大语言模型-GPT-Generative Pre-Training
一、背景信息:
GPT是2018 年 6 月由OpenAI 提出的预训练语言模型。
GPT可以应用于复杂的NLP任务中,例如文章生成,代码生成,机器翻译,问答对话等。
GPT也采用两阶段的训练过程,第一阶段是无监督的方式来预训练生成式的语言模型,第二阶段根据特定任务进行微调。
GPT的网络架构使用的是多层Transformer Decoder改的结构。
二、整体结构:
GPT 使用Transformer的 Decoder 结构,并进行了一些改动,GPT 中的Decoder只保留了原Decoder中的第一个Attention模块Mask Multi-Head Attention。

GPT堆叠了12个Transformer的Decoder模块作为解码器,然后通过全连接得到输出的概率分布。
GPT中采用的是单向的语言模型,即通过上文预测当前的词,而Decoder中的Masked Multi Self-Attention可以起到遮掩待预测的下文内容的效果。

GPT 处理不同任务时的输入变换
GPT模型由输入嵌入层、多层Transformer Decoder以及输出层这三个部分组成。
其中
1、输入嵌入层: 将输入的文本序列转换为词向量、位置向量并将二者相加得到输入向量。
2、多层Transformer Decode: 其中每一层由以残差和的方式做LayerNorm的掩码多头自注意力机层与以残差和的方式做LayerNorm的双层前馈神经网络组成。
X o u t p u t = X o u p u t − o r i ⊗ X M a s k X = L a y d e r N o r m ( X o u t p u t + M a s k M u l t i H e a d A t t e n t i o n ( X o u p u t ) ) X = F e e d F o r w o r d ( X ) = m a x ( 0 , X W 1 + b 1 ) W 2 + b 2 \begin{matrix} \\X_{output}=X_{ouput-ori }\otimes X_{Mask} \\X = LayderNorm(X_{output} + MaskMultiHeadAttention(X_{ouput})) \\X = FeedForword(X) = max(0, XW_{1} + b_{1})W_{2} + b_{2}\begin{matrix}\end{matrix} \end{matrix} Xoutput=Xouput−ori⊗XMaskX=LayderNorm(Xoutput+MaskMultiHeadAttention(Xouput))X=FeedForword(X)=max(0,XW1+b1)W2+b2
3、输出层: GPT模型的输出层通常为一个全连接层,将多层解码器的输出转换为对应的单词概率分布。
- 分类任务(Classification):将起始和终止token加入到原始序列两端,输入transformer中得到特征向量,最后经过一个全连接得到预测的概率分布。
- 自然语言推理(Entailment):将前提(premise)和假设(hypothesis)通过分隔符(Delimiter)隔开,两端加上起始和终止token。再依次通过Transformer多层Decoder和全连接得到预测结果。
- 语义相似度(Similarity):输入的两个句子,正向和反向各拼接一次,然后分别输入给Transformer多层Decoder,得到的特征向量拼接后再送给全连接得到预测结果;
- 多项选择(MutipleChoice):将n个选项的问题抽象化为n个二分类问题,即每个选项分别和内容进行拼接,然后各送入Transformer多层Decode和全连接中,最后选择置信度最高的作为预测结果。

