ElasticSearch快速入门详解(亲测好用,强烈推荐收藏)
3.快速入门
接下来快速看下elasticsearch的使用
3.1.概念
Elasticsearch虽然是一种NoSql库,但最终的目的是存储数据、检索数据。因此很多概念与MySQL类似的。
| ES中的概念 | 数据库概念 | 说明 |
|---|---|---|
| 索引库(indices) | 数据库(Database) | ES中可以有多个索引库,就像Mysql中有多个Database一样。 |
| 类型 | 表(table) | mysql中database可以有多个table,table用来约束数据结构。而ES中的每个索引库中只有一个类型,类型中用来约束字段属性的叫做映射(mapping) |
| 映射(mappings) | 表的字段约束 | mysql表对字段有约束,ES中叫做映射,用来约束字段属性,包括:字段名称、数据类型等信息 |
| 文档(document) | 行(Row) | 存入索引库原始的数据,比如每一条商品信息,就是一个文档。对应mysql中的每行数据 |
| 字段(field) | 列(Column) | 文档中的属性,一个文档可以有多个属性。就像mysql中一行数据可以有多个列。 |
因此,我们对ES的操作,就是对索引库、类型映射、文档数据的操作:
- 索引库操作:主要包含创建索引库、查询索引库、删除索引库等
- 类型映射操作:主要是创建类型映射、查看类型映射
- 文档操作:文档的新增、修改、删除、查询
Rest的API介绍
操作MySQL,主要是database操作、表操作、数据操作,对应在elasticsearch中,分别是对索引库操作、类型映射操作、文档数据的操作:
- 索引库操作:主要包含创建索引库、查询索引库、删除索引库等
- 类型映射操作:主要是创建类型映射、查看类型映射
- 文档操作:文档的新增、修改、删除、查询
而ES中完成上述操作都可以通过Rest风格的API来完成,符合请求要求的Http请求就可以完成数据的操作,详见官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
下面我们分别来学习。
4.ES的索引库操作
按照Rest风格,增删改查分别使用:POST、DELETE、PUT、GET等请求方式,路径一般是资源名称。因此索引库操作的语法类似。
4.1.创建索引库
创建索引库的请求格式:
-
请求方式:PUT
-
请求路径:/索引库名
-
请求参数:格式:
{"settings": {"属性名": "属性值"} }settings:就是索引库设置,其中可以定义索引库的各种属性,目前我们可以不设置,都走默认。
示例:
put /索引库名
{"settings": {"属性名": "属性值"}
}
在Kibana中测试一下:
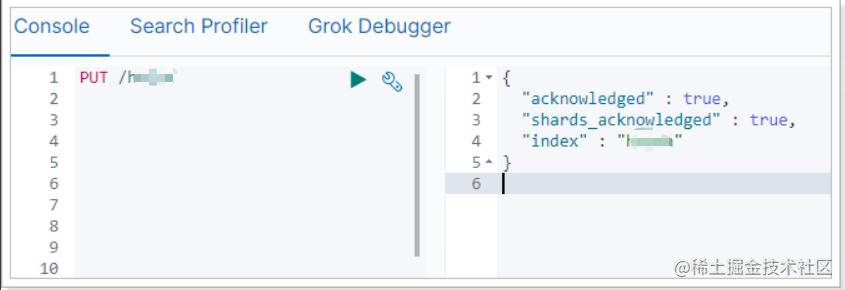
这里我们没有写settings属性,索引库配置都走默认。
4.2.查询索引库
Get请求可以帮我们查看索引信息,格式:
GET /索引库名
在Kibana中测试一下:
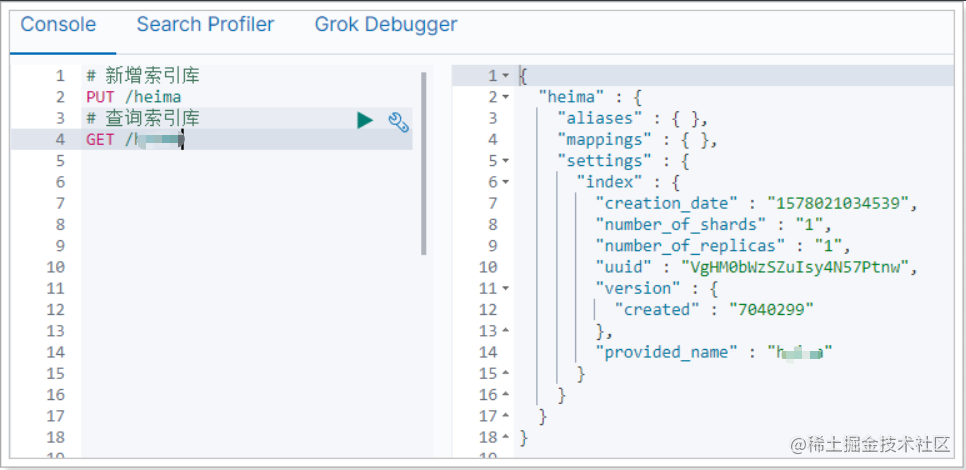
可以看到返回的信息也是JSON格式,其中包含这么几个属性:
- mappings:类型映射,目前我们没有给索引库设置映射
- settings:索引库配置,目前是默认配置
4.3.删除索引库
删除索引使用DELETE请求,格式:
DELETE /索引库名
在Kibana中测试一下:
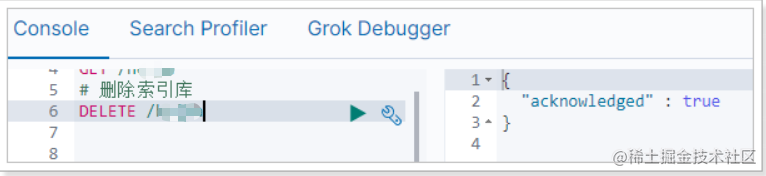
4.4.总结
索引库操作:
- 创建索引库:
PUT /库名称 - 查询索引库:
GET /索引库名称 - 删除索引库:
DELETE /索引库名称
5.类型映射
MySQL中有表,并且表中有对字段的约束,对应到elasticsearch中就是类型映射mapping.
5.1.映射属性
索引库数据类型是松散的,不过也需要我们指定具体的字段及字段约束信息。而约束字段信息的就叫做映射(mapping)。
映射属性包括很多:
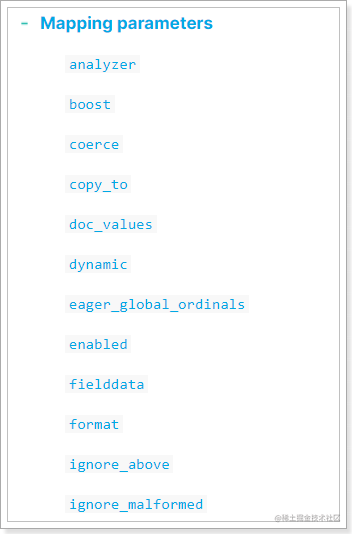
参考官网:https://www.elastic.co/guide/en/elasticsearch/reference/7.x/mapping-params.html
elasticsearch字段的映射属性该怎么选,除了字段名称外,我们一般要考虑这样几个问题:
-
1)数据的类型是什么?
- 这个比较简单,根据字段的含义即可知道,可以通过
type属性来指定
- 这个比较简单,根据字段的含义即可知道,可以通过
-
2)数据是否参与搜索?
- 参与搜索的字段将来需要创建倒排索引,作为搜索字段。可以通过
index属性来指定是否参与搜索,默认为true,也就是每个字段都参与搜索
- 参与搜索的字段将来需要创建倒排索引,作为搜索字段。可以通过
-
3)数据存储时是否需要分词?
- 一个字段的内容如果不是一个不可分割的整体,例如国家,一般都需要分词存储。
-
4)如果分词的话用什么分词器?
- 分词器类型很多,中文一般选择IK分词器
- 指定分词器类型可以通过
analyzer属性指定
5.2.数据类型
elasticsearch提供了非常丰富的数据类型:
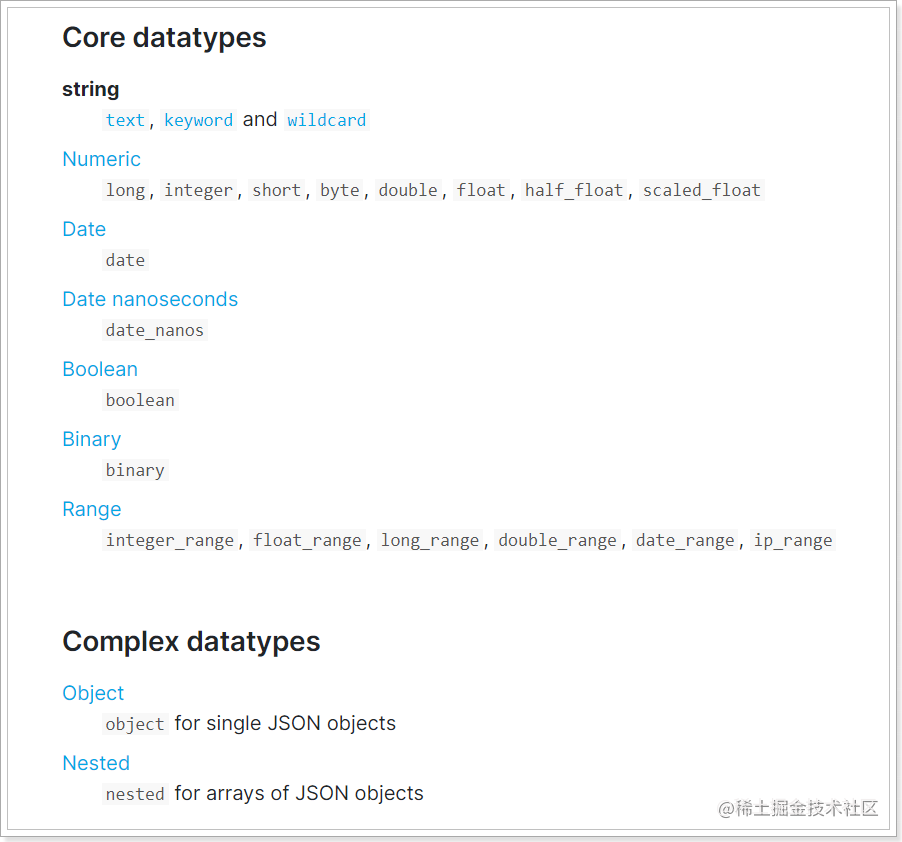
比较常见的有:
-
string类型,又分两种:
- text:可分词,存储到elasticsearch时会根据分词器分成多个词条
- keyword:不可分词,数据会完整的作为一个词条
-
Numerical:数值类型,分两类
-
基本数据类型:long、interger、short、byte、double、float、half_float
-
浮点数的高精度类型:scaled_float
- 需要指定一个精度因子,比如10或100。elasticsearch会把真实值乘以这个因子后存储,取出时再还原。
-
-
Date:日期类型
-
Object:对象,对象不便于搜索。因此ES会把对象数据扁平化处理再存储。
5.3.创建类型映射
我们可以给一个已经存在的索引库添加映射关系,也可以创建索引库的同时直接指定映射关系。
5.3.1.索引库已经存在
我们假设已经存在一个索引库,此时要给索引库添加映射。
语法
请求方式依然是PUT
PUT /索引库名/_mapping
{"properties": {"字段名1": {"type": "类型","index": true,"analyzer": "分词器"},"字段名2": {"type": "类型","index": true,"analyzer": "分词器"},...}
}
-
类型名称:就是前面将的type的概念,类似于数据库中的表 字段名:任意填写,下面指定许多属性,例如:
- type:类型,可以是text、long、short、date、integer、object等
- index:是否参与搜索,默认为true
- analyzer:分词器
示例
发起请求:
PUT /hello/_mapping
{"properties": {"title": {"type": "text","analyzer": "ik_max_word"},"images": {"type": "keyword","index": "false"},"price": {"type": "float"}}
}
响应结果:
{"acknowledged": true
}
上述案例中,就给hello这个索引库中设置了3个字段:
-
title:商品标题
- index:标题一般都参与搜索,所以index没有配置,按照默认为true
- type: 标题是字符串类型,并且参与搜索和分词,所以用text
- analyzer:标题内容一般较多,查询时需要分词,所以指定了IK分词器
-
images:商品图片
- type:图片是字符串,并且url不需要分词,所以用keyword
- index:图片url不参与搜索,所以给false
-
price:商品价格
- type:价格,浮点型,这里给了float
- index:这里没有配置,默认是true,代表参与搜索
并且给这些字段设置了一些属性:
5.3.2.索引库不存在
如果一个索引库是不存在的,我们就不能用上面的语法,而是这样:
PUT /索引库名
{"mappings":{"properties": {"字段名1": {"type": "类型","index": true,"analyzer": "分词器"},"字段名2": {"type": "类型","index": true,"analyzer": "分词器"},...}}
}
示例:
# 创建索引库和映射
PUT /hello2
{"mappings": {"properties": {"title": {"type": "text","analyzer": "ik_max_word"},"images": {"type": "keyword","index": "false"},"price": {"type": "float"}}}
}
结果:
{"acknowledged" : true,"shards_acknowledged" : true,"index" : "hello"
}
5.4.查看映射关系
查看使用Get请求
语法:
GET /索引库名/_mapping
示例:
GET /hello/_mapping
响应:
{"hello" : {"aliases" : { },"mappings" : {"properties" : {"images" : {"type" : "keyword","index" : false},"price" : {"type" : "float"},"title" : {"type" : "text","analyzer" : "ik_max_word"}}},"settings" : {"index" : {"creation_date" : "1590744589271","number_of_shards" : "1","number_of_replicas" : "1","uuid" : "v7AHmI9ST76rHiCNHb5KQg","version" : {"created" : "7040299"},"provided_name" : "hello"}}}
}
6.文档的操作
我们把数据库中的每一行数据查询出来,存入索引库,就是文档。文档的主要操作包括新增、查询、修改、删除。
6.1.新增文档
6.1.1.新增并随机生成id
通过POST请求,可以向一个已经存在的索引库中添加文档数据。ES中,文档都是以JSON格式提交的。
语法:
POST /{索引库名}/_doc
{"key":"value"
}
示例:
# 新增文档数据
POST /hello/_doc
{"title":"小米手机","images":"http://image.leyou.com/12479122.jpg","price":2699.00
}
响应:
{"_index" : "hello","_type" : "_doc","_id" : "rGFGbm8BR8Fh6kyTbuq8","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 0,"_primary_term" : 1
}
结果解释:
_index:新增到了哪一个索引库。_id:这条文档数据的唯一标示,文档的增删改查都依赖这个id作为唯一标示。此处是由ES随即生成的,我们也可以指定使用某个IDresult:执行结果,可以看到结果显示为:created,说明文档创建成功。
6.1.1.新增并指定id
通过POST请求,可以向一个已经存在的索引库中添加文档数据。ES中,文档都是以JSON格式提交的。
语法:
POST /{索引库名}/_doc/{id}
{"key":"value"
}
示例:
# 新增文档数据并指定id
POST /hello/_doc/1
{"title":"小米手机","images":"http://image.lello.com/12479122.jpg","price":2699.00
}
响应:
{"_index" : "hello","_type" : "_doc","_id" : "1","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 1,"_primary_term" : 1
}
同样新增成功了!
6.2.查看文档
根据rest风格,新增是post,查询应该是get,不过查询一般都需要条件,这里我们把刚刚生成数据的id带上。
语法:
GET /{索引库名称}/_doc/{id}
通过kibana查看数据:
GET /hello/_doc/rGFGbm8BR8Fh6kyTbuq8
查看结果:
{"_index": "hello","_type": "goods","_id": "r9c1KGMBIhaxtY5rlRKv","_version": 1,"found": true,"_source": {"title": "小米手机","images": "http://image.lello.com/12479122.jpg","price": 2699}
}
_source:源文档信息,所有的数据都在里面。
6.3.修改文档
把刚才新增的请求方式改为PUT,就是修改了。不过修改必须指定id,
- id对应文档存在,则修改
- id对应文档不存在,则新增
比如,我们把使用id为3,不存在,则应该是新增:
# 新增
PUT /hello/_doc/2
{"title":"大米手机","images":"http://image.lello.com/12479122.jpg","price":2899.00
}
结果:
{"_index" : "hello","_type" : "_doc","_id" : "2","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 2,"_primary_term" : 1
}
可以看到是created,是新增。
我们再次执行刚才的请求,不过把数据改一下:
# 修改
PUT /hello/_doc/2
{"title":"大米手机Pro","images":"http://image.lello.com/12479122.jpg","price":3099.00
}
查看结果:
{"_index" : "hello","_type" : "_doc","_id" : "2","_version" : 2,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 3,"_primary_term" : 1
}
可以看到结果是:updated,显然是更新数据
说明:
es对API的要求并没有那么严格
如:
- POST 新增文档时:如果指定了id,并且id在索引库不存在,直接存入索引库;如果id已经存在,则执行修改
- PUT修改文档时:先根据id删除指定文档,然后加入新的文档
- PUT修改文档时: 如果对应的文档不存在时,会添加该文档
6.4.删除文档
删除使用DELETE请求,同样,需要根据id进行删除:
语法
DELETE /索引库名/类型名/id值
示例
# 根据id删除数据
DELETE /hello/_doc/rGFGbm8BR8Fh6kyTbuq8
结果:
{"_index" : "hello","_type" : "_doc","_id" : "rGFGbm8BR8Fh6kyTbuq8","_version" : 2,"result" : "deleted","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 4,"_primary_term" : 1
}
可以看到结果result为:deleted,说明删除成功了。
6.5.默认映射
刚刚我们在新增数据时,添加的字段都是提前在类型中通过mapping定义过的,如果我们添加的字段并没有提前定义过,能够成功吗?
事实上Elasticsearch有一套默认映射规则,如果新增的字段从未定义过,那么就会按照默认映射规则来存储。
测试一下:
# 新增未映射字段
POST /hello/_doc/3
{"title":"超大米手机","images":"http://image.lello.com/12479122.jpg","price":3299.00,"stock": 200,"saleable":true,"subTitle":"超级双摄,亿级像素"
}
我们额外添加了stock库存,saleable是否上架,subtitle副标题、3个字段。
来看结果:
{"_index" : "hello","_type" : "_doc","_id" : "3","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 5,"_primary_term" : 1
}
成功了!在看下索引库的映射关系:
{"hello" : {"mappings" : {"properties" : {"images" : {"type" : "keyword","index" : false},"price" : {"type" : "float"},"saleable" : {"type" : "boolean"},"stock" : {"type" : "long"},"subTitle" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"title" : {"type" : "text","analyzer" : "ik_max_word"}}}}
}
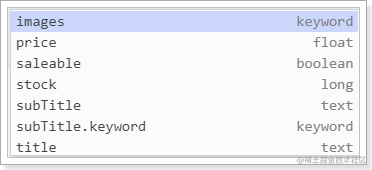
stock、saleable、subtitle都被成功映射了:
-
stock:默认映射为long类型
-
saleable:映射为布尔类型
-
subtitle是String类型数据,ES无法确定该用text还是keyword,它就会存入两个字段。例如:
- subtitle:text类型
- subtitle.keyword:keyword类型
如图:
6.6.动态映射模板
6.6.1.基本语法
默认映射规则不一定符合我们的需求,我们可以按照自己的方式来定义默认规则。这就需要用到动态模板了。
动态模板的语法:
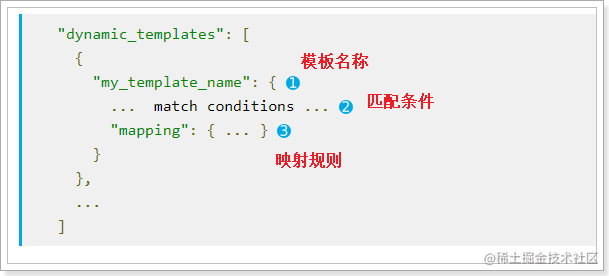
-
模板名称,随便起
-
匹配条件,凡是符合条件的未定义字段,都会按照这个mapping中的规则来映射,匹配规则包括:
match_mapping_type:按照数据类型匹配,如:string匹配字符串类型,long匹配整型match和unmatch:按照名称通配符匹配,如:t_*匹配名称以t开头的字段
-
映射规则,匹配成功后的映射规则
凡是映射规则中未定义,而符合2中的匹配条件的字段,就会按照3中定义的映射方式来映射
6.6.2.示例
在kibana中定义一个索引库,并且设置动态模板:
# 动态模板
PUT hello3
{"mappings": {"properties": {"title": {"type": "text","analyzer": "ik_max_word"}},"dynamic_templates": [{"strings": { "match_mapping_type": "string","mapping": {"type": "keyword"}}}]}
}
这个动态模板的意思是:凡是string类型的自动,统一按照 keyword来处理。
接下来新增一个数据试试:
POST /hello2/_doc/1
{"title":"超大米手机","images":"http://image.lello.com/12479122.jpg","price":3299.00
}
然后查看映射:
GET /hello2/_mapping
结果:
{"hello2" : {"mappings" : {"dynamic_templates" : [{"strings" : {"match_mapping_type" : "string","mapping" : {"type" : "keyword"}}}],"properties" : {"images" : {"type" : "keyword"},"price" : {"type" : "float"},"title" : {"type" : "text","analyzer" : "ik_max_word"}}}}
}
可以看到images是一个字符串,被映射成了keyword类型。
7.查询
首先我们批量导入一些数据,方便后面的讲解:
# 删除hello索引库
DELETE /hello
# 重新创建
PUT /hello
{"mappings": {"properties": {"title": {"type": "text","analyzer": "ik_max_word"},"images": {"type": "keyword","index": "false"},"price": {"type": "float"}}}
}
# 批量导入
POST _bulk
{"index":{"_index":"hello","_type":"_doc","_id":"1"}}
{"title":"三星 Note II (N7100) 云石白 联通3G手机","images":"http://image.leyou.com/12479122.jpg","price":2599.00}
{"index":{"_index":"hello","_type":"_doc","_id":"2"}}
{"title":"三星 B9120 钛灰色 联通3G手机 双卡双待双通","images":"http://image.leyou.com/12479122.jpg","price":2899.00}
{"index":{"_index":"hello","_type":"_doc","_id":"3"}}
{"title":"夏普(SHARP)LCD-46DS40A 46英寸 日本原装液晶面板 智能全高清液晶电视","images":"http://image.leyou.com/12479122.jpg","price":12880.00}
{"index":{"_index":"hello","_type":"_doc","_id":"4"}}
{"title":"中兴 U288 珠光白 移动3G手机","images":"http://image.leyou.com/12479122.jpg","price":1099.00}
{"index":{"_index":"hello","_type":"_doc","_id":"5"}}
{"title":"飞利浦 老人手机 (X2560) 喜庆红 移动联通2G手机 双卡双待","images":"http://image.leyou.com/12479122.jpg","price":500.00}
{"index":{"_index":"hello","_type":"_doc","_id":"6"}}
{"title":"诺基亚(NOKIA) 1050 (RM-908) 黑色 移动联通2G手机","images":"http://image.leyou.com/12479122.jpg","price":998.00}
{"index":{"_index":"hello","_type":"_doc","_id":"7"}}
{"title":"海信(Hisense)LED42EC260JD 42英寸 窄边网络 LED电视(黑色)","images":"http://image.leyou.com/12479122.jpg","price":3255.00}
{"index":{"_index":"hello","_type":"_doc","_id":"8"}}
{"title":"酷派 8076D 咖啡棕 移动3G手机 双卡双待","images":"http://image.leyou.com/12479122.jpg","price":1499.00}
{"index":{"_index":"hello","_type":"_doc","_id":"9"}}
{"title":"华为 P6 (P6-C00) 黑 电信3G手机 双卡双待双通", "images":"http://image.leyou.com/12479122.jpg","price":2340.00}
{"index":{"_index":"hello","_type":"_doc","_id":"10"}}
{"title":"康佳(KONKA) LED42K11A 42英寸 网络安卓智能液晶电视(黑色+银色)","images":"http://image.leyou.com/12479122.jpg","price":3699.00}
7.1.基本查询
elasticsearch提供的查询方式有很多,例如:
- 查询所有
- 分词查询
- 词条查询
- 模糊查询
- 范围查询
- 布尔查询
虽然查询的方式有很多,但是基本语法是一样的:
基本语法
GET /索引库名/_search
{"query":{"查询类型":{"查询条件":"查询条件值"}}
}
这里的query代表一个查询对象,里面可以有不同的查询属性
-
查询类型,有许多固定的值,如:
- match_all:查询所有
- match:分词查询
- term:词条查询
- fuzzy:模糊查询
- range:范围查询
- bool:布尔查询
-
查询条件:查询条件会根据类型的不同,写法也有差异,后面详细讲解
注意: 只有index为true的字段才可以作为查询条件哦~~
7.1.1 查询所有match_all
示例:
# 查询所有 match_all
GET /hello/_search
{"query":{"match_all": {}}
}
query:代表查询对象match_all:代表查询所有
结果:
{"took" : 3,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 10,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "hello","_type" : "_doc","_id" : "2","_score" : 1.0,"_source" : {"title" : "三星 Note II (N7100) 云石白 联通3G手机","images" : "http://image.leyou.com/12479122.jpg","price" : 2599}},{"_index" : "hello","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"title" : "三星 B9120 钛灰色 联通3G手机 双卡双待双通","images" : "http://image.leyou.com/12479122.jpg","price" : 2899}},{"_index" : "hello","_type" : "_doc","_id" : "3","_score" : 1.0,"_source" : {"title" : "夏普(SHARP)LCD-46DS40A 46英寸 日本原装液晶面板 智能全高清液晶电视","images" : "http://image.leyou.com/12479122.jpg","price" : 12880}},{"_index" : "hello","_type" : "_doc","_id" : "4","_score" : 1.0,"_source" : {"title" : "中兴 U288 珠光白 移动3G手机","images" : "http://image.leyou.com/12479122.jpg","price" : 1099}},{"_index" : "hello","_type" : "_doc","_id" : "5","_score" : 1.0,"_source" : {"title" : "飞利浦 老人手机 (X2560) 喜庆红 移动联通2G手机 双卡双待","images" : "http://image.leyou.com/12479122.jpg","price" : 500}},{"_index" : "hello","_type" : "_doc","_id" : "6","_score" : 1.0,"_source" : {"title" : "诺基亚(NOKIA) 1050 (RM-908) 黑色 移动联通2G手机","images" : "http://image.leyou.com/12479122.jpg","price" : 998}},{"_index" : "hello","_type" : "_doc","_id" : "7","_score" : 1.0,"_source" : {"title" : "海信(Hisense)LED42EC260JD 42英寸 窄边网络 LED电视(黑色)","images" : "http://image.leyou.com/12479122.jpg","price" : 3255}},{"_index" : "hello","_type" : "_doc","_id" : "8","_score" : 1.0,"_source" : {"title" : "酷派 8076D 咖啡棕 移动3G手机 双卡双待","images" : "http://image.leyou.com/12479122.jpg","price" : 1499}},{"_index" : "hello","_type" : "_doc","_id" : "9","_score" : 1.0,"_source" : {"title" : "华为 P6 (P6-C00) 黑 电信3G手机 双卡双待双通","images" : "http://image.leyou.com/12479122.jpg","price" : 2340}},{"_index" : "hello","_type" : "_doc","_id" : "10","_score" : 1.0,"_source" : {"title" : "康佳(KONKA) LED42K11A 42英寸 网络安卓智能液晶电视(黑色+银色)","images" : "http://image.leyou.com/12479122.jpg","price" : 3699}}]}
}
-
took:查询花费时间,单位是毫秒
-
time_out:是否超时
-
_shards:分片信息
-
hits:搜索结果总览对象
-
total:搜索到的总条数
-
max_score:所有结果中文档得分的最高分
-
hits:搜索结果的文档对象数组,每个元素是一条搜索到的文档信息
- _index:索引库
- _type:文档类型
- _id:文档id
- _score:文档得分
Elasticsearch 默认是按照文档与查询的相关度 (匹配度) 的得分倒序返回结果的. 得分 (_score) 就越大, 表示相关性越高.
- _source:文档的源数据
-
7.1.2 分词查询match
match类型查询,会把查询条件进行分词,然后进行查询,多个词条之间默认是or的关系
语法:
GET /hello/_search
{"query":{"match":{"字段名":"搜索条件"}}
}
示例:
GET /hello/_search
{"query":{"match":{"title":"三星手机"}}
}
结果:
{"took" : 5,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 7,"relation" : "eq"},"max_score" : 5.250329,"hits" : [{"_index" : "hello","_type" : "_doc","_id" : "2","_score" : 5.250329,"_source" : {"title" : "三星 Note II (N7100) 云石白 联通3G手机","images" : "http://image.leyou.com/12479122.jpg","price" : 2599}},{"_index" : "hello","_type" : "_doc","_id" : "1","_score" : 5.250329,"_source" : {"title" : "三星 B9120 钛灰色 联通3G手机 双卡双待双通","images" : "http://image.leyou.com/12479122.jpg","price" : 2899}},{"_index" : "hello","_type" : "_doc","_id" : "5","_score" : 1.0063455,"_source" : {"title" : "飞利浦 老人手机 (X2560) 喜庆红 移动联通2G手机 双卡双待","images" : "http://image.leyou.com/12479122.jpg","price" : 500}},{"_index" : "hello","_type" : "_doc","_id" : "4","_score" : 0.83515364,"_source" : {"title" : "中兴 U288 珠光白 移动3G手机","images" : "http://image.leyou.com/12479122.jpg","price" : 1099}},{"_index" : "hello","_type" : "_doc","_id" : "6","_score" : 0.8129092,"_source" : {"title" : "诺基亚(NOKIA) 1050 (RM-908) 黑色 移动联通2G手机","images" : "http://image.leyou.com/12479122.jpg","price" : 998}},{"_index" : "hello","_type" : "_doc","_id" : "8","_score" : 0.8129092,"_source" : {"title" : "酷派 8076D 咖啡棕 移动3G手机 双卡双待","images" : "http://image.leyou.com/12479122.jpg","price" : 1499}},{"_index" : "hello","_type" : "_doc","_id" : "9","_score" : 0.73464036,"_source" : {"title" : "华为 P6 (P6-C00) 黑 电信3G手机 双卡双待双通","images" : "http://image.leyou.com/12479122.jpg","price" : 2340}}]}
