AI_Papers周刊:第六期
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
2023.03.13—2023.03.19
文摘词云

Top Papers
Subjects: cs.CL
1.UPRISE: Universal Prompt Retrieval for Improving Zero-Shot Evaluation
标题:UPRISE:改进零样本评估的通用提示检索
作者:Daixuan Cheng, Shaohan Huang, Junyu Bi, Yuefeng Zhan, Jianfeng Liu
文章链接:https://arxiv.org/abs/2303.08518
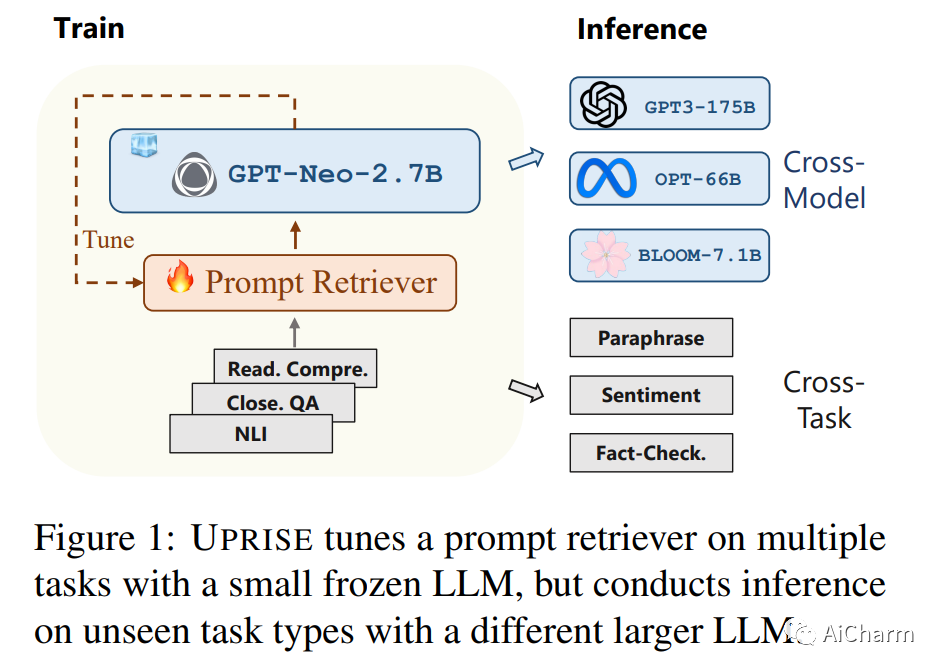
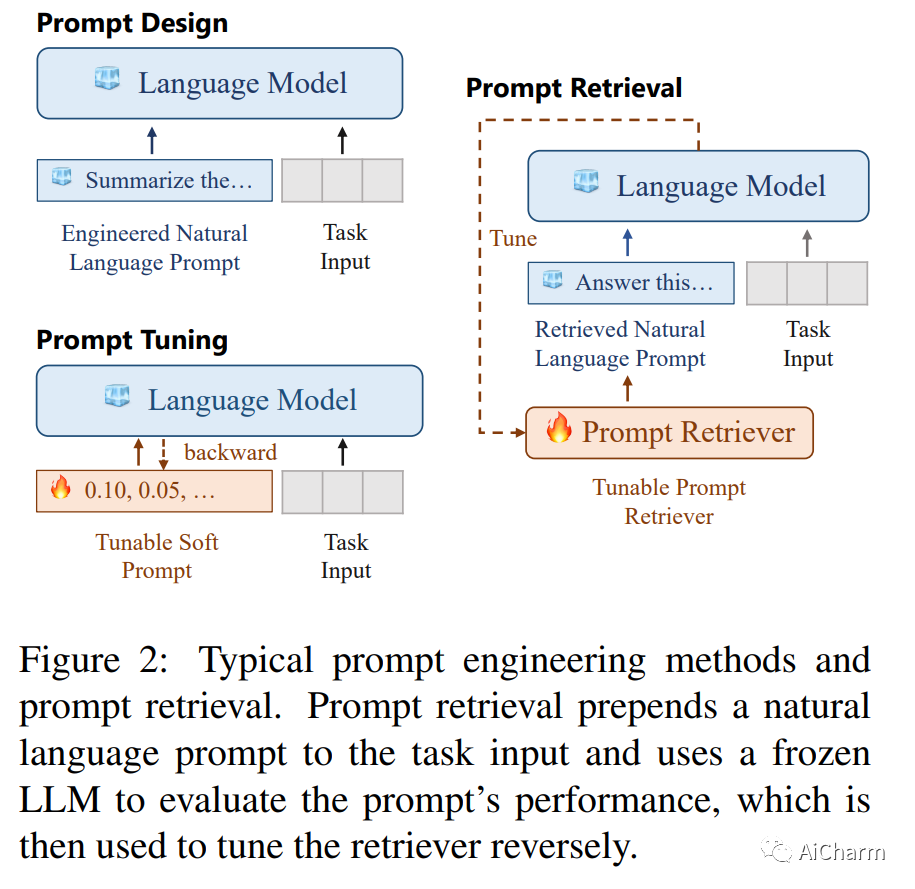

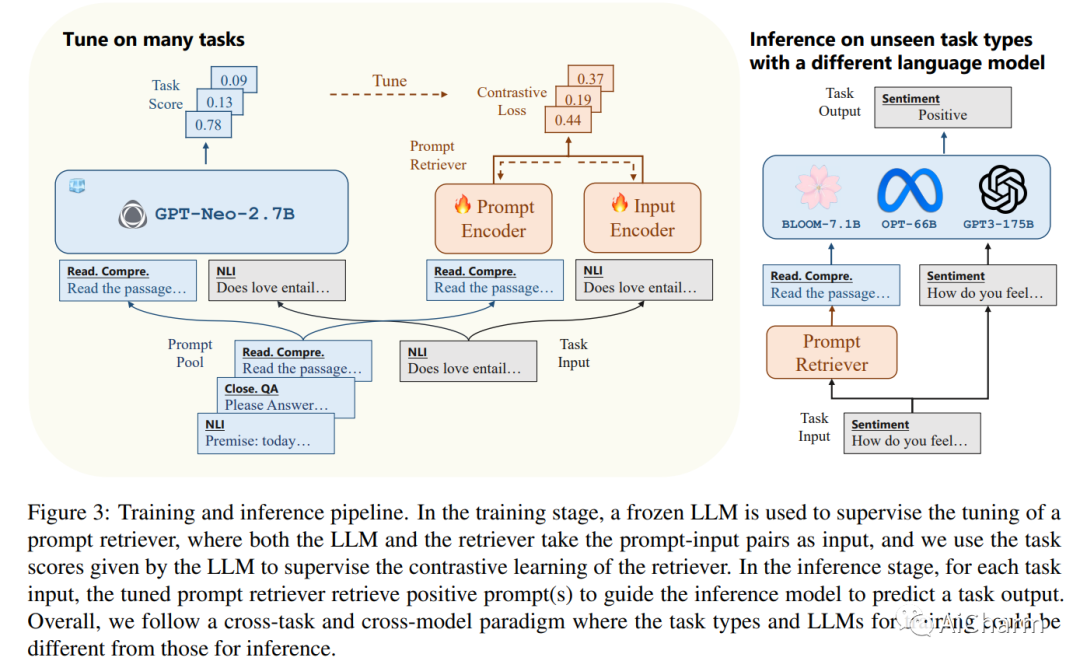
大型语言模型 (LLM) 因其令人印象深刻的能力而广受欢迎,但对特定于模型的微调或特定于任务的提示工程的需求可能会阻碍它们的泛化。我们提出了 UPRISE(用于改进零样本评估的通用提示检索),它调整了一个轻量级且多功能的检索器,该检索器可以自动检索给定零样本任务输入的提示。具体来说,我们展示了跨任务和跨模型场景中的普遍性:检索器针对不同的任务集进行了调整,但在未见过的任务类型上进行了测试;我们使用小型冻结 LLM GPT-Neo-2.7B 来调整检索器,但在规模大得多的不同 LLM 上测试检索器,例如 BLOOM-7.1B、OPT-66B 和 GPT3-175B。此外,我们表明 UPRISE 减轻了我们使用 ChatGPT 进行的实验中的幻觉问题,表明它有可能改善最强大的 LLM。
2.Efficiently Scaling Transformer Inference
标题:有效缩放 Transformer 推理
作者:Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury
文章链接:https://arxiv.org/abs/2211.05102




