【C++高阶】哈希之美:探索位图与布隆过滤器的应用之旅
📝个人主页🌹:Eternity._
⏩收录专栏⏪:C++ “ 登神长阶 ”
🤡往期回顾🤡:模拟实现unordered 的奥秘
🌹🌹期待您的关注 🌹🌹



❀哈希应用
- 📒1. 位图
- 🌄位图的概念
- 🏞️位图的实现
- 📜2. 布隆过滤器
- 🌈布隆过滤器概念
- 🌞布隆过滤器的插入
- 🌙布隆过滤器的查找
- ⭐布隆过滤器的优点和缺陷
- 📚3. 海量数据题目
- 🧩哈希切分
- 📖4. 总结
前言:在数据科学的浩瀚星空中,哈希函数犹如一颗璀璨的星辰,以其独特的光芒照亮了数据处理的每一个角落。哈希,这一简单而强大的技术,通过将任意长度的输入(如字符串、数字等)映射到固定长度的输出(即哈希值),实现了数据的快速定位与索引。然而,哈希的魅力远不止于此,当它与位图和布隆过滤器相结合时,更是催生出了一系列高效且实用的数据处理方案
位图(Bitmap)
但是库里面:bitset,作为一种基于位操作的数据结构,以其极低的内存占用和高效的查询性能,在数据去重、频繁项集挖掘等领域展现出了非凡的潜力。通过将数据映射到位图的特定位上,我们可以实现快速的数据检索和统计,极大地提升了数据处理的速度和效率。
而布隆过滤器(Bloom Filter),则是在位图的基础上进一步创新的杰作。它通过引入多个哈希函数和位数组的组合,巧妙地实现了对大量数据的高效检索和去重,同时允许一定程度的误判率,从而在空间效率和查询速度之间取得了完美的平衡。布隆过滤器的这一特性,使得它在网络爬虫去重、垃圾邮件过滤、数据库索引优化等多个领域得到了广泛的应用。
本文将带您踏上一场探索哈希应用、位图与布隆过滤器的旅程。我们将从哈希函数的基本原理出发,逐步深入到位图和布隆过滤器的内部工作机制,通过生动的案例和详细的解释,让您了解这些技术是如何相互协作,共同解决现实世界中的复杂问题的
让我们一起踏上学习的旅程,探索它带来的无尽可能!
📒1. 位图
🌄位图的概念
我们直接介绍位图的话,大家可能没那么好理解,我们先通过一道面试题来带领大家,看看位图的应用场景
面试题:
解决办法:
- 遍历,时间复杂度O(N)
- 排序(O(NlogN)),利用二分查找: logN
- 位图解决

大家在没学习位图之前,通常会用前两个方法来解决这个问题,但是前两个办法真的能够解决吗?对于这种海量数据,可能我们在使用前两种办法时,根本没有这么多的空间给你使用,因此我们就搞出了位图这个东西
位图解决:数据是否在给定的整形数据中,结果是在或者不在,刚好是两种状态,那么可以使用一个二进制比特位来代表数据是否存在的信息,如果二进制比特位为1,代表存在,为0代表不存在

所谓位图,就是用每一位来存放某种状态,适用于海量数据,数据无重复的场景。通常是用
来判断某个数据存不存在的
位图的应用:
- 快速查找某个数据是否在一个集合中
- 排序 + 去重
- 求两个集合的交集、并集等
- 操作系统中磁盘块标记
🏞️位图的实现

代码示例 (C++):
template<size_t N>
class bitset
{
public:// 构造函数bitset(){_bits.resize(N / 32 + 1, 0);}// ...... 其他待实现的函数
private:vector<int> _bits;
};
关于位图的模拟实现,我们只需要将它最常用的3个函数实现就够用了
- set:将一个数据放入位图中
- reset:将一个数据从位图中删掉
- test:检测一个数据在不在位图中
set的模拟实现