三、GPT训练
GPT的训练包含无监督预训练和有监督fine-tune两个阶段。
GPT的无监督预训练:
假设未标注的词汇集合为 U = { u 1 , u 2 , . . . u n } U = \left \{ {{u_{1},u_{2},...u_{n}}}\right \} U={u1,u2,...un},GPT模型的优化目标是对参数进行最大似然估计:
L 1 ( U ) = ∑ i l o g P ( u i ∣ u 1 , . . . , u k − 1 ; Θ ) L_{1}(U) = \sum_{i}^{} log P(u_{i}|u_{1},...,u_{k-1};\Theta ) L1(U)=i∑logP(ui∣u1,...,uk−1;Θ)
其中,k是滑动窗口的大小, P 为条件概率, Θ \Theta Θ为条件概率的参数, 参数更新采用随机梯度下降(SGD)方法。
下面是整个过程的公式示例:
{ h 0 = U W e + W p h l = T r a n s f o r m e r D e c o d e r B l o c k ( h l − q ) P ( u ) = s o f t m a x ( h n W e T ) \left\{\begin{matrix}h_{0} = UW_{e} + W{p} \\h_{l} = TransformerDecoderBlock(h_{l-q}) \\P(u) = softmax(h_{n}W_{e}^{T} ) \end{matrix}\right. ⎩ ⎨ ⎧h0=UWe+Wphl=TransformerDecoderBlock(hl−q)P(u)=softmax(hnWeT)
输入嵌入层:W e W_{e} We是token的词向量Embedding矩阵, W p W_{p} Wp是位置编码的Embedding矩阵,二者求和得到输入向量矩阵 h 0 h_{0} h0多层Transformer Decode:TransformerDecoderBlock指多层Decoder模块输出层:通过Softmax函数将输出的词向量转换为对应的单词概率分布
GPT的有监督fine-tune:
预训练后,需要针对特定任务进行有监督Fine-Tuning。
这里以一个文本分类任务举例,展示GPT在某一任务有监督微调的过程。
假设带标注的数据集C中的输入序列X为 [ x 1 , . . . , x m ] [x^{1},..., x^{m}] [x1,...,xm];模型的输出y是一个分类标签; h l m h_{l}^{m} hlm代表Decoder层最后的输出; W y W_{y} Wy代表输出层的Softmax参数。 L 2 ( C ) L_{2}(C) L2(C)是分类任务的最大似然函数, L 3 ( C ) L_{3}(C) L3(C)是整体的最大似然函数;GPT 在微调的时候需要同时考虑预训练的损失函数,因此微调的训练目标是最大化似然函数 L 3 ( C ) L_{3}(C) L3(C).
{ P ( y ∣ x 1 , . . . , x m ) = s o f t m a x ( h l m W y ) L 2 ( C ) = ∑ x , y l o g P ( y ∣ x 1 , . . . , x m ) L 3 ( C ) = L 2 ( C ) + λ × L 1 ( C ) \left\{\begin{matrix}P(y|x^{1},..., x^{m}) = softmax(h_{l}^{m}W_{y}) \\L_{2}(C) = \sum_{x,y}^{} log P(y|x^{1},..., x^{m}) \\L_{3}(C) = L_{2}(C) + \lambda \times L_{1}(C) \end{matrix}\right. ⎩ ⎨ ⎧P(y∣x1,...,xm)=softmax(hlmWy)L2(C)=∑x,ylogP(y∣x1,...,xm)L3(C)=L2(C)+λ×L1(C)
Reference
1.Attention Is All You Need
2.BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
3.Improving Language Understanding by Generative Pre-Training
相关文章:
大语言模型-GPT-Generative Pre-Training
一、背景信息: GPT是2018 年 6 月由OpenAI 提出的预训练语言模型。 GPT可以应用于复杂的NLP任务中,例如文章生成,代码生成,机器翻译,问答对话等。 GPT也采用两阶段的训练过程,第一阶段是无监督的方式来预训…...

mybatis批量插入、mybatis-plus批量插入、mybatis实现insertList、mybatis自定义实现批量插入
文章目录 一、mybatis新增批量插入1.1、引入依赖1.2、自定义通用批量插入Mapper1.3、把通用方法注册到mybatisplus注入器中1.4、实现InsertList类1.5、需要批量插入的dao层继承批量插入Mapper 二、可能遇到的问题2.1、Invalid bound statement 众所周知,mybatisplus…...

Springboot项目的行为验证码AJ-Captcha(源码解读)
目录 前言1. 复用验证码2. 源码解读2.1 先走DefaultCaptchaServiceImpl类2.2 核心ClickWordCaptchaServiceImpl类 3. 具体使用 前言 对于Java的基本知识推荐阅读: java框架 零基础从入门到精通的学习路线 附开源项目面经等(超全)【Java项目…...

【初阶数据结构篇】时间(空间)复杂度
文章目录 算法复杂度时间复杂度1. 定义2. 表示方法3. 常见时间复杂度4.案例计算分析冒泡排序二分查找斐波那契数列(递归法)斐波那契数列(迭代法) 空间复杂度案例分析冒泡排序斐波那契数列(递归法)斐波那契数…...

C# 设计模式分类
栏目总目录 1. 创建型模式(Creational Patterns) 创建型模式主要关注对象的创建过程,包括如何实例化对象,并隐藏实例化的细节。 单例模式(Singleton):确保一个类只有一个实例,并提…...

