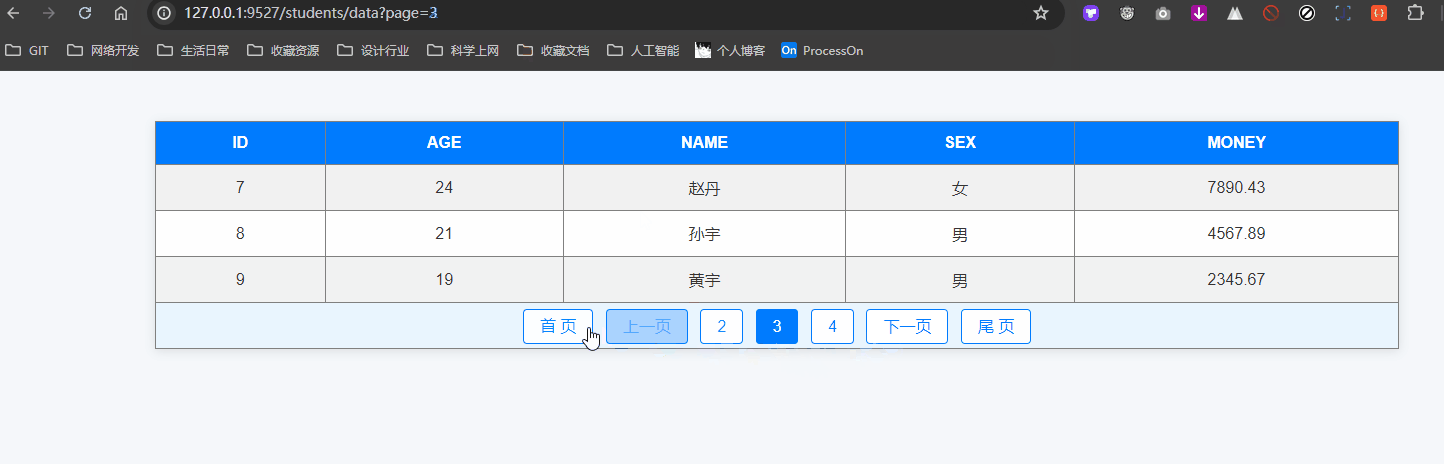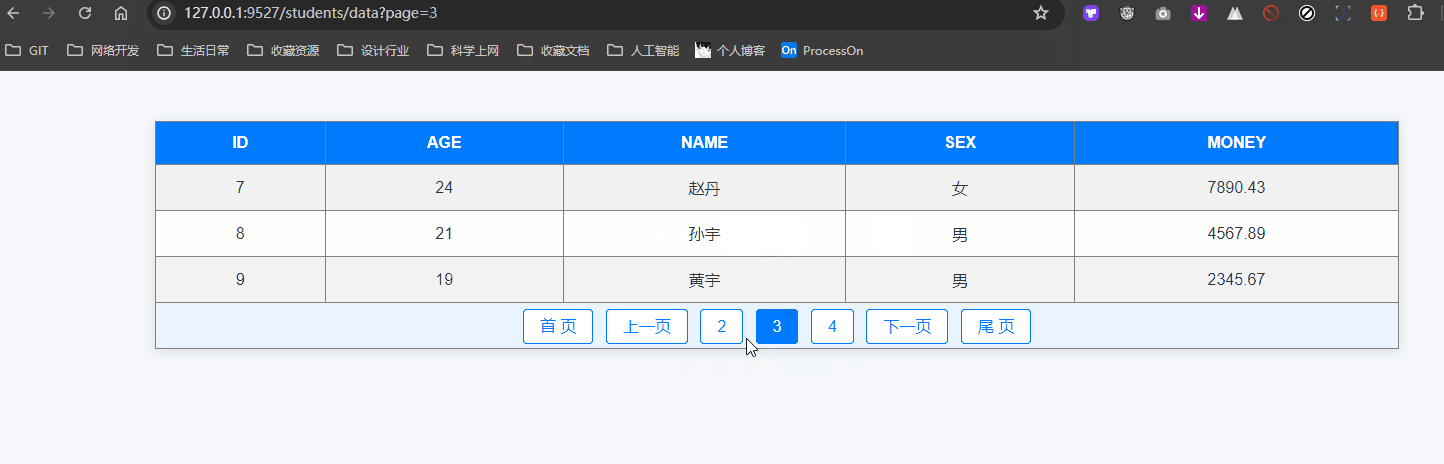
分页查询及其拓展应用案例
分页查询 分页查询是处理大量数据时常用的技术,通过分页可以将数据分成多个小部分,方便用户逐页查看。SQLAlchemy 提供了简单易用的方法来实现分页查询。 本篇我们也会在最终实现这样的分页效果: 1. 什么是分页查询 分页查询是将查询结果按照…...

