WEB前端开发中如何实现大文件上传?
大文件上传是个非常普遍的场景,在面试中也会经常被问到,大文件上传的实现思路和流程。在日常开发中,无论是云存储、视频分享平台还是企业级应用,大文件上传都是用户与服务器之间交互的重要环节。随着现代网络应用的日益复杂化,大文件上传已经成为前端开发中不可或缺的一部分。
然而,在实现大文件上传时,我们通常会面临以下几个挑战:
-
上传超时:一般前端请求都会限制最大请求时长,比如axios设置timeout,或者是 nginx(或其它代理/网关) 限制了最大请求时长。
-
服务器压力:大文件上传会给服务器带来较大的压力,甚至可能导致服务器崩溃。
-
文件大小超限:一般后端都会对上传文件的大小做限制,比如nginx和server都会限制。
-
用户体验:上传过程中用户需要等待较长时间,用户体验差。
-
网络波动:各种网络原因导致上传失败,比如网络不稳定可能导致上传过程中断,且失败之后需要从头开始。
对于前三点,虽说可以通过一定的配置来解决,但有时候也相当麻烦,或者服务器就规定不允许上传大型文件,需要兼顾实际场景。上传慢的话倒是无伤大雅,忍一忍是可以接受的,只是体验不好,但是失败后在重头开始上传,在网络环境差的时候简直就是灾难。为了应对以上挑战,我们就需要用到切片上传、断点续传等技术手段。
二、实现思路分析
整体流程图如下:
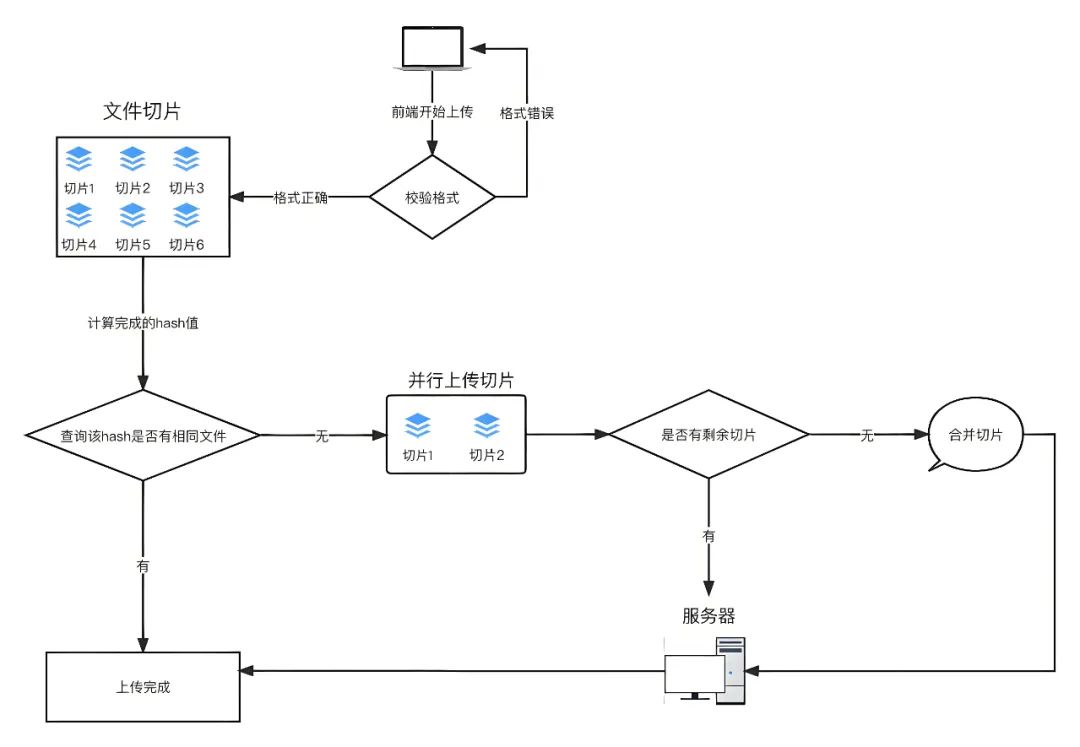
思路如下:
-
每个文件要有自己唯一的标识,因此在进行分片上传前,需要对整个文件进行MD5加密,生成MD5码,在后面上传文件每次调用接口时以formData格式上传给后端。可以使用spark-md5 计算文件的内容hash,以此来确定文件的唯一性将文件hash发送到服务端进行查询。以此来确定该文件在服务端的存储情况,这里可以分为三种:未上传、已上传、上传部分。
-
根据服务端返回的状态执行不同的上传策略。已上传:执行秒传策略,即快速上传,实际上没有对该文件进行上传,因为服务端已经有这份文件了。未上传、上传部分:执行计算待上传分块的策略并发上传还未上传的文件分块。当传完最后一个文件分块时,向服务端发送合并的指令,即完成整个大文件的分块合并,实现在服务端的存储。
上传过程:
-
分割文件:将要上传的文件切割成多个小文件片段。主要使用JavaScript的File API中的slice方法来实现。
-
上传文件分片:使用XMLHttpRequest或者Fetch API将分片信息以formData格式,并携带相关信息,如文件名、文件ID、当前片段序号等参数传给分片接口。
-
后端接收并保存文件片段:后端接收到每个文件片段后,将其保存在临时位置,并记录文件片段的序号、文件ID和文件MD5 hash值等信息。
-
续传处理:如果上传过程中断,下次继续上传时,通过查询后端已保存的文件片段信息,得知需要上传的文件片段,从断点处继续上传剩余的文件片段。
-
合并文件:当所有文件片段都上传完成后,后端根据文件ID将所有片段合并成完整的文件。
三、切片上传
切片上传原理:通过使用JavaScript的File API中的slice方法将大文件分割成多个小片段(chunk),然后逐个上传每个片段,在上传完切片后,前端通知后台再将文件片段拼接为一个完整的文件。
这样做的优点是可以并行多个请求一起上传文件,提高上传效率,并且在上传过程中如果某个片段因为某些原因上传失败,也不会影响其它文件切片,只需要重新上传该失败片段即可,不必重新上传整个文件。
实现思路:
在JavaScript中,文件File对象是Blob对象的子类,Blob对象包含了slice方法,通过这个方法,可以对二进制文件进行拆分。循环发送多个上传请求,然后返回结果后计数,当计数达到file片段长度后终止上传。
<input type="file" name="file" id="file" />const eleFile = document.getElementById('file');
eleFile.addEventListener('change', (event) => {const file = event.target.files[0];// 上传分块大小,单位Mbconst chunkSize = 1024 * 1024 * 1;// 当前已执行分片数位置let currentPosition = 0;//初始化分片方法,兼容问题let blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice;while(currentPosition < file.size) {const chunk = blobSlice.call(file, currentPosition, currentPosition + chunkSize);uploadChunk(chunk);currentPosition += chunkSize;}
})function uploadChunk(chunk) {// 将分片信息以formData格式作为参数传给分片接口let formData = new FormData();formData.append('fileChunk', chunk);// 根据项目实际情况axios.post('/api/oss/upload/file', formData, {headers: { 'Content-Type': 'multipart/form-data' },timeout: 600000,}).then(res => {// 上传成功console.log('分片上传成功', res)}).catch(error => {// 上传失败console.log('分片上传失败', error)})
}四、并发上传
