【selenium学习】数据驱动测试
数据驱动
在 unittest 中,使用读取数据文件来实现参数化可以吗?当然可以。这里以读取 CSV
文件为例。创建一个 baidu_data.csv 文件,如图所示:
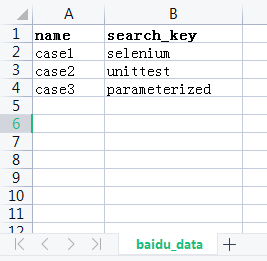
文件第一列为测试用例名称,第二例为搜索的关键字。接下来创建 test_baidu_data.py文件。
# _*_ coding:utf-8 _*_
"""
name:zhangxingzai
date:2023/3/19
"""import csv
import codecs
import unittest
from time import sleep
from itertools import islice
from selenium import webdriver
from selenium.webdriver.common.by import Byclass TestBaidu(unittest.TestCase):@classmethoddef setUpClass(cls):cls.driver = webdriver.Firefox()cls.base_url = "https://www.baidu.com"@classmethoddef tearDownClass(cls):cls.driver.quit()def baidu_search(self, search_key):self.driver.get(self.base_url)self.driver.find_element(By.ID, "kw").send_keys(search_key)self.driver.find_element(By.ID, "su").click()sleep(3)def test_search(self):with codecs.open('baidu_data.csv', 'r', 'utf_8_sig') as f:data = csv.reader(f)for line in islice(data, 1, None):search_key = line[1]self.baidu_search(search_key)if __name__ == '__main__':unittest.main(verbosity=2)这样做似乎没有问题,确实可以读取 baidu_data.csv 文件中的三条数据并进行测试,测
试结果如下:
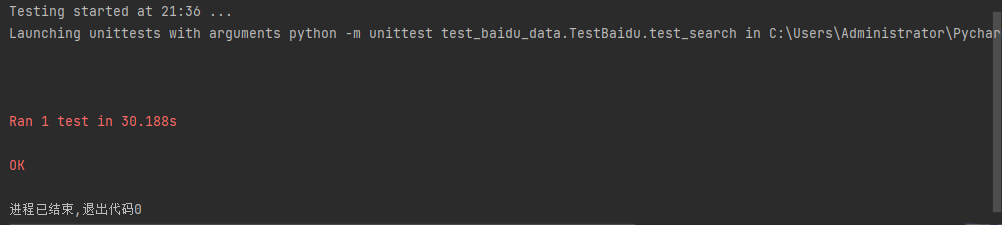
根据结果看这样划分并不合理,比如,有 10 条数据,只要有 1 条数据执行失败,那么整个测试用
例就执行失败了。所以,10 条数据对应 10 条测试用例更为合适,就算其中 1 条数据的测
试用例执行失败了,也不会影响其他 9 条数据的测试用例的执行,并且在定位测试用例失
败的原因时会更加简单。修改代码如下:
# _*_ coding:utf-8 _*_
"""
name:zhangxingzai
date:2023/3/19
"""import csv
import codecs
import unittest
from time import sleep
from itertools import islice
from selenium import webdriver
from selenium.webdriver.common.by import Byclass TestBaidu(unittest.TestCase):@classmethoddef setUpClass(cls):cls.driver = webdriver.Firefox()cls.base_url = "https://www.baidu.com"cls.test_data = []with codecs.open('baidu_data.csv', 'r', 'utf_8_sig') as f:data = csv.reader(f)for line in islice(data, 1, None):cls.test_data.append(line)@classmethoddef tearDownClass(cls):cls.driver.quit()def baidu_search(self, search_key):self.driver.get(self.base_url)self.driver.find_element(By.ID, "kw").send_keys(search_key)self.driver.find_element(By.ID, "su").click()sleep(3)def test_search_selenium(self):self.baidu_search(self.test_data[0][1])def test_search_unittest(self):self.baidu_search(self.test_data[1][1])def test_search_parameterized(self):self.baidu_search(self.test_data[2][1])if __name__ == '__main__':unittest.main(verbosity=2)优化后用setUpClass() 方法读取 baidu_data.csv 文件,并将文件中的数据存储到
test_data 数组中。分别创建不同的测试方法使用 test_data 中的数据,测试结果如下:
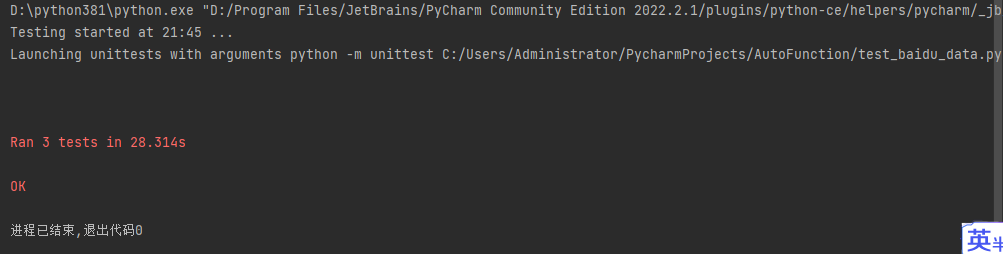
从测试结果可以看到,3 条数据被当作 3 条测试用例执行了。那么是不是就完美解决
了前面的问题呢?接下来,需要思考一下,读取数据文件带来了哪些问题?
(1)增加了读取的成本。不管什么样的数据文件,在运行自动化测试用例前都需要将
文件中的数据读取到程序中,这一步是不能少的。
(2)不方便维护。读取数据文件是为了方便维护,但事实上恰恰相反。在 CSV 数据文
件中,并不能直观体现出每一条数据对应的测试用例。而在测试用例中通过 test_data[0][1]
方式获取数据也存在很多问题,如果在 CSV 文件中间插入了一条数据,那么测试用例获取
到的测试数据很可能就是错的。
如果在测试过程中需要用很多数据怎么办?我们知道测试脚本并不是用来存放数据的
地方,如果待测试的数据很多,那么全部放到测试脚本中显然并不合适。
在回答这个问题之前,先思考一下什么是 UI 自动化测试?UI 自动化测试是站在用户
的角度模拟用户的操作。那么用户在什么场景下会输入大量的数据呢?其实输入大量数据
的功能很少,如果整个系统都需要用户重复或大量地输入数据,那么很可能是用户体验做
得不好!大多数时候,系统只允许用户输入用户名、密码和个人信息,或搜索一些关键字
等。
假设我们要测试用户发文章的功能,这时确实会用到大量的数据。
那么读取数据文件是不是就完全没必要了呢?当然不是,比如一些自动化测试的配置
就可以放到数据文件中,如运行环境、运行的浏览器等,放到配置文件中会更方便管理。
DDT(Data-Driven Tests)
DDT是针对 unittest 单元测试框架设计的扩展库。允许使用不同的测试数据来运行一个测试用例,并将其展示为多个测试用例。
GitHub 地址:https://github.com/datadriventests/ddt。
DDT 支持 pip 安装。
pip install ddt以百度搜索为例,来看看 DDT 的用法。创建 test_baidu_ddt.py 文件
# _*_ coding:utf-8 _*_
"""
name:zhangxingzai
date:2023/3/19
"""import unittest
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
from ddt import ddt, data, file_data, unpack@ddt
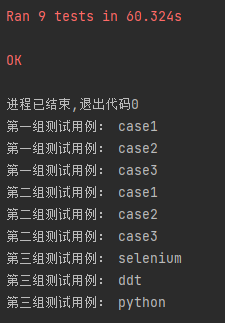
