TreeSet 与 TreeMap And HashSet 与 HashMap
目录
Map
TreeMap
put()方法 :
get()方法 :
Set> entrySet() (重) :
foreach遍历 :
Set
哈希表
哈希冲突 :
冲突避免 :
冲突解决 ---- > 比散列(开放地址法) :
开散列 (链地址法 . 开链法)
简介 :
在Java中 , TreeSet 与 TreeMap 利用搜索树实现 Map 与 Set , 其实它们的底层就是一个红黑树(仅作了解).
HashSet与HashMap底层是Hash表.
关于搜索 :
Map和set是一种专门用来搜索的容器.其搜索的效率与其具体的实例化子类有关.
像我们之前常见的搜索方式有 :
1.直接遍历 , 时间复杂度为O(n) , 元素如果比较多那么效率就会很慢很慢.
2.二分查找, 时间复杂度为O(logn),但搜索前必须要求序列是有序的.
在现实中会有一些查找 : 例如
根据一个人的姓名去查找它的成绩,或者根据姓名去查找电话号码.
如果是这样的一些查找那么上述的两种方式就不太适合了,而Map和Set就是一种适合动态查找的集合容器.根据Map和Set我们就可去实现这种要求去查询.
Map
对于Map来说它是一个Key - Value 模型 Key 就是一个关键字 而Value就是Key对应的一种结果
例如 :
统计文件中每个单词出现的次数 , 那么Map就可以实现, <单词 , 单词出现的次数>
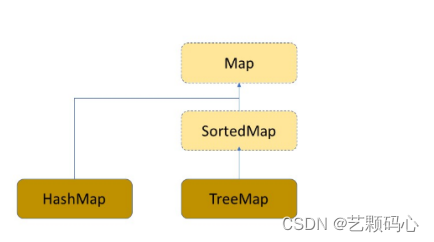
Map 与 SortedMap 是两个接口 , HashMap 与 TreeMap 就是两个普通类.
TreeMap
以下就是Map中的一些方法 :
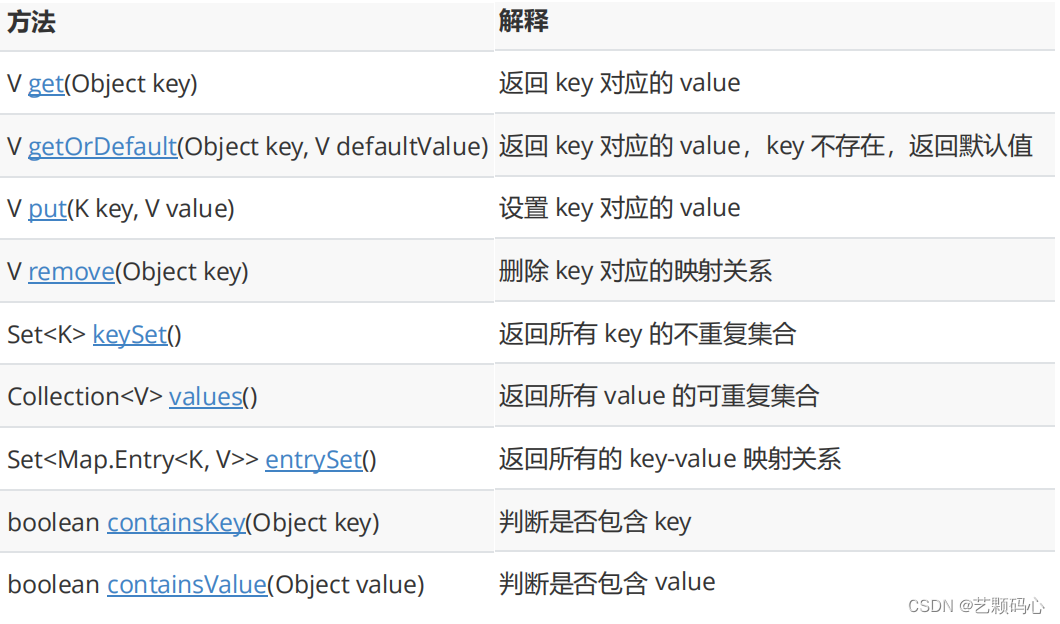
put()方法 :
put方法的一些注意点 :
public class Test {public static void main(String[] args) {Map<String,Integer> treeMap = new TreeMap<>();treeMap.put("he",3);treeMap.put("she",6);treeMap.put("it",8);System.out.println(treeMap);}
}
上面我们提到了TreeMap与TreeSet它的底层就是一个搜索树.在上一篇文章中我们讲到搜索树的原理以及是如何进行增,删,查的操作.

get()方法 :
根据get方法 : 当我们传进去一个Key关键字那么它就会输出相对应的value
public static void main(String[] args) {Map<String,Integer> treeMap = new TreeMap<>();treeMap.put("he",3);treeMap.put("she",6);treeMap.put("it",8);Integer val = treeMap.get("he");System.out.println(val);}
如果treeMap对象中不存在所要查找的关键字Key时 , 则会返回一个null.

或者我们可以使用另一个方法 :
如果treeMap对象中不存在abc这个字符串时 , 则输出默认值10.
public static void main(String[] args) {Map<String,Integer> treeMap = new TreeMap<>();treeMap.put("he",3);Integer val = treeMap.getOrDefault("abc",10);System.out.println(val);}
KeySet()方法 :
将treeMap对象中全部key放入keySet中.
public static void main(String[] args) {Map<String,Integer> treeMap = new TreeMap<>();treeMap.put("he",3);treeMap.put("she",6);treeMap.put("it",8);Set<String> keySet = treeMap.keySet();System.out.println(keySet);}
Set<Map.Entry<K, V>> entrySet() (重) :
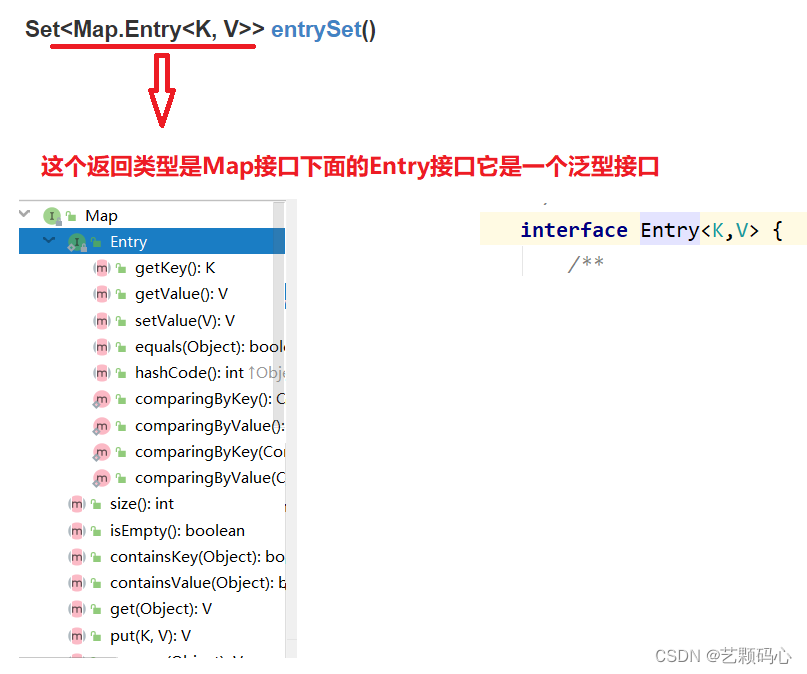
这个方法它会将所有存在treeMao对象中的Key - Value 模型返回.
public static void main(String[] args) {Map<String,Integer> treeMap = new TreeMap<>();treeMap.put("he",3);treeMap.put("she",6);treeMap.put("it",8);Set<Map.Entry<String, Integer>> entry = treeMap.entrySet();System.out.println(entry);}
foreach遍历 :
我们就可以使用Entry里面的getKey()方法来得到每一个模型的关键字key :
for (Map.Entry<String, Integer> entry: set) {System.out.print(entry.getKey() + " ");
}
注意 :
1.Map是一个接口,不能直接实例化对象, 如果要实例化对象只能实例化其实现类TreeMap或者HashMap.
2.Map中存放的键值对的Key是唯一的,value是可以重复的

