Milvus 向量数据库进阶系列丨部署形态选型
本系列文章介绍
在和社区小伙伴们交流的过程中,我们发现大家最关心的问题从来不是某个具体的功能如何使用,而是面对一个具体的实战场景时,如何选择合适的向量数据库解决方案或最优的功能组合。在 “Milvus 向量数据库进阶” 这个系列文章中,我们会聚焦回答这一类问题,如 “在 AI 应用开发的不同阶段,向量数据库应该如何选型”,“如何正确的构建 RAG 多租系统” 等。虽然这个系列名为进阶,但内容同时适用于初级和进阶用户。我们希望通过这些内容的介绍,帮助大家在向量数据库应用的过程中少走弯路。

Milvus 是目前发展最成熟的开源向量数据库项目。和 Qdrant、Weaviate、Chroma 这些近两年的新项目不同,Milvus 为开发者提供了多种部署形态。当然,更多的选择有时候也会带来一些困扰,经常会有同学问怎么选合适的部署形态,今天这篇文章就来和大家详细聊聊这个话题。
现在官方一共提供了三种 Milvus 部署形态:Milvus Lite,Milvus Standalone,Milvus Distributed:
Milvus Lite 可以认为是一个 library 级别的超小型 Milvus。主要面向 python/notebook 环境的快速原型构建、或一些本地的小规模实验。
Milvus Lite 原生集成在 pymilvus 包里,直接 pip install pymilvus,你就在本地完成了 Milvus Lite 的安装。用的时候不需要额外启动服务端,插入数据的持久化都是走的本地文件。
Milvus Standalone 是 Client-Server 模式,是 Milvus 的单机部署形态。Milvus Lite 和 Milvus Standalone 的关系,类似 SQLite 和 MySQL 的关系。Milvus Standalone 的所有组件都打在一个 Docker 镜像里,服务端部署也比较方便。
如果你不是在支持一个大型项目,一般搞一台内存大点儿的机器,部署一套 Milvus Standalone 就够用了。值得提的一点是,Milvus Standalone 支持主备模式高可用,生产环境是可以上的。
Milvus Distributed 是 Milvus 的分布式部署模式。企业用户搭大规模向量数据库系统(或向量数据平台、中台),一般首选这种模式。Milvus Distribute 采用云原生架构,读写分离,关键组件都支持冗余,在三种部署模式中提供最高的扩展性能力和高可用级别,以及组件级的弹性能力(如根据业务负载特征单独扩缩 Proxy、查询节点、索引节点等)。