【UE5.1】NPC人工智能——02 NPC移动到指定位置
效果 步骤 1. 新建一个蓝图,父类选择“AI控制器” 这里命名为“BP_NPC_AIController”,表示专门用于控制NPC的AI控制器 2. 找到我们之前创建的所有NPC的父类“BP_NPC” 打开“BP_NPC”,在类默认值中,将“AI控制器类”一项设置为“…...

有关电力电子技术的一些相关仿真和分析:⑤交-直-交全桥逆变+全波整流结构电路(MATLAB/Siumlink仿真)
全桥逆变+全波整流结构 参数:Vin=500V, Vo=200V, T=2:1:1, RL=10Ω, fs=100kHz, L=1mH, C=100uF (1)给定输入电压,输出电压和主电路参数,仿真研究电路工作原理,分析工作时序; (2)调节负载电阻,实现电流连续和断续,并仿真验证; (3)调节占空比,分析占空比与电…...

记录一次Android推流、录像踩坑过程
背景: 按照需求,需要支持APP在手机息屏时进行推流、录像。 技术要点: 1、手机在息屏时能够打开camera获取预览数据 2、获取预览数据时进行编码以及合成视频 一、息屏时获取camera预览数据: ①Camera.setPreviewDisplay(SurfaceH…...

VsCode 与远程服务器 ssh免密登录
首先配置信息 加入下列信息 Host qb-zn HostName 8.1xxx.2xx.3xx User root ForwardAgent yes Port 22 IdentityFile ~/.ssh/id_rsa 找到自己的公钥,不带pub是私钥,打死都不能给别人。复制公钥 拿到公钥后,来到远程服务器 vim ~/.ss…...

快马AI生成高性能JMeter压测脚本的核心原理与实战
1. 这不是“又一个AI写脚本工具”,而是压测工程师终于能睡整觉的转折点快马AI、JMeter、一键生成高性能测试脚本——这三个词凑在一起,很多老压测人第一反应是皱眉:又来个包装成“智能”的模板填充器?我亲手调过37版登录接口的Thi…...

如何做好费用率数据分析?巧用费用率研判企业盈利现状
企业经营发展过程中,盈利水平高低直接决定长远发展实力,而费用率数据是看透企业真实盈利水平最直观、最核心的指标。很多经营者在日常管理中,往往只看重账面营收的增长,却忽略了费用率数据的深层分析与解读,最终出现营…...

桌面图标变白纸别慌!手把手教你用右键属性+路径复制,5分钟找回所有软件图标
桌面图标异常修复指南:从白纸图标到完整恢复的实战解析 电脑桌面上那些熟悉的图标突然变成白纸,这种看似小问题却让人倍感困扰。不必惊慌,这通常是系统图标缓存更新不及时或软件关联异常导致的常见现象。本文将带你深入理解图标显示机制&…...

如何快速突破百度网盘限速:高效下载工具终极指南
如何快速突破百度网盘限速:高效下载工具终极指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 百度网盘作为国内最流行的云存储平台,其下载速度限制一…...
)
别再让日志拖慢你的服务器!深入对比C++同步与异步日志的性能差异(附TinyWebServer实测)
C服务器日志性能优化实战:同步与异步方案深度对比 当你的Web服务器开始承载真实流量时,那些看似无害的日志语句可能正在悄悄吞噬着系统性能。我曾在一个电商促销日亲眼目睹,由于同步日志的阻塞导致服务器响应时间从50ms飙升到800ms࿰…...

CANN/asc-devkit Ascend C矢量压缩API
asc_squeeze 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.co…...

企业级微服务架构解决方案:Abp Vnext Pro框架的5大技术优势解析
企业级微服务架构解决方案:Abp Vnext Pro框架的5大技术优势解析 【免费下载链接】abp-vnext-pro Abp Vnext 的 Vue 实现版本 项目地址: https://gitcode.com/gh_mirrors/ab/abp-vnext-pro Abp Vnext Pro是一个基于ABP框架和Vue.js技术栈构建的企业级开发平台…...

CANN/pypto量化矩阵乘法
pypto.scaled_mm 【免费下载链接】pypto PyPTO(发音: pai p-t-o):Parallel Tensor/Tile Operation编程范式。 项目地址: https://gitcode.com/cann/pypto 产品支持情况 产品是否支持Ascend 950PR/Ascend 950DT√ 功能说明 实现mat_…...

SynthID技术解析:AI生成图像的隐形数字身份证
1. 项目概述:当“眼见”不再为实,我们靠什么守住真实?去年冬天,我帮一个做教育短视频的朋友处理一批AI生成的插画素材。他用的是主流文生图工具,效果确实惊艳——古风课堂场景细腻得能看清宣纸纹理,学生表情…...

都在喊难,它却狂赚!深度扒开长鑫科技底牌:什么才是决定生死的产业势?
2026年的商业世界,正在经历一场冰火两重天的考验。 一边,是无数传统企业在需求萎缩、价格内卷的泥潭里苦苦挣扎,老板们每天为了几毛钱的利润拼得头破血流;而另一边,一份堪称“核弹级”的财报,直接炸翻了整个…...