强化学习学习(三)收敛性证明与DDPG
文章目录
- 证明收敛?
- Deep RL with Q-Functions
- Double Q-Learning
- 理论上的解法
- 实际上的解法
- DDPG: Q-Learning with continuous actions
- Advanced tips for Q-Learning
证明收敛?
-
对于Value迭代:不动点证明的思路
首先定义一个算子 B : B V = max a r a + γ T a V \mathcal{B}:\mathcal{B}V=\max_ar_a+\gamma\mathcal{T}_aV B:BV=maxara+γTaV
接着有一个不动点 V ∗ ( s ) = max a r ( s , a ) + γ E [ V ∗ ( s ′ ) ] V^*(s)=\max_{a}r(s,a)+\gamma E[V^*(s')] V∗(s)=maxar(s,a)+γE[V∗(s′)],有 V ∗ = B V ∗ V^*=\mathcal{B}V^* V∗=BV∗
每次使用算子都会,V离不动点的距离有收缩: ∣ ∣ B V − V ∗ ∣ ∣ ∞ ≤ γ ∣ ∣ V − V ∗ ∣ ∣ ∞ ||\mathcal{B}V-V^*||_\infty\leq\gamma||V-V^*||_{\infty} ∣∣BV−V∗∣∣∞≤γ∣∣V−V∗∣∣∞ -
对于神经网络拟合的Value迭代:对于监督学习,也是得到一个 V ′ V' V′使得距离 ∣ ∣ V ′ ( s ) − ( B V ) ( s ) ∣ ∣ 2 ||V'(s)-(\mathcal{B}V)(s)||^2 ∣∣V′(s)−(BV)(s)∣∣2最小——投影
V的迭代是这样的 V ← Π B V V\leftarrow \Pi\mathcal{B}V V←ΠBV
定义一个新的算子 Π : Π V = arg max V ′ ∈ Ω 1 2 ∑ ∣ ∣ V ′ ( s ) − V ( s ) ∣ ∣ 2 \Pi:\Pi V=\arg\max_{V'\in\Omega}\frac{1}{2}\sum||V'(s)-V(s)||^2 Π:ΠV=argmaxV′∈Ω21∑∣∣V′(s)−V(s)∣∣2, Π \Pi Π实际上是用l2范数对 Ω \Omega Ω的投影,也是收缩的
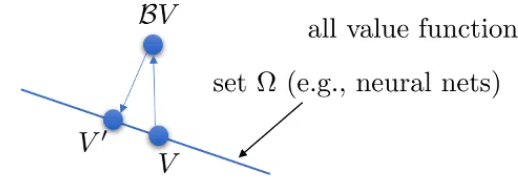
[!收缩:]
∣ ∣ Π V − Π V ˉ ∣ ∣ 2 ≤ ∣ ∣ V − V ˉ ∣ ∣ 2 ||\Pi V-\Pi \bar{V}||^2\leq||V-\bar{V}||^2 ∣∣ΠV−ΠVˉ∣∣2≤∣∣V−Vˉ∣∣2(注意这里用的是2范数而上面是无穷范数,两种算子都是再各自的范数上收缩的),但是把两个算子结合在一起就不会收缩了
所以就导致了使用Q-table能够保证收敛,而用神经网络拟合的V的Q-iteration不能够收敛
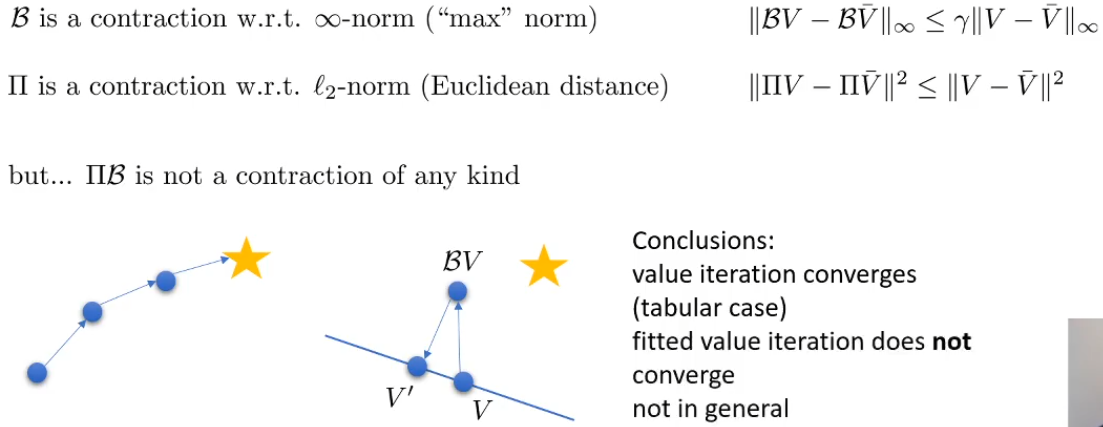
- 对于Q-iteration
和上面一样,用神经网络拟合时不收敛,因为有投影算子 - 对于A-C
也是再用神经网络拟合的时候不收敛
尽管理论上令人沮丧,但是实际中可以表现的很好!
Deep RL with Q-Functions

