Spark+实例解读
第一部分 Spark入门
学习教程:Spark 教程 | Spark 教程
Spark 集成了许多大数据工具,例如 Spark 可以处理任何 Hadoop 数据源,也能在 Hadoop 集群上执行。大数据业内有个共识认为,Spark 只是Hadoop MapReduce 的扩展(事实并非如此),如Hadoop MapReduce 中没有的迭代查询和流处理。然而Spark并不需要依赖于 Hadoop,它有自己的集群管理系统。更重要的是,同样数据量,同样集群配置,Spark 的数据处理速度要比 Hadoop MapReduce 快10倍左右。
Spark 的一个关键的特性是数据可以在内存中迭代计算,提高数据处理的速度。虽然Spark是用 Scala开发的,但是它对 Java、Scala、Python 和 R 等高级编程语言提供了开发接口。
第二部分 SparkCore
2 RDD
2.1 转换算子-map
map是将RDD的数据一条条处理,返回新的RDD
# 定义方法
def add(data):return data*10
print(rdd.map(add).collect)
# 定义lamabda表达式
rdd.map(lambda data:data*10)2.2 转换算子-flatMap
flatMap对RDD执行map操作,然后执行解除嵌套操作
rdd = sc.parallelize([('a',1),('a',11)])
# 将二元元组的所有value都*10进行处理
rdd.mapValues(lambda x:x*10) data.map { case (label, feature) => ((feature, label), 1)}.reduceByKey(_ + _).map { case ((feature, label), num) =>(feature, List((label, num))) //feature,label,cnt}.reduceByKey(_ ::: _).mapValues { x =>val size_entro = x.map(_._2).sumval res = x.map(_._2.toDouble / size_entro).map { t =>-t * (Math.log(t) / Math.log(2))}.sumsize_entro * res}.mapValues { x => x / size }.map(_._2).sum2.3转换算子-reduceByKey
针对KV型RRDD自动按照key进行分组,然后按照提供的聚合逻辑,对组内数据value完成聚合操作
rdd.reduceByKey(func)
val clickStat = joinDf.where(F.col("active_type")==="click").rdd.map(row => {val mapInfo = Option(row.getMap[String,Double](row.fieldIndex(feat)))mapInfo match {case Some(x) => xcase _ => null}}).filter(_!=null).flatMap(x=>x).reduceByKey(_+_)
2.4 转换算子-mapValues
针对二元元组RDD,对其内部的二元元组的value进行map操作
rdd = sc.parallelize([('a',1),('a',11)])
# 将二元元组的所有value都*10进行处理
rdd.mapValues(lambda x:x*10)
data.map { case (label, feature) => ((feature, label), 1)}.reduceByKey(_ + _).map { case ((feature, label), num) =>(feature, List((label, num))) //feature,label,cnt}.reduceByKey(_ ::: _).mapValues { x =>val size_entro = x.map(_._2).sumval res = x.map(_._2.toDouble / size_entro).map { t =>-t * (Math.log(t) / Math.log(2))}.sumsize_entro * res}.mapValues { x => x / size }.map(_._2).sum
2.5 转换算子-groupBy
将RDD的数据进行分组
rdd.groupBy(func)
rdd = sc.parallelize([('a',1),('a',11),('b',1)])
# 通过这个函数确认按照谁来分组(返回谁即可)
print(rdd.groupBy(lambda x:x[0]).collect())
print(rdd.groupBy(lambda x:x[0]).collect())
# 结果为:
val userContentListHis = spark.thriftSequenceFile(inpath_his, classOf[LongVideoUserContentStat]).map(l=>{(l.getUid,l.getContent_properties.get(0).getId)}).toDF("uid", "docid").groupBy($"uid")
2.6 转换算子-filter
过滤想要的数据进行保存
rdd = sc.parallelize([1,2,3,4,5,6]) rdd.filter(lamdba x:x%2 == 1) # 只保留奇数
val treatmentUser = spark.read.option("header", false).option("sep", "\t").csv(inpath).select("_c0").withColumnRenamed("_c0", "userid").withColumn("flow", getexpId($"userid")).filter($"flow" >= start and $"flow" <= end).select("userid").dropDuplicates()
2.7 转换算子-其他算子
distinct算子
rdd.distinct() 一般不写去重分区val userContentHis = hisPathList.map(path =>{val hisData = spark.thriftSequenceFile(path, classOf[LongVideoUserContentStat])println(s"hisData ==>${hisData.count()}")hisData}).reduce(_ union _).distinct().repartition(partition)
union算子 2个rdd合并成一个rdd:rdd.union(other_rdd) 只合并不去重 rdd的类型不同也是可以合并的 rdd1 = sc.parallelize([1,2,3]) rdd2 = sc.parallelize([1,2,3,4]) rdd3 = rdd1.union(rdd2)
2.8 算子面试题
1.groupByKey和reduceByKey的区别: groupByKey仅仅有分组功能而已,reduceByKey除了分组还有聚合作用,是一个分组+聚合一体化的算子. 分组前先聚合再shuffle,预聚合,被shuffle的数据极大的减少,提升了性能.数据量越大,reduceByKey的性能优势也就越大. 2.rdd的分区数怎么查看? 通过getNumPartitions API查看,返回int 3.Transformation和Action的区别: 转换算子的返回值100%是rdd,而Action算子不一定.转换算子是懒加载的,只有遇到Action才会执行 4.哪两个算子不经过Driver直接输出? foreach 和 saveAsTextFile
3 RDD的持久化
3.1 RDD的持久化
rdd是过程数据 rdd进行相互迭代计算,执行开启时,新的RDD生成,老的RDD消失

