GRL-图强化学习
GRL代码解析
- 一、agent.py
- 二、drl.py
- 三、env.py
- 四、policy.py
- 五、utils.py
一、agent.py
这个Python文件agent.py实现了一个强化学习(Reinforcement Learning, RL)的智能体,用于在图环境(graph environment)中进行学习。以下是文件的主要部分的概述:
-
导入依赖:
- 导入了
matplotlib.pyplot用于绘图,tqdm用于在循环中显示进度条。 - 从
utils.py和policy.py中导入了一些功能性代码(graph_nn是图神经网络)。 - 从
drl.py导入了REINFORCE类,这是强化学习的一种算法。 - 从
cora_gcn.py中导入了CoraGraphEnv,可能是图环境的一个实现。 - 从
env.py中导入graph_env,可能是定义的环境。 - 从
torch库中导入了设备管理和概率分布。
- 导入了
-
环境配置:
- 设置了使用
CUDA(如果可用)或者CPU。 - 设置随机种子以保证可复现性。
- 实例化了
graph_env(图形环境)。
- 设置了使用
-
超参数定义:
- 定义了学习速率
learning_rate,剧集数量episodes,折扣因子gamma,以及日志打印间隔log_interval。
- 定义了学习速率
-
策略网络:
- 实例化了图神经网络
graph_nn作为策略网络,根据环境动作空间、输入维度和隐藏维度。
- 实例化了图神经网络
-
学习器:
- 实例化了
REINFORCE算法作为学习器,传入策略网络、学习速率和折扣因子。
- 实例化了
-
学习循环:
- 使用
tqdm进行进度显示,迭代episodes次。 - 在每次迭代中重置环境,执行一系列操作直到达到环境的
done状态。 - 在每个步骤中,获取当前状态下的动作概率分布,选择动作,并与环境交互获得下一个状态、奖励和是否完成。
- 将这些数据存入学习器的记忆中。
- 更新累计奖励。
- 每次剧集结束后通过
learn()方法更新策略网络。
- 使用
-
可视化结果:
- 收集每集的奖励,并绘制奖励随时间变化的曲线。
- 将奖励曲线保存为图片。
整体上,这是一个图神经网络通过强化学习来优化策略的任务,代码使用了REINFORCE算法进行策略学习,并最终保存奖励曲线图。
二、drl.py
这个Python源代码文件drl.py实现了一个简单的强化学习算法类REINFORCE,该类使用了策略梯度方法(Policy Gradient Method)进行参数优化。以下是文件概述:
-
目的:
- 定义并实现了一个名为
REINFORCE的强化学习算法类。 - 用于优化给定的策略函数(例如图神经网络模型)。
- 定义并实现了一个名为
-
主要特征:
- 依赖于PyTorch库来构建和训练模型。
- 使用了Adam优化算法进行参数优化。
- 包含了一个经验数据存储池(experience buffer)用于存储经验数据。
- 引入了基线(baseline)以提高学习稳定性。
-
类成员:
policy:策略函数,待优化的神经网络模型。optimizer:优化算子,用于更新模型参数。gamma:折扣因子,用于计算未来的回报。experience_buffer:存储经验数据的列表。baseline:用于减少方差且提高学习效率的基线。
-
方法:
__init__:初始化方法,设置优化器和相关参数。memory_data(self, data):将新的经验数据添加到经验池中。learn(self):- 计算折扣回报并进行反向传播。
- 如果基线数据少于100个,直接用累计折现回报作为loss。
- 如果基线数据超过100个,使用最近10个回报的平均值作为基线,以减少方差。
-
注意事项:
- 代码中有大量的空行,应该清理。
- 在计算
loss时,应注意符号的使用,避免潜在的错误。 - 确认
prob是否应该是一个log概率,这在策略梯度方法中是常见的。 - 基线计算(在
else部分)通过转换最近的回报为一个PyTorch张量来计算,这需要和模型的数据类型保持一致。
总结:drl.py文件定义了强化学习算法REINFORCE,主要用于通过梯度上升法来优化给定策略网络。其中包含了保存经验数据、计算折扣回报、更新模型参数等方法。
三、env.py
这个env.py文件定义了一个基于图的环境模型类graph_env,它是OpenAI Gym环境的一个封装器。以下是概述:
-
目的: 旨在将标准的Gym环境(在这个例子中是’CartPole-v1’)的状态转换成图数据结构,以便可以使用图神经网络(Graph Neural Networks,GNNs)进行学习和处理。
-
依赖:
gym:用于导入OpenAI Gym环境。torch:用于创建和操作张量。torch_geometric.data:用于处理图数据结构。
-
核心类:
graph_env:继承自gym.Env,重写了标准的Gym环境的部分功能,使其能够返回图格式数据。
-
功能:
__init__:初始化方法,创建一个CartPole-v1环境的实例,并设置观察和动作空间。to_pyg_data:将环境状态数据转换成一个可以被torch_geometric处理的图数据结构(Data对象),包括节点特征和边索引。reset:重置环境到初始状态,并将这个状态转换为图数据结构。step:根据采取的动作将环境推进到下一个状态,并返回转换后的图状态、奖励、环境是否结束以及附加信息。
-
图数据构建:
- 在
to_pyg_data方法中,节点特征是由当前状态的不同组合构成的,边索引是由节点全排列生成的,表示图中所有可能的边。
- 在
-
适用性:
- 这个类适用于希望将图神经网络应用于像CartPole这样的经典控制问题环境的情况。
-
注意点:
- 这个简单的转换可能不足以表示所有类型的环境状态为图数据结构,特别是当环境复杂性提高时。
permutations用于生成图中所有可能的边,这并不适用于所有图场景,因为它假设所有节点之间都存在潜在的连接。
四、policy.py
这是一个用PyTorch编写的图神经网络(Graph Neural Network, GNN)模型,主要用于处理图结构的数据。以下是该源代码的概述:
-
依赖库:
torch:PyTorch的 核心。torch.nn:PyTorch的神经网络模块。torch.nn.functional:PyTorch的函数式API,用于激活函数等。torch_geometric.nn:用于图神经网络的PyTorch几何扩展库,包含专门的图处理层。
-
设备配置:
- 自动检查是否可用GPU,并将设备设置为
cuda:0,否则使用CPU。
- 自动检查是否可用GPU,并将设备设置为
-
类定义:
graph_nn:一个继承自nn.Module的图神经网络类。- 初始化参数:
action_space:动作空间的大小,决定输出层的神经元数。input_dim:输入特征的维度。hidden_dim:隐藏层神经元的维度。
- 网络结构:
GCNConv:图卷积层。nn.Linear:两个全连接层。LayerNorm:图归一化层(但在实际的前向传播中并没有使用)。
- 前向传播:
- 采用ReLU作为激活函数。
- 使用全局池化来减少图的特征到单点特征。
- 最后使用log-softmax作为输出层,常用于分类任务。
- 初始化参数:
-
前向传播函数:
forward(self,x,edge_index):定义了网络的前向传播过程,接收节点特征x和边索引edge_index作为输入,并输出节点的分类log-softmax结果。
-
注解:
- 代码中有一些被注释掉的部分,可能是以前版本的操作,如
self.layer_norm的调用方式。
- 代码中有一些被注释掉的部分,可能是以前版本的操作,如
这个模型是一个基于图的结构化数据学习框架,可以用于在图上的分类问题或其他需要在节点或图级别进行预测的问题。
五、utils.py
概述:
utils.py 是一个Python模块,属于一个用于图形神经网络(Graph Neural Network, GNN)相关项目的工具脚本。以下是该模块的功能概述:
-
导入库和模块:
torch:导入PyTorch库,用于构建和训练神经网络。torch_geometric.data.Data:从PyTorch Geometric中导入Data类,用于处理图形数据。itertools.permutations:导入itertools中的permutations,用于生成可迭代对象的排列。matplotlib.pyplot:用于绘制图表。numpy:使用NumPy进行数值计算。random:用于生成随机数。
-
功能函数:
-
seed_torch(seed):设置PyTorch、NumPy和Python的随机种子,以保证可重复性。如果CUDNN可用,还将设置相关选项以确保算法的确定性执行。 -
plot_reward(reward):接收一个奖励数组并绘制奖励曲线。此函数使用matplotlib库来创建图表,用于分析策略执行过程中累积奖励随时间(或迭代次数)的变化。
-
-
未使用的代码:有一行代码
plt.subplot(1, 3, 1)被注释掉,说明可能原本计划在一个更大的画布上绘制多个子图,但最终没有使用。
这个模块可能用于支持图形数据的处理、结果的可视化以及实验的可重复性。它作为项目的一部分,可以被其他脚本或模块调用以提供辅助功能。
以下是使用Markdown格式描述各个文件功能的表格:
| 文件路径 | 功能描述 |
|---|---|
agent.py | 实现了一个强化学习智能体,用于在图环境中使用REINFORCE算法进行策略学习。 |
drl.py | 定义并实现了REINFORCE算法类,基于策略梯度方法优化策略网络。 |
env.py | 封装了标准的Gym环境,将其转换为图数据结构,以便可以使用图神经网络进行学习和处理。 |
policy.py | 实现了一个图神经网络模型,用作策略网络来处理图结构的数据并输出动作概率分布。 |
utils.py | 提供了一系列工具函数,包括设置随机种子、绘图等,用于支持图神经网络训练过程。 |
整体程序功能的概括:
这个程序是一个基于图神经网络和强化学习的框架,旨在通过策略梯度方法学习在图形环境中的最优策略。
相关文章:

GRL-图强化学习
GRL代码解析 一、agent.py二、drl.py三、env.py四、policy.py五、utils.py 一、agent.py 这个Python文件agent.py实现了一个强化学习(Reinforcement Learning, RL)的智能体,用于在图环境(graph environment)中进行学习…...

昇思25天学习打卡营第22天|Pix2Pix实现图像转换
Pix2Pix图像转换学习总结 概述 Pix2Pix是一种基于条件生成对抗网络(cGAN)的深度学习模型,旨在实现不同图像风格之间的转换,如从语义标签到真实图像、灰度图到彩色图、航拍图到地图等。这一模型由Phillip Isola等人在2017年提出&…...

全感知、全覆盖、全智能的智慧快消开源了。
智慧快消视频监控平台是一款功能强大且简单易用的实时算法视频监控系统。它的愿景是最底层打通各大芯片厂商相互间的壁垒,省去繁琐重复的适配流程,实现芯片、算法、应用的全流程组合,从而大大减少企业级应用约95%的开发成本。AI安全管理平台&…...
)
ABC364:D - K-th Nearest(二分)
题目 在一条数线上有 NQNQ 个点 A1,…,AN,B1,…,BQA1,…,AN,B1,…,BQ ,其中点 AiAi 的坐标为 aiai ,点 BjBj 的坐标为 bjbj 。 就每个点 j1,2,…,Qj1,2,…,Q 回答下面的问题: 设 XX 是 A1,A2,…,ANA1,A2,…,AN 中最…...

hive中分区与分桶的区别
过去,在学习hive的过程中学习过分桶与分区。但是,却未曾将分区与分桶做详细比较。今天,回顾skew join时涉及到了分桶这一概念,一时间无法区分出分区与分桶的区别。查阅资料,特地记录下来。 一、Hive分区 1.分区一般是…...

Blender材质-PBR与纹理材质
1.PBR PBR:Physically Based Rendering 基于物理的渲染 BRDF:Bidirection Reflectance Distribution Function 双向散射分散函数 材质着色操作如下图: 2.纹理材质 左上角:编辑器类型中选择,着色器编辑器 新建着色器 -> 新建纹理 -> 新…...

微软的Edge浏览器如何设置兼容模式
微软的Edge浏览器如何设置兼容模式? Microsoft Edge 在浏览部分网站的时候,会被标记为不兼容,会有此网站需要Internet Explorer的提示,虽然可以手动点击在 Microsoft Edge 中继续浏览,但是操作起来相对复杂,…...
)
SpringBoot开启多端口探究(1)
文章目录 前情提要发散探索从management.port开始确定否需要开启额外端口额外端口是如何开启的ManagementContextFactory的故事从哪儿来创建过程 management 相关API如何被注册 小结 前情提要 最近遇到一个需求,在单个服务进程上开启多网络端口,将API的…...