我们研究了 Transformer 模型的高效生成推理问题,在其最具挑战性的设置之一:大型深度模型,具有严格的延迟目标和长序列长度。更好地理解基于 Transformer 的大型模型推理的工程权衡非常重要,因为这些模型的用例在整个应用领域都在迅速增长。我们开发了一个简单的推理效率分析模型,以根据应用要求选择针对 TPU v4 切片优化的最佳多维分区技术。我们将这些与一套低级优化相结合,以在超过 FasterTransformer 基准测试套件的 500B+ 参数模型上实现延迟和模型 FLOPS 利用率 (MFU) 权衡的新帕累托边界。我们进一步表明,通过适当的分区,多查询注意的较低内存需求(即多个查询头共享单个键/值头)可以将上下文长度扩展到 32 倍。最后,我们在生成期间实现了每个令牌 29 毫秒的低批量延迟(使用 int8 权重量化),在输入令牌的大批量处理期间实现了 76% 的 MFU,同时支持长 2048 令牌上下文长度PaLM 540B参数型号。
3.Steering Prototype with Prompt-tuning for Rehearsal-free Continual Learning
标题:具有快速调整功能的转向原型,可实现免排练的持续学习
作者:Zhuowei Li, Long Zhao, Zizhao Zhang, Han Zhang, Di Liu, Ting Liu, Dimitris N. Metaxas
文章链接:https://palm-e.github.io/assets/palm-e.pdf
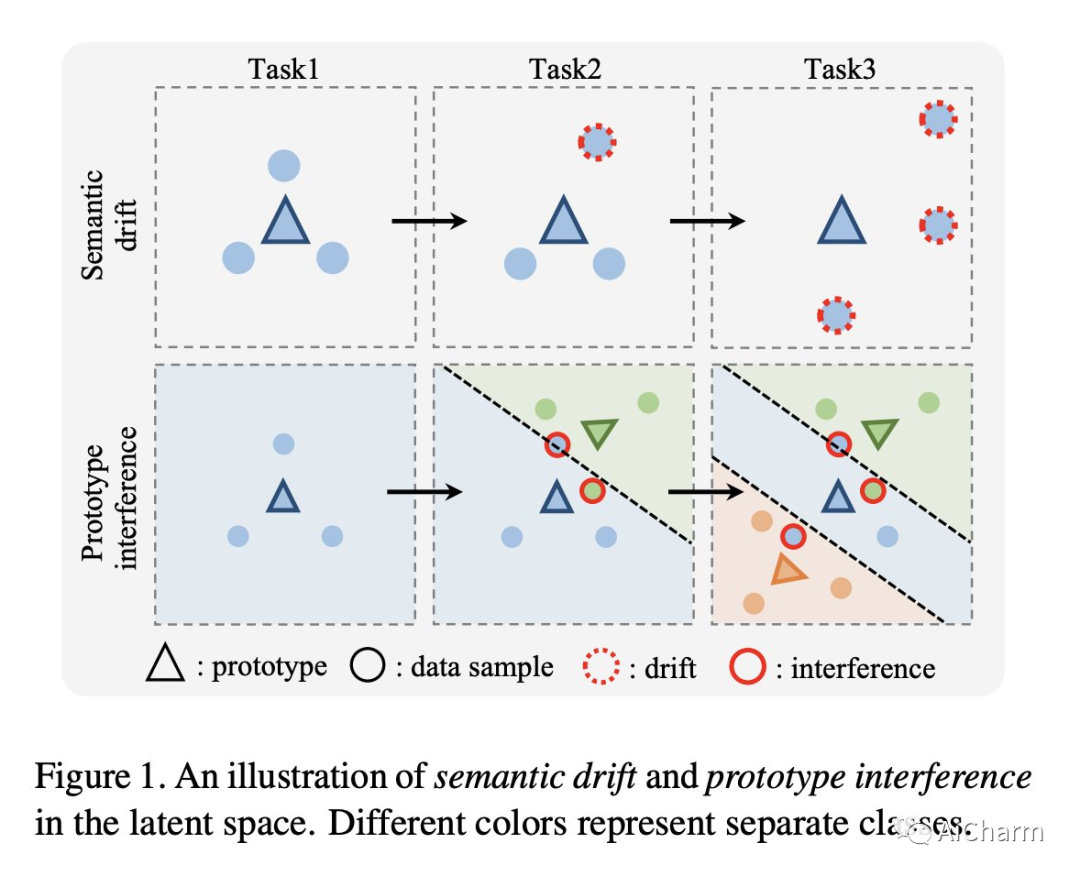
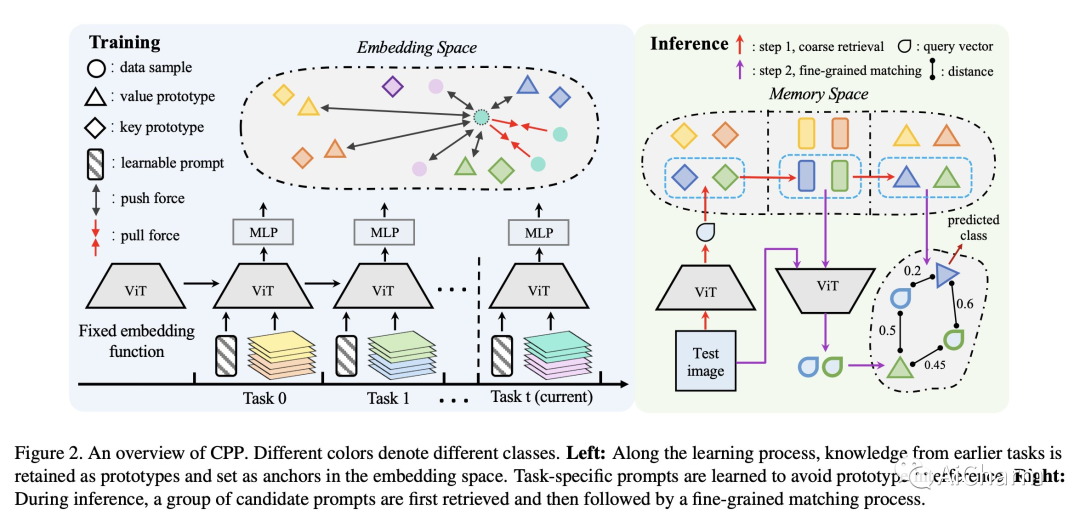
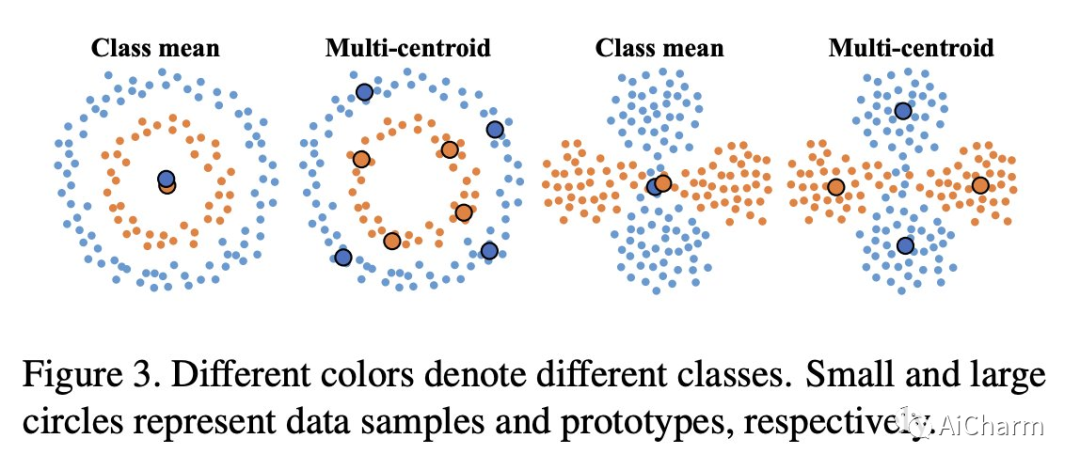
原型作为类嵌入的表示,已被探索用于减少内存占用或减轻持续学习场景的遗忘。然而,基于原型的方法仍然会因语义漂移和原型干扰而导致性能突然下降。在这项研究中,我们提出了对比原型提示 (CPP),并表明特定于任务的提示调整在针对对比学习目标进行优化时,可以有效地解决这两个障碍并显着提高原型的效力。我们的实验表明,CPP 在四个具有挑战性的类增量学习基准测试中表现出色,与最先进的方法相比,绝对改进了 4% 到 6%。此外,CPP 不需要排练缓冲区,它在很大程度上弥合了持续学习和离线联合学习之间的性能差距,展示了在 Transformer 架构下持续学习系统的有前途的设计方案。
Subjects: cs.CV
1.Erasing Concepts from Diffusion Models
标题:从扩散模型中删除概念
作者:Rohit Gandikota, Joanna Materzynska, Jaden Fiotto-Kaufman, David Bau
文章链接:https://arxiv.org/abs/2303.07345
项目代码:https://erasing.baulab.info/

