Elasticsearch:如何在 Elastic 中实现图片相似度搜索
作者:Radovan Ondas

在本文章,我们将了解如何通过几个步骤在 Elastic 中实施相似图像搜索。 开始设置应用程序环境,然后导入 NLP 模型,最后完成为你的图像集生成嵌入。
Elastic 图像相似性搜索概览 >>
如何设置环境
第一步是为你的应用程序设置环境。 一般要求包括:
- Git
- Python 3.9
- Docker
- 数百张图片
使用数百张图像以确保获得最佳效果非常重要。
转到工作文件夹并检查创建的存储库代码。 然后导航到存储库文件夹。
git clone https://github.com/radoondas/flask-elastic-image-search.git
cd flask-elastic-image-search$ git clone https://github.com/radoondas/flask-elastic-image-search.git
Cloning into 'flask-elastic-image-search'...
remote: Enumerating objects: 105, done.
remote: Counting objects: 100% (105/105), done.
remote: Compressing objects: 100% (72/72), done.
remote: Total 105 (delta 37), reused 94 (delta 27), pack-reused 0
Receiving objects: 100% (105/105), 20.72 MiB | 9.75 MiB/s, done.
Resolving deltas: 100% (37/37), done.
$ cd flask-elastic-image-search/
$ pwd
/Users/liuxg/python/flask-elastic-image-search因为你将使用 Python 来运行代码,所以你需要确保满足所有要求并且环境已准备就绪。 现在创建虚拟环境并安装所有依赖项。
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
安装
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考如下的文章来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
特别注意的是:我们将以最新的 Elastic Stack 8.6.1 来进行展示。请参考 Elastic Stack 8.x 的文章进行安装。
启动白金版试用功能
由于上传模型是一个白金版的功能,我们需要启动试用功能。更多关于订阅的信息,请参考网址:订阅 | Elastic Stack 产品和支持 | Elastic。
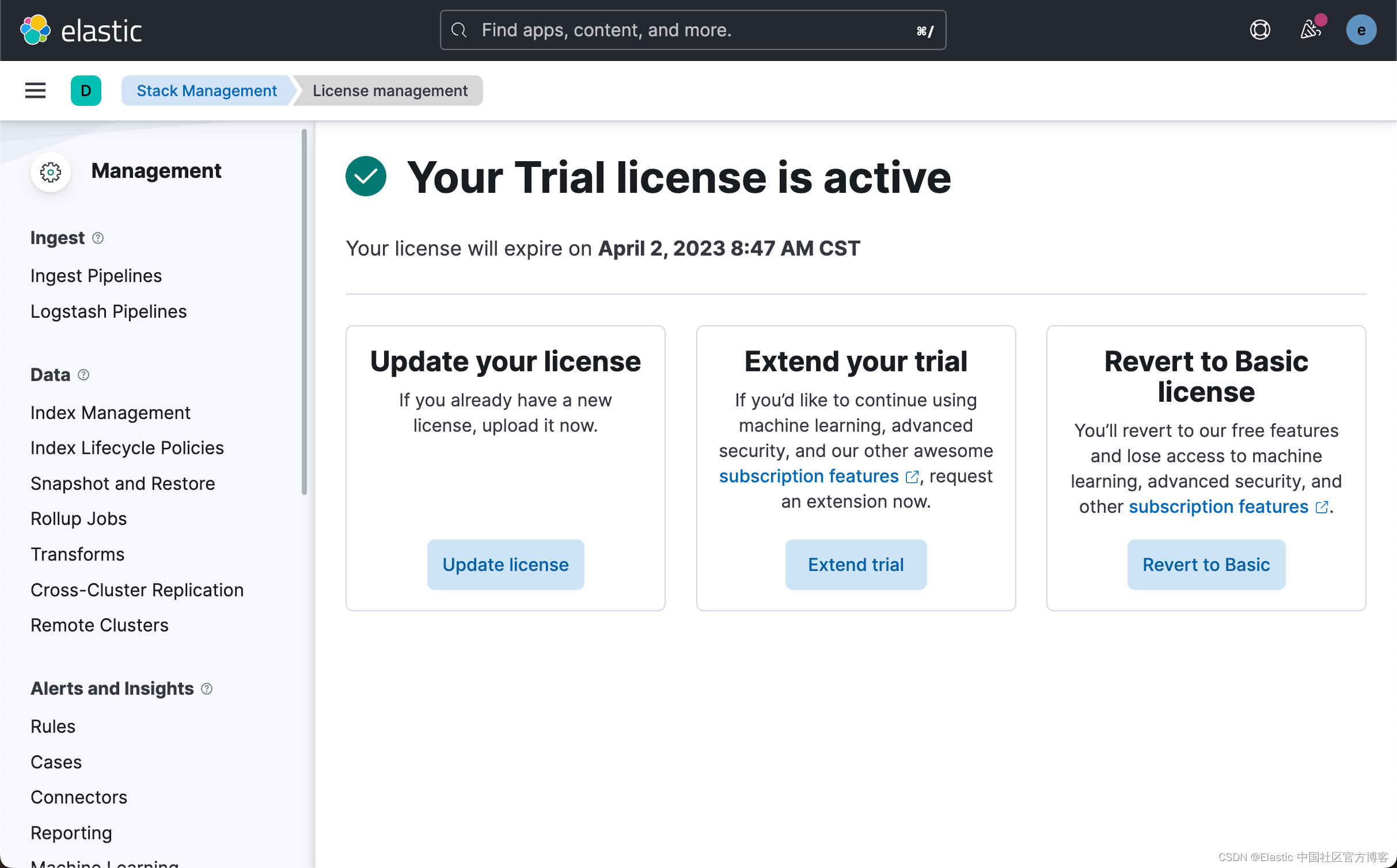
这样我们就成功地启动了白金版试用功能。
Elasticsearch 集群和嵌入模型
登录到你的帐户以启动 Elasticsearch 集群。 设置一个小型集群:
- 一个具有 2GB 内存的 HOT 节点
