KubeSphere 部署向量数据库 Milvus 实战指南
作者:运维有术星主
Milvus 是一个为通用人工智能(GenAI)应用而构建的开源向量数据库。它以卓越的性能和灵活性,提供了一个强大的平台,用于存储、搜索和管理大规模的向量数据。Milvus 能够执行高速搜索,并以最小的性能损失扩展到数百亿向量。其分布式架构确保了系统的高可用性和水平可扩展性,满足不断增长的数据需求。同时,Milvus 提供了丰富的 API 和集成选项,使其成为机器学习、计算机视觉和自然语言处理等 AI 应用的理想选择。
随着 AI 大模型的兴起,Milvus 成为了众多 AI 应用的首选向量数据库。本文将引导您探索,如何在 KubeSphere 管理的 Kubernetes 集群上,高效地部署和管理 Milvus 集群,让您的应用能够充分利用 Milvus 的强大功能。
实战服务器配置(架构 1:1 复刻小规模生产环境,配置略有不同)
| 主机名 | IP | CPU | 内存 | 系统盘 | 数据盘 | 用途 |
|---|---|---|---|---|---|---|
| ksp-registry | 192.168.9.90 | 4 | 8 | 40 | 200 | Harbor 镜像仓库 |
| ksp-control-1 | 192.168.9.91 | 4 | 8 | 40 | 100 | KubeSphere/k8s-control-plane |
| ksp-control-2 | 192.168.9.92 | 4 | 8 | 40 | 100 | KubeSphere/k8s-control-plane |
| ksp-control-3 | 192.168.9.93 | 4 | 8 | 40 | 100 | KubeSphere/k8s-control-plane |
| ksp-worker-1 | 192.168.9.94 | 8 | 16 | 40 | 100 | k8s-worker/CI |
| ksp-worker-2 | 192.168.9.95 | 8 | 16 | 40 | 100 | k8s-worker |
| ksp-worker-3 | 192.168.9.96 | 8 | 16 | 40 | 100 | k8s-worker |
| ksp-storage-1 | 192.168.9.97 | 4 | 8 | 40 | 400+ | ElasticSearch/Longhorn/Ceph/NFS |
| ksp-storage-2 | 192.168.9.98 | 4 | 8 | 40 | 300+ | ElasticSearch/Longhorn/Ceph |
| ksp-storage-3 | 192.168.9.99 | 4 | 8 | 40 | 300+ | ElasticSearch/Longhorn/Ceph |
| ksp-gpu-worker-1 | 192.168.9.101 | 4 | 16 | 40 | 100 | k8s-worker(GPU NVIDIA Tesla M40 24G) |
| ksp-gpu-worker-2 | 192.168.9.102 | 4 | 16 | 40 | 100 | k8s-worker(GPU NVIDIA Tesla P100 16G) |
| ksp-gateway-1 | 192.168.9.103 | 2 | 4 | 40 | 自建应用服务代理网关/VIP:192.168.9.100 | |
| ksp-gateway-2 | 192.168.9.104 | 2 | 4 | 40 | 自建应用服务代理网关/VIP:192.168.9.100 | |
| ksp-mid | 192.168.9.105 | 4 | 8 | 40 | 100 | 部署在 k8s 集群之外的服务节点(Gitlab 等) |
| 合计 | 15 | 68 | 152 | 600 | 2100+ |
实战环境涉及软件版本信息
- 操作系统:openEuler 22.03 LTS SP3 x86_64
- KubeSphere:v3.4.1
- Kubernetes:v1.28.8
- KubeKey: v3.1.1
- Milvus Helm Charts:4.2.0
- Milvus: v.2.4.6
1. Milvus 部署规划
部署目标:官方架构图所示的 Milvus 集群(不包含 Load Balancer)。
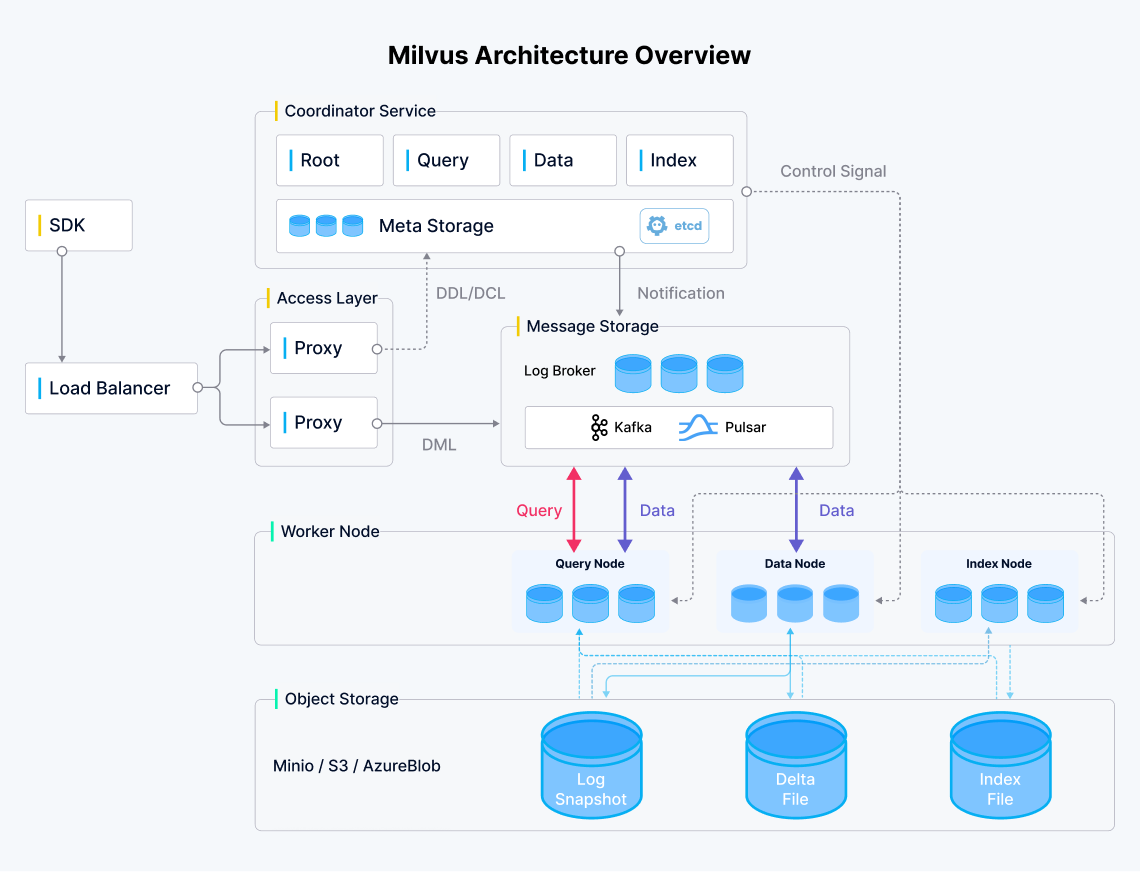
由于是初次安装部署,对 Milvus 的架构、组件关系仅有一个初步的了解,所以第一次部署只做如下考虑:
- 使用 Helm 的方式,大部分配置采用默认的 Values 部署
- 更改组件镜像地址为本地私有仓库
- 持久化存储使用自定义的 NFS 存储类
nfs-sc(生产不建议用,可能会造成磁盘 IO 不满足 etcd 的需求) - coordinators 没有选择 mixCoordinator,而是使用多个独立的 coordinators,这种方案运维成本高,维护麻烦
- 消息队列使用官方默认推荐的 pulsar,不选择 kafka
后续会深入研究,更正式的部署考虑:
- 使用 Helm 和自定义 values 生成部署资源清单,修改清单,使用原生 kubectl 方式部署
- 使用 Ceph 或是其它高性能存储,不使用 NFS 存储
- 消息队列继续使用官方推荐的 pulsar
- 使用社区官方推荐的包含所有 coordinators 的 mixCoordinator ,降低运维成本
- 合理规划 Minio、Etcd、pulsar 等组件使用持久化存储时所分配的存储空间,默认配置不可能满足所有场景
- Milvus 日志存储到持久化存储,适配没有集中日志采集能力的 k8s 集群
重要说明: 本文的内容对于安装部署 Milvus 有一定的借鉴意义,但切勿将本文的实战过程直接用于任何类型的正式环境。
2. 前置条件
以下内容来自 Milvus 官方环境需求文档,比较好理解,不做翻译了。
2.1 硬件需求
| Component | Requirement | Recommendation | Note |
|---|---|---|---|
| CPU | Intel 2nd Gen Core CPU or higherApple Silicon | Standalone: 4 core or moreCluster: 8 core or more | |
| CPU instruction set | SSE4.2AVXAVX2AVX-512 | SSE4.2AVXAVX2AVX-512 | Vector similarity search and index building within Milvus require CPU's support of single instruction, multiple data (SIMD) extension sets. Ensure that the CPU supports at least one of the SIMD extensions listed. See CPUs with AVX for more information. |
| RAM | Standalone: 8GCluster: 32G | Standalone: 16GCluster: 128G | The size of RAM depends on the data volume. |
| Hard drive | SATA 3.0 SSD or CloudStorage | NVMe SSD or higher | The size of hard drive depends on the data volume. |
2.2 软件需求
| Operating system | Software | Note |
|---|---|---|
| Linux platforms | Kubernetes 1.16 or laterkubectlHelm 3.0.0 or laterminikube (for Milvus standalone)Docker 19.03 or later (for Milvus standalone) | See Helm Docs for more information. |
