Redis缓存双写一致性
目录
- 双写一致性
- Redis与Mysql双写一致性
- canal
- 配置流程
- 代码案例
- 双写一致性理解
- 缓存操作细分
- 缓存一致性多种更新策略
- 挂牌报错,凌晨升级
- 先更新数据库,在更新缓存
- 先删除缓存,在更新数据库
- 先更新数据库,在删除缓存
- 延迟双删策略
- 总结
双写一致性
Redis与Mysql双写一致性
canal
主要是用于MySQL数据库增量日志数据的订阅,消费和解析(由阿里开源的Java项目),canal是通过伪装成MySQL的slave节点来转储master节点的binlog日志的一个中间件,他拿到日志内容以后,就可以把日志的相关数据变更重放到任何地方,可以是其他的MySQL,也可以是消息队列,redis甚至是文件中.
配置流程
- 开启MySQL的binlog写入功能(需要重启MySQL,阿里云的好像默认就开启了)
- 授权canal连接MySQL的账号,其实就是新建一个canal专用的账号便于区分(权限可以稍微高一些)
- 去官网下载并解压canal到自己的目录下,修改instance.properties配置文件
- 换成自己mysql主机所在的ip地址
- 换成自己刚才给MySQL新建的用户及其密码
- 启动canel并查看server和instance实例的日志来确保启动运行成功
代码案例
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import com.google.protobuf.InvalidProtocolBufferException;import java.net.InetSocketAddress;
import java.util.List;
import java.util.concurrent.TimeUnit;public class RedisCanalClientExample {public static final int _60SECONDS = 60;public static void main(String[] args) {CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("127.0.0.1", 1111), "example", "", "");int batchSize = 1000;int emptyCount = 0;System.out.println("---------程序启动,开始监听MySQL的变化: ");try {connector.connect();//这个就是你要订阅的变化的那个库表connector.subscribe("db_test.t_user");connector.rollback();int totalEmptyCount = 10 * _60SECONDS;while (emptyCount < totalEmptyCount) {//获取指定数量的数据Message message = connector.getWithoutAck(batchSize);long batchId = message.getId();int size = message.getEntries().size();if (batchId == -1 || size == 0) {emptyCount++;try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}} else {emptyCount = 0;printEntry(message.getEntries());System.out.println();}//提交确认connector.ack(batchId);//处理失败,回滚数据//connector.rollback(batchId);}System.out.println("empty too many times,exit");} finally {connector.disconnect();}}private static void printEntry(List<CanalEntry.Entry> entries) {for (CanalEntry.Entry entry : entries) {if (entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONBEGIN || entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONEND) {continue;}CanalEntry.RowChange rowChange = null;try {rowChange = CanalEntry.RowChange.parseFrom(entry.getStoreValue());} catch (InvalidProtocolBufferException e) {throw new RuntimeException(e);}CanalEntry.EventType eventType = rowChange.getEventType();System.out.printf("==========binlog[%s:%s],name[%s,%s],eventType : %s%n",entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),entry.getHeader().getSchemaName(), entry.getHeader().getTableName(), eventType);for (CanalEntry.RowData rowData : rowChange.getRowDatasList()) {if (eventType == CanalEntry.EventType.INSERT) {redisInsert(rowData.getAfterColumnsList());} else if (eventType == CanalEntry.EventType.UPDATE) {redisUpdate(rowData.getAfterColumnsList());} else {redisDelete(rowData.getAfterColumnsList());}}}}private static void redisInsert(List<CanalEntry.Column> columns) {//实现省略,往redis插入数据}private static void redisUpdate(List<CanalEntry.Column> columns) {//实现省略,往redis修改数据}private static void redisDelete(List<CanalEntry.Column> columns) {//实现省略,往redis删除数据}
}双写一致性理解
- redis中有数据,需要和数据库中的值相同
- redis中无数据,需要数据库中的值要是最新值
缓存操作细分
- 只读缓存
- 读写缓存
- 同步直写策略:写数据库时也同步写缓存,缓存和数据库中的数据一致(对于读写缓存来说,要想保证缓存和数据库中的数据一致,就要采用同步直写策略)
缓存一致性多种更新策略
挂牌报错,凌晨升级
让客户稍作等待,然后趁机更新mysql和redis(特别重要级别的数据最好不要多线程)
给缓存设置过期时间,是保证最终一致性的解决方案.所有的写操作以数据库为准,对缓存操作只是尽最大的努力即可.也就是说如果数据库写入成功,缓存更新失败,那么只要到达过期时间.后面的请求自然会从数据库中读取新数据然后回填缓存,达到一致性.切记以mysql的数据库写入为准.
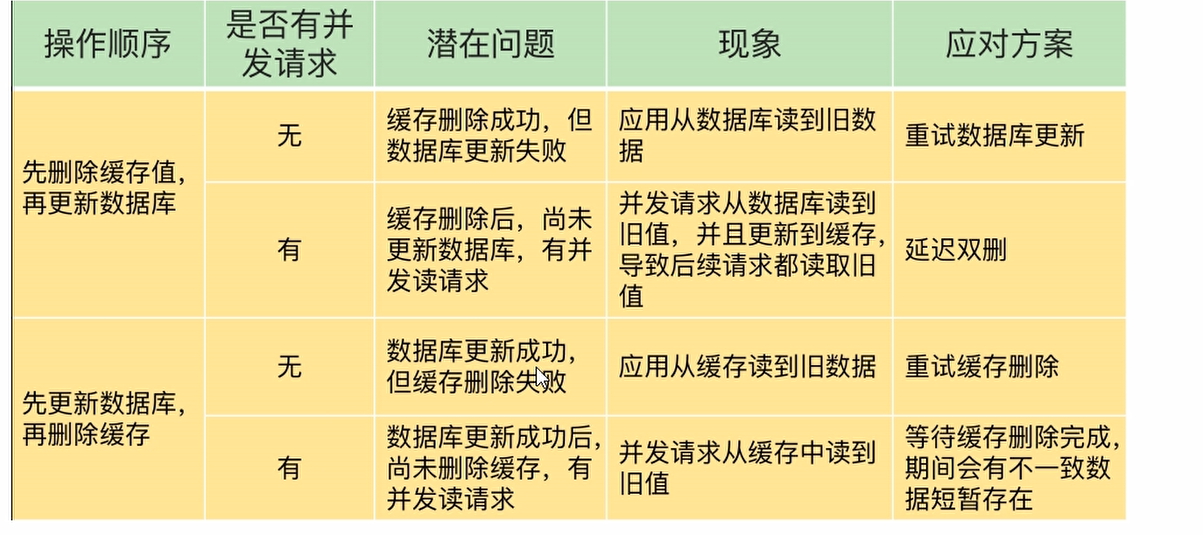
先更新数据库,在更新缓存
在高并发的情境下,这个操作是跨两个不同的系统的,就一定会可能发生数据不一致的问题,导致读到脏数据(比如某方更新失败了)
先删除缓存,在更新数据库
