Elasticsearch深入理解(十八)-集群关键指标及调优指南
1、CPU使用率
CPU使用率是指在一段时间内CPU执行程序的百分比,它是衡量系统资源利用率的一种指标。
1.1 详细说明:
在Elasticsearch中,高的CPU使用率通常意味着节点正在执行大量的计算任务,这可能是因为索引和搜索操作的负载较大,也可能是因为节点正在进行数据复制和分片重新平衡等任务。因此,高的CPU使用率通常是Elasticsearch性能瓶颈的一个指标。
1.2 注意:
有以下一些情况可能会导致 Elasticsearch 的 CPU 使用率变高:
-
查询负载增加:当 Elasticsearch 集群承受的查询负载增加时,会导致 CPU 使用率变高。这通常发生在索引大量新数据或者搜索流量增加的情况下。
-
索引负载增加:当 Elasticsearch 集群承受的索引负载增加时,会导致 CPU 使用率变高。这通常发生在索引大量新数据的情况下。
-
GC:当 Elasticsearch 的 Java 进程发生垃圾回收(GC)时,会导致 CPU 使用率变高。GC 是清理 Java 堆内存中不再使用的对象,它是 Java 程序中自带的机制,当 Java 堆内存中的对象数量增加时,GC 的频率和时间也会相应增加。
-
机器性能不足:当 Elasticsearch 部署的机器性能不足时,会导致 CPU 使用率变高。例如,CPU 处理器的速度较慢,内存不足,磁盘 I/O 较慢等。
-
插件/脚本等造成的性能问题:当 Elasticsearch 使用的插件或脚本存在性能问题时,会导致 CPU 使用率变高。在某些情况下,某些插件和脚本可能会影响 Elasticsearch 的性能,例如使用复杂的脚本或者调用较慢的第三方库。
总之,当 Elasticsearch 集群处理数据量增加、索引负载增加、查询负载增加、GC 或者机器性能不足等情况时,会导致 CPU 使用率变高。为了避免这种情况的发生,可以采取一些优化策略,如添加更多的节点、升级硬件等。
1.3 当CPU使用率升高时如何处理?
-
调整集群配置。可以通过调整Elasticsearch集群的配置来减少CPU的使用率。例如,可以调整查询的并发数、增加分片的数量、减少索引的副本数等,来减轻CPU的负担。
-
优化查询语句。复杂的查询语句可能会导致CPU的使用率飙升。因此,可以考虑优化查询语句,使用更简单、更高效的查询语句来减少CPU的使用率。
-
关闭不必要的插件。Elasticsearch的插件可以扩展其功能,但某些插件可能会占用大量的CPU资源。因此,可以考虑关闭某些不必要的插件来减少CPU的使用率。
-
增加硬件资源。如果Elasticsearch集群的CPU使用率经常超过限制,可能需要考虑增加硬件资源,例如增加CPU核心数量或升级CPU型号,以提高集群的性能。
-
增加集群规模。如果Elasticsearch集群的CPU使用率经常超过限制,还可以考虑增加集群规模,将负载分摊到多台机器上,以提高集群的性能。
-
调整集群中节点的负载均衡策略。Elasticsearch的负载均衡策略可能会导致某些节点的CPU使用率过高。因此,可以考虑调整负载均衡策略,将负载更均衡地分配到各个节点上。
1.4 当Elasticsearch集群的CPU使用率升高时,可以考虑调整哪些参数?
-
indices.store.throttle.max_bytes_per_sec: 索引写入速度控制参数,用于限制每秒写入的数据量。如果写入速度太快,可能会导致CPU使用率过高。可以降低该参数的值来减缓写入速度。该参数的最优值取决于硬件配置和写入负载,一般建议将其设置为每秒写入速率的80%到90%。例如,如果每秒写入速率为50MB/s,则该参数的最优值可能在40MB/s到45MB/s之间。
-
indices.memory.index_buffer_size: 索引缓冲区大小。如果该值太小,会导致频繁的IO操作,从而增加CPU负载。可以适当增大该值来减少IO操作。该参数的最优值取决于可用内存、索引大小和查询负载等因素,一般建议将其设置为可用内存的20%到30%。例如,如果集群有100GB的可用内存,该参数的最优值可能在20GB到30GB之间。
-
indices.fielddata.cache.size: 字段数据缓存大小。如果字段数据缓存过小,可能会导致频繁的磁盘读取,从而增加CPU负载。可以适当增大该值来减少磁盘读取操作。该参数的最优值取决于字段数据大小和查询负载等因素,一般建议将其设置为可用内存的20%到30%。例如,如果集群有100GB的可用内存,该参数的最优值可能在20GB到30GB之间。
-
indices.queries.cache.size: 查询缓存大小。如果查询缓存过小,可能会导致频繁的查询操作,从而增加CPU负载。可以适当增大该值来减少查询操作。该参数的最优值取决于查询负载,一般建议将其设置为查询缓存占用可用内存的20%到30%。例如,如果集群有100GB的可用内存,该参数的最优值可能在20GB到30GB之间。
-
indices.recovery.max_bytes_per_sec: 索引恢复速度控制参数,用于限制每秒恢复的数据量。如果恢复速度太快,可能会导致CPU使用率过高。可以降低该参数的值来减缓恢复速度。该参数的最优值取决于恢复速度和集群负载,一般建议将其设置为每秒恢复速率的80%到90%。例如,如果每秒恢复速率为50MB/s,则该参数的最优值可能在40MB/s到45MB/s之间。
-
indices.search.slowlog.threshold.query.warn: 查询慢日志告警阈值。如果查询操作太慢,可能会导致CPU使用率过高。可以降低该参数的值来快速发现查询慢的问题。该参数的最优值取决于查询负载和业务需求,一般建议将其设置为查询执行时间的90%到95%。例如,如果查询执行时间的中位数为1秒,则该参数的最优值可能在900ms到950ms之间。
2、内存使用率
当前使用的内存量占可用内存总量的比例。
2.1 详细说明:
-
Elasticsearch 会使用 JVM 来运行,因此 JVM 的内存分配对 Elasticsearch 的性能非常重要。默认情况下,Elasticsearch 的 JVM 内存分配为 1GB,但在生产环境中通常需要将其调整为更大的值。
-
Elasticsearch 将内存分为两部分:堆内存和非堆内存。堆内存用于存储文档、字段和查询缓存等数据,非堆内存用于存储索引缓存、文件系统缓存和其他内部缓存等数据。
-
Elasticsearch 会自动管理缓存,以确保常用的数据在内存中。当内存不足时,Elasticsearch 会将较少使用的数据从内存中移除,并将其存储到磁盘上。
-