这里面包含了replay buffer和target network,但是暂时不细说了。
Polyak averaging:模型平均的问题
Double Q-Learning
在实际的使用过程中,Q-Learning总是出现overestimate的问题:估计的价值比实际的价值高很多:
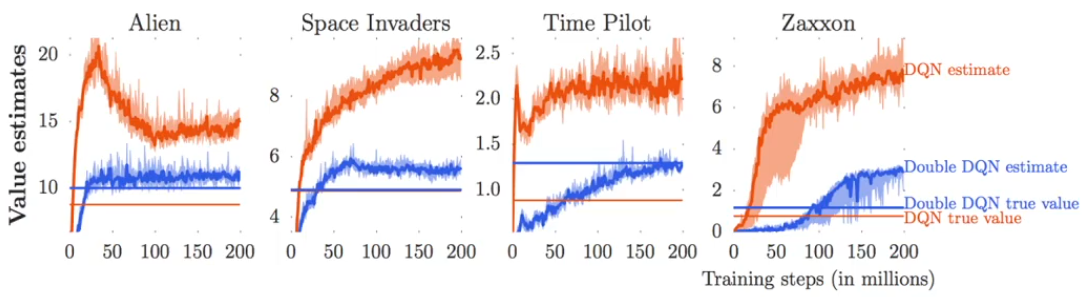
为什么会出现这样呢:
我们的target value是 y i = r i + γ max a j ′ Q ϕ ′ ( s j ′ , a j ′ ) y_i=r_i+\gamma\max_{a'_j}Q_{\phi'}(s'_j,a'_j) yi=ri+γmaxaj′Qϕ′(sj′,aj′),其中 ϕ ′ \phi' ϕ′是当前的价值函数
imagine we have two random variables: X 1 , X 2 X_1,X_2 X1,X2,We have E [ max ( X 1 , X 2 ) ] ≥ max ( E [ X 1 ] , E X 2 ) E[\max(X_1,X_2)]\ge\max(E[X_1],E{X_2}) E[max(X1,X2)]≥max(E[X1],EX2)
而对于 Q ϕ ′ ( s ′ , a ′ ) Q_{\phi'}(s',a') Qϕ′(s′,a′),它是对真正Q函数的估计,也就是真正的Q函数加上一些“噪声”,所以当我们取 Q ϕ ′ ( s ′ , a ′ ) Q_{\phi'}(s',a') Qϕ′(s′,a′)的最大值的时候,尽管“噪声”是无偏的,也会导致最后的值变大:
max a ′ Q ϕ ′ ( s ′ , a ′ ) = Q ϕ ′ ( s ′ , arg max a ′ Q ϕ ′ ( s ′ , a ′ ) ) \max_{a'}Q_{\phi'}(s',a')=Q_{\phi'}(s',\arg\max_{a'} Q_{\phi'}(s',a')) a′maxQϕ′(s′,a′)=Qϕ′(s′,arga′maxQϕ′(s′,a′))
为什么有上面这个式子的写法? 别忘了遵循贪婪(没有”探索“)的策略,我们选择下一个action就是根据 Q ϕ ′ Q_{\phi'} Qϕ′的,因为是根据 arg max \arg\max argmax选出来的,因此如果我们选择了正的噪声的action作为价值函数的输入,那么价值函数会基于同样的贪婪也会选择正的噪声,就会overestimate。

