【深度学习入门篇 ⑨】循环神经网络实战
【🍊易编橙:一个帮助编程小伙伴少走弯路的终身成长社群🍊】
大家好,我是小森( ﹡ˆoˆ﹡ ) ! 易编橙·终身成长社群创始团队嘉宾,橙似锦计划领衔成员、阿里云专家博主、腾讯云内容共创官、CSDN人工智能领域优质创作者 。
今天我们看一下用循环神经网络RNN的原理并且动手应用到案例。

循环神经网络
在普通的神经网络中,信息的传递是单向的,这种限制虽然使得网络变得更容易学习,但在一定程度上也减弱了神经网络模型的能力。特别是在很多现实任务中,网络的输出不仅和当前时刻的输入相关,也和其过去一段时间的输出相关。此外,普通网络难以处理时序数据,比如视频、语音、文本等,时序数据的长度一般是不固定的,而前馈神经网络要求输入和输出的维数都是固定的,不能任意改变。因此,当处理这一类和时序相关的问题时,就需要一种能力更强的模型。
循环神经网络 (RNN)是一类具有短期记忆能力的神经网络。在循环神经网络中,神经元不但可以接受其它神经元的信息,也可以接受自身的信息,形成具有环路的网络结构。

RNN比传统的神经网络多了一个循环圈,这个循环表示的就是在下一个时间步上会返回作为输入的一部分,我们把RNN在时间点上展开 :

在不同的时间步,RNN的输入都将与之前的时间状态有关 ,具体来说,每个时间步的RNN单元都会接收两个输入:当前时间步的外部输入和前一时间步(隐藏层)的输出状态。通过这种方式,RNN能够学习并理解数据中的长期依赖关系,使得它在处理文本生成、语音识别、时间序列预测等序列数据时表现尤为出色。
此外,RNN的隐藏状态(或称为内部状态)在每次迭代时都会更新,这种更新过程包含了当前输入和前一时间步状态的非线性组合,使得网络能够动态地调整其对序列中接下来内容的预测或理解。

LSTM和GRU
传统的RNN在处理长序列数据时常常面临梯度消失或梯度爆炸的问题,这限制了其在处理长期依赖关系上的能力。为了克服这一局限性,LSTM(Long Short-Term Memory,长短期记忆网络)作为RNN的一种变体被引入。
LSTM是一种RNN特殊的类型,可以学习长期依赖信息。在很多问题上,LSTM都取得相当巨大的成功,并得到了广泛的应用。

LSTM是通过一个叫做门的结构实现,门可以选择让信息通过或者不通过。 这个门主要是通过sigmoid和点乘实现的 ;sigmoid 的取值范围是在(0,1)之间,如果接近0表示不让任何信息通过,如果接近1表示所有的信息都会通过。
- 遗忘门通过sigmoid函数来决定哪些信息会被遗忘
-
输入门决定哪些新的信息会被保留。
例如:
我昨天吃了拉面,今天我想吃炒饭,在这个句子中,通过遗忘门可以遗忘拉面,同时更新新的主语为炒饭。
输出门
我们需要决定什么信息会被输出,也是一样这个输出经过变换之后会通过sigmoid函数的结果来决定那些细胞状态会被输出。
-
前一次的输出和当前时间步的输入的组合结果通过sigmoid函数进行处理得到O_t
-
更新后的细胞状态C_t会经过tanh层的处理,把数据转化到(-1,1)的区间
-
tanh处理后的结果和O_t进行相乘,把结果输出同时传到下一个LSTM的单元

GRU
GRU是一种LSTM的变形版本, 它将遗忘和输入门组合成一个“更新门”。它还合并了单元状态和隐藏状态,并进行了一些其他更改,由于他的模型比标准LSTM模型简单,所以越来越受欢迎。


双向LSTM
单向的 RNN,是根据前面的信息推出后面的,但有时候只看前面的词是不够的, 可能需要预测的词语和后面的内容也相关,那么此时需要一种机制,能够让模型不仅能够从前往后的具有记忆,还需要从后往前需要记忆。此时双向LSTM就可以帮助我们解决这个问题