}
查询结果中把title 字段包含了 “三星” 或 “手机” 的数据都查询了处理,说明在默认情况下,
分词查询 将查询条件进行分词,并以 or 的关系,将所有满足条件的数据查了出来。
某些情况下,我们需要更精确查找,我们希望这个关系变成and,可以这样做:
GET /hello/_search
{"query":{"match":{"title":{"query":"三星手机","operator":"and"}}}
}
结果:
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 5.250329,"hits" : [{"_index" : "hello","_type" : "_doc","_id" : "2","_score" : 5.250329,"_source" : {"title" : "三星 Note II (N7100) 云石白 联通3G手机","images" : "http://image.leyou.com/12479122.jpg","price" : 2599}},{"_index" : "hello","_type" : "_doc","_id" : "1","_score" : 5.250329,"_source" : {"title" : "三星 B9120 钛灰色 联通3G手机 双卡双待双通","images" : "http://image.leyou.com/12479122.jpg","price" : 2899}}]}
}
本例中,只有同时包含三星和手机的词条才会被搜索到。
7.1.3 词条匹配term
term 查询,词条查询。查询的条件是一个词条,不会被分词。可以是keyword类型的字符串、数值、或者text类型字段中分词得到的某个词条.
GET /hello/_search
{"query":{"term": {"price": 2599}}
}
结果:
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "hello","_type" : "_doc","_id" : "2","_score" : 1.0,"_source" : {"title" : "三星 Note II (N7100) 云石白 联通3G手机","images" : "http://image.leyou.com/12479122.jpg","price" : 2599}}]}
}
7.1.4.模糊查询fuzzy
相似度查询
首先看一个概念,叫做编辑距离:一个词条变为另一个词条需要修改的次数,例如:
facebool 要修改成facebook 需要做的是把 l 修改成k ,一次即可,编辑距离就是1
模糊查询允许用户查询内容与实际内容存在偏差,但是编辑距离不能超过2,示例:
# 模糊查询 fuzzy
GET /hello/_search
{"query":{"fuzzy": {"title": {"value": "飞利铺","fuzziness": 1}}}
}
本例中我搜索的是飞利铺,看看结果:
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.2439895,"hits" : [{"_index" : "hello","_type" : "_doc","_id" : "5","_score" : 1.2439895,"_source" : {"title" : "飞利浦 老人手机 (X2560) 喜庆红 移动联通2G手机 双卡双待","images" : "http://image.leyou.com/12479122.jpg","price" : 500}}]}
}
可以看到结果中飞利浦还是被搜索到了。
7.1.5.范围查询range
range 查询找出那些落在指定区间内的数字或者时间
# 范围查询
GET /hello/_search
{"query": {"range": {"price": {"gte": 1000,"lt": 2800}}}
}
range查询允许以下字符:
| 操作符 | 说明 |
|---|---|
| gt | 大于 |
| gte | 大于等于 |
| lt | 小于 |
| lte | 小于等于 |
结果:
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "hello","_type" : "_doc","_id" : "2","_score" : 1.0,"_source" : {"title" : "三星 Note II (N7100) 云石白 联通3G手机","images" : "http://image.leyou.com/12479122.jpg","price" : 2599}},{"_index" : "hello","_type" : "_doc","_id" : "4","_score" : 1.0,"_source" : {"title" : "中兴 U288 珠光白 移动3G手机","images" : "http://image.leyou.com/12479122.jpg","price" : 1099}},{"_index" : "hello","_type" : "_doc","_id" : "8","_score" : 1.0,"_source" : {"title" : "酷派 8076D 咖啡棕 移动3G手机 双卡双待","images" : "http://image.leyou.com/12479122.jpg","price" : 1499}},{"_index" : "hello","_type" : "_doc","_id" : "9","_score" : 1.0,"_source" : {"title" : "华为 P6 (P6-C00) 黑 电信3G手机 双卡双待双通","images" : "http://image.leyou.com/12479122.jpg","price" : 2340}}]}
}
7.1.6.布尔查询
bool把各种其它查询通过must(与)、must_not(非)、should(或)的方式进行组合
# 想查找手机
# 想查找价格 2099 ~ 2999
# 不想用三星
GET /hello/_search
{"query": {"bool": {"must": [{"match": {"title": "手机"}},{"range": {"price": {"gte": 2099,"lte": 2999}}}],"must_not": [{"match": {"title": "三星"}}]}}
}
结果:
{"took" : 7,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.7346404,"hits" : [{"_index" : "hello","_type" : "_doc","_id" : "9","_score" : 1.7346404,"_source" : {"title" : "华为 P6 (P6-C00) 黑 电信3G手机 双卡双待双通","images" : "http://image.leyou.com/12479122.jpg","price" : 2340}}]}
}
三个关系规则:
- MUST:该规则必须有效
- MUST_NOT:该规则必须无效
- SHOULD:该规则可以有效。
常见组合:
- Must+Must:交集:结果准确 ,类似于and
- Should+Should:并集:结果最多,类似于Or
- Must+MustNot:补集:排除某结果
各种组合参考(自己理解):
1)、MUST和MUST表示“与”的关系,即“交集”。
2)、MUST和MUST_NOT前者包含后者不包含。
3)、MUST_NOT和MUST_NOT没意义
4)、SHOULD与MUST表示MUST,SHOULD失去意义;
5)、SHOUlD与MUST_NOT相当于MUST与MUST_NOT。
6)、SHOULD与SHOULD表示“或”的概念。
7.2. 排序
排序、高亮、分页并不属于查询的条件,因此并不是在query内部,而是与query平级,
基本语法:
GET /{索引库名称}/_search
{"query": { ... },"sort": [{"{排序字段}": {"order": "{asc或desc}"}}]
}
sort 可以让我们按照不同的字段进行排序,并且通过order指定排序的方式
注意: 分词字段不能参与排序哦~~
# 排序
GET /hello/_search
{"query": {"match": {"title": "手机"}},"sort": [{"price": {"order": "desc"}}]
}
结果:
{"took" : 5,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 7,"relation" : "eq"},"max_score" : null,"hits" : [{"_index" : "hello","_type" : "_doc","_id" : "1","_score" : null,"_source" : {"title" : "三星 B9120 钛灰色 联通3G手机 双卡双待双通","images" : "http://image.leyou.com/12479122.jpg","price" : 2899},"sort" : [2899.0]},{"_index" : "hello","_type" : "_doc","_id" : "2","_score" : null,"_source" : {"title" : "三星 Note II (N7100) 云石白 联通3G手机","images" : "http://image.leyou.com/12479122.jpg","price" : 2599},"sort" : [2599.0]},{"_index" : "hello","_type" : "_doc","_id" : "9","_score" : null,"_source" : {"title" : "华为 P6 (P6-C00) 黑 电信3G手机 双卡双待双通","images" : "http://image.leyou.com/12479122.jpg","price" : 2340},"sort" : [2340.0]},{"_index" : "hello","_type" : "_doc","_id" : "8","_score" : null,"_source" : {"title" : "酷派 8076D 咖啡棕 移动3G手机 双卡双待","images" : "http://image.leyou.com/12479122.jpg","price" : 1499},"sort" : [1499.0]},{"_index" : "hello","_type" : "_doc","_id" : "4","_score" : null,"_source" : {"title" : "中兴 U288 珠光白 移动3G手机","images" : "http://image.leyou.com/12479122.jpg","price" : 1099},"sort" : [1099.0]},{"_index" : "hello","_type" : "_doc","_id" : "6","_score" : null,"_source" : {"title" : "诺基亚(NOKIA) 1050 (RM-908) 黑色 移动联通2G手机","images" : "http://image.leyou.com/12479122.jpg","price" : 998},"sort" : [998.0]},{"_index" : "hello","_type" : "_doc","_id" : "5","_score" : null,"_source" : {"title" : "飞利浦 老人手机 (X2560) 喜庆红 移动联通2G手机 双卡双待","images" : "http://image.leyou.com/12479122.jpg","price" : 500},"sort" : [500.0]}]}
}
7.3. 高亮
高亮是在搜索结果中把搜索关键字标记出来,因此必须使用match这样的条件搜索。
elasticsearch中实现高亮的语法比较简单:
GET /hello/_search
{"query": {"match": {"title": "联通手机"}},"highlight": {"pre_tags": "<em>","post_tags": "</em>", "fields": {"title": {}}}
}
在使用match查询的同时,加上一个highlight属性:
-
pre_tags:前置标签,可以省略,默认是em
-
post_tags:后置标签,可以省略,默认是em
-
fields:需要高亮的字段
- title:这里声明title字段需要高亮,后面可以为这个字段设置特有配置,也可以空
结果:
{"took" : 6,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 7,"relation" : "eq"},"max_score" : 1.8434389,"hits" : [{"_index" : "hello","_type" : "_doc","_id" : "5","_score" : 1.8434389,"_source" : {"title" : "飞利浦 老人手机 (X2560) 喜庆红 移动联通2G手机 双卡双待","images" : "http://image.leyou.com/12479122.jpg","price" : 500},"highlight" : {"title" : ["飞利浦 老人<em>手机</em> (X2560) 喜庆红 移动<em>联通</em>2G<em>手机</em> 双卡双待"]}},{"_index" : "hello","_type" : "_doc","_id" : "6","_score" : 1.761483,"_source" : {"title" : "诺基亚(NOKIA) 1050 (RM-908) 黑色 移动联通2G手机","images" : "http://image.leyou.com/12479122.jpg","price" : 998},"highlight" : {"title" : ["诺基亚(NOKIA) 1050 (RM-908) 黑色 移动<em>联通</em>2G<em>手机</em>"]}},{"_index" : "hello","_type" : "_doc","_id" : "2","_score" : 1.6723943,"_source" : {"title" : "三星 Note II (N7100) 云石白 联通3G手机","images" : "http://image.leyou.com/12479122.jpg","price" : 2599},"highlight" : {"title" : ["三星 Note II (N7100) 云石白 <em>联通</em>3G<em>手机</em>"]}},{"_index" : "hello","_type" : "_doc","_id" : "1","_score" : 1.6723943,"_source" : {"title" : "三星 B9120 钛灰色 联通3G手机 双卡双待双通","images" : "http://image.leyou.com/12479122.jpg","price" : 2899},"highlight" : {"title" : ["三星 B9120 钛灰色 <em>联通</em>3G<em>手机</em> 双卡双待双通"]}},{"_index" : "hello","_type" : "_doc","_id" : "4","_score" : 0.83515364,"_source" : {"title" : "中兴 U288 珠光白 移动3G手机","images" : "http://image.leyou.com/12479122.jpg","price" : 1099},"highlight" : {"title" : ["中兴 U288 珠光白 移动3G<em>手机</em>"]}},{"_index" : "hello","_type" : "_doc","_id" : "8","_score" : 0.8129092,"_source" : {"title" : "酷派 8076D 咖啡棕 移动3G手机 双卡双待","images" : "http://image.leyou.com/12479122.jpg","price" : 1499},"highlight" : {"title" : ["酷派 8076D 咖啡棕 移动3G<em>手机</em> 双卡双待"]}},{"_index" : "hello","_type" : "_doc","_id" : "9","_score" : 0.73464036,"_source" : {"title" : "华为 P6 (P6-C00) 黑 电信3G手机 双卡双待双通","images" : "http://image.leyou.com/12479122.jpg","price" : 2340},"highlight" : {"title" : ["华为 P6 (P6-C00) 黑 电信3G<em>手机</em> 双卡双待双通"]}}]}