对于单个节点的 Elasticsearch 集群,通常建议将 JVM 堆内存设置为总内存的一半,以留出一定的空间给操作系统和其他进程使用。而对于大型集群,建议将 JVM 堆内存设置为 30GB 到 32GB。
2.2 注意:
关于Elasticsearch的内存使用率,以下因素可能会对其产生影响:
-
索引的大小和数量:索引的大小和数量会直接影响 Elasticsearch 使用的内存量。较大的索引需要更多的内存来处理,而较小的索引则需要较少的内存。
-
查询负载:查询负载是指 Elasticsearch 在任何给定时刻处理的查询数量和类型。更多的查询负载需要更多的内存来处理和缓存查询结果。
-
JVM 堆内存大小:Elasticsearch 在 JVM 堆内存中缓存文档、字段和查询结果等数据,堆内存的大小直接影响 Elasticsearch 的性能。通常,增加堆内存大小可以提高 Elasticsearch 的性能,但是在可用内存受限的情况下,过大的堆内存大小可能会导致系统负载过重,甚至导致 OutOfMemoryError 错误。
-
硬件资源:Elasticsearch 的内存使用率还受限于硬件资源,包括 CPU、磁盘和网络带宽等。如果硬件资源不足,可能会导致 Elasticsearch 性能下降,甚至无法正常运行。
-
Elasticsearch 版本:Elasticsearch 版本之间的内存使用率也可能有所不同。较新的版本通常会更有效地利用内存,提高性能和稳定性。
综上所述,Elasticsearch 的内存使用率受多种因素影响,需要根据具体情况进行分析和调整,以优化性能和稳定性。
2.3 当内存使用率升高时如何处理?
-
检查Elasticsearch集群中是否有索引或搜索查询的负载异常,这可能导致内存使用率飙升。可以使用Elasticsearch的监控工具或REST API来查看负载和性能指标,并识别问题所在。
-
调整JVM的堆内存大小。JVM是Elasticsearch节点的内存管理器,可以通过调整JVM的堆内存大小来控制Elasticsearch的内存使用率。可以通过在elasticsearch.yml文件中设置-Xms和-Xmx参数来增加或减少JVM的堆内存大小。注意,不要将JVM的堆内存大小设置过小,否则会影响Elasticsearch的性能。
-
减小索引分片的数量。索引分片是Elasticsearch的分布式存储机制,但太多的分片会占用过多的内存资源。可以通过减小索引分片的数量来降低内存使用率。
-
使用更高效的查询。复杂的查询可能需要占用更多的内存资源,因此,可以尝试使用更高效的查询来降低内存使用率。例如,使用过滤器而不是查询语句来获取数据,或使用聚合操作来减少数据的返回。
-
增加硬件资源。如果Elasticsearch集群的内存使用率经常超过限制,可能需要考虑增加硬件资源,例如增加内存或CPU,以满足集群的性能需求。
2.4 当Elasticsearch集群的内存使用率升高时,可以考虑调整哪些参数?
-
indices.memory.index_buffer_size:该参数控制索引模块使用的内存缓冲区大小。如果内存使用率升高,可以尝试降低该参数的值,以减少索引模块占用的内存。不过,降低该参数的值可能会降低索引性能。此参数应该根据索引的大小和使用情况进行调整。建议将其设置为每个索引的可用堆内存的5%-10%。
-
indices.fielddata.cache.size:该参数控制字段数据缓存的大小。如果内存使用率升高,可以尝试降低该参数的值,以减少字段数据缓存占用的内存。不过,降低该参数的值可能会降低查询性能。此参数应该设置为尽可能大的值,以利用可用的内存来缓存字段数据。建议设置为10%-30%的可用堆内存。
-
indices.queries.cache.size:该参数控制查询缓存的大小。如果内存使用率升高,可以尝试降低该参数的值,以减少查询缓存占用的内存。不过,降低该参数的值可能会降低查询性能。此参数应该设置为尽可能大的值,以利用可用的内存来缓存查询。建议设置为10%-30%的可用堆内存。
-
indices.breaker.*:该参数控制Elasticsearch使用的熔断器(circuit breaker)阈值。熔断器是一种保护机制,用于防止过度使用内存和磁盘等资源。如果内存使用率升高,可以尝试调整熔断器阈值,以避免过度使用内存。
-
indices.recovery.max_bytes_per_sec:该参数控制恢复速度。如果内存使用率升高,可以尝试降低该参数的值,以降低恢复操作占用的内存。 此参数应该根据网络带宽进行调整,以确保恢复操作不会占用过多的内存。建议将其设置为网络带宽的70%-80%。
3、磁盘使用率
磁盘使用率是指已用磁盘空间和可用磁盘空间之间的比率,通常以百分比形式表示
3.1 详细说明:
关于磁盘使用率可详细描述的部分较少,这里说明一下常见的几种磁盘类型:
-
机械硬盘(HDD):机械硬盘是一种传统的存储设备,使用旋转的磁盘和移动的磁头来读写数据。它们相对较便宜,但速度较慢,因此不适合对性能要求较高的应用。
-
固态硬盘(SSD):固态硬盘使用闪存来存储数据,速度比机械硬盘更快,因此可以提供更好的性能。它们相对较昂贵,但在需要高性能的应用场景中通常更受欢迎。
-
NVMe硬盘:NVMe硬盘是一种专为固态硬盘设计的高速接口,比SATA接口的固态硬盘更快,因此提供更高的性能。
-
分布式文件系统:Elasticsearch还支持使用分布式文件系统作为存储后端,如Hadoop Distributed File System(HDFS)和Amazon S3。这些系统通常用于大规模数据存储和分析,但也可以用于Elasticsearch。
3.2 注意:
-
数据量:Elasticsearch的磁盘使用率与数据量直接相关,因为数据存储在磁盘上。如果数据量增加,磁盘使用率也会相应增加。
-
索引设置:Elasticsearch支持多种索引设置,如分片和副本,这些设置会影响数据在磁盘上的存储方式和占用空间的大小。例如,分片数量越多,每个分片占用的磁盘空间就越小,但需要更多的分片可能会导致额外的磁盘空间占用。
-
索引更新频率:当索引频繁更新时,会导致Elasticsearch写入更多的数据到磁盘上,从而增加磁盘使用率。
-
删除操作:在Elasticsearch中,删除文档不会立即释放磁盘空间,而是通过后台的段合并(segment merge)操作来回收空间。如果经常删除文档,可能需要定期执行段合并操作,否则会导致磁盘使用率持续增加。
-
数据复制:Elasticsearch支持副本机制,即将数据复制到其他节点以实现高可用性。这意味着每个副本都需要占用额外的磁盘空间。
-