3.2 RDD的缓存

val rawLog = profilePushLogReader(spark, date, span).persist()
3.3 RDD的checkPoint
也是将RDD的数据保存起来,仅支持磁盘存储,被认为是安全的, 不保留血缘关系


3.4 缓存面试题

4 案例
4.1 搜素引擎日志分析案例
4.2
4.3 ....
4.4 计算资源面试题
1.如何尽量提升任务计算的资源? 计算cpu核心和内存量,通过--executor-memory指定executor内存,通过--executor-cores指定executor的核心数
5 广播变量 累加器
相关文章:
Spark+实例解读
第一部分 Spark入门 学习教程:Spark 教程 | Spark 教程 Spark 集成了许多大数据工具,例如 Spark 可以处理任何 Hadoop 数据源,也能在 Hadoop 集群上执行。大数据业内有个共识认为,Spark 只是Hadoop MapReduce 的扩展(…...

WPF多语言国际化,中英文切换
通过切换资源文件的形式实现中英文一键切换 在项目中新建Language文件夹,添加资源字典(xaml文件),中文英文各一个。 在资源字典中写上想中英文切换的字符串,需要注意,必须指定key值,并且中英文…...
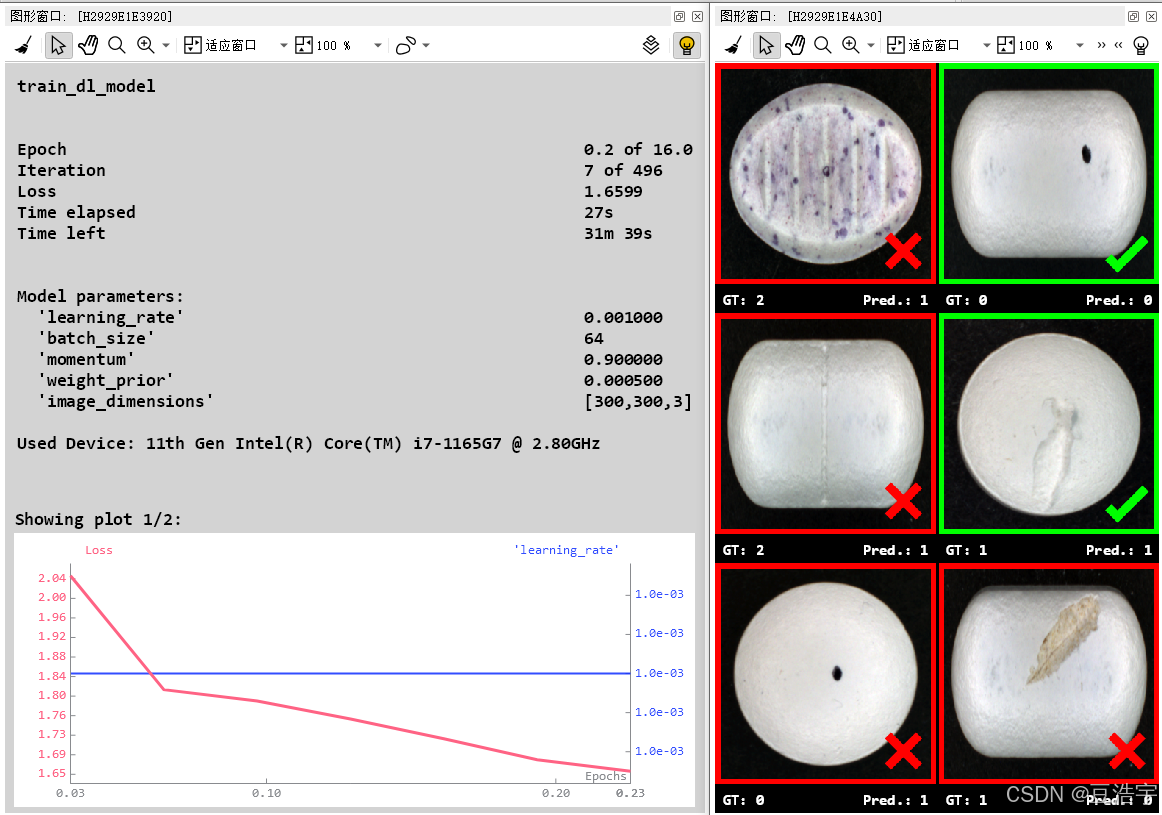
Halcon深度学习分类模型
1.Halcon20之后深度学习支持CPU训练模型,没有money买显卡的小伙伴有福了。但是缺点也很明显,就是训练速度超级慢,推理效果也没有GPU好,不过学习用足够。 2.分类模型是Halcon深度学习最简单的模型,可以用在物品分类&…...

