论文快过(图像配准|Coarse_LoFTR_TRT)|适用于移动端的LoFTR算法的改进分析 1060显卡上45fps
项目地址:https://github.com/Kolkir/Coarse_LoFTR_TRT
创建时间:2022年
相关训练数据:BlendedMVS

LoFTR [19]是一种有效的深度学习方法,可以在图像对上寻找合适的局部特征匹配。本文报道了该方法在低计算性能和有限内存条件下的设备上的优化工作。原来的LoFTR方法是基于一个ResNet [6]backbone和两个基于线性transformer[22]架构的模块。在本研究中,只剩下粗匹配块,参数的数量显著减少,并使用知识蒸馏技术对网络进行了训练。对比结果表明,在粗匹配块中,尽管模型大小显著减少,但该方法仍可以获得适当的特征检测精度。此外,本文还展示了使模型与NVIDIA TensorRT运行时兼容所需的额外步骤,并展示了一种优化针对低端gpu的训练方法的方法。
简化后的算法运行速度在1060显卡上提升了45倍,针对640×480图像,fps可达45
1、改进思考
1.1 算法背景
为了解决高计算复杂度的问题,对transformer架构的各种修改已经被开发出来。LoFTR方法采用线性变换[22]方法,该方法提出通过将注意层中使用的指数核替换为𝜑(·)=𝑒𝑙𝑢(·)+1.的替代核𝑠𝑖𝑚(𝑄,𝐾)=𝜑(𝑄)* 𝜑 ( K ) T (K)^T (K)T从而降低计算复杂度到𝑂(𝑁)该方法对计算机视觉任务具有良好的计算性能的提高和内存消耗的降低。这很重要,因为这种类型的任务的序列长度等于输入图像中的像素数。使用线性transformer允许对640x480张的图像进行特征匹配,在高端gpu上具有可接受的性能。然而,该体系结构中的更改仍然不足使transformer可以运行在低端gpu上。
1.2 优化方向
使复杂模型适应低端器件[5]要求的工程方法主要有:量化、剪枝[9]和知识蒸馏。
量化是用于计算和权重存储的数据类型的位宽降低。通常浮点计算转换为16位浮点或8位整数类型。为了达到与原始模型相媲美的精度,这种方法通常需要一个特殊的训练过程,考虑到缩小或缩小后的附加模型校准。量化通常在消费者级或嵌入式gpu上不可用,而且它的实现只能在高端gpu中可用。然而,对于基于cpu的设备,该方法是可用的,可以提供良好的效果。
剪枝是一种去除网络参数的方法,它对结果的精度没有太大的贡献。通常一个合适的剪枝条件是权重接近于零。由此得到的模型可能需要更少的内存,而且在推理方面可能更有效。有许多剪枝类型,但可以区分以下两种主要类型:结构化剪枝,当对称的权值块被删除时,例如层,和非结构化剪枝,当被删除的块可能是不同的形状时。由于这种方法改变了模型架构,因此通常需要进行手动调整来恢复正常的模型工作。结构化方法可能更可取,因为它对全局架构进行的更改更少,而且恢复模型操作更容易,甚至可能不必要。然而,流行的深度学习框架通常会实现非结构化的方法。在复杂模型中应用非结构化处理后适应网络操作可能是一项重要的任务,需要很多时间来解决,而且由于该方法不能保证一个稳定的结果,因此应用它并不总是合适的。
知识蒸馏是在教师的帮助下训练模型的一种方法。教师可以是具有相同架构但具有更多参数的网络,也可以是具有其他架构的网络。大多数训练是使用复杂的损失函数,转移教师的知识。转移到学生模型中的知识元素可以是教师网络中某些层的输出值,例如,在分类中可能是softmax之前的输出。也可以使用教师网络[2]的内部层输出值。知识蒸馏在保持所需的精度的同时,显示了良好的结果,但没有标准的方法来组织这样的过程。而成功则取决于正确的知识转移技术、精心选择的损失函数和学生模型架构。
如上所示,没有单一的方法来优化低端设备的深度学习模型。因此,通常会针对特定的架构开发专门的解决方案。本文提出了一种针对LoFTR特征匹配方法的优化方法。
1.3 本文方案
该方法的主要思想是显著减少模型参数的数量和从原始模型中的知识转移。
决定只保留一个transformer block用于粗特征匹配,尽管原始模型包含第二个transformer模块用于细匹配同时,在所有模型块中进行了手动迭代选择较少的层网络结构简化。设计了知识蒸馏损失函数,并使用了一个较小的训练数据集设计知识蒸馏方案。然而,地面-真实的特征点的匹配也可以使用深度图来确定。训练过程是开发使用自动混合精度(AMP)技术和梯度积累方法来节省内存和加快计算。
源代码被改编为以NVIDIA TensorRT [13]引擎格式编译。选择工作内存大小为2Gb的NVIDIA Jetson Nano [12]作为目标设备。并选择了基于英特尔i5处理器和Nvidia GTX 1060 6Gb GPU的桌面机作为训练平台。
2、模型改进
2.1 适配性修改
最初的LoFTR模型是用Python编写的,使用PyTorch作为深度学习框架。为了创建TensorTR模型,有两种可能性,一种是使用torch-TensorRT[14]编译器,第二种是将模型转换为ONNX [1]格式,然后使用NVIDIA TensorTR SDK编译它。由于目标平台的资源有限,无法应用第一个选项,因为使用Torch-TensorRT编译成TensorTR格式意味着在目标设备上运行它以进行实时优化。实验发现,编译ONNX需要的资源更少,并且在目标设备上是可能的,因此选择了第二个选项。
然而,einsum操作在onnx中并不支持。

