【MySQL】聚合查询

目录
1、前言
2、插入查询结果
3、聚合查询
3.1 聚合函数
3.1.1 count
3.1.2 sum
3.1.3 avg
3.1.4 max 和 min
4、GROUP BY 子句
5、HAVING 关键字
1、前言
前面的内容已经把基础的增删改查介绍的差不多了,也介绍了表的相关约束, 从本期开始往后的内容,就更加复杂了,更多的是一些复杂的查询 SQL.
本期虽然是讲述聚合查询相关知识,但是这里补充一个知识点,如何将查询结果插入到另一个表中呢?
2、插入查询结果
查询还是用的比较多的,对于查询到的数据,能不能也给保存下来呢?也就是把查询的结果插入到另一张表中。
案例:创建一张学生表,表中有 id,name,sex,java,python 这些字段,现需要把 java 成绩超过 90 的学生复制进 java_result 表,复制的字段为 name,java。
进行上述操作之前,我们需要创建一个学生表并准备好相关的数据:
create table student (id int primary key,name varchar(20),sex varchar(1),java float(5, 2)
);
insert into student value (1, '张三', '男', 92.1),(2, '小红', '女', 88.2),(3, '赵六', '男', 83.4),(4, '王五', '男', 93.3),(5, '小美', '女', 96.0);有了学生表之后,我们要把 name,java 这两个字段的查询结果复制到 java_result 这个表中,这里我们注意,要求查询结果的临时表的列数和列的类型,要和 java_result 这里匹配,所以接下来我们就来创建 java_result 这张表:
create table java_result (name varchar(20),java float(5, 2)
);创建好 java_result 这张表之后,就要查询 student 表中 name java 两个字段,并且 java > 90,将满足上述条件的查询结果,插入到 java_result 表中!:
insert into java_result select name, java from student where java > 90;
-- Query OK, 3 rows affected (0.00 sec)
-- Records: 3 Duplicates: 0 Warnings: 0select * from java_result;
+--------+-------+
| name | java |
+--------+-------+
| 张三 | 92.10 |
| 王五 | 93.30 |
| 小美 | 96.00 |
+--------+-------+
-- 3 rows in set (0.00 sec)这样我们就发现,已经将 student 表中 name 和 java 字段满足 > 90 的数据已经全部插入成功了!
3、聚合查询
前面我们接触过的 带表达式查询 都是列和列之间进行运算的,看哪一列满足了这个条件。
而现在要介绍的聚合查询,就是针对 行和行 之间进行运算的!
3.1 聚合函数
进行聚合查询,需要搭配聚合函数,下面介绍的函数都是 SQL 中内置的一组函数,我们先来简单的认识下:
| 函数 | 解释 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的总和,不是数字无意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的平均值,不是数字无意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的最大值,不是数字无意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的最小值,不是数字没有意义 |
下面我们就来演示一下上述的聚合函数的简单使用,在使用之前,我们需要有一张表,并且有相应的数据:
select * from student;
+----+--------+------+-------+
| id | name | sex | java |
+----+--------+------+-------+
| 1 | 张三 | 男 | 92.10 |
| 2 | 小红 | 女 | 88.20 |
| 3 | 赵六 | 男 | 83.40 |
| 4 | 王五 | 男 | 93.30 |
| 5 | 小美 | 女 | 96.00 |
| 6 | 李四 | 男 | NULL |
+----+--------+------+-------+
-- 6 rows in set (0.00 sec)下面我们就针对上述这张表,来使用下上述的聚合函数。
3.1.1 count
● 求出 student 表中有多少同学
select count(*) from student;
+----------+
| count(*) |
+----------+
| 6 |
+----------+
-- 1 row in set (0.00 sec)这个操作就相当于先进行 select * ,然后针对返回的结果,在进行 count 运算,求结果集合的行数. 注意:此处如果有一列的数据全是 null,也会算进去!(因为是针对 *)
此处这里的 count() 括号中,不一定写 *,可以写成任意的列明/表达式,所以我们可以针对 name 来统计人数:
select count(name) from student;
+-------------+
| count(name) |
+-------------+
| 6 |
+-------------+
-- 1 row in set (0.00 sec)● 统计有多少人有 java 考试成绩
select count(java) from student;
+-------------+
| count(java) |
+-------------+
| 5 |
+-------------+
-- 1 row in set (0.00 sec)这里我们看到了,由于 count 是针对 java 字段进行统计,而 李四 那一条数据中,java 为 null,前面我们学习过,null 与任何值计算都是 null,所以统计的时候,就把 null 给去掉了。
● 统计 java 成绩大于90分的人数
select count(java) from student where java > 90;
+-------------+
| count(java) |
+-------------+
| 3 |
+-------------+
-- 1 row in set (0.00 sec)这里我们要弄清楚,count() 这个括号中,是针对你要针对的那一列,针对不同列,不同的条件,就会有不同的结果,对于 count 的演示就到这里。
注意:count 和 () 之间不能有空格,必须紧挨着,在 Java 中函数名和() 之间是可以有空格的,但很少人会这样写。
3.1.2 sum
这个聚合函数,就是把指定列的所有行进行相加得到的结果,要求这个列得是数字,不能是字符串/日期。
● 求出学生表中 java 考试分数总和
select sum(java) from student;
+-----------+
| sum(java) |
+-----------+
| 453.00 |
+-----------+
-- 1 row in set (0.01 sec)虽然我们表中有 java 字段这列中有 null 值,前面了解到 null 与任何值运算都是 null,但是这里的 sum 函数会避免这种情况发生。
当然在后面也可也带上 where 条件,这里就不做过多演示了。
3.1.3 avg
● 求班级中 java 的平均分
select avg(java) from student;
+-----------+