磁盘类型:不同类型的磁盘对性能和空间占用有不同的影响。例如,固态硬盘通常比机械硬盘更快,但通常也更昂贵,而机械硬盘则更适合低成本应用。
3.3 当磁盘使用率升高时如何处理?
-
添加更多的节点:可以通过添加更多的节点来扩展集群的存储能力,从而减轻单个节点的负担。
-
删除旧的或不需要的数据:可以通过删除旧的或不需要的数据来释放磁盘空间。但是,在删除数据之前,请确保您不再需要这些数据,因为数据删除是不可逆的操作。
-
压缩索引:Elasticsearch提供了一些工具来压缩索引,可以在不降低性能的情况下减小索引的大小。
-
增加磁盘空间:如果磁盘使用率升高是由于磁盘空间不足导致的,可以考虑增加磁盘空间。
-
调整文档的存储方式:可以通过调整文档的存储方式来减小磁盘使用率。例如,可以将文档中的某些字段设置为不索引,或者将某些字段设置为压缩存储。
4、GC频次
指垃圾回收器在一定时间内执行的次数,它是一个反映JVM垃圾回收效率的指标。
4.1 详细说明:
这里指的是老年代的GC频次,老年代用来存储较老的对象空间,这些对象预期是长久的并且持续了很长时间。在Elasticsearch节点中最大可以设置为30GB。
一个缓慢的GC可能有1s甚至15s以上,从集群稳定性的角度来说是不可接受的。一个频繁长时间GC的集群是重负载并且没有足够内存的。这些长时间GC将使节点短暂离开集群,在Elasticsearch中为了保持集群的稳定和可用的副本,这种不稳定因素经常导致重新迁移分片。当集群尝试服务正常的索引(写入)和查询时,会增加网络流量和磁盘I/O。
在Elasticsearch集群的垃圾回收器替换成G1后,GC的频次和持续时间均有明显改善。
4.2 注意:
-
JVM堆内存不足:当JVM堆内存不足时,会导致GC频繁触发,以释放内存空间。这种情况通常是由于索引数据量增加或者查询负载增加等原因导致的。
-
索引数据过多:当索引数据量过多时,会占用大量的内存空间,导致JVM堆内存不足,从而引发GC频繁触发。
-
查询压力过大:当查询压力过大时,会导致Elasticsearch集群需要处理大量的查询请求,从而导致JVM堆内存不足,引发GC频繁触发。
-
代码逻辑问题:有时候可能存在代码逻辑问题,例如内存泄漏等,也会导致JVM堆内存占用过高,从而引发GC频繁触发。
4.3 降低GC频次的措施?
-
增加JVM堆内存大小:GC频次过高的一个主要原因是JVM内存不足,因此增加JVM堆内存大小可以有效降低GC频次。一般来说,JVM堆内存大小应该设置为应用程序所需要的最小值加上一定的余量,以确保系统具有足够的内存。
-
优化查询和索引操作:查询和索引操作是Elasticsearch集群中最耗费内存和CPU资源的操作,因此可以通过优化查询和索引操作来降低GC频次。例如,可以使用filter代替query,避免使用过多的聚合操作,避免使用过多的脚本等。
-
使用合适的垃圾回收器:不同的垃圾回收器有不同的GC算法和优化策略,选择合适的垃圾回收器可以降低GC频次。一般来说,CMS垃圾回收器比较适合应用程序的实时处理,而G1垃圾回收器则适合大型堆内存的应用程序。
-
使用合适的JVM参数:合适的JVM参数可以对Elasticsearch集群的GC频次产生重要影响。例如,可以通过设置合适的堆内存大小、调整垃圾回收器的参数等方式来降低GC频次。
5、fielddata内存使用量
fielddata内存使用量是指已经被加载到内存中的fielddata的大小。
5.1 详细说明:
当在Elasticsearch中对一个字段使用聚合、排序、脚本或者用于全文搜索时,该字段的fielddata就会被加载到内存中进行操作。fielddata是一种用于对文本类型的字段进行排序和聚合的数据结构。
如果一个集群中有大量的字段需要在内存中加载fielddata,那么这个指标可能会对集群性能产生负面影响。因此,需要根据实际情况来调整fielddata的使用策略,以平衡内存的使用和查询性能的需求。
5.2 注意:
当fielddata内存使用量达到一定程度时,会对Elasticsearch集群的性能和稳定性产生负面影响。具体来说,主要有以下几点:
-
内存不足:当fielddata内存使用量过高时,可能会导致内存不足,从而影响Elasticsearch集群的运行。这可能会导致请求被拒绝、节点故障等问题。
-
垃圾回收:当fielddata内存使用量过高时,垃圾回收器会频繁执行,这可能会导致性能下降。特别是在大型集群中,这可能会导致所有节点的性能下降,进而影响整个集群。
-
磁盘使用量:当fielddata内存使用量过高时,Elasticsearch可能会将部分数据写入磁盘,从而占用更多的磁盘空间。如果磁盘空间不足,可能会影响Elasticsearch集群的稳定性。
5.3 当fielddata内存使用量增高时如何处理?
有以下几种方法可以减少fielddata内存使用量:
-
使用 doc values 替代 fielddata:doc values 是一种结构化的、只读的数据结构,可以直接被用于排序、聚合和脚本,与 fielddata 相比可以减少内存使用。可以使用 doc_values 属性将字段显式地配置为使用 doc values。
-
避免过度使用 text 类型的字段:text 类型的字段会产生 fielddata,如果不需要进行全文搜索、聚合、排序等操作,可以考虑使用 keyword 类型的字段来替代。
-
减少不必要的聚合操作:聚合操作会对 fielddata 进行操作,如果聚合操作不是必须的,可以考虑避免使用。
-
增加 fielddata 缓存大小:可以通过在配置文件中设置 indices.fielddata.cache.size 来增加 fielddata 缓存大小,从而减少 fielddata 的内存使用。
-
减少索引的字段数:减少索引的字段数可以减少 fielddata 的内存使用。
注意,以上方法需要根据具体情况来选择,不同的情况可能需要不同的方法来减少 fielddata 内存使用量。
相关文章:
-集群关键指标及调优指南)
Elasticsearch深入理解(十八)-集群关键指标及调优指南
1、CPU使用率 CPU使用率是指在一段时间内CPU执行程序的百分比,它是衡量系统资源利用率的一种指标。 1.1 详细说明: 在Elasticsearch中,高的CPU使用率通常意味着节点正在执行大量的计算任务,这可能是因为索引和搜索操作的负载较大…...
Transformer到底为何这么牛
从注意力机制(attention)开始,近两年提及最多的就是Transformer了,那么Transformer到底是什么机制,凭啥这么牛?各个领域都能用?一文带你揭开Transformer的神秘面纱。 目录 1.深度学习࿰…...

