数据结构--二叉树
目录
- 1.树概念及结构
- 1.1数的概念
- 1.2数的表示
- 2.二叉树概念及结构
- 2.1二叉树的概念
- 2.2数据结构中的二叉树
- 2.3特殊的二叉树
- 2.4二叉树的存储结构
- 2.4.1顺序存储
- 2.4.2链式存储
- 2.5二叉树的性质
- 3.堆的概念及结构
- 3.1堆的实现
- 3.1.1堆的创建
- 3.1.2堆的插入
- 3.1.3堆顶的删除
- 3.1.4堆的代码实现
- 3.1.5建堆时间复杂度
- 3.2堆的应用
- 3.2.1堆排序
- 3.2.2TOP-K问题
- 4.二叉树链式结构的实现
- 4.1二叉树的定义
- 4.2二叉树的遍历
- 4.2.1二叉树的前序递归遍历
- 4.2.2二叉树的中序递归遍历
- 4.2.3二叉树的后序递归遍历
- 4.2.4二叉树的层序遍历
- 4.3二叉树节点数
- 4.4二叉树叶子节点数
- 4.5二叉树第K层节点数
- 4.6二叉树查找值为X的节点
- 4.7二叉树的深度
- 4.8判断二叉树是否是完全二叉树
- 4.9二叉树完整代码
1.树概念及结构
1.1数的概念
数是一种非线性的数据结构,它是由n(n>=0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
- 根结点:根节点没有前驱结点。
- 除根节点外,其余结点被分成是一棵结构与树类似的子树。每棵子树的根结点有且只有一个前驱,可以有0个或多个后继。
