数据结构之《栈》
在之前我们已经学习了数据结构中线性表里面的顺序表与链表,了解了如何实现顺序表与链表增、删、查、该等功能。其实在线性表中除了顺序表和链表还有其他的类别,在本篇中我们就将学习另外一种线性表——栈,在通过本篇的学习后,你将会对栈的结构有充足的了解,在了解完结构后我们还将进行栈的实现。一起加油吧!!!

1.栈的概念与结构
栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的⼀端称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出(先进后出)LIFO(Last In First Out的原则。
压栈:栈的插入操作叫做进栈/压栈/入栈,入数据在栈顶。
出栈:栈的删除操作叫做出栈。出数据也在栈顶。

那么栈的底层结构是基于什么的呢?其实基于数组还是基于单链表或者是双链表都是可以的,那么哪一种是最优解呢?接下来我们就来分析基于不同底层结构的利与弊
若底层结构基于数组,则可以让数组的低地址处表示栈底,数组的高地址处表示栈顶,使用一个size变量来表示数组有效数据个数,这样就可以要入栈时直接在size位置插入数据,之后size加一;出栈时就可以直接让size减一,这样就可以让数组的有效个数减一。以上使用数组来作为栈的底层结构时间复杂度为O(1)
在数组当中虽然每次在空间不足时都会以之前二倍的方式申请新空间,这时可能会存在内存的浪费,当时由于数组在内存中是连续存放的,这就使得在入栈和出栈不需要再每次都申请空间,而且数组在取数据的时候可能缓存中就有不一定要在主存中取。

若栈的底层结构为单链表,如果是在单链表尾部表示栈顶,头部表示栈底这样在无论是在入栈还是在出栈时因为都需要通过遍历来找到单链表的尾节点,所以时间复杂度都为O(N)。所以这时就要改变栈顶为单链表的头部,栈底为单链表的尾部,这时在入栈和出栈时就不需要遍历单链表,时间复杂度就都为O(1)。
但是单链表每次在入栈和出栈时都要申请节点和销毁节点,并且由于单链表每个节点空间在内存当中不一定是连续的,所以每次访问数据都需要区主存取。