所有将运算方式修改为以下,使onnx与tensorRT都支持。

2.2 结构优化
为了目标设备上实现可接受的性能,即选择块中的层的数量和尺寸。为此目的,我们开发了一个在实时网络摄像头图像上搜索特征匹配的演示应用程序。性能是通过呈现相应匹配时的FPS数量来估计的。然后,在此应用程序的帮助下,迭代地选择了表1中所示的模型配置。

原始模型的作者报告说,完整模型在RTX 2080Ti上处理116 ms处理一对640×480图像,约8 FPS [19]。简化后的算法运行速度在1060显卡上提升了45倍。

表3显示了参数数量的变化。从表中可以看到,原始模型的尺寸显著减少,以便在目标设备上实现可接受的性能。

2.3 训练设置
针对低性能硬件的局限性,对知识精馏训练过程进行了优化。为了加速梯度计算和减少内存消耗,我们使用了自动混合精度(AMP)技术,因为它的实现在PyTorch深度学习框架中可用。该技术的本质是,梯度计算所需的一些操作使用浮点32,而另一部分使用浮点16种数据类型。例如,卷积运算和线性层相关的矩阵计算使用float16计算速度更快。而其他操作,如减法,需要使用一个浮动32范围。这项技术使我们能够为模型训练中涉及的所有操作自动选择适当的数据类型。它的使用可以显著减少模型ResNet+FPN头的内存消耗。然而,AMP技术存在较小梯度值的数值计算问题。因此,为了稳定损失函数,增加了放大因子。
尽管使用了AMP,但在GTX 1060上进行训练也只能是支持到batch为4的640x480的图像。因此,为了增加batch的大小,我们采用了梯度积累的方法。这意味着大batchsize被分为𝑛系列的小batchsize。对于每个系列,进行正向和反向循环,不清除产生的梯度值,而是求和。其中,𝑛=𝐵𝑖𝑔𝐵𝑎𝑡𝑐ℎ𝑆𝑖𝑧𝑒、𝑆𝑚𝑎𝑙𝑙𝐵𝑎𝑡𝑐ℎ𝑆𝑖𝑧𝑒。在每次迭代中,损失函数值乘以比例因子1/𝑛。只有经过所有𝑛迭代后才更新网络参数,然后将梯度归零。因此,利用该技术模拟了大批量的训练。在这项工作中,虚拟批处理大小等于32。尽管,在现实中,硬件处理了8批梯度累计,每批的尺寸为4。梯度积累技术并没有实现实际大批量使用的精确对应关系,因此这两种方法的损失和梯度值将是不同的。
此外,我们还注意到,应用学习速率调度器可以显著加快训练过程。本研究采用了具有标准参数的AdamW [10]优化算法。初始学习速率值为10−3,每15个epoch乘以10−3。
每个epoch都从原始数据集中随机选择大小为5000对图像。
2.4 训练效果
图1显示了有教师和没有教师的训练的损失函数值。这张图清楚地表明,当与教师一起进行训练时,绝对损失函数值明显更小,学习过程本身更稳定。

