Spark读取JDBC调优
Spark读取JDBC调优,如何调参
- 一、场景构建
- 二、参数设置
- 1.灵活运用分区列
实际问题:工作中需要读取一个存放了三四年历史数据的pg数仓表(缺少主键id),需要将数据同步到阿里云 MC中,Spark在使用JDBC读取关系型数据库时,默认只开启一个task去执行,性能低下,因此需要通过设置一些参数来提高并发度。一定要充分理解参数的含义,否则可能会因为配置不当导致数据倾斜!
翻看了网络上好多相关介绍,都沾边。下边总结一下!
您是菜鸟就好好学习,您是大佬欢迎提出修改意见!
一、场景构建
以100行数据为例(实际307983条):
- 创建表
CREATE TABLE IF NOT EXISTS test(good_id STRING ,title STRING ,sellcount BIGINT,salesamount Double
)COMMENT '测试表'
PARTITIONED BY (dt STRING COMMENT '分区字段'
);
- 插入数据
insert into test partition (dt = '202001')
values ('1001','卫衣',1,100.1),('1002','卫裤',2,101.2),('1003','拖鞋',3,10.3)...,('1100','帽子',100,19.23)
二、参数设置
配置文件示例:
jdbc: &jdbcoptions.url: "jdbc:postgresql://xxx.xxx.xxx.xxx:8000/postgres"options.user: "xxxxxx"options.password: "xxxxxx"options.driver: "org.postgresql.Driver"input:- moduleClass: "JDBC"<<: *jdbcoptions.dbtable: "SELECT *,cast(good_id as bigint)*1%6 mo FROM test.test where dt = '202001'"options.fetchsize: "100"options.partitionColumn: "mo" # 分区列,一般为自增id,下边解释下为啥用mooptions.numPartitions: "6" #分区数options.lowerBound: "0"options.mytime: "${yyyy}-${MM}-${dd}"options.upperBound: "6" # 该值设置为和分区列最大值差不多的值resultDF: "df"
提交spark配置
spark-submit \--class xx.xxx.xxx.xxx \--master local[*] \--num-executors 6 \--executor-cores 1 \--executor-memory 2G \--driver-memory 4G \/root/test/xxx.jar \-p xxx/xxx.yaml -cyctime $cyctime
-
options.fetchsize:一次性读取的数据条数,按集群规模(例:64核128G)一次1000条;阿里云Spark集群链接不了华为云pg数仓,我开了一台独立机器(8核16G)一次100条
-
options.partitionColumn:分区列,必须是bigint类型;
-
options.numPartitions:设置分区数,最好和spark提交的executors数一致;上文中spark任务数为6,分区数也为6
-
options.lowerBound:分区开始值
-
options.upperBound:分区结束值;numPartitions、lowerBound、upperBound这三个必须同时设置,每个分区的数据量计算公式为:upperBound / numPartitions - lowerBound / numPartitions,任务运行时间看的是最长的那个任务,所以要尽可能保证每一个分区的数据量差不多