洗地机哪种牌子好?洗地机排行榜前十名公布
洗地机市场上品牌琳琅满目,每个品牌都有其独特的魅力和优势。消费者在选择时,往往会根据自己的实际需求、预算以及对产品性能的期望来做出决策。因此,无论是哪个品牌的洗地机,只要能够满足用户的清洁需求,提供便捷的操…...

C++中的虚函数与多态机制如何工作?
在C中,虚函数和多态机制是实现面向对象编程的重要概念。 虚函数是在基类中声明的函数,可以在派生类中进行重写。当基类的指针或引用指向派生类的对象时,通过调用虚函数可以实现动态绑定,即在运行时确定要调用的函数。 多态是指通…...

《LeetCode热题100》---<哈希三道>
本篇博客讲解 LeetCode热题100道中的哈希篇中的三道题。分别是 1.第一道:两数之和(简单) 2.第二道:字母异位词分组(中等) 3.第三道:最长连续序列(中等) 第一道࿱…...
秒懂C++之string类(下)
目录 一.接口说明 1.1 erase 1.2 replace(最好别用) 1.3 find 1.4 substr 1.5 rfind 1.6 find_first_of 1.7 find_last_of 二.string类的模拟实现 2.1 构造 2.2 无参构造 2.3 析构 2.4.【】运算符 2.5 迭代器 2.6 打印 2.7 reserve扩容 …...
github简单地操作
1.调节字体大小 选择options 选择text 选择select 选择你需要的参数就可以了。 2.配置用户名和邮箱 桌面右键,选择git Bash Here git config --global user.name 用户名 git config --global user.email 邮箱名 3.用git实现代码管理的过程 下载别人的项目 git …...