优化算法:2.粒子群算法(PSO)及Python实现
一、定义 粒子群算法(Particle Swarm Optimization,PSO)是一种模拟鸟群觅食行为的优化算法。想象一群鸟在寻找食物,每只鸟都在尝试找到食物最多的位置。它们通过互相交流信息,逐渐向食物最多的地方聚集。PSO就是基于这…...

ThreadLocal面试三道题
针对ThreadLocal的面试题,我将按照由简单到困难的顺序给出三道题目,并附上参考答案的概要。 1. 简单题:请简述ThreadLocal是什么,以及它的主要作用。 参考答案: ThreadLocal是Java中的一个类,用于提供线…...
)
Git操作指令(已完结)
Git操作指令 一、安装git 1、设置配置信息: # global全局配置 git config --global user.name "Your username" git config --global user.email "Your email"# 显示颜色 git config --global color.ui true# 配置别名,各种指令都…...

大数据采集工具——Flume简介安装配置使用教程
Flume简介&安装配置&使用教程 1、Flume简介 一:概要 Flume 是一个可配置、可靠、高可用的大数据采集工具,主要用于将大量的数据从各种数据源(如日志文件、数据库、本地磁盘等)采集到数据存储系统(主要为Had…...

C语言 #具有展开功能的排雷游戏
文章目录 前言 一、整个排雷游戏的思维梳理 二、整体代码分布布局 三、游戏主体逻辑实现--test.c 四、整个游戏头文件的引用以及函数的声明-- game.h 五、游戏功能的具体实现 -- game.c 六、老六版本 总结 前言 路漫漫其修远兮,吾将上下而求索。 一、整个排…...

npm publish出错,‘proxy‘ config is set properly. See: ‘npm help config‘
问题:使用 npm publish发布项目依赖失败,报错 proxy config is set properly. See: npm help config 1、先查找一下自己的代理 npm config get proxy npm config get https-proxy npm config get registry2、然后将代理和缓存置空 方式一: …...
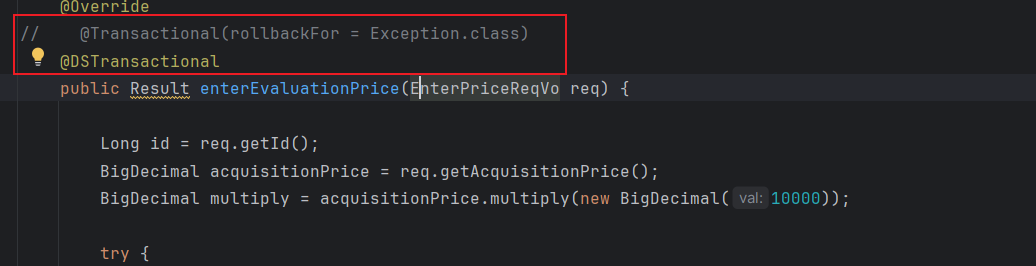
Springboot 多数据源事务
起因 在一个service方法上使用的事务,其中有方法是调用的多数据源orderDB 但是多数据源没有生效,而是使用的primaryDB 原因 spring 事务实现的方式 以 Transactional 注解为例 (也可以看 TransactionTemplate, 这个流程更简单一点)。 入口:ProxyTransa…...

Python每日学习
我是从c转来学习Python的,总感觉和c相比Python的实操简单,但是由于写c的代码多了,感觉Python的语法好奇怪 就比如说c的开头要有库(就是类似于#include <bits/stdc.h>)而且它每一项的代码结束之后要有一个表示结…...

数据库 执行sql添加删除字段
添加字段: ALTER TABLE 表明 ADD COLUMN 字段名 类型 DEFAULT NULL COMMENT 注释 AFTER 哪个字段后面; 效果: 删除字段: ALTER TABLE 表明 DROP COLUMN 字段;...