官方配置文档:
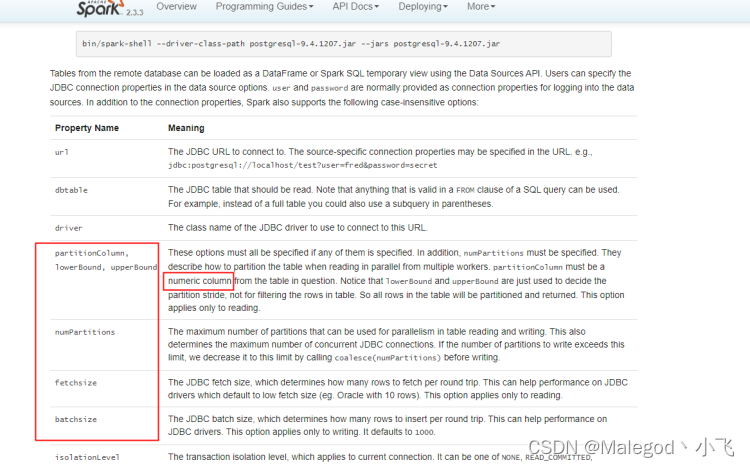
1.灵活运用分区列
有的小伙伴就该思考为啥不用自增id做分区列呢?
因为实际生产环境中,一是不需要,二是创建表忽略了自增id等等。
为啥要新做一列mo,而不直接将商品id转bigint用呢?
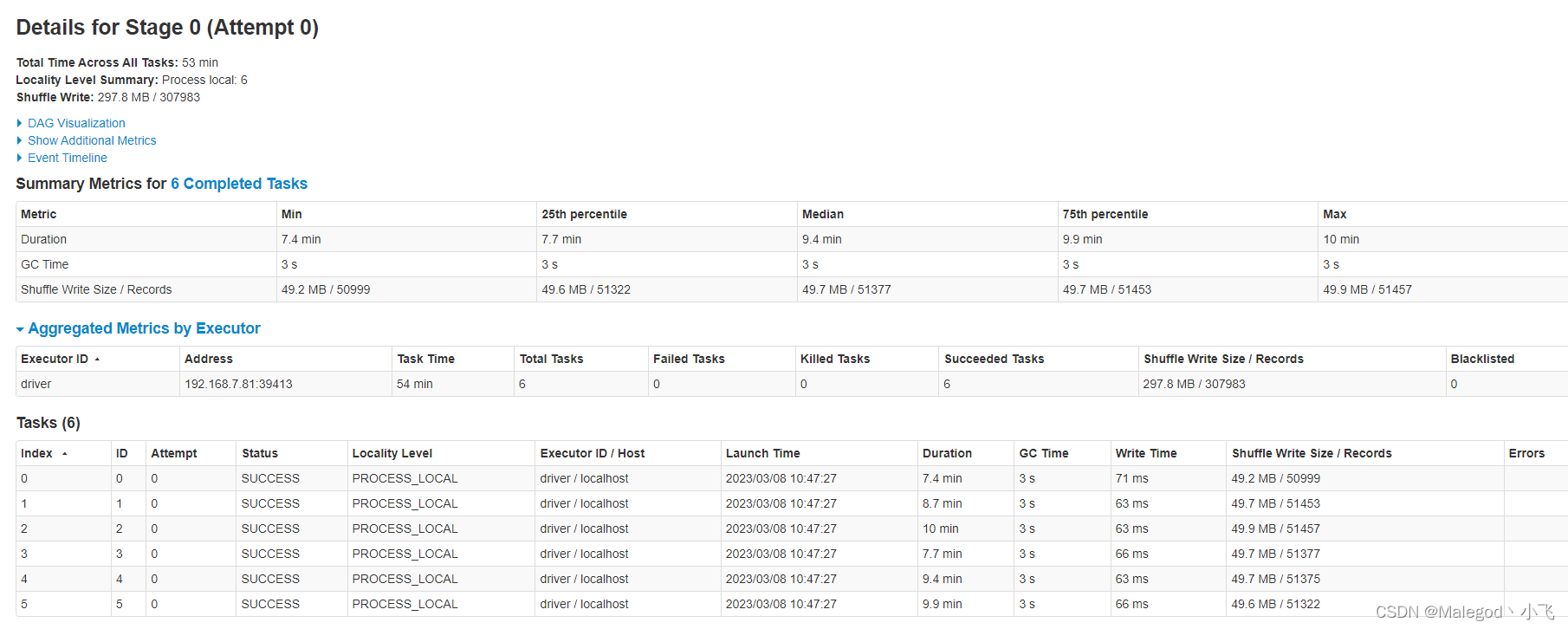
算是一个补救措施,新做一个数据列,在读取过程用mo做shuffle,mo是商品id强转为bigint后对6取膜,结果为0-5共6种可能,提高了shuffle的效率,计算分区的数据量:6 / 6 - 0 / 6 = 1;也就是说分区值为0,1,2,3,4,(大于5),对应6个任务,6个核心。
下面是运行shuffle结束后的截图,可以看到每一个task获取的数据量都比较均匀
下面来看一个错误的案例:
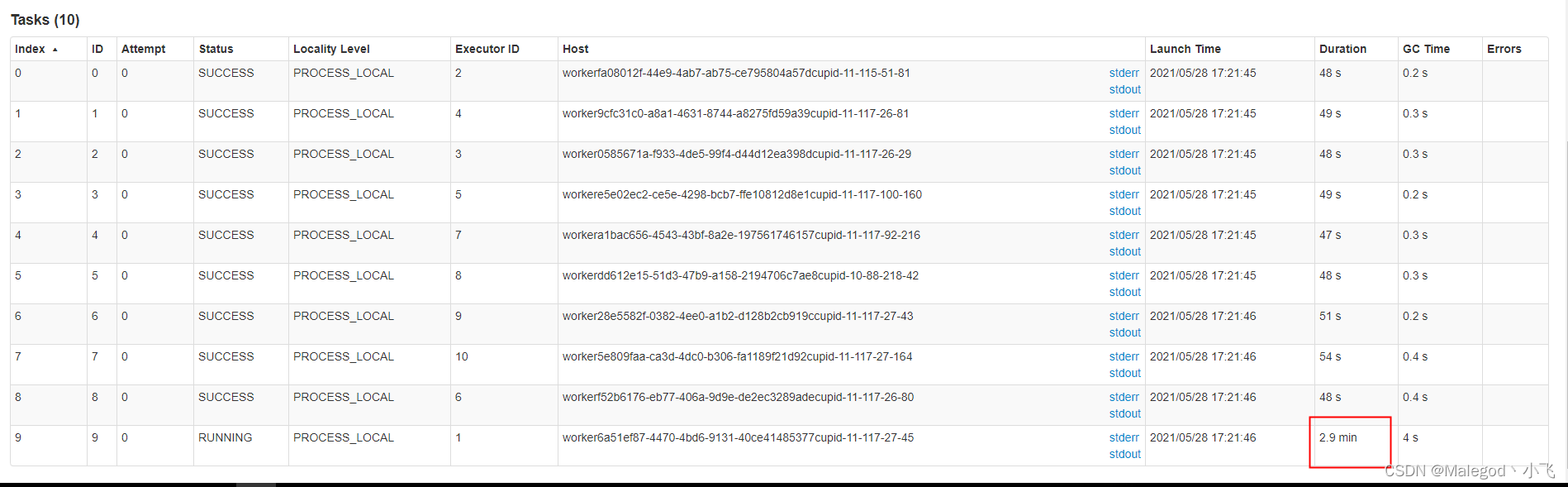
上图配置就会导致数据倾斜
numPartitions=10,
lowerBound=0,
upperBound=100,
表的数据量是1000。
根据计算公式每个分区的数据量是100/10-0/10=10,分10个区,那么前9个分区数据量都是10,但最后一个分区数据量却达到了910,即数据倾斜了,所以upperBound-lowerBound要和表的分区字段最大值差不多
有啥需要优化的欢迎评论纠正
相关文章:
Spark读取JDBC调优
Spark读取JDBC调优,如何调参一、场景构建二、参数设置1.灵活运用分区列实际问题:工作中需要读取一个存放了三四年历史数据的pg数仓表(缺少主键id),需要将数据同步到阿里云 MC中,Spark在使用JDBC读取关系型数…...