前端模块化CommonJS、AMD、CMD、ES6
在前端开发中,模块化是一种重要的代码组织方式,它有助于将复杂的代码拆分成可管理的小块,提高代码的可维护性和可重用性。CommonJS、AMD(异步模块定义)和CMD(通用模块定义)是三种不同的模块规范…...
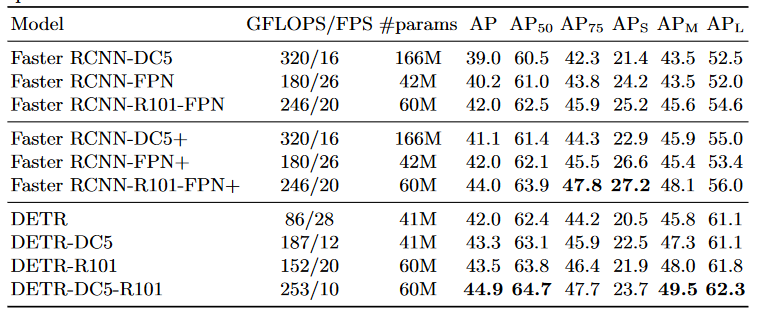
论文阅读:(DETR)End-to-End Object Detection with Transformers
论文阅读:(DETR)End-to-End Object Detection with Transformers 参考解读: 论文翻译:End-to-End Object Detection with Transformers(DETR)[已完结] - 怪盗kid的文章 - 知乎 指示函数&…...

react中路由跳转以及路由传参
一、路由跳转 1.安装插件 npm install react-router-dom 2.路由配置 路由配置:react中简单的配置路由-CSDN博客 3.实现代码 // src/page/index/index.js// 引入 import { Link, useNavigate } from "react-router-dom";function IndexPage() {const …...

C++ STL set_symmetric_difference
一:功能 给定两个集合A,B;求出两个集合的对称差(只属于其中一个集合,而不属于另一个集合的元素),即去除那些同时在A,B中出现的元素。 二:用法 #include <vector>…...

postman请求响应加解密
部分接口,需要请求加密后,在发动到后端。同时后端返回的响应内容,也是经过了加密。此时,我们先和开发获取到对应的【密钥】,然后在postman的预执行、后执行加入js脚本对明文请求进行加密,然后在发送请求&am…...

数据集,批量更新分类数值OR批量删除分类行数据
数据集批量更新分类OR删除分类行数据 import osdef remove_class_from_file(file_path, class_to_remove):"""从YOLO格式的标注文件中删除指定类别的行记录,并去除空行。:param file_path: YOLO标注文件路径:param class_to_remove: 需要删除的类别…...

一款功能强大的视频编辑软件会声会影2023
会声会影2023是一款功能强大的视频编辑软件,由加拿大Corel公司制作,正版英文名称为Corel VideoStudio。它具备图像抓取和编修功能,可以处理和转换多种视频格式,如MV、DV、V8、TV和实时记录抓取画面文件。会声会影提供了…...

政安晨【零基础玩转各类开源AI项目】基于Ubuntu系统部署LivePortrait :通过缝合和重定向控制实现高效的肖像动画制作
目录 项目论文介绍 论文中实际开展的工作 非扩散性的肖像动画 基于扩散的肖像动画 方法论 基于Ubuntu的部署实践开始 1. 克隆代码并准备环境 2. 下载预训练权重 3. 推理 快速上手 驱动视频自动裁剪 运动模板制作 4. Gradio 界面 5. 推理速度评估 社区资源 政安…...

在Spring项目中使用Maven和BCrypt来实现修改密码功能
简介 在数字时代,信息安全的重要性不言而喻,尤其当涉及到个人隐私和账户安全时。每天,无数的用户登录各种在线服务,从社交媒体到银行账户,再到电子邮件和云存储服务。这些服务的背后,是复杂的系统架构&am…...

RedHat8安装Oracle19C
RedHat8安装Oracle19C 1、 更新yum源 更新yum源为阿里云镜像源: # 进入源目录 cd /etc/yum.repos.d/ # 删除 redhat 默认源 rm redhat.repo # 下载阿里云的centos7源 curl -O http://mirrors.aliyun.com/repo/Centos-8.repo # 替换 Centos-8.repo 中的 $releasev…...

React系列面试题
大家好,我是有用就点赞,有用就扩散。 1.React的组件间通信都有哪些形式? 父传子:在React中,父组件调用子组件时可以将要传递给子组件的数据添加在子组件的属性中,在子组件中通过props属性进行接收。这个就…...

C#:通用方法总结—第6集
大家好,今天继续介绍我们的通用方法系列。 下面是今天要介绍的通用方法: (1)这个通用方法为SW查找草图数量 /// <summary> /// 查找草图数量 /// </summary> /// <param name"doc2"></param>…...