容易出现的异常问题:A线程删除了缓存,去更新mysql. B线程过来又要读取,A还在更新中,这时候有可能发生
- 有可能缓存击穿(看你有没有双端检索加锁来初始化缓存)
- B从mysql获得了旧值
- B会把获得的旧值写回到Redis缓存(被A删除掉的旧数据,又被B给写会了,缓存的更新就失败了)
- 请求A更新完成,MySQL与Redis发生了数据不一致的情况
这种方案尽量不要用
先更新数据库,在删除缓存
还是会出现短时间的数据不一致(可能会从缓存中读取到旧数据)
canal就是类似的思想
延迟双删策略
先删除Redis的缓存,在更新完数据库之后,再删除一次Redis的缓存(延迟删除),这时候能保证数据的最终一致性.
- 这个删除该休眠多久
- 自己根据业务进行一个具体的评估,在此耗时基础上面加个**百毫秒**左右即可
- 如果MySQL是主从分离如何
- 从库更可能导致数据不一致问题(还有个主从复制的延迟时间),所以更加需要采用延迟双删的策略了(延迟时间可能需要再加上百毫秒时间)
- 这种同步淘汰策略,吞吐量降低了怎么办
- 可以新起来一个线程去后台做这个事情(用CompletableFuture等实现)
分布式系统只有最终一致性,很难去做到强一致性
总结
把Redis作为只读缓存的话还好,没有一致性的问题,但是如果把Redis作为读写缓存来用.建议使用先更新数据库,再删除缓存的方案.理由如下:
- 先删除缓存的值在更新数据库,有可能缓存击穿打满MySQL,并且也避免不了数据不一致的问题
- 如果业务应用中读取数据库和写缓存的时间不好估算,那么延迟双删中的等待时间就不好设置
相关文章:
Redis缓存双写一致性
目录双写一致性Redis与Mysql双写一致性canal配置流程代码案例双写一致性理解缓存操作细分缓存一致性多种更新策略挂牌报错,凌晨升级先更新数据库,在更新缓存先删除缓存,在更新数据库先更新数据库,在删除缓存延迟双删策略总结双写一致性 Redis与Mysql双写一致性 canal 主要是…...
【2023-Pytorch-检测教程】手把手教你使用YOLOV5做交通标志检测
项目下载地址:YOLOV5交通标志识别检测数据集代码模型教学视频-深度学习文档类资源-CSDN文库 交通标志的目标检测算法在计算机视觉领域一直属于热点研究问题,改进的优化算法不断地被提出。国内外许多学者针对现有的目标检测方法中网络结构、目标定位、损…...
Java中的二叉树
文章目录前言一、树形结构(了解)1.1 概念1.2 概念(重要)1.3 树的表示形式(了解)1.4 树的应用二、二叉树(重点)2.1 概念2.2 两种特殊的二叉树2.3 二叉树的性质2.5 二叉树的存储2.5 二…...
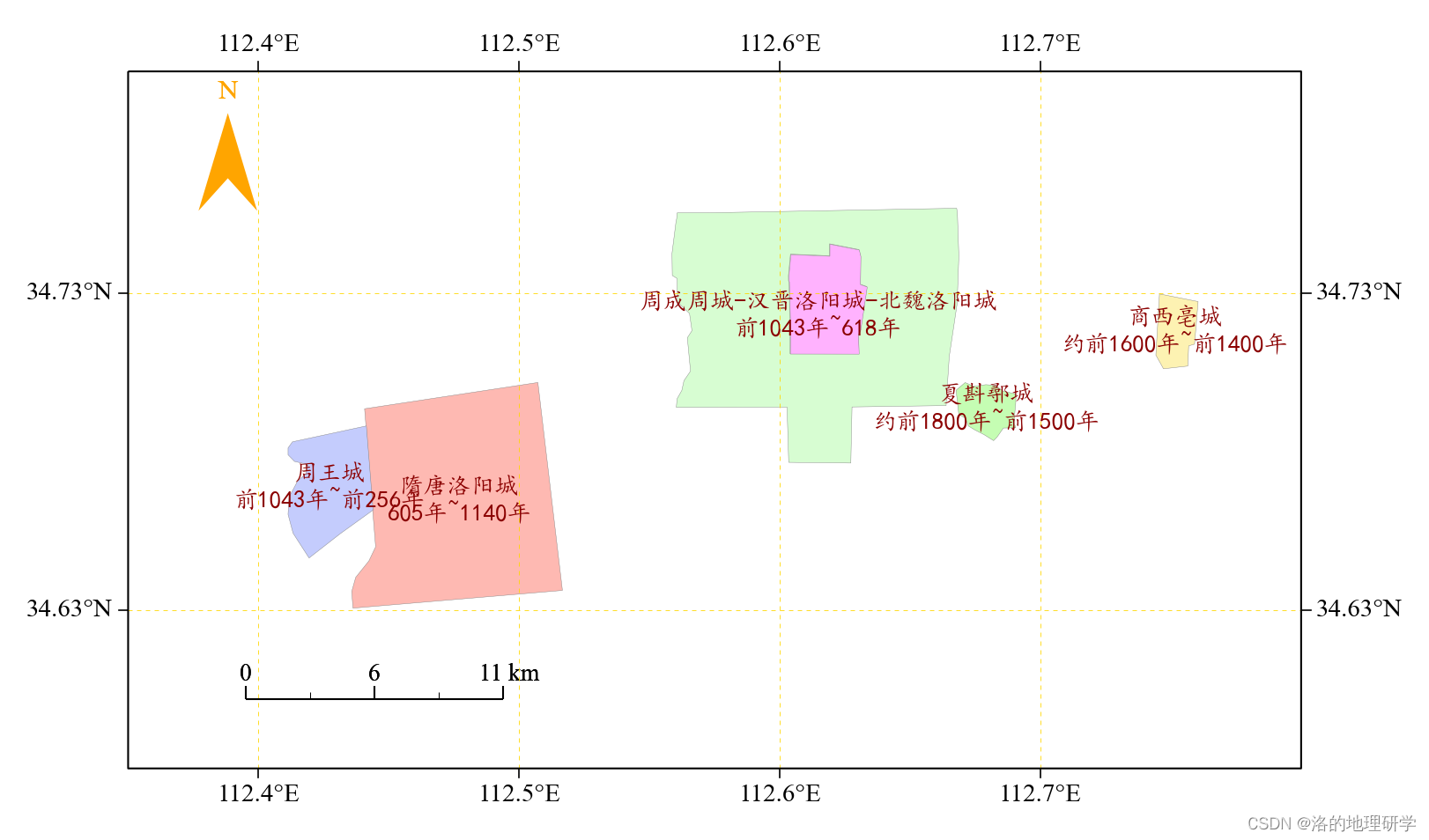
基于 gma 绘制古代洛阳 5 大都城遗址空间分布地图
了解 gma gma 是什么? gma 是一个基于 Python 的地理、气象数据快速处理和数据分析函数包(Geographic and Meteorological Analysis,gma)。gma 网站:地理与气象分析库。 gma 的主要功能有哪些? 气候气象&a…...
分析 Spring 的依赖注入模式
一、依赖注入二、Field Injection优点缺点三、Constructor Injection优点1. 容易发现 code smell优点2. 容易厘清依赖关系优点3. 容易写单元测试优点4. Immutable Object缺点:循环依赖四、总结一、依赖注入 依赖注入 (Dependency Injection,…...
IntelliJ IDEA创建Servlet
目录 ——————————————————————————————— 一、创建Java项目 1、创建java项目 2、选择java 3、next 4、给项目命名 5、新创建完java项目的目录结构 二、变java为servlet项目 1、变servlet项目 2、选择Web Application 3、更新完成后的目录…...