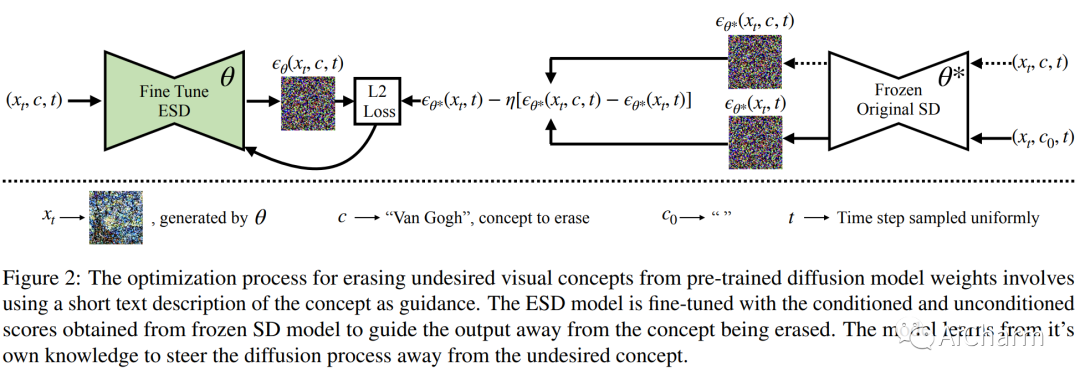
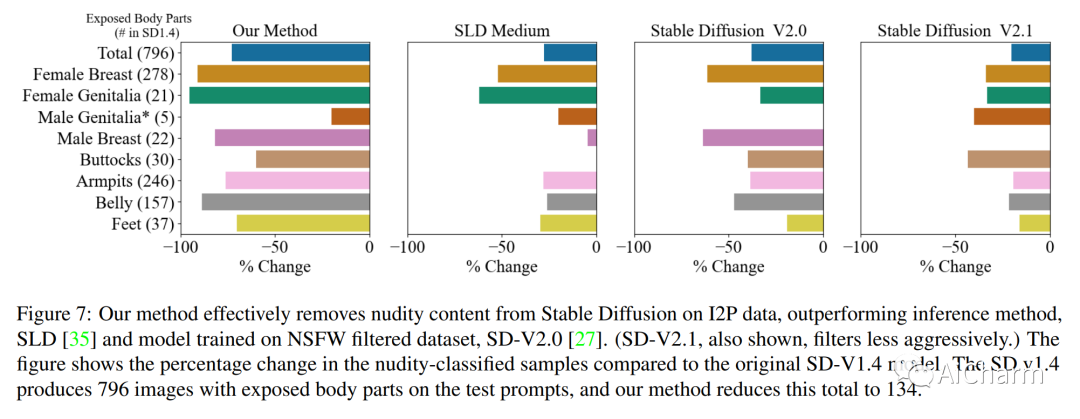
受文本到图像扩散的最新进展的推动,我们研究了模型权重中特定概念的擦除。尽管 Stable Diffusion 在制作明确或逼真的艺术作品方面显示出希望,但它引起了人们对其滥用可能性的担忧。我们提出了一种微调方法,可以从预训练的扩散模型中删除视觉概念,只给出风格的名称并使用负指导作为老师。我们将我们的方法与以前的方法进行了基准测试,这些方法删除了露骨的色情内容并证明了其有效性,其性能与安全潜在扩散和审查培训相当。为了评估艺术风格的移除,我们进行了从网络中删除五位现代艺术家的实验,并进行了一项用户研究以评估人类对删除风格的感知。与以前的方法不同,我们的方法可以从扩散模型中永久删除概念,而不是在推理时修改输出,因此即使用户可以访问模型权重也无法规避
2.ViperGPT: Visual Inference via Python Execution for Reasoning
标题:ViperGPT:通过 Python 执行进行推理的视觉推理
作者:Dídac Surís, Sachit Menon, Carl Vondrick
文章链接:https://arxiv.org/abs/2303.08128
项目代码:https://github.com/cvlab-columbia/viper

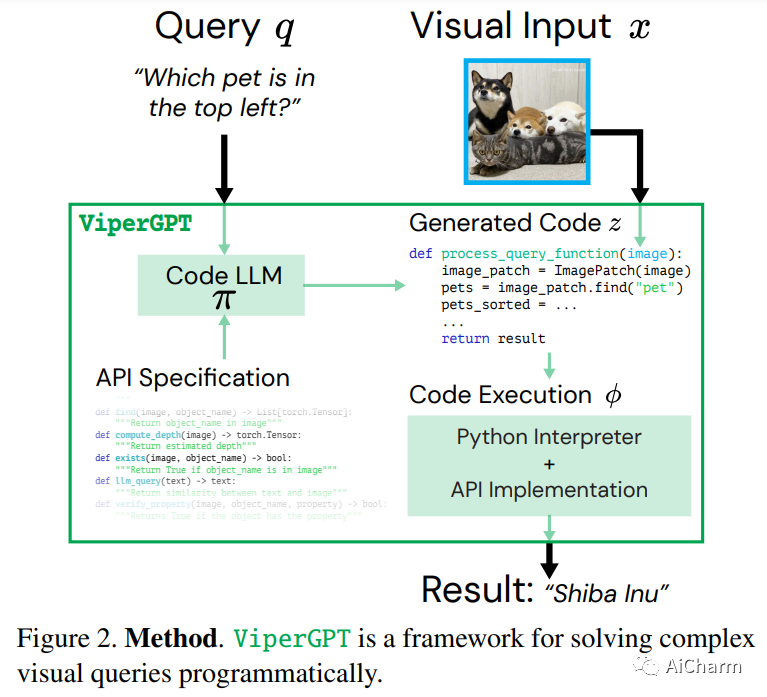

回答视觉查询是一项复杂的任务,需要视觉处理和推理。端到端模型是这项任务的主要方法,没有明确区分这两者,限制了可解释性和泛化性。学习模块化程序是一种很有前途的选择,但由于难以同时学习程序和模块,因此已被证明具有挑战性。我们介绍了 ViperGPT,这是一个利用代码生成模型将视觉和语言模型组合成子例程以生成任何查询结果的框架。ViperGPT 利用提供的 API 访问可用模块,并通过生成稍后执行的 Python 代码来组合它们。这种简单的方法不需要进一步的培训,并在各种复杂的视觉任务中取得了最先进的结果。
3.FreeNeRF: Improving Few-shot Neural Rendering with Free Frequency Regularization(CVPR 2023)
标题:FreeNeRF:使用自由频率正则化改进小样本神经渲染
作者:Jiawei Yang, Marco Pavone, Yue Wang
文章链接:https://arxiv.org/abs/2303.07418
项目代码:https://github.com/Jiawei-Yang/FreeNeRF