而在双链表中无论是让头部作为栈顶,尾部作为栈底还是让尾部作为栈顶,头部作为栈底,由于双链表每个节点内部都有指向前一个节点和下一个节点的指针,所以在入栈和出栈时都不需要遍历链表,所以入栈和出栈时的时间复杂度都为O(1)。
但是双链表在每个节点内部相比单链表都多一个指针变量,在32位环境下每个节点大小就会多4个字节;在64位环境下每个节点大小就会多8字节。因此使用双链表就会造成更多的内存损耗。
通过以上的分析可以发现无论栈的底层结构是基于数组还是单链表还是双链表在入栈和出栈时的时间复杂度都为O(1),但是综合其他因素使用数组是最优解
2.栈的实现
在实现栈的代码内在Stack.h头文件内定义栈的结构以及对各种功能函数进行声明,在Stack.c文件内实现各个函数,在test.c文件内对实现的各函数进行测试
2.1栈结构的定义
在Stack.h中创建一个结构体来定义栈的结构,在该结构体中的成员变量和顺序表中基本是相同的,只不过将顺序表中表示有效元素个数的size改名位top,让top来表示栈顶
//定义栈的结构
typedef int STDataType;
typedef struct stack
{STDataType* a;int capacity;//栈空间大小int top;//栈顶
}stack;2.2栈的初始化
要完成栈的初始化函数首先要在Stack.h完成初始化函数的声明
//初始化栈
void stackInit(stack* ps);将该函数命名为stackInit,函数的参数就为指向结构体的指针
接下来就是在stack.c内完成初始化函数的实现
由于ps指针是指向结构体的指针,所以该指针不能为空,所以要对ps进行assert断言
//初始化栈
void stackInit(stack* ps)
{assert(ps);ps->a = NULL;ps->top = ps->capacity = 0;
}2.3检测栈是否为空
要完成检测栈是否为空函数首先要在Stack.h完成该函数函数的声明
//检测栈是否为空
bool stackEmpty(stack* ps);将该函数命名为stackEmpty,函数的参数就为指向结构体的指针,函数的返回类型为布尔类型
接下来就是在stack.c内完成检测栈是否为空函数的实现
由于ps指针是指向结构体的指针,所以该指针不能为空,所以要对ps进行assert断言
在该函数中若数组内的有效个数top为0函数就会返回true,不为0就返回false
//检测栈是否为空
bool stackEmpty(stack* ps)
{assert(ps);return ps->top==0;
}2.4入栈
要完成入栈函数首先要在Stack.h完成初始化函数的声明
void stackPush(stack* ps,STDataType x);将该函数命名为stackPush,函数的参数有两个,第一个为指向结构体的指针,第二个为要进入栈的数据
接下来就是在stack.c内完成入栈函数的实现
由于在入栈时数组的空间可以已经满了,因此在进行插入数据之前要判断数组的有效个数是否与数组的空间大小相同,如果相同就需要进行增容。增容的代码就和之前的顺序表检测数组空间大小函数一样。
在调整完空间大小之后的入栈就和顺序表中得尾插一样,ps->a[ps->top++] = x一句代码就可以实现
//入栈
void stackPush(stack* ps,STDataType x)
{assert(ps);if (ps->top == ps->capacity){int newcapacity = ps->capacity == 0 ? 4 : 2 * ps->capacity;STDataType* tmp = (STDataType*)realloc(ps->a, newcapacity * sizeof(STDataType));if (tmp == NULL){perror("realloc fail!");exit(1);}ps->a=tmp;ps->capacity = newcapacity;}ps->a[ps->top++] = x;
}2.5出栈
要完成出栈函数首先要在Stack.h完成出栈函数的声明
//出栈
void stackPop(stack* ps);将该函数命名为stackPop,函数的参数为指向结构体的指针
接下来就是在stack.c内完成出栈函数的实现
由于ps指针是指向结构体的指针,所以该指针不能为空,所以要对ps进行assert断言
同时在出栈时栈不能为空,所以要对satckEmpt(ps)进行assert断言
在出栈就和顺序表中得尾删一样将top减一就可
//出栈
void stackPop(stack* ps)
{assert(ps);assert(!stackEmpty(ps));--ps->top;
}2.6取栈顶元素
要完成取栈顶元素函数首先要在Stack.h完成取栈顶元素函数的声明
//获取栈顶元素
STDataType stackTop(stack* ps);将该函数命名为stackTop,函数的参数为指向结构体的指针,函数的返回值就为栈顶的元素
接下来就是在stack.c内完成取栈顶原始函数的实现
由于ps指针是指向结构体的指针,所以该指针不能为空,所以要对ps进行assert断言
同时在出栈时栈不能为空,所以要对satckEmpt(ps)进行assert断言
由于top指向数组的尾元素的后一位,所以只要将size-1就可以得到栈顶元素
//获取栈顶元素
STDataType stackTop(stack* ps)
{assert(ps);assert(!stackEmpty(ps));return ps->a[ps->top - 1];
}2.7获取栈中有效元素个数