| avg(java) |
+-----------+
| 90.600000 |
+-----------+
-- 1 row in set (0.00 sec)当前只是针对某一列进行平均运算,如果有两门课程,求每个学生总分的平均分呢?
select avg(java + python) from student;这里每次查询结果都只有一列,能否把两个聚合函数一起使用呢?
select sum(java), avg(java) as '平均分' from student;
+-----------+-----------+
| sum(java) | 平均分 |
+-----------+-----------+
| 453.00 | 90.600000 |
+-----------+-----------+
-- 1 row in set (0.00 sec)这里我们能发现一个细节,使用聚合函数查询,字段也是可以取别名的。
3.1.4 max 和 min
● 求出 java 考试分数的最高分和最低分
select max(java) as '最高分', min(java) as '最低分' from student;
+-----------+-----------+
| 最高分 | 最低分 |
+-----------+-----------+
| 96.00 | 83.40 |
+-----------+-----------+
-- 1 row in set (0.00 sec)上述就是聚合函数最基础的用法了, 但是在实际中也可能会有更复杂的情况,比如需要按照某某进行分组查询,这就需要搭配 GROUP BY 字句了。
4、GROUP BY 子句
select 中使用 group by 自居可以对指定列进行分组查询,但是需要满足指定分组的字段必须是 "分组依据字段",其他字段若想出现在 select 中,则必须包含在聚合函数中。
这里我们构造出一张薪水表 salary:
create table salary (id int primary key,name varchar(20),role varchar(20),income int
);
insert into salary value (1, '麻花疼', '老板', 5000000),(2, '篮球哥', '程序猿', 3000),(3, '歪嘴猴', '经理', 20000),(4, '多嘴鸟', '经理', 25000),(5, '雷小君', '老板', 3000000),(6, '阿紫姐', '程序猿', 5000);像上述的情况,如果要查平均工资,那公平吗???
select avg(income) from salary;
+--------------+
| avg(income) |
+--------------+
| 1342166.6667 |
+--------------+
-- 1 row in set (0.00 sec)那篮球哥的月薪连平均下来的零头都不到,所以这样去求平均工资是毫无意义的,真正有意义的是啥呢?求老板这个职位的平均工资,以及经理这个职位的平均工资,及程序猿这个职位的平均工资,通俗来说,就是按照 role 这个字段进行分组。每一组求平均工资:
select role, avg(income) from salary group by role;
+-----------+--------------+
| role | avg(income) |
+-----------+--------------+
| 程序猿 | 4000.0000 |
| 经理 | 22500.0000 |
| 老板 | 4000000.0000 |
+-----------+--------------+
-- 3 rows in set (0.00 sec)这就也就是把 role 这一列,值相同的行给分成了一组,然后计算平均值,也是针对每个分组,分别计算。
在 MySQL 中,这里得到的查询结果临时表,如果没有 order by 指定列排序,这里的顺序是不可预期的,当然也可以手动指定排序,比如最终结果按照平均工资降序排序:
select role, avg(income) from salary group by role order by avg(income) desc;
+-----------+--------------+
| role | avg(income) |
+-----------+--------------+
| 老板 | 4000000.0000 |
| 经理 | 22500.0000 |
| 程序猿 | 4000.0000 |
+-----------+--------------+
-- 3 rows in set (0.00 sec)如果不带聚合函数的普通查询,能否可行呢?这里如果你没有修改任何配置文件,是不可行的,记住千万不能把前面的 order by 与 group by 弄混!
5、HAVING 关键字
分组查询也是可以指定条件的,具体三种情况:
- 先筛选,再分组(where)
- 先分组,再筛选(having)
- 分组前分组后都指定条件筛选(where 和 having 结合使用)
如何理解上述三条的含义呢? 这里我们举几个例子就很好理解了:
● 篮球哥月薪 3000 实在是太低了,简直给程序猿岗位拖后腿,干脆求平均工资时去掉篮球哥的月薪数据。
select role, avg(income) from salary where name != '篮球哥' group by role;
+-----------+--------------+
| role | avg(income) |
+-----------+--------------+
| 程序猿 | 5000.0000 |
| 经理 | 22500.0000 |
| 老板 | 4000000.0000 |
+-----------+--------------+
-- 3 rows in set (0.00 sec)这样求出来的平均值就不包含篮球哥的月薪数据了,这就是先筛选,再分组。
● 还是查询每个岗位的平均工资,但是除去平均月薪在 10w 以上的岗位,不能让篮球哥眼红!
select role, avg(income) from salary group by role having avg(income) < 100000;
+-----------+-------------+
| role | avg(income) |
+-----------+-------------+
| 程序猿 | 4000.0000 |
| 经理 | 22500.0000 |
+-----------+-------------+
-- 2 rows in set (0.00 sec)这样一来就只保留了平均月薪小于 10w 的岗位了,很明显这个平均值是在分组之后才算出来的,这也就是先分组,再筛选。
这里 having 也能加上逻辑运算符,具体感兴趣的小伙伴可以自行下来尝试一下,好比如你想要拿好 offer,就得技术过关,还能加班!
至于第三种分组前后都需要筛选,就是把上述俩例子结合起来,这里就不多赘述了!
【MySQL】联合查询
相关文章:
【MySQL】聚合查询
目录 1、前言 2、插入查询结果 3、聚合查询 3.1 聚合函数 3.1.1 count 3.1.2 sum 3.1.3 avg 3.1.4 max 和 min 4、GROUP BY 子句 5、HAVING 关键字 1、前言 前面的内容已经把基础的增删改查介绍的差不多了,也介绍了表的相关约束, 从本期开始…...
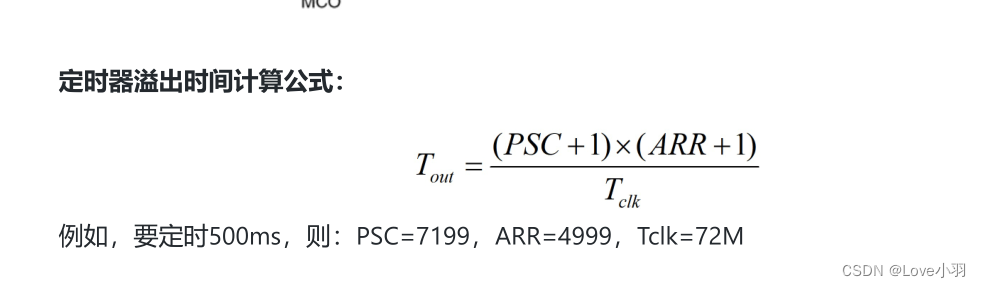
初时STM32单片机
目录 一、单片机基本认知 二、STM系列单片机命名规则 三、标准库与HAL库区别 四、通用输入输出端口GPIO 五、推挽输出与开漏输出 六、复位和时钟控制(RCC) 七、时钟控制 八、中断和事件 九、定时器介绍 一、单片机基本认知 单片机和PC电脑相比…...