- 一个具有 4GB 内存的 ML(机器学习)节点(此节点的大小很重要,因为你将导入 Elasticsearch 的 NLP 模型会消耗约 1.5GB 的内存。)
部署准备就绪后,转到 Kibana 并检查机器学习节点的容量。 你将在视图中看到一个机器学习节点。 目前没有加载模型。
使用 Eland 库从 OpenAI 上传 CLIP 嵌入模型。 Eland 是一个 Python Elasticsearch 客户端,用于在 Elasticsearch 中探索和分析数据,能够处理文本和图像。 您将使用此模型从文本输入生成嵌入并查询匹配图像。 在 Eland 库的文档中找到更多详细信息。
对于下一步,你将需要 Elasticsearch 端点。 你可以从部署详细信息部分的 Elasticsearch 云控制台获取它。
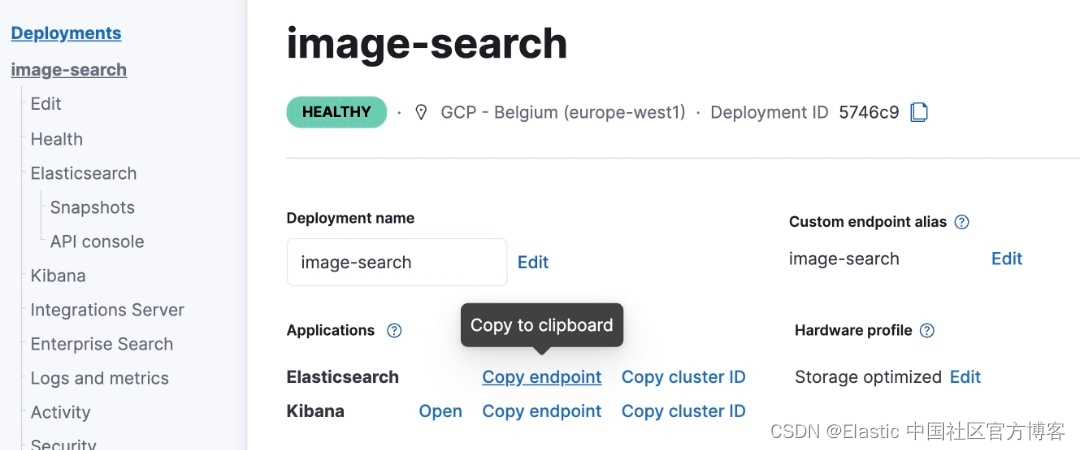
在本示例中,我们将使用本地部署来进行展示,所以,我们并不必要完成上面的步骤。
Eland
Eland 可以通过 pip 从 PyPI 安装。在安装之前,我们需要安装好自己的 Python。
$ python --version
Python 3.10.2可以使用 Pip 从 PyPI 安装 Eland:
python -m pip install eland也可以使用 Conda 从 Conda Forge 安装 Eland:
conda install -c conda-forge eland希望在不安装 Eland 的情况下使用它的用户,为了只运行可用的脚本,可以构建 Docker 容器:
git clone https://github.com/elastic/eland
cd eland
docker build -t elastic/eland .
Eland 将 Hugging Face 转换器模型到其 TorchScript 表示的转换和分块过程封装在一个 Python 方法中; 因此,这是推荐的导入方法。
- 安装 Eland Python 客户端。
- 运行 eland_import_hub_model 脚本。 例如:
eland_import_hub_model --url <clusterUrl> \
--hub-model-id elastic/distilbert-base-cased-finetuned-conll03-english \
--task-type ner - 指定 URL 以访问你的集群。 例如,https://<user>:<password>@<hostname>:<port>。
- 在 Hugging Face 模型中心中指定模型的标识符。
- 指定 NLP 任务的类型。 支持的值为 fill_mask、ner、text_classification、text_embedding, question_answering 和 zero_shot_classification。
上传模型
我们使用如下的命令来进行上传模型:
eland_import_hub_model --url https://<user>:<password>@<hostname>:<port> \--hub-model-id sentence-transformers/clip-ViT-B-32-multilingual-v1 \--task-type text_embedding \--ca-certs <your certificate> \--start针对我的情况:
eland_import_hub_model --url https://elastic:ZgzSt2vHNwA6yPn-fllr@localhost:9200 \--hub-model-id sentence-transformers/clip-ViT-B-32-multilingual-v1 \--task-type text_embedding \--ca-certs /Users/liuxg/elastic/elasticsearch-8.6.1/config/certs/http_ca.crt \--start请注意: 你需要根据自己的 Elasticsearch 访问端点,用户名及密码来修改上面的设置,同时你需要根据自己的配置修改上面的证书路径。
运行上面的命令:
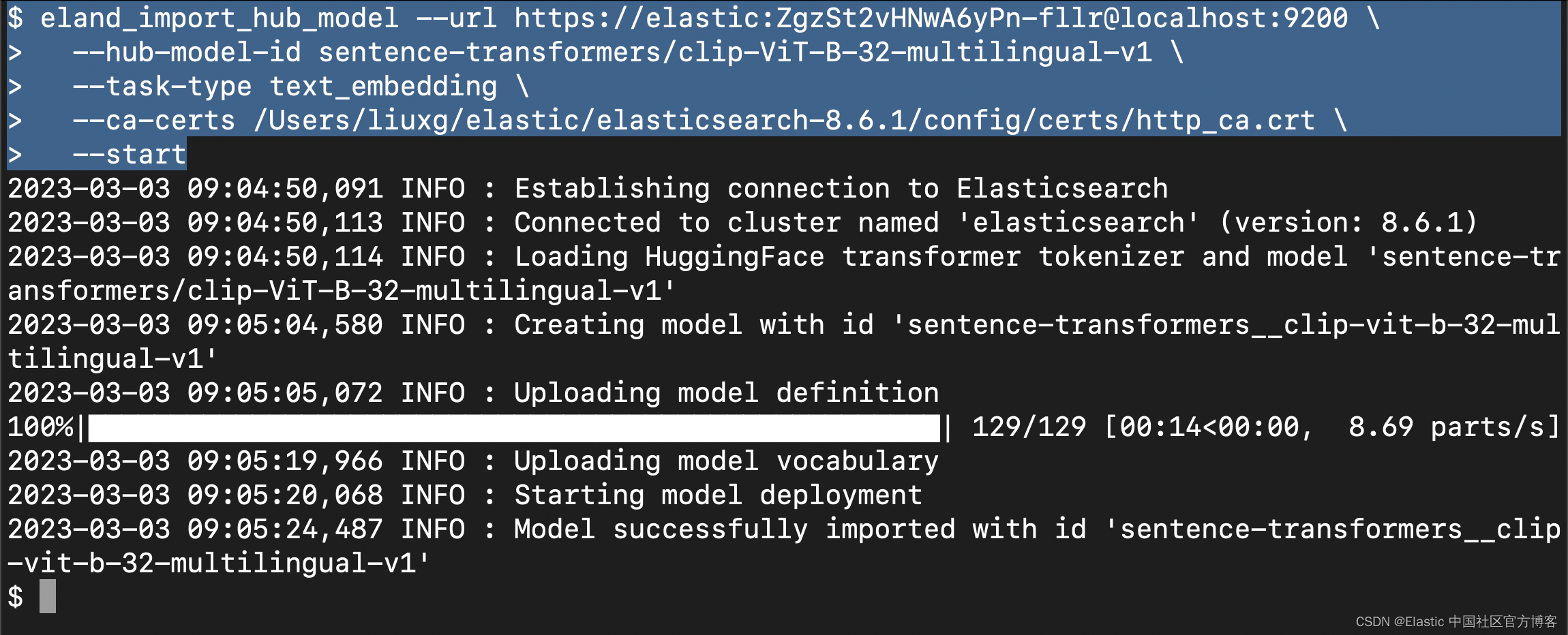
上面显示,我们已经成功地上传了模型。我们可以到 Kibana 中进行查看:
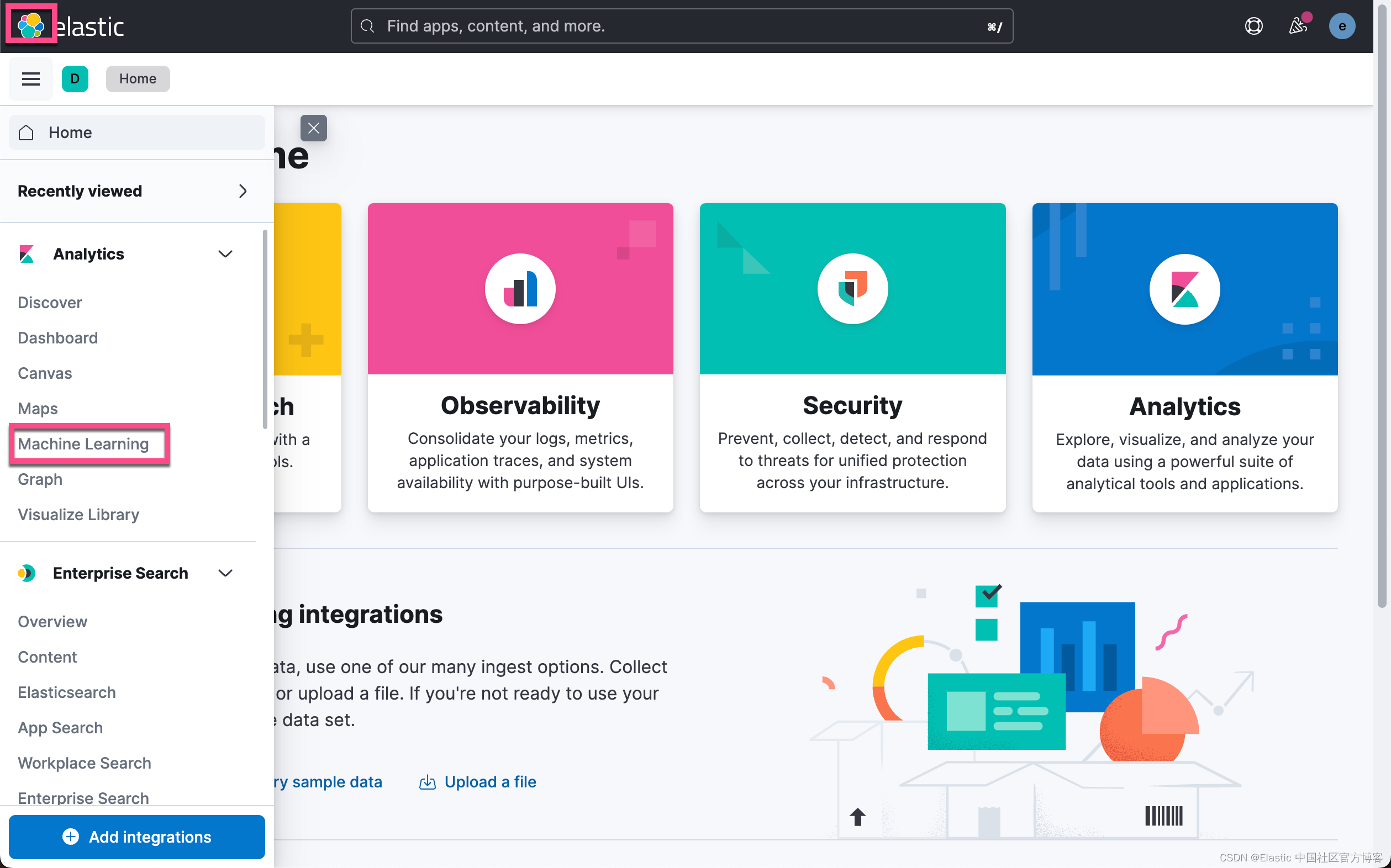
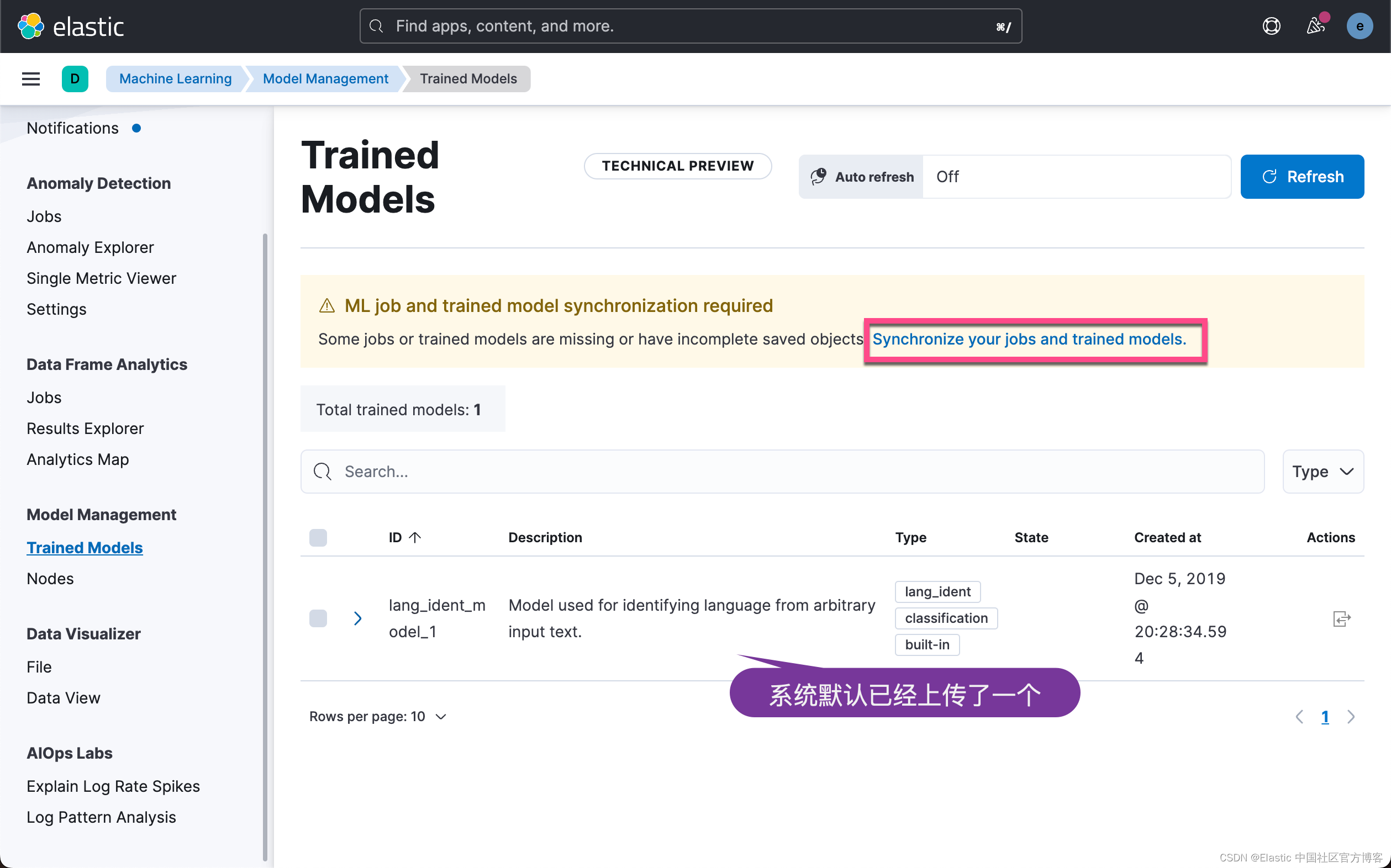
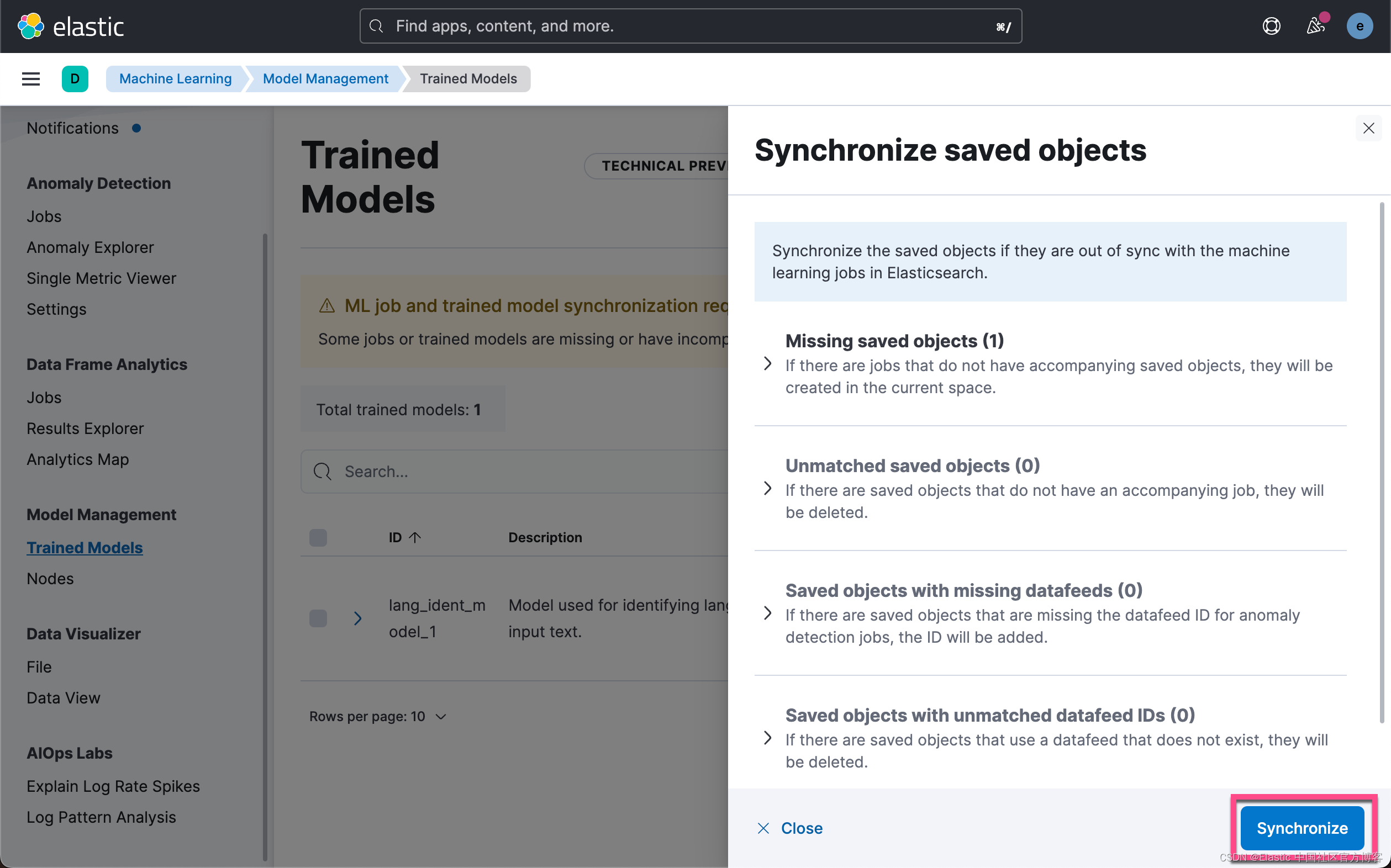
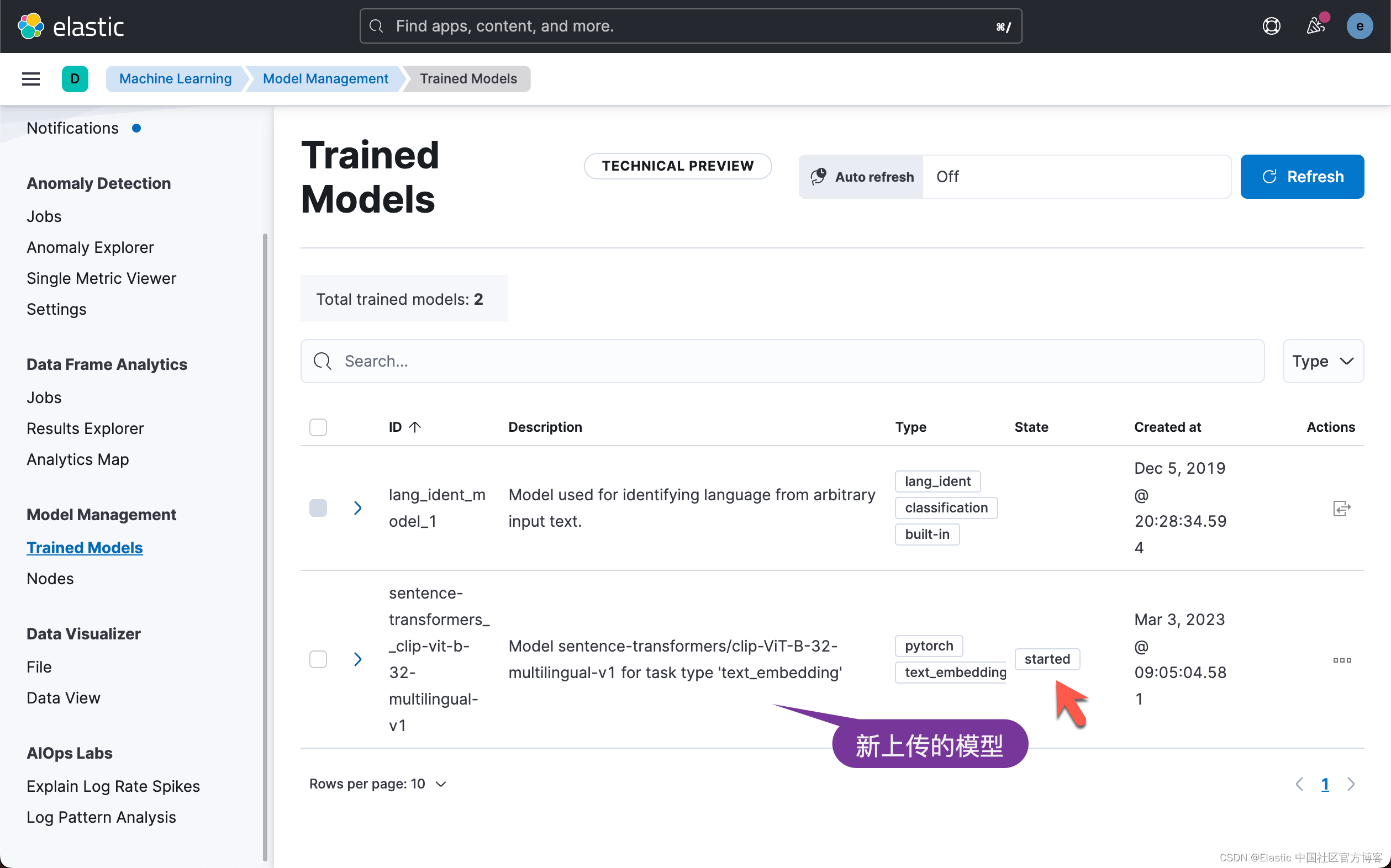
上面显示我们已经上传了所需要的 CLIP 模型,并且它的状态是 started。
如何创建图像嵌入
在设置 Elasticsearch 集群并导入嵌入模型后,你需要矢量化图像数据并为数据集中的每个图像创建图像嵌入。
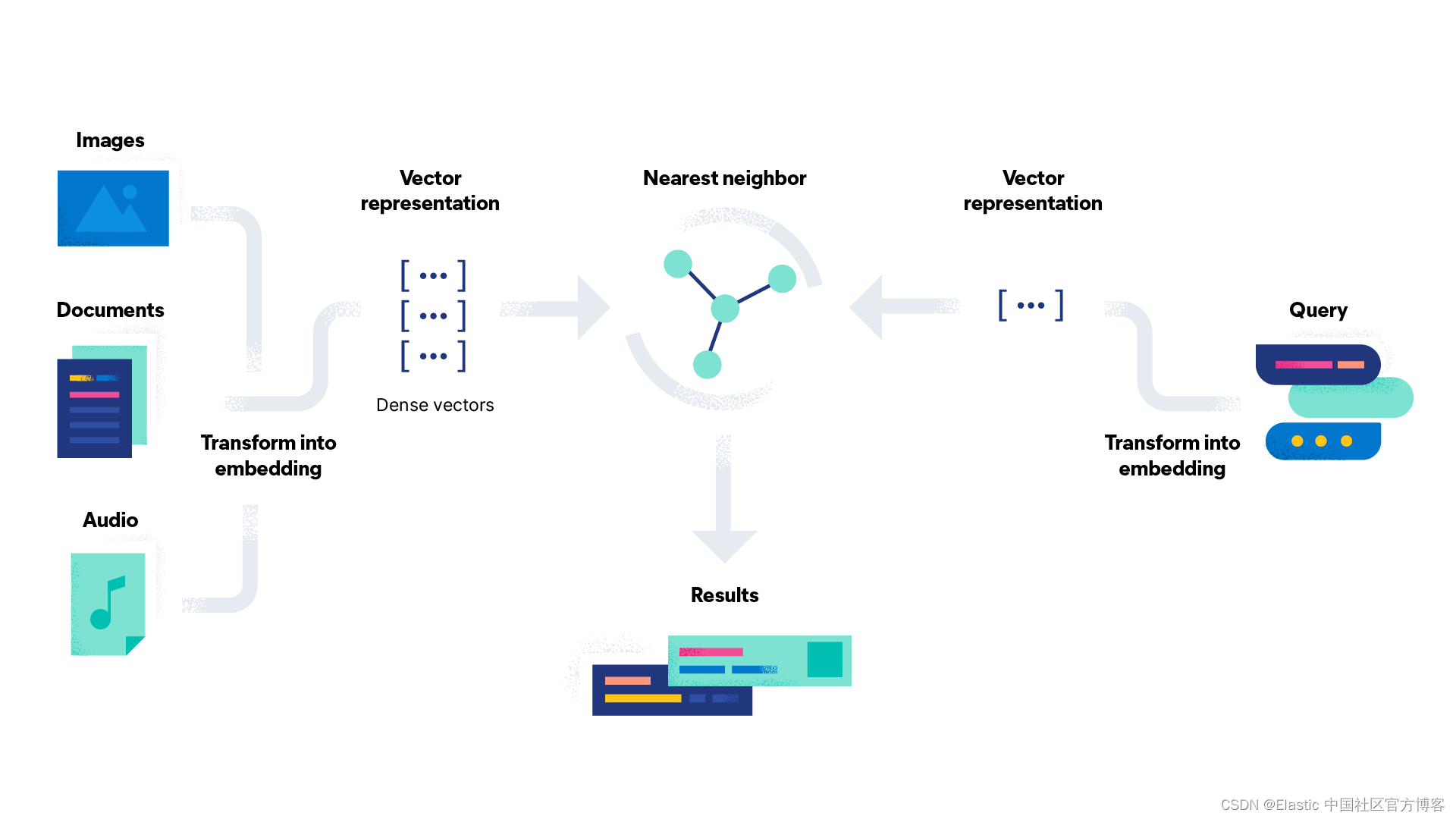
要创建图像嵌入,请使用简单的 Python 脚本。 你可以在此处找到该脚本:create-image-embeddings.py。 该脚本将遍历你的图像目录并生成单独的图像嵌入。 它将使用名称和相对路径创建文档,并使用提供的映射将其保存到 Elasticsearch 索引 my-image-embeddings 中。
将所有图像(照片)放入文件夹 app/static/images。 使用带有子文件夹的目录结构来组织图像。 所有图像准备就绪后,使用几个参数执行脚本。
至少要有几百张图像才能获得合理的结果,这一点至关重要。 图像太少不会产生预期的结果,因为你要搜索的空间非常小,而且到搜索向量的距离也非常相似。我尝试在网上下载很多的照片,但是感觉一张一张地下载非常麻烦。你可以在谷歌浏览器中添加插件 Image downloader - Imageye。它可以方便地把很多照片一次下载下来。
在 image_embeddings 文件夹中,运行脚本并为变量使用你的值。
cd image_embeddings
python3 create-image-embeddings.py \--es_host='https://localhost:9200' \--es_user='elastic' --es_password='ZgzSt2vHNwA6yPn-fllr' \--ca_certs='/Users/liuxg/elastic/elasticsearch-8.6.1/config/certs/http_ca.crt'根据图像的数量、它们的大小、你的 CPU 和你的网络连接,此任务将需要一些时间。 在尝试处理完整数据集之前,先试验少量图像。脚本完成后,吧可以使用 Kibana 开发工具验证索引 my-image-embeddings 是否存在并具有相应的文档。