- 因此,树是递归定义的。
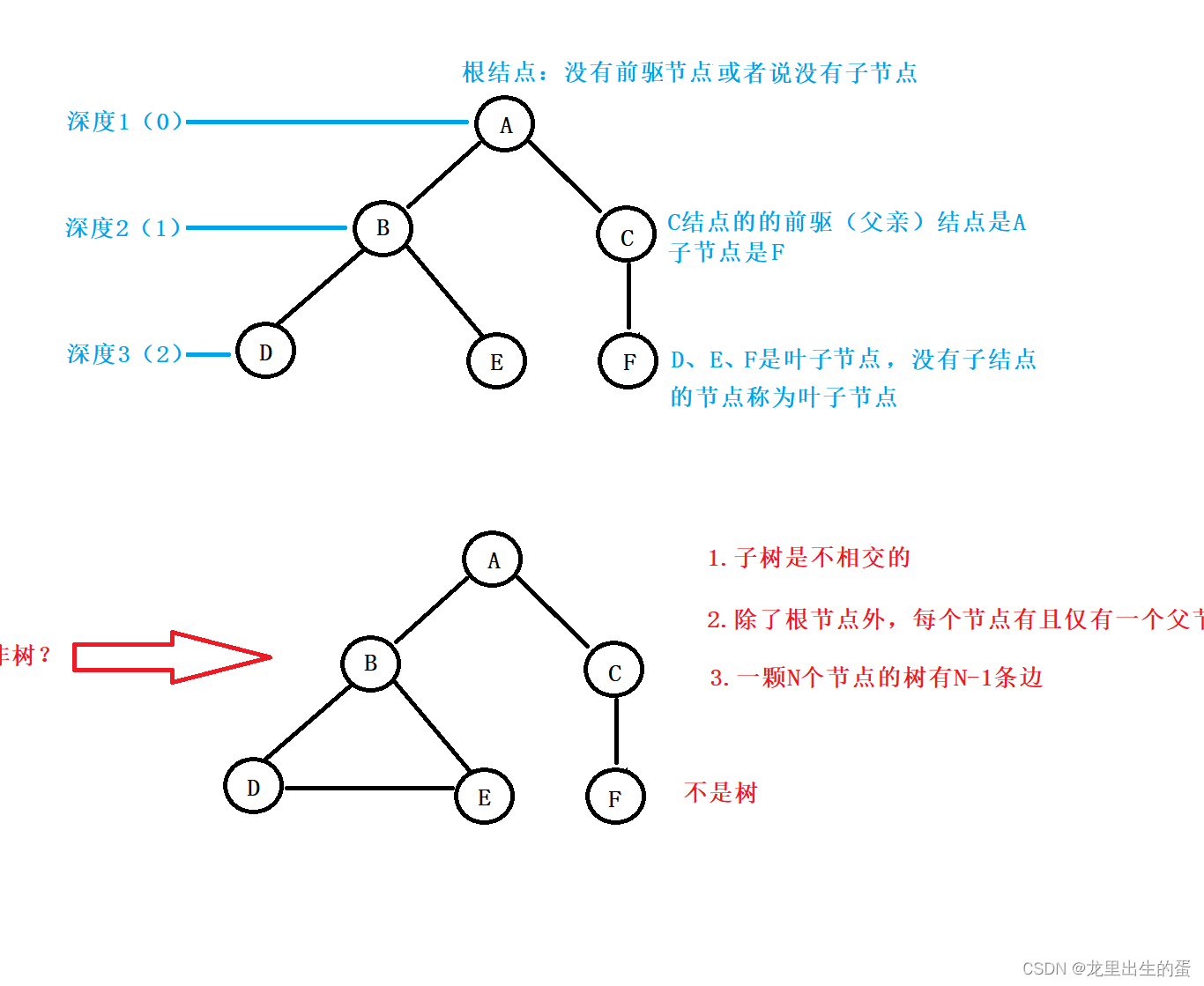
• 节点的度:一个节点含有的子树的个数称为该节点的度;如上图:A的为2
• 叶节点:度为0的节点称为叶子节点;如上图:D、E、F节点为叶子节点
• 非终端节点或分支节点:度不为0的节点; 如上图:B、C为分支节点
• 双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点; 如上图:A是B的父节点
• 孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点; 如上图:B是A的孩子节点
• 兄弟节点:具有相同父节点的节点互称为兄弟节点; 如上图:B、C是兄弟节点
• 树的度:一棵树中,最大的节点的度称为树的度;如上图:树的度为2
• 节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
• 树的高度或深度:树中节点的最大层次;如上图:树的高度为3
• 堂兄弟节点:双亲在同一层的节点互为堂兄弟;如上图:B、F互为堂兄弟节点
• 节点的祖先:从根到该节点所经分支上的所有节点;如上图:A是所有节点的祖先
• 以某节点为根的子树中任一节点都称为该节点的子孙。如上图:所有节点都是A的子孙
• 由m棵互不相交的树的集合称为森林
1.2数的表示
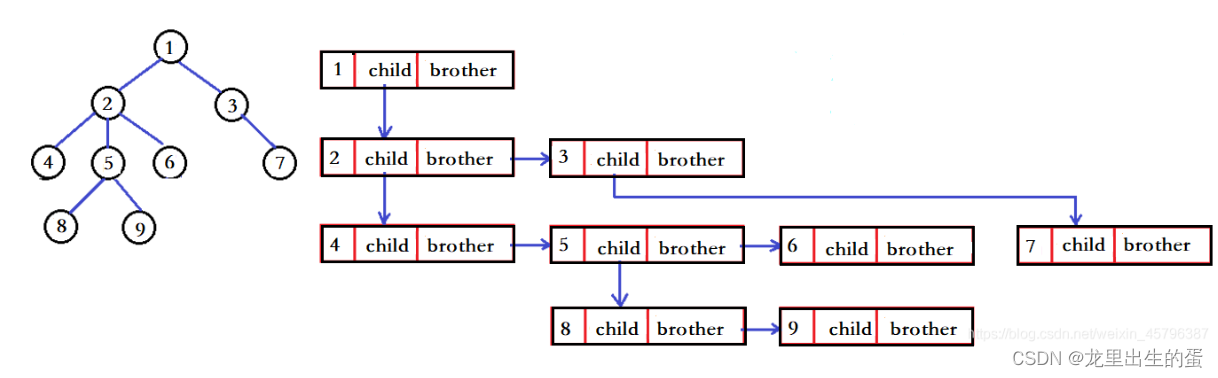