3 . 在TreeMap中插入键值对时,key不能为空,否则就会抛NullPointerException异常,value可以为空。但是HashMap的key和value都可以为空。

使用Collection<V> values()方法
Set
Set是一个纯Key模型. 因此它只存关键词key.
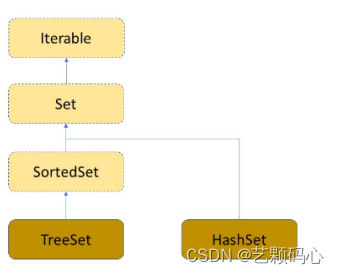
Set 与 SortedSet 就是两个接口 , 而 TreeSet 和 HashSet是两个普通类.
TreeSet使用add的方法来添加Key.但是如果重复它就不放入.
public static void main(String[] args) {Set<String> set = new TreeSet<>();set.add("she");set.add("he");set.add("he");System.out.println(set);}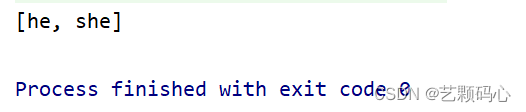
TreeSet底层也是去调用TreeMap.
注意 :
哈希表
在顺序结构以及平衡树中, 查找一个元素时,必须要经过关键码的多次比较.顺序查找时间复杂度O(n),平衡树中为树的高度,即O(logn).
而哈希表它就可以直接以O(1)的速度去查找!!!!
实现方法 : 构造一种存储结构 , 通过某种函数使元素的存储位置与它的关键码之间能够建立---映射关系,那么在查找时通过该函数就可以很快找到该元素.
哈希函数 (散列函数) : 哈希方法中使用的转换函数称为哈希(散列)函数 , 构造出来的结构称为哈希表(HashTable)(或者称散列表)
例如 : 有一组数 {1,4,3,2,75,23}
哈希函数设置为 : hash(key) = key % capacity ; capacity为元素底层空间总的大小
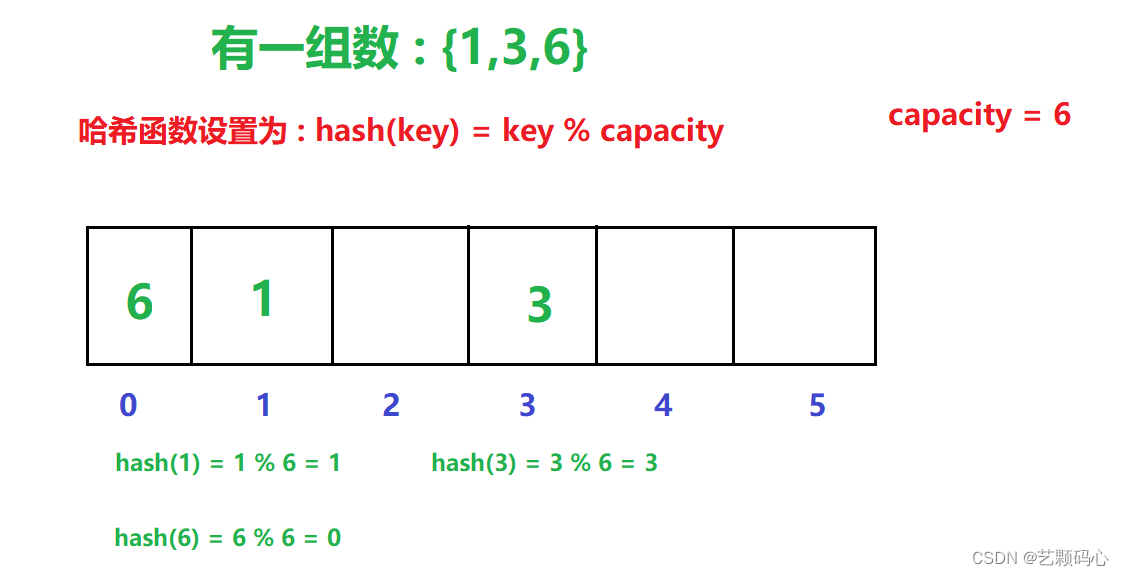
哈希冲突 :
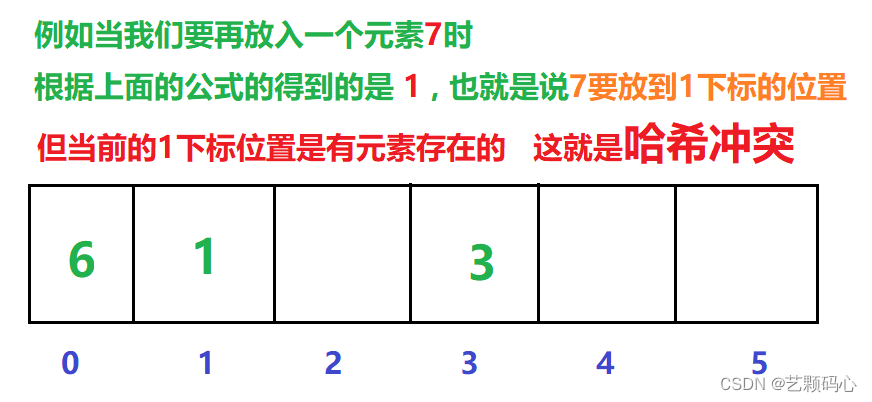
冲突避免 :
首先我们要明白一点 : 在哈希表底层数组的容量往往是小于实际要存储的关键字的数量的, 这就导致了 : 冲突的发生是必然的 , 因此我们要做的就是尽量的降低冲突率.
冲突避免 -----> 负载因子调节 (重点)
散列表的载荷因子定义为 : α = 填入表中的元素个数 / 散列表的长度