由于是双向LSTM,所以每个方向的LSTM都会有一个输出,最终的输出会有2部分,所以往往需要concat的操作。
 RNN实现文本情感分类
RNN实现文本情感分类
torch.nn.LSTM(input_size,hidden_size,num_layers,batch_first,dropout,bidirectional)-
input_size:输入数据的形状,即embedding_dim -
hidden_size:隐藏层神经元的数量,即每一层有多少个LSTM单元 -
num_layer:即RNN的中LSTM单元的层数 -
batch_first:默认值为False,输入的数据需要[seq_len,batch,feature],如果为True,则为[batch,seq_len,feature] -
dropout:dropout的比例,默认值为0。dropout是一种训练过程中让部分参数随机失活的一种方式,能够提高训练速度,同时能够解决过拟合的问题。 -
bidirectional:是否使用双向LSTM,默认是False
实例化LSTM对象之后,不仅需要传入数据,还需要前一次的h_0(前一次的隐藏状态)和c_0
LSTM的默认输出为output, (h_n, c_n)
-
output:(seq_len, batch, num_directions * hidden_size)--->batch_first=False -
h_n:(num_layers * num_directions, batch, hidden_size) -
c_n:(num_layers * num_directions, batch, hidden_size)

LSTM和GRU的使用注意点
-
第一次调用之前,需要初始化隐藏状态,如果不初始化,默认创建全为0的隐藏状态
-
往往会使用LSTM or GRU 的输出的最后一维的结果,来代表LSTM、GRU对文本处理的结果,其形状为
[batch, num_directions*hidden_size]。
使用LSTM完成文本情感分类
class IMDBLstmmodel(nn.Module):def __init__(self):super(IMDBLstmmodel,self).__init__()self.hidden_size = 64self.embedding_dim = 200self.num_layer = 2self.bidriectional = Trueself.bi_num = 2 if self.bidriectional else 1self.dropout = 0.5self.embedding = nn.Embedding(len(ws),self.embedding_dim,padding_idx=ws.PAD) #[N,300]self.lstm = nn.LSTM(self.embedding_dim,self.hidden_size,self.num_layer,bidirectional=True,dropout=self.dropout)self.fc = nn.Linear(self.hidden_size*self.bi_num,20)self.fc2 = nn.Linear(20,2)def forward(self, x):x = self.embedding(x)x = x.permute(1,0,2) h_0,c_0 = self.init_hidden_state(x.size(1))_,(h_n,c_n) = self.lstm(x,(h_0,c_0))out = torch.cat([h_n[-2, :, :], h_n[-1, :, :]], dim=-1)out = self.fc(out)out = F.relu(out)out = self.fc2(out)return F.log_softmax(out,dim=-1)def init_hidden_state(self,batch_size):h_0 = torch.rand(self.num_layer * self.bi_num, batch_size, self.hidden_size).to(device)c_0 = torch.rand(self.num_layer * self.bi_num, batch_size, self.hidden_size).to(device)return h_0,c_0为了提高程序的运行速度,可以考虑把模型放在GPU上运行:
-
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") -
model.to(device)
train_batch_size = 64
test_batch_size = 5000
imdb_model = IMDBLstmmodel().to(device)
optimizer = optim.Adam(imdb_model.parameters())
criterion = nn.CrossEntropyLoss()def train(epoch):mode = Trueimdb_model.train(mode)train_dataloader =get_dataloader(mode,train_batch_size)for idx,(target,input,input_lenght) in enumerate(train_dataloader):target = target.to(device)input = input.to(device)optimizer.zero_grad()output = imdb_model(input)loss = F.nll_loss(output,target) loss.backward()optimizer.step()if idx %10 == 0:pred = torch.max(output, dim=-1, keepdim=False)[-1]acc = pred.eq(target.data).cpu().numpy().mean()*100.print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\t ACC: {:.6f}'.format(epoch, idx * len(input), len(train_dataloader.dataset),100. * idx / len(train_dataloader), loss.item(),acc))torch.save(imdb_model.state_dict(), "model/mnist_net.pkl")torch.save(optimizer.state_dict(), 'model/mnist_optimizer.pkl')def test():mode = Falseimdb_model.eval()test_dataloader = get_dataloader(mode, test_batch_size)with torch.no_grad():for idx,(target, input, input_lenght) in enumerate(test_dataloader):target = target.to(device)input = input.to(device)output = imdb_model(input)test_loss = F.nll_loss(output, target,reduction="mean")pred = torch.max(output,dim=-1,keepdim=False)[-1]correct = pred.eq(target.data).sum()acc = 100. * pred.eq(target.data).cpu().numpy().mean()print('idx: {} Test set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)\n'.format(idx,test_loss, correct, target.size(0),acc))if __name__ == "__main__":test()for i in range(10):train(i)test()
然后由大家写代码得到模型训练的最终输出,大家可以改变模型来观察不同的结果。
相关文章:
【深度学习入门篇 ⑨】循环神经网络实战
【🍊易编橙:一个帮助编程小伙伴少走弯路的终身成长社群🍊】 大家好,我是小森( ﹡ˆoˆ﹡ ) ! 易编橙终身成长社群创始团队嘉宾,橙似锦计划领衔成员、阿里云专家博主、腾讯云内容共创官…...