01.
不同场景下的部署形态选型
一般说选型肯定离不开阶段。用到向量数据库的应用基本有这么几个阶段:
AI 应用的快速原型构建。比如你在做一个 AI 个人助手、一个小的搜索引擎原型、一个端到端的 RAG 原型,这类项目的迭代速度是很关键的,而且原型构建期不需要关心性能或者稳定性这样的指标。因此 Milvus Lite,或 Milvus Lite + Milvus Standalone 会是比较合适的选择。你可以在 notebook 结合 Milvus Lite 快速实现端到端功能搭建,以及面向效果的轻量化实验。
如果你同时也需要在规模大一些的数据集上验证效果,那再起一套 Milvus Standalone 是合适的。注意这里 Milvus Lite 和 Milvus Standalone 并不是独立的两部分,它们支持了一个简单的从笔记本到服务器的工作流:由于 Milvus Lite、Standalone、Distributed 共享一套客户端接口,同样的业务侧代码既可以使用本地数据进行原型开发,也可以链接到服务端进行大规模数据验证。同时 Standalone 支持多用户,一个敏捷开发小组可以使用一套 Milvus Standalone 服务进行协作或共享数据。
早期的生产部署。这里早期指的是项目上线早期,业务访问请求和数据还没有上量、项目还在寻找 Product-market-fit 的阶段。这个阶段你需要关心的仍然是业务效果和业务竞争力,而不是基础设施。因此 Milvus Standalone 是最合适的选择。对于在线业务,需要部署一套主备模式的 Milvus 来保证高可用。对于测试环境,单节点部署即可。
需要注意的是,Milvus Standalone 并不提供表间物理资源隔离。因此如果你有两个业务都很关键且性能敏感,最好把它们的数据通过两套 Milvus Standalone 进行隔离。这可能会带来一些物理资源的浪费,但仍然会比运维 Milvus Distributed 的综合成本低很多。还是那句话,这个阶段你需要聚焦的是业务效果和业务竞争力,而不是基础设施。
当然,这个阶段你仍然可以结合 Milvus Lite 进行一些效果调试工作,特别是面向一些具体用户需求的效果调试。这部分工作不建议在部署 Milvus Standalone 的生产环境进行,这有可能会带来一些潜在的性能和稳定性风险。
大规模生产部署。在这个阶段,你的数据已经超过了单台服务器所能容纳的规模;或数据每天都在快速增长,你需要为后续的业务增长提前做好基础设施的准备。这个时候就需要 Milvus Distributed 登场了。前期会是 Milvus Standalone 和 Milvus Distributed 两套实例并存,我们需要把流量逐步从 Standalone 切换至 Milvus Distributed。并观察至少一个月保证 Milvus Distributed 运行稳定。