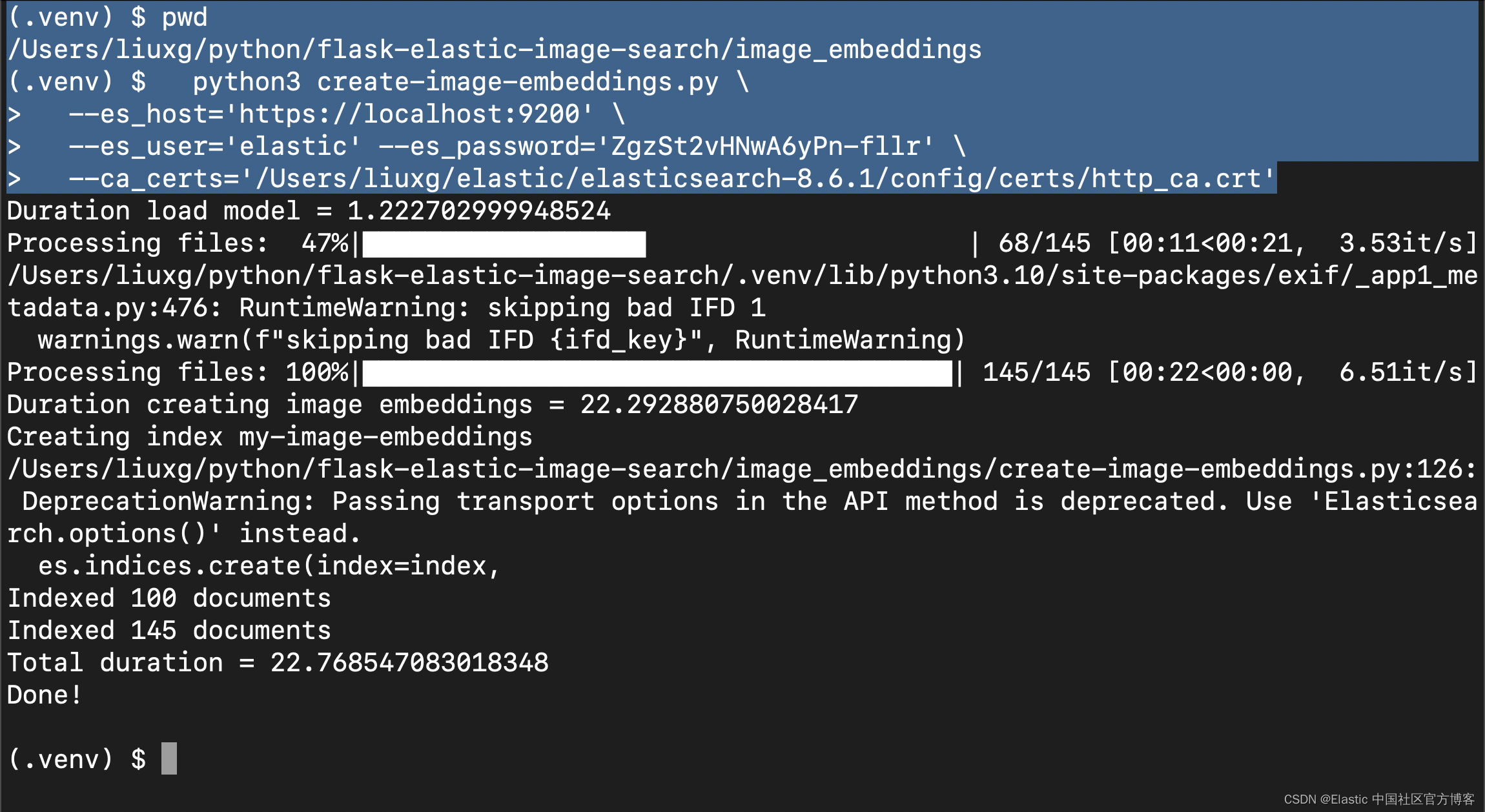
我们在Kibana 中进行查看:
GET _cat/indices/my-image-embeddings?v上面命令的响应为:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
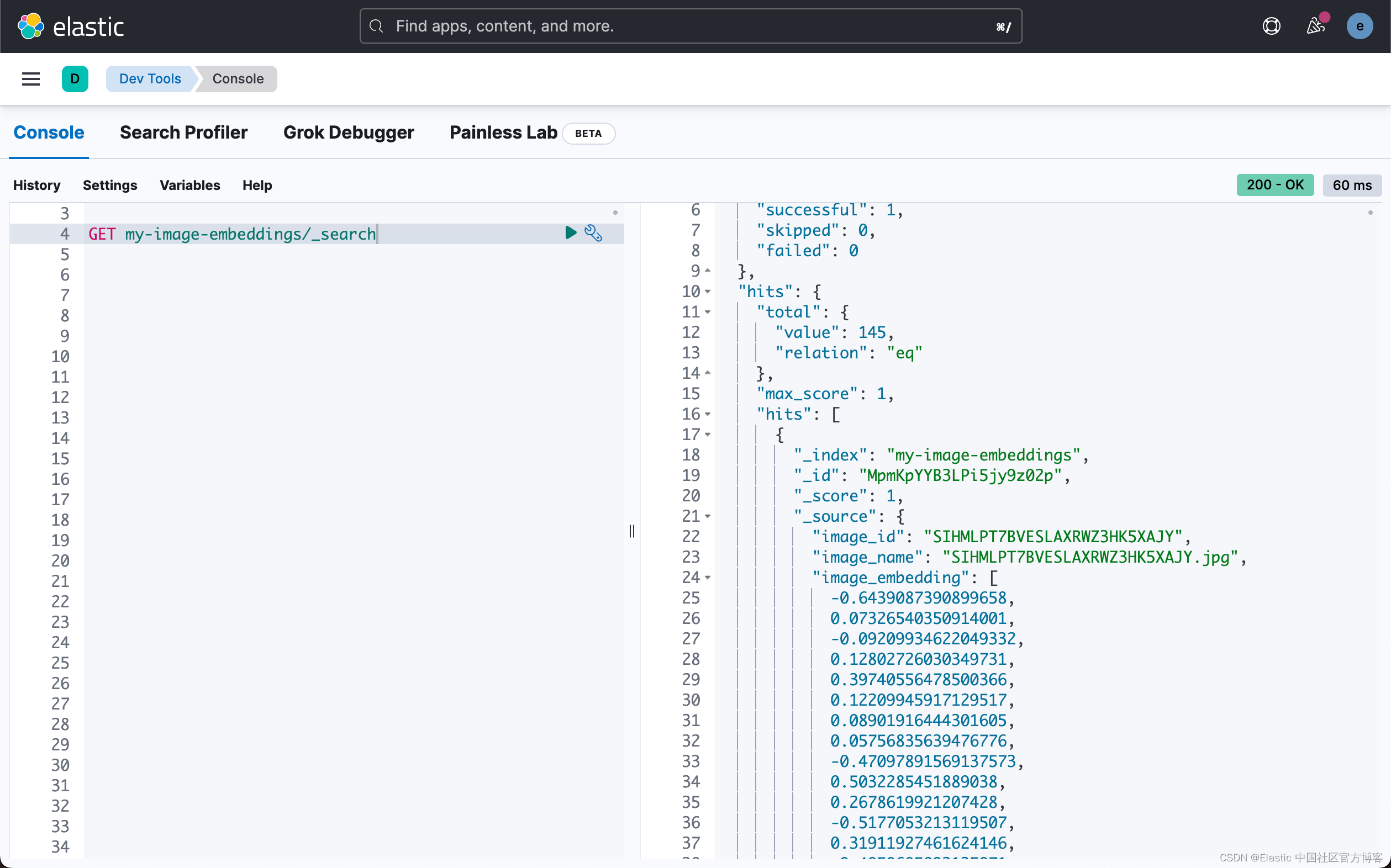
yellow open my-image-embeddings h6oUBdHCScWmXOZaf57oWg 1 1 145 0 1.4mb 1.4mb查看文档,你会看到非常相似的 JSON 对象(如示例)。 你将在图像文件夹中看到图像名称、图像 ID 和相对路径。 此路径用于前端应用程序以在搜索时正确显示图像。JSON 文档中最重要的部分是包含 CLIP 模型生成的密集矢量的 image_embedding。 当应用程序正在搜索图像或类似图像时使用此矢量。
GET my-image-embeddings/_search{"_index": "my-image-embeddings","_id": "_g9ACIUBMEjlQge4tztV","_score": 6.703597,"_source": {"image_id": "IMG_4032","image_name": "IMG_4032.jpeg","image_embedding": [-0.3415695130825043,0.1906963288784027,.....-0.10289803147315979,-0.15871885418891907],"relative_path": "phone/IMG_4032.jpeg"}
}
使用 Flask 应用程序搜索图像
现在你的环境已全部设置完毕,你可以进行下一步,使用我们作为概念证明提供的 Flask 应用程序,使用自然语言实际搜索图像并查找相似图像。 该 Web 应用程序具有简单的 UI,使图像搜索变得简单。 你可以在此 GitHub 存储库中访问原型 Flask 应用程序。
后台应用程序执行两个任务。 在搜索框中输入搜索字符串后,文本将使用机器学习 _infer 端点进行矢量化。 然后,针对带有向量的索引 my-image-embeddings 执行带有密集向量的查询。
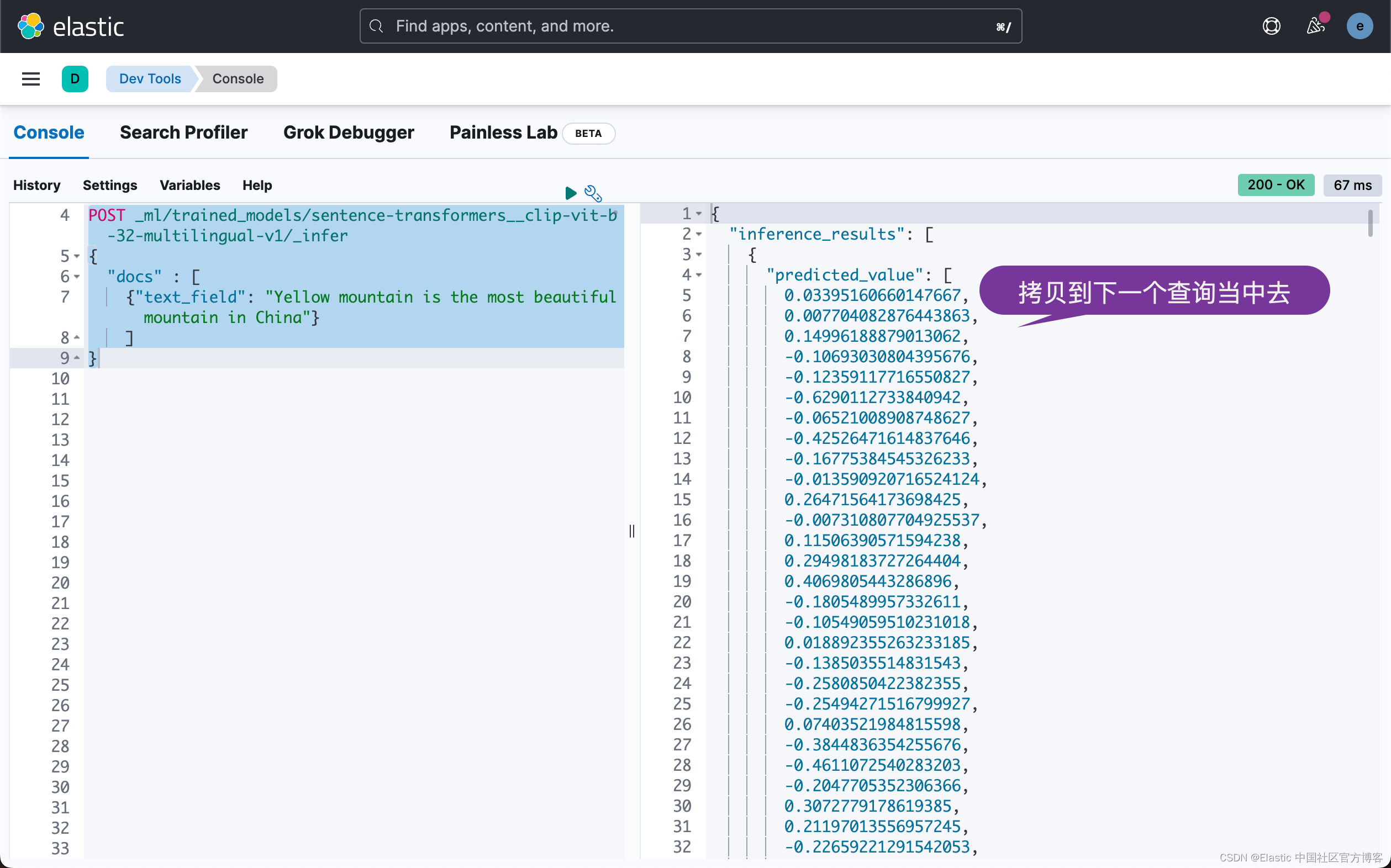
你可以在示例中看到这两个查询。 第一个 API 调用使用 _infer 端点,结果是一个密集矢量。
POST _ml/trained_models/sentence-transformers__clip-vit-b-32-multilingual-v1/_infer
{"docs" : [{"text_field": "Yellow mountain is the most beautiful mountain in China"}]
}上面的响应如下:
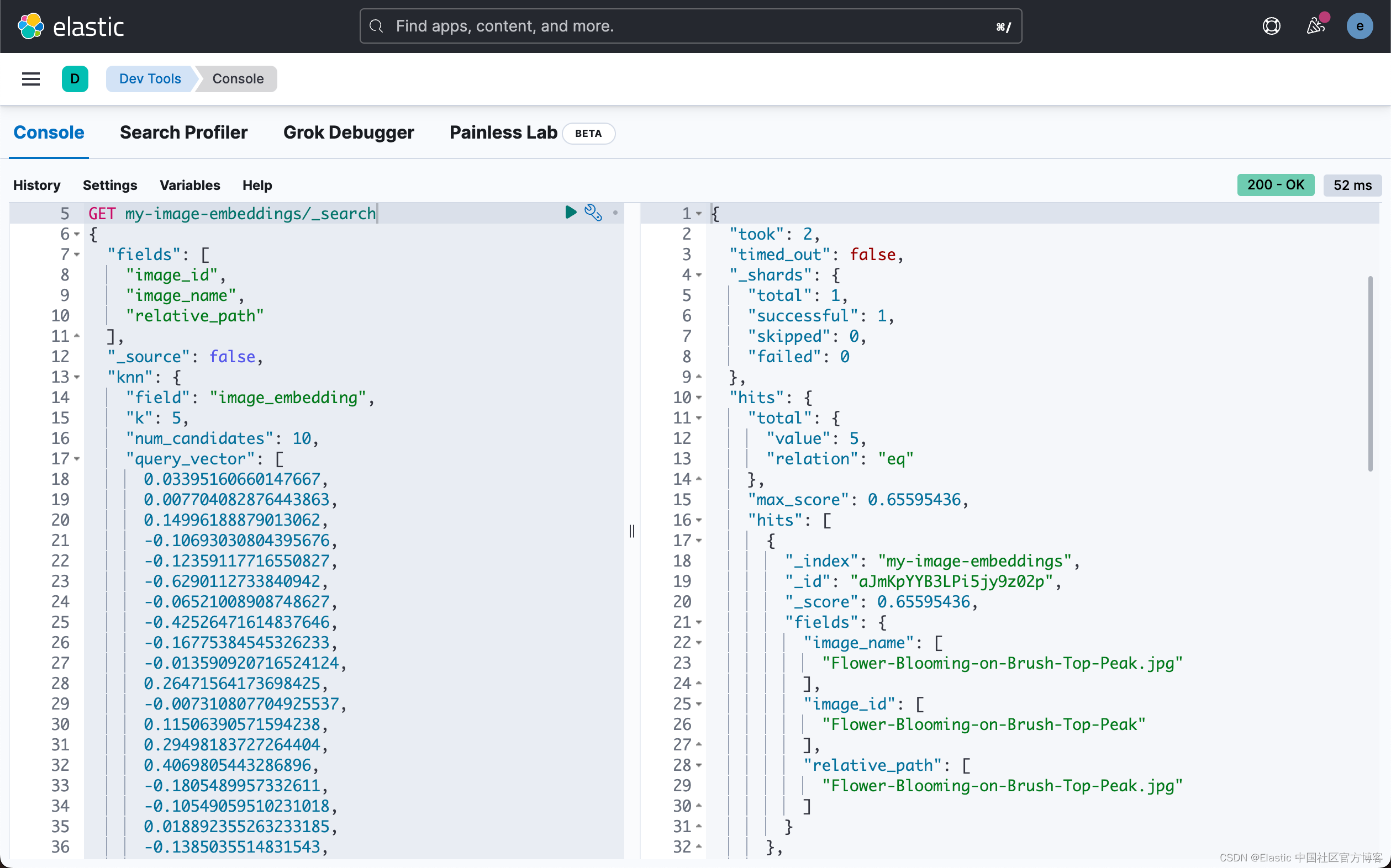
在第二个任务中,搜索查询,我们将使用密集矢量并获得按分数排序的图像。
GET my-image-embeddings/_search
{"fields": ["image_id","image_name","relative_path"],"_source": false,"knn": {"field": "image_embedding","k": 5,"num_candidates": 10,"query_vector": [0.03395160660147667,0.007704082876443863,0.14996188879013062,-0.10693030804395676,...0.05140634626150131,0.07114913314580917]}
}
要启动并运行 Flask 应用程序,请导航到存储库的根文件夹并配置 .env 文件。 配置文件中的值用于连接到 Elasticsearch 集群。 你需要为以下变量插入值。 这些与图像嵌入生成中使用的值相同。
.env
ES_HOST='URL:PORT'
ES_USER='elastic'
ES_PWD='password'为了能够使得我们自构建的 Elasticsearch 集群能够被正确地访问,我们必须把 Elasticsearch 的根证书拷贝到 Flask 应用的相应目录中:
flask-elastic-image-search/app/conf/ca.crt
(.venv) $ pwd
/Users/liuxg/python/flask-elastic-image-search/app/conf
(.venv) $ cp ~/elastic/elasticsearch-8.6.1/config/certs/http_ca.crt ca.crt
overwrite ca.crt? (y/n [n]) y在上面,我们替换了仓库中原有的证书文件 ca.crt。
准备就绪后,运行主文件夹中的 flask 应用程序并等待它启动。
# In the main directory
$ flask run --port=5001如果应用程序启动,你将看到类似于下面的输出,它在末尾指示你需要访问哪个 URL 才能访问该应用程序。
恭喜! 你的应用程序现在应该已启动并正在运行,并且可以通过互联网浏览器在 http://127.0.0.1:5001 上访问。
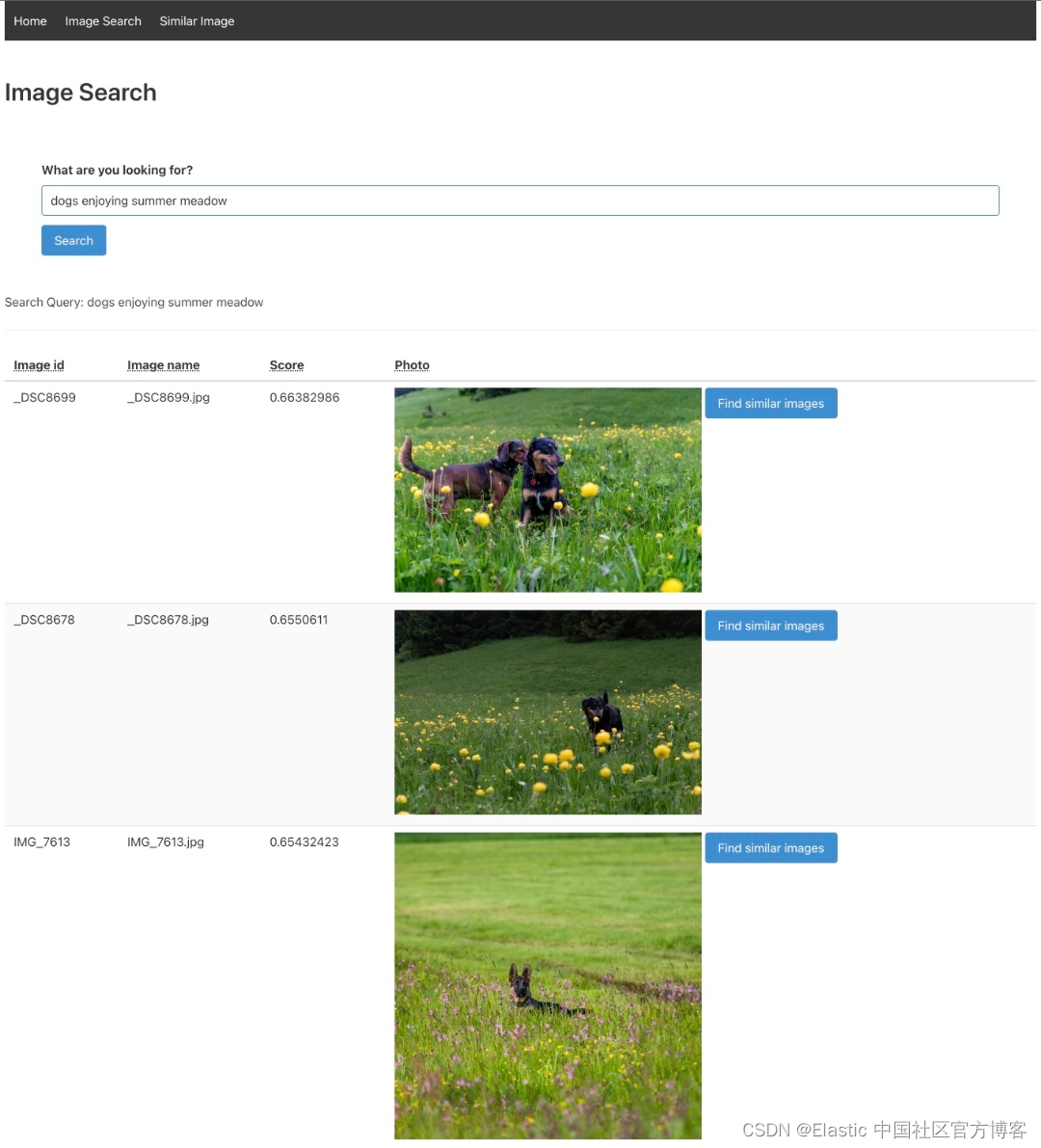
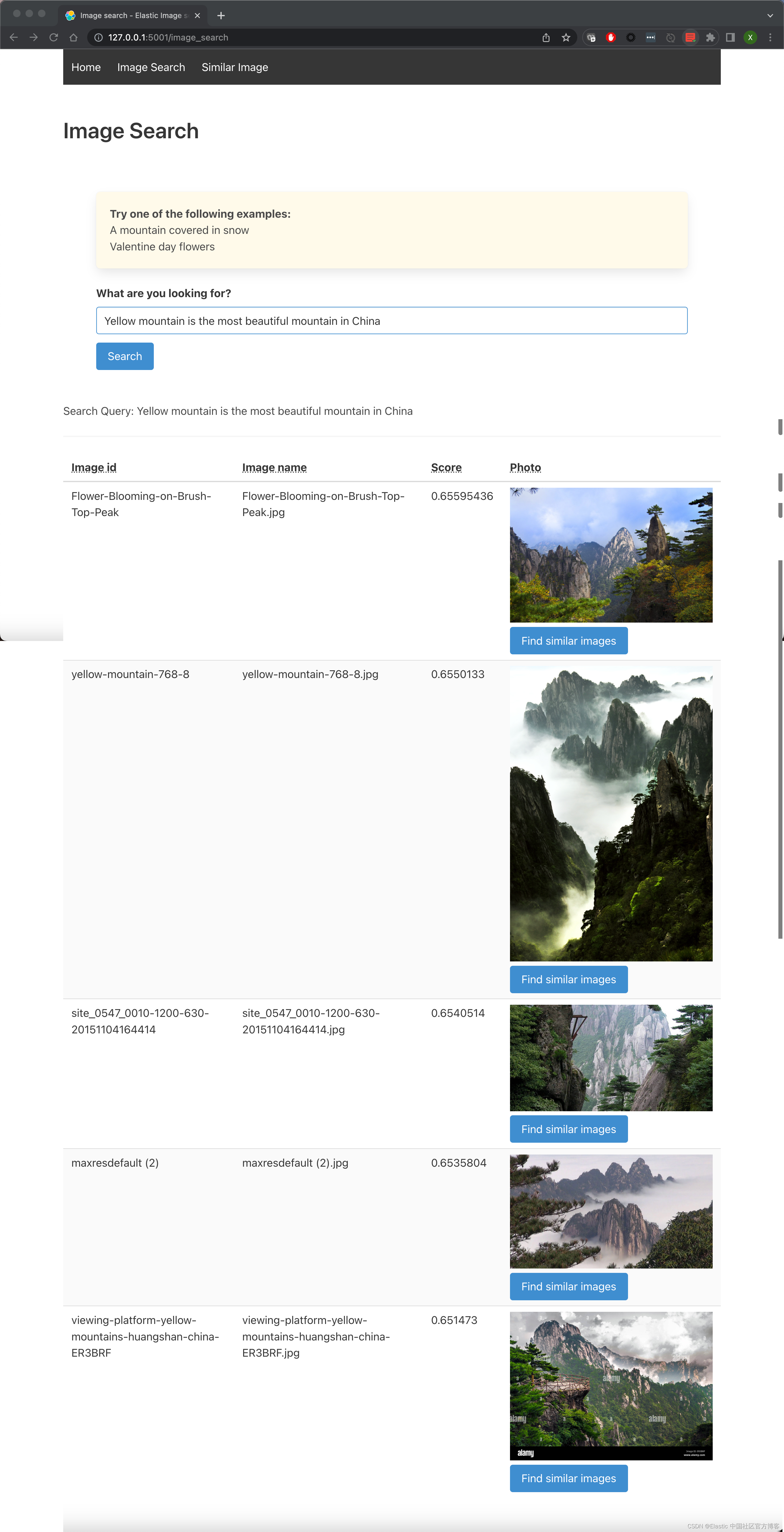
导航到图像搜索选项卡并输入描述你最佳图像的文本。 尝试使用非关键字或描述性文字。
在下面的示例中,输入的文本是 “Yellow mountain is the most beautiful mountain in China”。 结果显示在我们的数据集中。 如果用户喜欢结果集中的一张特定图像,只需单击它旁边的按钮,就会显示类似的图像。 用户可以无限次地这样做,并通过图像数据集构建自己的路径。
我们尝试另外的一个例子。这次我们输入:I love beautiful girls。
搜索也可以通过简单地上传图像来进行。 该应用程序会将图像转换为矢量并在数据集中搜索相似的图像。 为此,导航到第三个选项卡 “Similar Image”,从磁盘上传图像,然后点击 “Search”。