并发上传相对要优雅一下,将文件分割成小片段后,使用Promise.all()把所有请求都放到一个Promise.all里,它会自动判断所有请求都完成然后触发 resolve 方法。并发上传可以同时上传多个片段而不是依次上传,进一步提高效率。
实现思路:
1、使用slice方法对二进制文件进行拆分,并把拆分的片段放到chunkList里面。
2、使用map将chunkList里面的每个chunk映射到一个Promise上传方法。
3、把所有请求都放到一个Promise.all里,它会自动判断所有请求都完成然后触发 resolve 方法,上传成功后通知后端合并分片文件。
代码实现如下:
const eleFile = document.getElementById('file');
eleFile.addEventListener('change', (event) => {const file = event.target.files[0];// 上传分块大小,单位Mbconst chunkSize = 1024 * 1024 * 1;// 当前已执行分片数位置let currentPosition = 0;// 存储文件的分片let chunkList = [];//初始化分片方法,兼容问题let blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice;while(currentPosition < file.size) {const chunk = blobSlice.call(file, currentPosition, currentPosition + chunkSize);chunkList.push(chunk);currentPosition += chunkSize;}uploadChunk(chunkList, file.name)
})function uploadChunk(chunkList, fileName) {const uploadPromiseList = chunkList.map((chunk, index) => {// 将分片信息以formData格式作为参数传给分片接口let formData = new FormData();formData.append('fileChunk', chunk);// 可以根据实际的需要添加其它参数,比如切片的索引formData.append('index', index);// 根据项目实际情况return axios.post('/api/oss/upload/file', formData, {headers: { 'Content-Type': 'multipart/form-data' },timeout: 600000,})})Promise.all(uploadPromiseList).then(res => {// 上传成功并通知后端合并分片文件axios.post('/api/oss/file/merge', {message: fileName},{headers: { 'Content-Type': 'application/json' },timeout: 600000,}).then(data => {console.log('文件合并成功', data)})}).catch(error => {// 上传错误console.log('上传失败', error)})
}五、断点续传之1
断点续传允许在网络中断或其它原因导致上传失败时,从上次上传中断的位置继续上传,而不是重新从头上传整个文件。
实现断点续传需要后端配合记录上传的进度,并且在前端重新上传时,需要先查询已上传的进度,让后从断点处继续上传。
const eleFile = document.getElementById('file');
eleFile.addEventListener('change', (event) => {const file = event.target.files[0];// 上传分块大小,单位Mbconst chunkSize = 1024 * 1024 * 1;// 当前已执行分片数位置let currentPosition = 0;// 存储文件的分片let chunkList = [];//初始化分片方法,兼容问题let blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice;while(currentPosition < file.size) {const chunk = blobSlice.call(file, currentPosition, currentPosition + chunkSize);chunkList.push(chunk);currentPosition += chunkSize;}axios.post('/api/upload/file/history',{fileName: file.name},{headers: { 'Content-Type': 'multipart/form-data' },timeout: 600000,}).then(res => {const historyChunks = res.uploadedChunks;const remainChunks = chunkList.filter((item, index) => !historyChunks.includes(index));// 并发上传剩余分片uploadChunk(remainChunks, file.name)})