这个阶段你也需要逐步完善你的运维系统。Milvus Distributed 原生支持 Prometheus,同时也提供了 Attu 等管理工具。需要注意的是,尽管 Milvus 官方提供了一系列专用运维工具,以及尽可能丰富的生态工具对接,运维一套大型分布式系统并非容事,在这期间你可能会需要比较多的社区帮助。Milvus 社区非常开放,一些主要的社区交流入口我都留在了文末。
02.
不同开源向量数据库的适用数据规模
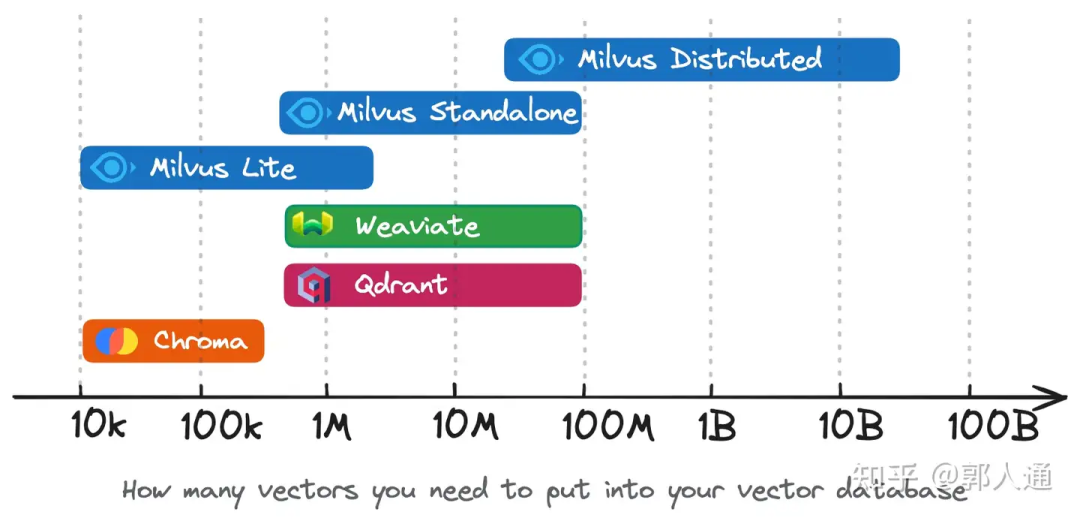
图1. 开源向量数据库适用的数据规模
咱们前面主要说的都是 Milvus,这里把其他几个受欢迎的开源向量数据库也拿过来做一个比较。
去年,Chroma 在 AI 个人开发者圈子里比较火。这个项目的特点是聚焦小数据规模,并提供向量数据库功能的最小功能集。如果你的应用只有不到几十万的向量,而且只需要使用数据插入和查询这样的最基本功能,Chroma 可以提供非常轻便的体验。需要注意的是,即便和 Milvus Lite 相比,Chroma 也仅提供了一个功能子集,且并不面向生产。
Weaviate 和 Qdrant 这两个项目更加的 Production Ready。其中,Weaviate 更聚焦 AI 应用对向量数据库的集成,原生提供了一些上游模型的支持。Qdrant 更聚焦向量数据库本身,关注向量查询能力以及性能。(Qdrant 是所有向量数据库项目中,在性能上跟随 Milvus 最紧的一个项目,详见 VectorDB Benchmark)
图1 对这几个向量数据库的数据规模适用范围进行了比较:
-
Milvus Lite 和 Chroma 都适合不超过百万的数据,这个区间的设计考量主要是系统能力和易用性之间的tradeoff,且更偏向易用性。
-
Milvus Standalone、Weaviate、Qdrant 合适的数据规模是百万至小几千万这个范围。在系统能力和易用性之间的设计考量比较平衡。
-
Milvus Distributed 合适的数据规模在千万及以上。目前社区已经广泛验证了十亿级规模的场景支持,今年也陆续有百亿级规模的场景落地。
和 Milvus 相比,其他几个项目暂未提供长跨度的部署支持。因此在项目演进的不同阶段会有向量数据库选型切换的成本。对于不同数据规模下的混合工作流的支持也没有 Milvus 灵活。