Spark实时(一):StructuredStreaming 介绍
文章目录 Structured Streaming 介绍 一、SparkStreaming实时数据处理痛点 1、复杂的编程模式 2、SparkStreaming处理实时数据只支持Processing Time 3、微批处理,延迟高 4、精准消费一次问题 二、StructuredStreaming架构与场景应用 三、…...
LangChain4j-RAG基础
RAG是什么 简而言之,RAG 是一种在将数据发送到 LLM 之前从数据中查找相关信息并将其注入到提示中的方法。这样LLM将获得(希望)相关信息,并能够使用这些信息进行回复,这应该会减少产生幻觉的可能性。 实现方法: 全文…...

git--本地仓库修改同步到远程仓库
尝试将本地分支推送到远程仓库时,出现一个非快速前进的错误。通常是因为远程仓库中的分支包含本地分支没有的提交。在推送之前,需要将远程仓库的更改合并到本地分支。 解决步骤如下: 切换到你的本地分支: 确保处于想要推送的分支…...

Go语言ARP工具包:从协议原理到网络诊断实战
1. 项目概述:一个被低估的网络诊断利器 如果你在运维、网络安全或者仅仅是喜欢折腾家庭网络的圈子里混过一段时间,大概率听说过或者用过 arp 命令。但大多数人,包括很多从业者,对它的认知可能还停留在“查看IP和MAC地址对应关系…...

VRLog×框架:隐私保护记录链接与验证注册的创新融合
1. VRLog框架:隐私保护记录链接与验证注册的融合创新在选民登记系统这类需要跨机构协作的高敏感场景中,如何在确保数据隐私的同时实现准确记录匹配,一直是困扰业界的难题。传统隐私保护记录链接(PPRL)技术虽然能保护计…...

DeepSeek Ansible剧本调试黑洞破解:1行debug命令+4个隐藏日志开关,5分钟定位playbook卡死根源
更多请点击: https://intelliparadigm.com 第一章:DeepSeek Ansible剧本调试黑洞破解:1行debug命令4个隐藏日志开关,5分钟定位playbook卡死根源 当 DeepSeek 定制的 Ansible playbook 在执行中突然“静默卡死”——无报错、无超时…...

Win11 一键安装 OpenClaw 从下载到使用完整版
适配系统:Windows 11 专业版 / 家庭版 / 正式版(全版本兼容) 项目介绍:OpenClaw 是 GitHub 星标 28W 的开源本地 AI 智能体,可自动操控电脑、整理文件、浏览器自动化、办公自动化,被国内用户称为小龙虾&…...

免费获取A股行情数据的终极解决方案:Python通达信接口实战指南
免费获取A股行情数据的终极解决方案:Python通达信接口实战指南 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 在前100个字内,MOOTDX作为一款基于Python的通达信数据接口封…...

亲测分享!优豆云免费资源助力我的小站起飞,还有惊喜优惠
大家好呀! 最近一直在捣鼓自己的个人小项目和博客,对于像我这样的新手来说,成本控制是首要考虑的问题。偶然间发现了 优豆云 这个宝藏平台 (https://www.udouyun.com),简直是为我们这些预算有限但又想练手、展示创意的朋友量身定做…...

Android定位模拟技术全解析:Xposed Hook实现位置伪造的完整指南
Android定位模拟技术全解析:Xposed Hook实现位置伪造的完整指南 【免费下载链接】FakeLocation Xposed module to mock locations per app. 项目地址: https://gitcode.com/gh_mirrors/fak/FakeLocation 在移动应用开发和测试领域,Android定位模拟…...

Mysql JOIN 的物理执行流程
一、关联字段在两个表中都没有索引 当两个参与 join 的表在关联字段上都没有索引时,MySQL 无法使用高效的索引树搜索,而是被迫采用 Block Nested-Loop Join (BNL) 算法。 为了清晰讲解物理流程,我们设定如下 SQL 示例 : 表 t1t1t1…...

研一新生必看!文献管理软件到底要不要用?Scholaread vs Zotero新手友好度对比
刚进入研究生阶段,你可能会听到师兄师姐反复强调"一定要用文献管理软件",但心里却充满疑问:我就几十篇文献,真的需要专门的工具吗?市面上那么多软件,Zotero、EndNote、Scholaread…到底哪个适合零基础的我? **研一新生面临的最大困境:**电脑里200篇PDF文件散落在下…...

别只看版本号!思科show version命令里这5个隐藏信息,排错时超有用
思科show version命令的5个排错黄金线索:工程师实战指南 当网络设备突然抽风时,大多数工程师的第一反应是查看日志或运行诊断命令。但有个被严重低估的宝藏命令——show version,它输出的信息远不止版本号那么简单。想象一下,你凌…...