冲突解决的两种方法 :
冲突解决 ---- > 比散列(开放地址法) :
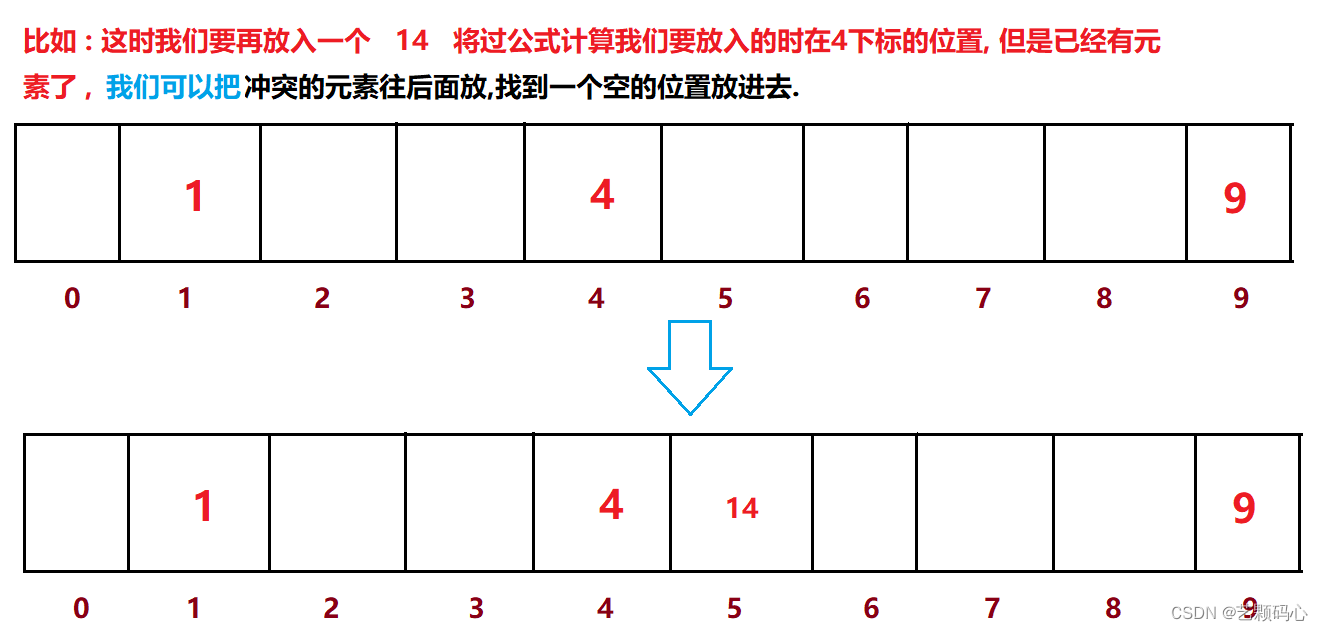
上面这种方法叫做线性探测 : 缺点是如果我们要删除4下标这个元素,如果直接删掉之后,那14就找不到了,因此我们在删4的时候只能是通过标记法来标记他已经被删除.
相比起比散列, 开散列会好很多
开散列 (链地址法 . 开链法):
它是由数组 + 链表 + 红黑树 组织起来的
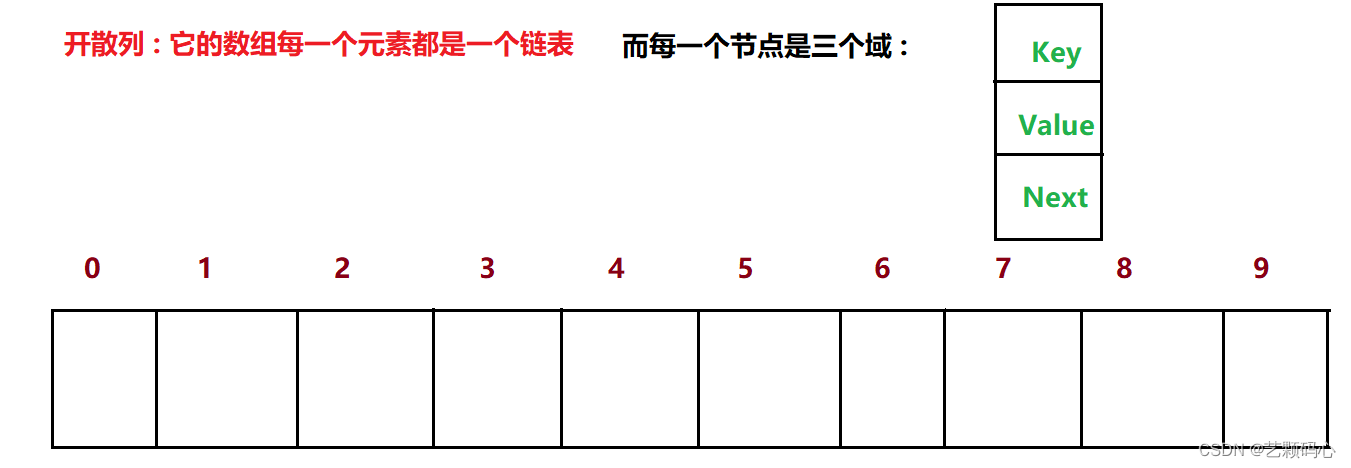
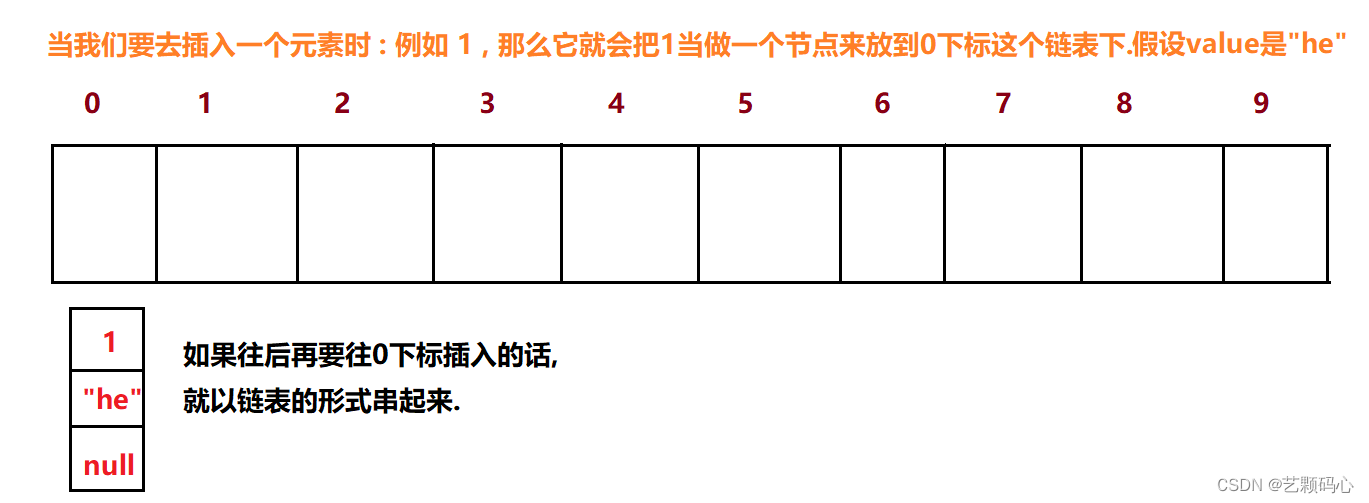
红黑树的体现 :
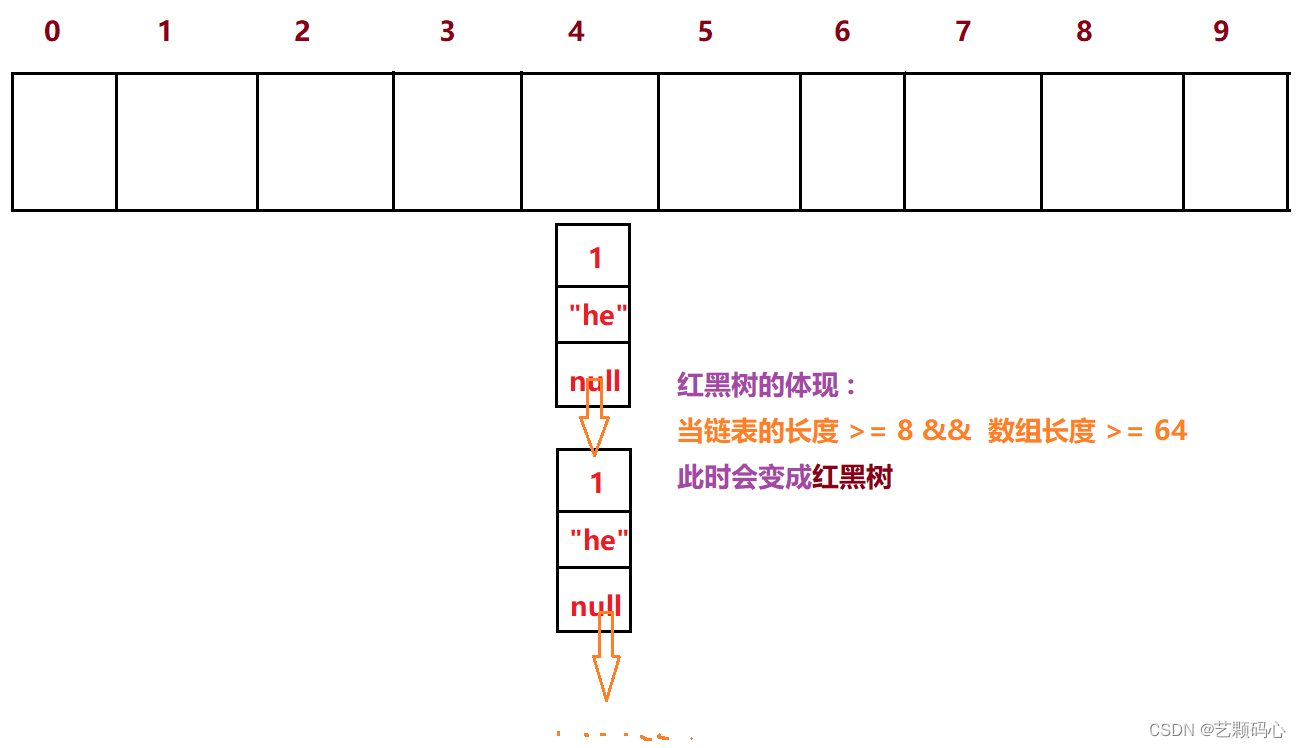
在java底层代码中 , 每一个下标下是一个链表, 采用的是尾插.
接下来我们来实现一下哈希表下面的put方法 :
我采用了头插的方式.
public class HashBuck {static class Node {public int key;public int val;public Node next;public Node(int key, int value) {this.key = key;this.val = value;}}public Node[] array;public int usedSize;//负载因子 设置为0.7public static final double loadFactor = 0.7;public HashBuck() {this.array = new Node[10];}public void put(int key, int val) {int index = key % array.length;Node cur = array[index];while (cur != null) {if (cur.key == key) {cur.val = val;}cur = cur.next;}Node newNode = new Node(key,val);newNode.next = array[index];array[index] = newNode;usedSize++;//如果负载因子 大于0.7那就扩容数组if (calculateLoadFactor() >= loadFactor) {//扩容}}//计算负载因子public double calculateLoadFactor() {return (usedSize*1.0) / array.length;}}重点在于 : 如果负载因子超过了0.7,那么我们就要去扩容,
扩容要注意 :
一定要重新哈希计算,假设我们最开始的14存在了4下标,扩容后它应该在14下标.
//扩容private void resize() {Node[] newArray = new Node[2*array.length];for (int i = 0; i < array.length; i++) {Node cur = array[i];Node curNext = null;while (cur != null) {curNext = cur.next;int index = cur.key % newArray.length; //找到了在新数组当中的位置cur.next = newArray[index];newArray[index] = cur;cur = curNext;}}this.array = newArray;}get方法 :
public int get(int key) {int index = key % array.length;Node cur = array[index];while (cur != null) {if (cur.key == key) {return cur.val;}cur = cur.next;}return -1;}我们在去求哈希参数的位置时 , 用key%数组的长度. 但是如果key是引用类型呢?
那我们就去调用hashcode方法 , 如果引用数据类型没有实现hashcode方法,那么就会调用Object里面的hashcode方法.
class Student {public int age;public String name;public Student(int age, String name) {this.age = age;this.name = name;}
}
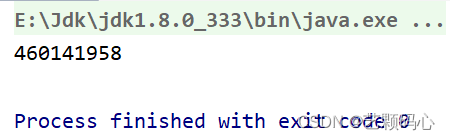
public class Test {public static void main(String[] args) {Student stu = new Student(12,"zs");System.out.println(stu.hashCode());}
}
但是问题又来了 : 如果stu 与 stu2里面的两个参数值一样 , 按照我们的理解它们应该是一样的 :
但结果确实不一样的两个结果.
public static void main(String[] args) {Student stu = new Student(12,"zs");System.out.println(stu.hashCode());Student stu2 = new Student(12,"zs");System.out.println(stu2.hashCode());}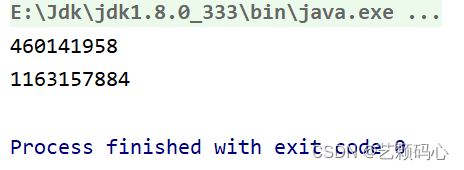