树结构相对线性表就比较复杂了,要存储表示起来就比较麻烦了,实际中树有很多种表示方式,如:双亲表示法,孩子表示法、孩子兄弟表示法等等。我们这里就简单的了解其中最常用的孩子兄弟表示法。
typedef int DataType;
struct Node
{struct Node* firstChild1; struct Node* pNextBrother; DataType data;
};
2.二叉树概念及结构
2.1二叉树的概念
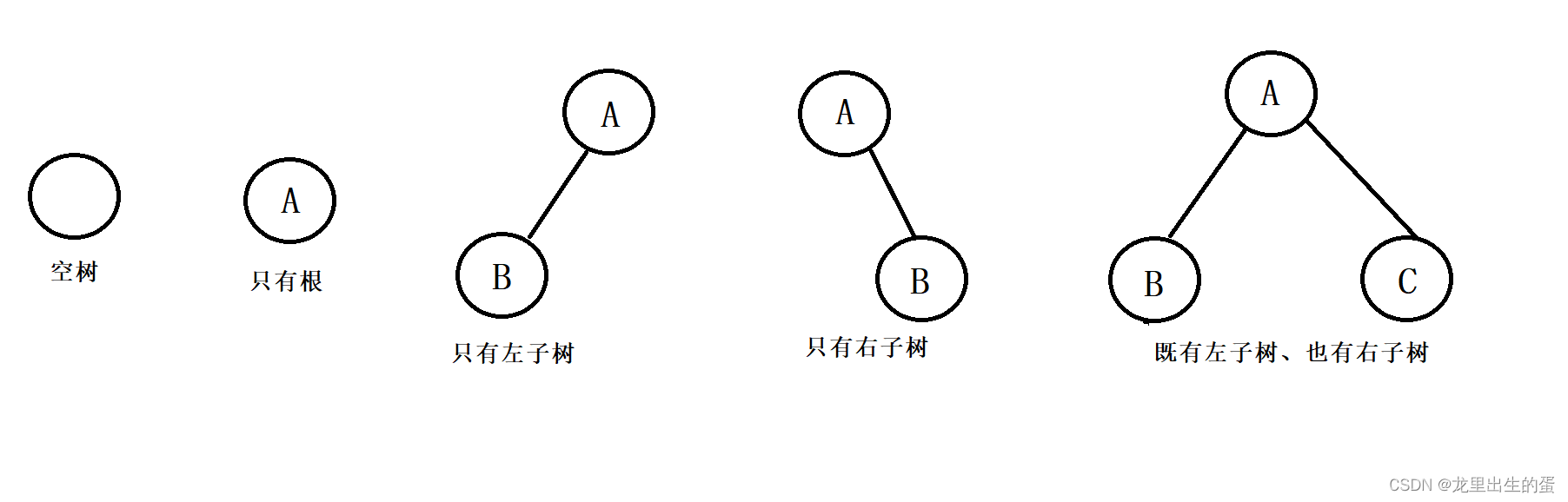
一棵二叉树是结点的一个有限集合,该集合或者为空,或者是由一个根节点加上两棵别称为左子树和右子树的二叉树组成。
二叉树的特点:
- 每个结点最多有两棵子树,即二叉树不存在度大于2的结点。
- 二叉树的子树有左右之分,其子树的次序不能颠倒。
2.2数据结构中的二叉树
2.3特殊的二叉树
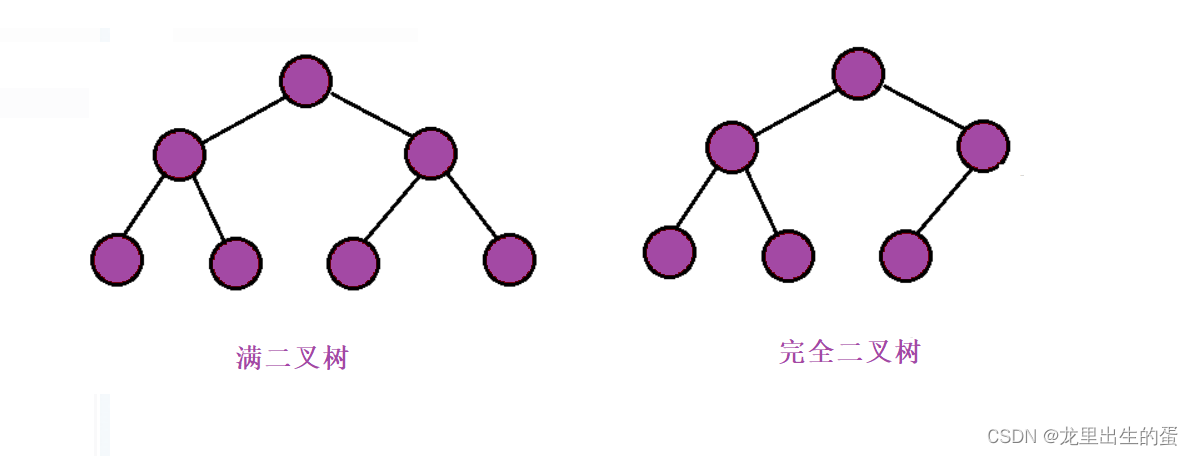
- 满二叉树:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。### 3.2.1堆排序也就是说,如果一个二叉树的层数为K,且结点总数是(2^k) -1 ,则它就是满二叉树。
- 完全二叉树:完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的。对于深度为K的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对应时称之为完全二叉树。 要注意的是满二叉树是一种特殊的完全二叉树。