理论上的解法
因此,提出了Double Q-Learning,我们分别使用两个神经网络去产生动作和估计价值,这样两个神经网络拟合时产生的”噪声“就是不相关的!——这个操作非常像通信里面的啊!
Q ϕ A ( s , a ) = r + γ Q ϕ B ( s ′ , arg max a ′ Q ϕ A ( s ′ , a ′ ) ) Q_{\phi_A}(s,a)=r+\gamma Q_{\phi_B}(s',\arg\max_{a'} Q_{\phi_A}(s',a')) QϕA(s,a)=r+γQϕB(s′,arga′maxQϕA(s′,a′))
Q ϕ B ( s , a ) = r + γ Q ϕ B ( s ′ , arg max a ′ Q ϕ B ( s ′ , a ′ ) ) Q_{\phi_B}(s,a)=r+\gamma Q_{\phi_B}(s',\arg\max_{a'} Q_{\phi_B}(s',a')) QϕB(s,a)=r+γQϕB(s′,arga′maxQϕB(s′,a′))
实际上的解法
实际上,我们不需要麻烦的创造一个动作选择神经网络,一个价值神经网络,而是直接利用现成的:

别忘了我们其实有两个 ϕ \phi ϕ和 ϕ ′ \phi' ϕ′的,一个表示目标函数,另一个则是不断更新的,而目标函数会定期更新,因此我们直接借助这两个现成的:
y i = r i + γ Q ϕ ′ ( s j ′ , arg max a ′ Q ϕ ( s ′ , a ′ ) ) y_i=r_i+\gamma Q_{\phi'}(s'_j,\arg\max_{a'}Q_{\phi}(s',a')) yi=ri+γQϕ′(sj′,arga′maxQϕ(s′,a′))
上面利用当前的神经网络去确定动作action,而利用目标网络去确定价值value
DDPG: Q-Learning with continuous actions
- 各种对连续动作采样的方法
- DDPG
回忆一下,我们的目标是 max a Q ϕ ( s , a ) = Q ϕ ( s , arg max a Q ϕ ( s , a ) ) \max_a Q_{\phi}(s,a)=Q_{\phi}(s,\arg\max_{a}Q_{\phi}(s,a)) maxaQϕ(s,a)=Qϕ(s,argmaxaQϕ(s,a))
因此,想办法训练另一个网络 μ θ ≈ arg max a Q ϕ ( s , a ) \mu_\theta\approx\arg\max_a Q_\phi(s,a) μθ≈argmaxaQϕ(s,a),它可以看作是一个状态-动作函数,用来模拟 arg max \arg\max argmax的过程
怎么去寻找这个网络的参数呢?因为我们是寻找最大的Q,因此用梯度上升就可以 d Q ϕ d θ = d a d θ d Q ϕ d a \frac{dQ_\phi}{d\theta}=\frac{da}{d\theta}\frac{dQ_\phi}{da} dθdQϕ=dθdadadQϕ
新的target: y j = r j + γ Q ϕ ′ ( s j ′ , μ θ ( s j ′ ) ) ≈ r j + γ Q ϕ ′ ( s j ′ , arg max a ′ Q ϕ ′ ( s j ′ , a j ′ ) ) y_j=r_j+\gamma Q_{\phi'}(s'_j,\mu_\theta(s'_j))\approx r_j+\gamma Q_{\phi'}(s'_j,\arg\max_{a'}Q_{\phi'}(s'_j,a'_j)) yj=rj+γQϕ′(sj′,μθ(sj′))≈rj+γQϕ′(sj′,argmaxa′Qϕ′(sj′,aj′))