})function uploadChunk(chunkList, fileName) {const uploadPromiseList = chunkList.map((chunk, index) => {// 将分片信息以formData格式作为参数传给分片接口let formData = new FormData();formData.append('fileChunk', chunk);// 可以根据实际的需要添加其它参数,比如切片的索引formData.append('index', index);// 根据项目实际情况return axios.post('/api/oss/upload/file', formData, {headers: { 'Content-Type': 'multipart/form-data' },timeout: 600000,})})Promise.all(uploadPromiseList).then(res => {// 剩余分片上传成功并通知后端合并分片文件axios.post('/api/oss/file/merge', {message: fileName},{headers: { 'Content-Type': 'application/json' },timeout: 600000,}).then(data => {console.log('文件合并成功', data)})}).catch(error => {// 上传错误console.log('上传失败', error)})
}以上是一个简易版的断点续传实现流程代码,但在实际场景应用中我们还需要更严谨的处理来实现断点续传功能。不如,上传文件前通常需要生成文件的唯一标识,比如文件名与文件大小的组合、文件的hash值或者文件hash值与文件大小的组合来支持断点续传的逻辑。请继续看下面的代码实现!!!
六、断点续传之2
已上传的执行秒传策略,即快速上传,实际上没有对该文件进行上传,因为服务端已经有这份文件了。
秒传的关键在于计算文件的唯一性标识。文件的不同不是命名的差异,而是内容的差异,所以我们将整个文件的二进制码作为入参,计算 Hash 值,将其作为文件的唯一性标识。一般而言,这样做就够了,但是摘要算法是存在碰撞概率的,我们如果想要再严谨点的话,可以将文件大小也作为衡量指标,只有文件摘要和文件大小同时相等,才认为是相同的文件。
<input type="file" name="file" id="file" @change="changeFile" />计算文件hash值可以使用spark-md5。
import SparkMD5 from 'spark-md5'通过input的change事件获取要上传的文件。
function changeFile(event) {const file = event.target.files[0];handleUploadFile(file, 1)
}接下来对文件进行分片和hash计算:
/*** @param {File} file 目标上传文件* @param {number} size 上传分块大小,单位Mb* @returns {filelist:ArrayBuffer,fileHash:string}*/
async function handleSliceFile(file, size = 1) {return new Promise((resolve, reject) => {// 上传分块大小,单位Mbconst chunkSize = 1024 * 1024 * size;// 分片数const totalChunkCount = file && Math.ceil(file.size / chunkSize);// 当前已执行分片数位置let currentChunkCount = 0;// 存储文件的分片let fileList = [];//初始化分片方法,兼容问题let blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice;// 文件读取对象const fileReader = new FileReader();// spark-md5 计算文件hash值SparkMD5对象const spark = new SparkMD5.ArrayBuffer();// 存储计算后的文件hash值let fileHash = "";// 错误fileReader.onerror = function () {reject('Error reading file');};fileReader.onload = (e) => {//当前读取的分块结果 ArrayBufferconst curChunk = e.target.result;//将当前分块追加到spark对象中spark.append(curChunk);currentChunkCount++;fileList.push(curChunk);//判断分块是否完成if (currentChunkCount >= totalChunkCount) {// 全部读取,获取文件hashfileHash = spark.end();resolve({ fileList, fileHash });} else {readNext();}};//读取下一个分块const readNext = () => {//计算分片的起始位置和终止位置const start = chunkSize * currentChunkCount;let end = start + chunkSize;if (end > file.size) {end = file.size}//读取文件,触发onLoadfileReader.readAsArrayBuffer(blobSlice.call(file, start, end))}readNext()})