03.
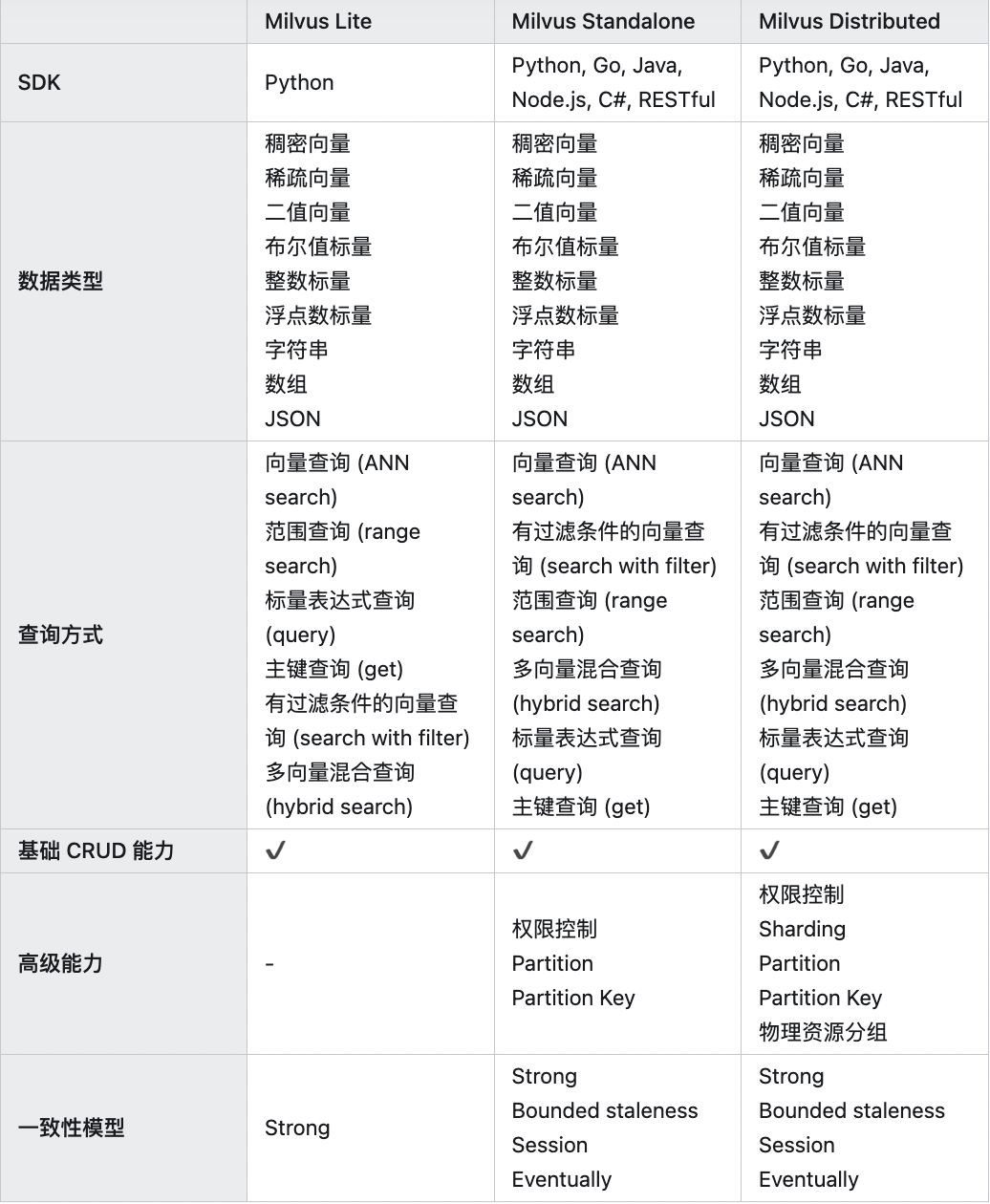
Milvus Lite,Standalone,Distributed的能力对比
04.
Milvus Lite,Standalone,Distributed的组件功能关系
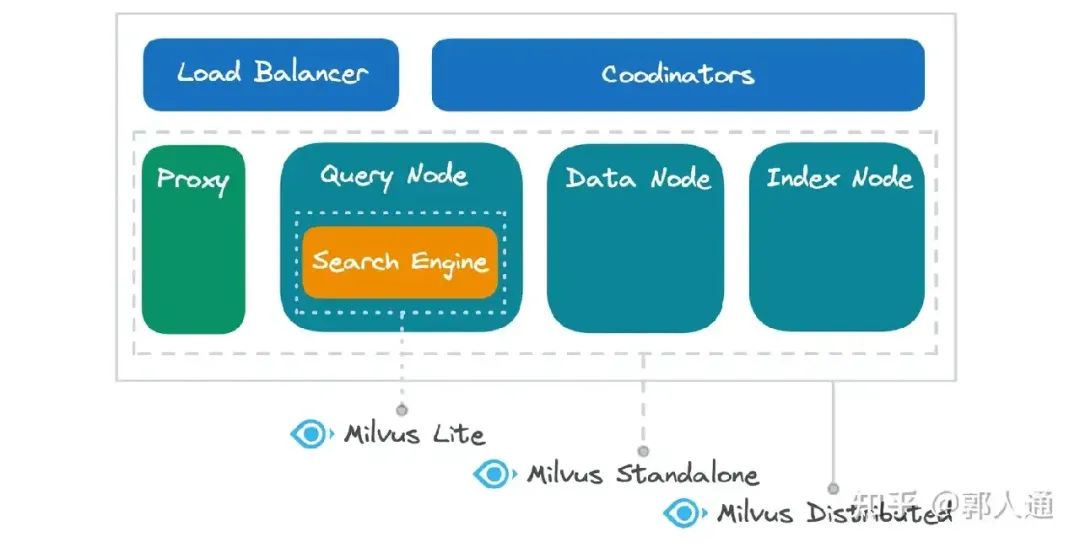
图2. Lite, Standalone, Distributed 包含的功能组件
Milvus Lite,Standalone,Distributed 之所以能提供一致的使用体验, 并保持相同的演进速度,主要得益于这三种部署模式对底层组件的共享。
上图给出了这三种形态各自覆盖的 Milvus 功能组件:
Milvus Lite 主要是对 Search Engine 的封装,同时对数据写入、持久化、索引构建、元信息管理等必备能力提供了本地实现。这也是为什么 Milvus Lite 可以被视为一个 library 的主要原因。但相比 Chroma 这样具有简易实现的 library,Milvus 的 search engine 无论在性能还是查询能力上都要强悍很多,且更适合嵌入。如果你只是在寻找一个 Faiss 或者 HNWSLib 的替代,Milvus Lite 也是相当合适的。Milvus 查询引擎原生集成了这些主流的向量搜索算法库,整合社区也投入了大量工作进行深度的性能和功能优化。
Milvus Standalone 包含了除负载均衡 (load balancer)、多节点管理 (coordinators) 以外的所有功能组件。这些组件运行在同一个 Docker 环境中,因为所有组件间都是本地通信,因此可以获得很好的服务端延迟。
Milvus Distributed 包含所有功能组件。需要注意的是,Standalone 和 Distributed 虽然都包含 Proxy、Query Node、Data Node、Index Node,且功能相同,但 Distributed 提供更加灵活的部署方式。从数量上看,每一种功能组件都可以部署多个,从而支持更高的负载;从物理资源映射的层面看,不同功能的组件可以被部署到相同物理节点以实现资源共享,或部署到不同物理节点以实现组件间资源隔离;从组件间解耦的层面看,每一种组件都可以进行独立的扩缩容,以适应多样化的负载特征,并有效提高资源利用率。
Milvus 向量数据库进阶系列下期预告
现在市面上的 RAG 系统不管是 to B 的还是to C 的,基本都需要考虑多租。下一篇我们将结合Milvus,讲一讲如何构建 RAG 多租户/多用户系统。
作者介绍