要完成获取栈中有效元素个数函数首先要在Stack.h完成获取栈中有效元素个数函数的声明
//获取栈中有效元素个数
int stackSize(stack* ps);将该函数命名为stackSize,函数的参数为指向结构体的指针,函数的返回值就为栈的元素个数
接下来就是在stack.c内完成获取栈中有效元素个数函数的实现
由于ps指针是指向结构体的指针,所以该指针不能为空,所以要对ps进行assert断言
因为在结构体中的top就为数组的有效元素个数,所以在该函数中返回ps->top即可
//获取栈中有效元素个数
int stackSize(stack* ps)
{assert(ps);return ps->top;
}2.8销毁栈
要完成销毁栈函数首先要在Stack.h完成销毁栈函数的声明
//销毁栈
void stackDestory(stack* ps);将该函数命名为stackDestory,函数的参数为指向结构体的指针
接下来就是在stack.c内完成销毁栈函数的实现
由于ps指针是指向结构体的指针,所以该指针不能为空,所以要对ps进行assert断言
在销毁时,由于栈的空间是由realloc申请来的,所以在使用完后要用free来释放内存空间,并且在释放后将指针ps->a置为NULL,且将top和capacity都赋值为0
//销毁栈
void stackDestory(stack* ps)
{assert(ps);if (ps->a){free(ps->a);}ps->a = NULL;ps->top = ps->capacity = 0;
}2.9栈的打印
因为在栈和顺序表以及链表不同,由于栈只能在一端进和出所以栈是不能遍历,所以我们不能通过创建一个函数来遍历栈
所以要打印栈就只能在test.c内调用相关函数来实现
例如以下栈先依次入栈1,2,3,4,之后要打印就通过以下循环来实现
#include"stack.h"void test()
{stack ps;stackInit(&ps);stackPush(&ps, 1);stackPush(&ps, 2);stackPush(&ps, 3);stackPush(&ps, 4);while (!stackEmpty(&ps)){STDataType p = stackTop(&ps);printf("%d ", p);stackPop(&ps);}stackDestory(&ps);
}int main()
{test();return 0;
}3.栈的实现完整代码
stack.h
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<stdbool.h>
#include<assert.h>
#include<stdlib.h>
//定义栈的结构
typedef int STDataType;
typedef struct stack
{STDataType* a;int capacity;//栈空间大小int top;//栈顶
}stack;//初始化栈
void stackInit(stack* ps);
//销毁栈
void stackDestory(stack* ps);
//检测栈是否为空
bool stackEmpty(stack* ps);
//入栈
void stackPush(stack* ps,STDataType x);
//出栈
void stackPop(stack* ps);
//获取栈顶元素
STDataType stackTop(stack* ps);
//获取栈中有效元素个数
int stackSize(stack* ps);stack.c
#include"stack.h"//初始化栈
void stackInit(stack* ps)
{assert(ps);ps->a = NULL;ps->top = ps->capacity = 0;
}//销毁栈
void stackDestory(stack* ps)
{assert(ps);if (ps->a){free(ps->a);}ps->a = NULL;ps->top = ps->capacity = 0;
}//检测栈是否为空
bool stackEmpty(stack* ps)
{assert(ps);return ps->top==0;
}//入栈
void stackPush(stack* ps,STDataType x)
{assert(ps);if (ps->top == ps->capacity){int newcapacity = ps->capacity == 0 ? 4 : 2 * ps->capacity;STDataType* tmp = (STDataType*)realloc(ps->a, newcapacity * sizeof(STDataType));if (tmp == NULL){perror("realloc fail!");exit(1);}ps->a=tmp;ps->capacity = newcapacity;}ps->a[ps->top++] = x;
}//出栈
void stackPop(stack* ps)
{assert(ps);assert(!stackEmpty(ps));--ps->top;
}//获取栈顶元素
STDataType stackTop(stack* ps)
{assert(ps);assert(!stackEmpty(ps));return ps->a[ps->top - 1];
}//获取栈中有效元素个数
int stackSize(stack* ps)
{assert(ps);return ps->top;
}相关文章:

数据结构之《栈》
在之前我们已经学习了数据结构中线性表里面的顺序表与链表,了解了如何实现顺序表与链表增、删、查、该等功能。其实在线性表中除了顺序表和链表还有其他的类别,在本篇中我们就将学习另外一种线性表——栈,在通过本篇的学习后,你将…...

Vue3基础语法
一:创建Vue3工程(适用Vite打包工具) Vite官网:Home | Vite中文网 (vitejs.cn) 直接新建一个文件夹,打开cmd运行: npm create vitelatest 选择Vue和TS语言即可 生成一个项目。 Vue3的核心语法ÿ…...

【Python】基础学习技能提升代码样例4:常见配置文件和数据文件读写ini、yaml、csv、excel、xml、json
一、 配置文件 1.1 ini 官方-configparser config.ini文件如下: [url] ; section名称baidu https://www.zalou.cnport 80[email]sender ‘xxxqq.com’import configparser # 读取 file config.ini # 创建配置文件对象 con configparser.ConfigParser() # 读…...

JavaScript基础——JavaScript调用的三种方式
JavaScript简介 JavaScript的作用 JavaScript的使用方式 内嵌JS 引入外部js文件 编写函数 JavaScript简介 JavaScript(简称“JS”)是一种具有函数优先的轻量级,解释型或即时编译型的编程语言。它是Web开发中最常用的脚本语言之一&#x…...

ITSS:IT服务工程师
证书亮点:适中的费用、较低的难度、广泛的应用范围以及专业的运维认证。 总体评价:性价比良好! 证书名称:ITSS服务工程师 证书有效期:持续3年 培训要求:必须参加培训,否则将无法参与考试 发…...

鸿蒙开发——axios封装请求、拦截器
描述:接口用的是PHP,框架TP5 源码地址 链接:https://pan.quark.cn/s/a610610ca406 提取码:rbYX 请求登录 HttpUtil HttpApi 使用方法...

Scikit-Learn中的分层特征工程:构建更精准的数据洞察
Scikit-Learn中的分层特征工程:构建更精准的数据洞察 在机器学习中,特征工程是提升模型性能的核心技术之一。Scikit-Learn(简称sklearn),作为Python中广受欢迎的机器学习库,提供了多种方法来进行特征工程&…...

CSOL遭遇DDOS攻击如何解决
CSOL遭遇DDOS攻击如何解决?在错综复杂的数字网络丛林中,《Counter-Strike Online》(简称CSOL)犹如一座坚固的堡垒,屹立在游戏世界的中心,吸引着无数玩家的目光与热情。这座堡垒并非无懈可击,DDo…...
基于python的BP神经网络红酒品质分类预测模型
1 导入必要的库 import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder from tensorflow.keras.models import Sequential from tenso…...

Kylin与Spark:大数据技术集成的深度解析
引言 在大数据时代,企业面临着海量数据的处理和分析需求。Kylin 和 Spark 作为两个重要的大数据技术,各自在数据处理领域有着独特的优势。Kylin 是一个开源的分布式分析引擎,专为大规模数据集的 OLAP(在线分析处理)查…...

⌈ 传知代码 ⌋ 利用scrapy框架练习爬虫
💛前情提要💛 本文是传知代码平台中的相关前沿知识与技术的分享~ 接下来我们即将进入一个全新的空间,对技术有一个全新的视角~ 本文所涉及所有资源均在传知代码平台可获取 以下的内容一定会让你对AI 赋能时代有一个颠覆性的认识哦&#x…...
)
深入了解 Python 面向对象编程(最终篇)
大家好!今天我们将继续探讨 Python 中的类及其在面向对象编程(OOP)中的应用。面向对象编程是一种编程范式,它使用“对象”来模拟现实世界的事务,使代码更加结构化和易于维护。在上一篇文章中,我们详细了解了…...

手把手教你实现基于丹摩智算的YoloV8自定义数据集的训练、测试。
摘要 DAMODEL(丹摩智算)是专为AI打造的智算云,致力于提供丰富的算力资源与基础设施助力AI应用的开发、训练、部署。 官网链接:https://damodel.com/register?source6B008AA9 平台的优势 💡 超友好! …...