| Software | Version | Note |
|---|---|---|
| etcd | 3.5.0 | See additional disk requirements. |
| MinIO | RELEASE.2023-03-20T20-16-18Z | |
| Pulsar | 2.8.2 |
2.3 磁盘需求
磁盘性能对 etcd 至关重要。官方强烈建议使用本地 NVMe SSD 磁盘。较慢的磁盘响应可能导致频繁的集群选举,最终降低 etcd 服务的性能,甚至是集群的崩溃。
这个需求比较重要,我刚接触 Milvus 时,由于时间比较仓促,在略知一二的情况下,使用默认配置部署了一套半生产的 Milvus 集群。
因为选择了 NFS 存储且没有测试磁盘 IO 性能,经常会出现 etcd 服务异常,响应慢,被 Kubernetes 的存活检测机制判断为不可用,导致频繁自动重建 etcd 集群。
因此,在 K8s 上创建 Milvus 集群时最好先测试一下集群持久化存储的性能。
Milvus 官方给出的测试磁盘性能的工具和命令如下:
mkdir test-data
fio --rw=write --ioengine=sync --fdatasync=1 --directory=test-data --size=2200m --bs=2300 --name=mytest测试结果,理想情况下,您的磁盘应该达到 500 IOPS 以上,99th percentile fsync latency 低于 10ms。请阅读 etcd 官方文档 了解更详细的需求。
具体的磁盘性能测试过程,请参考下文。
2.4 Kubernetes 集群配置
k8s 集群一定要配置默认存储类,Milvus 的 Helm 控制 storageClass 的参数不够灵活,最好直接使用默认存储类,简化配置。
3. 持久化存储性能测试
实战环境使用了自建的 NFS 存储,部署 Milvus 之前,先测试存储性能:
官方建议的测试工具是 fio ,为了在 K8s 中模拟测试,我选择了 openEBS 官方提供的 openebs/tests-fio:latest 作为测试镜像,创建测试 Pod。
3.1 创建测试 pvc
编辑测试 PVC 资源清单,vi test-nfs-fio-pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:name: test-nfs-fio-pvc
spec:storageClassName: nfs-scaccessModes:- ReadWriteManyresources:requests:storage: 1Gi执行命令,创建 PVC。
kubectl apply -f test-nfs-fio-pvc.yaml3.2 创建测试 Pod
编辑测试 Pod 资源清单,vi test-nfs-fio-pod.yaml
kind: Pod
apiVersion: v1
metadata:name: test-nfs-fio-pod
spec:containers:- name: test-nfs-fio-podimage: openebs/tests-fio:latestcommand:- "/bin/sh"args:- "-c"- "touch /mnt/SUCCESS && sleep 86400"volumeMounts:- name: nfs-fio-pvcmountPath: "/mnt"restartPolicy: "Never"volumes:- name: nfs-fio-pvcpersistentVolumeClaim:claimName: test-nfs-fio-pvc执行命令,创建 Pod。
kubectl apply -f test-nfs-fio-pod.yaml3.3 连接测试 Pod 终端
执行下面的命令,打开 fio 测试 Pod 终端。
kubectl exec -it test-nfs-fio-pod -- /bin/bash查看已经挂载的 NFS 存储。
root@test-nfs-fio-pod:/# df -h
Filesystem Size Used Avail Use% Mounted on
overlay 100G 6.5G 94G 7% /
tmpfs 64M 0 64M 0% /dev
tmpfs 7.6G 0 7.6G 0% /sys/fs/cgroup
192.168.9.97:/datanfs/k8s/default-test-nfs-fio-pvc-pvc-7158aa17-f003-47a2-b6d6-07c69d014178 100G 746M 100G 1% /mnt
/dev/mapper/openeuler-root 35G 2.3G 31G 7% /etc/hosts
/dev/mapper/data-lvdata 100G 6.5G 94G 7% /etc/hostname
shm 64M 0 64M 0% /dev/shm
tmpfs 14G 12K 14G 1% /run/secrets/kubernetes.io/serviceaccount
tmpfs 7.6G 0 7.6G 0% /proc/acpi
tmpfs 7.6G 0 7.6G 0% /proc/scsi
tmpfs 7.6G 0 7.6G 0% /sys/firmware3.4 测试磁盘性能
执行下面的测试命令。
mkdir /mnt/test-data
fio --rw=write --ioengine=sync --fdatasync=1 --directory=/mnt/test-data --size=2200m --bs=2300 --name=nfstest测试结果:
root@test-nfs-fio-pod:/# fio --rw=write --ioengine=sync --fdatasync=1 --directory=/mnt/test-data --size=2200m --bs=2300 --name=nfstest
nfstest: (g=0): rw=write, bs=2300-2300/2300-2300/2300-2300, ioengine=sync, iodepth=1
fio-2.2.10
Starting 1 process
nfstest: Laying out IO file(s) (1 file(s) / 2200MB)
Jobs: 1 (f=1): [W(1)] [100.0% done] [0KB/956KB/0KB /s] [0/426/0 iops] [eta 00m:00s]
nfstest: (groupid=0, jobs=1): err= 0: pid=26: Tue Jul 23 02:55:35 2024write: io=2199.2MB, bw=870003B/s, iops=378, runt=2651558msecclat (usec): min=4, max=87472, avg=224.30, stdev=309.99lat (usec): min=4, max=87473, avg=224.71, stdev=310.00clat percentiles (usec):| 1.00th=[ 7], 5.00th=[ 8], 10.00th=[ 8], 20.00th=[ 9],| 30.00th=[ 10], 40.00th=[ 12], 50.00th=[ 302], 60.00th=[ 338],| 70.00th=[ 366], 80.00th=[ 398], 90.00th=[ 442], 95.00th=[ 482],| 99.00th=[ 588], 99.50th=[ 700], 99.90th=[ 1848], 99.95th=[ 3120],| 99.99th=[ 7008]bw (KB /s): min= 1, max= 1078, per=100.00%, avg=873.03, stdev=221.69lat (usec) : 