}
7.4. 分页
通过from和size来指定分页的开始位置及每页大小。
如果size不指定, 默认为10
语法:
GET /hello/_search
{"query": {"match_all": {}},"sort": [{"price": {"order": "asc"}}],"from": 0,"size": 2
}
结果:
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 10,"relation" : "eq"},"max_score" : null,"hits" : [{"_index" : "hello","_type" : "_doc","_id" : "5","_score" : null,"_source" : {"title" : "飞利浦 老人手机 (X2560) 喜庆红 移动联通2G手机 双卡双待","images" : "http://image.leyou.com/12479122.jpg","price" : 500},"sort" : [500.0]},{"_index" : "hello","_type" : "_doc","_id" : "6","_score" : null,"_source" : {"title" : "诺基亚(NOKIA) 1050 (RM-908) 黑色 移动联通2G手机","images" : "http://image.leyou.com/12479122.jpg","price" : 998},"sort" : [998.0]}]}
}
但是,其本质是逻辑分页,因此为了避免深度分页的问题,ES限制最多查到第10000条。
如果需要查询到10000以后的数据,你可以采用两种方式:
- scroll滚动查询
- search after
详见文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.5/search-request-body.html#request-body-search-search-after
7.5. Filter过滤
当我们在京东这样的电商网站购物,往往查询条件不止一个,还会有很多过滤条件:
而在默认情况下,所有的查询条件、过滤条件都会影响打分和排名。而对搜索结果打分是比较影响性能的,因此我们一般只对用户输入的搜索条件对应的字段打分,其它过滤项不打分。此时就不能简单实用布尔查询的must来组合条件了,而是实用filter方式。
示例,比如我们要查询手机,同时对价格过滤,原本的写法是这样的:
GET /hello/_search
{"query": {"bool": {"must": [{"match": {"title": "手机"}},{"range": {"price": {"gte": 2099,"lte": 2999}}}]}}
}
现在要修改成这样:
GET /hello/_search
{"query": {"bool": {"must": {"match": {"title": "手机"}},"filter": [{"range": {"price": {"gte": 2099,"lte": 2999}}}]}}
}
7.6._source筛选
默认情况下,elasticsearch在搜索的结果中,会把文档中保存在_source的所有字段都返回。
如果我们只想获取其中的部分字段,我们可以添加_source的过滤
7.6.1.直接指定字段
示例:
GET /hello/_search
{"_source": ["title","price"],"query": {"term": {"price": 2699}}
}
返回的结果:
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "hello","_type" : "_doc","_id" : "5","_score" : 1.0,"_source" : {"price" : 500,"title" : "飞利浦 老人手机 (X2560) 喜庆红 移动联通2G手机 双卡双待"}}]}
}
7.6.2.指定includes和excludes
我们也可以通过:
- includes:来指定想要显示的字段
- excludes:来指定不想要显示的字段
二者都是可选的。
示例:
GET /hello/_search
{"_source": {"includes":["title","price"]},"query": {"term": {"price": 500}}
}
与下面的结果将是一样的:
GET /hello/_search
{"_source": {"excludes": ["images"]},"query": {"term": {"price": 500}}
}
8.aggs聚合
聚合(aggregations)可以让我们极其方便的实现对数据的统计、分析。例如:
- 什么品牌的手机最受欢迎?
- 这些手机的平均价格、最高价格、最低价格?
- 这些手机每月的销售情况如何?
实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现近实时搜索效果。
要注意:参与聚合的字段,必须是keyword类型 和 数值类型 。
8.1 基本概念
Elasticsearch中的聚合,包含多种类型,最常用的两种,一个叫桶,一个叫度量:
桶(bucket)
桶的作用,是按照某种方式对数据进行分组,每一组数据在ES中称为一个桶,例如我们根据国籍对人划分,可以得到中国桶、英国桶,日本桶……或者我们按照年龄段对人进行划分:010,1020,2030,3040等。
Elasticsearch中提供的划分桶的方式有很多:
- Date Histogram Aggregation:根据日期阶梯分组,例如给定阶梯为周,会自动每周分为一组
- Histogram Aggregation:根据数值阶梯分组,与日期类似,需要知道分组的间隔(interval)
- Terms Aggregation:根据词条内容分组,词条内容完全匹配的为一组,类似数据库group by
- Range Aggregation:数值和日期的范围分组,指定开始和结束,然后按段分组
- ……
综上所述,我们发现bucket aggregations 只负责对数据进行分组,并不进行计算,因此往往bucket中往往会嵌套另一种聚合:metrics aggregations即度量
度量(metrics)
分组完成以后,我们一般会对组中的数据进行聚合运算,例如求平均值、最大、最小、求和等,这些在ES中称为度量
比较常用的一些度量聚合方式:
- Avg Aggregation:求平均值
- Max Aggregation:求最大值
- Min Aggregation:求最小值
- Percentiles Aggregation:求百分比
- Stats Aggregation:同时返回avg、max、min、sum、count等
- Sum Aggregation:求和
- Top hits Aggregation:求前几
- Value Count Aggregation:求总数
- ……
为了测试聚合,我们先批量导入一些数据
创建索引:
PUT /car
{"mappings": {"properties": {"color": {"type": "keyword"},"make": {"type": "keyword"}}}
}
注意:在ES中,需要进行聚合、排序的字段其处理方式比较特殊,因此不能被分词,必须使用keyword或数值类型。这里我们将color和make这两个文字类型的字段设置为keyword类型,这个类型不会被分词,将来就可以参与聚合
导入数据,这里是采用批处理的API,大家直接复制到kibana运行即可:
POST /car/_bulk
{ "index": {}}
{ "price" : 10000, "color" : "红", "make" : "本田", "sold" : "2014-10-28" }
{ "index": {}}
{ "price" : 20000, "color" : "红", "make" : "本田", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 30000, "color" : "绿", "make" : "福特", "sold" : "2014-05-18" }
{ "index": {}}
{ "price" : 15000, "color" : "蓝", "make" : "丰田", "sold" : "2014-07-02" }
{ "index": {}}
{ "price" : 12000, "color" : "绿", "make" : "丰田", "sold" : "2014-08-19" }
{ "index": {}}
{ "price" : 20000, "color" : "红", "make" : "本田", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 80000, "color" : "红", "make" : "宝马", "sold" : "2014-01-01" }
{ "index": {}}
{ "price" : 25000, "color" : "蓝", "make" : "福特", "sold" : "2014-02-12" }
度量计算
类似数据库中聚合运算,es提供了更为丰富的各种运算分析方法
语法:
{"query":{},..."aggs":{"自定义的聚合处理名称": {"聚合类型":{"field":"域字段"}}}}
常用度量类型:
count 数量
min 最小值
max 最大值
avg 平均值
sum 求和
stats 显示上面5种信息
get /car/_search
{"query":{"match_all": {}},"aggs":{"avg_price":{"stats": {"field": "price"}}}
}
// 对价格进行分析 的结果
"aggregations" : {"avg_price" : {"count" : 8, //8条记录"min" : 10000.0, // 最小值"max" : 80000.0, // 最大值"avg" : 26500.0, // 平均值"sum" : 212000.0 // 所有价格之和}}
8.2 聚合为桶
类似于数据库中的分组,
首先,我们按照 汽车的颜色color来划分桶,按照颜色分桶,最好是使用TermAggregation类型,按照颜色的名称来分桶。
GET /car/_search
{"size" : 0,"aggs" : { "my_popular_colors" : { "terms" : { "field" : "color"}}}
}
-
size: 查询条数,这里设置为0,因为我们不关心搜索到的数据,只关心聚合结果,提高效率
-
aggs:声明这是一个聚合查询,是aggregations的缩写
-
popular_colors:给这次聚合起一个名字,可任意指定。
-
terms:聚合的类型,这里选择terms,是根据词条内容(这里是颜色)划分
- field:划分桶时依赖的字段
-
-
结果:
{"took": 33,"timed_out": false,"_shards": {"total": 5,"successful": 5,"skipped": 0,"failed": 0},"hits": {"total": 8,"max_score": 0,"hits": []},"aggregations": {"my_popular_colors": {"doc_count_error_upper_bound": 0,"sum_other_doc_count": 0,"buckets": [{"key": "红","doc_count": 4},{"key": "绿","doc_count": 2},{"key": "蓝","doc_count": 2}]}}
}
-
hits:查询结果为空,因为我们设置了size为0
-
aggregations:聚合的结果
-
my_popular_colors:我们定义的聚合名称
-
buckets:查找到的桶,每个不同的color字段值都会形成一个桶
- key:这个桶对应的color字段的值
- doc_count:这个桶中的文档数量
通过聚合的结果我们发现,目前红色的小车比较畅销!
8.3 桶内度量
前面的例子告诉我们每个桶里面的文档数量,这很有用。 但通常,我们的应用需要提供更复杂的文档度量。 例如,每种颜色汽车的平均价格是多少?
因此,我们需要告诉Elasticsearch使用哪个字段,使用何种度量方式进行运算,这些信息要嵌套在桶内,度量的运算会基于桶内的文档进行
现在,我们为刚刚的聚合结果添加 求价格平均值的度量:
GET /car/_search
{"size" : 0,"aggs" : { "my_popular_colors" : { "terms" : { "field" : "color"},"aggs":{"my_avg_price": { "avg": {"field": "price" }}}}}
}
- aggs:我们在上一个aggs(my_popular_colors)中添加新的aggs。可见度量也是一个聚合
- my_avg_price:聚合的名称
- avg:度量的类型,这里是求平均值
- field:度量运算的字段
结果:
{"took" : 8,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 8,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"my_popular_colors" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "红","doc_count" : 4,"my_avg_price" : {"value" : 32500.0}},{"key" : "绿","doc_count" : 2,"my_avg_price" : {"value" : 21000.0}},{"key" : "蓝","doc_count" : 2,"my_avg_price" : {"value" : 20000.0}}]}}
}
可以看到每个桶中都有自己的avg_price字段,这是度量聚合的结果
8.4 桶内嵌套桶
刚刚的案例中,我们在桶内嵌套度量运算。事实上桶不仅可以嵌套运算, 还可以再嵌套其它桶。也就是说在每个分组中,再分更多组。
比如:我们想统计每种颜色的汽车中,分别属于哪个制造商,按照make字段再进行分桶
相关文章:
ElasticSearch快速入门详解(亲测好用,强烈推荐收藏)
3.快速入门 接下来快速看下elasticsearch的使用 3.1.概念 Elasticsearch虽然是一种NoSql库,但最终的目的是存储数据、检索数据。因此很多概念与MySQL类似的。 ES中的概念数据库概念说明索引库(indices)数据库(Database)ES中可…...
出入了解——Vue.js
个人简介:云计算网络运维专业人员,了解运维知识,掌握TCP/IP协议,每天分享网络运维知识与技能。座右铭:海不辞水,故能成其大;山不辞石,故能成其高。个人主页:小李会科技的…...
MySQL8 双主(主主)架构部署实战
前言 大家好,我是 沐风晓月 本文收录于《数据库入门到精通系列》专栏, 更多内容可以关注我的csdn博客。 本文主要讲解MySQL主主架构实战,在开始之前需要根据下面的提示来配置环境: Linux基础命令不熟参考: 《linux基本功-基础…...
【数据结构】第三站:单链表
目录 一、顺序表的缺陷 二、链表 1.链表的概念以及结构 2.链表的分类 3.单链表的逻辑结构与物理结构 三、单链表的实现 1.单链表的定义 2.单链表的接口定义 3.单链表的接口实现 四、单链表的实现完整代码 一、顺序表的缺陷 在上一篇文章中,我们了解了顺序…...
【蓝桥杯2020】七段码
【题目描述】 七段码 HUSTOJ 题目导出文件 [蓝桥杯2020] 第十一届蓝桥杯第二次省赛—填空题E题 七段码 小蓝要用七段码数码管来表示一种特殊的文字。 上图给出了七段码数码管的一个图示,数码管中一共有 7 段可以发光的二 极管,分别标记为 a, b, c,…...
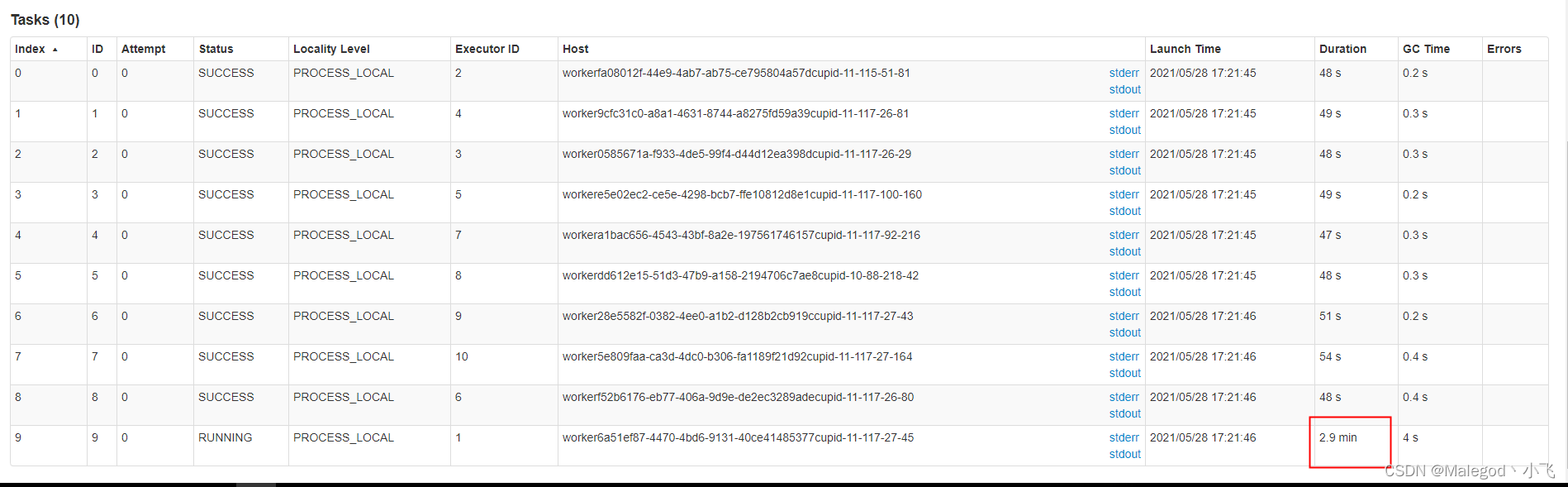
Spark读取JDBC调优
Spark读取JDBC调优,如何调参一、场景构建二、参数设置1.灵活运用分区列实际问题:工作中需要读取一个存放了三四年历史数据的pg数仓表(缺少主键id),需要将数据同步到阿里云 MC中,Spark在使用JDBC读取关系型数…...