}文件上传,首选调用接口获取需要上传的文件index,返回的集合length等于0执行秒传,如果返回的集合length不等于0执行需要过滤得到需要上传的remainingChunks,使用map将remainingChunks里面的每个chunk映射为一个Promise上传方法,把所有请求都放到一个Promise.all里,上传成功后通知后端合并分片文件。
sync function handleUploadFile(file, chunkSize) {const { fileList, fileHash } = await handleSliceFile(file, chunkSize);// 存放切片let chunkList = fileList;// 显示上传的进度条let process = 0;// 获取文件上传状态const { data } = await axios.post('/api/upload/file/history', {fileHash,totalCount: chunkList.length,extname: file.name,})// 返回已经上传的const { needUploadChunks } = data;// 已上传,无待上传文件,秒传if (!needUploadChunks.length) {process = 100;return;} // 此处包含了未上传和上传部分的情况// 过滤剩余需要上传的分片序列const remainingChunks = chunkList.filter((item, index) => needUploadChunks.includes(index + 1));// 同步上传进度,断点续传情况下progress = ((chunkList.length - needUploadChunks.length) / chunkList.length) * 100;// 上传if (remainingChunks.length) {const uploadPromiseList = remainingChunks.map(async (chunk, index) => {const response = await uploadChunk(chunk, index + 1, fileHash);//更新进度progress += Math.ceil(100 / allChunkList.length);if (progress >= 100) progress = 100;return response;});Promise.all(uploadPromiseList).then(() => {// 清空已上传的切片chunkList = [];//发送请求,通知后端进行合并axios.post('/api/file/merge', {fileHash,extname: 'fileName.mp4'}, {headers: { 'Content-Type': 'multipart/form-data' },timeout: 600000,}).then(res => {console.log('合并完成', res)}).catch(error => {// 合并错误console.log('合并错误', error)})}).catch(error => {// 上传错误console.log('上传错误', error)})}
}上传函数返回一个promise,参数为formData。
function uploadChunk(chunk, index, fileHash) {// 将分片信息以formData格式作为参数传给分片接口let formData = new FormData();formData.append('fileChunk', new Blob([chunk]));// 可以根据实际的需要添加其它参数,比如切片的索引formData.append('index', index);// 文件的标识hash值formData.append('fileHash', fileHash);// 根据项目实际情况return axios.post('/api/upload/file', formData, {headers: { 'Content-Type': 'multipart/form-data' },timeout: 600000,})
}我们在 fileReader 里面使用了 readAsArrayBuffer 方法做转换并分割,因此传入的chunk的类型是ArrayBuffer,而formData中文件的类型应该是Blob,所以需要时用new Blob() 将每一个chunk转为Blob类型。
七、总结
断点续传的重点是文件的切片与合并,整个上传流程需要前后端配合好,细节较多。
注意事项:
-
计算整个文件的 MD5 值,当大文件比较大时会比较慢,耗时,更好地做法是将这部分任务放在 Web Worker 中执行。Web Worker 是 HTML5 标准的一部分,它允许一段 JavaScript 程序运行在主线程之外的另外一个线程中。这样计算任务就不会影响到当前线程的渲染任务。可以和当前线程间使用 postMessage 的方式进行通讯。
-
可以根据文件切片的状态,发送上传请求,由于存在并发限制,需要限制 request 创建个数,避免页面卡死。
-
在上传大文件时,应提供适当的进度反馈和错误处理以确保良好的用户体验。
-
对于文件切片、并发上传和断点续传,后端需要能够接受文件片段,并能够处理并发请求和断点数据,因此需要合后端人员密切配合。
相关文章:
WEB前端开发中如何实现大文件上传?
大文件上传是个非常普遍的场景,在面试中也会经常被问到,大文件上传的实现思路和流程。在日常开发中,无论是云存储、视频分享平台还是企业级应用,大文件上传都是用户与服务器之间交互的重要环节。随着现代网络应用的日益复杂化&…...