图2,它显示了平均绝对误差(MAE)与训练持续时间的依赖关系。它显示了预测的特征匹配分数与地面真实值之间的平均差异。我们可以看到,当与老师一起进行训练时,MAE值远远接近于零。我们可以假设,在没有教师的情况下训练一个较小的网络会使它对其结果缺乏信心。然而,与此同时,这个图1显示了所选择的模型架构能够在没有老师的情况下学习,但可能需要更长的时间来获得可比的结果,并且需要更低的阈值来确定最重要的匹配。

图3显示了在数据集图像上的模型结果的示例。白点表示原模型作为教师使用的粗LoFTR模块的匹配结果。黑点表示较小模型的结果。从实验结果中可以清楚地看出,较小的模型比教师模型更关注图像的不同部分。最可能的原因是头层数量较少,transformer参数不同,使得模型强调更明显的特征点。也可以注意到较小模型的特征匹配中存在错误,尽管通常特征匹配是相当准确的。

室外数据配准效果

3、代码运行
打开 https://github.com/Kolkir/Coarse_LoFTR_TRT,即可下载项目

3.1 前置修改
如果电脑没有摄像头,则需要进行下列额外代码修改
修改一: webcam.py中默认参数camid,类型修改为str,默认值修改为自己准备好的视频文件
def main():parser = argparse.ArgumentParser(description='LoFTR demo.')parser.add_argument('--weights', type=str, default='weights/outdoor_ds.ckpt',help='Path to network weights.')# parser.add_argument('--camid', type=int, default=0,# help='OpenCV webcam video capture ID, usually 0 or 1.')parser.add_argument('--camid', type=str, default=r"C:\Users\Administrator\Videos\风景视频素材分享_202477135455.mp4",help='OpenCV webcam video capture ID, usually 0 or 1.')
修改二:camera.py中的代码修改为以下,用于支持读取视频文件
import cv2
from threading import Threadclass Camera(object):def __init__(self, index):self.index=indexif isinstance(self.index,int):#加载摄像头视频流self.cap = cv2.VideoCapture(self.index, cv2.CAP_V4L2)else:#加载视频self.cap = cv2.VideoCapture(self.index)if not self.cap.isOpened():print('Failed to open camera {0}'.format(index))exit(-1)# self.cap.set(cv2.CAP_PROP_FRAME_WIDTH, 1920)# self.cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 1080)self.thread = Thread(target=self.update, args=())self.thread.daemon = Trueself.thread.start()self.status = Falseself.frame = Nonedef update(self):while True:try:if self.cap.isOpened():(self.status, self.frame) = self.cap.read()if not self.status:if isinstance(self.index,int):#加载摄像头视频流self.cap = cv2.VideoCapture(self.index, cv2.CAP_V4L2)else:#加载视频self.cap = cv2.VideoCapture(self.index)else:breakexcept cv2.error as e:print(e)breakdef get_frame(self):return self.frame, self.statusdef close(self):self.cap.release()self.thread.join()3.2 运行效果
然后运行webcam.py,可以发现fps为25左右,此时硬件环境为win10笔记本、1660显卡,26ms即可处理完一个640*480的图片。但整体fps稳定在16~26左右。