最后的运算我们也只需要将1移位过去进行|运算
reset的模拟实现
reset的模拟实现和set只需要将最后一步反过来:1 -> 0,但是我们没有办法将0进行移位,所以我们依旧是将1移位过去进行,但是在运算前我们进行~取反,然后进行&运算
test的模拟实现
test的模拟实现我们只需要判断该数据的映射位置是否为1就行,还是比较简单的
代码实现 (C++):
template<size_t N>
class bitset
{
public:bitset(){// 构造函数,我们在需要的空间基础上 +1_bits.resize(N / 32 + 1, 0);}void set(size_t x){size_t i = x / 32;size_t j = x % 32;_bits[i] |= (1 << j);}void reset(size_t x){size_t i = x / 32;size_t j = x % 32;_bits[i] &= ~(1 << j);}bool test(size_t x){size_t i = x / 32;size_t j = x % 32;return _bits[i] & (1 << j);}
private:vector<int> _bits;
};📜2. 布隆过滤器
我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉那些已经看过的内容。问题来了,新闻客户端推荐系统如何实现推送去重的? 用服务器记录了用户看过的所有历史记录,当推荐系统推荐新闻时会从每个用户的历史记录里进行筛选,过滤掉那些已经存在的记录。 如何快速查找呢?
- 用哈希表存储用户记录,缺点:浪费空间
- 用位图存储用户记录,缺点:位图一般只能处理整形,如果内容编号是字符串,就无法处理了
- 将哈希与位图结合,即布隆过滤器
🌈布隆过滤器概念
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间


代码示例 (C++):
template<size_t N, class K = string>
class BloomFilter
{
public:// ...... 其他待实现的函数
private:bitset<N> _bs;
}
注意:布隆过滤器的底层是上面讲到的位图
如果想要更深入的了解可以阅读一下这篇文章:
布隆过滤器详解
🌞布隆过滤器的插入
布隆过滤器的应用通常是
string类型的参数,因此我们需要和之前哈希一样,将他们转化成整形,而布隆过滤器一般会映射到3个位置,因此我们会有3个不同仿函数来计算

仿函数示例 (C++):
struct BKDRHash
{size_t operator()(const string& key){size_t hash = 0;for (auto e : key){e *= 31;hash += e;}return hash;}
}; struct APHash
{size_t operator()(const string& key){size_t hash = 0;size_t ch;for (size_t i = 0; i < key.size(); i++){ch = key[i];if ((i & 1) == 0){hash ^= ((hash << 7) ^ ch ^ (hash >> 3));}else{hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));}}return hash;}
};struct DJBHash
{size_t operator()(const string& key){size_t hash = 5381;for (auto ch : key){hash += (hash << 5) + ch;}return hash;}
};
插入代码示例 (C++):
void Set(const K& key)
{size_t hash1 = HashFunc1()(key) % N;size_t hash2 = HashFunc2()(key) % N;size_t hash3 = HashFunc3()(key) % N;_bs.set(hash1);_bs.set(hash2);_bs.set(hash3);
}
🌙布隆过滤器的查找
分别计算每个哈希值对应的比特位置存储的是否为零,只要有一个为零,代表该元素一定不在哈希表中,否则可能在哈希表中
注意:布隆过滤器如果说某个元素不存在时,该元素一定不存在,如果该元素存在时,该元素可能存在,因为有些哈希函数存在一定的误判
查找代码示例 (C++):
bool Test(const K& key)
{// 判断不存在时准确的size_t hash1 = HashFunc1()(key) % N;if (_bs.test(hash1) == false)return false;size_t hash2 = HashFunc2()(key) % N;if (_bs.test(hash2) == false)return false;size_t hash3 = HashFunc3()(key) % N;if (_bs.test(hash3) == false)return false;// 存在误判return true;
}

布隆过滤器如果说某个元素不存在时,该元素一定不存在
如果该元素存在时,该元素可能存在
⭐布隆过滤器的优点和缺陷
优点:
- 增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无
关- 哈希函数相互之间没有关系,方便硬件并行运算
- 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
- 在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势
- 数据量很大时,布隆过滤器可以表示全集,其他数据结构不能
- 使用同一组散列函数的布隆过滤器可以进行交、并、差运算
缺陷:
- 有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再
建立一个白名单,存储可能会误判的数据)- 不能获取元素本身
- 一般情况下不能从布隆过滤器中删除元素
- 如果采用计数方式删除,可能会存在计数回绕问题
📚3. 海量数据题目
🧩哈希切分