debian部署docker(傻瓜式)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 debian10部署dockerdebian10部署docker(傻瓜式)一、准备工作二、**使用 APT 安装,注意要先配置apt网络源**1.配置网络源2.官方下载三、安装…...
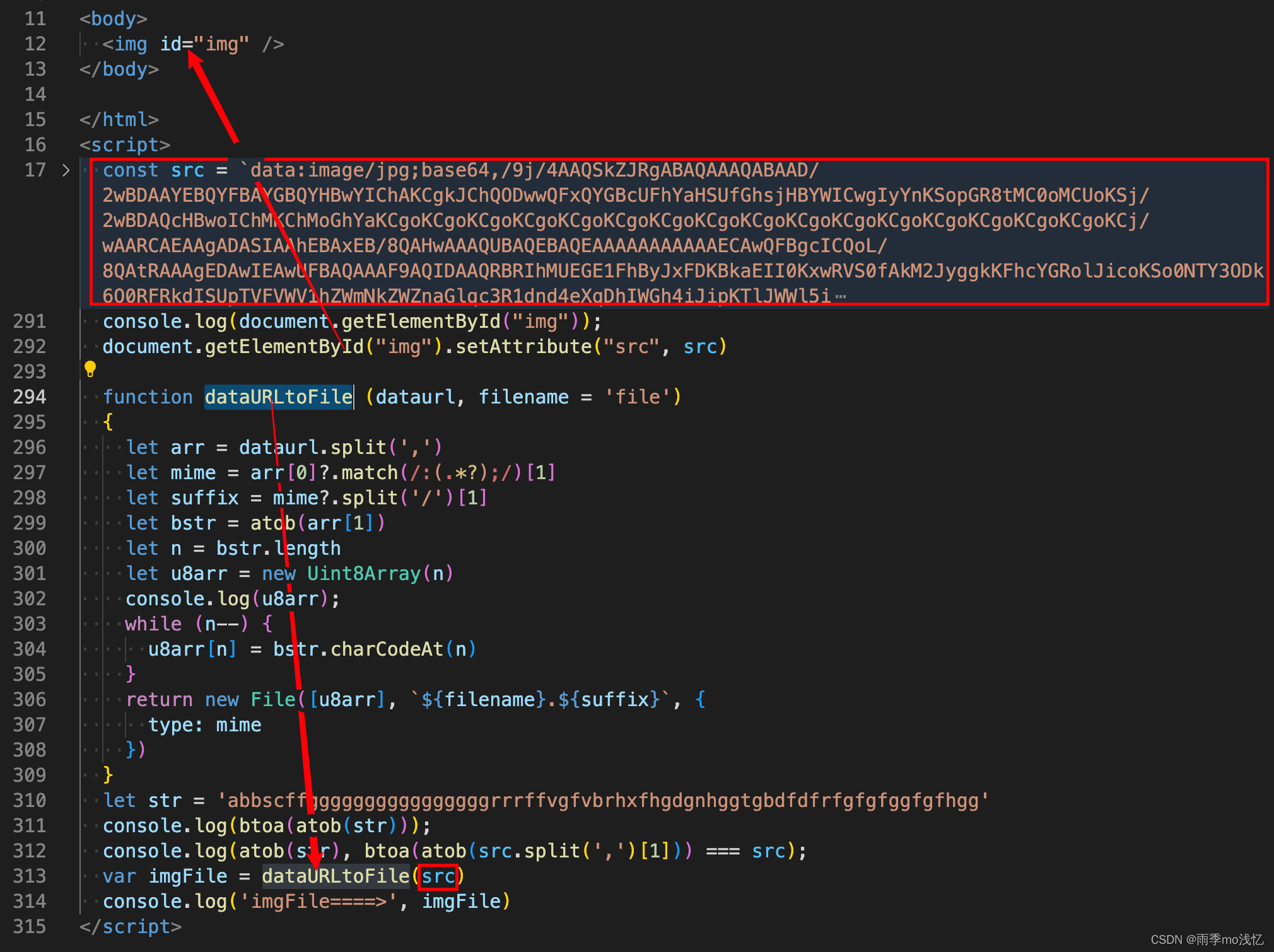
JS判断是否为base64字符串如何转换为图片src格式
需求背景 : 如何判断后端给返回的 字符串 是否为 base-64 位 呢 ? 以及如果判断为是的话,如何给它进行转换为 img 标签可使用的那种 src 格式 呢 ? 1、判断字符串是否为 base64 以下方法,可自行挨个试试,…...

【SpringMVC】SpringMVC方式,向作用域对象共享数据(ModelAndView、Model、map、ModelMap)
个人简介:Java领域新星创作者;阿里云技术博主、星级博主、专家博主;正在Java学习的路上摸爬滚打,记录学习的过程~ 个人主页:.29.的博客 学习社区:进去逛一逛~ 向域对象共享数据一、使用 原生ServletAPI二、…...
】实验3 - Activity及数据存储)
本科课程【移动互联网应用开发(Android开发)】实验3 - Activity及数据存储
大家好,我是【1+1=王】, 热爱java的计算机(人工智能)渣硕研究生在读。 如果你也对java、人工智能等技术感兴趣,欢迎关注,抱团交流进大厂!!! Good better best, never let it rest, until good is better, and better best. 近期会把自己本科阶段的一些课程设计、实验报…...