Spring Boot如何让自己的bean优先加载
背景介绍 在一些需求中,可能存在某些场景,比如先加载自己的bean,然后自己的bean做一些DB操作,初始化配置问题,然后后面的bean基于这个配置文件,继续做其他的业务逻辑。因此有了本文的这个题目。 实现方法…...
LeetCode分类刷题----动态规划
动态规划509.斐波那契数列70.爬楼梯746.使用最小花费怕楼梯62.不同路径63.不同路径||343.整数拆分96.不同的二叉搜索树01背包问题416.分割等和子集1049.最后一块石头的重量||494.目标和474.一和零完全背包问题518.零钱兑换||377.组合总和IV322.零钱兑换279.完全平方数139.单词拆…...

今年好像没有金三银四了?
大家好,我是记得诚。 金三银四,是换工作的高峰期,新的一年结束了,在年前拿完年终奖,在年后3月和4月换个满意的工作。 单从我公司来看,目前还没有一个人离职,往年离职率是要高一些的。 还有我…...
【C++】入门知识之 函数重载
前言提到重载这个词,我们会想到什么呢?重载有一种一词多义的意思,中华文化博大精深,之前有一个笑话,中国的乒乓球谁都打不过,男足谁都打不过,哈哈哈这也是非常有意思的,但是今天我们…...
文心一言发布,你怎么看?chatGPT
百度全新一代知识增强大语言模型“文心一言”于2021年3月16日正式发布,作为一款自然语言处理技术,它引起了广泛的关注和讨论。 首先,文心一言是一款具有重大意义的自然语言处理技术。在人工智能领域,自然语言处理技术一直是一个难…...