要想解决这个问题 , 我们就去Student里面去重写hashCode方法.
class Student {public int age;public String name;public Student(int age, String name) {this.age = age;this.name = name;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return age == student.age &&Objects.equals(name, student.name);}@Overridepublic int hashCode() {return Objects.hash(age, name);}
}可以看到重写后的哈希方法里 , return语句 括号里面有两个参数 , 也就意味着根据age与name去形成结果. 因此在一样的age 与 name 的情况下 , 它们调用hashCode返回的值都是相同的.
将上面的代码转变为引用类型 :
package demo2;public class HashBuck<K,V> {static class Node<K,V> {public K key;public V value;public Node<K,V> next;public Node(K key, V value) {this.key = key;this.value = value;}}public Node<K,V>[] array;public int usedSize;public static final double loadFactor = 0.7;public HashBuck() {this.array = (Node<K,V>[])new Node[10];}public void put(K key, V value) {int index = key.hashCode() % array.length;Node<K,V> cur = array[index];while (cur != null) {if (cur.key.equals(key)) {cur.value = value;return;}cur = cur.next;}Node<K,V> node = new Node<>(key,value);node.next = array[index];array[index] = node;usedSize++;if (calculateLoadFactor() >= loadFactor) {resize();}}private void resize() {Node<K,V>[] newArray = (Node<K,V>[])new Node[2*array.length];for (int i = 0; i < array.length; i++) {Node cur = array[i];Node curNext = null;while (cur != null) {curNext = cur.next;int index = cur.key.hashCode() % newArray.length; //找到了在新数组当中的位置cur.next = newArray[index];newArray[index] = cur;cur = curNext;}}this.array = newArray;}public double calculateLoadFactor() {return (usedSize*1.0) / array.length;}public V get(K key) {int index = key.hashCode() % array.length;Node<K,V> cur = array[index];while (cur != null) {if (cur.key.equals(key)) {return cur.value;}cur = cur.next;}throw new RuntimeException("找不到Key所对应的Value");}
}
重点要注意一下 : 在求哈希函数时 , 要用key.hashCode() % 数组的长度. 再然后引用数据类型之间比较相不相同要用equals()方法.
问题 : hashCode()一样 , equals一定一样吗 ?
equals()一样 , hashCode()一定一样吗 ?
答案分别为 : 不一定 , 一定 .
以上就是我对 HashMap 与 HashSet 的一些见解 . 希望可以帮到大家~~~
相关文章:
TreeSet 与 TreeMap And HashSet 与 HashMap
目录 Map TreeMap put()方法 : get()方法 : Set> entrySet() (重) : foreach遍历 : Set 哈希表 哈希冲突 : 冲突避免 : 冲突解决 ---- > 比散列(开放地址法) : 开散列 (链地址法 . 开链法) 简介 : 在Java中 , TreeSet 与 TreeMap 利用搜索树实现 Ma…...
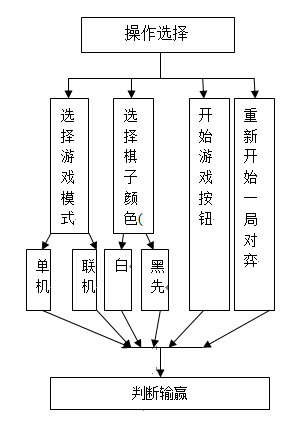
Java围棋游戏的设计与实现
技术:Java等摘要:围棋作为一个棋类竞技运动,在民间十分流行,为了熟悉五子棋规则及技巧,以及研究简单的人工智能,决定用Java开发五子棋游戏。主要完成了人机对战和玩家之间联网对战2个功能。网络连接部分为S…...