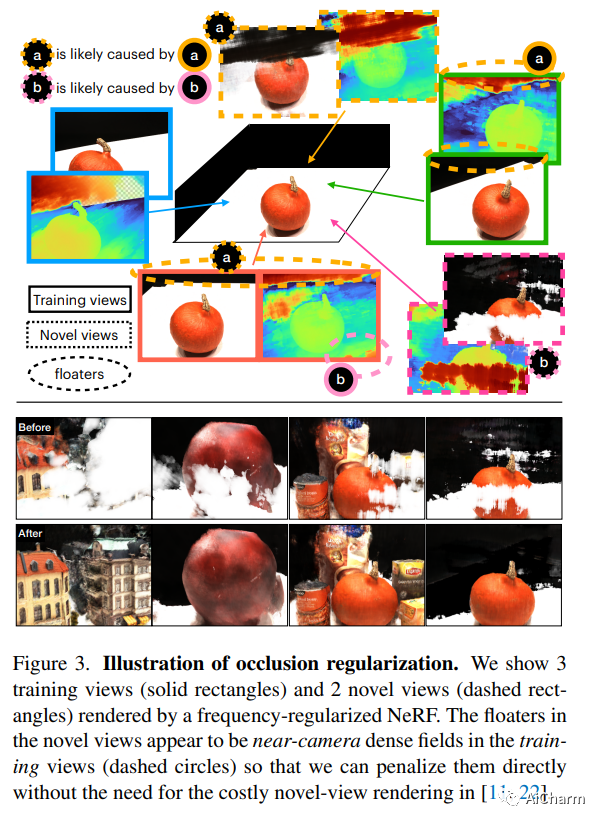
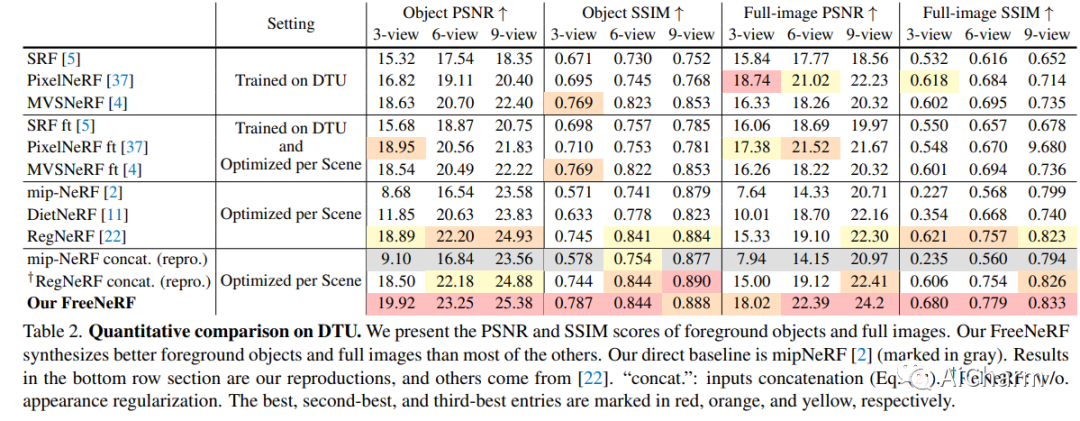
具有稀疏输入的新型视图合成是神经辐射场 (NeRF) 的一个具有挑战性的问题。最近的努力通过引入外部监督(例如预训练模型和额外深度信号)以及基于非平凡补丁的渲染来缓解这一挑战。在本文中,我们介绍了频率正则化 NeRF (FreeNeRF),这是一个非常简单的基线,它优于以前的方法,对普通 NeRF 的修改最少。我们分析了少样本神经渲染中的关键挑战,发现频率在 NeRF 的训练中起着重要作用。基于分析,我们提出了两个正则化项。一种是规范 NeRF 输入的频率范围,另一种是惩罚近相机密度场。这两种技术都是“免费午餐”,无需额外的计算成本。我们证明即使更改一行代码,原始 NeRF 也可以在少样本设置中实现与其他复杂方法相似的性能。FreeNeRF 在包括 Blender、DTU 和 LLFF 在内的各种数据集上实现了最先进的性能。我们希望这个简单的基线能够激发人们重新思考频率在低数据制度及以后的 NeRF 训练中的基本作用。
4.LERF: Language Embedded Radiance Fields
标题:LERF:语言嵌入辐射场
作者:Justin Kerr, Chung Min Kim, Ken Goldberg, Angjoo Kanazawa, Matthew Tancik
文章链接:https://arxiv.org/abs/2303.09553
项目代码:https://www.lerf.io/