【Spring事务】声明式事务 使用详解
个人简介:Java领域新星创作者;阿里云技术博主、星级博主、专家博主;正在Java学习的路上摸爬滚打,记录学习的过程~ 个人主页:.29.的博客 学习社区:进去逛一逛~ 声明式事务一、编程式事务二、声明式事务&…...
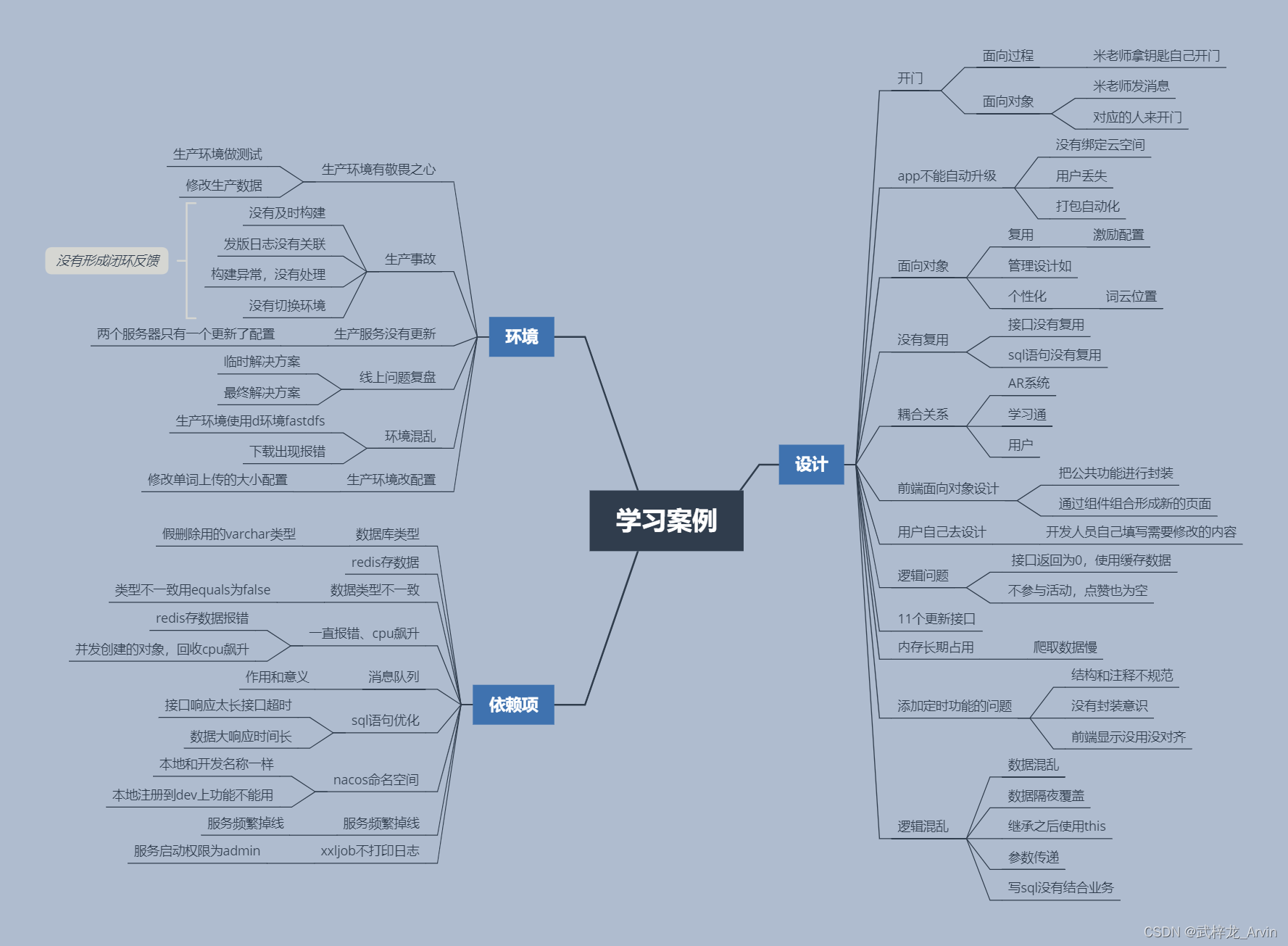
学习28个案例总结
学习前 对于之前遇到的问题没有及时总结,导致做什么事情都是新的一样。没有把之前学习到接触到的内容应用上。通过这次对28个案例的学习。把之前遇到的问题总结成自己的经验,在以后的开发过程中避免踩重复性的坑。多看帮助少走弯路。 学习中 对28个案例…...

