Mongodb数组字段索引之多键索引
学习mongodb,体会mongodb的每一个使用细节,欢迎阅读威赞的文章。这是威赞发布的第92篇mongodb技术文章,欢迎浏览本专栏威赞发布的其他文章。如果您认为我的文章对您有帮助或者解决您的问题,欢迎在文章下面点个赞,或者关注威赞。谢谢。
Mongodb字段允许包含字符,文档,数组等各种各样的类型。同样Mongodb索引也可以支持字符,文档,数组等类型。本文结合Mongodb官方文档,介绍Mongodb数组类型数据的索引——多键索引。如果应用经常查询数组字段,为该字段添加多键索引,能够提高查询效率,增加索引查询覆盖率,优化数据库查询性能。
如在学生集合当中,包含了存储学生测验成绩的test_scores字段,这个学期的每一次测验成绩都会在这个数组当中。老师需要查询出至少5次测验成绩超过90分的学生 。这样就可以在字段test_scores上添加索引来提高查询效率。因为test_scores是数组类型,Mongodb自动为数组类型创建多键索引。
概述
多键索引,包含并排序了字段中的数组数据。多键索引,能够改善数组字段的查询性能。用户不需要显示的定义多键索引类型。当Mongodb构建索引时,看到该字段是数组字段,就会自动的创建多键索引。Mongodb可以为普通类型数据数组(如字符串数组,数字数组)和嵌入式文档数据来构建多键索引。如果一个数组包含相同值的多个元素,则Mongodb只会选择这些元素中的一个来放入索引当中。
下面的图中描述了多键索引的结构。有一个collection集合,字段addr是文档类型的数组。现在为addr数组中的zip字段建立索引。在索引当中,数组元素的数值从小到大排列。
语法
使用下面的语句来创建多键索引
db.<collection>.createIndex({<arrayField>: <sortOrder>})使用和限制
索引边界
在查询中,边界定义了索引扫描的各个部分。Mongodb在多键索引边界计算上有特殊的规则,详细查看文档《Mongodb多键索引边界》。
唯一多键索引
在唯一多键索引当中,文档的数组元素,只能包含集合中其他文档数组中不存在的元素。
复合多键索引
在复合多键索引中,每一个文档最多只能包含一个被索引的数组字段。
用户不可以为多个数组创建索引。如在集合中包含了下面一个文档数据
{_id: 1, scores_spring:[8, 6], scores_fall:[5,9]}其中字段scores_spring和字段scores_fall是数组索引,用户不能够使用{scores_spring: 1, scores_fall:1}来创建索引。
如果一个复合索引已经存在,用户也不能够插入还是索引定义相违背的文档数据。
如集合中包含文档
{_id: 1, scores_spring:[8, 6], scores_fall:9}
{_id: 2, scores_spring:6, scores_fall:[5, 7]}用户可以创建一个复合多键索引{scores_spring: 1, scores_fall:1},因为每一个文档当中,只有一个字段是数组索引,不包含这两个字段同时是数组字段的文档数据。该索引创建后,Mongodb不允许用户插入两个字段都是数据元素的文档。
排序
基于数组字段的索引进行排序时,满足下面两个条件,才会使用索引排序,而不会在查询中包含一个内存排序。
- 所有排序字段的值包含在索引边界最大最小值内
- 任何一个与排序模版带有相同前缀的多键索引都不能有边界限制。这句话在文档中很绕口。尝试去理解一下。如前面提到的索引{scores_spring: 1, scores_fall:1}。当某个查询排序,使用{sort:{scores_spring:1}},这该排序字段是索引{scores_spring: 1, scores_fall:1}的索引前缀。在查询当中,不能对scores_spring做边界限制,否者将使用内存排序。
分片集合
多键索引的字段,不能作为分片键。但是,当分片键是复合索引的前缀时,后续索引字段包含数组时,这个复合索引就会成为一个符合多键索引。
如下文档, 集合中带有索引{field2:1, field1: 1},当使用field2字段作为分片集的关键字时,则field2既是分片关键字,也是复合索引的前缀。外国人写的这些英语,还是很绕的,要理解一下。
{_id:1, field1: [2,8],field2: 'A'}哈希索引
哈希索引,不能是多键索引
索引覆盖查询
多键索引不能覆盖数组字段的查询。但是,多键索引,能够使用索引前缀,覆盖非数组字段的查询。如下面的一个使用案例。
在集合matches中插入文档。
db.matches.insertMany([{ name: "joe", event: ["open", "tournament"]},{ name: "bill", event: ["match", "championship"]}
])在name字段和event字段建立索引
db.matches.createIndex({name: 1,event: 1