2.4二叉树的存储结构
二叉树一般可以使用两种存储结构,一种顺序结构,一种链式结构。
2.4.1顺序存储
顺序结构存储就是使用数组来存储,一般使用数组只适合表示完全二叉树,因为不是完全二叉树会有空间的浪费。而现实中使用中只有堆才会使用数组来存储。二叉树顺序存储在物理上是一个数组,在逻辑上是一颗二叉树。
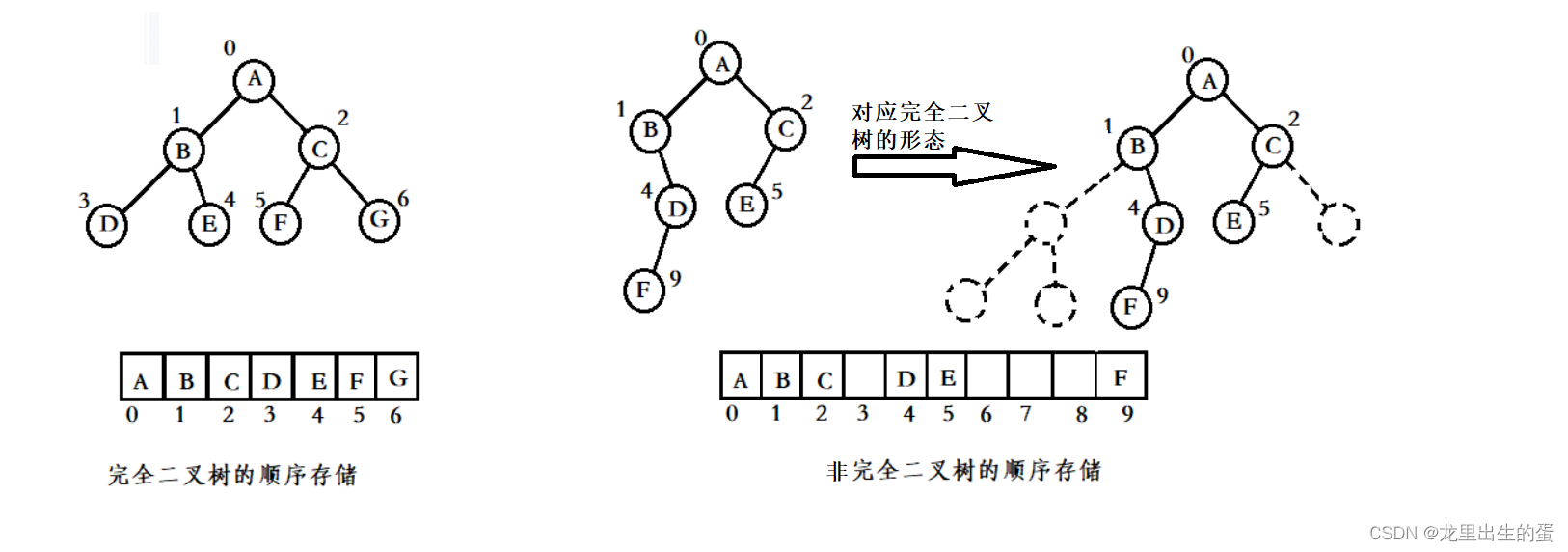
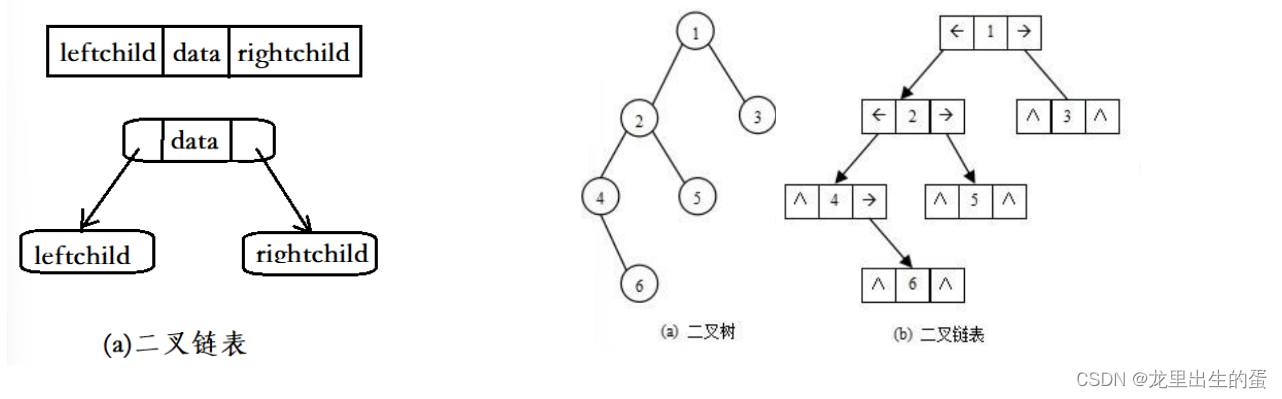
2.4.2链式存储
二叉树的链式存储结构是指,用链表来表示一棵二叉树,即用链来指示元素的逻辑关系。 通常的方法是链表中每个结点由三个域组成,数据域和左右指针域,左右指针分别用来给出该结点左孩子和右孩子所在的链结点的存储地址 。链式结构又分为二叉链和三叉链,当前介绍的是二叉链,后面课程学到高阶数据结构如红黑树等会用到三叉链。
// 二叉链struct BinaryTreeNode{struct BinTreeNode* _pLeft; // 指向当前节点左孩子struct BinTreeNode* _pRight; // 指向当前节点右孩子BTDataType _data; // 当前节点值域};
2.5二叉树的性质
- 若规定根节点的层数为1,则一棵非空二叉树的第i层上最多有2^(i-1) 个结点.