class TestBaidu(unittest.TestCase):@classmethoddef setUpClass(cls):cls.driver = webdriver.Firefox()cls.base_url = "https://www.baidu.com"def baidu_search(self, search_key):self.driver.get(self.base_url)self.driver.find_element(By.ID, "kw").send_keys(search_key)self.driver.find_element(By.ID, "su").click()sleep(3)# 参数化使用方式一@data(["case1", "selenium"], ["case2", "ddt"], ["case3", "python"])@unpackdef test_search1(self, case, search_key):print("第一组测试用例:", case)self.baidu_search(search_key)self.assertEqual(self.driver.title, search_key + "_百度搜索")# 参数化使用方式二@data(("case1", "selenium"), ("case2", "ddt"), ("case3", "python"))@unpackdef test_search2(self, case, search_key):print("第二组测试用例:", case)self.baidu_search(search_key)self.assertEqual(self.driver.title, search_key + "_百度搜索")# 参数化使用方式三@data({"search_key": "selenium"}, {"search_key": "ddt"}, {"search_key": "python"})@unpackdef test_search3(self, search_key):print("第三组测试用例:", search_key)self.baidu_search(search_key)self.assertEqual(self.driver.title, search_key + "_百度搜索")@classmethoddef tearDownClass(cls):cls.driver.quit()if __name__ == '__main__':unittest.main(verbosity=2)使用 DDT 需要注意以下几点:
首先,测试类需要通过@ddt 装饰器进行装饰。
其次,DDT 提供了不同形式的参数化。这里列举了三组参数化,第一组为列表,第二
组为元组,第三组为字典。需要注意的是,字典的 key 与测试方法的参数要保持一致。
执行结果如下:
DDT 同样支持数据文件的参数化。它封装了数据文件的读取,让我们更专注于数据文
件中的内容,以及在测试用例中的使用,而不需要关心数据文件是如何被读取进来的。
首先,创建 ddt_data_file.json 文件:
{"case1": {"search_key": "python"},"case2": {"search_key": "ddt"},"case3": {"search_key": "Selenium"}
}在测试用例中使用 test_data_file.json 文件参数化测试用例,在 test_baidu_ddt.py 文件中
增加测试用例数据。代码如下:
# _*_ coding:utf-8 _*_
"""
name:zhangxingzai
date:2023/3/19
"""import unittest
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
from ddt import ddt, data, file_data, unpack@ddt
class TestBaidu(unittest.TestCase):@classmethoddef setUpClass(cls):cls.driver = webdriver.Firefox()cls.base_url = "https://www.baidu.com"def baidu_search(self, search_key):self.driver.get(self.base_url)self.driver.find_element(By.ID, "kw").send_keys(search_key)self.driver.find_element(By.ID, "su").click()sleep(3)# 参数化使用方式一@data(["case1", "selenium"], ["case2", "ddt"], ["case3", "python"])@unpackdef test_search1(self, case, search_key):print("第一组测试用例:", case)self.baidu_search(search_key)self.assertEqual(self.driver.title, search_key + "_百度搜索")# 参数化使用方式二@data(("case1", "selenium"), ("case2", "ddt"), ("case3", "python"))@unpackdef test_search2(self, case, search_key):print("第二组测试用例:", case)self.baidu_search(search_key)self.assertEqual(self.driver.title, search_key + "_百度搜索")# 参数化使用方式三@data({"search_key": "selenium"}, {"search_key": "ddt"}, {"search_key": "python"})@unpackdef test_search3(self, search_key):print("第三组测试用例:", search_key)self.baidu_search(search_key)self.assertEqual(self.driver.title, search_key + "_百度搜索")# 参数化读取 JSON 文件@file_data('ddt_data_file.json')def test_search4(self, search_key):print("第四组测试用例:", search_key)self.baidu_search(search_key)self.assertEqual(self.driver.title, search_key + "_百度搜索")@classmethoddef tearDownClass(cls):cls.driver.quit()if __name__ == '__main__':unittest.main(verbosity=2)注意,ddt_data_file.json 文件需要与 test_baidu_ddt.py 放在同一目录下面,否则需要指
定 ddt_data_file.json 文件的路径。
除此之外,DDT 还支持 yaml 格式的数据文件。创建 ddt_data_file.yaml 文件:
case1:- search_key: "python"
case2:- search_key: "ddt"
case3:- search_key: "unittest"在 test_baidu_ddt.py 文件中增加测试用例:
以上省略。。。
# 参数化读取 yaml 文件@file_data('ddt_data_file.yaml')def test_search5(self, case):search_key = case[0]["search_key"]print("第五组测试用例:", search_key)self.baidu_search(search_key)self.assertEqual(self.driver.title, search_key + "_百度搜索")这里的取值与上面的 JSON 文件有所不同,因为每一条用例都被解析为[{'search_key':
'python'}],所以要想取到搜索关键字,则需要通过 case[0]["search_key"]的方式获取。
注意:这里有可能读取yaml文件夹失败,程序执行报错,可以安装PyYAML库修复。
pip install PyYAML相关文章:
【selenium学习】数据驱动测试
数据驱动在 unittest 中,使用读取数据文件来实现参数化可以吗?当然可以。这里以读取 CSV文件为例。创建一个 baidu_data.csv 文件,如图所示:文件第一列为测试用例名称,第二例为搜索的关键字。接下来创建 test_baidu_da…...