})该索引是复合多键索引,但是能够覆盖在name字段的查询
db.matches.find({name: "joe"
}).explain()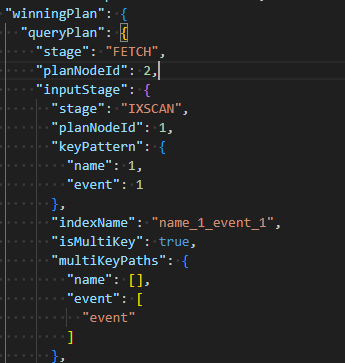
使用数组作为查询条件
当查询过滤器中,使用整个数组做为查询条件时,Mongodb能够使用多键索引,查询数组过滤条件中的第一个数组元素,但不能使用多键索引去查询整个数组。当Mongodb使用多键索引查询过滤数组中的第一个元素以后所查询出来的文档,Mongodb在内存中会对这部分文档进一步过滤,过滤出复合查询条件中整个数组的文档。
举例说明一下这个过程。创建集合inventory并插入数据
db.inventory.insertMany([{ _id:5, type: "food", item:"apple", ratings: [ 5, 8, 9 ] },{ _id:6, type: "food", item:"banana", ratings: [ 5, 9 ] },{ _id:7, type: "food", item:"grapes", ratings: [ 9, 5, 8 ] },{ _id:8, type: "food", item:"orange", ratings: [ 5, 9, 5 ] },{ _id:9, type: "food", item:"pear", ratings: [ 9, 5 ] }
])在数组ratings建立多键索引
db.inventory.createIndex({ratings: 1})构建一个使用数组作为过滤器的查询语句
db.inventory.find({ratings: [5, 9]
})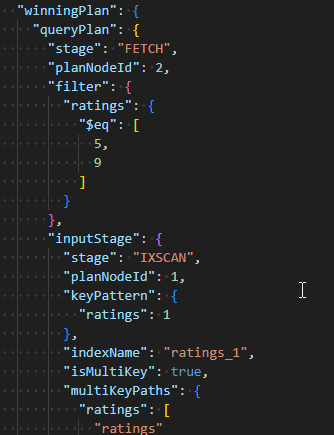
在查询计划中,能够看出,mongodb先使用5通过多键索引,查询出所有包含元素5的文档,然后在内存中过滤出包含整个数组[5,9]的文档数据
$expr
$expr表达式,不支持多键索引
应用
为数值数组添加索引
创建students集合,并插入数据。其中 test_scores是数值类型的数组。
db.students.insertMany([{name: 'Andre Robinson', test_scores: [88, 97]},{name: 'Alice Martin', test_scores: [62, 73]},{name: 'Bob Smith', test_scores: [92, 89]}
])用户经常需要查询出至少有一次测验分数大于90的同学,这可以向数组字段添加索引来提高性能
db.students.createIndex({test_scores: 1})因为字段test_scores是数组类型,所以Mongodb自动为该字段创建了多键索引。该索引中包含了字段test_scores的所有值,并按照从小到大排列,[62, 73, 88, 89, 92, 97].该索引支持在字段test_scores上的查询
如
db.students.find({test_scores: { $elemMatch: { $gte: 90 } }
})为文档数组添加索引
构建inventory集合并插入数据
db.inventory.insertMany([{item: "t-shirt",stock: [{ size: "S", quantity: 8 },{ size: "L", quantity: 10 }]},{item: "sweater",stock: [{ size: "S", quantity: 4 },{ size: "M", quantity: 7 }]},{item: "vest",stock: [{ size: "S", quantity: 6 },{ size: "L", quantity: 1 }]}
])用户需要在库存低于5的时候,下订单来补货。为了查找出哪些需要补货,需要构建语句,查出来stock数组中,数量quantity少于5的记录。为了提高性能,用户需要在字段stock.quantity上添加索引。
db.inventory.createIndex({'stock.quantity': 1})因为stock是包含文档的数组,索引Mongodb将这个索引存储为多键索引。该索引将字段stock.quantity所有值按照从小到大排列[1,4,6,7,8,10]
构建语句,查询出少于5的数据
db.inventory.find({'stock.quantity': { $lt: 5 }})查询数据,按照库存的倒序排列
db.inventory.find().sort({'stock.quantity': -1})相关文章:
Mongodb数组字段索引之多键索引
学习mongodb,体会mongodb的每一个使用细节,欢迎阅读威赞的文章。这是威赞发布的第92篇mongodb技术文章,欢迎浏览本专栏威赞发布的其他文章。如果您认为我的文章对您有帮助或者解决您的问题,欢迎在文章下面点个赞,或者关…...