郭人通,Zilliz 合伙人和产品总监,CCF 分布式计算与系统专委会执行委员。专注于开发面向 AI 的高效并可扩展的数据分析系统。郭人通拥有华中科技大学计算机软件与理论博士学位。
相关文章:
Milvus 向量数据库进阶系列丨部署形态选型
本系列文章介绍 在和社区小伙伴们交流的过程中,我们发现大家最关心的问题从来不是某个具体的功能如何使用,而是面对一个具体的实战场景时,如何选择合适的向量数据库解决方案或最优的功能组合。在 “Milvus 向量数据库进阶” 这个系列文章中&…...

【React】详解受控表单绑定
文章目录 一、受控组件的基本概念1. 什么是受控组件?2. 受控组件的优势3. 基本示例导入和初始化定义函数组件处理输入变化处理表单提交渲染表单导出组件 二、受控组件的进阶用法1. 多个输入框的处理使用多个状态变量使用一个对象管理状态 2. 处理选择框(…...

使用puma部署ruby on rails的记录
之前写过一篇《记录一下我的Ruby On Rails的systemd服务脚本》的记录,现在补上一个比较政治正确的Ruby On Rails的生产环境部署记录。使用Puma部署项目。 创建文件 /usr/lib/systemd/system/puma.service [Unit] DescriptionPuma HTTP Server DocumentationRuby O…...

如何在Linux上使用Ansible自动化部署
Ansible是一个开源的自动化工具,可以帮助开发人员和系统管理员对大规模的服务器进行自动化部署和管理。它使用SSH协议来在远程服务器上执行任务,并通过模块化的方式提供了丰富的功能,可以轻松地管理服务器配置、软件部署和应用程序运行。 在…...

scrapy爬取城市天气数据
scrapy爬取城市天气数据 一、创建scrapy项目二、修改settings,设置UA,开启管道三、编写爬虫文件四、编写items.py五、在weather.py中导入WeatherSpiderItem类六、管道中存入数据,保存至csv文件七、完整代码一、创建scrapy项目 先来看一下爬取的字段情况: 本次爬取城市天…...
一天搞定React(5)——ReactRouter(下)【已完结】
Hello!大家好,今天带来的是React前端JS库的学习,课程来自黑马的往期课程,具体连接地址我也没有找到,大家可以广搜巡查一下,但是总体来说,这套课程教学质量非常高,每个知识点都有一个…...

微信小程序之计算器
在日常生活中,计算器是人们广泛使用的工具,可以帮助我们快速且方便地计算金额、成本、利润等。下面将会讲解如何开发一个“计算器”微信小程序。 一、开发思路 1、界面和功能 “计算器”微信小程序的页面效果如图所示 在计算器中可以进行整数和小数的…...

【logstash】logstash使用多个子配置文件
这里有个误区在pipelines.yml中写conf.d/*,实测会有问题,不同的filter处理逻辑会复用。 现在有两个从kafka采集日志的配置文件:from_kafka1.conf,from_kafka2.conf 修改pipelines.yml配置文件 config/pipelines.yml- pipeline.i…...