字符函数和字符串函数【上篇】
文章目录🎖️1.函数介绍📬1.1. strlen📬1.2. strcpy📬1.3. strcat📬1.4. strcmp📬1.5. strncpy📬1.6. strncat📬1.7. strncmp🎖️1.函数介绍 📬1.1. strlen …...

list的模拟实现(模仿STL)
目录 一、模拟实现前的准备 1.list结构认识 2.迭代器的实现不同 3.如何实现需要的功能 二.结点类实现 三.迭代器实现 1.实现前的问题 2._list_iterator类的成员变量和构造函数 3.*和->运算符重载 4.前置和后置的实现 5.前置--和后置-- 6.和!运算符重载 四.list类的实现 1.li…...

05-STM32F1 - 串行通信SPI
SPI STM-SPI作为主机,从机 SPI的时钟,最高为Pclk/2,SPI1最高为36Mhz,SPI2最高为18Mhz。 SPI的四种模式 CPOL CPHA,数据帧8~16位,LSB,MSB 全双工,双向单线,单线 物理层 接口标准…...

【Pytorch】Tensor的分块、变形、排序、极值与in-place操作
本文参加新星计划人工智能(Pytorch)赛道:https://bbs.csdn.net/topics/613989052 这是目录Tensor的分块Tensor的变形Tensor的排序Tensor的极值Tensor的in-place操作Tensor是PyTorch中用于存储和处理多维数据的基本数据结构,它类似于NumPy中的ndarray&…...