【文心一言】什么是文心一言,如何获得内测和使用方法。
文心一言什么是文心一言怎么获得内测资格接下来就给大家展示一下文学创作商业文案创作数理逻辑推算中文理解多模态生成用python写一个九九乘法表写古诗前言: 🏠个人主页:以山河作礼。 📝📝:本文章是帮助大家了解文心…...
CentOS8服务篇10:FTP服务器配置与管理
一、安装与启动FTP服务器 1、安装VSFTP服务器所需要的安装包 #yum -y install vsftpd 2、查看配置文件参数 Vim /etc/vsftpd/vsftpd.conf (1)是否允许匿名登录 anonymous_enableYES 该行用于控制是否允许匿名用户登录。 (2&…...

笔试强训3.14
一、选择题 1.以下说法错误的是(C) A.数组是一个对象 B.数组不是一种原生类 C.数组的大小可以任意改变 D.在Java中,数组存储在堆中连续内存空间里 相关知识点:原生/内置数组是那八个,其他的都是引用的,借…...

elasticsearch 环境搭建和基本操作
参考资料 适合后端编程人员的elasticsearch快速实战教程 ElasticSearch最新实战教程 ElasticSearch配套笔记 自制搜索引擎 https://www.elastic.co/guide/en/elasticsearch/reference/7.17/setup.html restful风格的api REST 设计风格 例如以下springboot示例 RestContr…...
IDEA操作:Springboot项目打包为jar包并运行
在IDEA环境下对Springboot项目打包为jar包且在terminal运行操作 1、 2、 3、注意:在项目目录里创建一个用来存放jar包的文件夹(res),该路径不能使用IDEA设置的默认路径,必须手动创建。 4、 5、点击ok后加载运行包 (8…...
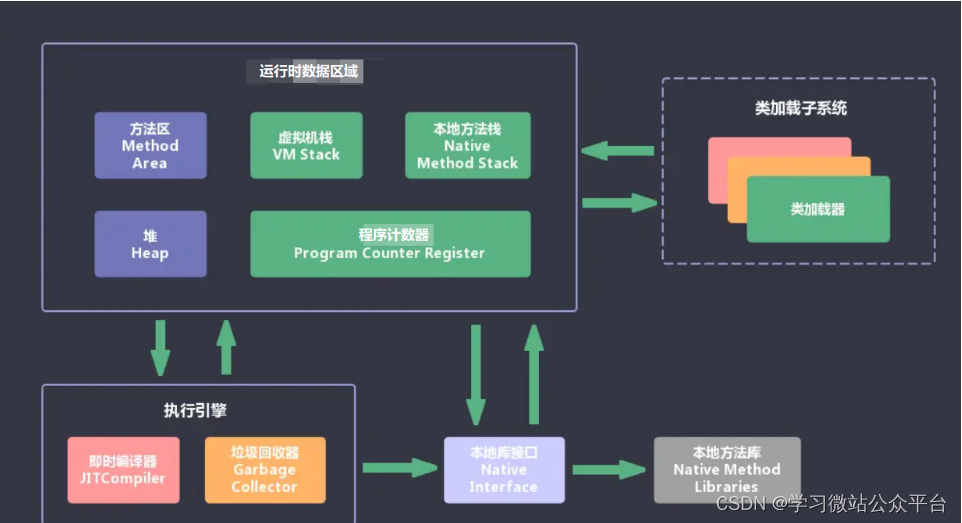
原理底层计划---JVM
二、JVM对空间大小怎么配置?各区域怎么划? 新生代:短时间生成,可以马上回收 老生代:少部分对象会存在很久,回收策略应不同 三、JVM哪些内存区域会发生内存溢出(程序计数器不会) …...