10=25.84%, 20=16.33%, 50=1.64%, 100=0.03%, 250=0.23%lat (usec) : 500=52.30%, 750=3.19%, 1000=0.15%lat (msec) : 2=0.20%, 4=0.05%, 10=0.03%, 20=0.01%, 50=0.01%lat (msec) : 100=0.01%cpu : usr=0.38%, sys=1.56%, ctx=1567342, majf=0, minf=12IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%issued : total=r=0/w=1002985/d=0, short=r=0/w=0/d=0, drop=r=0/w=0/d=0latency : target=0, window=0, percentile=100.00%, depth=1Run status group 0 (all jobs):WRITE: io=2199.2MB, aggrb=849KB/s, minb=849KB/s, maxb=849KB/s, mint=2651558msec, maxt=2651558msec测试结果说明: 测试结果明显不符合官方建议的最低值。由于,是个人测试环境也就无所谓了。生产环境请严谨测试、评估。
4. 使用 Helm 安装 Milvus 集群
Milvus 官方提供了 Operator、Helm 等多种方式的集群安装文档。本文实战演示了 Helm 的安装方式。其他方式请参考 Milvus 官方文档。
4.1 安装 Milvus Helm Chart
添加 Milvus Helm repository。
helm repo add milvus https://zilliztech.github.io/milvus-helm/更新本地 charts。
helm repo update milvus4.2 安装 Milvus
官方默认安装命令(仅供参考,本文未用)。
helm install my-release milvus/milvus按规划设置自定义配置项,执行下面的安装命令:
helm install --namespace opsxlab --create-namespace opsxlab milvus/milvus \--set image.all.repository="milvusdb/milvus" \--set image.tools.repository="milvusdb/milvus-config-tool" \--set etcd.image.registry="docker.io" \--set etcd.image.repository="milvusdb/etcd" \--set pulsar.images.broker.repository="milvusdb/pulsar" \--set pulsar.images.autorecovery.repository="milvusdb/pulsar" \--set pulsar.images.zookeeper.repository="milvusdb/pulsar" \--set pulsar.images.bookie.repository="milvusdb/pulsar" \--set pulsar.images.proxy.repository="milvusdb/pulsar" \--set pulsar.images.pulsar_manager.repository="milvusdb/pulsar-manager" \--set pulsar.pulsar_metadata.image.repository="milvusdb/pulsar" \--set minio.image.repository="milvusdb/minio" \--set etcd.persistence.storageClass="nfs-sc" \--set minio.persistence.storageClass="nfs-sc" \--set pulsar.zookeeper.volumes.data.storageClassName="nfs-sc" \--set pulsar.bookkeeper.volumes.journal.storageClassName="nfs-sc"自定义配置说明:
- 指定并自动创建命名空间 opsxlab
- 设置组件的镜像地址,本文为了演示修改方法,保留了默认值,实际使用中可以修改为自己的镜像仓库地址
- etcd 的镜像地址比较特殊,有两个配置项,请注意
- 设置持久化存储类为
nfs-sc,适用于 k8s 有多种存储类,需要部署到指定存储类的场景 - 所有配置仅供参考,请参考官方文档查看更详细的配置
附录: 默认安装的组件镜像地址及版本:
| 序号 | 组件名称 | 默认 repository | 组件版本 |
|---|---|---|---|
| 1 | milvus | milvusdb/milvus | v2.4.6 |
| 2 | milvus-config-tool | milvusdb/milvus-config-tool | v0.1.2 |
| 3 | etcd | milvusdb/etcd | 3.5.5-r4 |
| 4 | pulsar | apachepulsar/pulsar | 2.9.5 |
| 5 | pulsar-manager | apachepulsar/pulsar-manager | v0.1.0 |
| 6 | minio | minio/minio | RELEASE.2023-03-20T20-16-18Z |
4.3 查看安装结果
Helm 安装命令成功执行后,观察 Pod 运行状态。
kubectl get pods -n opsxlab安装成功后,输出结果如下:
$ kubectl get pods -n opsxlab
NAME READY STATUS RESTARTS AGE
opsxlab-etcd-0 1/1 Running 0 8m9s
opsxlab-etcd-1 1/1 Running 0 8m20s
opsxlab-etcd-2 1/1 Running 0 11m
opsxlab-milvus-datacoord-6cd875684d-fbkgx 1/1 Running 6 (9m19s ago) 13m
opsxlab-milvus-datanode-5c5558cbc7-r24vj 1/1 Running 6 (9m40s ago) 13m
opsxlab-milvus-indexcoord-f48d66647-52crb 1/1 Running 0 13m
opsxlab-milvus-indexnode-c6979d59b-rvm5p 1/1 Running 6 (9m44s ago) 13m
opsxlab-milvus-proxy-79997676f9-hftdf 1/1 Running 6 (9m22s ago) 13m
opsxlab-milvus-querycoord-5d94f97dc4-tv52n 1/1 Running 6 (9m43s ago) 13m
opsxlab-milvus-querynode-59b9bd7c8b-7qljj 1/1 Running 6 (9m26s ago) 13m
opsxlab-milvus-rootcoord-745b9fbb68-mr7st 1/1 Running 6 (9m36s ago) 13m
opsxlab-minio-0 1/1 Running 0 13m
opsxlab-minio-1 1/1 Running 0 13m
opsxlab-minio-2 1/1 Running 0 13m
opsxlab-minio-3 1/1 Running 0 13m
opsxlab-pulsar-bookie-0 1/1 Running 0 13m
opsxlab-pulsar-bookie-1 1/1 Running 0 13m
opsxlab-pulsar-bookie-2 1/1 Running 0 13m