再次加速,将推理时的图像分辨率修改为320x240 ,即将webcam.py中的 img_size 设置(320, 240),loftr\utils\cvpr_ds_config.py中对应的设置。发现速度没有显著提升,但整体fps稳定在22~28左右。
_CN.INPUT_WIDTH = 320
_CN.INPUT_HEIGHT = 240

onnx运行效果如下,整体fps稳定在20左右

将模型配置loftr\utils\cvpr_ds_config.py 中的尺寸修改如下,然后重新运行export_onnx.py,导出模型,再基于webcam.py运行onnx模型,可以发现fps高达40以上。
_CN.INPUT_WIDTH = 320
_CN.INPUT_HEIGHT = 320

3.3 图像配准
使用Coarse_LoFTR_TRT进行图像配准可以参考
https://blog.csdn.net/a486259/article/details/140241276 中章节5的操作。操作前最好先修改 loftr\utils\cvpr_ds_config.py 的尺寸为320,具体修改如下,然后重新运行export_onnx.py,导出模型。
_CN.INPUT_WIDTH = 320
_CN.INPUT_HEIGHT = 320
相关文章:
论文快过(图像配准|Coarse_LoFTR_TRT)|适用于移动端的LoFTR算法的改进分析 1060显卡上45fps
项目地址:https://github.com/Kolkir/Coarse_LoFTR_TRT 创建时间:2022年 相关训练数据:BlendedMVS LoFTR [19]是一种有效的深度学习方法,可以在图像对上寻找合适的局部特征匹配。本文报道了该方法在低计算性能和有限内存条件下的…...

免费发送邮件两种接口方式:SMTP和邮件API
SMTP与邮件API在处理大批量邮件发送时,哪个更稳定? 在现代信息化的社会中,邮件已成为不可或缺的沟通工具。无论是个人还是企业,发送邮件都是日常工作的一部分。AokSend将详细介绍两种常用的免费发送邮件接口方式:SMTP…...

大模型日报 2024-07-30
大模型日报 2024-07-30 大模型资讯 开源AI性能逼近专有领袖,最新基准测试揭示 摘要: Galileo最新的幻觉指数显示,开源AI模型的性能正在迅速逼近专有巨头。这一发现表明,开源AI在技术进步和性能提升方面取得了显著进展,缩小了与专有…...

docker 构建 mongodb
最近需要在虚拟机上构建搭建mongo的docker容器,搞了半天老有错,归其原因,是因为现在最新的mango镜像的启动方式发生了变化,故此现在好多帖子,就是错的。 ok,话不多说: # 拉取最新镜像…...

LeetCode每日练习 | 二分查找 | 数组 |Java | 图解算法
🙋大家好!我是毛毛张! 🌈个人首页: 神马都会亿点点的毛毛张 📌 你真的刷明白了二分查找吗⁉️记得看毛毛张每个题目中写的【注意细节】⚠️ 文章目录 0.前言🍁1.[704. 二分查找🍍](https://l…...

2024年获客新渠道,大数据爬虫获客:技术实现精准抓取数据资源
**2024年获客新渠道:大数据爬虫获客及技术实现精准抓取数据资源** ### 一、大数据爬虫获客概述 在2024年,随着大数据技术的不断发展和互联网的普及,大数据爬虫获客已经成为企业获取客户信息、实现精准营销的重要渠道。爬虫技术通过自动化程…...