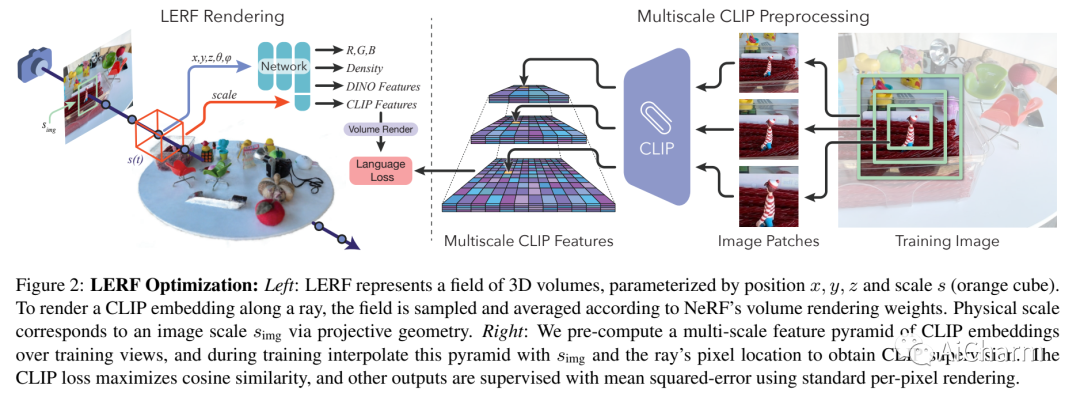
人类使用自然语言来描述物理世界,以指代基于大量属性的特定 3D 位置:视觉外观、语义、抽象关联或可操作的可供性。在这项工作中,我们提出了语言嵌入辐射场 (LERF),这是一种将语言嵌入从现成模型(如 CLIP)嵌入到 NeRF 中的方法,它可以在 3D 中实现这些类型的开放式语言查询。LERF 通过沿训练射线的体积渲染 CLIP 嵌入来学习 NeRF 内部的密集、多尺度语言场,跨训练视图监督这些嵌入以提供多视图一致性并平滑底层语言场。优化后,LERF 可以实时交互地为广泛的语言提示提取 3D 相关图,这在机器人技术、理解视觉语言模型以及与 3D 场景交互方面具有潜在的用例。LERF 在不依赖区域提议或掩码的情况下,支持对提取的 3D CLIP 嵌入进行像素对齐、零样本查询,支持跨卷分层的长尾开放词汇查询。
5.Unified Visual Relationship Detection with Vision and Language Models
标题:视觉和语言模型的统一视觉关系检测
作者:Long Zhao, Liangzhe Yuan, Boqing Gong, Yin Cui, Florian Schroff, Ming-Hsuan Yang, Hartwig Adam, Ting Liu
文章链接:https://arxiv.org/abs/2303.08998
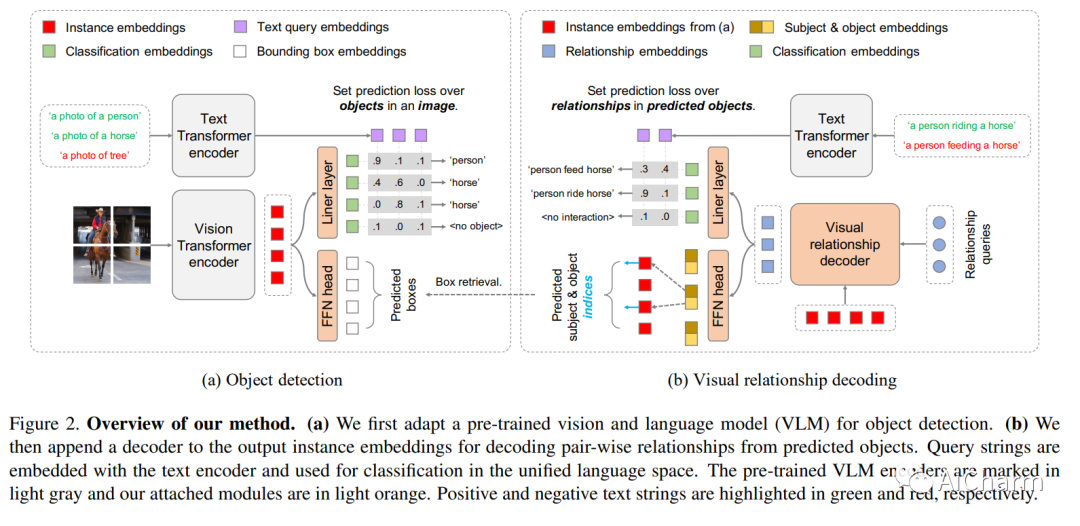
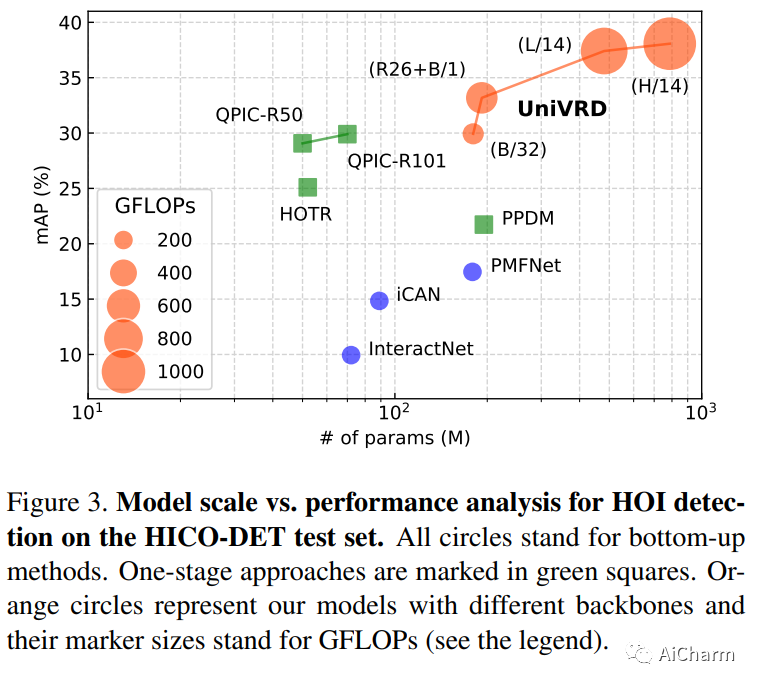

这项工作的重点是训练一个单一的视觉关系检测器来预测来自多个数据集的标签空间的联合。由于分类不一致,合并跨越不同数据集的标签可能具有挑战性。当在对象对之间引入二阶视觉语义时,视觉关系检测中的问题会加剧。为了应对这一挑战,我们提出了 UniVRD,这是一种利用视觉和语言模型 (VLM) 进行统一视觉关系检测的新型自下而上方法。VLM 提供对齐良好的图像和文本嵌入,其中相似的关系被优化为彼此接近以实现语义统一。我们自下而上的设计使模型能够享受到对象检测和视觉关系数据集训练的好处。人机交互检测和场景图生成的实证结果证明了我们模型的竞争性能。UniVRD 在 HICO-DET 上实现了 38.07 mAP,比目前最好的自底向上 HOI 检测器相对高出 60%。更重要的是,我们展示了我们的统一检测器在 mAP 中的性能与特定于数据集的模型一样好,并且在我们扩展模型时实现了进一步的改进。
6.FateZero: Fusing Attentions for Zero-shot Text-based Video Editing
标题:FateZero:融合注意力以进行基于文本的零镜头视频编辑
作者:Chenyang Qi, Xiaodong Cun, Yong Zhang, Chenyang Lei
文章链接:https://arxiv.org/abs/2303.08998
项目代码:https://github.com/chenyangqiqi/fatezero