嵌入式硬件电路设计的基本技巧
目录 1 分模块 2 标注关键参数 3 电阻/电容/电感/磁珠的注释 4 可维修性 5 BOM表归一化 6 电源和地的符号 7 测试点 8 网络标号 9 容错性/兼容性 10 NC、NF 11 版本变更 12 悬空引脚 13 可扩展性 14 防呆 15 信号的流向 16 PCB走线建议 17 不使用\表示取反 不…...

Spring MVC 图片的上传和下载
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...
远程工具神器之MobaXterm (小白必看)
目录 1、介绍 2、ssh连接详解过程 3、特点 1、介绍 带有 X11 服务器、选项卡式 SSH 客户端、网络工具等的 Windows 增强型终端。 MobaXterm 是您远程计算的终极工具箱。在单个Windows应用程序中,它提供了大量功能,这些功能是为程序员,网站管…...
VRIK+Unity XR Interaction Toolkit 实现VR上半身的追踪(附带VRM模型导入Unity方法和手腕扭曲的解决方法)
文章目录📕第一步:配置 OpenXR XR Interaction Toolkit 的开发环境📕第二步:导入人物模型⭐VRM 模型导入 Unity 的方法📕第三步:配置 VRIK⭐给模型加上 VRIK 组件⭐将模型的头部和手部的位置作为 VR 追踪目…...
【C++进阶】map的介绍和使用
文章目录map的介绍map的模板参数介绍map的容器介绍map重要容器接口的介绍及使用构造函数增删查改迭代器的使用map的介绍 map是关联容器,它按照特定的次序(按照key来比较)存储由键值key和值value组合而成的元素。在map中,键值key通常用于排序和惟一地标识…...
第十四届蓝桥杯三月真题刷题训练——第 15 天
目录 第 1 题:斐波那契与7 问题描述 答案提交 运行限制 代码: 第 2 题:小蓝做实验 问题描述 答案提交 运行限制 代码: 第 1 题:斐波那契与7 问题描述 斐波那契数列的递推公式为: FnFn−1Fn−2, 其中 F1F21…...