刷题Java常用方法总结
刷题Java常用方法总结 文章目录刷题Java常用方法总结快速查看:静态数组 Static Array初始化instance属性length技巧Arrays.sort从小到大排序Arrays.fill填满一个数组Arrays.copyOf / arr.clone()复制一个数组(二维数组也可以)动态数组 List & Dynamic Array初始化常规 - Ar…...
大数据技术之Hive
第1章Hive基本概念1.1 Hive1.1.1 Hive的产生背景在那一年的大数据开源社区,我们有了HDFS来存储海量数据、MapReduce来对海量数据进行分布式并行计算、Yarn来实现资源管理和作业调度。但是面对海量数据和负责的业务逻辑,开发人员要编写MR来对数据进行统计…...

第33篇:Java集合类框架总结
目录 1、集合概念 2、集合与数组的区别 3、集合框架的特性 1)高性能 2)可操作...
数据结构 | 栈的中缀表达式求值
目录 什么是栈? 栈的基本操作 入栈操作 出栈操作 取栈顶元素 中缀表达式求值 实现思路 具体代码 什么是栈? 栈是一种线性数据结构,具有“先进后出”(Last In First Out, LIFO)的特点。它可以看作是一种受限的…...
vue2前端实现html导出pdf功能
1. 功能实现方案 1.html转换成canvas后生成图片导出pdf(本文选用) html转canvas插件:html2canvas是一款将HTML代码转换成Canvas的插件;canvas生成pdf:jsPDF是一个使用Javascript语言生成PDF的开源库 2.HTML代码转出…...