opsxlab-pulsar-bookie-init-7l4kh 0/1 Completed 0 13m
opsxlab-pulsar-broker-0 1/1 Running 0 13m
opsxlab-pulsar-proxy-0 1/1 Running 0 13m
opsxlab-pulsar-pulsar-init-ntbh8 0/1 Completed 0 13m
opsxlab-pulsar-recovery-0 1/1 Running 0 13m
opsxlab-pulsar-zookeeper-0 1/1 Running 0 13m
opsxlab-pulsar-zookeeper-1 1/1 Running 0 13m
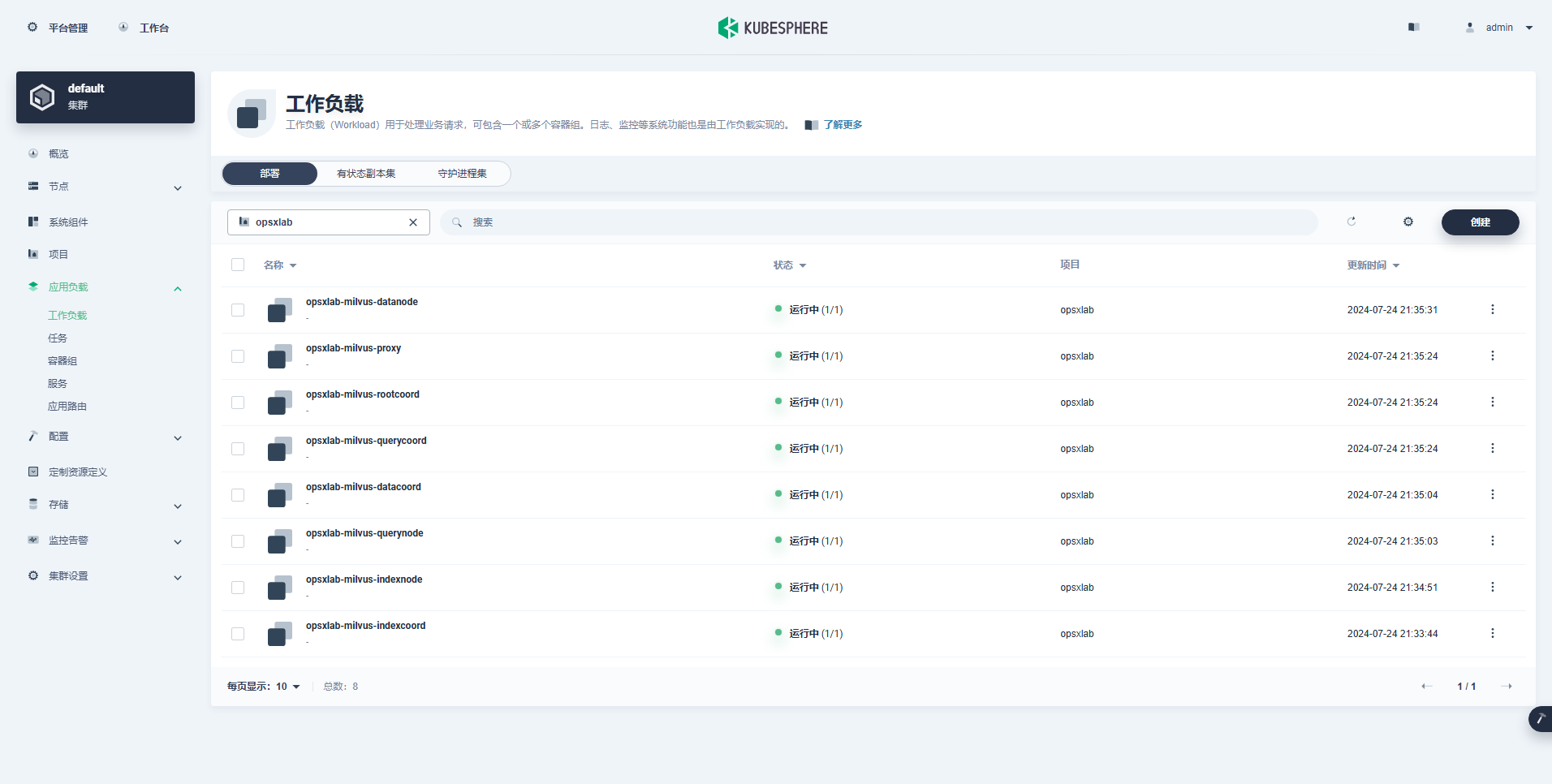
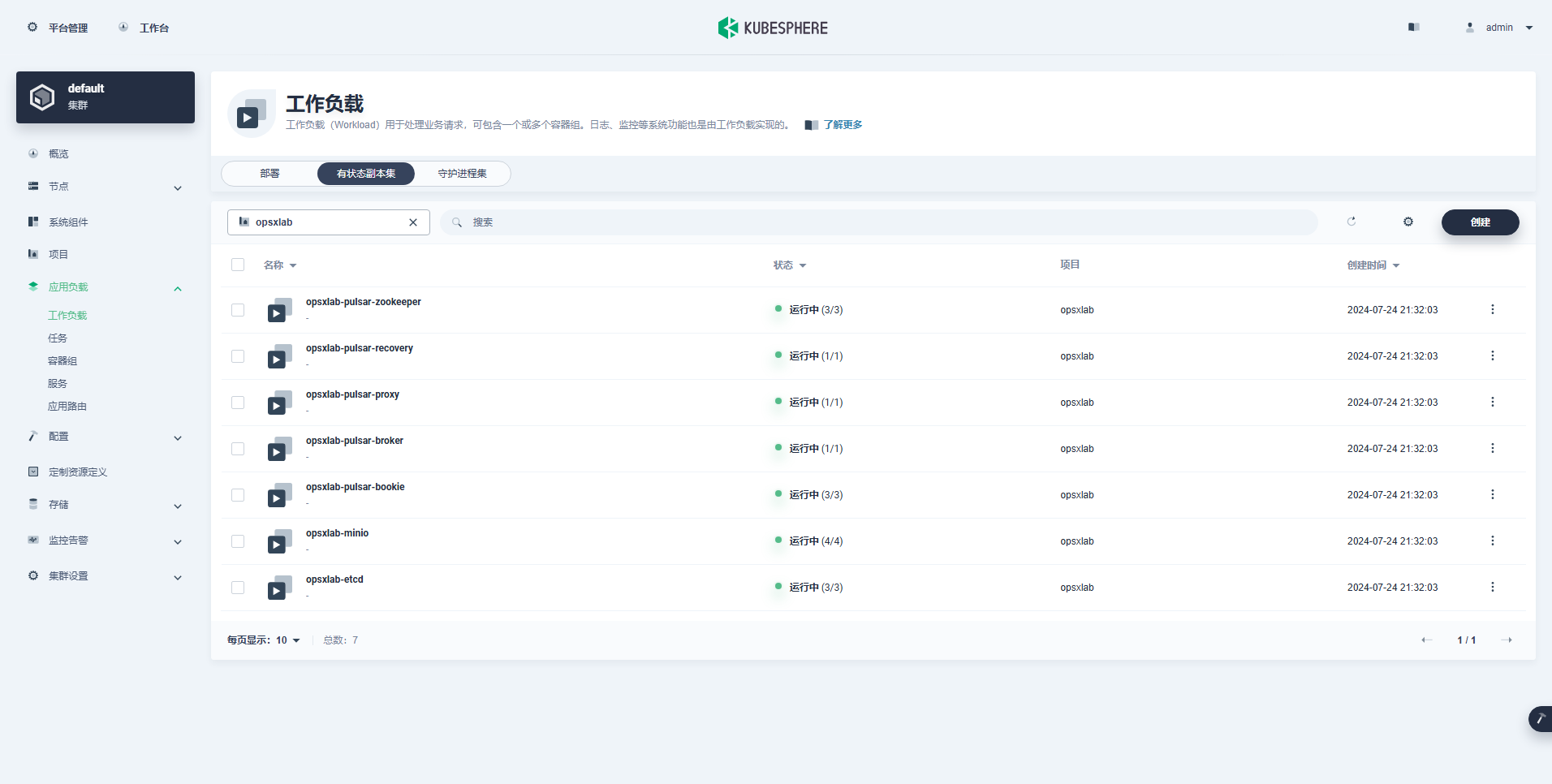
opsxlab-pulsar-zookeeper-2 1/1 Running 0 12mKubeSphere 管理控制台查看部署的组件信息。
- Depolyment(8 个)
- StatefulSet(7 个)
- Services(17 个)
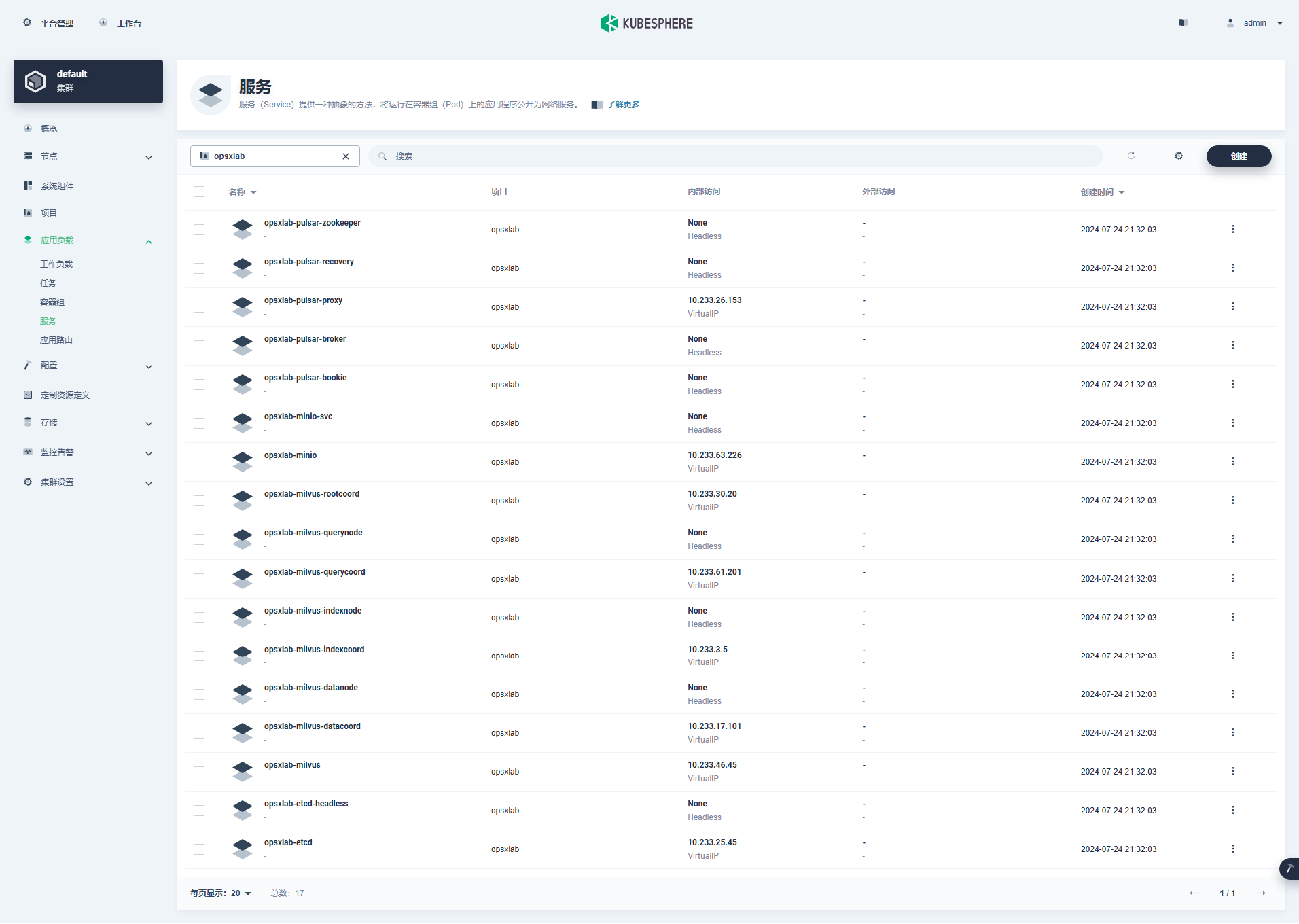
从上面的 Deployment、StatefulSet、Services 资源数量来看,默认部署的 Milvus 组件还是比较多的,后期运维成本比较高。
4.4 配置认证并开启外部访问
默认配置部署的 Milvus,没有启用安全认证,任何人都可以随意读写。这不符合生产环境要求,因此,需要增加认证配置。
创建并编辑 Helm 自定义 values 配置文件,vi custom-milvus.yaml。
extraConfigFiles:user.yaml: |+common:security:authorizationEnabled: true执行 helm 命令更新配置。
helm upgrade opsxlab milvus/milvus --values custom-milvus.yaml -n opsxlab注意: 如果安装时自定义了镜像地址,上面的操作会导致所有组件的镜像地址被还原成 helm 默认值,请谨慎使用。
默认配置部署的 Milvus 只能被 K8s 集群内部资源访问,如果开放给集群外部,需要定义外部访问方式,本文选择最简单的 NodePort 方式。
创建并编辑外部访问 svc 资源清单,vi milvus-external-svc.yaml。
kind: Service
apiVersion: v1
metadata:name: opsxlab-milvus-externalnamespace: opsxlablabels:app: opsxlab-milvus-externalapp.kubernetes.io/name: milvus
spec:ports:- name: milvusprotocol: TCPport: 19530targetPort: 19530nodePort: 31011selector:app.kubernetes.io/instance: opsxlabapp.kubernetes.io/name: milvuscomponent: proxyclusterIP:type: NodePort执行命令,创建外部服务。
kubectl apply -f milvus-external-svc.yaml4.5 验证测试 Milvus 服务可用性
Milvus 官方默认提供了 hello_milvus.py 工具,用来测试数据库的连接和读写。
工具获取方式:
wget https://raw.githubusercontent.com/milvus-io/pymilvus/master/examples/hello_milvus.py该脚本运行需要 Python 环境,为了测试方便,我自己制作了一个 Docker 镜像,可用于在 Docker、k8s 环境中进行测试。
创建并编辑 milvus 测试 Pod 资源清单,vi test-milvus-pod.yaml。
kind: Pod
apiVersion: v1
metadata:name: test-milvus-pod
spec:containers:- name: test-milvus-podimage: opsxlab/milvus-hello:v2.3.7-amd64command:- "/bin/sh"args:- "-c"- "sleep 86400"restartPolicy: "Never"执行命令,创建测试 Pod。
kubectl apply -f test-milvus-pod.yam登录测试容器终端(等待一段时间,确认 Pod 创建成功后执行)。
kubectl exec -it test-milvus-pod -- /bin/bash官方hello_milvus.py 脚本,默认连接不带密码认证的 Milvus 集群。我们的集群增加了认证,需要修改脚本,添加认证配置,默认的用户名和密码为 root/Milvus 。
# 原内容(32行)connections.connect("default", host="localhost", port="19530")# 修改为
connections.connect("default", host="192.168.9.91", port="31011", user="root", password='Milvus')执行测试命令。
python hello_milvus.py正确执行后,输出结果如下 :
root@test-milvus-pod:/app# python hello_milvus.py=== start connecting to Milvus ===Does collection hello_milvus exist in Milvus: False=== Create collection `hello_milvus` ====== Start inserting entities ===Number of entities in Milvus: 3001=== Start Creating index IVF_FLAT ====== Start loading ====== Start searching based on vector similarity ===hit: id: 2998, distance: 0.0, entity: {'random': 0.9728033590489911}, random field: 0.9728033590489911
hit: id: 999, distance: 0.09934990108013153, entity: {'random': 0.9519034206569449}, random field: 0.9519034206569449
hit: id: 1310, distance: 0.10135537385940552, entity: {'random': 0.26669865443188623}, random field: 0.26669865443188623
hit: id: 2999, distance: 0.0, entity: {'random': 0.02316334456872482}, random field: 0.02316334456872482
hit: id: 2502, distance: 0.13083189725875854, entity: {'random': 0.9289998713260136}, random field: 0.9289998713260136
hit: id: 2669, distance: 0.1590736210346222, entity: {'random': 0.6080847854541138}, random field: 0.6080847854541138
search latency = 0.2742s=== Start querying with `random > 0.5` ===query result:
-{'random': 0.6378742006852851, 'embeddings': [np.float32(0.8367804), np.float32(0.20963514), np.float32(0.6766955), np.float32(0.39746654), np.float32(0.8180806), np.float32(0.1201905), np.float32(0.9467144), np.float32(0.6947491)], 'pk': '0'}
search latency = 0.2361s
query pagination(limit=4):[{'random': 0.6378742006852851, 'pk': '0'}, {'random': 0.5763523024650556, 'pk': '100'}, {'random': 0.9425935891639464, 'pk': '1000'}, {'random': 0.7893211256191387, 'pk': '1001'}]
query pagination(offset=1, limit=3):[{'random': 0.5763523024650556, 'pk': '100'}, {'random': 0.9425935891639464, 'pk': '1000'}, {'random': 0.7893211256191387, 'pk': '1001'}]=== Start hybrid searching with `random > 0.5` ===hit: id: 2998, distance: 0.0, entity: {'random': 0.9728033590489911}, random field: 0.9728033590489911
hit: id: 999, distance: 0.09934990108013153, entity: {'random': 0.9519034206569449}, random field: 0.9519034206569449
hit: id: 1553, distance: 0.12913644313812256, entity: {'random': 0.7723335927084438}, random field: 0.7723335927084438
hit: id: 2502, distance: 0.13083189725875854, entity: {'random': 0.9289998713260136}, random field: 0.9289998713260136
hit: id: 2669, distance: 0.1590736210346222, entity: {'random': 0.6080847854541138}, random field: 0.6080847854541138
hit: id: 2628, distance: 0.1914074569940567, entity: {'random': 0.940077754658375}, random field: 0.940077754658375
search latency = 0.2026s=== Start deleting with expr `pk in ["0" , "1"]` ===query before delete by expr=`pk in ["0" , "1"]` -> result:
-{'embeddings': [np.float32(0.8367804), np.float32(0.20963514), np.float32(0.6766955), np.float32(0.39746654), np.float32(0.8180806), np.float32(0.1201905), np.float32(0.9467144), np.float32(0.6947491)], 'pk': '0', 'random': 0.6378742006852851}
-{'embeddings': [np.float32(0.27875876), np.float32(0.95355743), np.float32(0.976228), np.float32(0.54545516), np.float32(0.16776836), np.float32(0.82360446), np.float32(0.65080017), np.float32(0.21096307)], 'pk': '1', 'random': 0.43925103574669633}query after delete by expr=`pk in ["0" , "1"]` -> result: []=== Drop collection `hello_milvus` ===5. 部署可视化管理工具 Attu
Milvus 的可视化(GUI)管理工具官方推荐 Attu。它是一款 all-in-one 的 Milvus 管理工具。使用 Attu,可以显著的降低 Milvus 运维管理成本。
5.1 安装 Attu
Milvus Helm Chart 自带 Attu 的部署能力,默认是禁用的。我本人比较喜欢手工安装,所以下面介绍 kubectl 原生安装 Attu 的方法。
创建并编辑 Attu 部署资源清单, vi milvus-attu.yaml。
apiVersion: v1
kind: Service
metadata:name: milvus-attu-externalnamespace: opsxlablabels:app: attu
spec:type: NodePortclusterIP:ports:- name: attuprotocol: TCPport: 3000targetPort: 3000nodePort: 31012selector:app: attu---
apiVersion: apps/v1
kind: Deployment
metadata:name: milvus-attunamespace: opsxlablabels:app: attu
spec:replicas: 1selector:matchLabels:app: attutemplate:metadata:labels:app: attuspec:containers:- name: attuimage: zilliz/attu:v2.4imagePullPolicy: IfNotPresentports:- name: attucontainerPort: 3000protocol: TCPenv:- name: MILVUS_URLvalue: "opsxlab-milvus:19530"执行命令,创建 Attu 资源。
kubectl apply -f milvus-attu.yaml5.2 登录 Attu 管理控制台
打开浏览器,访问 K8s 集群任意节点 IP 的 31012 端口,例如 http://192.168.9.91:31012,默认用户名密码 root/Milvus。登录后请立即修改密码。
下面以一组 Attu 管理界面的预览截图,结束本文。请各位自己探究 Attu 的强大功能。
- 登录页面
- 首页
- 系统视图
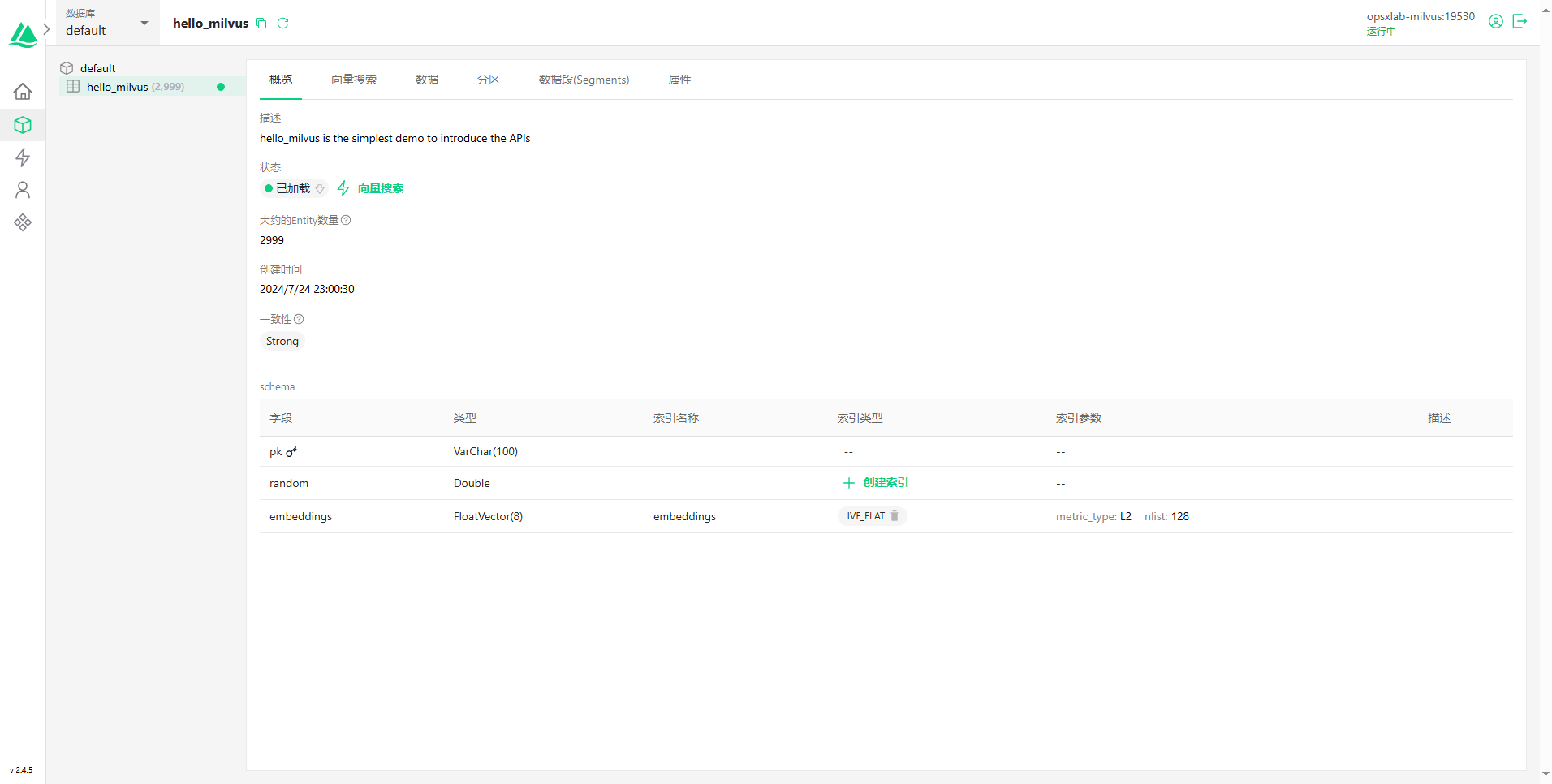
- 数据库-概览
- 数据库-向量搜索
- 数据库-数据
- 数据库-分区
- 数据库-数据段
- 数据库-属性
免责声明:
- 笔者水平有限,尽管经过多次验证和检查,尽力确保内容的准确性,但仍可能存在疏漏之处。敬请业界专家大佬不吝指教。
- 本文所述内容仅通过实战环境验证测试,读者可学习、借鉴,但严禁直接用于生产环境。由此引发的任何问题,作者概不负责!
本文由博客一文多发平台 OpenWrite 发布!
相关文章:
KubeSphere 部署向量数据库 Milvus 实战指南
作者:运维有术星主 Milvus 是一个为通用人工智能(GenAI)应用而构建的开源向量数据库。它以卓越的性能和灵活性,提供了一个强大的平台,用于存储、搜索和管理大规模的向量数据。Milvus 能够执行高速搜索,并以…...