CSDN-猜年龄、纸牌三角形、排他平方数
猜年龄 原题链接:https://edu.csdn.net/skill/practice/algorithm-a413078fb6e74644b8c9f6e28896e377/2258 美国数学家维纳(N.Wiener)智力早熟,11岁就上了大学。他曾在1935~1936年应邀来中国清华大学讲学。 一次,他参加某个重要会议…...
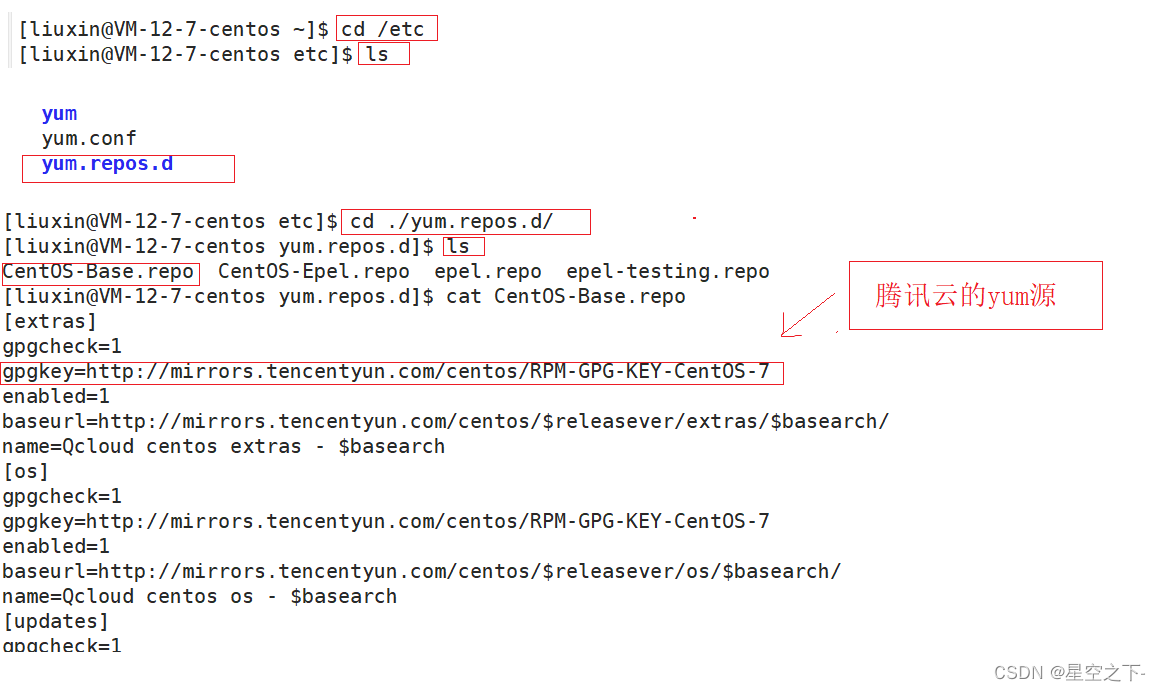
【Linux】软件包管理器 yum
什么是软件包和软件包管理器 在 Linux 下需要安装软件时, 最原始的办法就是下载到程序的源代码, 进行编译得到可执行程序。但是这样太麻烦了,所以有些人就把一些常用的软件提前编译好, 做成软件包 ( 就相当于windows上的软件安装程序)放在服…...
一天吃透TCP面试八股文
本文已经收录到Github仓库,该仓库包含计算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享等核心知识点,欢迎star~ Github地址:https://github.com/…...

zzu天梯赛选拔
C. NANA去上课 — 简单数学 需要记录上一步处在哪个位置 然后判断如果是同一侧移动距离就是abs(x1 - x2) 如果不同就是x1 x2 #include <iostream> #include <cmath> using namespace std; #define int long long signed main() {int n; c…...
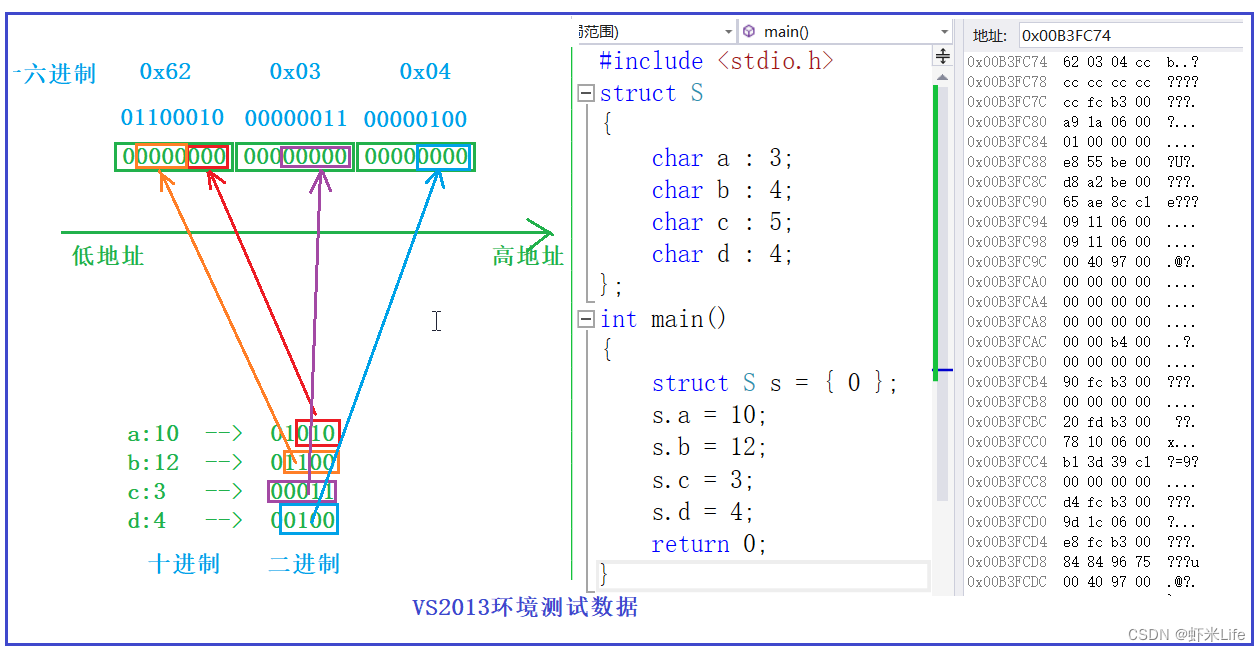
【C语言】一篇让你彻底吃透(结构体与结构体位段)
本章重点 主要讲解结构体和位移动的使用和定义与声明,并且结构体和位段在内存中是如何存储的。 文章目录结构体结构体类型的声明结构体特殊的声明结构体变量的定义和初始化结构体成员的访问结构的自引用结构体内存对齐结构体传参位段什么是位段位段的内存分配位段的…...