用 ChatGPT 辅助学好机器学习
文章目录一、前言二、主要内容🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 探索更高效的学习方法可能是有志者共同的追求,用好 ChatGPT,先行于未来。 作为一个人工智能大语言模型,ChatGPT 可以在帮助初…...
【动态规划】最长上升子序列(单调队列、贪心优化)
Halo,这里是Ppeua。平时主要更新C语言,C,数据结构算法......感兴趣就关注我吧!你定不会失望。 🌈个人主页:主页链接 🌈算法专栏:专栏链接 我会一直往里填充内容哒! &…...
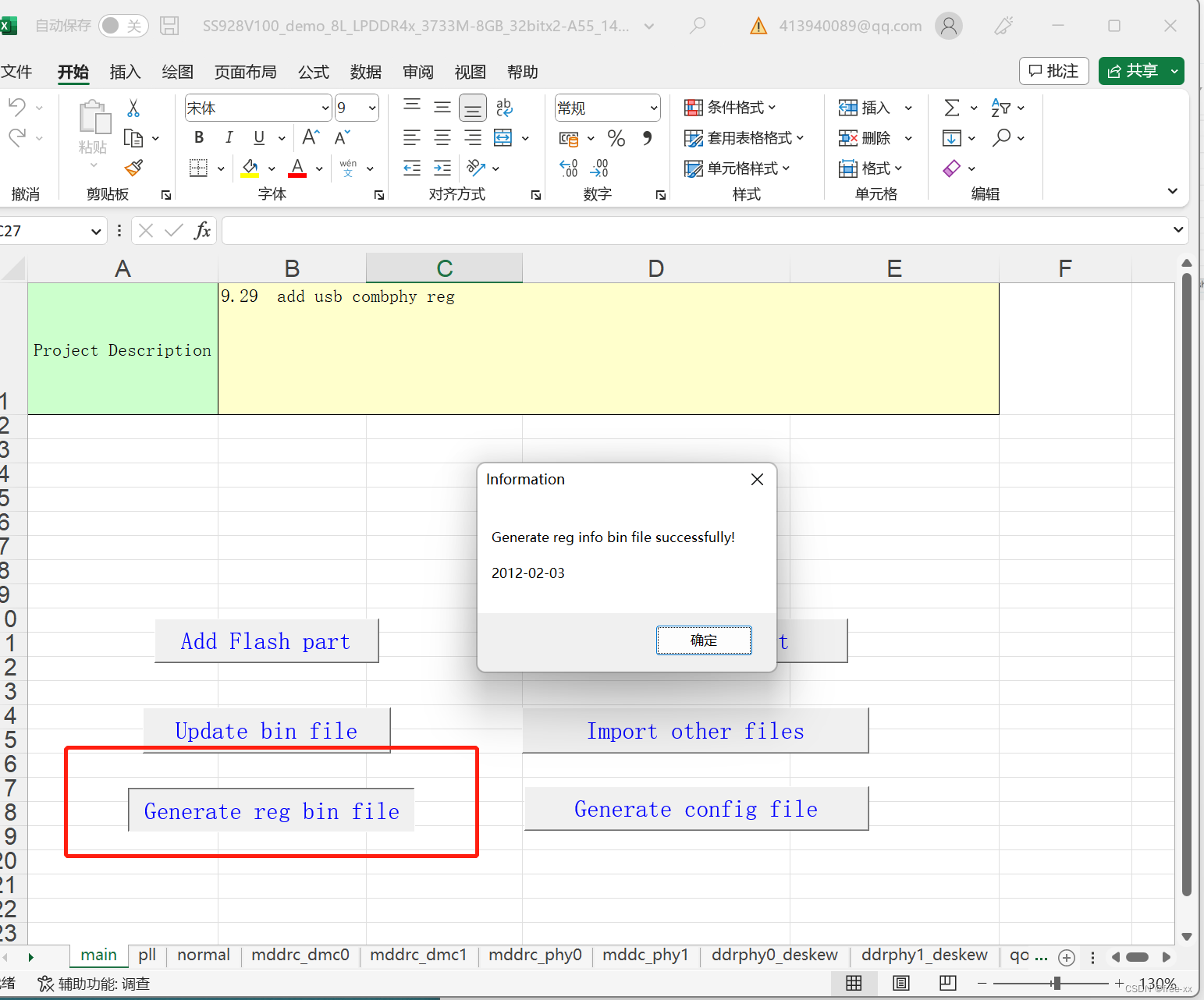
海思SD3403/SS928V100开发(7)mcp2515-SPI转CAN驱动开发
1. 前言 需求: 需要一路can进行收发 分析: 根据目前使用较多的方案是使用主控端SPI接口 接入MCP2515芯片进行CAN协议转换 硬件: MCP2515->SPI2->SS928 2. Uboot开发 2.1 pinmux复用配置 2.1.1 修改uboot参数表 路径: osdrv/tools/pc/uboot_tools/ SS928V100…...
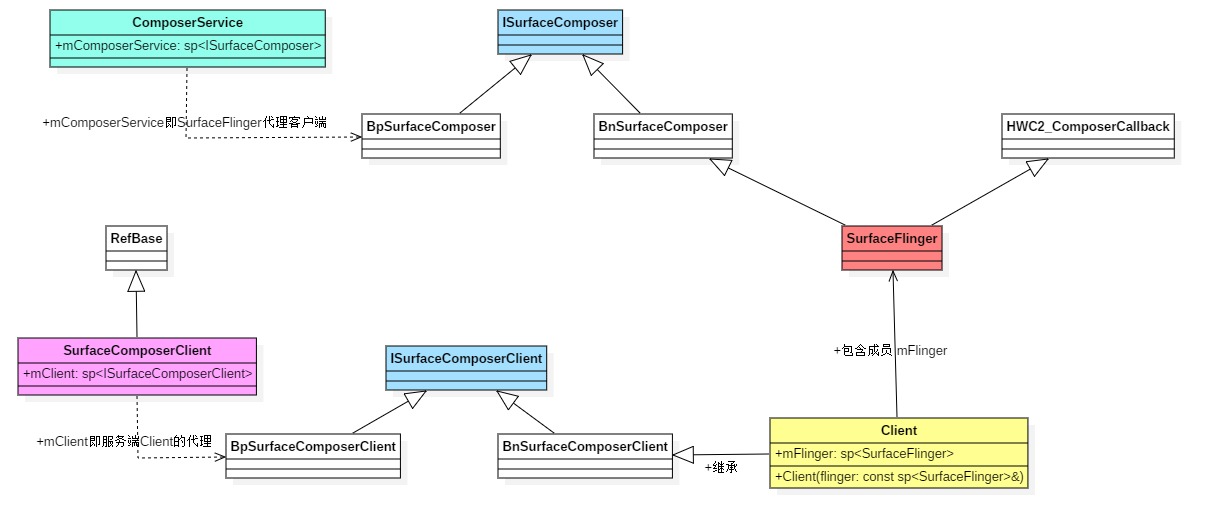
【安卓源码】SurfaceFlinger 启动及其与应用通信
1. surfaceFlinger 初始化和消息队列处理机制 surfaceflinger 的makefile 文件 /frameworks/native/services/surfaceflinger/Android.bp 235 cc_binary { 236 name: "surfaceflinger", 237 defaults: ["libsurfaceflinger_binary"], 238 i…...
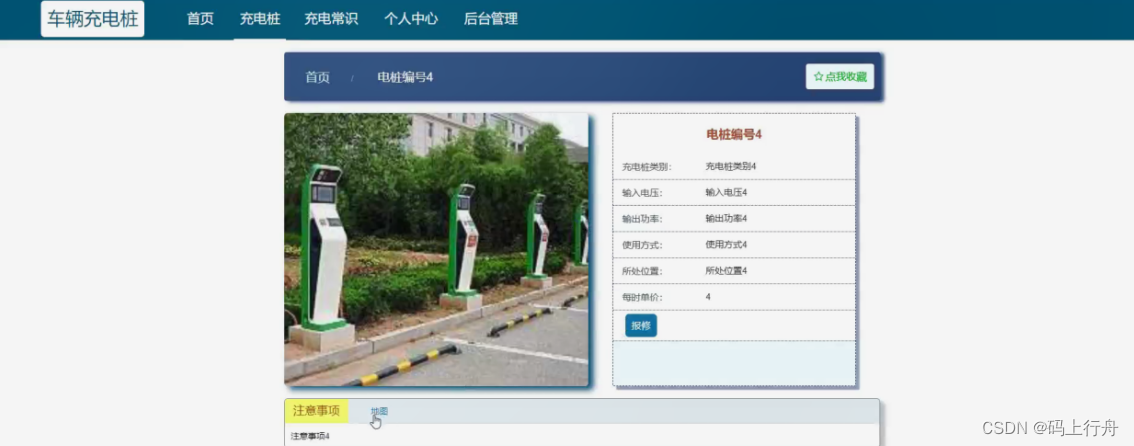
springboot车辆充电桩
sprinboot车辆充电桩演示录像2022开发语言:Java 框架:springboot JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7(一定要5.7版本) 数据库工具:Navicat11 开发软件:ecli…...