- 若规定根节点的层数为1,则深度为h的二叉树的最大结点数是2^h- 1.
- 对任何一棵二叉树, 如果度为0其叶结点个数为 n0, 度为2的分支结点个数为 n2,则有n0=n2+1
- 若规定根节点的层数为1,具有n个结点的满二叉树的深度,h=Log2(n+1). (ps:Log2(n+1)是log以2为底,n+1为对数)
- 对于具有n个结点的完全二叉树,如果按照从上至下从左至右的数组顺序对所有节点从0开始编号,则对于序号为i的结点有:
- 若i>0,i位置节点的双亲序号:(i-1)/2;i=0,i为根节点编号,无双亲节点
- 若2i+1<n,左孩子序号:2i+1,2i+1>=n否则无左孩子
- 若2i+2<n,右孩子序号:2i+2,2i+2>=n否则无右孩子
3.堆的概念及结构
在上面2.4.1中提到了堆,那么什么是堆呢?
堆从分类来分,分为大堆和小堆。从性质来看,堆其实是一个特别的完全二叉树,这个特别的完全二叉树中所有的父亲节点的值要么都大于等于子节点值(大堆),要么小于等于子节点值(小堆)。

堆的性质:
1.堆中某个节点的值总是不大于或不小于其父节点的值;
2.堆总是一棵完全二叉树。
3.1堆的实现
3.1.1堆的创建
首先先定义一个堆
.h文件
#include<assert.h>
#include<stdbool.h>
#include<time.h>
typedef int HeapDateType;
typedef struct Heap
{HeapDateType* arr;int size;int capacity;
}HP;
//初始化
void HeapInit(HP* hp);
//销毁
void HeapDestory(HP* hp);
.c文件
#include"Heap.h"
//初始化
void HeapInit(HP* hp)
{hp->arr = NULL;hp->capacity = hp->size = 0;
}
//销毁
void HeapDestory(HP* hp)
{assert(hp);free(hp->arr);hp->capacity = hp->size = 0;
}
3.1.2堆的插入
堆的插入思路:
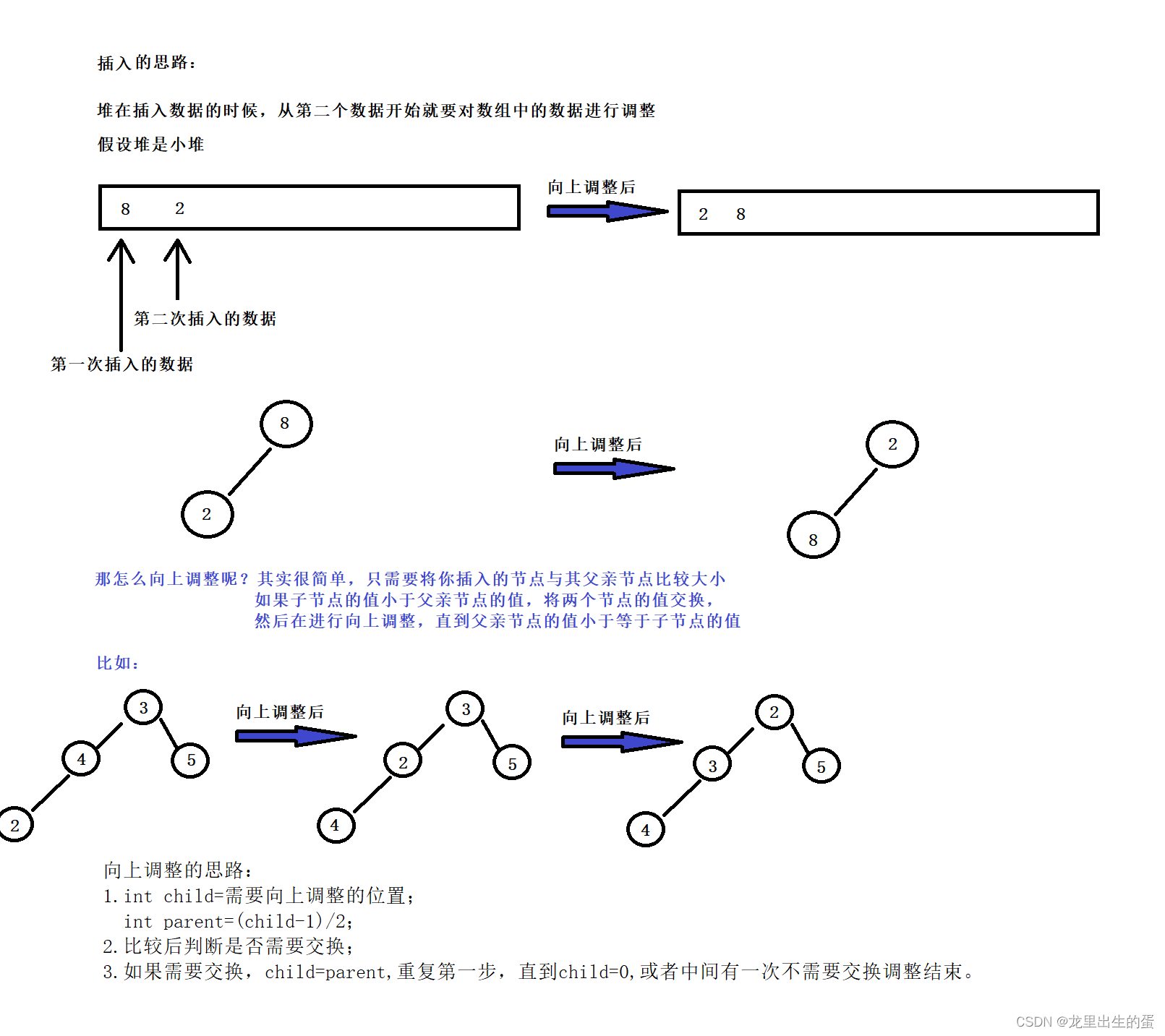
堆的插入代码:
.h文件
//插入数据
void HeapPush(HP* hp, HeapDateType x);
//向上调整
void AjustUp(HeapDateType* arr, int child);
.c文件
//向上调整
void AjustUp(HeapDateType* arr, int child)