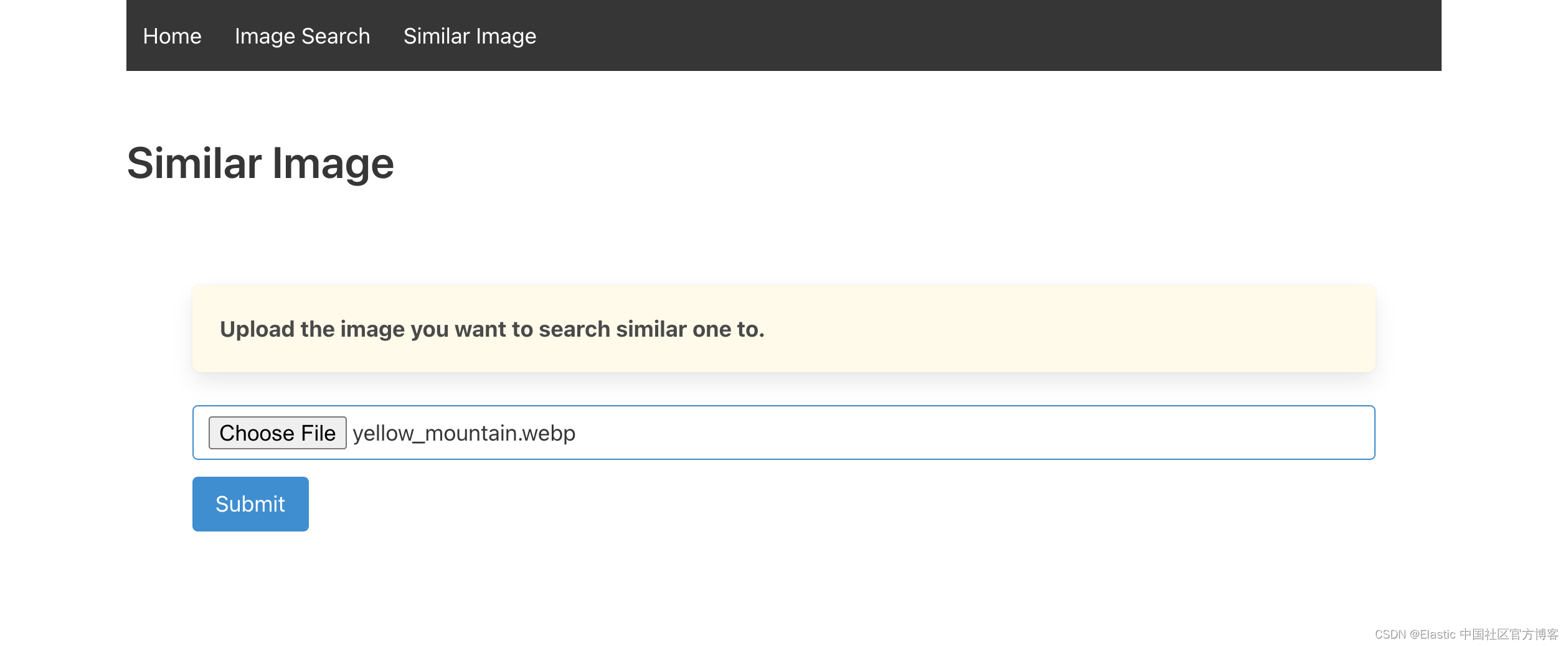
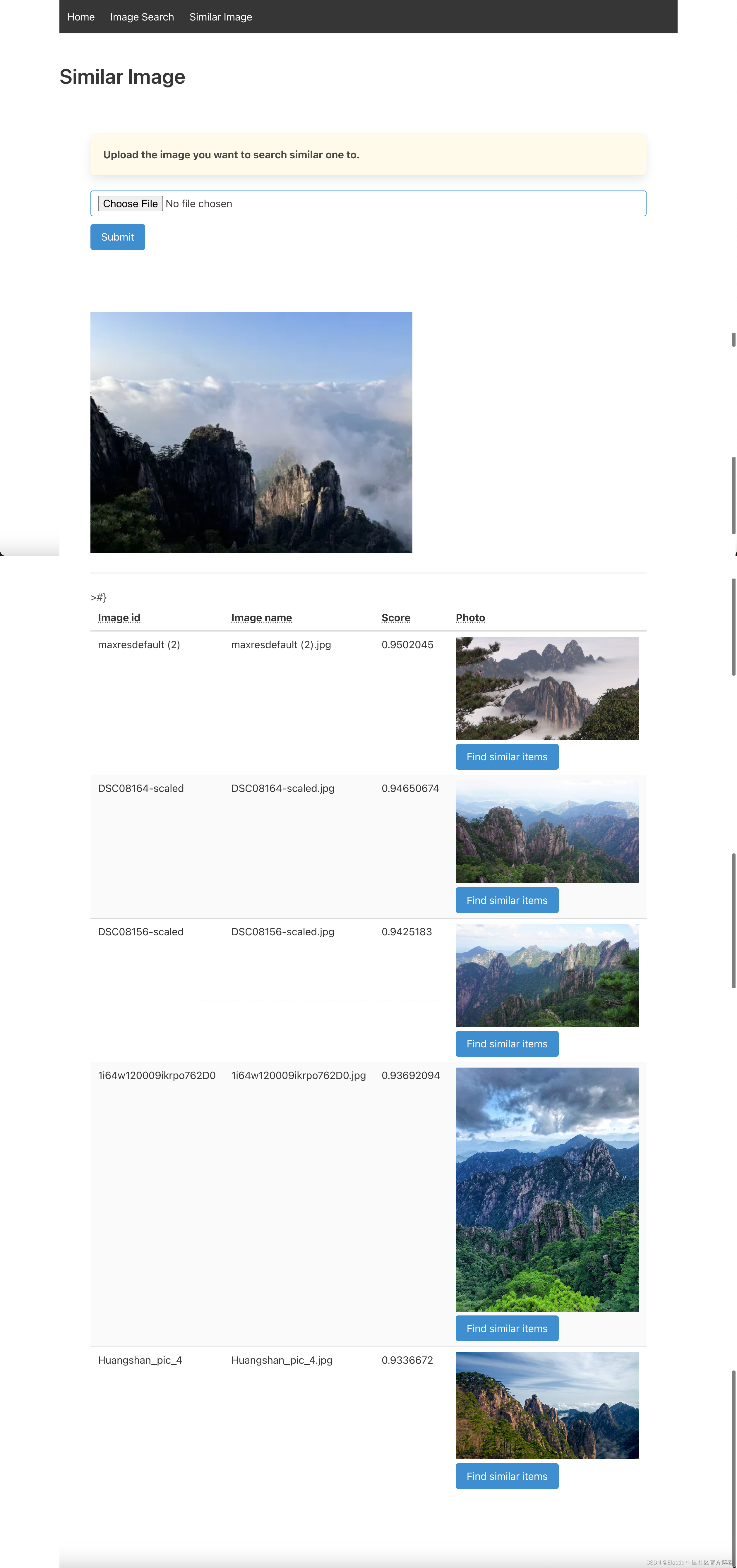
我们可以看到相似的图片。我们尝试使用一个女孩的照片再试试:
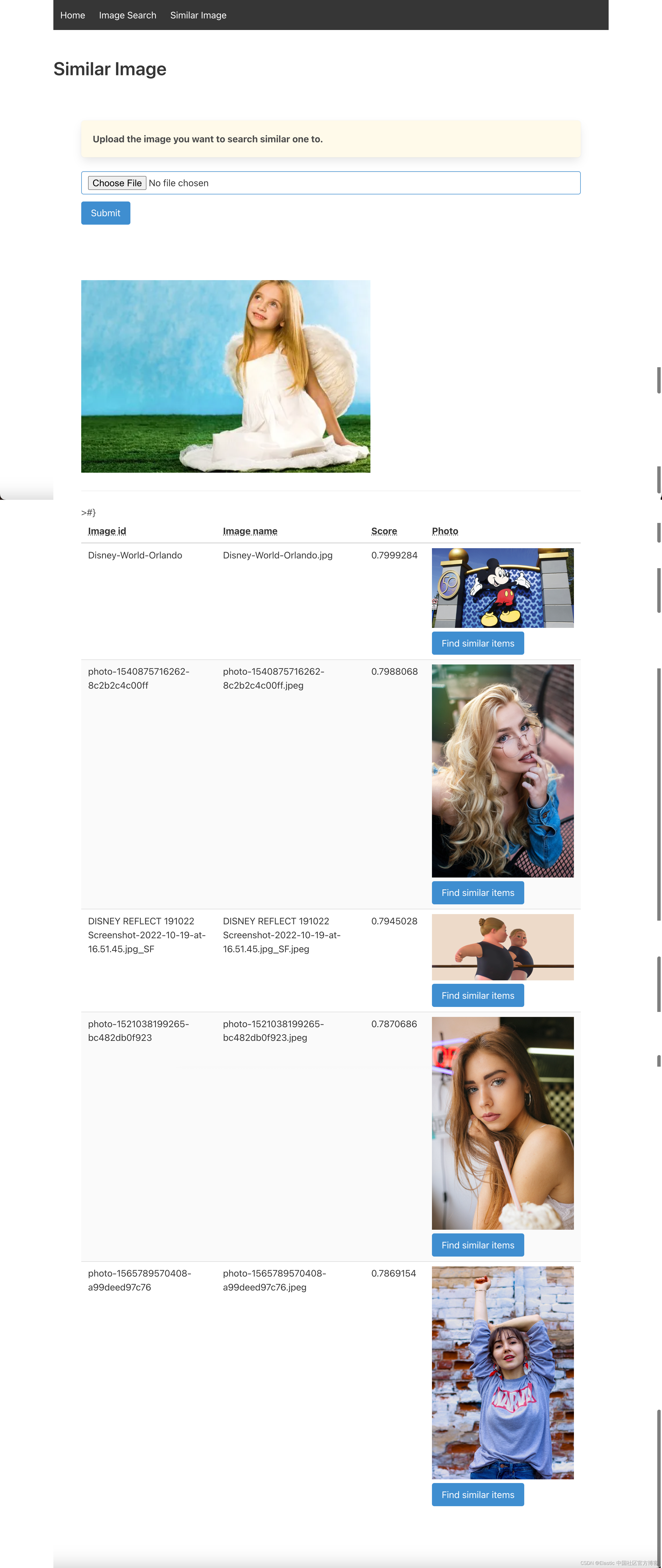
因为我们在 Elasticsearch 中使用的 NLP(sentence-transformers/clip-ViT-B-32-multilingual-v1)模型是多语言的,支持多语言推理,所以尽量搜索自己语言的图片。 然后也使用英文文本验证结果。我们尝试使用 “黄山是中国最漂亮的山”:
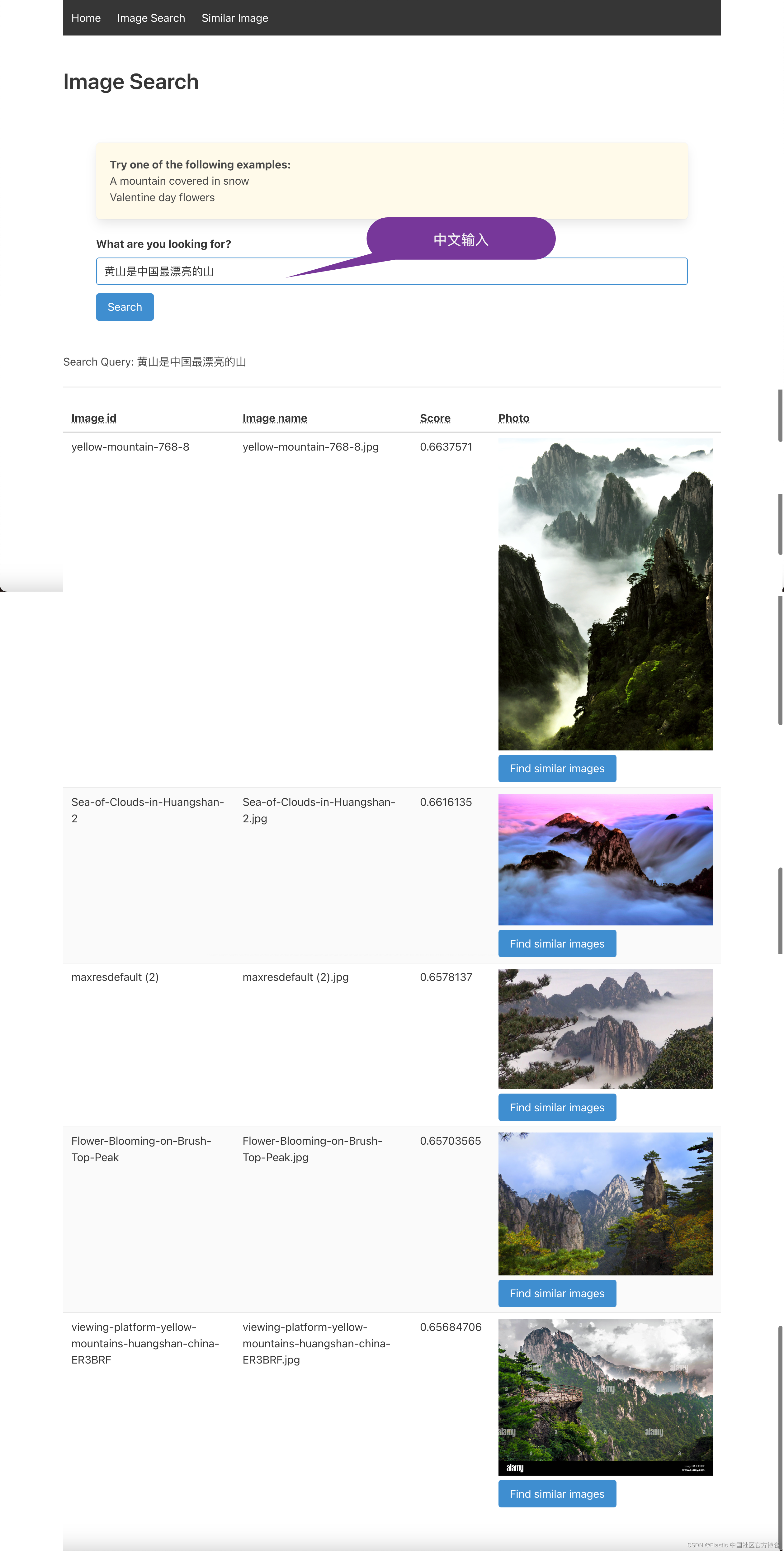
请务必注意,使用的模型是通用模型,这些模型非常准确,但你获得的结果会因用例或其他因素而异。 如果你需要更高的精度,则必须采用通用模型或开发自己的模型 —— CLIP 模型只是一个起点。
代码摘要
你可以在 GitHub 存储库中找到完整的代码。 你可能正在检查 routes.py 中的代码,它实现了应用程序的主要逻辑。 除了明显的路线定义之外,你还应该关注定义 _infer 和 _search 端点(infer_trained_model 和 knn_search_images)的方法。 生成图像嵌入的代码位于 create-image-embeddings.py文件中。
总结
现在你已经设置了 Flask 应用程序,你可以轻松地搜索你自己的图像集! Elastic 在平台内提供了矢量搜索的原生集成,避免了与外部进程的通信。 你可以灵活地开发和使用你可能使用 PyTorch 开发的自定义嵌入模型。
语义图像搜索具有其他传统图像搜索方法的以下优点:
- 更高的准确度:向量相似性捕获上下文和关联,而不依赖于图像的文本元描述。
- 增强的用户体验:与猜测哪些关键字可能相关相比,描述你正在寻找的内容或提供示例图像。
- 图像数据库的分类:不用担心对图像进行分类——相似性搜索可以在一堆图像中找到相关图像,而无需对它们进行组织。
如果你的用例更多地依赖于文本数据,你可以在以前的博客中了解更多关于实现语义搜索和将自然语言处理应用于文本的信息。 对于文本数据,向量相似度与传统关键词评分的结合呈现了两全其美的效果。
准备好开始了吗? 在我们的虚拟活动中心报名参加矢量搜索实践研讨会,并在我们的在线论坛中与社区互动。
相关文章:
Elasticsearch:如何在 Elastic 中实现图片相似度搜索
作者:Radovan Ondas 在本文章,我们将了解如何通过几个步骤在 Elastic 中实施相似图像搜索。 开始设置应用程序环境,然后导入 NLP 模型,最后完成为你的图像集生成嵌入。 Elastic 图像相似性搜索概览 >> 如何设置环境 第一步…...
)
一起Talk Android吧(第五百二十三回:获取位置信息经验总结)
文章目录 整体概述位置权限与蓝牙权限综合使用特殊机型的使用方法官方建议各位看官们大家好,上一回中咱们说的例子是"如何有效地获取位置权限",这一回中咱们说的例子是" 获取位置信息经验总结"。闲话休提,言归正转, 让我们一起Talk Android吧! 整体概…...