宝塔安装RabbitMq教程
需要放开15672端口,默认账号密码为guest/guest...

韦东山嵌入式linux系列-驱动进化之路:设备树的引入及简明教程
1 设备树的引入与作用 以 LED 驱动为例,如果你要更换LED所用的GPIO引脚,需要修改驱动程序源码、重新编译驱动、重新加载驱动。 在内核中,使用同一个芯片的板子,它们所用的外设资源不一样,比如A板用 GPIO A,…...
实现原理和java代码示例)
长轮询(Long Polling)实现原理和java代码示例
长轮询(Long Polling)背景 长轮询是一种在Web开发中常用的技术,用于实现服务器与客户端之间的即时通信或近乎实时的数据交换。在传统的轮询(Polling)中,客户端会定期向服务器发送请求以检查是否有新数据。…...

OWASP 移动应用 2024 十大安全风险
1. OWASP 移动应用 2024 十大安全风险 开放全球应用程序安全项目 (OWASP) 是一个非营利性基金会,致力于提高软件的安全性。自 2014、2016 年两次发布了移动应用的十大风险后,今年再次发布2024版。这对移动应用软件的检查工具有着…...

Qt界面假死原因
创建一个播放器类,继承QLabel,在播放器类中起一个线程用ffmpeg取流解码,将解码后的图像保存到队列,在gui线程中调用update()刷新显示。 当ffmpeg打开视频流失败后调用update()将qlabel刷新为黑色,有一定概率会使得qla…...

python调用MATLAB出错matlab.engine.MatlabExecutionError无法调用MATLAB函数报错
python调用MATLAB出错matlab.engine.MatlabExecutionError无法调用MATLAB函数报错 说明(废话)解决方案MATLAB异常乱码python矩阵转MATLAB矩阵matlab.engine.MatlabExecutionError 说明(废话) python调用MATLAB,调用m文件中的函数,刚开始都没有问题&…...

[GXYCTF2019]Ping Ping Ping1
打开靶机 结合题目名称,考虑是命令注入,试试ls 结果应该就在flag.php。尝试构造命令注入载荷。 cat flag.php 可以看到过滤了空格,用 $IFS$1替换空格 还过滤了flag,我们用字符拼接的方式看能否绕过,ag;cat$IFS$1fla$a.php。注意这里用分号间隔…...

成为git砖家(1): author 和 committer 的区别
大家好,我是白鱼。一直对 git author 和 committer 不太了解, 今天通过 cherry-pick 的例子搞清楚了区别。 原理 例如我克隆了著名开源项目 spdlog 的源码, 根据某个历史 commit A 创建了分支, 然后 cherry-pick 了这个 commit …...