HTML5是什么?怎么学习HTML5?
HTML5 是什么?HTML5是什么?相信这个问题并不容易回答,大多数人对于HTML5的概念仅仅是听说过而已,非要让他说出个所以然来,结果只能让你失望。相比普及了近十四年的HTML4来说,HTML5带来的震撼其实丝毫不亚于…...

个人算法题精简导航整理(精炼汇总,含知识点、模板题、题单)
文章目录前言导航注意事项技巧类自定义Pair排序N维数组转一维位运算状态压缩算法基础枚举 √指数型枚举排列型枚举组合型枚举模拟 √日期天数问题:平年闰年情况递归&分治 √贪心 √货仓选址-模板题排序 √归并排序前缀和&差分 √前缀和差分(一维…...

Mac 和 Win,到底用哪个系统学编程?
今天来聊一个老生常谈的问题,学编程时到底选择什么操作系统?Mac、Windows,还是别的什么。。 作为一个每种操作系统都用过很多年的程序员,我会结合我自己的经历来给大家一些参考和建议。 接下来先分别聊聊每种操作系统的优点和不…...
文心一言---中国版的“ChatGPT”狂飙的机会或许要出现了
⭐️我叫忆_恒心,一名喜欢书写博客的在读研究生👨🎓。 如果觉得本文能帮到您,麻烦点个赞👍呗! 近期会不断在专栏里进行更新讲解博客~~~ 有什么问题的小伙伴 欢迎留言提问欧,喜欢的小伙伴给个三…...
2023最全Python+Selenium环境搭建教程-你绝对想不到有这么简单!
还有视频版本结合项目实战介绍,轻松学习! PythonSelenium自动化测试环境搭建Web自动化测试全套教程_哔哩哔哩_bilibiliPythonSelenium自动化测试环境搭建Web自动化测试全套教程共计180条视频,包括:1、Web自动化测试需求和挑战、2…...