发光立方体效果 html+css
一.话不多,看效果 css简单创意特效,关注我看更多简单创意特效~ 二.实现(附完整代码) 定义标签: <div class"container"><div class"q1"></div><div class"h2"&…...
READ: Large-Scale Neural Scene Rendering for Autonomous Driving
READ: Large-Scale Neural Scene Rendering for Autonomous Driving :面向自动驾驶的大规模神经场景绘制 门卷积 https://www.jianshu.com/p/09fc8490104d https://blog.csdn.net/weixin_44996354/article/details/117409438摘要:论文提出了一种大规模神…...
Linux环境C语言开发基础
C语言是一门面向过程的计算机编程语言,与C、C#、Java等面向对象编程语言有所不同。C语言的设计目标是提供一种能以简易的方式编译、处理低级存储器、仅产生少量的机器码以及不需要任何运行环境支持便能运行的编程语言。C语言诞生于美国的贝尔实验室,由丹…...
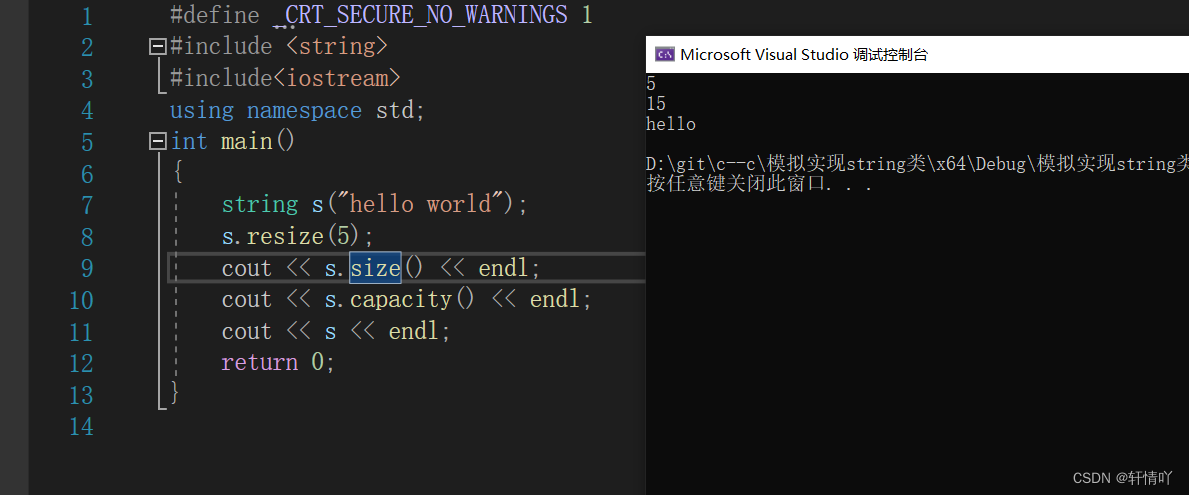
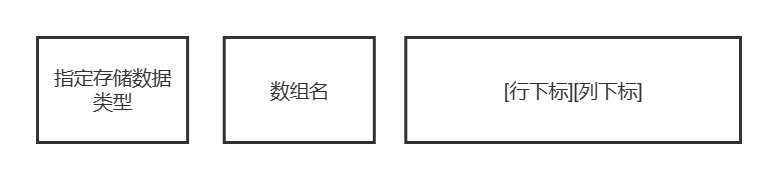
string类(上)
string类(上)1.标准库中的string类2.string类对象的常见构造①string()②string(const char* s)③string(size_t n,char c)④string(const string&s)⑤string(const string& str,size_t pos,size_t lennpos)⑥string(const char* s,s…...
ElasticSearch快速入门详解(亲测好用,强烈推荐收藏)
3.快速入门 接下来快速看下elasticsearch的使用 3.1.概念 Elasticsearch虽然是一种NoSql库,但最终的目的是存储数据、检索数据。因此很多概念与MySQL类似的。 ES中的概念数据库概念说明索引库(indices)数据库(Database)ES中可…...
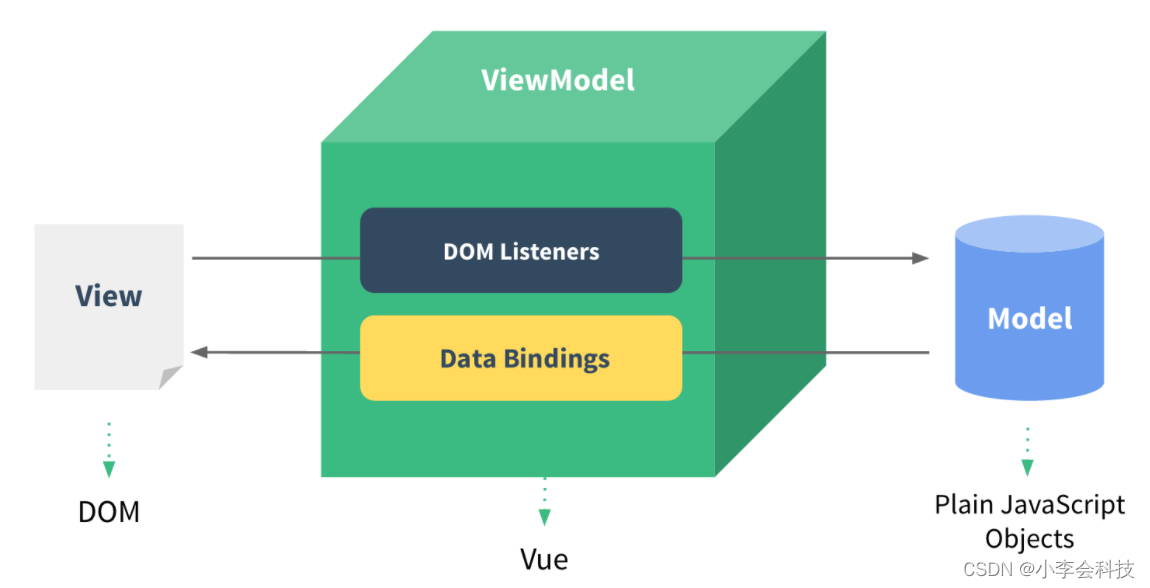
出入了解——Vue.js
个人简介:云计算网络运维专业人员,了解运维知识,掌握TCP/IP协议,每天分享网络运维知识与技能。座右铭:海不辞水,故能成其大;山不辞石,故能成其高。个人主页:小李会科技的…...
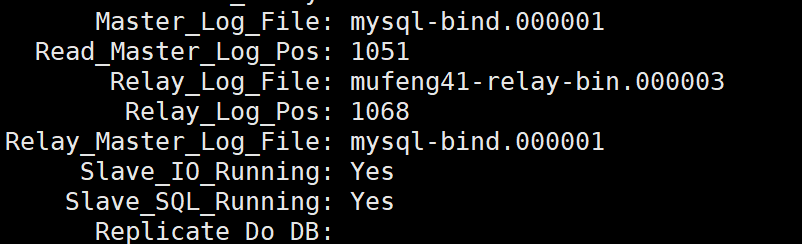
MySQL8 双主(主主)架构部署实战
前言 大家好,我是 沐风晓月 本文收录于《数据库入门到精通系列》专栏, 更多内容可以关注我的csdn博客。 本文主要讲解MySQL主主架构实战,在开始之前需要根据下面的提示来配置环境: Linux基础命令不熟参考: 《linux基本功-基础…...
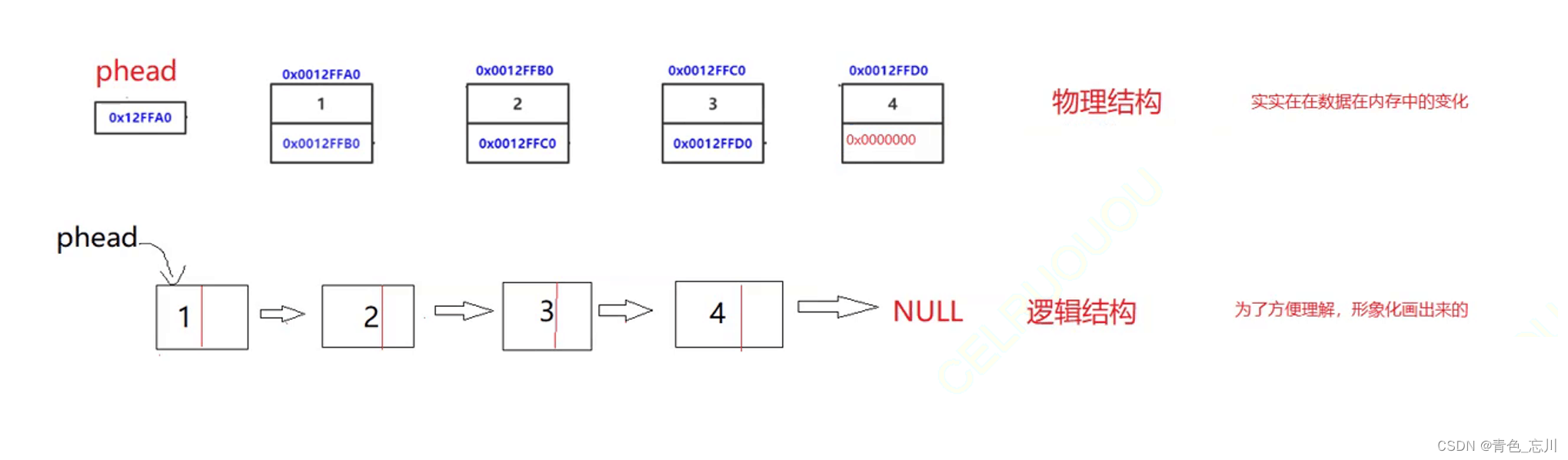
【数据结构】第三站:单链表
目录 一、顺序表的缺陷 二、链表 1.链表的概念以及结构 2.链表的分类 3.单链表的逻辑结构与物理结构 三、单链表的实现 1.单链表的定义 2.单链表的接口定义 3.单链表的接口实现 四、单链表的实现完整代码 一、顺序表的缺陷 在上一篇文章中,我们了解了顺序…...
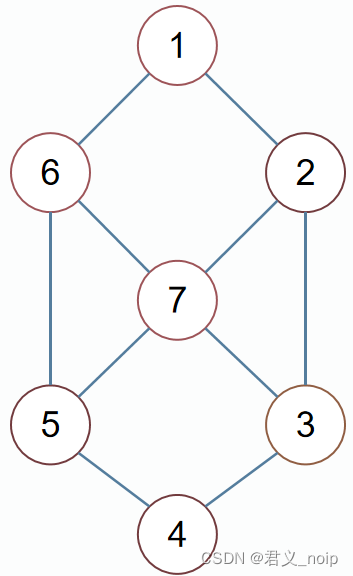
【蓝桥杯2020】七段码
【题目描述】 七段码 HUSTOJ 题目导出文件 [蓝桥杯2020] 第十一届蓝桥杯第二次省赛—填空题E题 七段码 小蓝要用七段码数码管来表示一种特殊的文字。 上图给出了七段码数码管的一个图示,数码管中一共有 7 段可以发光的二 极管,分别标记为 a, b, c,…...
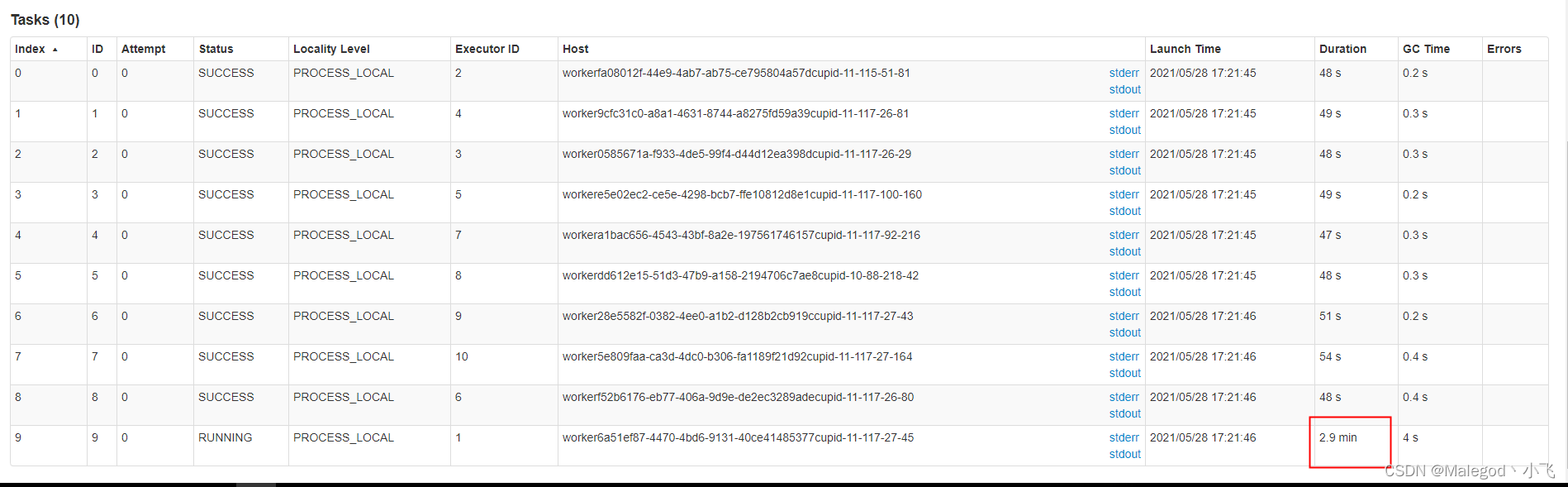
Spark读取JDBC调优
Spark读取JDBC调优,如何调参一、场景构建二、参数设置1.灵活运用分区列实际问题:工作中需要读取一个存放了三四年历史数据的pg数仓表(缺少主键id),需要将数据同步到阿里云 MC中,Spark在使用JDBC读取关系型数…...