linux进程和进程通信编程(1)
What makes the desert beautiful is that somewhere it hides a well. 沙漠之所以美丽,是因为在它的某个角落隐藏着一口井. linux进程和进程通信编程(1)1.什么是进程2.进程id(pid)3.进程间通信的方法管道信号IPCSocket4.创建进程forkfork有三个返回值父…...

操作系统(1.3)--习题
一、课堂习题 1、一个作业第一 次执行时用了5min ,而第二次执行时用了6min,这说明了操作系统的( )特点。 A、并发性 B、共享性 C、虚拟性 D、不确定性 D 2、在计算机系统中,操作系统是( )。 A、处于裸机之上的第一层软件 B、处于硬件之下的低层软件 C、处于应用软件之上的系统软…...

刷题笔记之十三(有假币、最难的问题、因子个数)
目录 1. 求正数数组的最小不可组成和 2. 有假币 3. 继承时先调用父类的构造方法;类中的成员变量的初始化操作都在构造方法时进行 4. 学会并理解装箱拆箱,注意new出来的也可以拆!! 5. getDeclaredMethods()是标识类或接口的声明成员(这个表示public private 包访问权限 pro…...
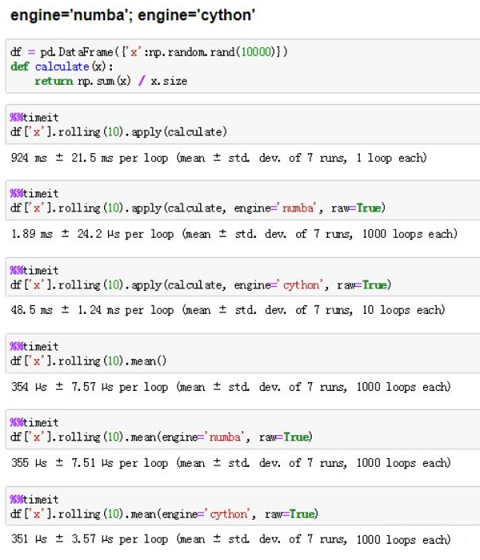
5个代码技巧,加速你的Python
5个代码技巧,加速你的Python 人生苦短,快学Python! Python作为一种功能强大的编程语言,因其简单易学而受到很多初学者的青睐。它的应用领域又非常广泛:科学计算、游戏开发、爬虫、人工智能、自动化办公、Web应用开发…...