SSH相关
前言 这篇是K8S及Rancher部署的前置知识。因为项目部署测试需要,向公司申请了一个虚拟机做服务器用。此前从未接触过服务器相关的东西,甚至命令也没怎么接触过(接触最多的还是git命令,但我日常用sourceTree)。本篇SSH…...
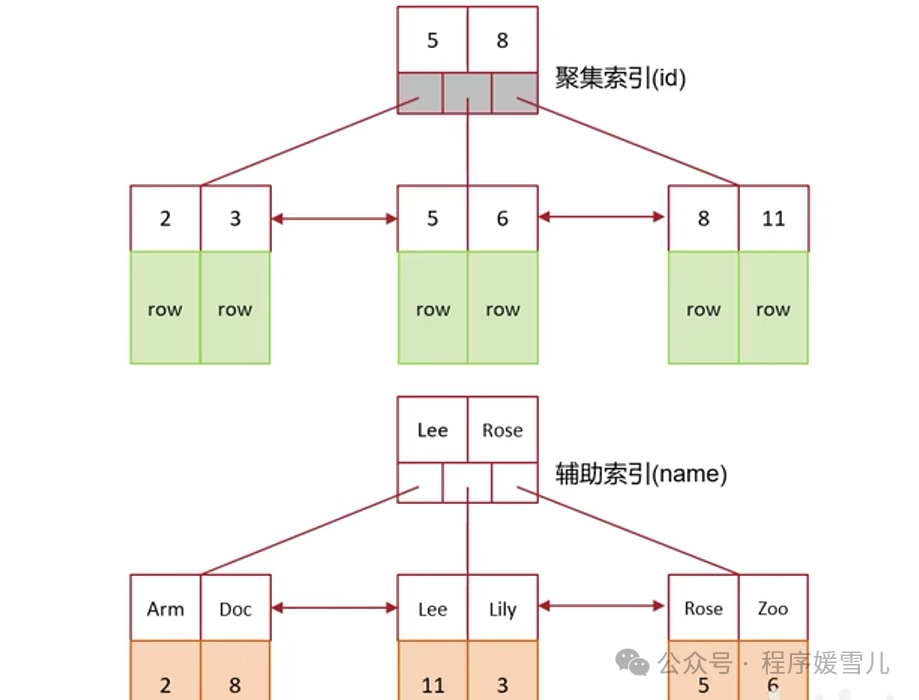
mysql超大分页问题处理~
大家好,我是程序媛雪儿,今天咱们聊mysql超大分页问题处理。 超大分页问题是什么? 数据量很大的时候,在查询中,越靠后,分页查询效率越低 例如 select * from tb_sku limit 0,10; select * from tb_sku lim…...

Gitlab以及分支管理
一、概述 Git 是一个分布式版本控制系统,用于跟踪文件的变化,尤其是源代码的变化。它由 Linus Torvalds 于 2005 年开发,旨在帮助管理大型软件项目的开发过程。 二、Git 的功能特性 Git 是关注于文件数据整体的变化,直接会将文件…...

探索Axure在数据可视化原型设计中的无限可能
在当今数字化浪潮中,产品设计不仅关乎美观与功能的平衡,更在于如何高效、直观地传达复杂的数据信息。Axure RP,作为原型设计领域的佼佼者,其在数据可视化原型设计中的应用,正逐步揭开产品设计的新篇章。本文将从多个维…...

Redis 内存淘汰策略
Redis 作为一个内存数据库,必须在内存使用达到配置的上限时采取策略来处理新数据的写入需求。Redis 提供了多种内存淘汰策略(Eviction Policies),以决定在内存达到上限时应该移除哪些数据。...