JavaSe第10次笔记
1.Java中,static不能修饰局部变量。 2.构造代码块:可用于成员变量的赋值,但需要注意的是,构造代码块最先执行(比构造方法先)。 3.静态代码块(可用于静态成员变量赋值):写法如下 static { 静态成员操作; } (比构造…...
【C语言笔记】自定义类型全解
【C语言笔记】自定义类型全解一、结构体1、什么是结构体2、结构体的声明与定义2.1、结构体的声明2.2、对结构体成员的访问2.3、对结构体成员的初始化2.4、结构体的不完整声明2.5、结构体嵌套定义3、结构体的自引用3.1、错误的自引用3.2、正确的自引用4、结构体大小的计算4.1、结…...

文心一言硬刚ChatGPT。文心一言能否为百度止颓?中国版ChatGPT“狂飙”的机会在哪儿?
一.文心一言介绍 今天,3月16日消息,百度于北京总部召开新闻发布会,主题围绕新一代大语言模型、生成式AI产品文心一言。百度首席技术官王海峰现在详解了文心一言背后的文心大模型及技术特性。 文心一言是新一代知识增强大语言模型࿰…...
【RabbitMQ笔记10】消息队列RabbitMQ之死信队列的介绍
这篇文章,主要介绍消息队列RabbitMQ之死信队列。 目录 一、RabbitMQ死信队列 1.1、什么是死信队列 1.2、设置过期时间TTL 1.3、配置死信交换机和死信队列(代码配置) (1)设置队列过期时间 (2ÿ…...