模型改进-损失函数合集
模版 第一步在哪些地方做出修改: 228行 self.use_wiseiouTrue 230行 self.wiou_loss WiseIouLoss(ltypeMPDIoU, monotonousFalse, inner_iouTrue, focaler_iouFalse) 238行 wiou self.wiou_loss(pred_bboxes[fg_mask], target_bboxes[fg_mask], ret_iouFalse…...
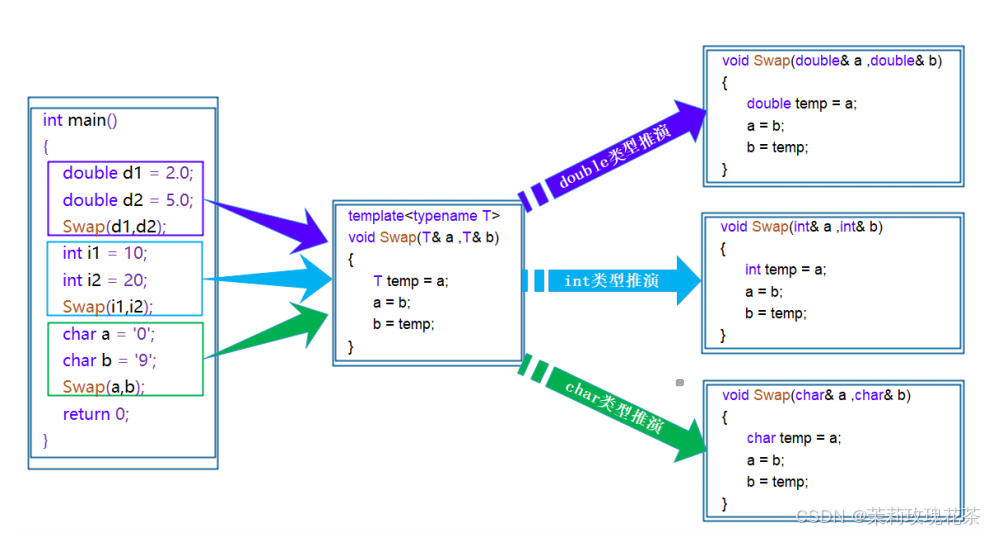
C++模板(初阶)
1.引入 在之前的笔记中有提到:函数重载(特别是交换函数(Swap)的实现) void Swap(int& left, int& right) {int temp left;left right;right temp; } void Swap(double& left, double& right) {do…...

下面关于Date类的描述错误的一项是?
下面关于Date类的描述错误的一项是? A. java.util.Date类下有三个子类:java.sql.Date、java.sql.Timestamp、java.sql.Time; B. 利用SimpleDateFormat类可以对java.util.Date类进行格式化显示; C. 直接输出Date类对象就可以取得日…...
【Python面试题收录】Python编程基础练习题①(数据类型+函数+文件操作)
本文所有代码打包在Gitee仓库中https://gitee.com/wx114/Python-Interview-Questions 一、数据类型 第一题(str) 请编写一个Python程序,完成以下任务: 去除字符串开头和结尾的空格。使用逗号(","&#…...
C# Nmodbus,EasyModbusTCP读写操作
Nmodbus读写 两个Button控件分别为 读取和写入 分别使用控件的点击方法 ①引用第三方《NModbus4》2.1.0版本 全局 public SerialPort port new SerialPort("COM2", 9600, Parity.None, 8, (StopBits)1); ModbusSerialMaster master; public Form1() port.Open();…...

spark常用参数调优
目录 1.set spark.grouping.sets.reference.hivetrue;2.set spark.locality.wait.rack0s3.set spark.locality.wait0s;4.set spark.executor.memoryOverhead 2G;5.set spark.sql.shuffle.partitions 1000;6.set spark.shuffle.file.buffer 256k7. set spark.reducer.maxSizeInF…...
C#/WinFrom TCP通信+ 网线插拔检测+客服端异常掉线检测
Winfor Tcp通信(服务端) 今天给大家讲一下C# 关于Tcp 通信部分,这一块的教程网上一大堆,不过关于掉网,异常断开连接的这部分到是到是没有多少说明,有方法 不过基本上最多的两种方式(1.设置一个超时时间,2.…...

一篇文章掌握Python爬虫的80%
转载:一篇文章掌握Python爬虫的80% Python爬虫 Python 爬虫技术在数据采集和信息获取中有着广泛的应用。本文将带你掌握Python爬虫的核心知识,帮助你迅速成为一名爬虫高手。以下内容将涵盖爬虫的基本概念、常用库、核心技术和实战案例。 一、Python 爬虫…...

【用户会话信息在异步事件/线程池的传递】
用户会话信息在异步事件/线程池的传递 author:shengfq date:2024-07-29 version:1.0 背景: 同事写的一个代码功能,是在一个主线程中通过如下代码进行异步任务的执行,结果遇到了问题. 1.ThreadPool.execute(Runnable)启动一个子线程执行异步任务 2.applicationContext.publis…...

Java8: BigDecimal
Java8:BigDecimal 转两位小数的百分数-CSDN博客 BigDecimal 先做除法 然后取绝对值 在Java 8中,如果你想要对一个BigDecimal值进行除法操作,并随后取其绝对值,你可以通过组合divide方法和abs方法来实现这一目的。不过,需要注意的…...