【文心一言】什么是文心一言,如何获得内测和使用方法。
文心一言什么是文心一言怎么获得内测资格接下来就给大家展示一下文学创作商业文案创作数理逻辑推算中文理解多模态生成用python写一个九九乘法表写古诗前言: 🏠个人主页:以山河作礼。 📝📝:本文章是帮助大家了解文心…...
CentOS8服务篇10:FTP服务器配置与管理
一、安装与启动FTP服务器 1、安装VSFTP服务器所需要的安装包 #yum -y install vsftpd 2、查看配置文件参数 Vim /etc/vsftpd/vsftpd.conf (1)是否允许匿名登录 anonymous_enableYES 该行用于控制是否允许匿名用户登录。 (2&…...

笔试强训3.14
一、选择题 1.以下说法错误的是(C) A.数组是一个对象 B.数组不是一种原生类 C.数组的大小可以任意改变 D.在Java中,数组存储在堆中连续内存空间里 相关知识点:原生/内置数组是那八个,其他的都是引用的,借…...

elasticsearch 环境搭建和基本操作
参考资料 适合后端编程人员的elasticsearch快速实战教程 ElasticSearch最新实战教程 ElasticSearch配套笔记 自制搜索引擎 https://www.elastic.co/guide/en/elasticsearch/reference/7.17/setup.html restful风格的api REST 设计风格 例如以下springboot示例 RestContr…...
IDEA操作:Springboot项目打包为jar包并运行
在IDEA环境下对Springboot项目打包为jar包且在terminal运行操作 1、 2、 3、注意:在项目目录里创建一个用来存放jar包的文件夹(res),该路径不能使用IDEA设置的默认路径,必须手动创建。 4、 5、点击ok后加载运行包 (8…...
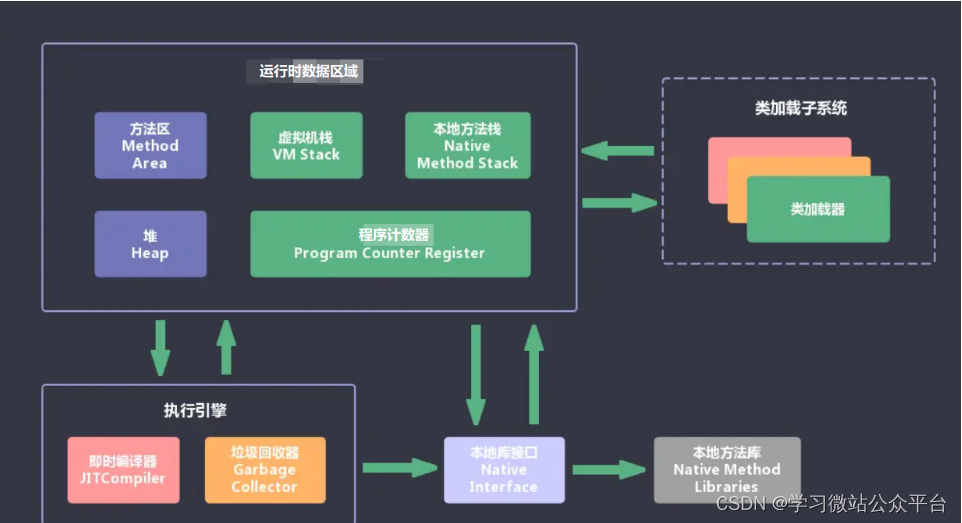
原理底层计划---JVM
二、JVM对空间大小怎么配置?各区域怎么划? 新生代:短时间生成,可以马上回收 老生代:少部分对象会存在很久,回收策略应不同 三、JVM哪些内存区域会发生内存溢出(程序计数器不会) …...