Advanced tips for Q-Learning
- Q-Learning再不同问题上的稳定度很不同,因此需要首先确保稳定性,包括选择合适的随机数种子。
- 较大的replay buffer能够帮助提高稳定性
- Looks more like fitted Q-iteration
- 学习可能需要很长时间才能有突破
- 进行探索的时候,先把 ϵ \epsilon ϵ设置大一点,随后慢慢的逐步减小
- Bellman error gradients can be big: clip gradients or use Huber loss instead L = { x 2 / 2 if ∣ x ∣ ≤ δ δ ∣ x ∣ − δ 2 / 2 otherwise L=\begin{cases} x^2/2& \text{ if } |x|\leq\delta \\ \delta|x|-\delta^2/2& \text{ otherwise } \end{cases} L={x2/2δ∣x∣−δ2/2 if ∣x∣≤δ otherwise
- 多使用Double Q-Learning,非常好用
- 变化的学习率或者Adam optimizer会很有帮助

相关文章:
强化学习学习(三)收敛性证明与DDPG
文章目录 证明收敛? Deep RL with Q-FunctionsDouble Q-Learning理论上的解法实际上的解法 DDPG: Q-Learning with continuous actionsAdvanced tips for Q-Learning 证明收敛? 对于Value迭代:不动点证明的思路 首先定义一个算子 B : B V ma…...

培养前端工程化思维,不要让一行代码毁了整个程序
看《阿丽亚娜 5 号(Ariane 5)火箭爆炸》有感。 1、动手写项目之前,先进行全局性代码逻辑思考,将该做的事情,一些细节,统一建立标准,避免为以后埋雷。 2、避免使用不必要或无意义的代码、注释。…...

电子文件怎么盖章?
电子文件怎么盖章?电子文件盖章是数字化办公中常见的操作,包括盖电子公章和电子骑缝章。以下是针对这两种情况的详细步骤: 一、盖电子公章 方法一:使用专业软件 选择软件:选择一款专业的电子签名或PDF编辑软件&…...

IDEA在编译的时候报Error: java: 找不到符号符号: 变量 log lombok失效问题
错误描述 idea因为lombok的报错: java: You arent using a compiler supported by lombok, so lombok will not work and has been disabled.Your processor is: com.sun.proxy.$Proxy8Lombok supports: sun/apple javac 1.6, ECJ 原因:这是由于Lombok的版本过低的…...

【Python】如何修改元组的值?
一、题目 We have seen that lists are mutable (they can be changed), and tuples are immutable (they cannot be changed). Lets try to understand this with an example. You are given an immutable string, and you want to make chaneges to it. Example >>…...
【安卓】Android Studio简易计算器(实现加减乘除,整数小数运算,正数负数运算)
目录 前言 运算效果 一、创建一个新的项目 二、编写xml文件(计算器显示页面) 三、实现Java运算逻辑 编辑 完整代码 xml文件代码: Java文件代码: 注: 前言 随着移动互联网的普及,手机应用程序已…...

一个vue mixin 小案例,实现等比例缩放
mixin.js /** Author: jinjianwei* Date: 2024-07-24 16:17:16* Description: 等比例缩放,屏幕适配 mixin 函数*/// * 默认缩放值 const scale {width: 1,height: 1, } // * 设计稿尺寸(px) const baseWidth 1920 const baseHeight 1080 …...

【数据结构初阶】单链表经典算法题十二道——得道飞升(中篇)
hi,bro—— 目录 5、 链表分割 6、 链表的回文结构 7、 相交链表 8、 环形链表 【思考】 —————————————— DEAD POOL —————————————— 5、 链表分割 /* struct ListNode {int val;struct ListNode *next;ListNode(int x) : val(x), …...