前端canvas——贝塞尔曲线
曲线之美,不在于曲线本身,而在于用的人。 所以就有了这期贝塞尔曲线。 新规矩,先上个GIT。 效果图 开局一张图,代码全靠编。 代码 画骨 先想着怎么画一个心形吧,等你想好了,就知道怎么画了。 首先就还…...

Elasticsearch模糊查询之Wildcard
{“wildcard” : { “LPR.keyword” : { “wildcard” : “${Keyword}”} }},你的示例中使用了 wildcard 查询,它适用于模糊搜索,允许使用通配符(* 和 ?)来匹配字段值。你使用了 keyword 子字段来确保精确匹配,这是一…...

【人工智能】穿越科技迷雾:解锁人工智能、机器学习与深度学习的奥秘之旅
文章目录 前言一、人工智能1. 人工智能概述a.人工智能、机器学习和深度学习b.人工智能发展必备三要素c.小案例 2.人工智能发展历程a.人工智能的起源b.发展历程 3.人工智能的主要分支 二、机器学习1.机器学习工作流程a.什么是机器学习b.机器学习工作流程c.特征工程 2.机器学习算…...

Nginx服务 rewrite、proxy_pass 用rewrite去除URL中的特定参数
Nginx 是一个高性能的开源反向代理服务器,可以用于处理跨域请求、负载均衡和缓存等功能。在本文中,我们将介绍如何使用 Nginx 配置文件来实现反向代理。 我们可以实现跨域请求的处理,同时保护用户的隐私和安全。此外,Nginx 还…...