数据结构之二叉树构建、广度/深度优先(前序、中序、后序)遍历
一、二叉树 1.1 树 说到树,我们暂时忘记学习,来看一下大自然的树: 哈哈 以上照片是自己拍的,大家凑合看看 回归正题,那么在数据结构中,树是什么呢,通过上面的图片大家也可以理解 树是一种非…...

“国产版ChatGPT”文心一言发布会现场Demo硬核复现
文章目录前言实验结果一、文学创作问题1 :《三体》的作者是哪里人?问题2:可以总结下三体的核心内容吗?如果要续写的话,可以从哪些角度出发?问题3:如何从哲学角度来进行续写?问题4:电…...

202304读书笔记|《不被定义的女孩》——做最真实最漂亮的自己,依心而行
202304读书笔记|《不被定义的女孩》——做最真实最漂亮的自己,依心而行《不被定义的女孩》作者ASEN,很棒的书。处处透露着洒脱,通透,悦己,阅世界的自由的氛围和态度! 部分节选如下: 让自己活得…...

SpringBoot帮你优雅的关闭WEB应用程序
Graceful shutdown 应用 Graceful shutdown说明 Graceful shutdown is supported with all four embedded web servers (Jetty, Reactor Netty, Tomcat, and Undertow) and with both reactive and servlet-based web applications. It occurs as part of closing the applica…...