为何在 node 项目中使用固定版本号,而不使用 ~、^?
以语雀 文档为准 使用 ~、^ 时吃过亏希望版本号掌握在自己手里,作者自己升级(跟随官方进行升级,就算麻烦作者,也不想麻烦使用者)虽然 pnpm 很好用,但是不希望在项目中用到(临时性解决问题可以选…...
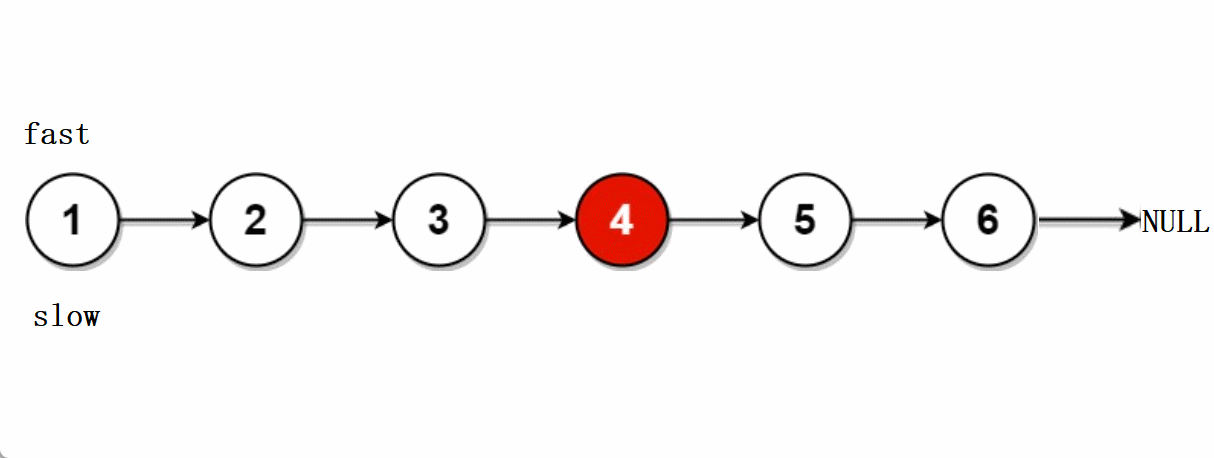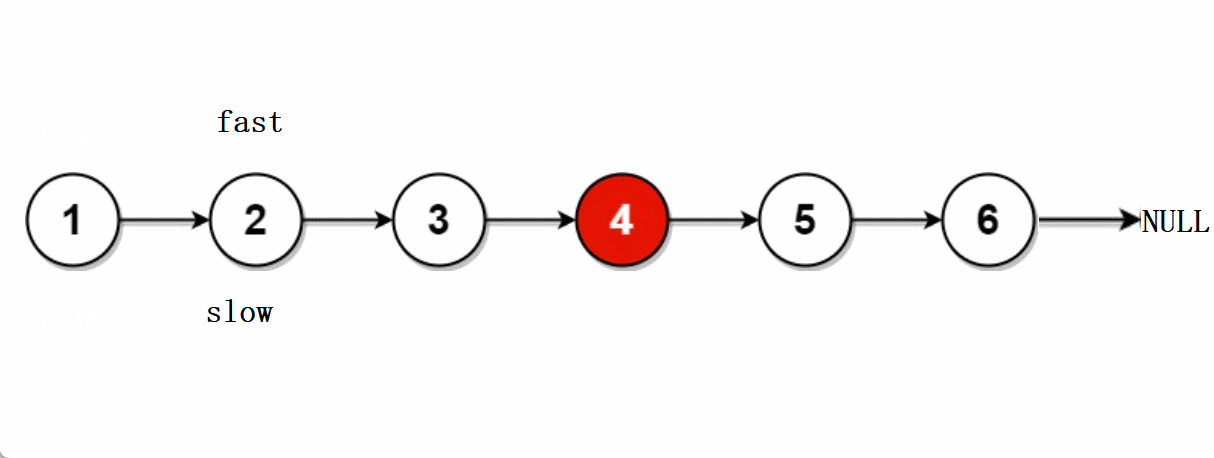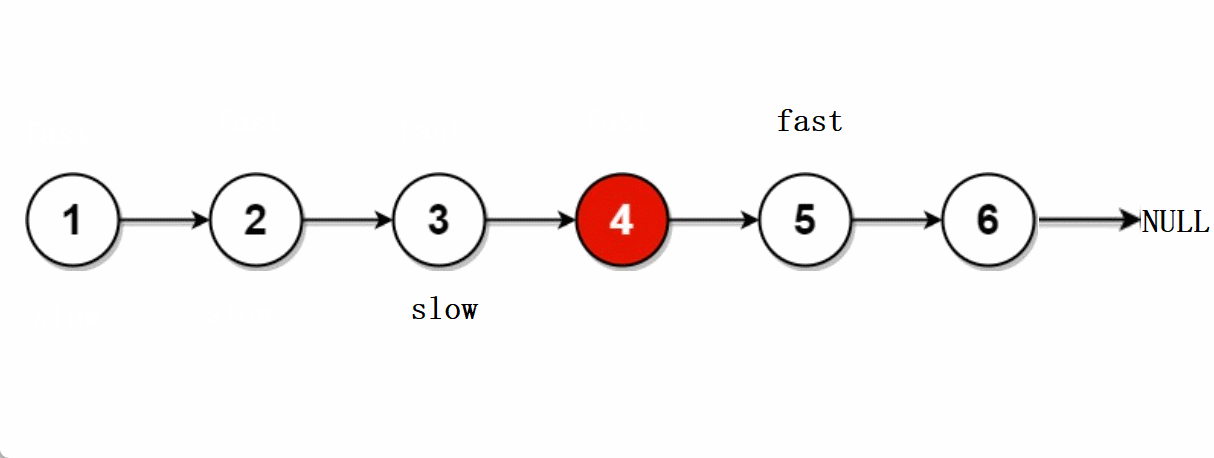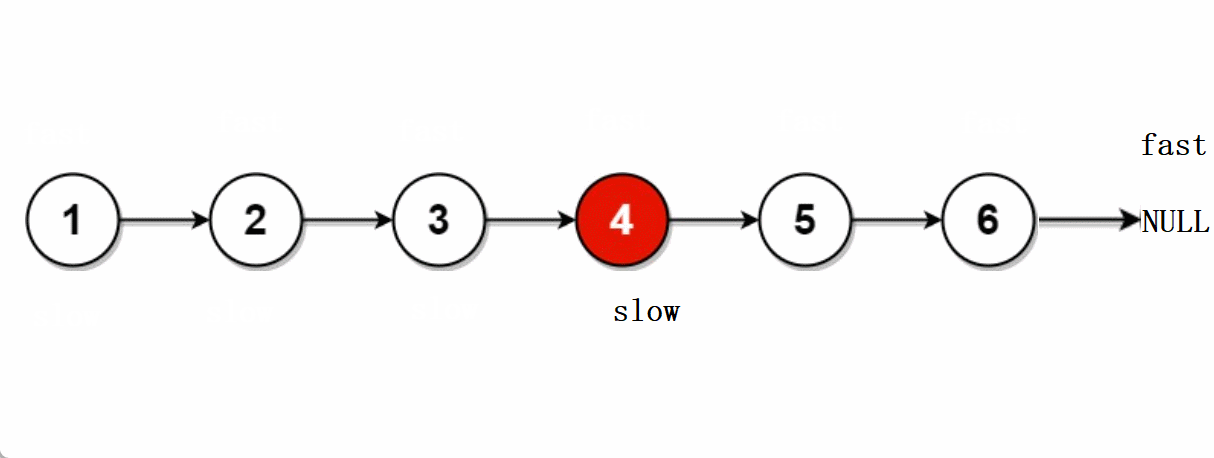
leetcode -- 876.链表的中间节点
文章目录🐨1.题目🐇2. 解法1-两次遍历🍀2.1 思路🍀2.2 代码实现🐁3. 解法2-快慢指针🌾3.1 思路🌾3.2 **代码实现**🐮4. 题目链接🐨1.题目 给你单链表的头结点head&#…...