逆天!吴恩达+OpenAI合作出了大模型课程!重磅推出《LLM CookBook》中文版
吴恩达老师与OpenAI合作推出的大模型系列教程,从开发者在大型模型时代的必备技能出发,深入浅出地介绍了如何基于大模型API和LangChain架构快速开发出结合大模型强大能力的应用。 这些教程非常适合开发者学习,以便开始基于LLM实际构建应用程序…...

uint16_t、uint32_t类型数据高低字节互换
1. 使用位运算和逻辑运算符实现 #include<stdio.h> #include<stdint.h> int main() {void test_3() {uint16_t version = 0x1234;printf("%#x\n",(uint8_t)version);printf("%#x\n", version>>8);/*** 在C语言中,uint16和uint8是无符号…...

2026年局域网考试系统选型对比:优考试助力政企信创与内网安全
在数字政府与信创产业全面推进的当下,政企、事业单位及涉密单位的考试场景,正面临国产化适配、数据安全、灵活部署三重核心要求。既要满足内网环境下的数据安全与物理隔离,又要兼顾部分场景下外网访问的灵活性,传统单一架构考试系…...
)
从模糊到微距级细节:Midjourney纹理生成的6层提示结构法(工业级纹理资产生产标准)
更多请点击: https://kaifayun.com 第一章:从模糊到微距级细节:Midjourney纹理生成的6层提示结构法(工业级纹理资产生产标准) 在游戏、影视与工业设计领域,高质量纹理资产需同时满足物理可信性、UV可平铺性…...

我在大厂做开发的5年:那些996的日子
作为一名在互联网大厂摸爬滚打五年的开发工程师,如今转型成为软件测试团队的负责人,回望过去那些被996填满的日子,我有太多话想对同为技术从业者的测试同仁们说。这些经历不仅是我个人的成长印记,更藏着开发与测试岗位在高压环境下…...

手写一个AI代码审查员:Claude Agent SDK + MCP 深度实战
引言2026年5月,Anthropic做了一件意味深长的事:把 Claude Code SDK 改名为 Claude Agent SDK。改名背后是一个判断——这不再是"帮你写代码的工具",而是一个能自主读代码、分析逻辑、修改文件、跑测试、甚至提PR的AI Agent编排框架…...

终极AI评估指南:用DeepEval开源框架轻松保障你的大语言模型质量
终极AI评估指南:用DeepEval开源框架轻松保障你的大语言模型质量 【免费下载链接】deepeval The LLM Evaluation Framework 项目地址: https://gitcode.com/GitHub_Trending/de/deepeval 你是否曾担心AI助手给出错误的医疗建议?是否焦虑金融AI客服…...

针对现在的AI模型的token中转转包业务的分析
📊 价格优势深度分析 1. 价格差异全景图(2026年实测数据) 服务类型1亿Token价格价格倍差适用场景超低价陷阱1351倍个人测试、极低质量需求主流中转站800-1,5006-11倍中小企业、开发者合规服务商3,000-5,00022-37倍企业级应用、生产环境官方…...

3D格式转换神器:如何用stltostp轻松实现STL到STEP的无缝转换
3D格式转换神器:如何用stltostp轻松实现STL到STEP的无缝转换 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 你是否曾经遇到这样的困境?精心设计的3D打印模型在STL格式下…...

为什么我强烈推荐大学生打CTF!看完你就懂了!
前言 写这个文章是因为我很多粉丝都是学生,经常有人问: 感觉大一第一个学期忙忙碌碌的过去了,啥都会一点,但是自己很难系统的学习到整个知识体系,很迷茫,想知道要如何高效学习。 这篇文章我主要就围绕两点…...
)
在线课程|基于springboot+vue的在线课程管理系统(源码+数据库+文档)
在线课程管理系统 目录 基于springbootvue的在线课程管理系统 一、前言 二、系统设计 三、系统功能设计 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介绍:✌️大厂码农|毕设布道师,…...

Python之rf-phate包语法、参数和实际应用案例
一、RF‑PHATE 包核心功能 RF‑PHATE 是一个有监督降维与可视化包,核心是把随机森林(RF)特征重要性与 PHATE(基于热扩散的流形嵌入) 结合,生成标签导向的低维嵌入,凸显与响应变量相关的结构、抑…...