暴风骑士S9电摩上市,定义青少年骑行安全新标准
暴风骑士,作为全球高端儿童电动车的开创品牌,以其卓越的技术实力和创新精神,不断推动行业发展。如今,暴风骑士再次突破自我,推出了全新力作——S9青少年电摩。这款全新上市的青少年专属电摩,以其领先的安全…...

spring security如何适配盐存在数据库中的密码
19.token认证过滤器代码实现_哔哩哔哩_bilibili19.token认证过滤器代码实现是SpringSecurity框架教程-Spring SecurityJWT实现项目级前端分离认证授权-挑战黑马&尚硅谷的第20集视频,该合集共计41集,视频收藏或关注UP主,及时了解更多相关视…...

Go语言编程 学习笔记整理 第2章 顺序编程 后半部分
1.流程控制 1.1 条件语句 if a < 5 { return 0 } else { return 1 } 注意:在有返回值的函数中,不允许将“最终的”return语句包含在if...else...结构中, 否则会编译失败!!! func example(x int) i…...

美团后端二面
美团后端二面 ……………………………… 两道场景 一道 数字转中文读法(1000-》一千) 0八股0自我介绍 反问 “您觉得我能过吗?” “这个需要横行对比之后才能有结果” ……………………………… 什么时候到岗 场景题 1 假设我有一个…...
:对C语言作用域规则 局部变量、全局变量的认识)
学懂C语言(十六):对C语言作用域规则 局部变量、全局变量的认识
一、C 作用域规则 任何一种编程中,作用域是程序中定义的变量所存在的区域,超过该区域变量就不能被访问。C 语言中有三个地方可以声明变量: 局部变量:在函数或块内部全局变量:在所有函数外部形式参数:在函数…...
的理论知识)
关于TS(typescript)的理论知识
关于TS(typescript)的理论知识 TypeScript 是一种由微软开发的开源编程语言,它是 JavaScript 的一个超集,添加了可选的静态类型和基于类的面向对象编程。TypeScript 最终会被编译成纯 JavaScript 代码,以便在任何支持 …...

【OpenCV C++20 学习笔记】基本图像容器——Mat
【OpenCV C20 学习笔记】基本图像容器——Mat 概述Mat内部结构引用计数机制颜色数据格式 显式创建Mat对象使用cv::Mat::Mat构造函数矩阵的数据项 使用数组进行初始化的构造函数cv::Mat::create函数MATLAB风格的初始化小型矩阵通过复制创建Mat对象 Mat对象的输出其他普通数据项的…...

枚举单例是怎么保证线程安全和防止反射的
枚举单例在Java中具有天然的线程安全性和防止反射攻击的特性,这是由于Java对枚举类型的特殊处理方式。以下是详细解释: 1. 线程安全性 Java 枚举类的特性 类加载机制:枚举类型在Java中是特殊的类,由JVM保证其线程安全性。枚举类…...

传知代码-智慧医疗:纹理特征VS卷积特征(论文复现)
代码以及视频讲解 本文所涉及所有资源均在传知代码平台可获取 论文链接:https://www.sciencedirect.com/science/article/abs/pii/S1076633223003537?__cf_chl_rt_tkJ9Aipfxyk5d.leu48P20ePFNd4B2aunaSmzVpXCg.7g-1721292386-0.0.1.1-6249 论文概述 今天我们把视线…...

数据结构中的八大金刚--------八大排序算法
目录 引言 一:InsertSort(直接插入排序) 二:ShellSort(希尔排序) 三:BubbleSort(冒泡排序) 四: HeapSort(堆排序) 五:SelectSort(直接选择排序) 六:QuickSort(快速排序) 1.Hoare版本 2.前后指针版本 …...