ts给vue中props设置指定类型
interface IBaseObject {[key: string | number]: any; }export default defineComponent({name:xx,props:{data:{type:Object as PropType<IBaseObject>,default:()>({}),required:true},}, })...

模拟实现c++中的list模版
☺☺☺☺☺☺☺☺☺☺ 点击 进入杀马特的主页☺☺☺☺☺☺☺☺☺☺ 目录 一list简述: 二库内常用接口函数使用: 1reverse(): 2.s…...
从信息论的角度看微博推荐算法
引言 在数字时代,推荐系统已成为社交媒体和其他在线服务平台的核心组成部分。它们通过分析用户行为和偏好,为用户提供个性化的内容,从而提高用户满意度和平台的参与度。推荐系统不仅能够增强用户体验,还能显著提升广告投放的效率…...
与RISC(精简指令集)的区别)
CISC(复杂指令集)与RISC(精简指令集)的区别
RISC(Reduced Instruction Set Computer)和CISC(complex instruction set computer)是当前CPU的两种架构。 它们的区别在于不同的CPU设计理念和方法。 早期的CPU全部是CISC架构,它的设计目的是要用最少的机器语言指令来完成所需的计算任务。比如对于乘法运算&#x…...

自定义数据库连接的艺术:Laravel中配置多数据库连接详解
自定义数据库连接的艺术:Laravel中配置多数据库连接详解 在现代Web应用开发中,经常需要连接到多个数据库。Laravel,作为PHP界最受欢迎的框架之一,提供了强大的数据库抽象层,支持多种数据库系统,并且允许开…...