CSDN-猜年龄、纸牌三角形、排他平方数
猜年龄 原题链接:https://edu.csdn.net/skill/practice/algorithm-a413078fb6e74644b8c9f6e28896e377/2258 美国数学家维纳(N.Wiener)智力早熟,11岁就上了大学。他曾在1935~1936年应邀来中国清华大学讲学。 一次,他参加某个重要会议…...
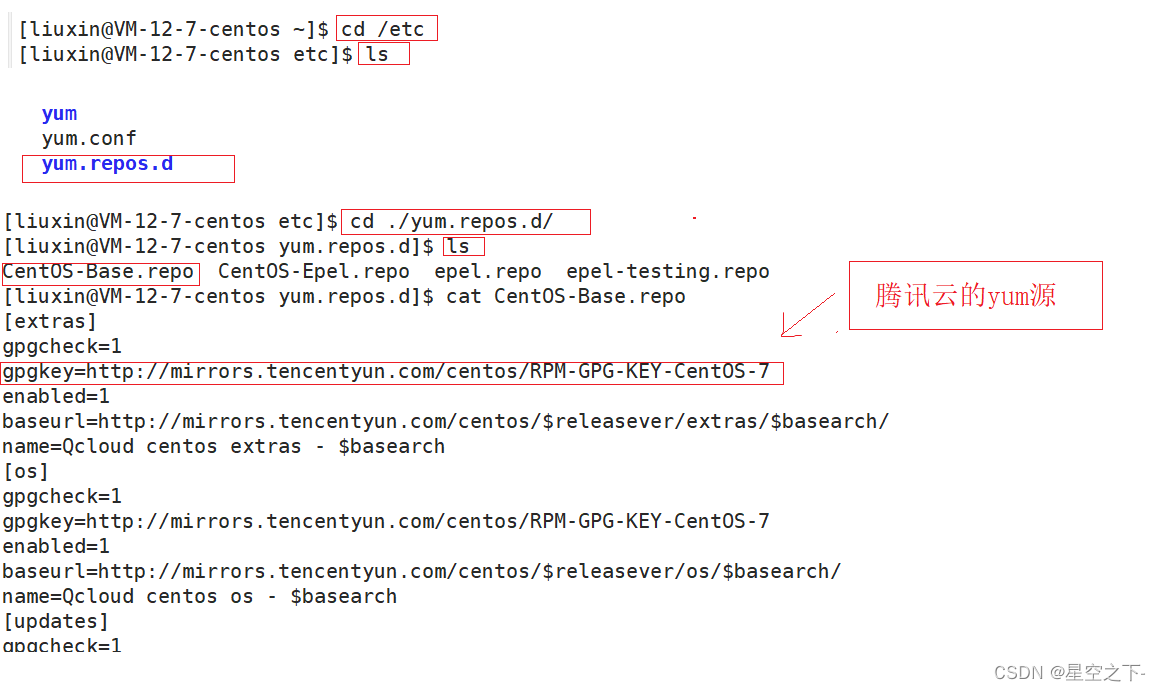
【Linux】软件包管理器 yum
什么是软件包和软件包管理器 在 Linux 下需要安装软件时, 最原始的办法就是下载到程序的源代码, 进行编译得到可执行程序。但是这样太麻烦了,所以有些人就把一些常用的软件提前编译好, 做成软件包 ( 就相当于windows上的软件安装程序)放在服…...
一天吃透TCP面试八股文
本文已经收录到Github仓库,该仓库包含计算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享等核心知识点,欢迎star~ Github地址:https://github.com/…...