不管文件大小,我们都是直接读取到内存,然后插入set
- 情况一:文件很多重复,后面重复插入都是失败,因此我们可以直接插入到set中
- 情况二:不断插入set后,内存不足,会抛异常,因此我们要换哈希函数,进行二次切分
位图应用:
- 给定100亿个整数,设计算法找到只出现一次的整数?
- 给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
- 位图应用变形:1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整
数
布隆过滤器:
- 给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出
精确算法和近似算法- 如何扩展BloomFilter使得它支持删除元素的操作
📖4. 总结
随着我们对哈希应用、位图与布隆过滤器的深入探讨,不难发现,这些技术不仅仅是数据科学工具箱中的简单工具,它们更是智慧与创新的结晶,为数据的快速处理、高效检索和精确去重提供了强有力的支持
哈希函数以其独特的映射能力,为我们打开了一扇通往高效数据处理的大门。而位图,则以其极低的内存占用和快速的查询性能,成为了处理大规模数据集时的得力助手。至于布隆过滤器,它更是在继承位图优势的基础上,通过引入哈希函数的组合,实现了对大量数据的快速检索与去重,虽然伴随着一定的误判率,但其在空间效率与查询速度之间的精妙平衡,让它在众多应用场景中大放异彩
随着数据量的持续增长和数据处理需求的日益复杂,我们有理由相信,哈希应用、位图与布隆过滤器等高效数据处理技术将会得到更加广泛的应用和深入的研究。它们将继续在数据科学的舞台上发光发热,为我们揭示更多数据背后的秘密和价值
我们期待每一位读者都能从本次探索中汲取到宝贵的知识和经验,保持对新技术、新知识的好奇心和求知欲,不断探索、不断学习、不断进步

希望本文能够为你提供有益的参考和启示,让我们一起在编程的道路上不断前行!
谢谢大家支持本篇到这里就结束了,祝大家天天开心!

相关文章:
【C++高阶】哈希之美:探索位图与布隆过滤器的应用之旅
📝个人主页🌹:Eternity._ ⏩收录专栏⏪:C “ 登神长阶 ” 🤡往期回顾🤡:模拟实现unordered 的奥秘 🌹🌹期待您的关注 🌹🌹 ❀哈希应用 Ǵ…...

文件包涵条件竞争(ctfshow82)
Web82 利用 session.upload_progress 包含文件漏洞 <!DOCTYPE html> <html> <body> <form action"https://09558c1b-9569-4abd-bf78-86c4a6cb6608.challenge.ctf.show//" method"POST" enctype"multipart/form-data"> …...

通信原理-思科实验三:无线局域网实验
实验三 无线局域网实验 一:无线局域网基础服务集 实验步骤: 进入物理工作区,导航选择 城市家园; 选择设备 AP0,并分别选择Laptop0、Laptop1放在APO范围外区域 修改笔记本的网卡,从以太网卡切换到无线网卡WPC300N 切…...
第三十一天 | 1049. 最后一块石头的重量 II、494. 目标和、474. 一和零)
*算法训练(leetcode)第三十一天 | 1049. 最后一块石头的重量 II、494. 目标和、474. 一和零
刷题记录 *1049. 最后一块石头的重量 II*494. 目标和474. 一和零 *1049. 最后一块石头的重量 II leetcode题目地址 本题与分割等和子集类似,要达到碰撞最后的石头重量最小,则尽可能把石头等分为两堆。 时间复杂度: O ( m ∗ n ) O(m * n)…...

mac中如何使用obs推流以及使用vlc播放
使用obs推流 1.打开obs,在“来源”框中->点加号->选择媒体源->选择本地ts文件 2.obs中->点击右下角设置->点直播->服务选自定义->服务器填写你的srt服务url,比如:srt://192.168.13.211:14000?modecaller 注意ÿ…...

shopee虾皮 java后端 一面面经 整体感觉不难
面试总结:总体不难,算法题脑抽了只过了一半,面试官点出了问题说时间到了,反问一点点,感觉五五开,许愿一个二面 1.Java中的锁机制,什么是可重入锁 Java中的机制主要包括 synchronized关键字 Loc…...

HydraRPC: RPC in the CXL Era——论文阅读
ATC 2024 Paper CXL论文阅读笔记整理 问题 远程过程调用(RPC)是分布式系统中的一项基本技术,它允许函数在远程服务器上通过本地调用执行来促进网络通信,隐藏底层通信过程的复杂性简化了客户端/服务器交互[15]。RPC已成为数据中心…...

pve笔记
配置显卡直通参考 https://blog.csdn.net/m0_59148723/article/details/130923893 https://foxi.buduanwang.vip/virtualization/pve/561.html/ https://www.cnblogs.com/MAENESA/p/18005241 https://www.wangsansan.com/archives/181/ pve配置显卡直通到虚拟机后,…...
typecho仿某度响应式主题Xaink
新闻类型博客主题,简洁好看,适合资讯类、快讯类、新闻类博客建站,响应式设计,支持明亮和黑暗模式 直接下载 zip 源码->解压后移动到 Typecho 主题目录->改名为xaink->启用。 演示图: 下载链接: t…...

springcloud RocketMQ 客户端是怎么走到消费业务逻辑的 - debug step by step
springcloud RocketMQ ,一个mq消息发送后,客户端是怎么一步步拿到消息去消费的?我们要从代码层面探究这个问题。 找的流程图,有待考究。 以下我们开始debug: 拉取数据的线程: PullMessageService.java 本…...