数组栈的实现
个人主页:平行线也会相交 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 平行线也会相交 原创 收录于专栏【数据结构初阶(C实现)】 目录所有接口函数栈的初始化在栈顶放数据释放数据删除数据取栈顶的数据判断栈取区是否为…...
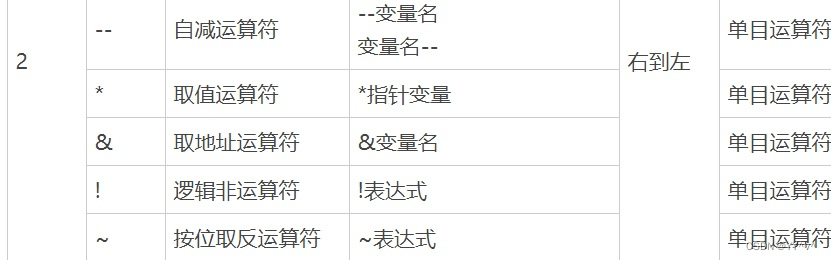
*p++,*(p++),*++p,(*p)++区别?
*p++:等同于:*p; p += 1; 解析:由于和++的运算优先级一样,且是右>结合。故p++相当于*(p++),p先与++结合,>然后p++整体再与结合。前面陈述是一种最 常见的错误,很多初学者也是这么理解的。 但是,因为++后置的时候,本身含义就是先 运算后增加1(运算指的是p++作为…...
又一个线上偶发问题-系统短暂无法获取到Redis连接
概述 最近不知道咋回事,老是在线上遇到偶发的故障,它突然出现,又很快消失了。 在2023年3月11下午差不多六点左右,我正在工位上喝着香味扑鼻的金骏眉红茶,突然接到了一个电话,拿起手机一看,是阿里…...
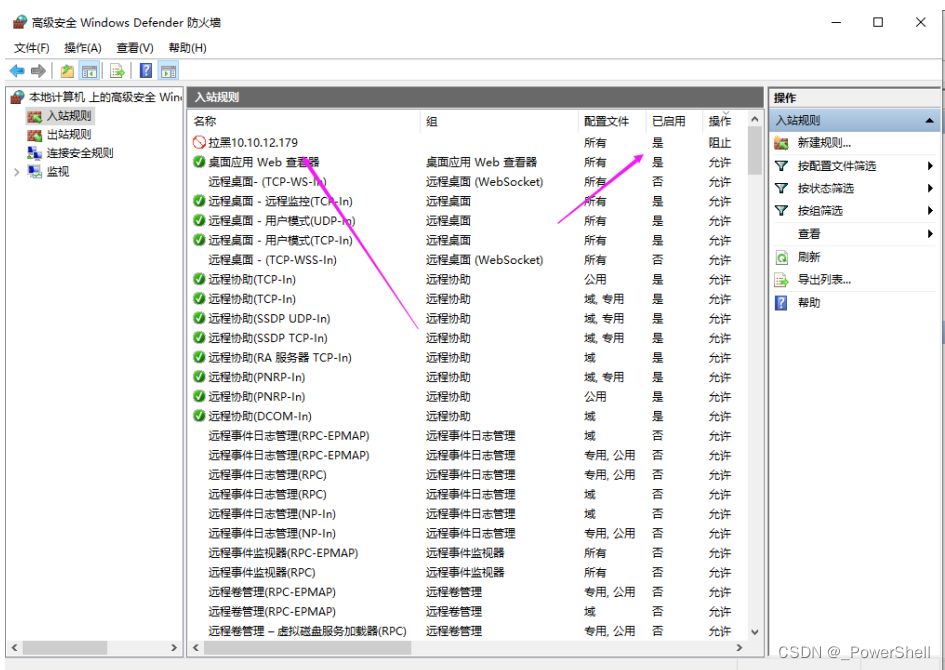
[ 系统安全篇 ] 拉黑IP - 火绒安全软件设置IP黑名单 windows使用系统防火墙功能设置IP黑名单
🍬 博主介绍 👨🎓 博主介绍:大家好,我是 _PowerShell ,很高兴认识大家~ ✨主攻领域:【渗透领域】【数据通信】 【通讯安全】 【web安全】【面试分析】 🎉点赞➕评论➕收藏 养成习…...
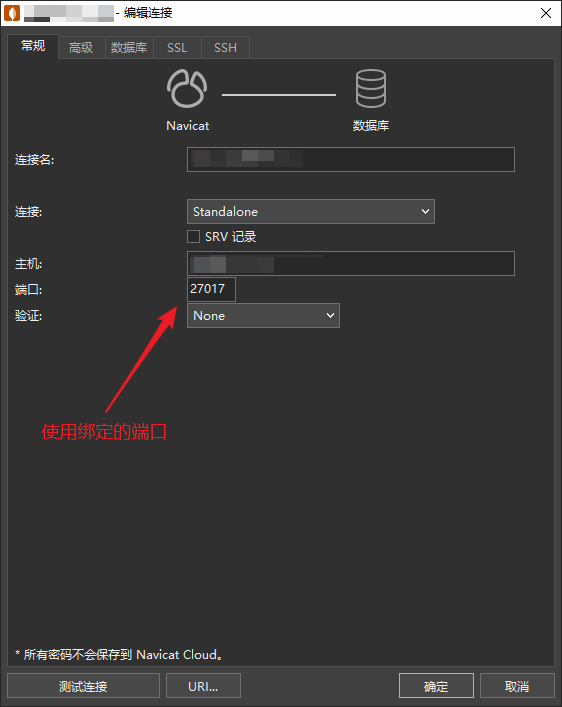
MongoDB【部署 01】mongodb最新版本6.0.5安装部署配置使用及mongodb-shell1.8.0安装使用(云盘分享安装文件)
云盘分享文件: 链接:https://pan.baidu.com/s/11sbj1QgogYHPM4udwoB1rA 提取码:l2wz 1.mongodb简单介绍 MongoDB的 官网 内容还是挺丰富的。 是由 C语言编写的,是一个基于分布式文件存储的开源数据库系统。在高负载的情况下&…...
)
用8086和蜂鸣器DIY音乐盒:手把手教你复刻童年旋律(附完整汇编代码)
用8086和蜂鸣器DIY音乐盒:手把手教你复刻童年旋律(附完整汇编代码) 记得小时候第一次听到电子贺卡发出《生日快乐》的单调旋律时,那种机械却又神奇的"音乐"让我盯着电路板研究了半天。现在想来,那些简单的方…...