zzu天梯赛选拔
C. NANA去上课 — 简单数学 需要记录上一步处在哪个位置 然后判断如果是同一侧移动距离就是abs(x1 - x2) 如果不同就是x1 x2 #include <iostream> #include <cmath> using namespace std; #define int long long signed main() {int n; c…...
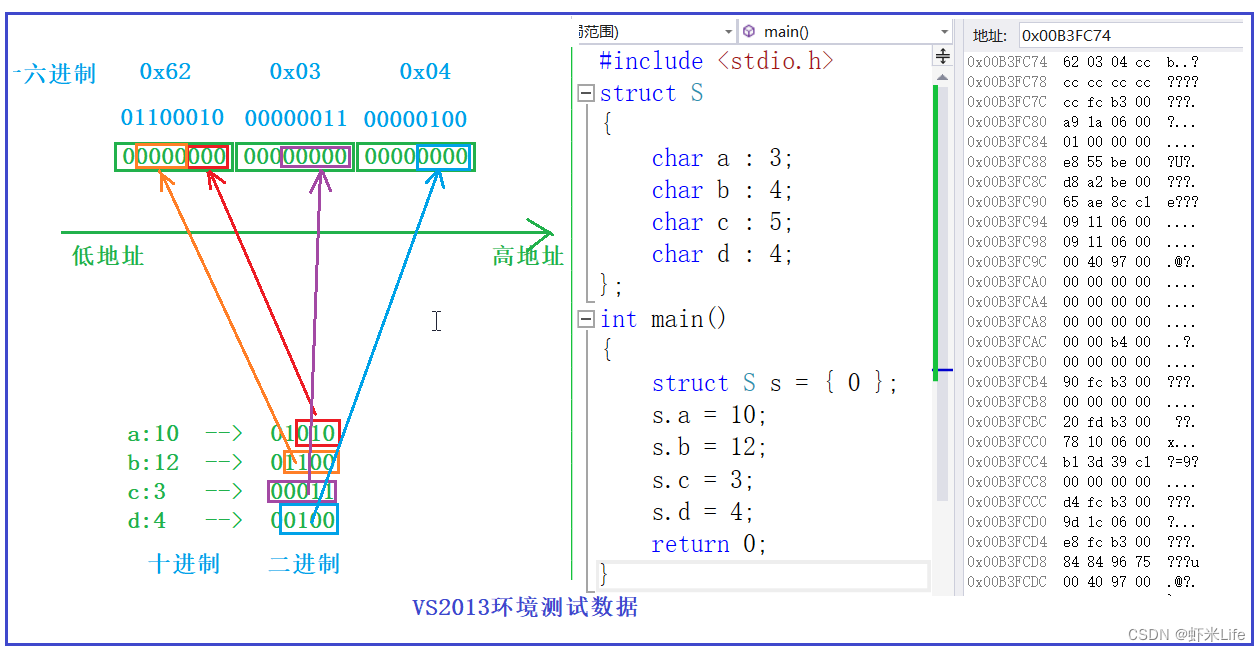
【C语言】一篇让你彻底吃透(结构体与结构体位段)
本章重点 主要讲解结构体和位移动的使用和定义与声明,并且结构体和位段在内存中是如何存储的。 文章目录结构体结构体类型的声明结构体特殊的声明结构体变量的定义和初始化结构体成员的访问结构的自引用结构体内存对齐结构体传参位段什么是位段位段的内存分配位段的…...