第七十三章 使用 irisstat 实用程序监控 IRIS - 使用选项运行 irisstat
文章目录第七十三章 使用 irisstat 实用程序监控 IRIS - 使用选项运行 irisstat使用选项运行 irisstatirisstat Options第七十三章 使用 irisstat 实用程序监控 IRIS - 使用选项运行 irisstat 使用选项运行 irisstat 不带选项运行 irisstat 会生成基本报告。通常,…...

【博客619】PromQL如何实现Left joins以及不同metrics之间的复杂联合查询
PromQL如何实现Left joins以及不同metrics之间的复杂联合查询 1、场景 我们需要在PromQL中实现类似SQL中的连接查询: SELECT a.value*b.value, * FROM a, b2、不同metrics之间的复杂联合查询 瞬时向量与瞬时向量之间进行数学运算: 例如:根…...
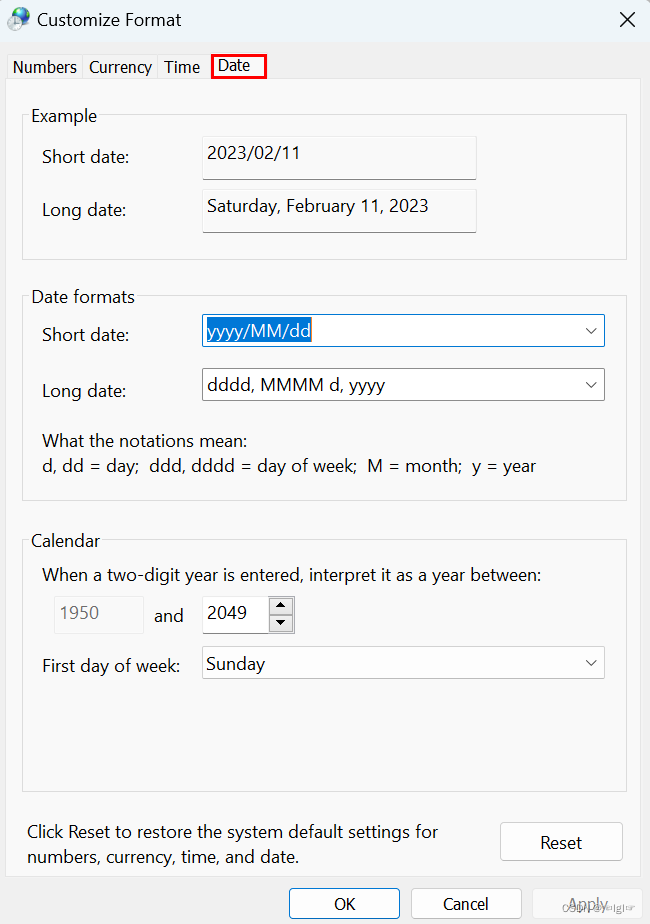
Win11自定义电脑右下角时间显示格式