力扣高频SQL 50题(基础版)第八题
文章目录 力扣高频SQL 50题(基础版)第八题1581. 进店却未进行过交易的顾客题目说明思路分析实现过程准备数据:实现方式:结果截图:总结: 力扣高频SQL 50题(基础版)第八题 1581. 进店…...

【C++20】从0开始自制协程库
文章目录 参考 很多人对协程的理解就是在用户态线程把CPU对线程的调度复制了一遍,减少了线程的数量,也就是说在一个线程内完成对协程的调度,不需要线程切换导致上下文切换的开销。但是线程切换是CPU行为,就算你的程序只有一个线程…...

Docker 深度解析:从入门到精通
引言 在当今的软件开发领域,容器化技术已经成为一种趋势。Docker 作为容器化技术的代表,以其轻量级、可移植性和易用性,被广泛应用于各种场景。本文将从 Docker 的基本概念入手,详细介绍 Docker 的安装、基本操作、网络配置、数据…...

[C++] 模板编程-02 类模板
一 类模板 template <class T或者typename T> class 类名 { .......... } 1.1 两种不同的实现 在以下的两种实现中,其实第一种叫做成员函数模板,并不能称为类模板因为这种实现,我们在调用时,并不需要实例化为Product这个类指定指定特定类型。 // 实现1 clas…...

嵌入式C++、STM32、树莓派4B、OpenCV、TensorFlow/Keras深度学习:基于边缘计算的实时异常行为识别
1. 项目概述 随着物联网和人工智能技术的发展,智能家居安全系统越来越受到人们的关注。本项目旨在设计并实现一套基于边缘计算的智能家居安全系统,利用STM32微控制器和树莓派等边缘设备,实时分析摄像头数据,识别异常行为(如入侵、跌倒等),并及时发出警报,提高家庭安全性。 系…...

C++ //练习 15.30 编写你自己的Basket类,用它计算上一个练习中交易记录的总价格。
C Primer(第5版) 练习 15.30 练习 15.30 编写你自己的Basket类,用它计算上一个练习中交易记录的总价格。 环境:Linux Ubuntu(云服务器) 工具:vim 代码块: /********************…...
3个方法快速找回忘记的PDF文件密码
为确保PDF文件的重要信息不轻易外泄,很多人都会给PDF文件设置打开密码,但伴随着时间的推移,让我们忘记了原本设置的密码,但这时,我们又非常急需要打开编辑这份文件,这时我们该怎么办呢?下面小编…...

排序算法:选择排序,golang实现
目录 前言 选择排序 代码示例 1. 算法包 2. 选择排序代码 3. 模拟排序 4. 运行程序 5. 从大到小排序 循环细节 外层循环 内层循环 总结 选择排序的适用场景 1. 数据规模非常小 2. 稳定性不重要 3. 几乎全部数据已排序 4. 教育目的 前言 在实际场景中…...

【测试】博客系统的测试报告
项目背景 个人博客系统采用了 SSM 框架与 Redis 缓存技术的组合 ,为用户提供了一个功能丰富、性能优越的博客平台。 在技术架构上 ,SSM 框架确保了系统的稳定性和可扩展性。Spring 负责管理项目的各种组件 ,Spring MVC 实现了清晰的请求处理…...

PointCLIP: Point Cloud Understanding by CLIP
Abstract 近年来,基于对比视觉语言预训练(CLIP)的零镜头和少镜头学习在二维视觉识别中表现出了令人鼓舞的效果,该方法在开放词汇设置下学习图像与相应文本的匹配。然而,通过大规模二维图像-文本对预训练的CLIP是否可以推广到三维识别&#x…...

搜索(剪枝)
定义: 剪枝,就是减少搜索树的规模、尽早排除搜索树中不必要分支的一种手段。 在深度优先搜索中,有以下几类常见的剪枝方法: 优化搜索顺序排除等效冗余可行性剪枝最优性剪枝记忆化剪枝 例题1:AcWing 167.木棒 题目:…...
python基础知识点
最近系统温习了一遍python基础语法,把自己不熟知的知识点罗列一遍,便于查阅~~ python教程 Python 基础教程 | 菜鸟教程 1、python标识符 以单下划线开头 _foo 的代表不能直接访问的类属性,需通过类提供的接口进行访问,不能用 f…...
)
Android SurfaceFlinger——GraphicBuffer获取内存信息(三十一)
上一篇文章介绍了 GraphicBuffer 初始化的 initWithSize() 函数中的申请内存流程,这里我们看一下另一个比较重要的函数,GraphicBufferMapper. getTransportSize 获取内存信息。该函数通常在需要了解缓冲区的实际内存占用情况时调用,例如在调试内存使用情况或优化性能时。 一…...