基于扩散的生成模型在基于文本的图像生成中取得了显着的成功。然而,由于它在生成过程中包含巨大的随机性,因此将此类模型应用于现实世界的视觉内容编辑仍然具有挑战性,尤其是在视频中。在本文中,我们提出了 FateZero,这是一种针对真实世界视频的基于文本的零镜头编辑方法,无需按提示训练或使用特定掩码。为了一致地编辑视频,我们提出了几种基于预训练模型的技术。首先,与直接的 DDIM 反演技术相比,我们的方法在反演期间捕获中间注意力图,从而有效地保留结构和运动信息。这些地图在编辑过程中直接融合,而不是在去噪过程中生成。为了进一步减少源视频的语义泄漏,我们随后将自注意力与通过源提示中的交叉注意力特征获得的混合掩码融合在一起。此外,我们通过引入时空注意力来确保帧的一致性,从而对 UNet 降噪中的自注意力机制进行了改革。简而言之,我们的方法是第一个展示零镜头文本驱动视频风格和来自训练有素的文本到图像模型的局部属性编辑能力的方法。我们还有更好的基于文本到视频模型的零样本形状感知编辑能力。广泛的实验证明了我们比以前的作品更优越的时间一致性和编辑能力。
Notable Papers
1.Unifined Multi-Modal Latent Diffusion for Joint Subject and Text Conditional Image Generatio
标题:用于联合主题和文本条件图像生成的统一多模态潜在扩散
文章链接:https://arxiv.org/abs/2303.09319
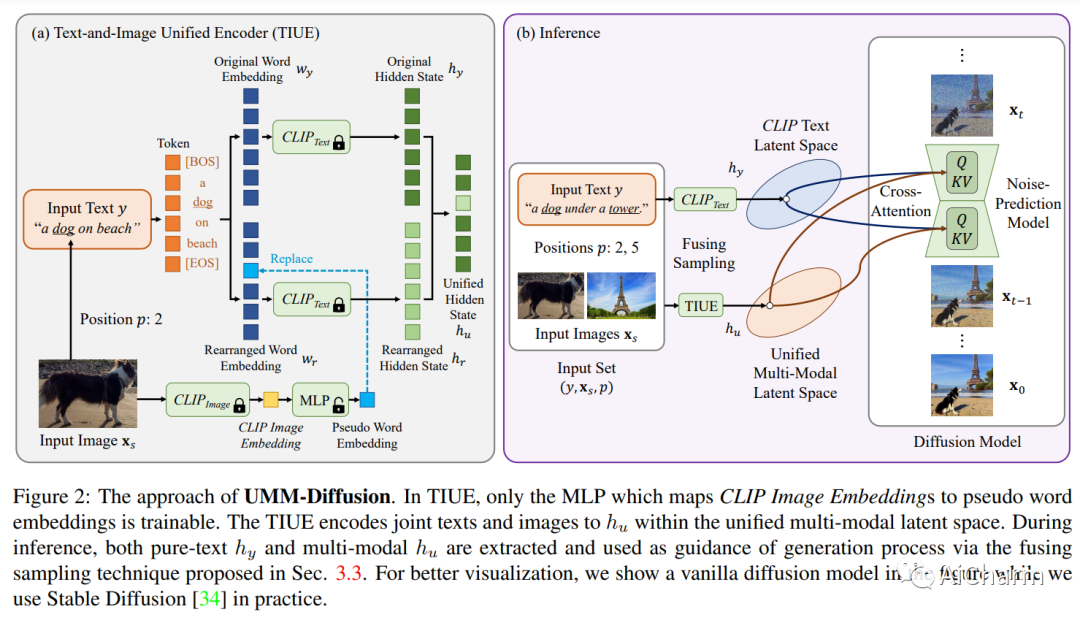
摘要:
如今,通过使用扩散模型,语言引导的图像生成取得了巨大的成功。然而,文本可能不够详细以描述高度具体的主题,例如特定的狗或特定的汽车,这使得纯文本到图像的生成不够准确,无法满足用户需求。在这项工作中,我们提出了一种新颖的统一多模态潜在扩散(UMM-Diffusion),它将包含指定主题的联合文本和图像作为输入序列,并生成带有主题的自定义图像。更具体地说,输入文本和图像都被编码到一个统一的多模态潜在空间中,其中输入图像被学习投影到伪词嵌入,并可以进一步与文本结合以指导图像生成。此外,为了消除输入图像的不相关部分,如背景或光照,我们提出了一种新的图像生成器使用的扩散模型采样技术,该技术融合了多模态输入和纯文本输入引导的结果。通过利用大规模预训练的文本到图像生成器和设计的图像编码器,我们的方法能够从输入文本和图像的两个方面生成具有复杂语义的高质量图像。
2.MeshDiffusion: Score-based Generative 3D Mesh Modeling(ICLR 2023)
标题:MeshDiffusion:基于分数的生成 3D 网格建模
文章链接:https://arxiv.org/abs/2303.08133


摘要:
我们考虑生成逼真的 3D 形状的任务,这对于自动场景生成和物理模拟等各种应用非常有用。与体素和点云等其他 3D 表示相比,网格在实践中更受欢迎,因为 (1) 它们可以轻松随意地操纵形状以进行重新照明和模拟,以及 (2) 它们可以充分利用现代图形管道的强大功能主要针对网格进行了优化。以前用于生成网格的可扩展方法通常依赖于次优的后处理,并且它们往往会产生过于光滑或嘈杂的表面,而没有细粒度的几何细节。为了克服这些缺点,我们利用网格的图形结构,使用一种简单但非常有效的生成建模方法来生成 3D 网格。具体来说,我们用可变形四面体网格表示网格,然后在这种直接参数化上训练扩散模型。我们展示了我们的模型在多个生成任务上的有效性。3.Mesh Strikes Back: Fast and Efficient Human Reconstruction from RGB videos
标题:Mesh Strikes Back:从 RGB 视频快速高效地重建人体
文章链接:https://arxiv.org/abs/2303.0880


摘要:
由于服装、遮挡、纹理不连续性和锐度以及特定于帧的姿势变化,单眼 RGB 视频的人体重建和合成是一个具有挑战性的问题。许多方法采用延迟渲染、NeRF 和隐式方法来表示穿着衣服的人,前提是基于网格的表示不能单独从 RGB、轮廓和关键点捕获复杂的衣服和纹理。我们通过优化 SMPL+D 网格和仅使用 RGB 图像、二进制轮廓和稀疏 2D 关键点的高效多分辨率纹理表示,为这一基本前提提供了一个反观点。实验结果表明,与视觉船体、基于网格的方法相比,我们的方法更能够捕获几何细节。与基于 NeRF 的方法相比,我们展示了具有竞争力的新视图合成和新姿势合成的改进,后者引入了明显的、不需要的伪影。通过将解决方案空间限制为结合可微分渲染的 SMPL+D 模型,我们在计算、训练时间(高达 24 倍)和推理时间(高达 192 倍)方面获得了显着的加速。因此,我们的方法可以按原样使用,也可以作为对基于 NeRF 的方法的快速初始化。
更多Ai资讯:公主号AiCharm
相关文章:
AI_Papers周刊:第六期
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理 2023.03.13—2023.03.19 文摘词云 Top Papers Subjects: cs.CL 1.UPRISE: Universal Prompt Retrieval for Improving Zero-Shot Evaluation 标题:UPRISE:改进零样本评估…...

JS运行环境、包管理、打包工具总结
🌳JS运行环境-node.js 运行环境就是代码解析和执行的程序,比如jvm等虚拟机,他们的主要工作就是根据设定的语法规则解析编译代码,然后运行代码。 js的语法规则遵循ES规范。 🍁node.js Node.Js官网 Node.js是一种基于Ch…...

day4网络编程(广播和组播)
1.广播 发送端(类似于客户端) 流程: 创建套接字 填充接收端(服务器)网络信息结构体 bind(非必须绑定) 设置允许广播 向接收端(服务器)发送数据 关闭套接字文件 #include <stdio.h> #in…...

Vue3 自动引入组件及函数、动态生成侧边栏路由
Vue3 自动引入组件及函数、动态生成侧边栏路由 1、安装依赖 npm install -D unplugin-auto-import unplugin-icons unplugin-vue-components插件使用说明 unplugin-auto-import 说明 —— 自动引入函数、组件 unplugin-vue-components 说明 —— 自动注册组件 unplugin-ic…...

人工智能交互系统界面设计
文章目录前言一、项目介绍二、项目准备三、项目实施1.导入相关库文件2.人脸信息验证功能3.语音交互与TCP数据通信4.数据信息可视化四、相关附件前言 在现代信息化时代,图形化用户界面(Graphical User Interface, GUI)已经成为各种软件应用和…...
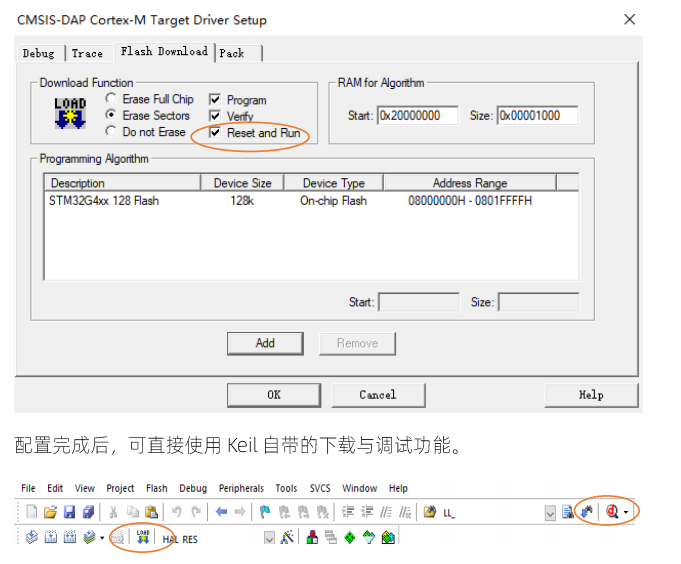
蓝桥杯嵌入式第一课--创建工程
概述学习本节之前,必须要先安装好 keil5 以及 CubeMX 等软硬件环境,如果你已经安装完成,请告诉自己:考试现在开始!从CubeMX开始CubeMX是创建工程模板的软件,也是我们比赛时第一个要进行操作的软件。一、选择…...