Lianwei 安全周报|2024.07.15
新的一周又开始了,以下是本周「Lianwei周报」,我们总结推荐了本周的政策/标准/指南最新动态、热点资讯和安全事件,保证大家不错过本周的每一个重点! 政策/标准/指南最新动态 01 《人工智能全球治理上海宣言》发布 我们强调共同促…...
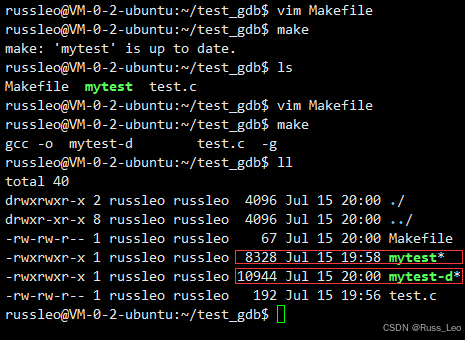
Linux - 基础开发工具(yum、vim、gcc、g++、make/Makefile、git、gdb)
目录 Linux软件包管理器 - yum Linux下安装软件的方式 认识yum 查找软件包 安装软件 如何实现本地机器和云服务器之间的文件互传 卸载软件 Linux编辑器 - vim vim的基本概念 vim下各模式的切换 vim命令模式各命令汇总 vim底行模式各命令汇总 vim的简单配置 Linux编译器 - gc…...

Git使用介绍教程
Git使用介绍教程 小白第一次写博客,内容写的可能不是很详细,仅供参考,大家一起努力 gitee网址:https://gitee.com 大部分的开发团队都以 Git 作为自己的版本控制工具,需要对 Git 的使用非常的熟悉。这篇文章中本人整理了自己在开发过程中经常使用到的 Git 命令,方便在偶…...

STM32的TIM1之PWM互补输出_死区时间和刹车配置
STM32的TIM1之PWM互补输出_死区时间和刹车配置 1、定时器1的PWM输出通道 STM32高级定时器TIM1在用作PWM互补输出时,共有4个输出通道,其中有3个是互补输出通道,如下: 通道1:TIM1_CH1对应PA8引脚,TIM1_CH1N对应PB13引…...

C++复习的长文指南
C复习的长文指南 一、入门语法知识1.预备1.1 main函数1.2 注释1.3 变量1.3 常量1.4 关键字1.5 标识符明明规则 2. 数据类型2.1 整型2.1.1 sizeof关键字 2.2 实型(浮点型)2.3 字符型2.4 转义字符2.5 字符串型2.6 布尔类型bool2.7 数据的输入 3. 运算符3.1…...

深入了解MySQL文件排序
数据准备 CREATE TABLE user_info (id bigint(20) NOT NULL AUTO_INCREMENT COMMENT ID,name varchar(20) NOT NULL COMMENT 用户名,age tinyint(4) NOT NULL DEFAULT 0 COMMENT 年龄,sex tinyint(2) NOT NULL DEFAULT 0 COMMENT 状态 0:男 1: 女,creat…...

【JAVA基础】反射
编译期和运行期 首先大家应该先了解两个概念,编译期和运行期,编译期就是编译器帮你把源代码翻译成机器能识别的代码,比如编译器把java代码编译成jvm识别的字节码文件,而运行期指的是将可执行文件交给操作系统去执行, …...
贪心算法(2024/7/16)
1合并区间 以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。 示例 1: 输入:inter…...

Python 在Word表格中插入、删除行或列
Word文档中的表格可以用于组织和展示数据。在实际应用过程中,有时为了调整表格的结构或适应不同的数据展示需求,我们可能会需要插入、删除行或列。以下提供了几种使用Python在Word表格中插入或删除行、列的方法供参考: 文章目录 Python 在Wo…...

Java二十三种设计模式-单例模式(1/23)
引言 在软件开发中,设计模式是一套被反复使用的、大家公认的、经过分类编目的代码设计经验的总结。单例模式作为其中一种创建型模式,确保一个类只有一个实例,并提供一个全局访问点。本文将深入探讨单例模式的概念、实现方式、使用场景以及潜…...