RocketMQ事务消息机制原理
RocketMQ工作流程 在RocketMQ当中,当消息的生产者将消息生产完成之后,并不会直接将生产好的消息直接投递给消费者,而是先将消息投递个中间的服务,通过这个服务来协调RocketMQ中生产者与消费者之间的消费速度。 那么生产者是如何…...

【C++】选择结构- 嵌套if语句
嵌套if语句的语法格式: if(条件1) { if(条件1满足后判断是否满足此条件) {条件2满足后执行的操作} else {条件2不满足执行的操作} } 下面是一个实例 #include<iostream> using namespace std;int main4() {/*提示用户输入一个高考分数,根据分…...

scrapy解决管道阻塞问题采用threadpool库线程池+twisted同步语法异步编程
实现方法:process_item和download任务函数像下面编写即可,其他管道像往常一样写法 import time import threadpool import random from twisted.internet import deferclass VideoPipeline:def __init__(self):self.pool threadpool.ThreadPool(10) # …...

Axure RP:打造动态交互的大屏可视化设计利器
Axure大屏可视化是指使用Axure RP这款原型设计工具来创建具有视觉冲击力和数据展示功能的大屏幕界面。Axure以其强大的交互设计和丰富的组件库,成为了实现大屏可视化的重要工具之一。以下是对Axure大屏可视化的详细阐述: 一、Axure在大屏可视化中的优势 …...