Win11自定义电脑右下角时间显示格式 一、进入附加设置菜单 1、进入控制面板,选择日期和时间 2、选择修改日期和时间 3、选择修改日历设置 4、选择附加设置 二、自定义时间显示出秒 1、在选项卡中,选时间选项卡 2、在Short time的输入框中输入H:m…...
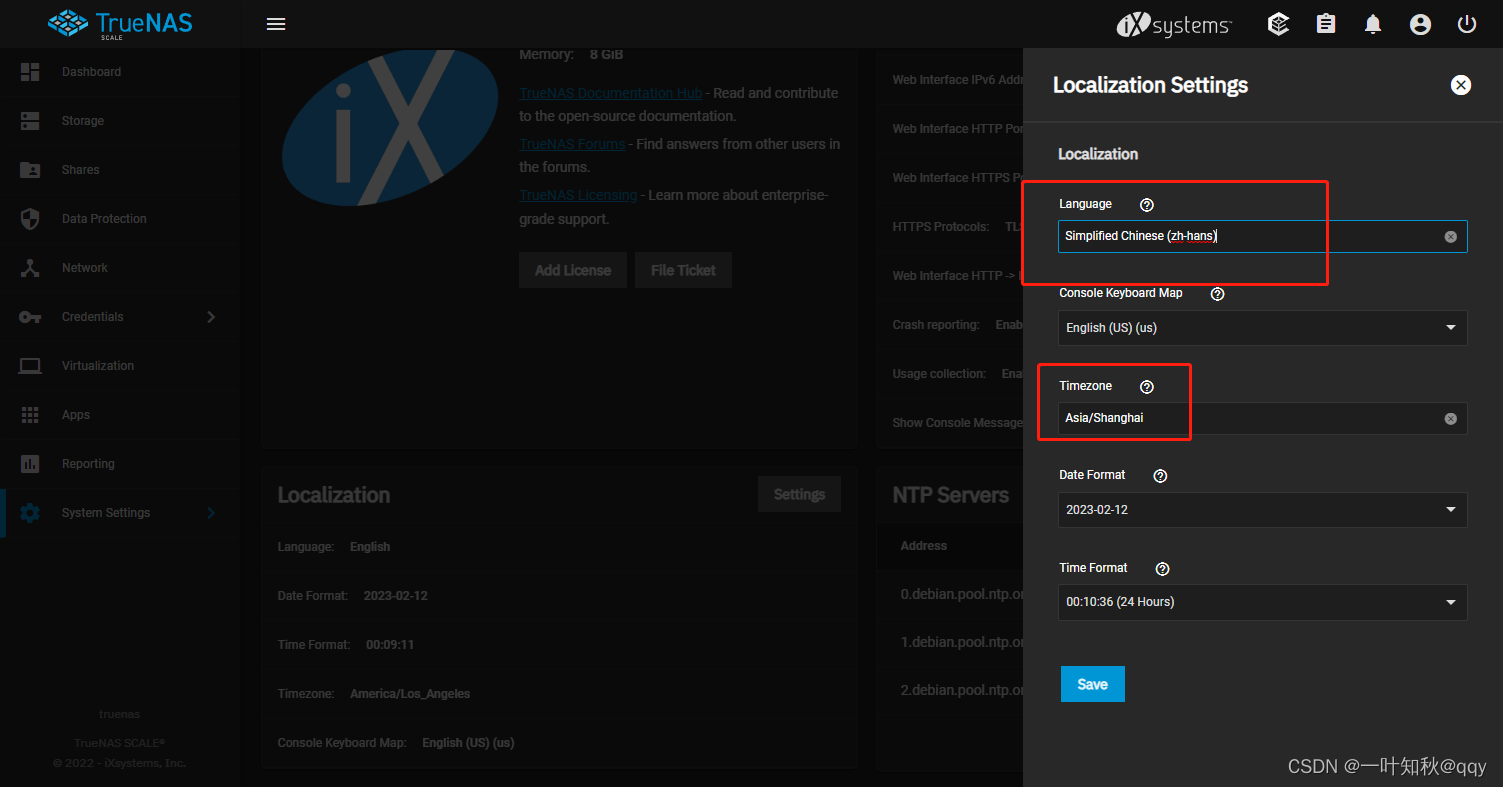
TrueNas篇-trueNas Scale安装
安装TrueNAS Scale 在尝试trueNas core时发下可以成功安装,但是一直无法成功启动,而且国内对我遇见的错误几乎没有案例,所以舍弃掉了,而且trueNas core是基于Linux的,对Linux的生态好了很多,还可以可以在t…...
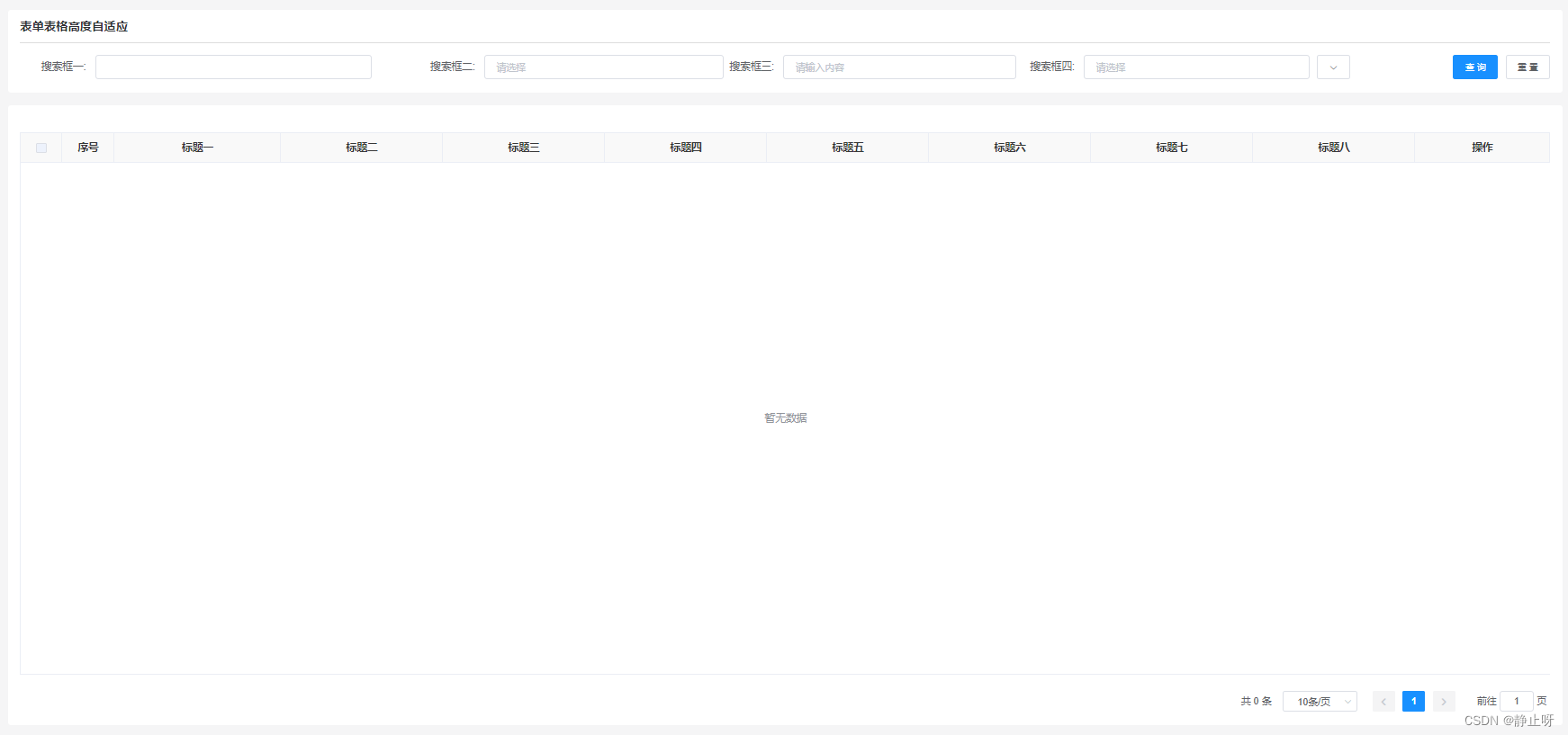
element表单搜索框与表格高度自适应
一般在后台管理系统中,表单搜索框和表格的搭配是非常常见的,如下所示: 在该图中,搜索框有五个,分为了两行排列。但根据大多数的UI标准,搜索框默认只显示一行,多余的需要进行隐藏。此时的页面被…...