Java面向对象:接口的学习
本文介绍了Java中接口的基本语法, 什么是接口, java中的接口 语法规则, 接口的使用,接口的特性,如何实现多个接口,接口间的继承,以及抽象类和接口的区别 Java接口的学习一.接口的概念二.Java中的接口1.接口语法规则2.接口的使用3.接口的特性4.实现多个接口5.接口间的继承三.抽象…...

西瓜视频登录页面
题目 代码 <!DOCTYPE html> <html><head><meta charset"utf-8"><title>登录页面</title><style>td{width: 160px;height: 25px;}img{width: 20px;height: 20px;}.number, .password{background: rgba(0,0,0,.05);}.numbe…...

【springboot】常用快捷键:
Ctrl快捷键介绍Ctrl F在当前文件进行文本查找 (必备)Ctrl R在当前文件进行文本替换 (必备)Ctrl Z撤销 (必备)Ctrl Y删除光标所在行 或 删除选中的行 (必备)Ctrl X剪切光标所在行…...

宝塔控制面板常用Linux命令大全
宝塔面板是站长朋友们常见的一款服务器运维面板,可以通过 Web 端轻松管理服务器,提升运维效率。大家在服务器中安装宝塔面板会用到宝塔面板特定的脚本命令。今天这篇文章为大家整理汇总了宝塔面板常用Linux命令,这样方便大家收藏查找。 1、安…...
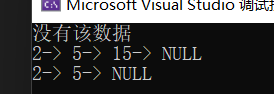
C语言实现单链表(超多配图,这下不得不学会单链表了)
目录 一:什么是链表? 二:创建源文件和头文件 (1)头文件 (2)源文件 三:实参和形参 四:一步步实现单向链表 (1)建立一个头指针并置空 (2)打印链表,便于…...
SQL编写优化技巧
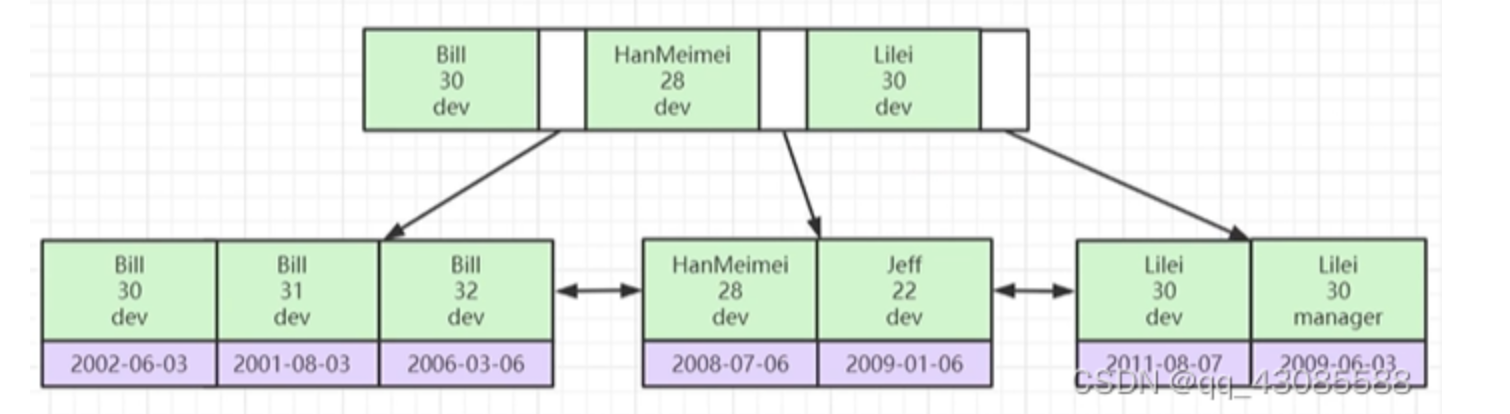
一、底层原理 sql慢是因为没有走索引,因此需要添加索引然它走索引联合索引需要匹配最左匹配原则(索引回表)如果查询列超出索引的key, 会导致回表,回表数量多,则会走全表扫描 索引是分聚集索引、非聚集索引…...
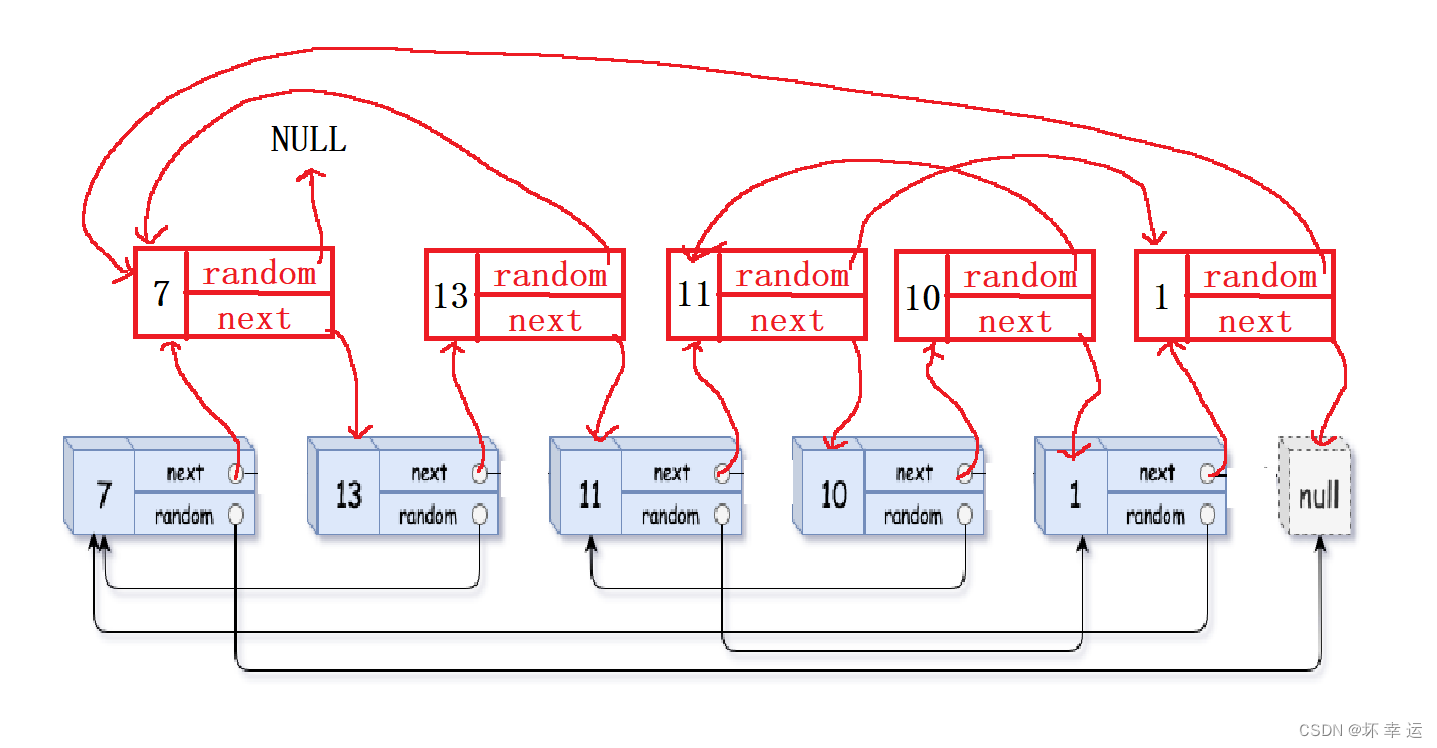
【基础算法】单链表的OJ练习(6) # 复制带随机指针的链表 #
文章目录🍇前言🍎复制带随机指针的链表🍑写在最后🍇前言 本章的链表OJ练习,是最后的也是最难的。对于本题,我们不仅要学会解题的思路,还要能够通过这个思路正确的写出代码,也就是思路…...