苹果推送iOS 18.1带来Apple Intelligence预览
🦉 AI新闻 🚀 苹果推送iOS 18.1带来Apple Intelligence预览 摘要:苹果向iPhone和iPad用户推送iOS 18.1和iPadOS 18.1开发者预览版Beta更新,带来“Apple Intelligence”预览。目前仅支持M1芯片或更高版本的设备。Apple Intellige…...

testRigor-基于人工智能驱动的无代码自动化测试平台
1、testRigor介绍 简单来说,testRigor是一款基于人工智能驱动的无代码自动化测试平台,它能够通过分析应用的行为模式,智能地生成测试用例,并自动执行这些测试,无需人工编写测试脚本。可以用于Web、移动、API和本机桌面…...
)
AI大模型选型生死线(2026企业级部署避坑指南)
更多请点击: https://intelliparadigm.com 第一章:AI大模型选型生死线(2026企业级部署避坑指南) 企业在2026年落地AI大模型时,选型失误的代价已远超算力采购成本——模型架构错配、上下文长度硬伤、商用许可证模糊、推…...

Davinci vs. 其他BI工具怎么选?从私有化部署和二次开发角度深度对比
Davinci vs. 主流BI工具技术选型指南:私有化部署与二次开发实战解析 当企业数据量突破TB级时,我们技术团队曾面临一个关键抉择:是继续支付每年六位数的商业BI服务费,还是转向可深度定制的开源方案?这个决策不仅关乎成本…...

从SPICE到Q-SPICE:四阶累积量如何重塑阵列信号处理的超分辨能力
1. 从SPICE到Q-SPICE:为什么我们需要四阶累积量? 我第一次接触SPICE算法是在处理雷达信号的时候。当时团队遇到一个头疼的问题:在强噪声环境下,传统算法就像近视眼观察星空,明明知道那里有信号,却怎么也分辨…...
)
STM32F4上跑FreeType:手把手教你为嵌入式GUI添加矢量字体(附源码)
STM32F4实战:FreeType矢量字体移植与GUI深度优化指南 1. 嵌入式矢量字体技术选型与原理 在资源受限的嵌入式环境中实现矢量字体渲染,本质上是一场内存效率与视觉质量的博弈。FreeType作为行业标准的字体引擎,其核心优势在于采用二次贝塞尔曲…...

告别轮询!用DSP28335 GPIO中断实现矩阵按键响应,效率提升实战指南
DSP28335 GPIO中断驱动矩阵按键:从轮询到事件驱动的实战重构 在嵌入式系统开发中,按键响应速度往往直接影响用户体验和系统实时性。传统轮询方式虽然实现简单,但在处理矩阵键盘时会导致CPU资源浪费和响应延迟。我曾在一个工业控制面板项目中&…...

告别并行接口:手把手教你用Stm32F4的SPI高效读取AD7606八通道数据
告别并行接口:手把手教你用Stm32F4的SPI高效读取AD7606八通道数据 在嵌入式系统设计中,AD7606作为一款高性能八通道16位ADC芯片,常被用于电力监测、工业控制等需要多通道高精度采样的场景。传统方案往往依赖其并行接口实现数据读取ÿ…...

USB枚举过程深度解析:主机是如何‘读懂’你的配置描述符的?
USB枚举过程深度解析:主机是如何‘读懂’你的配置描述符的? 当我们将一个USB设备插入电脑时,短短几秒钟内,主机和设备之间已经完成了数十次数据交换。这个过程被称为枚举(Enumeration),是USB协议…...

从图文对到通用视觉:CLIP如何用对比学习重塑多模态预训练范式
1. 从图文匹配到通用视觉:CLIP的颠覆性思路 第一次看到CLIP模型时,我正为一个老问题头疼:训练好的图像分类器遇到新类别就直接"罢工"。比如用猫狗数据集训练的模型,突然给它看一只考拉,结果只会输出"猫…...
 从零到一:跨平台安装全攻略)
Webots 机器人仿真平台(一) 从零到一:跨平台安装全攻略
1. Webots机器人仿真平台初探 第一次接触机器人仿真时,我和大多数新手一样茫然。市面上有Gazebo这样知名的仿真工具,但配置复杂得让人望而生畏。直到发现了Webots,这个开源的3D机器人仿真平台,才真正找到了适合初学者的入门利器。…...

Cursor编辑器集成Claude 3:AI双模型编程实战与成本优化指南
1. 项目概述:当AI代码助手遇上你的IDE 最近在开发者圈子里,一个名为“Cursor-Claude-Extension”的开源项目热度持续攀升。简单来说,它是一款为Cursor编辑器设计的扩展插件,核心功能是将Anthropic公司强大的Claude系列模型&#x…...