[Spring] Spring Web MVC案例实战
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...

大模型“重构”教育:解构学习奥秘,推动教育普惠
大模型“重构”千行百业系列选题 生成式人工智能的热潮,为AI领域的发展注入新的活力,而“赋能千行百业”已经成为人们普遍对于人工智能和大模型的全新理解。 人工智能和大模型技术的迅猛发展正在以前所未有的速度深刻改变着各个行业。正如专家所预测&a…...

HCNA VRP基础
交换机可以隔离冲突域,路由器可以隔离广播域,这两种设备在企业网络中应用越来越广泛。随着越来越多的终端接入到网络中,网络设备的负担也越来越重,这时网络设备可以通过专有的VRP系统来提升运行效率。通过路由平台VRP是华为公司数…...

单片机外围设备-EEPROM
eeprom用iic通信。eeprom有几个特点需要关注: 1、可以单字节读写 2、eeprom按页划分存储,不同型号的eeprom的页大小不一致,往eeprom写数据时,如果写到了该页的末尾,会自动从该页的开头继续写,把之前的数据…...
YOLO--置信度(超详细解读)
YOLO(You Only Look Once)算法中的置信度(Confidence)是一个关键概念,用于评估模型对预测框内存在目标对象的信心程度以及预测框对目标对象位置的准确性。 一、置信度的定义 数值范围:置信度是一个介于0和…...

“解锁物流新纪元:深入探索‘沂路畅通‘分布式协作平台“
"解锁物流新纪元:深入探索沂路畅通分布式协作平台" 在21世纪的数字浪潮中,物流行业作为连接生产与消费的关键纽带,其重要性不言而喻。然而,随着市场规模的持续扩大和消费者需求的日益多样化,传统物流模式已…...

昇思25天学习打卡营第六天|应用实践/计算机视觉/Vision Transformer图像分类
心得 运行模型似乎有点靠天意?每次跑模型之前先来个焚香沐浴?总之今天是机器视觉的最后一课了,尽管课程里强调模型跑得慢,可是我的这次运行,居然很快的就看到结果了。 如果一直看我这个系列文章的小伙伴,…...

vxe-table合并行数据
场景: 混批名称相同合并混批名称,在混批名称相同条件下合并相同的混批类型;在混混批类型相同条件下合并相同的混批值;在混批值相同条件下合并相同的单位 实现根据四个不同的key值,当四个key值对应相等时,合…...
LabVIEW异步和同步通信详细分析及比较
1. 基本原理 异步通信: 原理:异步通信(Asynchronous Communication)是一种数据传输方式,其中数据发送和接收操作在独立的时间进行,不需要在特定时刻对齐。发送方在任何时刻可以发送数据,而接收…...

【多模态学习笔记二】MINIGPT-4论文阅读
MINIGPT-4:ENHANCING VISION-LANGUAGE UNDERSTANDING WITH ADVANCED LARGE LANGUAGE MODELS 提出的MiniGPT-4使用一个投影层,将冻结的视觉编码器与冻结的先进的LLM Vicuna对齐。我们的工作首次揭示,将视觉特征与先进的大型语言模型正确对齐可以具有GPT-4所展示的许多先进的多…...
Docker基本讲解及演示
Docker安装教程 Docker安装教程 1、Docker介绍 Docker是一个开源的应用容器引擎,允许开发者将应用程序及其依赖项打包成一个轻量级、可移植的容器,然后发布到任何支持 Docker 的环境中运行,无论是开发机、测试机还是生产环境。 Docker基于…...

各类专业技术的pdf电子书
从业多年,收集了海量的pdf电子书籍,感兴趣的私聊。...

【Linux】多线程_9
文章目录 九、多线程10. 线程池 未完待续 九、多线程 10. 线程池 这里我没实现一些 懒汉单例模式 的线程池,并且包含 日志打印 的线程池: Makefile: threadpool:Main.ccg -o $ $^ -stdc11 -lpthread .PHONY:clean clean:rm -f threadpoolT…...

LabVIEW设备检修信息管理系统
开发了基于LabVIEW设计平台开发的设备检修信息管理系统。该系统应用于各种设备的检修基地,通过与基地管理信息系统的连接和数据交换,实现了本地检修工位数据的远程自动化管理,提高了设备的检修效率和安全性。 项目背景 现代设备运维过程中信…...

python爬虫基础:使用lxml库进行HTML解析和数据提取的实践指南
使用lxml库进行HTML解析和数据提取的实践指南 在Python编程中,网页抓取和数据提取是一项常见任务。lxml库因其高效性和强大的XPath支持,成为了处理HTML和XML文档的优选工具。本文将带你了解如何使用lxml来解析HTML文档并提取所需数据。 1. 安装lxml库 …...
大语言模型系列:Transformer
在自然语言处理(NLP)领域,Transformer模型自2017年由Vaswani等人在论文《Attention Is All You Need》中提出以来,已成为最具影响力的技术之一。这种模型设计的核心是自注意力机制,它允许模型在处理序列数据时…...