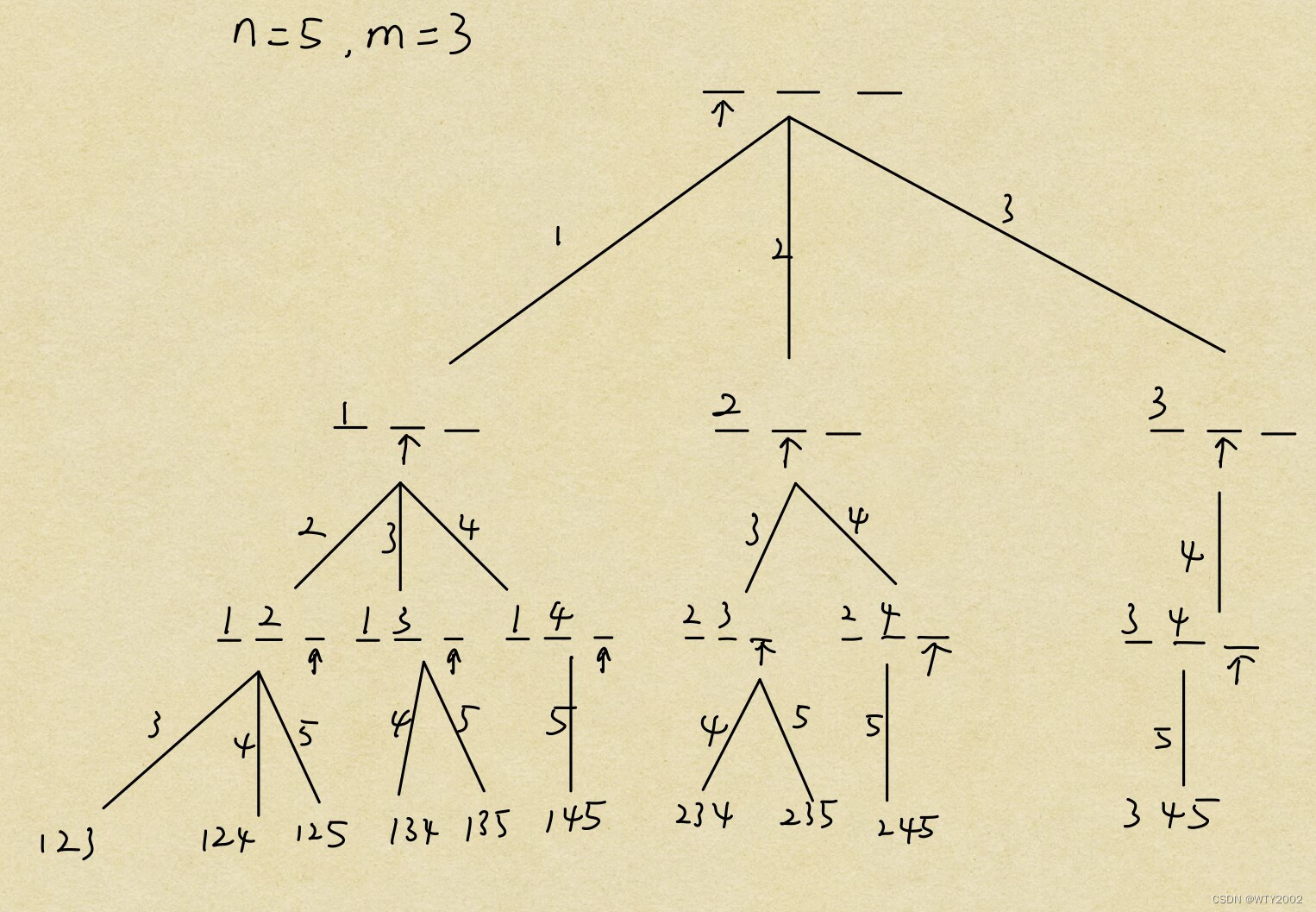
递归与递推
递归 直白理解:函数在其内部调用自身(自己调用自己)所有递归都可以采用递归搜索树来理解递归的特点: 一般来说代码较为简短,但是理解难度大一般时间和空间消耗较大,容易产生重复计算,可能爆栈 …...
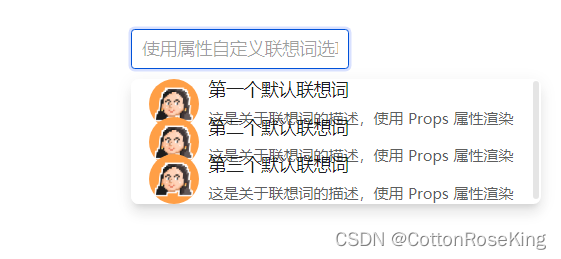
使用<style scoped>导致的样式问题
问题描述: 今天使用开源组件库TDesign的自动补全组件时,遇到了一个样式失效问题,一开始怎么也找不到问题出在哪,后面一个偶然去掉了scoped,竟然发现样式竟然正常了,具体原因不知道在哪,有大佬知…...
-集群关键指标及调优指南)
Elasticsearch深入理解(十八)-集群关键指标及调优指南
1、CPU使用率 CPU使用率是指在一段时间内CPU执行程序的百分比,它是衡量系统资源利用率的一种指标。 1.1 详细说明: 在Elasticsearch中,高的CPU使用率通常意味着节点正在执行大量的计算任务,这可能是因为索引和搜索操作的负载较大…...
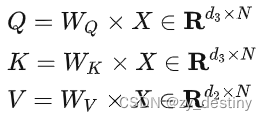
Transformer到底为何这么牛
从注意力机制(attention)开始,近两年提及最多的就是Transformer了,那么Transformer到底是什么机制,凭啥这么牛?各个领域都能用?一文带你揭开Transformer的神秘面纱。 目录 1.深度学习࿰…...