CTF ssrf 基础入门 (一)
0x01 引言 我发现我其实并不是很明白这个东西,有些微妙,而且记忆中也就记得Gopherus这个工具了,所以重新学习了一下,顺便记录一下吧 0x02 辨别 我们拿到一个题目,他的名字可能就是题目类型,但是也有可能…...

IP地址在后端怎么存才好?
目录 一、地址的区别 二、字符串存取 2.1 IPV4空间大小 2.2 IPV6空间大小 三、整数存取 四、总结 4.1 字符串存取优缺点 4.2 整数存取的优缺点 一、地址的区别 在网络中,IP地址分为IPV4和IPV6,IPV4是一共占32位的,每8位小数点分隔&…...
《通讯世界》是什么级别的期刊?是正规期刊吗?能评职称吗?
问题解答 问:《通讯世界》是不是核心期刊? 答:不是,是知网收录的第一批认定学术期刊。 问:《通讯世界》级别? 答:国家级。主管单位:科学技术部 主办单位:中国科学技…...

go get的原理
1、GOPROXY 可以写在os的环境变量中,也可以写在go的环境变量中 GOPROXYhttps://goproxy.cn,direct 表示先去第一个网址下载,下载不到,就直接下载 也可以配置GOPRIVATE私有仓库,遇到私有仓库中的包,就直接下载 2、go…...

jenkins替换配置文件
1.点击首页的【Manage Jenkins】-【Manage Plugins】,在选项【Available plugins】安装 Config File Provider Plugin ,安装后重启jenkins 2.安装完成后会有这个图标,点进去 3.点击新建,选择自定义,填入要替换的文件…...

C# Web控件与数据感应之 填充 HtmlTable
C# Web控件与数据感应之 填充 HtmlTable 在C#中,特别是在ASP.NET Web Forms应用中,你可能会遇到需要将数据动态填充到HTML表格(HtmlTable)中的场景。这通常涉及到遍历数据源(如数据库查询结果、集合等)&am…...

HAL库源码移植与使用之SPI驱动VS1053音频解码
你可以理解为带着dac adc芯片功能的集成芯片,声音的高低音形成由频率决定,大小声由波峰决定,所以采集时记录时间和电压值就可以确定高低音色和大小声,形成声音波形,再把波形用dac输出给喇叭,让喇叭在对应时…...

RK3568 Linux 平台开发系列讲解(内核入门篇):从内核的角度看外设芯片的驱动
在嵌入式 Linux 开发中,外设芯片的驱动是实现操作系统与硬件之间交互的关键环节。对于 RK3568 这样的处理器平台,理解如何从内核的角度构建和管理外设芯片的驱动程序至关重要。 1. 外设驱动的基础概念 外设驱动(Device Driver)是操作系统与硬件设备之间的桥梁。它负责控…...

初识C++ · AVL树(2)
目录 前言: 1 左右旋 2 右左旋 3 部分细节补充 3.1 单旋和插入 3.2 部分小函数 前言: AVL树作为一种结构,理解树的本身是不大难的,难的在于,树旋转之后的连接问题,写AVL树的代码大部分都是在旋转部分…...

LLM:归一化 总结
一、Batch Normalization 原理 Batch Normalization 是一种用于加速神经网络训练并提高稳定性的技术。它通过在每一层网络的激活值上进行归一化处理,使得每一层的输入分布更加稳定,从而加速训练过程,并且减轻了对参数初始化的依赖。 公式 …...

蓝桥杯 2024 年第十五届省赛真题 —— 最大异或结点
目录 1. 最大异或结点1. 问题描述2. 输入格式3. 输出格式4. 样例输入5. 样例输出6. 样例说明7. 评测用例规模与约定 2. 解题思路1. 解题思路2. AC_Code 1. 最大异或结点 1. 问题描述 小蓝有一棵树,树中包含 N N N 个结点,编号为 0 , 1 , 2 , ⋯ , N − 1 0,1,2,…...