{assert(arr);int parent = (child - 1) / 2;while (child > 0){//大于号是大堆,小于号是小堆if (arr[child] > arr[parent]){Swap(&arr[parent], &arr[child]);child = parent;parent = (child - 1) / 2;}else{break;}}
}//插入数据
void HeapPush(HP* hp, HeapDateType x)
{//检查一下是否需要扩容if (hp->capacity == hp->size){hp->capacity = hp->capacity == 0 ? 4 : hp->capacity * 2;}HeapDateType* ptr = (HeapDateType*)realloc(hp->arr, hp->capacity * sizeof(HeapDateType));if (ptr == NULL){perror("HeapPushBack::realloc");}hp->arr = ptr;hp->arr[hp->size++] = x;AjustUp(hp->arr, hp->size - 1);
}
3.1.3堆顶的删除
堆顶的删除思路:
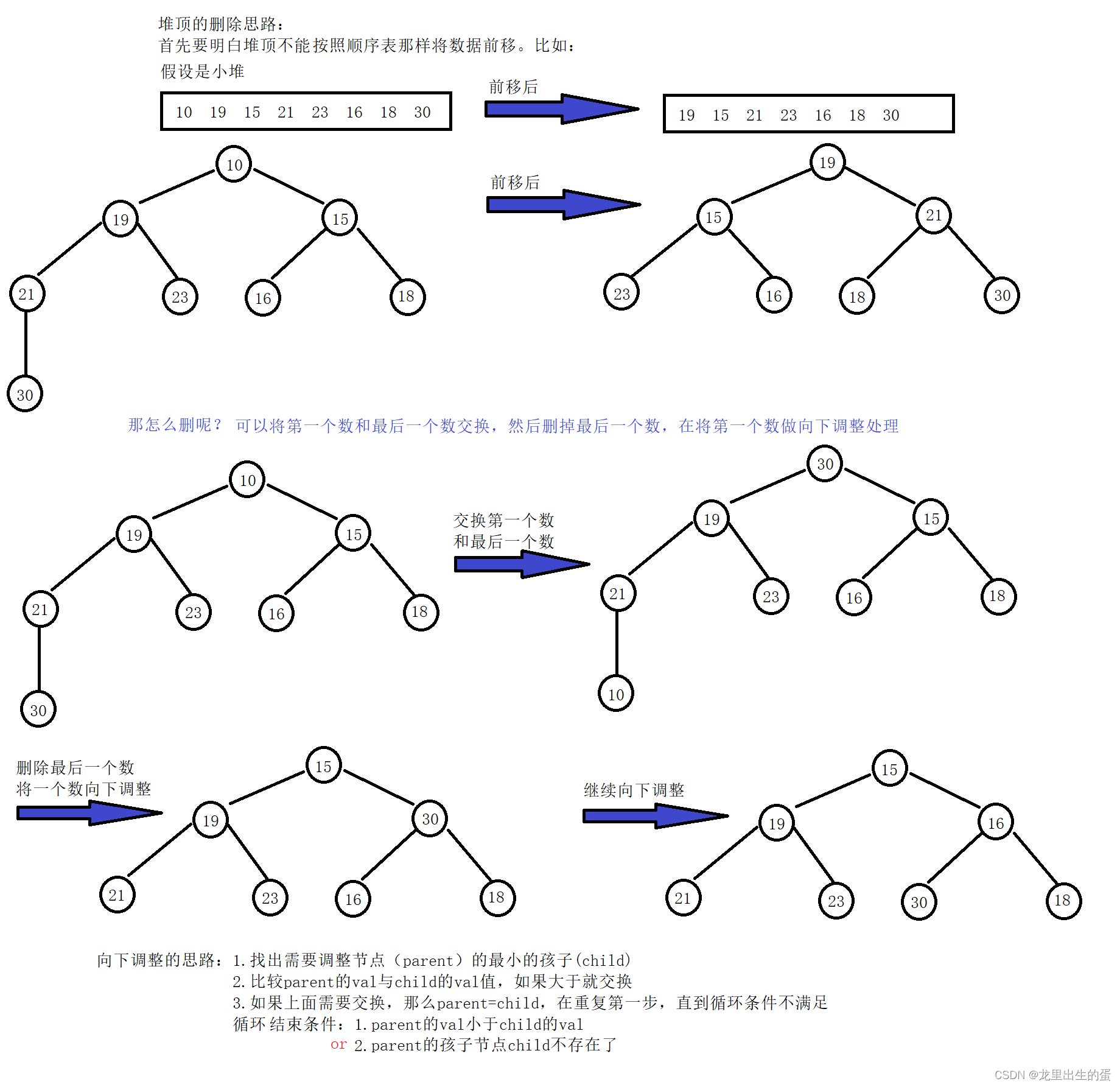
堆顶删除的代码:
.h文件
//删除堆顶数据
void HeapPop(HP* hp);
//向下调整
void AjustDown(HeapDateType* arr, int len, int parent);
.c文件
//向下调整
void AjustDown(HeapDateType* arr, int len, int parent)
{assert(arr);int child = parent * 2 + 1;while (child < len){//大于号是大堆,小于号是小堆if (child + 1 < len && arr[child + 1] > arr[child]){child++;}//大于号是大堆,小于号是小堆if (arr[child] > arr[parent]){Swap(&arr[parent], &arr[child]);parent = child;child = parent * 2 + 1;}else{break;}}
}//删除堆顶数据
void HeapPop(HP* hp)
{assert(hp);assert(!HeapIsEmpty(hp));//交换Swap(&hp->arr[0], &hp->arr[hp->size - 1]);hp->size--;//向下调整AjustDown(hp->arr, hp->size, 0);}
3.1.4堆的代码实现
.h文件