企业网络安全防御策略需要考虑哪些方面?
随着企业数字化转型的加速,企业网络安全面临越来越多的威胁。企业网络安全不仅仅关乎企业数据的安全,还关系到企业的声誉和利益,因此,建立全面的网络安全防御策略至关重要。 企业网络安全防御策略的实现需要考虑以下几个方面&…...
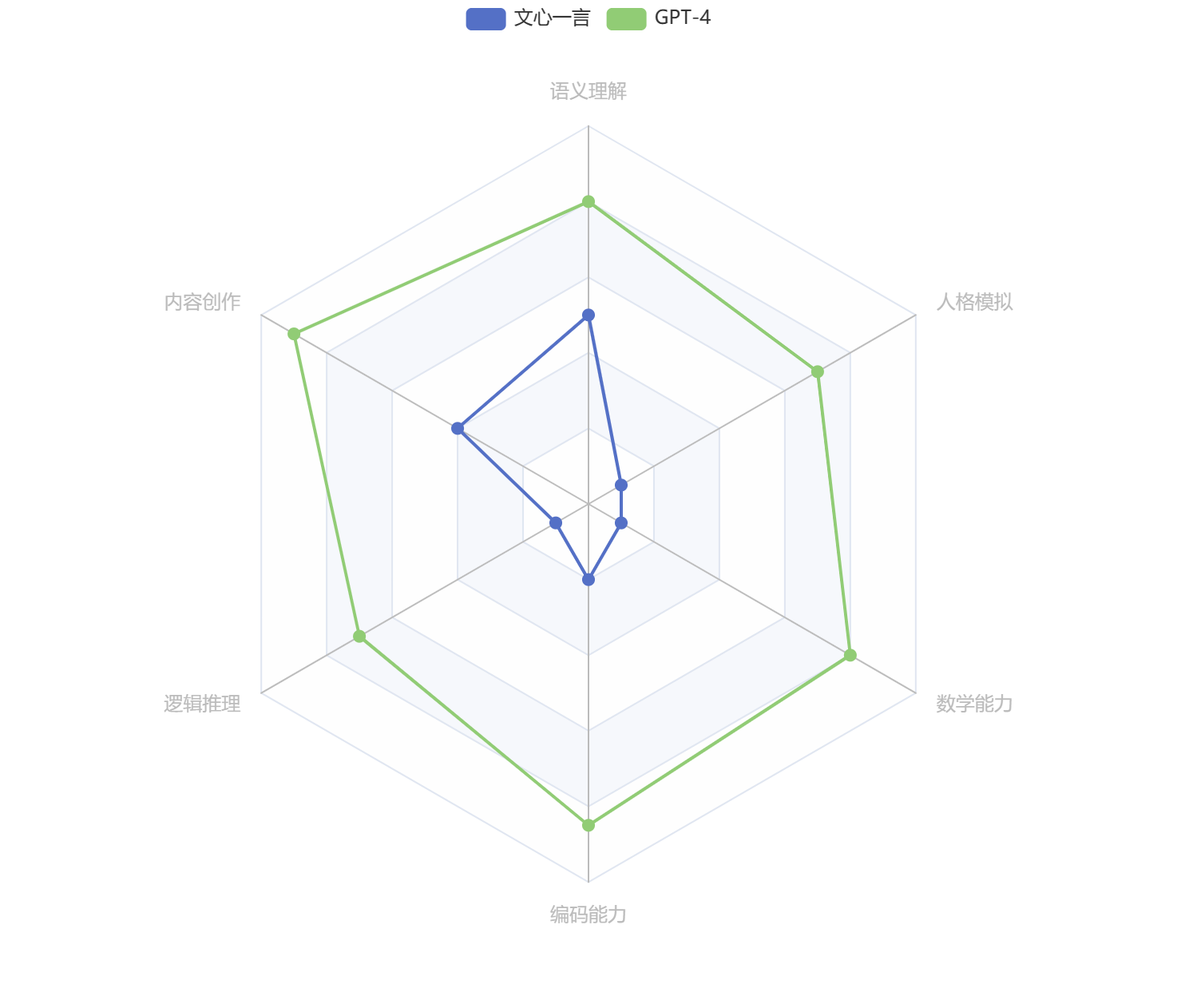
文心一言 vs. GPT-4 —— 全面横向比较
文心一言 vs. GPT-4 —— 全面横向比较 3月15日凌晨,OpenAI发布“迄今为止功能最强大的模型”——GPT-4。我第一时间为大家奉上了体验报告《OpenAI 发布GPT-4——全网抢先体验》。 时隔一日,3月16日下午百度发布大语言模型——文心一言。发布会上&…...
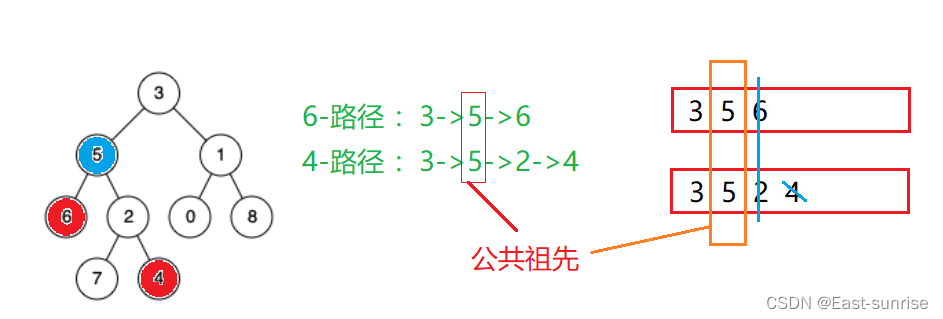
【进阶数据结构】二叉搜索树经典习题讲解
🌈感谢阅读East-sunrise学习分享——[进阶数据结构]二叉搜索树 博主水平有限,如有差错,欢迎斧正🙏感谢有你 码字不易,若有收获,期待你的点赞关注💙我们一起进步 🌈我们在之前已经学习…...
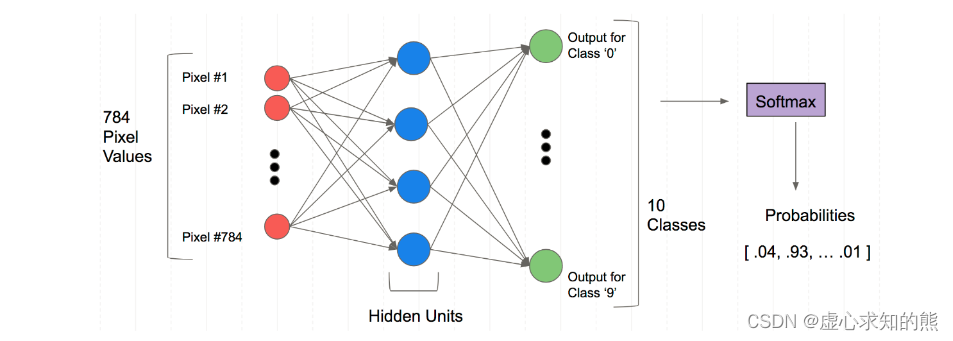
PyTorch 之 神经网络 Mnist 分类任务
文章目录一、Mnist 分类任务简介二、Mnist 数据集的读取三、 Mnist 分类任务实现1. 标签和简单网络架构2. 具体代码实现四、使用 TensorDataset 和 DataLoader 简化本文参加新星计划人工智能(Pytorch)赛道:https://bbs.csdn.net/topics/613989052 一、Mnist 分类任…...