LoRA训练助手GPU显存优化:Qwen3-32B INT4量化后仅需9.2GB显存稳定运行
LoRA训练助手GPU显存优化:Qwen3-32B INT4量化后仅需9.2GB显存稳定运行 1. 引言:当大模型遇见显存焦虑 如果你尝试过在个人电脑上运行大语言模型,大概率会遇到一个令人头疼的问题:显存不足。特别是像Qwen3-32B这样拥有320亿参数的…...

AutoHotkey自动化效率提升指南:从入门到进阶的全场景应用技巧
AutoHotkey自动化效率提升指南:从入门到进阶的全场景应用技巧 【免费下载链接】antimicrox Graphical program used to map keyboard buttons and mouse controls to a gamepad. Useful for playing games with no gamepad support. 项目地址: https://gitcode.co…...

OpenClaw-DingTalk终极指南:Stream模式钉钉机器人企业级部署实战
OpenClaw-DingTalk终极指南:Stream模式钉钉机器人企业级部署实战 【免费下载链接】openclaw-channel-dingtalk Dingtalk channel plugin for OpenClaw 项目地址: https://gitcode.com/gh_mirrors/op/openclaw-channel-dingtalk OpenClaw-DingTalk是一款专为O…...
)
FRP内网穿透实战:5分钟搞定Linux服务器+Docker部署(含HTTPS配置)
FRP内网穿透实战:Linux服务器与Docker部署全指南 引言 在当今分布式开发和远程办公的浪潮中,内网穿透技术已成为开发者工具箱中不可或缺的一部分。想象一下这样的场景:你正在本地开发一个Web应用,需要让远方的同事实时预览效果&am…...

BGE Reranker-v2-m3在VSCode插件开发中的应用
BGE Reranker-v2-m3在VSCode插件开发中的应用 1. 引言 作为一名长期使用VSCode进行开发的程序员,我经常遇到这样的困扰:在庞大的代码库中搜索特定功能或文档时,传统的文本搜索往往返回大量不相关的结果,需要花费大量时间手动筛选…...

LuckyLilliaBot架构解析:NTQQ OneBot API插件的深度技术实现指南
LuckyLilliaBot架构解析:NTQQ OneBot API插件的深度技术实现指南 【免费下载链接】LuckyLilliaBot NTQQ的OneBot API插件 项目地址: https://gitcode.com/gh_mirrors/li/LuckyLilliaBot LuckyLilliaBot是一款基于OneBot 11协议的开源QQ机器人框架,…...

基于LSTM的CasRel模型变体实现与性能对比分析
基于LSTM的CasRel模型变体实现与性能对比分析 最近在关系抽取这个领域,大家的目光似乎都被Transformer架构给吸引走了。确实,像BERT、RoBERTa这些基于自注意力机制的模型,在各类NLP任务上表现都相当亮眼。但这就让我产生了一个疑问ÿ…...
GPU算力高效利用:Pixel Language Portal在单卡多实例部署中的资源隔离与负载均衡教程
GPU算力高效利用:Pixel Language Portal在单卡多实例部署中的资源隔离与负载均衡教程 1. 引言:为什么需要单卡多实例部署 在AI应用开发中,GPU资源往往是稀缺且昂贵的。Pixel Language Portal作为一款基于Tencent Hunyuan-MT-7B的高端翻译工…...

如何让你的论文表达直接提升一个等级
在科研写作的道路上,许多科研人员常陷入一种难以言说的困境:明明实验数据详实,研究过程严谨,但落笔成文后,语言却显得平淡无力。文章往往停留在“描述事实”的层面,仅仅机械地陈述“做了什么”和“发现了什…...