数据结构之二叉树构建、广度/深度优先(前序、中序、后序)遍历
一、二叉树 1.1 树 说到树,我们暂时忘记学习,来看一下大自然的树: 哈哈 以上照片是自己拍的,大家凑合看看 回归正题,那么在数据结构中,树是什么呢,通过上面的图片大家也可以理解 树是一种非…...

“国产版ChatGPT”文心一言发布会现场Demo硬核复现
文章目录前言实验结果一、文学创作问题1 :《三体》的作者是哪里人?问题2:可以总结下三体的核心内容吗?如果要续写的话,可以从哪些角度出发?问题3:如何从哲学角度来进行续写?问题4:电…...

202304读书笔记|《不被定义的女孩》——做最真实最漂亮的自己,依心而行
202304读书笔记|《不被定义的女孩》——做最真实最漂亮的自己,依心而行《不被定义的女孩》作者ASEN,很棒的书。处处透露着洒脱,通透,悦己,阅世界的自由的氛围和态度! 部分节选如下: 让自己活得…...

2026年实测10款降AI工具:毕业论文降AIGC哪款最靠谱?
2026年毕业季临近,降低论文AI生成痕迹、通过学校AIGC检测已经成为所有毕业生的必过关卡。但当前降AI工具市场鱼龙混杂:不少用户花了高价处理,AI率却纹丝不动;还有的工具改完的论文语句生硬、逻辑混乱,反而过不了答辩。…...

别让import.*拖慢你的Spring Boot项目!IDEA优化导入配置详解
别让import.*拖慢你的Spring Boot项目!IDEA优化导入配置详解 在微服务架构盛行的今天,Spring Boot项目的启动速度已经成为开发者关注的焦点。一个常见的性能陷阱就隐藏在那些看似无害的import.*语句中——它们会强制JVM加载整个包的类,即使你…...
)
告别付费IP!手把手教你用ZCU102 PS端DP接口点亮显示器(附参数调试心得)
解锁ZCU102 PS端DisplayPort潜力:零成本实现高效显示输出的实战指南 在嵌入式视觉系统开发中,显示输出往往是项目落地的最后一道关卡。当我在多个Zynq UltraScale MPSoC项目中反复遭遇HDMI IP核的授权困扰和PL端实现的复杂性后,意外发现PS端集…...
)
10分钟搞定 Nginx 安装:Linux/Windows 双平台实测(附避坑指南)
一、前言上一篇我们初识了Nginx——知道了它是高性能的HTTP和反向代理服务器,懂了它为什么被99%的互联网公司青睐,也明确了我们后续的学习路线。本篇文章将手把手教你在Linux和Windows系统上,完成Nginx的安装、部署、启动、停止 ,…...

intv_ai_mk11效果对比:同一Prompt下intv_ai_mk11与Qwen2.5在代码生成任务表现
intv_ai_mk11效果对比:同一Prompt下intv_ai_mk11与Qwen2.5在代码生成任务表现 1. 测试背景与目的 在当今AI技术快速发展的背景下,代码生成已成为大语言模型的重要应用场景之一。本次测试旨在对比intv_ai_mk11与Qwen2.5两款模型在相同Prompt下的代码生成…...

AIVideo一站式AI长视频工具与Visual Studio的深度集成开发
AIVideo一站式AI长视频工具与Visual Studio的深度集成开发 1. 引言 作为一名长期使用Visual Studio进行开发的程序员,我经常遇到这样的痛点:想要录制一段代码演示视频,需要反复切换多个软件;想要制作项目介绍视频,得…...
)
Emacs verilog-mode实战:5分钟搞定AUTOARG自动参数生成(附避坑指南)
Emacs verilog-mode实战:5分钟掌握AUTOARG高效参数生成技巧 在数字电路设计领域,Verilog作为主流硬件描述语言,其模块化开发方式虽然提高了代码复用性,却也带来了大量重复性工作。模块接口定义中的参数列表维护就是典型痛点——每…...

QT6.5串口编程第一步:用CMakeLists.txt引入SerialPort模块的避坑指南
QT6.5串口编程避坑指南:CMakeLists.txt配置全解析 当你满怀期待地在QT6.5项目中引入串口通信功能,却在编译时遭遇"找不到QtSerialPort"的红色错误提示,这种挫败感我深有体会。作为一位经历过无数次类似"战斗"的开发者&am…...

突破限速:8大网盘直链解析方案全解析
突破限速:8大网盘直链解析方案全解析 【免费下载链接】Online-disk-direct-link-download-assistant 可以获取网盘文件真实下载地址。基于【网盘直链下载助手】修改(改自6.1.4版本) ,自用,去推广,无需输入“…...

一键部署后的第一步:LiuJuan20260223Zimage API调用详解与调试
一键部署后的第一步:LiuJuan20260223Zimage API调用详解与调试 刚在星图GPU平台上一键部署好LiuJuan20260223Zimage镜像,看着运行状态显示“正常”,是不是感觉离用上强大的AI能力只差临门一脚了?别急,这最后一步——学…...