宠物健康新守护:智能听诊器引领科技突破
在宠物护理领域,一项令人瞩目的科技创新正逐渐兴起,那便是智能听诊器。这款革命性的设备以前所未有的准确性和便利性,为宠物主人提供了一种全新的健康监测体验。 只需将智能听诊器轻轻放置在爱宠的身上,它便立即开始工作…...

KITTI 3D 数据可视化
引言 KITTI 视觉基准测试套件(KITTI Vision Benchmark Suite)提供了大量用于理解自动驾驶场景的工具。尤其是3D数据可视化在分析和解释传感器(如激光雷达)与环境的复杂交互中起到了至关重要的作用。本文将详细探讨KITTI数据集中3…...

旅游数据可视化:免费工具让复杂数据变得简单易懂
随着旅游业的蓬勃发展,海量的数据如同繁星点点,记录着每一位旅者的足迹与偏好。然而,如何将这些复杂的数据转化为直观、易懂的信息,为旅游企业精准决策、为消费者提供更加个性化的服务,成为了行业内外共同关注的焦点。…...

Onekey Steam清单下载工具:3步搞定游戏清单管理的终极指南
Onekey Steam清单下载工具:3步搞定游戏清单管理的终极指南 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 在Steam游戏生态中,清单文件是连接游戏客户端与服务器资源的关…...

AssetStudio深度解析:Unity资源提取原理与跨版本兼容实践
1. 这不是个“点开即用”的工具,而是一把需要校准的Unity资源解剖刀AssetStudio这个名字听起来像某个轻量级小工具,但实际用过的人很快会意识到:它根本不是拿来就跑的“一键提取器”,而是一套需要你亲手调参、理解Unity底层序列化…...

GanttProject终极指南:免费开源的项目管理工具完全攻略
GanttProject终极指南:免费开源的项目管理工具完全攻略 【免费下载链接】ganttproject Official GanttProject repository. 项目地址: https://gitcode.com/gh_mirrors/ga/ganttproject GanttProject是一款功能强大的免费开源项目管理软件,通过直…...

从零开始:5分钟掌握Mermaid Live Editor,告别复杂图表绘制烦恼
从零开始:5分钟掌握Mermaid Live Editor,告别复杂图表绘制烦恼 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending/me/…...

3步让PS手柄在Windows上完美运行:DS4Windows终极配置指南
3步让PS手柄在Windows上完美运行:DS4Windows终极配置指南 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 你是否曾为心爱的PlayStation手柄在Windows电脑上无法被游戏识别而烦…...

5分钟学会Windows自动化:Pulover‘s Macro Creator终极指南
5分钟学会Windows自动化:Pulovers Macro Creator终极指南 【免费下载链接】PuloversMacroCreator Automation Utility - Recorder & Script Generator 项目地址: https://gitcode.com/gh_mirrors/pu/PuloversMacroCreator 你是否每天重复着相同的鼠标点击…...

【软考高级架构】案例题考前突击——构建可观测与弹性服务架构的实践设计
案例分析题:构建可观测与弹性服务架构的实践设计 案例背景 某金融科技公司搭建了基于Spring Cloud 的微服务系统,用于支撑其多租户 SaaS 金融平台,核心功能包括用户管理、交易撮合、支付结算、风控审计等模块。由于业务快速扩张、团队并行开发,系统逐渐暴露出如下痛点: …...

家居用品展行业深度分析:格局、痛点与前景
家居用品展是家居产业的风向标与商贸核心枢纽,2026年行业正处于存量焕新、设计驱动、数智赋能的关键转型期。本文从发展现状、核心格局、痛点拆解、趋势机遇、前景预判五大维度,深度剖析家居用品展行业的底层逻辑与发展脉络,助力从业者把握行…...

【紧急预警】ElevenLabs 2024 Q3瑞典文语音许可证变更:3类商业场景已触发合规风险,附欧盟GDPR语音数据处理自查清单
更多请点击: https://codechina.net 第一章:ElevenLabs瑞典文语音许可证变更的合规背景与影响速览 2024年第三季度,ElevenLabs正式更新其语音合成服务的区域许可政策,将瑞典语(sv-SE)语音模型纳入欧盟《人…...

Diablo Edit2:10分钟掌握暗黑破坏神2存档修改终极指南
Diablo Edit2:10分钟掌握暗黑破坏神2存档修改终极指南 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 厌倦了在暗黑破坏神2中反复刷装备?想要快速测试新build却不想花费40小…...