如何实现用pillow库来实现给图片加滤镜?
使用Pillow库可以非常容易地给图片加滤镜。Pillow库是Python图像处理的一个强大库,提供了多种滤镜效果,如模糊、边缘检测、色彩增强等。 下面是使用Pillow库实现给图片加滤镜的简单步骤: 安装Pillow库:首先需要安装Pillow库。可…...
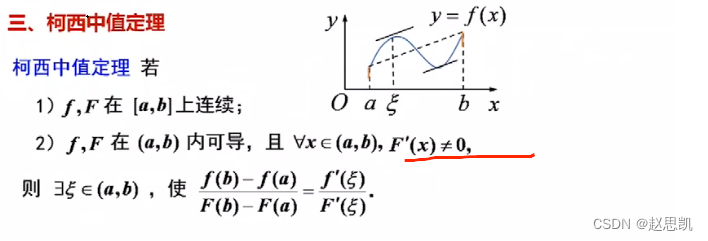
微分中值定理
极值 目录 极值 费马引理 编辑 罗尔定理 拉格朗日中值定理 例题: 例2 例3 两个重要结论: 编辑 柯西中值定理: 如何用自己的语言理解极值呢? 极大值和极小值的类似,我们不再进行说明 极值点有什么特点吗&…...

redis 存储一个map 怎么让map中其中一个值设置过期时间,而不是过期掉整个map?
文章目录 redis 存储一个map 怎么让map中其中一个值设置过期时间,而不是过期掉整个map?Java 中 怎么 实现?方案一: Jedis方案二: Lettuce方案三: Redisson方案四: Jedisson方案五: RedisTemplate那种方式 效率最高 ?拓展:结语redis 存储一个map 怎么让map中其中一个值设置过…...