Activity生命周期完成EvenetLog回调
Activity 生命周期 系统EvenetLog回调 EventLog路径: Android13/frameworks/base/core/java/android/app/EventLogTags.logtags wm_on_create_called wm_on_restart_called wm_on_start_called wm_on_resume_called wm_on_top_resumed_gained_called wm_on_top_resumed_lost_c…...

西安石油大学C语言期末真题实战
很简单的一道程序阅读题,pa’默认为a【0】,接下来会进行3次循环 0 1 2 输出结果即可 前3题就是一些基础定义,在此不多赘述 要注意不同的数据类型的字节数不同 a<<2 b>>1(b>>1;就是说b自身右位移一位(…...

【Shell】Shell变量
Shell变量系统预定义变量自定义变量基本语法定义变量撤销变量命名规则使用变量只读变量删除变量变量类型系统预定义变量 $HOME、$PWD、$SHELL、$SUSER等 实例 yysubuntu:~$ echo $HOME #查看系统变量的值 /home/yys yysubuntu:~$ set #显示当前shell中所有变量自定义变量…...
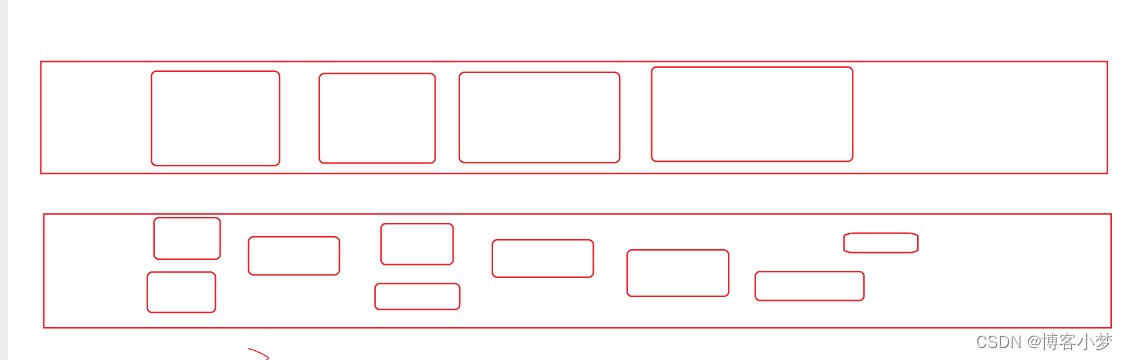
你是真的“C”——结构体中鲜有人知的“秘密”
你是真的“C”——结构体中的精髓剖析【内存对齐】 【位段】 😎前言🙌结构体内存对齐:😊结构体内存对齐存在的意思是什么?😘内存对齐例子详细剖析:😘结构体中的位段:&…...
)
2023年“网络安全”赛项江苏省淮安市赛题解析(超详细)
2023年中职组江苏省淮安市“网络空间安全”赛项 ①.2023年中职组江苏省淮安市任务书②.2023年中职组江苏省淮安市解析③.需要环境或者不懂的可以私信博主!①.2023年中职组江苏省淮安市任务书 任务一:服务器内部信息获取 任务环境说明: 服务器场景:Server210510(关闭链接…...

【二分查找】
二分查找704. 二分查找35. 搜索插入位置34. 在排序数组中查找元素的第一个和最后一个位置结语704. 二分查找 给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在…...
Vue学习 -- 如何用Axios发送请求(get post)Promise对象 跨域请求问题
什么是Axios Vue本身是不支持发送axios请求,需要使用第三方插件,这里推荐使用Axios,Axios是基于promise的HTTP库;它会从浏览器中创建XMLHttpRequset对象。 安装Axios npm install axios -S下载后把axios.js文件复制进项目目录 …...

基于卷积神经网络的忍者像素绘卷风格迁移:从原理到实战部署
基于卷积神经网络的忍者像素绘卷风格迁移:从原理到实战部署 1. 引言:当AI遇见像素艺术 想象一下,你手头有一张普通的照片,但希望它能变成复古游戏里的忍者像素风格——就像那些经典的街机游戏画面。这听起来像是需要专业美术师才…...

打造掌机媒体中心:wiliwili跨设备播放全攻略
打造掌机媒体中心:wiliwili跨设备播放全攻略 【免费下载链接】wiliwili 专为手柄控制设计的第三方跨平台B站客户端,目前可以运行在PC全平台、PSVita、PS4 和 Nintendo Switch上 项目地址: https://gitcode.com/GitHub_Trending/wi/wiliwili 在移动…...

Qt跨平台即时通讯实战:从界面设计到TCP通信的完整实现
1. Qt跨平台即时通讯开发概述 用Qt框架开发即时通讯软件最大的优势就是"一次编写,到处运行"。我去年接手过一个项目,需要在Windows和Linux双平台上部署聊天工具,当时尝试过多种技术方案,最终Qt以绝对优势胜出。想象一下…...

突发!国行苹果 AI 凌晨偷跑又紧急下线
3 月 31 日凌晨,大量升级 iOS 26.4 的国行 iPhone 16 及后续机型用户,突然发现设置里 “Siri” 变成 “Apple 智能与 Siri”,可下载 9.5GB 本地 AI 模型,解锁实时翻译、视觉智能、照片消除等全套功能。不过这场“惊喜”仅持续了数…...
)
别再手动敲命令了!用PyCharm自带功能一键创建Linux桌面快捷方式(附手动配置备份方案)
告别终端:PyCharm内置工具3秒生成Linux桌面快捷方式(附应急手动方案) 每次打开PyCharm都要在终端输入一长串路径?作为开发者,我们的时间应该花在创造价值上,而不是重复输入命令。JetBrains早就为Linux用户准…...

快手数据采集引擎:无水印解析与多源内容整合工具
快手数据采集引擎:无水印解析与多源内容整合工具 【免费下载链接】kuaishou-crawler As you can see, a kuaishou crawler 项目地址: https://gitcode.com/gh_mirrors/ku/kuaishou-crawler 价值定位:重新定义短视频数据采集标准 在数字内容分析与…...
)
别再手动整理了!用Python脚本5分钟搞定ImageNet验证集标签映射(附完整代码)
5分钟极速搞定ImageNet验证集标签映射:Python自动化实战指南 每次处理ImageNet验证集时,你是否也对着那些晦涩的数字标签头疼不已?手动查表不仅效率低下,还容易出错。今天我们就来彻底解决这个痛点——用Python脚本自动完成标签映…...

终极网盘下载加速方案:3分钟解锁八大平台极速下载
终极网盘下载加速方案:3分钟解锁八大平台极速下载 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘…...

seo公司招聘的实习机会有哪些
SEO公司招聘的实习机会有哪些? 在当今数字化时代,SEO(搜索引擎优化)已经成为企业在网络上获得高流量和高曝光度的关键手段。随着越来越多的企业意识到SEO的重要性,SEO公司也在不断扩展,吸引大量优秀的实习…...

革新性图表创作:Mermaid Live Editor如何重构技术可视化工作流
革新性图表创作:Mermaid Live Editor如何重构技术可视化工作流 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending/me/mermaid-liv…...