字节跳动软件测试岗,前两面过了,第三面HR天坑!竟然跟我说……
阎王易见,小鬼难缠。我一直相信这个世界上好人居多,但是也没想到自己也会在阴沟里翻船。我感觉自己被字节跳动的HR坑了。在这里,我只想告诫大家,offer一定要拿到自己的手里才是真的,口头offer都是不牢靠的,…...
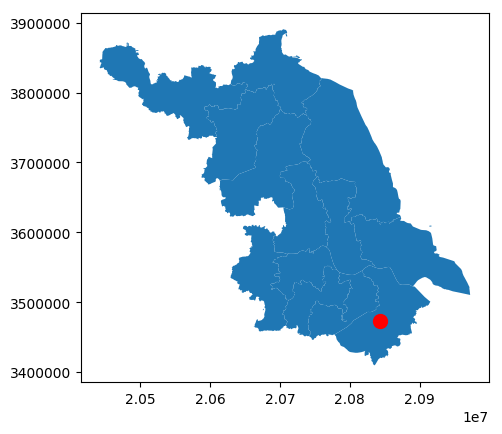
[数据分析与可视化] Python绘制数据地图1-GeoPandas入门指北
本文主要介绍GeoPandas的基本使用方法,以绘制简单的地图。GeoPandas是一个Python开源项目,旨在提供丰富而简单的地理空间数据处理接口。GeoPandas扩展了Pandas的数据类型,并使用matplotlib进行绘图。GeoPandas官方仓库地址为:GeoP…...

Granite TimeSeries FlowState R1高可用部署架构:基于Kubernetes的容器化方案
Granite TimeSeries FlowState R1高可用部署架构:基于Kubernetes的容器化方案 如果你正在为时间序列预测模型的生产部署而头疼,担心服务不稳定、无法应对流量高峰,那么这篇文章就是为你准备的。今天,我们来聊聊如何把一个强大的时…...

Vue3项目实战:5分钟搞定DeepSeek API对接,打造你的专属AI聊天助手
Vue3项目实战:5分钟搞定DeepSeek API对接,打造你的专属AI聊天助手 最近在重构个人博客时,突然想到如果能给访客加个智能问答助手应该挺酷的。作为一个长期混迹开源社区的全栈开发者,我习惯性先搜了圈现有方案——结果发现DeepSeek…...

从工作流到超级智能体,Claude Code 重构AI应用底层逻辑
从工作流到超级智能体,Claude Code 重构AI应用底层逻辑 当AI应用从简单的对话交互,逐步演进到复杂的自动化工作流,再到如今的自主智能体时代,行业始终在探寻更高效、更智能的系统架构范式。Anthropic推出的Claude Code,…...

Windows右键菜单效率革命:ContextMenuManager极简操作与深度定制指南
Windows右键菜单效率革命:ContextMenuManager极简操作与深度定制指南 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 每天面对电脑上杂乱的右键菜单&…...

别再手动改配置了!用Docker Compose一键部署Pikachu靶场,5分钟搞定测试环境
5分钟极速搭建Pikachu靶场:Docker Compose自动化实战指南 每次准备网络安全练习环境时,最头疼的莫过于反复安装配置各种服务——PHP版本不兼容、MySQL连接失败、Web服务器配置错误...这些琐碎问题消耗了本应用于渗透测试学习的宝贵时间。今天要分享的这套…...

GPEN肖像增强使用技巧:自然、强力、细节三种模式适用场景解析
GPEN肖像增强使用技巧:自然、强力、细节三种模式适用场景解析 1. 认识GPEN的三种处理模式 GPEN作为当前最先进的肖像增强工具之一,其核心价值在于提供了三种差异化的处理模式:自然、强力和细节。这三种模式不是简单的强度差异,而…...

ARMv8汇编指令实战解析:adrp、adr与adr_l在Linux内核启动中的应用
1. ARMv8寻址指令家族概览 在ARMv8架构中,adrp、adr和adr_l这三个指令堪称地址计算的"三剑客"。它们虽然名字相似,但各自有着独特的设计哲学和应用场景。就像搬家时选择不同的交通工具——adr是短途搬运的小推车,adrp是能承载重物的…...

uniapp 如何实现google登录-安卓端
uniapp 如何实现google登录-安卓端 本文只讲解uniapp安卓端如何获取到idToken来实现登录,ios使用uniapp官方方法可以获取 海外app貌似最常用的就是邮箱登录,在app上表现出来最常用的就是谷歌一键登录,或者邮箱加网页验证;google登…...

Qwen3-0.6B-FP8应用场景:开发者测试LLM应用前端UI兼容性的沙盒环境
Qwen3-0.6B-FP8应用场景:开发者测试LLM应用前端UI兼容性的沙盒环境 1. 引言:为什么需要一个轻量级的“测试沙盒”? 如果你正在开发一个基于大语言模型的应用,比如一个智能客服系统、一个文档助手,或者一个创意写作工…...

mxbai-embed-large-v1 应用开发:从零构建智能文档检索系统
mxbai-embed-large-v1 应用开发:从零构建智能文档检索系统 1. 项目概述与核心价值 mxbai-embed-large-v1 是由 mixedbread-ai 开发的高性能文本嵌入模型,在 MTEB 基准测试中超越了 OpenAI text-embedding-3-large 等商业模型。该模型能够将文本转换为高…...