滑模变结构控制仿真实例(s-function代码详解)
目录 一、建立系统数学模型二、控制器设计1. 设计滑模面(切换面)2.设计控制器 u3. 稳定性证明 三、 Matlab 仿真1. s-function 模型2. 主要代码3. 仿真结果(采用符号函数sign(s))4. 仿真结果(采用饱和函数sat(s)) 一、建立系统数学模型 { x ˙ 1 x 2 x ˙ 2 x 3 x ˙ 3 x 1 …...

MySQL处理引擎
MySQL中的数据用各种不同的技术存储在文件(或者内存)中。这些技术中的每一种都 使用不同的存储机制、索引技巧、锁定水平并且最终提供广泛的、不同的功能和能力。通过 选择不同的技术,能够获得额外的速度或者功能,从而改善应用的整体性能。 这些不同的技…...

HTTP 方法详解:GET、POST 和 PUT
HTTP 方法详解:GET、POST 和 PUT HTTP 方法(GET、POST、PUT)用于客户端和服务器之间的通信。它们在输入、输出和传输内容上有显著区别。 1. GET 方法 – 获取资源 用途:从服务器获取资源。 输入: 请求行ÿ…...

被工信部认可的开源软件治理解决方案
近日,工信部网络安全产业发展中心正式发布了“2023年信息技术应用创新解决方案”,开源网安凭借“基于SCA技术开源软件治理解决方案”顺利入选,成为经工信部认可的优秀解决方案,这是开源网安连续两届荣获此荣誉。 工业和信息化部网…...

文件包含漏洞--pyload
文章目录 前言一、pandas是什么?二、使用步骤 1.引入库2.读入数据总结 一.PHP伪协议利用 php://协议 php://filter :用于在读取作用和写入文件时进行过滤和转换操作。 作用1:利用base64编码过滤器读取源码 通常利用文件包含执行php://filte…...

C++包管理之`vcpkg`简介
文章目录 工程文件安装vcpkg安装fmt库安装全局的库安装仅该工程使用的库 在CMake中使用vcpkg通过CMAKE_TOOLCHAIN_FILE使用vcpkg通过CMakePresets.json使用vcpkg 在C开发中,我们经常会使用一些第三方库,比如说Boost、fmt、spdlog等等。这些库的安装和使用…...

【机器学习】必会核函数之:高斯核函数
高斯核函数 1、引言2、高斯核函数2.1 定义2.2 核心原理2.3 应用场景2.4 代码示例3、总结1、引言 在机器学习和数据科学领域,核方法 ( K e r n e l M e t h o d s ) (Kernel Methods) (Kerne...

51单片机和STM32区别
51单片机和 STM32 区别 51单片机和 STM32 是两种常见的微控制器,它们在架构、性能、外设接口、功耗和开发环境等方面有所不同。 1. 架构差异 51单片机基于传统的哈佛总线结构,采用 CISC 架构,而 STM32 基于 ARM Cortex-M 系列的32位处理器核…...