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>
#include<time.h>
typedef int HeapDateType;
typedef struct Heap
{HeapDateType* arr;int size;int capacity;
}HP;
//初始化
void HeapInit(HP* hp);
//销毁
void HeapDestory(HP* hp);
//插入数据
void HeapPush(HP* hp, HeapDateType x);
//删除堆顶数据
void HeapPop(HP* hp);
//打印
void HeapPrint(HP* hp);
//向上调整
void AjustUp(HeapDateType* arr, int child);
//向下调整
void AjustDown(HeapDateType* arr, int len, int parent);
//断空
bool HeapIsEmpty(HP* hp);
//堆大小
int HeapSize(HP* hp);
//堆顶
HeapDateType HeapTop(HP* hp);
//交换
void Swap(HeapDateType* px, HeapDateType* py);
.c文件
#include"Heap.h"
//交换
void Swap(HeapDateType* px, HeapDateType* py)
{HeapDateType tmp = *px;*px = *py;*py = tmp;
}//初始化
void HeapInit(HP* hp)
{hp->arr = NULL;hp->capacity = hp->size = 0;
}//销毁
void HeapDestory(HP* hp)
{assert(hp);free(hp->arr);hp->capacity = hp->size = 0;
}//向上调整
void AjustUp(HeapDateType* arr, int child)
{assert(arr);int parent = (child - 1) / 2;while (child > 0){//大于号是大堆,小于号是小堆if (arr[child] > arr[parent]){Swap(&arr[parent], &arr[child]);child = parent;parent = (child - 1) / 2;}else{break;}}
}//向下调整
void AjustDown(HeapDateType* arr, int len, int parent)