Python04 数据序列-字符串
Python04 数据序列-字符串 4.1 字符串概念 字符串是 Python 中最常用的数据类型。我们可以使用引号( ’ 或 " )来创建字符串。 格式: 变量名 数据 / "数据" / """ 数据 """案例: a hello world b &q…...
Redis限流接口防刷
Redis限流接口防刷 Redis 除了做缓存,还能干很多很多事情:分布式锁、限流、处理请求接口幂等性。。。太多太多了~ 大家好,我是llp,许久没有写博客了,今天就针对Redis实现接口限流做个记录。废话不多说&am…...
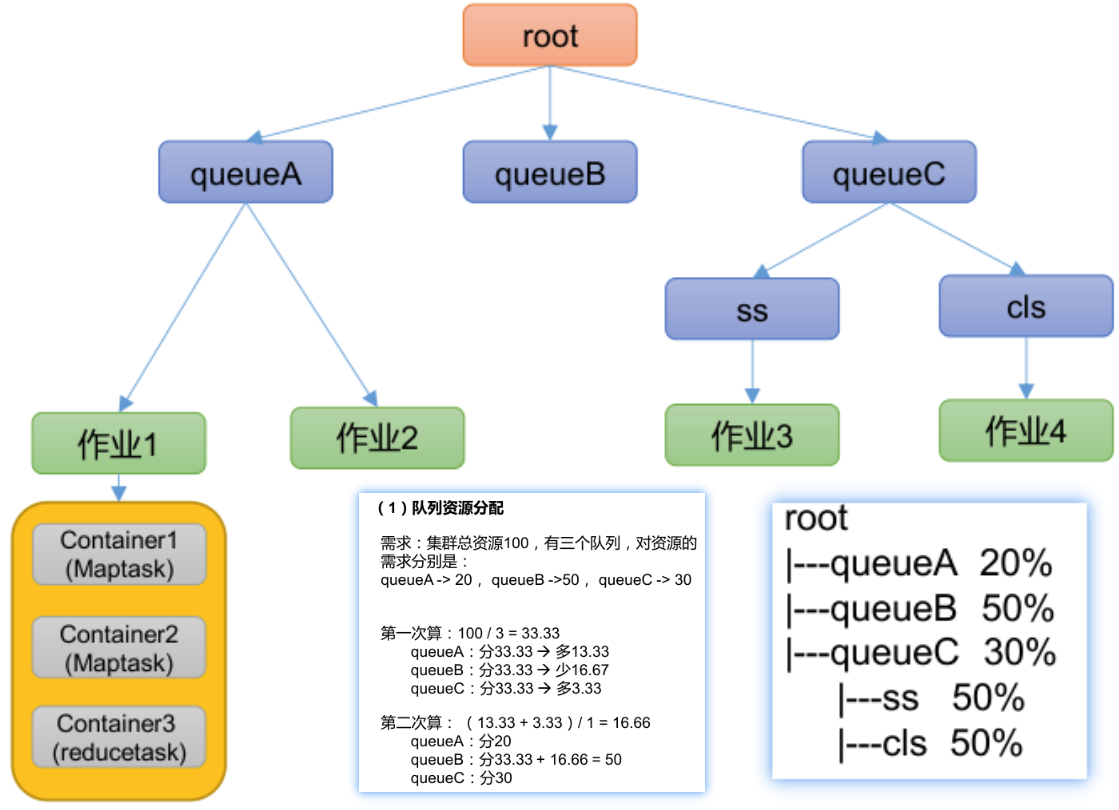
Yarn 资源调度器
Yarn 资源调度器:资源调度平台,负责为运算程序提供服务器运算资源 1 Yarn 基础架构 YARN 主要由 ResourceManager、NodeManager、ApplicationMaster 和 Container 等组件构成。 MR 程序提交到客户端所在的节点。YarnRunner 向 ResourceManager 申请一个…...
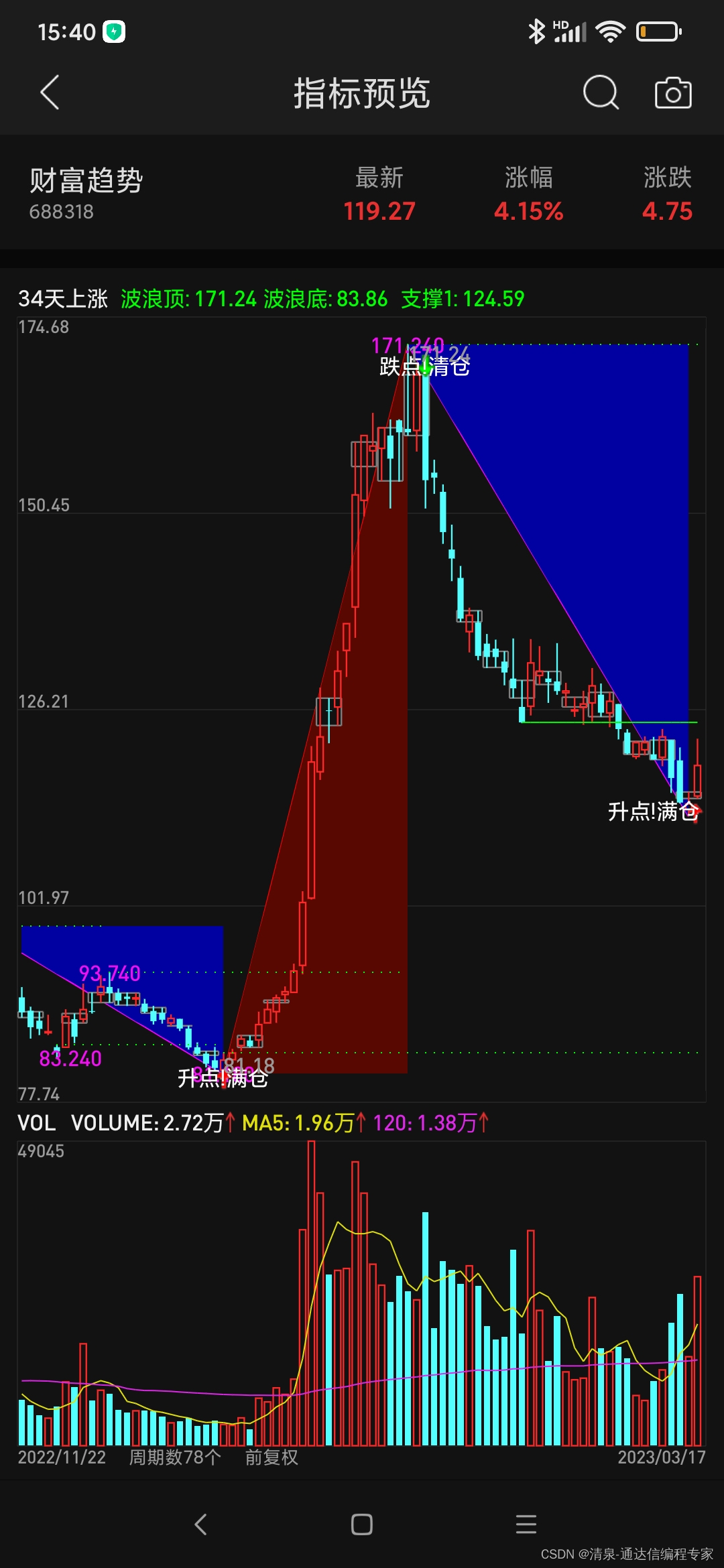
通达信 34日上升三角形主图源码
请先看效果图。 以下是编程源码,可以参考学习一下: N:34;{三角背景} 趋势下:DRAWLINE(HHHV(H,N),H,LLLV(L,N),L,0),LINETHICK2,COLORMAGENTA; SX:REF(趋势下,1)<趋势下; SS:DRAWLINE(SX,趋势下,REF(SX,1),REF(趋势下,1),1); DRAWBAND(SS,RGB(0,0,16…...