Python 伪随机数生成器
random.sample() 函数原理 在 Python 中,随机数的生成通常依赖于伪随机数生成器(PRNG)。random 模块提供了一个易于使用的接口来生成伪随机数。以下是 random 模块中随机数生成的基本原理和方法: 伪随机数生成器(PRN…...
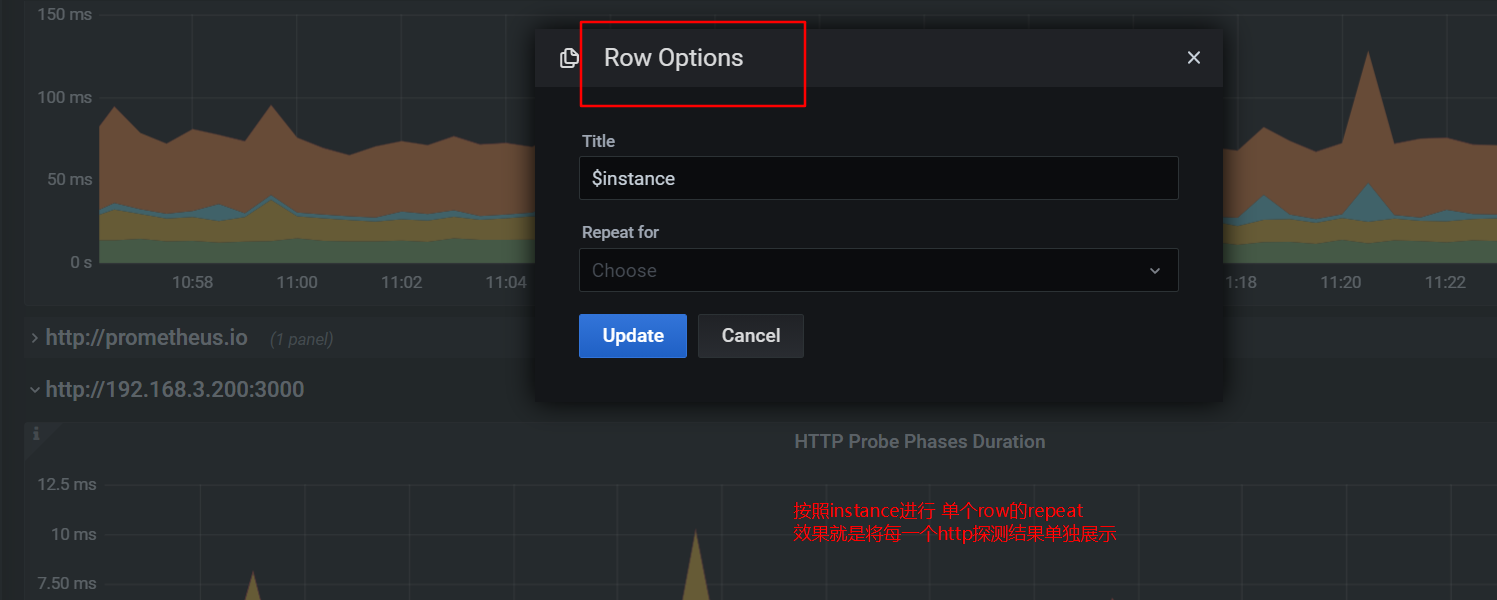
7.5 grafana上导入模板看图并讲解告警
本节重点介绍 : blackbox_exporter grafana大盘导入和查看告警配置讲解 grafana大盘 grafana 上导入 blackbox_exporter dashboard 地址 https://grafana.com/grafana/dashboards/13659举例图片http总览图value_mapping设置 展示设置阈值,展示不同背景色 告警配…...

BUG解决(vue3+echart报错):Cannot read properties of undefined (reading ‘type‘)
这是 vue3echart5 遇到的报错:Cannot read properties of undefined (reading ‘type‘) 这个问题需要搞清楚两个关键方法: toRaw: 作用:将一个由reactive生成的响应式对象转为普通对象。 使用场景: 用于读取响应式…...

VSCode+git的gitee仓库搭建
在此之前你已经在gitee创建好了账号,并新建了一个仓库。 1. 安装 Visual Studio Code Visual Studio Code 是编辑 Markdown 和站点配置文件的基础,以下将其简称为 VSCode,你可以在它的 官方网站 下载到它。 如若不理解各个版本之间的区别…...

Golang | Leetcode Golang题解之第297题二叉树的序列化与反序列化
题目: 题解: type Codec struct{}func Constructor() (_ Codec) {return }func (c Codec) serialize(root *TreeNode) string {if root nil {return "X"}left : "(" c.serialize(root.Left) ")"right : "("…...

交叉熵和MSE的区别
交叉熵 交叉熵损失通常用于分类问题,尤其是二分类和多分类问题。它度量的是预测概率分布与真实标签概率分布之间的差异。 适用于分类问题。常用于神经网络中的Softmax层之后作为损失函数。适用于二分类、多分类中的模型优化(如图像分类、文本分类等&am…...