基于 SASL/SCRAM 让 Kafka 实现动态授权认证
一、说明 在大数据处理和分析中 Apache Kafka 已经成为了一个核心组件。然而在生产环境中部署 Kafka 时,安全性是一个必须要考虑的重要因素。SASL(简单认证与安全层)和 SCRAM(基于密码的认证机制的盐化挑战响应认证机制ÿ…...

深度解析Magic VLSI:开源集成电路布局设计的基石工具
深度解析Magic VLSI:开源集成电路布局设计的基石工具 【免费下载链接】magic Magic VLSI Layout Tool 项目地址: https://gitcode.com/gh_mirrors/magi/magic 在集成电路设计领域,Magic VLSI Layout Tool 作为一款历史悠久的开源布局编辑器&#…...

终极免费方案:cursor-vip完全指南,让AI编程助手触手可及
终极免费方案:cursor-vip完全指南,让AI编程助手触手可及 【免费下载链接】cursor-vip cursor IDE enjoy VIP 项目地址: https://gitcode.com/gh_mirrors/cu/cursor-vip 你是否为高昂的AI编程助手订阅费而苦恼?cursor-vip为你提供了一套…...

Focus-DETR:基于前景特征选择的高效目标检测模型解析
1. 项目概述与核心痛点目标检测,这个计算机视觉领域的经典任务,如今正站在一个十字路口。一方面,以DETR(Detection Transformer)为代表的端到端检测范式,凭借其简洁优雅的架构和强大的性能,正迅…...

Excel MCP Server:革命性的无Excel数据处理引擎
Excel MCP Server:革命性的无Excel数据处理引擎 【免费下载链接】excel-mcp-server A Model Context Protocol server for Excel file manipulation 项目地址: https://gitcode.com/gh_mirrors/ex/excel-mcp-server 在数据处理领域,传统Excel依赖…...

Desktop Postflop v0.2.7:高性能德州扑克GTO求解器架构设计与实现原理深度解析
Desktop Postflop v0.2.7:高性能德州扑克GTO求解器架构设计与实现原理深度解析 【免费下载链接】desktop-postflop [Development suspended] Advanced open-source Texas Holdem GTO solver with optimized performance 项目地址: https://gitcode.com/gh_mirrors…...

KindEditor开源富文本编辑器:企业级内容创作解决方案深度解析
KindEditor开源富文本编辑器:企业级内容创作解决方案深度解析 【免费下载链接】kindeditor Try Lake, the new editor I developed 项目地址: https://gitcode.com/gh_mirrors/ki/kindeditor 在当今数字化内容创作环境中,富文本编辑器已成为Web应…...

从XML-RPC到gRPC:一个老派RPC协议如何影响了今天的微服务通信设计
从XML-RPC到gRPC:技术演进中的通信范式变迁 二十年前,当Dave Winer和Microsoft首次提出XML-RPC协议时,他们可能不会想到这个简单的远程调用机制会成为现代微服务架构的启蒙。在1998年的技术背景下,XML-RPC以其基于HTTP和XML的简洁…...

2000-2025年区县国家数字乡村试点DID
2019年《数字乡村发展战略纲要》明确数字乡村作为乡村振兴战略方向与数字中国重要内容,2022年《数字乡村发展行动计划(2022-2025年)》,部署了8个方面重点行动“数字乡村”一般指随着网络化、信息化、数字化在农业农村经济社会发展…...

初创团队如何通过Taotoken模型广场选型并控制AI成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何通过Taotoken模型广场选型并控制AI成本 对于资源有限的初创团队而言,将大模型能力集成到产品中是加速创新…...

异常检测实战:从面试陷阱到产线落地的20个关键问题
1. 项目概述:这不是刷题手册,而是一张通往机器学习工程现场的“通关地图”“Crack ML Interviews with Confidence: Anomaly Detection (20 Q&A)”——这个标题里藏着三个被绝大多数求职者严重低估的关键信号:Crack不是“背答案”&#x…...