AV1技术学习:Loop Restoration Filter
环路恢复滤波器(restoration filter)适用于64 64、128 128 或 256 256 像素块单元,称为 loop restoration units (LRUs)。每个单元可以独立选择是否跳过滤波、使用维纳滤波器(Wiener filter)或使用自导滤波器&#…...

基于Git与Markdown的文档即代码协作平台CORP实践指南
1. 项目概述:一个面向未来的开源协作平台 最近在开源社区里,一个名为“CORP”的项目引起了我的注意。这个项目全称是“CORP-md/CORP”,从名字上看,它似乎是一个与Markdown文档和协作相关的工具。作为一个长期在开源项目和团队协作…...

如何快速掌握WarcraftHelper:魔兽争霸III终极辅助工具完整指南
如何快速掌握WarcraftHelper:魔兽争霸III终极辅助工具完整指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸III的画面拉…...

不止于水:用MS动力学模拟和RDF分析,探究任意离子/分子在溶液中的溶剂化结构
从水到多元溶液:MS动力学模拟与RDF分析的高级应用指南 当我们需要理解溶液中离子或分子的行为时,径向分布函数(RDF)分析提供了一个强有力的工具。传统的纯水体系研究固然重要,但现实中的溶液系统往往更为复杂——电解液中的锂离子、蛋白质溶液…...

告别硬件依赖:用Virtual ZPL Printer构建完整的标签打印测试环境
告别硬件依赖:用Virtual ZPL Printer构建完整的标签打印测试环境 【免费下载链接】Virtual-ZPL-Printer An ethernet based virtual Zebra Label Printer that can be used to test applications that produce bar code labels. 项目地址: https://gitcode.com/gh…...

QQ音乐加密文件解密终极指南:qmcdump实战深度解析
QQ音乐加密文件解密终极指南:qmcdump实战深度解析 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 你是否遇到…...

MCP协议实战:构建AI智能体任务管理服务器与二次开发指南
1. 项目概述:一个为AI智能体“开眼”的MCP服务器最近在折腾AI智能体(Agent)开发的朋友,估计都绕不开一个词:MCP。全称是Model Context Protocol,你可以把它理解为给大模型(比如Claude、GPT-4&am…...

基于Vercel AI SDK与Next.js的聊天机器人模板开发实战
1. 项目概述:一个开箱即用的AI聊天机器人模板 如果你正在寻找一个能快速启动、功能齐全且易于定制的AI聊天机器人项目,那么Vercel官方出品的这个Chatbot模板绝对值得你花时间研究。它不是一个简单的Demo,而是一个生产就绪的、基于现代Web技术…...

从斯普特尼克时刻到产业政策:美国科技竞争力焦虑的深层剖析
1. 从“斯普特尼克时刻”到竞争力焦虑:一场持续了半个世纪的美国辩论2011年1月25日,时任美国总统奥巴马在国情咨文演讲前,将美国当时面临的挑战称为又一个“斯普特尼克时刻”。这个比喻精准地戳中了一代美国工程师、企业家和政策制定者的神经…...

企业微信消息发送踩坑实录:.NET Core下处理AccessToken过期与消息安全的最佳实践
企业微信消息发送实战:.NET Core中的AccessToken管理与消息安全策略 当企业微信API集成到生产环境时,开发者常会遇到两个看似简单却暗藏玄机的问题:AccessToken突然失效导致消息发送失败,以及敏感信息传输时的安全风险。本文将分享…...

3PEAK思瑞浦 TPA2644-SO2R-S SOP14 运算放大器
特性 供电电压:3V至36V 偏移电压:3mV(最大值)差分输入电压范围至电源轨,可作为比较器工作 带宽:1.5MHz,斜率:0.5V/us输入轨至-Vs,无内部ESD二极管至Vs 低1/f噪声:在10Hz时为50nV/Hz 高PSRR:100kHz时60dB 开机和关机电流期间无明显输出抖动 工…...