MySQL使用技巧整理
title: MySQL使用技巧整理 date: 2021-04-11 00:00:00 tags: MySQL categories:数据库 重建索引 索引可能因为删除,或者页分裂等原因,导致数据页有空洞,重建索引的过程会创建一个新的索引,把数据按顺序插入,这样页面…...

七大设计原则之里氏替换原则应用
目录1 里氏替换原则2 里氏替换原则应用1 里氏替换原则 里氏替换原则(Liskov Substitution Principle,LSP)是指如果对每一个类型为 T1 的对象 o1,都有类型为 T2 的对象 o2,使得以 T1 定义的所有程序 P 在所有的对象 o1 都替换成 o2 时,程序 P…...

1行Python代码去除图片水印,网友:一干二净
大家好,这里是程序员晚枫。 最近小明在开淘宝店(店名:爱吃火锅的少女),需要给自己的原创图片加水印,于是我上次给她开发了增加水印的功能:图片加水印,保护原创图片,一行…...
)
Connext DDS属性配置参考大全(2)
DDSSecure安全com.rti.servcom.rti.serv.load_plugin...
)
一起Talk Android吧(第四百九十二回:精简版动画)
文章目录概念介绍使用方法示例代码经验总结各位看官们大家好,上一回中咱们说的例子是"动画集合:AnimatorSetBuilder",这一回中咱们说的例子是" 精简版动画"。闲话休提,言归正转,让我们一起Talk Android吧&…...
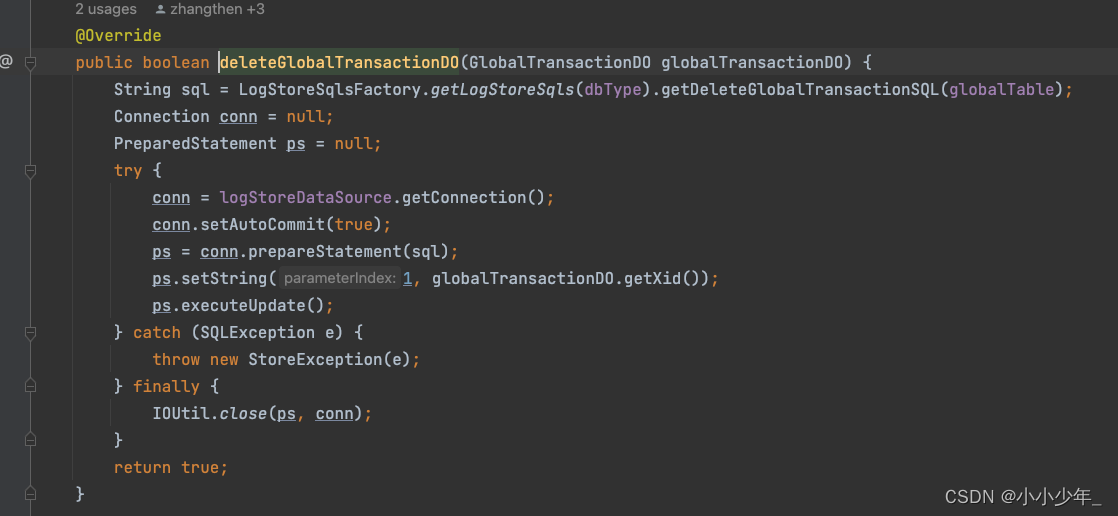
seata源码-全局事务回滚服务端源码
这篇博客来记录在发起全局事务回滚时,服务端接收到netty请求是如何处理的 1. 发起全局事务回滚请求 在前面的博客中,有说到过,事务发起者在发现分支事务执行异常之后,会提交全局事务回滚的请求到netty服务端,这里是发…...
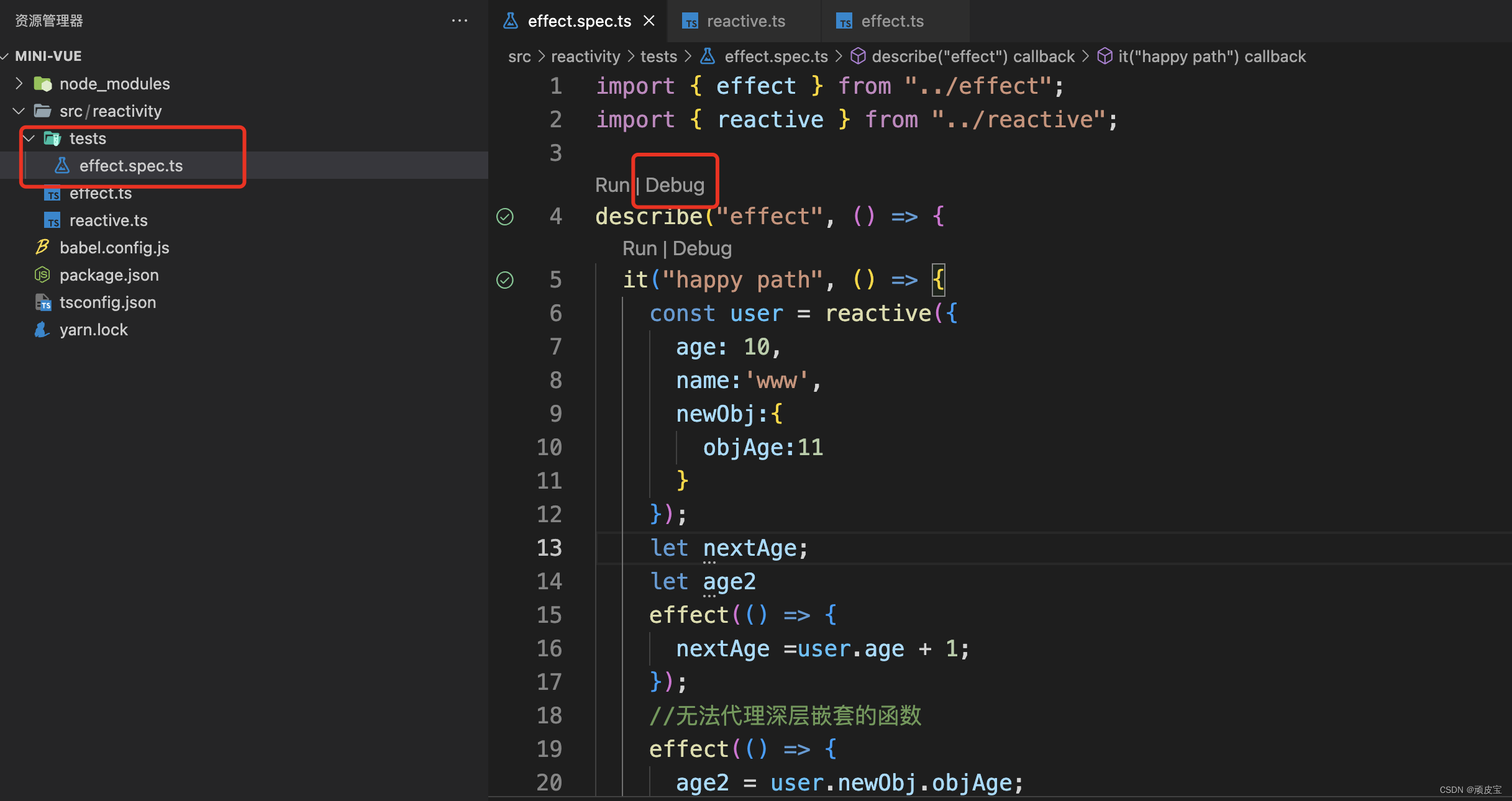
【Vue3源码】第一章 effect和reactive
文章目录【Vue3源码】第一章 effect和reactive前言1、实现effect函数2、封装track函数(依赖收集)3、封装reactive函数4、封装trigger函数(依赖触发)5、单元测试【Vue3源码】第一章 effect和reactive 前言 今天就正式开始Vue3源码…...

C函数指针
函数指针是指向函数的指针变量。通常我们说的指针变量是指向一个整型、数组或字符型等变量,而函数指针是指向函数。函数指针可以像一般函数一样,用于调用函数、传递参数。函数指针变量的声明:typedef int (*fun_ptr)(int,int); // 声明一个指…...

2023同等学力申请硕士计算机综合国考
同等学力国考报名要开始了 2023年2月15日,中国教育考试网和“全国同等学力人员申请硕士学位管理工作信息平台”(https://tdxl.chsi.com.cn,联系服务电话:010-67410388)公布报名工作通知。考生须按照通知要求进行注册或…...