ACC2.【C语言】经验积累 栈区简单剖析
int main() {int i0;int arr[10]{1,2,3,4,5,6,7,8,9,10};for (i0;i<12;i){arr[i]0;printf("A");}return 0; } 执行后无限打印A 在VS2022,X86,Debug环境下,用监视后,原因是arr[12]的地址与i的地址重合(数组越界&…...

c# 索引器
索引器(Indexer)允许你像访问数组一样,通过索引访问对象的属性或数据。索引器的主要用途是在对象内部封装复杂的数据结构,使得数据访问更加直观。下面是关于 C# 索引器的详细解释及示例: 基本语法 索引器的语法类似于…...

终极指南:Diablo Edit2暗黑破坏神2存档修改器完整使用教程
终极指南:Diablo Edit2暗黑破坏神2存档修改器完整使用教程 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否曾为暗黑破坏神2中重复刷装备而烦恼?是否因为技能点分配失…...

5个简单步骤彻底解决MoviePilot连接TheMovieDb异常问题
5个简单步骤彻底解决MoviePilot连接TheMovieDb异常问题 【免费下载链接】MoviePilot NAS媒体库自动化管理工具 项目地址: https://gitcode.com/gh_mirrors/mo/MoviePilot MoviePilot作为一款优秀的NAS媒体库自动化管理工具,为你提供了便捷的影视资源管理体验…...

魔兽争霸3兼容性修复终极指南:5步解决现代系统闪退问题
魔兽争霸3兼容性修复终极指南:5步解决现代系统闪退问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为魔兽争霸3在现代Windo…...

基于MCP协议与RAG技术构建智能聊天应用:架构解析与实战指南
1. 项目概述:一个基于MCP协议的RAG聊天应用最近在开源社区里,一个名为gogabrielordonez/mcp-ragchat的项目引起了我的注意。乍一看标题,它融合了当下两个非常热门的技术概念:MCP和RAG。对于从事AI应用开发,特别是希望构…...

基于BLE与CircuitPython的远程服务器重启开关设计与实现
1. 项目概述与核心思路手头有几台电脑分散在家里各个角落,有时候它们死机了需要重启,但偏偏其中一台作为监控录像存储的服务器,被我塞进了一个带锁的柜子里。每次都得找钥匙、开门、按按钮,实在麻烦。这个需求催生了我动手做一个无…...

基于RP2040与VL53L1X的自动触发空气炮:嵌入式感知-决策-执行系统实践
1. 项目概述:一个会“思考”的自动空气炮如果你玩过或者听说过那些在鬼屋里突然喷气吓人的恶作剧道具,那你大概能想象出这个项目的最终效果。但今天我们要做的,远不止一个简单的“吓人盒子”。这是一个融合了现代嵌入式系统、高精度传感器和气…...

MVDRAM技术:利用DRAM隐藏计算潜力加速LLM推理
1. MVDRAM技术背景与核心挑战在当今大语言模型(LLM)推理场景中,矩阵向量乘法(GeMV)操作占据了超过70%的计算开销。传统CPU/GPU架构面临三个根本性瓶颈:内存墙问题(数据搬运能耗是计算的200倍&am…...

基于APScheduler的定时提醒服务设计与Python实现
1. 项目概述与核心价值最近在折腾一个名为rogerwus/Noonwake_test的项目,这名字乍一看有点神秘,像是某个内部测试或者个人实验性质的仓库。作为一名常年泡在代码仓库里的开发者,我对这类项目标题背后的故事和技术探索总是充满好奇。经过一番深…...

RISC-V SoC上DNN加速的内存优化与FTL算法实践
1. RISC-V SoC上的DNN加速内存优化挑战在边缘计算场景下,深度神经网络(DNN)的部署面临严峻的内存带宽挑战。典型的RISC-V异构SoC(如Siracusa)采用多级软件管理内存架构,包含L1紧耦合存储器(32KB)、L2共享缓…...

【限时开放】Midjourney未来主义风格权威认证路径:完成这5个里程碑任务,获取由Adobe+MJ Labs联合签发的Futurism Prompt Architect证书
更多请点击: https://intelliparadigm.com 第一章:【限时开放】Midjourney未来主义风格权威认证路径:完成这5个里程碑任务,获取由AdobeMJ Labs联合签发的Futurism Prompt Architect证书 什么是未来主义Prompt架构师认证…...