LeetCode:704. 二分查找
🍎道阻且长,行则将至。🍓 🌻算法,不如说它是一种思考方式🍀算法专栏: 👉🏻123 一、🌱704. 二分查找 题目描述:给定一个 n 个元素有序的ÿ…...
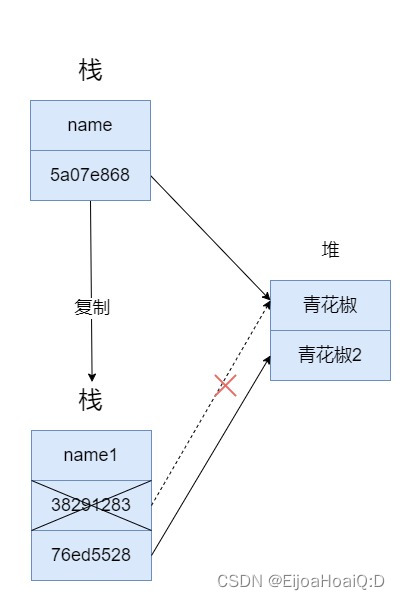
Java 到底是值传递还是引用传递?
C 语言是很多变成语言的母胎,包括 Java。对于 C 语言来说,所有的方法参数都是通过 “值” 传递的,也就是说,传递给被调用方法的参数值存放在临时变量中,而不是存放在原来的变量中。这就意味着,被调用的方法…...
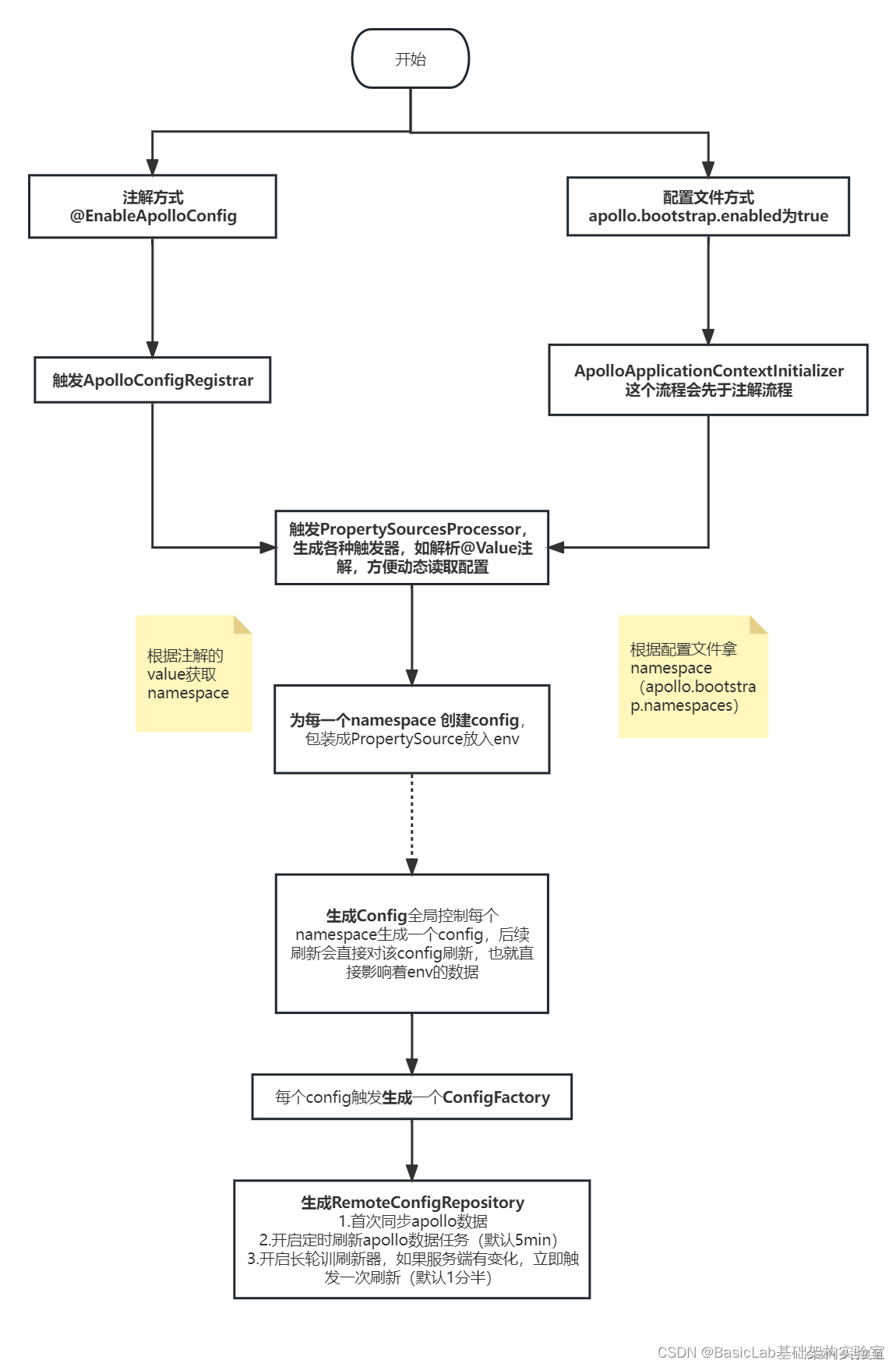
Apollo 配置变更原理
我们经常用到apollo的两个特性:1.动态更新配置:apollo可以动态更新Value的值,也可以修改environment的值。2.实时监听配置:实现apollo的监听器ConfigChangeListener,通过onChange方法来实时监听配置变化。你知道apollo…...
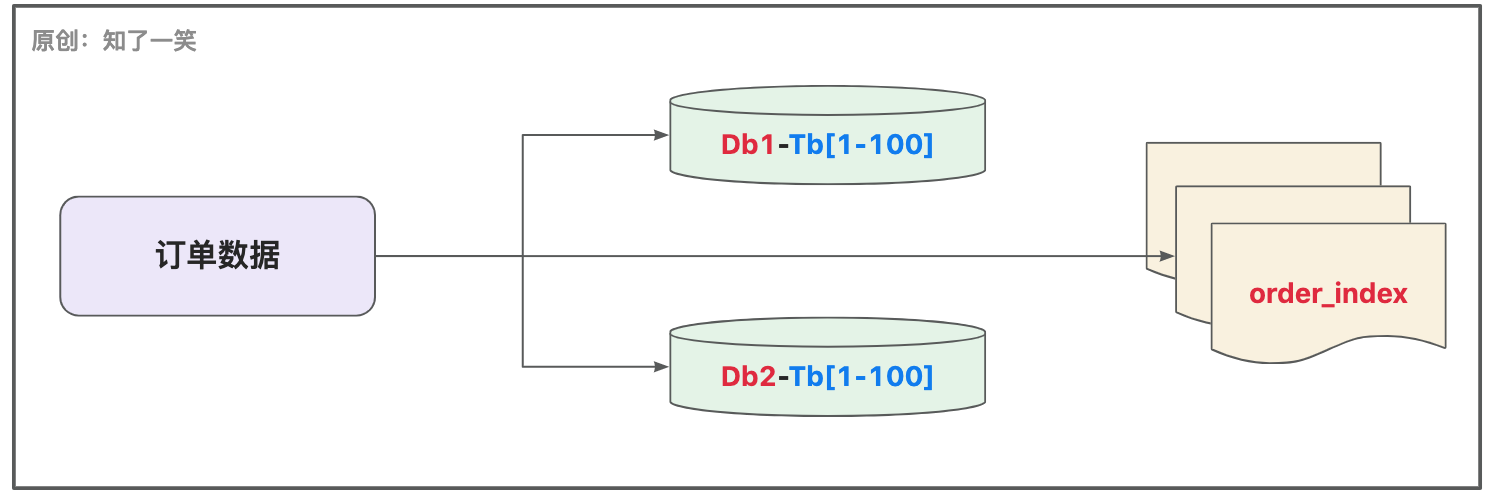
聊聊「订单」业务的设计与实现
订单,业务的核心模块; 一、背景简介 订单业务一直都是系统研发中的核心模块,订单的产生过程,与系统中的很多模块都会高度关联,比如账户体系、支付中心、运营管理等,即便单看订单本身,也足够的复…...