如何通过智慧树自动化学习助手解决网课学习效率问题
如何通过智慧树自动化学习助手解决网课学习效率问题 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 副标题:面向时间紧张学习者的智能网课辅助工具 一、价…...
)
C++27执行策略演进全图谱(从C++17到C++27 TS23742的5次关键修订与ABI兼容性断崖预警)
第一章:C27执行策略的范式跃迁与标准定位C27正将执行策略(Execution Policies)从“并行化提示”升格为“可验证执行契约”,标志着标准库算法语义模型的根本性重构。这一转变不再仅依赖实现对std::execution::par_unseq等策略的启发…...

AD09 PCB设计核心技巧与实战经验
1. PCB设计基础与AD09平台概述作为一名从业超过十年的硬件工程师,我使用过从Protel 99到Altium Designer 21的各种版本,其中AD09(Altium Designer 2009)因其稳定性和适中的硬件要求,至今仍是许多工程师的首选工具。PCB…...
镜像视界|AI空间计算重塑公安实战:从“找人”到“锁人”的智能体革命——基于Pixel-to-Space、MatrixFusion与三维轨迹建模的空间级无感定位系统
📘 镜像视界|AI空间计算重塑公安实战:从“找人”到“锁人”的智能体革命 ——基于Pixel-to-Space、MatrixFusion与三维轨迹建模的空间级无感定位系统 一、实战痛点:为什么公安仍停留在“找人阶段” 在当前公安实战中,…...

arduino新手福音:在快马平台零基础点亮第一盏led灯
作为一个刚接触Arduino的小白,最近在尝试点亮人生第一盏LED灯时,发现传统方式需要下载IDE、配置驱动、研究接线图,光是环境搭建就劝退了不少人。直到遇到InsCode(快马)平台,才发现原来入门可以这么简单——不用安装任何软件&#…...

OpenClaw性能优化:Qwen3.5-9B-AWQ-4bit的AWQ量化效果实测
OpenClaw性能优化:Qwen3.5-9B-AWQ-4bit的AWQ量化效果实测 1. 为什么需要量化模型? 当我第一次在OpenClaw中尝试接入Qwen3.5-9B模型时,就遇到了一个现实问题:我的MacBook Pro风扇开始疯狂转动,内存占用直接飙升到16GB…...

github上传项目代码手把手运行,包含部分坑
git config --global init.defaultBranch main 自定义默认分支名称,远程分支是main git init(默认是master) git config --global init.defaultBranch main(以后默认使用main) git push -f origin main (强制覆盖…...

如何保证 Session ID 的随机性和不可猜测性?
你的 Session ID 安全吗?—— 从可预测的“门禁卡”到安全的“加密钥匙”1. 引言:一张编号可以被猜到的门禁卡2. Session 与 Session ID:会话的“钥匙”3. 为什么 Session ID 必须随机且不可预测?4. 攻击详解:会话劫持…...
)
国产化服务器上,手把手教你用TongHttpServer V6.0搭建静态资源站(含麒麟/统信系统适配指南)
国产化环境实战:TongHttpServer V6.0静态资源站部署全攻略 在信创产业快速发展的背景下,国产化软硬件生态已逐步成熟。对于需要在国产CPU和操作系统环境中部署Web服务的工程师而言,选择一款性能优异且兼容性良好的国产Web服务器软件至关重要。…...

告别LiveCharts免费版性能瓶颈:这5个隐藏设置让你的WPF实时曲线图飞起来
突破WPF实时图表性能瓶颈:LiveCharts隐藏优化全解析 当你的WPF应用需要展示实时数据流时,LiveCharts免费版可能是你的首选工具——直到你发现图表开始卡顿、刷新率跟不上数据变化。这不是LiveCharts的终点,而是性能调优的起点。本文将带你深入…...