Unity动画系统(3)---融合树
6.1 动画系统基础2-6_哔哩哔哩_bilibili Animator类 using System.Collections; using System.Collections.Generic; using UnityEngine; public class EthanController : MonoBehaviour { private Animator ani; private void Awake() { ani GetComponen…...

惠来海康医院眼科母亲节:愿岁月温柔,护她眼底有光
惠来海康医院眼科母亲节:愿岁月温柔,护她眼底有光五月浅夏,暖意氤氲,当康乃馨的芬芳漫过街巷,母亲节便载着满心敬意如期而至。母亲,是岁月里最温柔的守望者,用一双眼眸,藏下对我们所…...

Perplexity学术模式到底有多“实时”?我们用NIST标准测试集连续监控72小时,结果让3所常春藤图书馆紧急更新采购清单…
更多请点击: https://intelliparadigm.com 第一章:Perplexity学术模式到底有多“实时”?我们用NIST标准测试集连续监控72小时,结果让3所常春藤图书馆紧急更新采购清单… 实时性验证方法论 我们采用 NIST TREC 2023 Dynamic Filt…...

芯片巨头并购软件公司:从硬件竞赛到软硬协同的产业变革
1. 行业现象背后的深层逻辑最近和几个在芯片设计公司和EDA软件公司工作的老朋友聊天,大家不约而同地提到了一个趋势:芯片巨头们的手,伸得越来越长了。以前是买IP核、买制造厂,现在则是频频出手,将一家家软件公司收入囊…...

深入解析WeChatFerry:基于RPC与进程注入的微信自动化框架
1. 项目概述:一个为微信自动化而生的强力引擎如果你正在寻找一个能够稳定、高效地控制微信客户端进行自动化操作的解决方案,那么lich0821/WeChatFerry这个项目绝对值得你花时间深入研究。它不是一个简单的消息发送工具,而是一个基于 RPC&…...

开源AI工具集Muse:模块化架构与创意工作流实践指南
1. 项目概述:一个面向创意工作者的开源AI工具集最近在开源社区里,一个名为myths-labs/muse的项目引起了我的注意。乍一看这个名字,你可能会联想到艺术灵感,但实际上,它是一个定位非常精准的开发者工具集合。简单来说&a…...

从零构建开源语音AI交互中枢:EchoKit Server部署与调优指南
1. 项目概述:构建你自己的语音AI交互中枢 如果你对智能音箱、语音助手这类设备感兴趣,但又觉得市面上的产品要么功能封闭,要么隐私堪忧,那么今天聊的这个项目——EchoKit Server,可能会让你眼前一亮。简单来说&#x…...

直播人力成本居高不下?2026十大AI数字人直播平台推荐实现长效运营
引文: 2026年,直播电商的竞争早已从“拼人设”转向了“拼夜间值守效率”。据公开数据显示,AI数字人核心市场规模预计在2026年逼近千亿大关,其中“降本”和“长效运营”是众多商家投身高频无人直播的核心诉求。事实上,…...

Casbin Talent 2026:高校开发者开源进阶与工业级项目实战指南
1. 项目概述:Casbin Talent 2026,一个为高校开发者量身定制的开源进阶通道如果你是一名在校大学生,对开源世界充满好奇,渴望在真实的工业级项目中打磨技术,但又觉得像Google Summer of Code(GSoC࿰…...

Python Redis 缓存策略实战:提升应用性能的最佳实践
Python Redis 缓存策略实战:提升应用性能的最佳实践 引言 在后端开发中,缓存是提升系统性能的关键技术。作为一名从Rust转向Python的开发者,我深刻认识到缓存策略在高并发场景下的重要性。Redis作为一款高性能的内存数据库,已成为…...

Vue3 + Vite项目集成vue-particles避坑指南:从安装到性能优化全流程
Vue3 Vite项目集成vue-particles全流程实战:从安装到性能调优 在Vue3和Vite构建的现代前端项目中,集成像vue-particles这样的视觉特效组件往往会遇到意想不到的兼容性问题。不同于传统的Webpack环境,Vite的ES模块系统和Vue3的组合式API带来了…...