前端开发:HTML与CSS
文章目录 前言1.1、CS架构和BS架构1.2、网页构成 HTML1.web开发1.1、最简单的web应用程序1.2、HTTP协议1.2.1 、简介1.2.2、 http协议特性1.3.3、http请求协议与响应协议 2.HTML概述3.HTML标准结构4.标签的语法5.基本标签6.超链接标签6.1、超链接基本使用6.2、锚点 7.img标签8.…...

ctfshow解题方法
171 172 爆库名->爆表名->爆字段名->爆字段值 -1 union select 1,database() ,3 -- //返回数据库名 -1 union select 1,2,group_concat(table_name) from information_schema.tables where table_schema库名 -- //获取数据库里的表名 -1 union select 1,group_concat(…...

探索 Blockly:自定义积木实例
3.实例 3.1.基础块 无输入 , 无输出 3.1.1.json var textOneJson {"type": "sql_test_text_one","message0": " one ","colour": 30,"tooltip": 无输入 , 无输出 };javascriptGenerator.forBlock[sql_test_te…...

BetterGI:解放双手的终极原神自动化助手,每天节省2小时游戏时间
BetterGI:解放双手的终极原神自动化助手,每天节省2小时游戏时间 【免费下载链接】better-genshin-impact 📦BetterGI 更好的原神 - 自动拾取 | 自动剧情 | 全自动钓鱼(AI) | 全自动七圣召唤 | 自动伐木 | 自动刷本 | 自动采集/挖矿/锄地 | 一…...

为OpenClaw配置Taotoken实现高效AI智能体工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为OpenClaw配置Taotoken实现高效AI智能体工作流 OpenClaw 是一个流行的开源AI智能体框架,它允许开发者快速构建和编排复…...

IntelliNode:统一AI模型调用,加速Node.js智能应用开发
1. 项目概述:从IntelliNode到智能应用开发的新范式最近在开源社区里,一个名为“IntelliNode”的项目引起了我的注意,更具体地说,是它的核心库intelligentnode/Intelli。乍一看这个名字,你可能会联想到“智能节点”&…...

演讲口才课到底有没有用?上完三个月后的真实反馈
三个月前,林薇坐在会议室的角落里,手里攥着一份精心准备的方案,却迟迟没有开口。那一刻,她看着同事们侃侃而谈,心里反复问自己:为什么明明有想法,却说不出来?就是那个瞬间࿰…...

终极指南:3分钟学会在Windows电脑上安装安卓应用
终极指南:3分钟学会在Windows电脑上安装安卓应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想过在Windows电脑上直接运行手机应用ÿ…...

【最新v2.7.1 版本安装包】OpenClaw 新手部署全攻略,无需命令零代码一键安装保姆级
Windows 一键部署 OpenClaw 教程|5 分钟搞定本地 AI 智能体,告别复杂配置 核心亮点 零代码门槛|全程可视化|无需手动配置运行环境|内置全部运行依赖|28 万 Tokens 额度 前言 2026 年开源圈热度居高不下…...

如何利用WinRAR分卷压缩,轻松突破大文件传输限制
1. 为什么需要分卷压缩? 在日常工作和生活中,我们经常会遇到需要传输大文件的情况。比如设计师要发送PSD源文件给客户,程序员要分享开发环境的镜像,或者普通用户想通过邮件发送高清视频给亲友。但几乎所有主流传输平台都对单个文件…...

OpencvSharp 算子学习教案之 - Cv2.Sobel
OpencvSharp 算子学习教案之 - Cv2.Sobel 大家好,Opencv在很多工程项目中都会用到,而OpencvSharp则是以C#开发与实现的Opencv操作库,对.NET开发人员友好,但很多API的中文资料、应用场景及常见坑点等缺乏系统性归纳,因此…...

Zotero中文文献管理终极指南:三步彻底解决知网PDF元数据抓取难题
Zotero中文文献管理终极指南:三步彻底解决知网PDF元数据抓取难题 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 你是…...
)
通用AGI终极范式:从多模态感知到意识涌现的统一理论(世毫九实验室原创研究)
通用AGI终极范式:从多模态感知到意识涌现的统一理论作者:方见华单位:世毫九实验室摘要本研究基于世毫九理论体系的数学框架,构建了通用人工智能(AGI)的完整理论体系和演化路径。通过建立包含拓扑复杂度、动…...