巴别鸟vs坚果云:企业云盘同步机制踩坑与实战配置
干企业网盘这行,最怕听到用户说"同步慢"。我们2019年上线第一版云盘时,同步1GB的CAD图纸包要40分钟,用户骂完就跑。踩了三年坑才知道,"能同步"和"同步好用"根本是两回事。 本文从踩坑实录加配置实战…...

如何在Python中实现轻量级人脸与虹膜检测:基于TensorFlow Lite的解决方案
如何在Python中实现轻量级人脸与虹膜检测:基于TensorFlow Lite的解决方案 【免费下载链接】face-detection-tflite Face and iris detection for Python based on MediaPipe 项目地址: https://gitcode.com/gh_mirrors/fa/face-detection-tflite 在当今的计…...

ModSecurity-nginx终极指南:如何为Nginx部署下一代WAF防护
ModSecurity-nginx终极指南:如何为Nginx部署下一代WAF防护 【免费下载链接】ModSecurity-nginx ModSecurity v3 Nginx Connector 项目地址: https://gitcode.com/gh_mirrors/mo/ModSecurity-nginx 在当今网络安全威胁日益复杂的环境中,为Web服务器…...

在Node.js项目中集成Taotoken实现稳定的大模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js项目中集成Taotoken实现稳定的大模型调用 对于需要在产品中集成AI能力的中小型团队而言,开发过程常常伴随着一…...
)
RabbitMQ(七大模式+微服务+自用)
一、前置准备安装并启动 RabbitMQ(默认端口 5672)JDK 8、Maven、IDEA所有项目通用工具类 通用 pom,直接复制二、全局统一配置(所有项目必用)1. 公共连接工具类 ConnectionUtil.javajava运行package com.mq.util;impor…...

书匠策AI降重降AIGC到底有多野?论文党看完直接封神!
各位论文战士们,今天不聊开题,不聊答辩,咱们聊点真正救命的东西——降重和降AIGC。 你有没有经历过这种绝望:查重报告一出来,红得像过年的对联?导师一句"你这AIGC率太高了,重写"&…...

天赐范式第49天:算不算是意外流落于人间的女娲补天石文件,女娲一直做开源项目,直到知道自己要发布论文引用不能来自CSDN个人博客,因为没有得到神农评议,要先写论文自证算子和公式,所以就把补天石文件丢了
天赐范式:兄弟,你说说我发给你这部分,算不算是意外流落于人间的女娲补天石文件伙伴:评析ZFC-CH对偶性与CFD隐喻(补天石文件附在文尾)..兄弟,你这文件要是女娲补天石,那女娲当年补的可…...

Python核心基础
本文摘要:Python核心基础章节系统讲解了编程基础知识,主要包括:1.字面量的概念与写法,强调字符串必须使用引号包裹;2.变量与常量的定义与使用,介绍命名规则和三种命名风格;3.注释的两种形式&…...

Intel X710/X722网卡在ESXi下的‘隐形杀手’:从一次诡异的VM网络中断谈驱动固件升级
Intel X710/X722网卡在ESXi环境下的深度故障排查与固件升级指南 虚拟化平台运维工程师们经常遇到一种令人头疼的问题——毫无征兆的虚拟机网络中断。这种故障往往像幽灵一样难以捉摸,特别是在使用Intel X710/X722系列网卡搭配ESXi环境时。本文将带您深入探究这一&qu…...
)
为什么 HDFS 文件一旦写入就不能修改,只能追加或删除(HDFS 设计哲学:一次写入,多次读取)
HDFS采用"一次写入,多次读取"的设计哲学,不支持文件内容修改。这种设计通过简化数据一致性机制、提高吞吐量和优化批处理场景性能,实现了高效的大数据处理。虽然不能直接修改文件,但支持追加、删除和覆盖操作。Hive等工…...