血细胞智能检测与计数软件(Python+YOLOv5深度学习模型+清新界面版)
摘要:血细胞智能检测与计数软件应用深度学习技术智能检测血细胞图像中红细胞、镰状细胞等不同形态细胞并可视化计数,以辅助医学细胞检测。本文详细介绍血细胞智能检测与计数软件,在介绍算法原理的同时,给出Python的实现代码以及Py…...

C++学习笔记——初始化列表、创建和实例化对象、new 关键字、隐式构造与 explicit 关键字、运算符与运算符重载
目录 1. 初始化列表 1.1 基本语法 1.2 为什么使用初始化列表? 1.3 初始化顺序 2. 创建和实例化对象 2.1 栈上分配(自动存储期) 2.2 堆上分配(动态存储期) 2.3 栈 vs 堆:Cherno 的建议 3. new 关键…...

2026年3月Github开源项目精选Top10
📅统计周期:2026-02-28 ~ 2026-03-29 🌋数据来源:www.ffgithub.com 📚数据更新:2026-03-29 Top1. 666ghj/MiroFish 🔺 总星标数量:43670⭐🔺 周增长数量:63…...

[Python3高阶编程] - 横跨同步异步的利器: asgiref.sync
一、asgiref.sync 是什么?asgiref.sync 是 ASGI(Asynchronous Server Gateway Interface)参考实现库 asgiref 中的核心子模块,主要用于安全地桥接同步代码与异步代码。📌 一句话总结: 它让你在异步环境中调…...

OneDrive导致桌面图标变白的解决方案
OneDrive导致桌面图标变白的原因主要是由于OneDrive的同步功能或图标缓存损坏。当使用OneDrive的“释放空间”功能时,可能会导致图标变为空白页或默认图标。此外,图标缓存损坏也可能导致图标变白。解决方法:1. 调整OneDrive设置:在…...

OpenClaw多模态技能库:Qwen3.5-9B-AWQ-4bit实现10种图片处理场景
OpenClaw多模态技能库:Qwen3.5-9B-AWQ-4bit实现10种图片处理场景 1. 为什么需要多模态技能库? 去年我接手了一个个人项目,需要批量处理几百张产品照片。手动用PS抠图、调色、加文字,花了两周才完成。当时就想:如果能…...

OpenClaw学习助手方案:Qwen2.5-VL-7B解析教材插图生成记忆卡片
OpenClaw学习助手方案:Qwen2.5-VL-7B解析教材插图生成记忆卡片 1. 为什么需要AI辅助学习工具 去年备考专业认证时,我发现自己总在重复低效的学习循环——花大量时间手动整理教材图表中的关键数据,再誊写到Anki卡片上。这种机械劳动不仅耗时…...

2026年4月OpenClaw如何安装?腾讯云2分钟零基础教程及百炼APIKey配置方法
2026年4月OpenClaw如何安装?腾讯云2分钟零基础教程及百炼APIKey配置方法。OpenClaw(原Clawdbot)作为2026年主流的AI自动化助理平台,可通过阿里云轻量服务器实现724小时稳定运行,并快速接入钉钉,让AI在企业群…...

如何写 Skill
核心概念 Skill 是一个自包含的模块,用来给 Claude/Cascade 注入特定领域的知识、工作流和工具。本质上就是一个"新手入职指南",让通用 AI 变成某个领域的专家。 目录结构 skill-name/ ├── SKILL.md # 必须,核心文件 └…...

内网渗透全流程拆解|从入门到实战,小白也能看懂的步骤
内网渗透不是“盲目尝试”,而是遵循固定流程的系统化操作,核心流程可概括为:信息收集→漏洞利用→权限提升→横向移动→权限维持→痕迹清理,每个环节环环相扣,缺一不可。本文将结合小白易理解的实战场景,详…...

Vue2项目构建优化实战:时间戳防缓存与资源压缩的配置详解
1. 为什么Vue2项目需要构建优化 最近接手了一个老项目的维护工作,发现每次前端更新后总有用户反馈页面显示异常。排查后发现是浏览器缓存惹的祸——用户访问的仍然是旧版本的静态资源。这让我意识到构建优化的重要性,特别是对于需要频繁更新的业务系统。…...