硬币凑钱--动态规划--完全背包的变式
1.硬币凑钱import java.util.Scanner;// 注意类名必须为 Main, 不要有任何 package xxx 信息 public class Main {public static void main(String[] args) {Scanner sc new Scanner(System.in);int nsc.nextInt();//背包问题的其中一种int[] dpnew int[n1];for(int i1;i<n…...
)
静息态fMRI分析避坑指南:DPARSFA预处理中那些容易踩的‘雷’(附解决方案)
静息态fMRI分析实战避坑手册:DPARSFA预处理中的7个致命陷阱与修复方案 当你熬夜跑完DPARSFA预处理流程,满心期待地点开结果图时——突然发现ReHo图像像被泼了墨水,fALFF数值全部溢出,或是软件弹出一串看不懂的报错代码。这种崩溃…...

除了阿里云,还有哪些靠谱的身份证实名认证方案?SpringBoot整合横向评测
SpringBoot整合主流身份证实名认证API横向评测:从阿里云到多服务商技术选型指南 当你的应用需要接入身份证实名认证功能时,阿里云可能只是众多选项中的一个起点。作为技术决策者,如何在腾讯云、百度智能云、聚合数据等众多服务商中做出最优选…...
Hunyuan-MT-7B保姆级教程:Pixel Language Portal在树莓派5上的轻量级翻译终端部署
Hunyuan-MT-7B保姆级教程:Pixel Language Portal在树莓派5上的轻量级翻译终端部署 1. 项目介绍与核心价值 Pixel Language Portal(像素语言跨维传送门)是一款基于Tencent Hunyuan-MT-7B大语言模型的创新翻译工具。与传统翻译软件不同&#…...

Ubuntu系统资源监控实战:从命令行到图形化工具全解析
1. 为什么需要监控Ubuntu系统资源? 刚装好的Ubuntu系统跑得飞快,用着用着突然发现电脑变卡了?浏览器开多几个标签页就开始转圈?这种情况我遇到过太多次了。后来才发现,很多时候是因为某个程序偷偷吃掉了大量CPU或内存资…...

VxLAN网络如何“破圈”?聊聊Type5路由在云网融合中的真实应用场景
VxLAN Type5路由:云网融合时代的智能连接引擎 在数字化转型浪潮中,企业网络架构正经历着从传统三层架构向云原生网络的跃迁。VxLAN作为新一代网络虚拟化技术的代表,其Type5路由功能正在成为打通云网边界的关键推手。想象一下这样的场景&#…...

intv_ai_mk11行业落地:教育机构课件辅助生成、HR招聘文案批量产出案例
intv_ai_mk11行业落地:教育机构课件辅助生成、HR招聘文案批量产出案例 1. 模型能力与行业价值 intv_ai_mk11作为一款基于Llama架构的文本生成模型,在教育培训和人力资源领域展现出独特的实用价值。这个开箱即用的解决方案特别适合需要快速处理大量文本…...

终极免费抖音无水印视频下载完整教程:3步快速获取高清素材
终极免费抖音无水印视频下载完整教程:3步快速获取高清素材 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback s…...
)
记一次攻防演练复盘(蓝队)
事件:某省大数据局主导的一次攻防演练中午时段遭受大量攻击。 告警信息(TOP 5):[疑似目录穿越攻击URI] [漏洞攻击: Apache log4j RCE Attempt (http ldap) (CVE-2021-44228)] [web路径遍历漏洞攻击-Linux环境] [XSS跨站脚本攻击U…...

数据科学入门指南:10周掌握数据分析核心技能 [特殊字符]
数据科学入门指南:10周掌握数据分析核心技能 🚀 【免费下载链接】Data-Science-For-Beginners 10 Weeks, 20 Lessons, Data Science for All! 项目地址: https://gitcode.com/GitHub_Trending/da/Data-Science-For-Beginners 想要在数据驱动的时代…...