“八股文”在实际工作中是助力、阻力还是空谈
目录 1.概述 1.1.对实际工作的助力 1.2.存在的问题 2.“八股文”对招聘过程的影响 2.1.“八股文”在筛选候选人时的作用 2.2.面试中的比重及其合理性 2.3.如何平衡“八股文”与实际编程能力的考察 3.“八股文”在日常工作中的实用价值 3.1.在团队协作环境中进行有效沟…...

项目开发:@ControllerAdvice注解的基本应用
目录 简介基本用法全局异常处理全局拦截器全局数据绑定 注解参数1.value(): String[]2.basePackages(): String[]3.basePackageClasses(): Class<?>[]4.assignableTypes(): Class<?>[]5.annotations(): Class<? extends Annotation>[] 三.注解组成总结 简…...

Jmeter三种方式获取数组中多个数据并将其当做下个接口参数入参【附带JSON提取器和CSV格式化】
目录 一、传统方式-JOSN提取器获取接口返回值 1、接口调用获取返回值 2、添加JSON提取器 3、调试程序查看结果 4、添加循环控制器 5、设置count计数器 6、添加请求 7、执行请求 二、CSV参数化 1、将结果写入后置处理程序 2、设置循环处理器 3、添加CSV文件 4、设置…...

C++入门基础:C++中的循环语句
循环语句是编程语言中用来重复执行一段代码直到满足特定条件的一种控制结构。它们对于处理需要重复任务的场景非常有用,比如遍历数组、累加数值、重复执行某项操作直到满足条件等。 但是在使用循环语句的时候需要注意下哈,有时候一不小心会构成死循环或者…...
)
VUE 基础(二)
1 v-show:根据表达值的真假,切换元素的显示和隐藏 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0">&l…...
VMware Cloud Foundation ESXi 主机
一、准备嵌套 ESXi 主机环境# 1)物理 ESXi 主机信息 本次准备用于部署 VCF 嵌套实验环境的物理宿主机的配置信息如下图所示。其实,部署 VCF 环境主要对内存的大小要求比较高,部署完整的管理域相关组件下来差不多就要占用 200 GB左右内存,而对 CPU 和存储的需求可以根据实…...

PyTorch深度学习快速入门(下)
PyTorch深度学习快速入门(下) 一、现有网络模型的使用及修改(一)背景知识(二)修改网络模型的三种方法 二、网络模型的保存与加载(一)保存网络模型的两种方法(二ÿ…...

轻松入门Linux—CentOS,直接拿捏 —/— <1>
一、什么是Linux Linux是一个开源的操作系统,目前是市面上占有率极高的服务器操作系统,目前其分支有很多。是一个基于 POSIX 和 UNIX 的多用户、多任务、支持多线程和多 CPU 的操作系统 Linux能运行主要的UNIX工具软件、应用程序和网络协议 Linux支持 32…...

pandas安装以及导入CSV
安装pandas pip install pandas速度慢可以切换国内镜像源 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas执行导入csv操作 import pandas as pd# 读取csv文件 data pd.read_csv(yourPath)输入data查看数据 导入成功!...
新能源车浪潮来袭,同时存在高压低压系统,如何准确进行高低压布线间距EMC分析?
摘要 随着车辆电气化水平的逐步提升,电气零部件布局和布线面临着前所未有的挑战,在不断的压缩电气零部件间间距后,EMC性能成为非常关键的性能指标。特别是对于新能源车型,同时存在高压和低压系统,高低压耦合若处理的不…...

QUIC 协议
详解 QUIC 协议:它为何比 TCP 更优越?...

Taotoken用量看板与成本管理,让团队模型开销一目了然
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板与成本管理,让团队模型开销一目了然 当团队开始将多个大语言模型应用于不同业务场景时,一…...

Wifite2 终极指南:快速掌握无线网络安全审计工具
Wifite2 终极指南:快速掌握无线网络安全审计工具 【免费下载链接】wifite2 Rewrite of the popular wireless network auditor, "wifite" 项目地址: https://gitcode.com/gh_mirrors/wi/wifite2 Wifite2 是一款功能强大的无线网络安全审计工具&…...

AI资讯简报如何成为工程师的决策加速器
1. 项目概述:一份真正“够用”的AI资讯简报,到底长什么样?“This AI newsletter is all you need #35”——光看标题,你可能以为这是某份泛泛而谈的行业 roundup,或是又一个堆砌链接、靠标题党吸睛的邮件列表。但在我连…...

学术赋能国际交流 实干彰显时代担当——刘庆武受聘泰国清迈西北大学国际金融类博士生导师
(泰国讯)近日,第二届文化出海・泰国高校学术访问活动在泰国南邦国际科技学院多媒体会议室隆重举行。本次中泰跨境学术文化交流活动规格高、覆盖面广,汇聚两国学界、商界、侨界优质资源。南邦国际科技学院代理校长普・西素、副校长…...
、 小模型(小脑、肌肉记忆、条件反射)功能的差别,会导致模型在结构和训练等维度上哪些差别?!!)
[具身智能-857]:大模型(大脑、知识记忆、反复推演)、 小模型(小脑、肌肉记忆、条件反射)功能的差别,会导致模型在结构和训练等维度上哪些差别?!!
大脑大模型 VS 小脑小模型:功能差异→结构差异→训练差异 全维度对比一、核心功能差异(根源)大脑大模型:负责认知理解、语义交互、多轮逻辑推演、长时序任务规划、经验归纳、知识推理,先思后行,全局预判&am…...

FastGithub:5分钟告别GitHub龟速访问,开发效率提升3倍的终极方案
FastGithub:5分钟告别GitHub龟速访问,开发效率提升3倍的终极方案 【免费下载链接】FastGithub github定制版的dns服务,解析访问github最快的ip 项目地址: https://gitcode.com/gh_mirrors/fa/FastGithub 你是否经历过这样的场景&#…...
)
AI Agent驱动的管理咨询实战手册(麦肯锡/BCG未公开方法论首次披露)
更多请点击: https://intelliparadigm.com 第一章:AI Agent驱动的管理咨询范式革命 传统管理咨询依赖专家经验、手工访谈与静态模型,响应周期长、知识复用率低、规模化交付困难。AI Agent 的崛起正从根本上重构这一价值链——它不再是辅助工…...

如何在5分钟内彻底改变你的Illustrator工作流程:批量替换脚本终极指南
如何在5分钟内彻底改变你的Illustrator工作流程:批量替换脚本终极指南 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 还在为Adobe Illustrator中重复的替换操作浪费宝贵…...

对比直接使用厂商api体验taotoken在延迟与可用性上的差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商 API 体验 Taotoken 在延迟与可用性上的差异 在构建依赖大模型能力的应用时,开发者通常会直接调用特定…...

Python字节码反编译技术深度解析:pycdc项目的架构实现与实战应用
Python字节码反编译技术深度解析:pycdc项目的架构实现与实战应用 【免费下载链接】pycdc C python bytecode disassembler and decompiler 项目地址: https://gitcode.com/GitHub_Trending/py/pycdc 在Python生态系统中,字节码反编译技术一直是系…...