GPT-4o mini小型模型具备卓越的文本智能和多模态推理能力
GPT-4o mini 是首个应用OpenAI 指令层次结构方法的模型,这有助于增强模型抵抗越狱、提示注入和系统提示提取的能力。这使得模型的响应更加可靠,并有助于在大规模应用中更安全地使用。 GPT-4o mini 在学术基准测试中,无论是在文本智能还是多模…...

Milvus 向量数据库进阶系列丨部署形态选型
本系列文章介绍 在和社区小伙伴们交流的过程中,我们发现大家最关心的问题从来不是某个具体的功能如何使用,而是面对一个具体的实战场景时,如何选择合适的向量数据库解决方案或最优的功能组合。在 “Milvus 向量数据库进阶” 这个系列文章中&…...

【React】详解受控表单绑定
文章目录 一、受控组件的基本概念1. 什么是受控组件?2. 受控组件的优势3. 基本示例导入和初始化定义函数组件处理输入变化处理表单提交渲染表单导出组件 二、受控组件的进阶用法1. 多个输入框的处理使用多个状态变量使用一个对象管理状态 2. 处理选择框(…...

使用puma部署ruby on rails的记录
之前写过一篇《记录一下我的Ruby On Rails的systemd服务脚本》的记录,现在补上一个比较政治正确的Ruby On Rails的生产环境部署记录。使用Puma部署项目。 创建文件 /usr/lib/systemd/system/puma.service [Unit] DescriptionPuma HTTP Server DocumentationRuby O…...

如何在Linux上使用Ansible自动化部署
Ansible是一个开源的自动化工具,可以帮助开发人员和系统管理员对大规模的服务器进行自动化部署和管理。它使用SSH协议来在远程服务器上执行任务,并通过模块化的方式提供了丰富的功能,可以轻松地管理服务器配置、软件部署和应用程序运行。 在…...

scrapy爬取城市天气数据
scrapy爬取城市天气数据 一、创建scrapy项目二、修改settings,设置UA,开启管道三、编写爬虫文件四、编写items.py五、在weather.py中导入WeatherSpiderItem类六、管道中存入数据,保存至csv文件七、完整代码一、创建scrapy项目 先来看一下爬取的字段情况: 本次爬取城市天…...
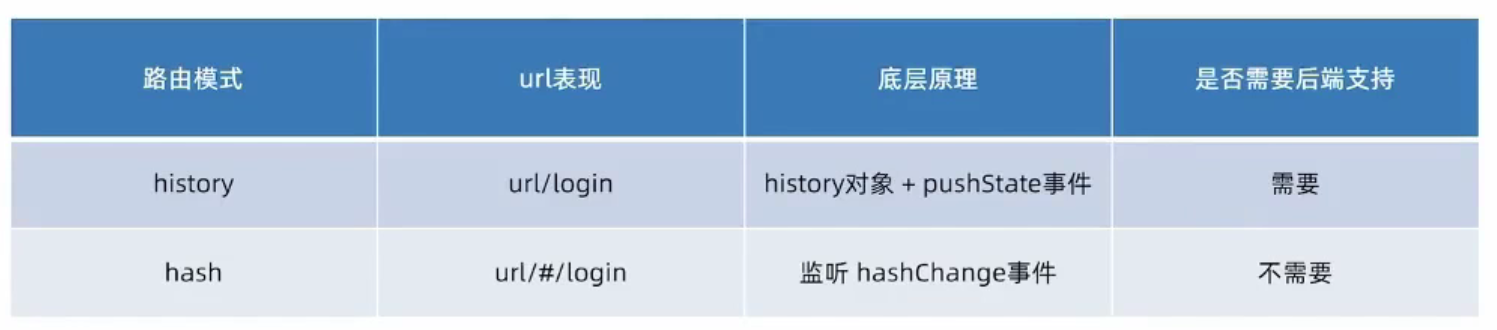
一天搞定React(5)——ReactRouter(下)【已完结】
Hello!大家好,今天带来的是React前端JS库的学习,课程来自黑马的往期课程,具体连接地址我也没有找到,大家可以广搜巡查一下,但是总体来说,这套课程教学质量非常高,每个知识点都有一个…...