【文心一言】什么是文心一言,如何获得内测和使用方法。
文心一言什么是文心一言怎么获得内测资格接下来就给大家展示一下文学创作商业文案创作数理逻辑推算中文理解多模态生成用python写一个九九乘法表写古诗前言: 🏠个人主页:以山河作礼。 📝📝:本文章是帮助大家了解文心…...
CentOS8服务篇10:FTP服务器配置与管理
一、安装与启动FTP服务器 1、安装VSFTP服务器所需要的安装包 #yum -y install vsftpd 2、查看配置文件参数 Vim /etc/vsftpd/vsftpd.conf (1)是否允许匿名登录 anonymous_enableYES 该行用于控制是否允许匿名用户登录。 (2&…...

笔试强训3.14
一、选择题 1.以下说法错误的是(C) A.数组是一个对象 B.数组不是一种原生类 C.数组的大小可以任意改变 D.在Java中,数组存储在堆中连续内存空间里 相关知识点:原生/内置数组是那八个,其他的都是引用的,借…...

elasticsearch 环境搭建和基本操作
参考资料 适合后端编程人员的elasticsearch快速实战教程 ElasticSearch最新实战教程 ElasticSearch配套笔记 自制搜索引擎 https://www.elastic.co/guide/en/elasticsearch/reference/7.17/setup.html restful风格的api REST 设计风格 例如以下springboot示例 RestContr…...
IDEA操作:Springboot项目打包为jar包并运行
在IDEA环境下对Springboot项目打包为jar包且在terminal运行操作 1、 2、 3、注意:在项目目录里创建一个用来存放jar包的文件夹(res),该路径不能使用IDEA设置的默认路径,必须手动创建。 4、 5、点击ok后加载运行包 (8…...
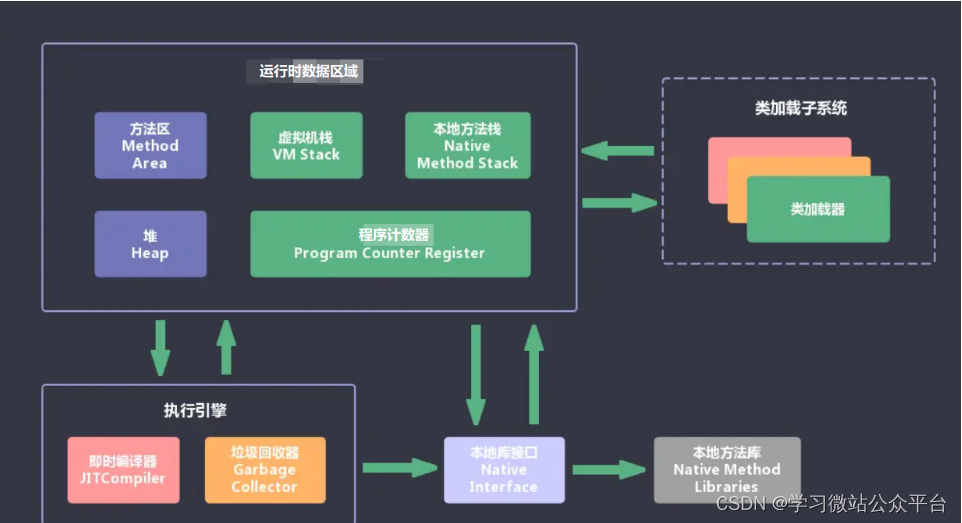
原理底层计划---JVM
二、JVM对空间大小怎么配置?各区域怎么划? 新生代:短时间生成,可以马上回收 老生代:少部分对象会存在很久,回收策略应不同 三、JVM哪些内存区域会发生内存溢出(程序计数器不会) …...

CSDN-猜年龄、纸牌三角形、排他平方数
猜年龄 原题链接:https://edu.csdn.net/skill/practice/algorithm-a413078fb6e74644b8c9f6e28896e377/2258 美国数学家维纳(N.Wiener)智力早熟,11岁就上了大学。他曾在1935~1936年应邀来中国清华大学讲学。 一次,他参加某个重要会议…...
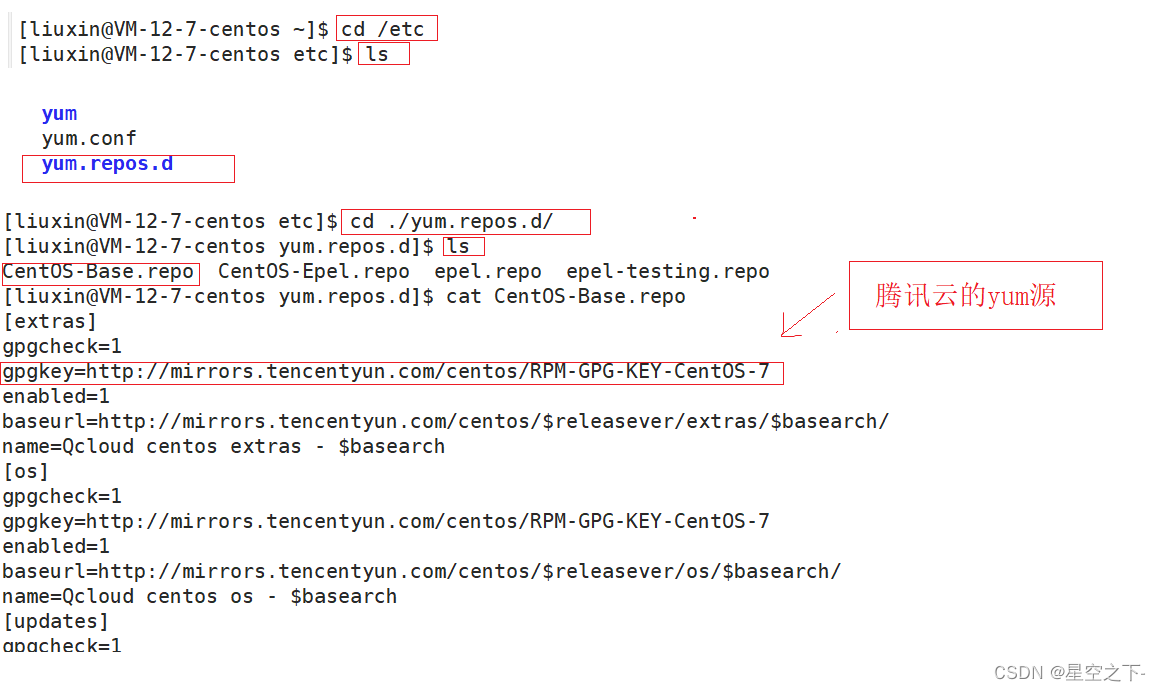
【Linux】软件包管理器 yum
什么是软件包和软件包管理器 在 Linux 下需要安装软件时, 最原始的办法就是下载到程序的源代码, 进行编译得到可执行程序。但是这样太麻烦了,所以有些人就把一些常用的软件提前编译好, 做成软件包 ( 就相当于windows上的软件安装程序)放在服…...

SecGPT-14B镜像免配置实战:开箱即用的网络安全大模型推理方案
SecGPT-14B镜像免配置实战:开箱即用的网络安全大模型推理方案 1. 为什么选择SecGPT-14B 在网络安全领域,专业知识的获取往往需要多年经验积累。SecGPT-14B作为一款专注于网络安全的大语言模型,能够为安全工程师、开发人员和IT运维人员提供即…...

X键位8芯M12插座的传输速率最高能到多少?
在工业以太网高速传输场景中,X键位(X-coded)M12插座是专为万兆级速率设计的圆形连接器接口。其最高传输速率可达10Gbps(万兆以太网),符合IEEE 802.3an 10GBASE-T标准,并可向下兼容1000BASE-T&am…...

HP20x气压传感器Arduino驱动深度解析
1. Grove Barometer HP20x 高精度气压/温度/海拔传感器驱动深度解析1.1 项目定位与工程价值Grove Barometer HP20x 是 Seeed Studio 推出的基于 HP206C(或兼容型号 HP203B/HP202C)高精度气压传感芯片的模块化传感器。该驱动库并非简单封装,而…...

告别网络限制!哔咔漫画离线下载神器使用全攻略
告别网络限制!哔咔漫画离线下载神器使用全攻略 【免费下载链接】picacomic-downloader 哔咔漫画 picacomic pica漫画 bika漫画 PicACG 多线程下载器,带图形界面 带收藏夹,已打包exe 下载速度飞快 项目地址: https://gitcode.com/gh_mirrors…...

实战指南:基于快马AI开发具备核心功能的电商比价插件
最近在做一个电商比价插件的开发项目,正好用到了InsCode(快马)平台,整个过程特别顺畅,分享下我的实战经验。 项目背景与需求分析 电商比价插件是很多网购达人的刚需工具。核心要解决三个问题:实时比价、历史价格追踪和降价提醒。传…...

贾子哲学思想理论体系研究:学术贡献、实证争议与文明治理范式创新——基于鸽姆智库创始人贾龙栋的综合评估
贾子哲学思想理论体系研究:学术贡献、实证争议与文明治理范式创新——基于鸽姆智库创始人贾龙栋的综合评估摘要 本文系统梳理鸽姆智库创始人贾龙栋(笔名贾子)的学术背景及其创立的贾子哲学思想理论体系。该体系以“1-2-3-4-5”层级架构为核心…...

P1163 银行贷款 总结与反思
提炼以下几点:1,问:C中 整型怎么转浮点数(int/ long long to double):答:直接赋值即可, eg ll N; double a N;2, 问:C中整型和浮点数怎么做加减法答:直接加减即可,自…...

linux——消息队列发送和读取函数
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg); //读取消息,成功返回消息数据的长度,失败返回‐1 参数: msgid:消息队列的ID msgp:指向消息的指针,常用结构体msgbuf如下: struct msgbuf { lon…...

项目经理面试必备:5 大核心问题拆解与高通过率回答策略
1. 项目经理面试的核心问题解析 面试官抛出"请描述你负责过的一个典型项目"时,往往不是想听流水账。我当年第一次面试时就犯过这个错误,花了10分钟详细描述项目背景,结果面试官直接打断:"所以你到底做了什么&#…...

如何使用Photon光影包提升Minecraft视觉体验
如何使用Photon光影包提升Minecraft视觉体验 【免费下载链接】photon A gameplay-focused shader pack for Minecraft 项目地址: https://gitcode.com/gh_mirrors/photon3/photon Photon光影包是一款专注于游戏体验的Minecraft光影解决方案,通过先进的光照算…...