英语基础-并列句概述
什么是并列句?并列句就是用连词把独立的句子连接起来,使得句子之间产生并列的逻辑。 1. 并列句中的逻辑 1. 小明步行上学,小红骑自行车上班。 Ming goes to school on foot,and Hong goes to work by bike. 平行逻辑 2. 小红经常玩手机…...
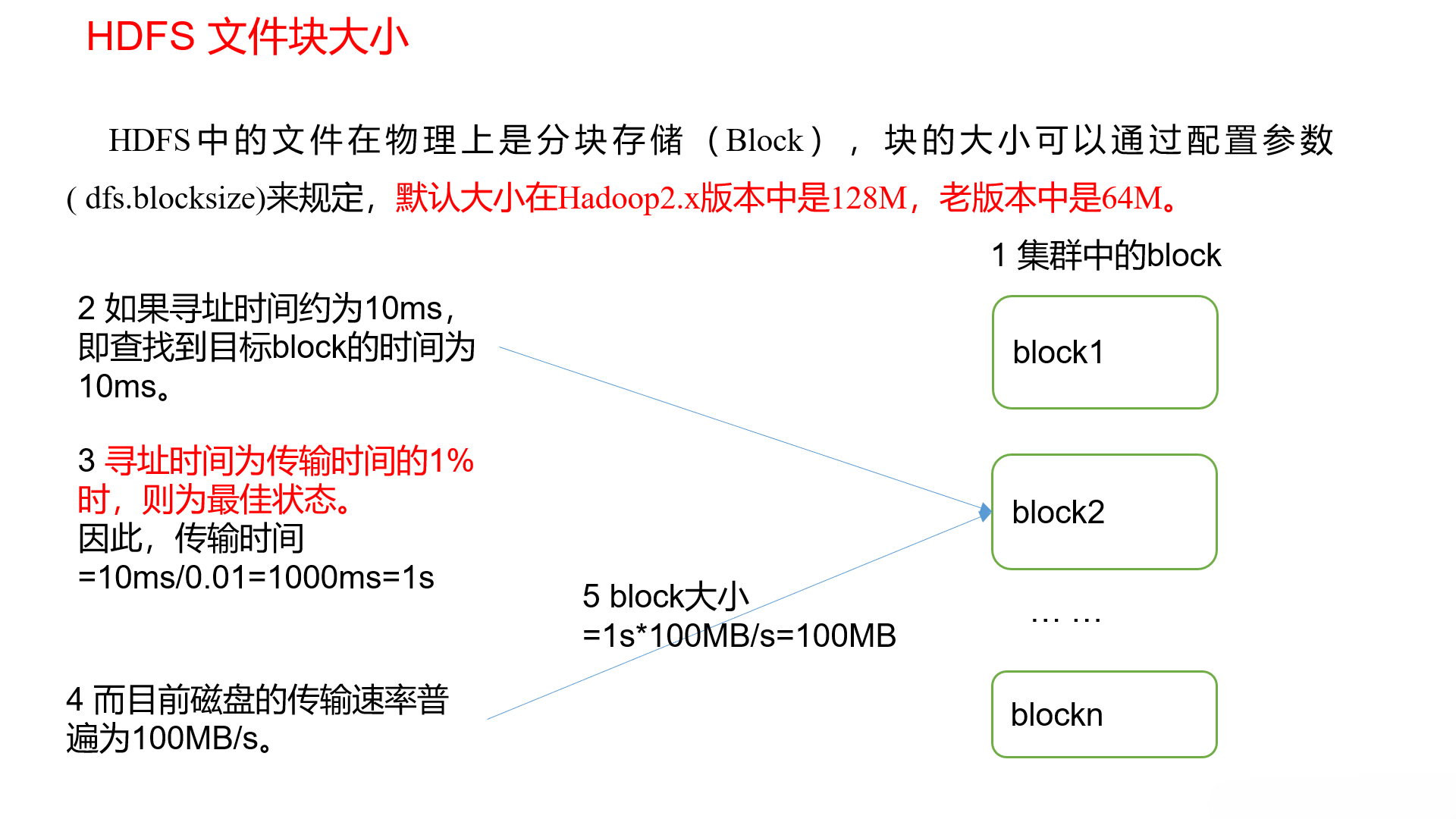
大数据框架之Hadoop:HDFS(一)HDFS概述
1.1HDFS产出背景及定义 HDFS 产生背景 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件…...
20230210组会论文总结
目录 【Ultra-High-Definition Low-Light Image Enhancement: A Benchmark and Transformer-Based Method】 【ShuffleMixer: An Efficient ConvNet for Image Super-Resolution】 【A Close Look at Spatial Modeling: From Attention to Convolution 】 【DEA-Net: Single i…...

Python - 数据容器dict(字典)
目录 字典的定义 字典数据的获取 字典的嵌套 字典的各种操作 新增与更新元素 [Key] Value 删除元素 pop和del 清空字典 clear 获取全部的键 keys 遍历字典 容器通用功能总览 字典的定义 使用{},不过存储的元素是一个个的:键值对&#…...

Excel+ChatGPT函数实战:零代码实现语义理解与智能数据处理
1. 为什么说“在Excel里直接调用ChatGPT”不是噱头,而是真正在改写数据处理的工作流 你有没有过这样的时刻:盯着Excel表格里一列杂乱的客户反馈,想快速标出哪些是投诉、哪些是表扬,却卡在手动翻查、复制粘贴、反复试错公式上&…...
)
从零到上手:用LDAP Browser连接和管理你的OpenLDAP服务器(Windows平台实战)
从零到上手:用LDAP Browser连接和管理你的OpenLDAP服务器(Windows平台实战) 在企业级身份认证体系中,LDAP(轻量级目录访问协议)扮演着核心角色。许多技术团队虽然已经部署了OpenLDAP服务端,却苦…...

TQVaultAE:泰坦之旅终极仓库管理与装备锻造指南
TQVaultAE:泰坦之旅终极仓库管理与装备锻造指南 【免费下载链接】TQVaultAE Extra bank space for Titan Quest Anniversary Edition 项目地址: https://gitcode.com/gh_mirrors/tq/TQVaultAE 你是否曾经在《泰坦之旅》中因为背包爆满而不得不丢弃心爱的传奇…...

【Gemini赋能Google Meet实时字幕】:2024企业级会议无障碍升级的5大落地陷阱与避坑指南
更多请点击: https://intelliparadigm.com 第一章:Gemini赋能Google Meet实时字幕的技术演进与企业价值定位 Google Meet 的实时字幕能力已从早期基于传统语音识别(ASR)的静态模型,跃迁至由 Gemini 多模态大模型深度驱…...

医疗电源设计:IEC 60601-1标准与EMC挑战解析
1. IEC 60601-1标准演进与医疗电源设计挑战医疗电气设备的安全性和可靠性直接关系到患者生命健康,这使得相关设计标准比普通电子设备严格得多。作为医疗设备领域的"圣经",IEC 60601-1标准自1977年首次发布以来,已经历四次重大修订&…...

Modbus文件读写功能码0x14与0x15:从协议解析到批量数据操作实战
1. Modbus文件读写功能码0x14与0x15基础解析 在工业自动化领域,Modbus协议就像设备之间的"普通话",而0x14和0x15这两个功能码则是专门用于文件读写的"方言"。想象一下,你需要从PLC读取生产配方,或者将设备配置…...
的5次机会与触发逻辑)
你的手机变砖前兆?聊聊Android救援模式(Rescue Mode)的5次机会与触发逻辑
你的手机变砖前兆?聊聊Android救援模式(Rescue Mode)的5次机会与触发逻辑 最近有位朋友在群里吐槽:"新装的购物App让手机卡成幻灯片,重启三次都没用,最后居然弹窗问我要不要恢复出厂设置?"这其实是触发了And…...

告别“盲调”:用OllyDbg 2.x手把手破解TraceMe,从GetDlgItemTextA断点到NOP修改实战
逆向工程实战:用OllyDbg 2.x破解TraceMe的关键技术与思维训练 逆向工程就像一场精心设计的数字解谜游戏,而OllyDbg则是我们手中的万能钥匙。本文将带你深入TraceMe这个经典逆向练习的内部世界,从API断点设置到关键跳转修改,完整呈…...

解锁暗黑破坏神2终极体验:d2s-editor网页版存档编辑器完全指南
解锁暗黑破坏神2终极体验:d2s-editor网页版存档编辑器完全指南 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 你是否曾经为暗黑破坏神2中漫长的升级过程感到疲惫?是否想要尝试不同的角色构建却苦于重新练…...

视频转文字软件免费的哪个最好用?2026年免费视频转文字软件对比指南
截至 2026 年,处理视频转文字需求的工具大致分为三类:桌面软件、在线网页版、微信小程序。不同类型的选择往往取决于你习惯的使用场景——有人倾向装软件后离线处理,有人则更喜欢打开就用不用卸载的方案。本文会重点拆解一款叫提词匠的微信小…...