微信小程序之计算器
在日常生活中,计算器是人们广泛使用的工具,可以帮助我们快速且方便地计算金额、成本、利润等。下面将会讲解如何开发一个“计算器”微信小程序。 一、开发思路 1、界面和功能 “计算器”微信小程序的页面效果如图所示 在计算器中可以进行整数和小数的…...

【logstash】logstash使用多个子配置文件
这里有个误区在pipelines.yml中写conf.d/*,实测会有问题,不同的filter处理逻辑会复用。 现在有两个从kafka采集日志的配置文件:from_kafka1.conf,from_kafka2.conf 修改pipelines.yml配置文件 config/pipelines.yml- pipeline.i…...

暴风骑士S9电摩上市,定义青少年骑行安全新标准
暴风骑士,作为全球高端儿童电动车的开创品牌,以其卓越的技术实力和创新精神,不断推动行业发展。如今,暴风骑士再次突破自我,推出了全新力作——S9青少年电摩。这款全新上市的青少年专属电摩,以其领先的安全…...

如何判断孩子是否适合学GESP
判断孩子是否适合学GESP,核心是看年龄、兴趣、逻辑能力与长期目标是否匹配。以下是结合当前(2026年)政策与实践的系统性判断标准: 一、适龄范围:6–18岁,但分阶段更关键 年龄段 是否适合 说明 6–9岁…...

绝地求生罗技鼠标宏终极教程:5分钟实现完美压枪
绝地求生罗技鼠标宏终极教程:5分钟实现完美压枪 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求生》中难以控制的后坐…...

基于RAG的Obsidian智能知识库:本地部署与优化实战
1. 项目概述:当知识管理遇上大语言模型 如果你和我一样,是 Obsidian 的深度用户,同时又对大语言模型(LLM)的智能涌现能力感到着迷,那么你肯定也想过一个问题:能不能让我的知识库“活”起来&…...

法律科技实践:基于Python与NLP的法律文书自动化处理工具集
1. 项目概述:一个法律从业者的效率工具箱如果你是一名律师、法务或者法律专业的学生,每天面对海量的法律文书、案例检索和合同审查,你一定会对“效率”这个词有切肤之痛。我从事法律相关工作超过十年,从最初的实习律师到后来独立处…...

t-io HTTP服务器实现:如何替代Tomcat和Jetty的完整指南
t-io HTTP服务器实现:如何替代Tomcat和Jetty的完整指南 【免费下载链接】t-io T-io is a network programming framework developed based on Java AIO. From the collected cases, t-io is widely used for IoT, IM, and customer service, making it a top-notch …...

Windows任务栏图标自由拖拽:DriftX开源工具原理与编译部署指南
1. 项目概述:一个被低估的桌面美化利器如果你和我一样,是个对Windows桌面整洁度有强迫症的程序员或者效率追求者,那你肯定对系统自带的图标排列方式感到过无奈。任务栏上堆满了图标,桌面文件散落各处,想找个应用还得在…...

AI驱动软件架构可视化:C4模型与生成式AI的融合实践
1. 项目概述:当企业架构图遇上生成式AI 最近在技术社区里,一个名为 codecentric/c4-genai-suite 的项目引起了我的注意。乍一看标题,它融合了两个看似不相关的领域:C4模型和生成式AI。C4模型,对于软件架构师和开发者…...

GitHub PR全流程实战:从创建、自动化测试到代码审查与合并
1. 项目概述与核心价值 如果你参与过开源项目,或者在公司内部使用GitHub进行团队协作,那么“Pull Request”(PR)这个流程你一定不陌生。它不仅仅是把代码从一个分支合并到另一个分支那么简单,而是一整套围绕代码质量、…...

创业团队如何用Taotoken低成本试验多个AI模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业团队如何用Taotoken低成本试验多个AI模型 对于资源有限的创业团队而言,在开发产品原型或验证AI功能时,…...

VMware Workstation 17 Pro 保姆级教程:5分钟搞定Win11虚拟机TPM 2.0和安全启动配置
VMware Workstation 17 Pro 极速配置指南:Win11虚拟机TPM 2.0与安全启动实战 在虚拟化技术领域,VMware Workstation一直保持着领先地位。随着Windows 11的发布,许多开发者和技术爱好者都希望在虚拟机中体验这个新系统,却频繁遭遇T…...