{assert(arr);int child = parent * 2 + 1;while (child < len){//大于号是大堆,小于号是小堆if (child + 1 < len && arr[child + 1] > arr[child]){child++;}//大于号是大堆,小于号是小堆if (arr[child] > arr[parent]){Swap(&arr[parent], &arr[child]);parent = child;child = parent * 2 + 1;}else{break;}}}//插入数据
void HeapPush(HP* hp, HeapDateType x)
{//检查一下是否需要扩容if (hp->capacity == hp->size){hp->capacity = hp->capacity == 0 ? 4 : hp->capacity * 2;}HeapDateType* ptr = (HeapDateType*)realloc(hp->arr, hp->capacity * sizeof(HeapDateType));if (ptr == NULL){perror("HeapPushBack::realloc");}hp->arr = ptr;hp->arr[hp->size++] = x;AjustUp(hp->arr, hp->size - 1);}//删除堆顶数据
void HeapPop(HP* hp)
{assert(hp);assert(!HeapIsEmpty(hp));//交换Swap(&hp->arr[0], &hp->arr[hp->size - 1]);hp->size--;//向下调整AjustDown(hp->arr, hp->size, 0);}//断空
bool HeapIsEmpty(HP* hp)
{return hp->size == 0;
}//堆大小
int HeapSize(HP* hp)
{return hp->size;
}//堆顶
HeapDateType HeapTop(HP* hp)
{assert(!HeapIsEmpty(hp));return hp->arr[0];
}//打印
void HeapPrint(HP* hp)
{for (int i = 0; i < hp->size; i++){printf("%d ", hp->arr[i]);}printf("\n");
}
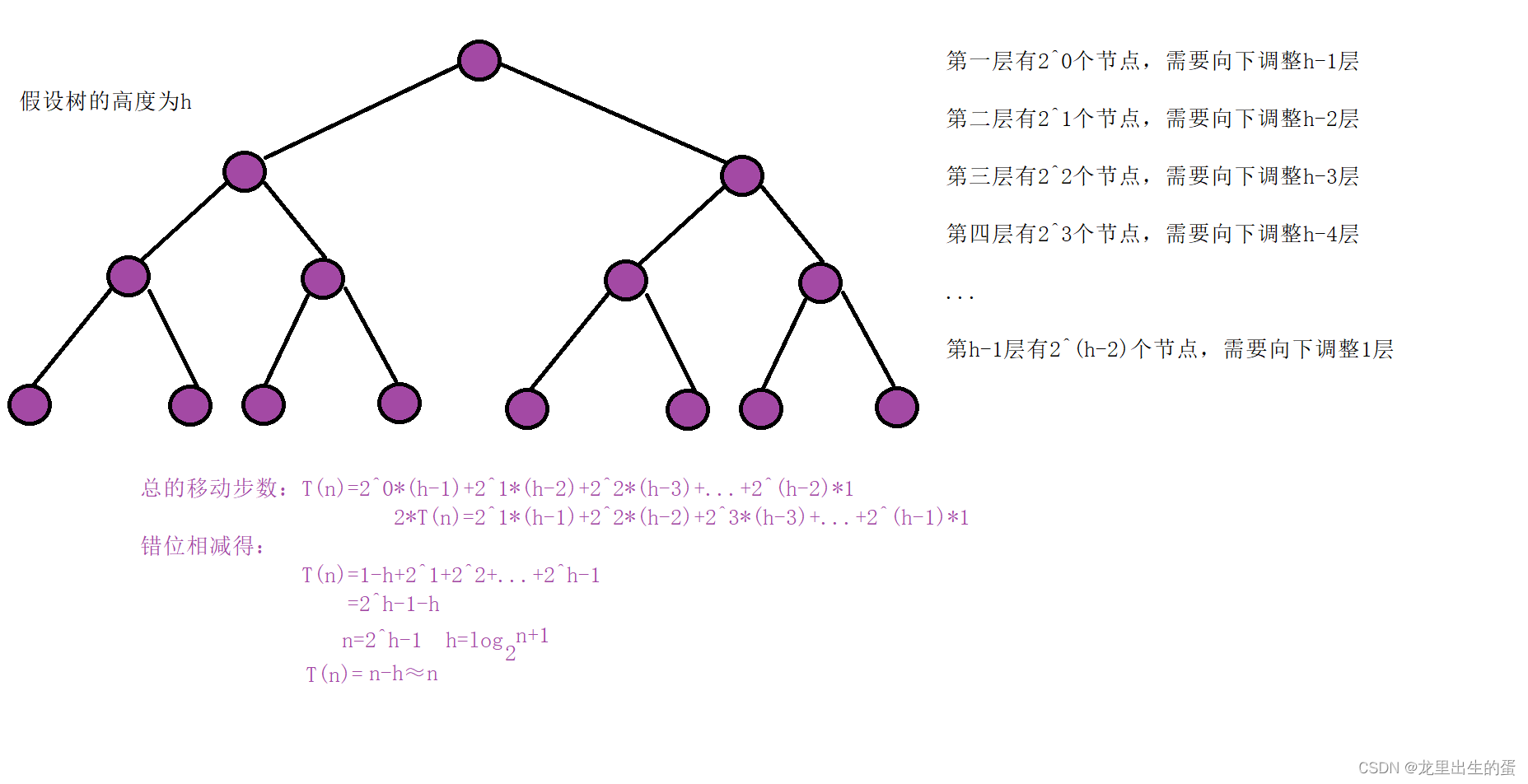
3.1.5建堆时间复杂度
说到时间复杂度,就要考虑到最坏情况。那么假设完全二叉树的每一个节点都需要调整需要多少时间复杂度呢?
因为堆是完全二叉树,而满二叉树也是完全二叉树,此处为了简化使用满二叉树来证明(时间复杂度本来看的就是近似值,多几个节点不影响最终结果):
3.2堆的应用
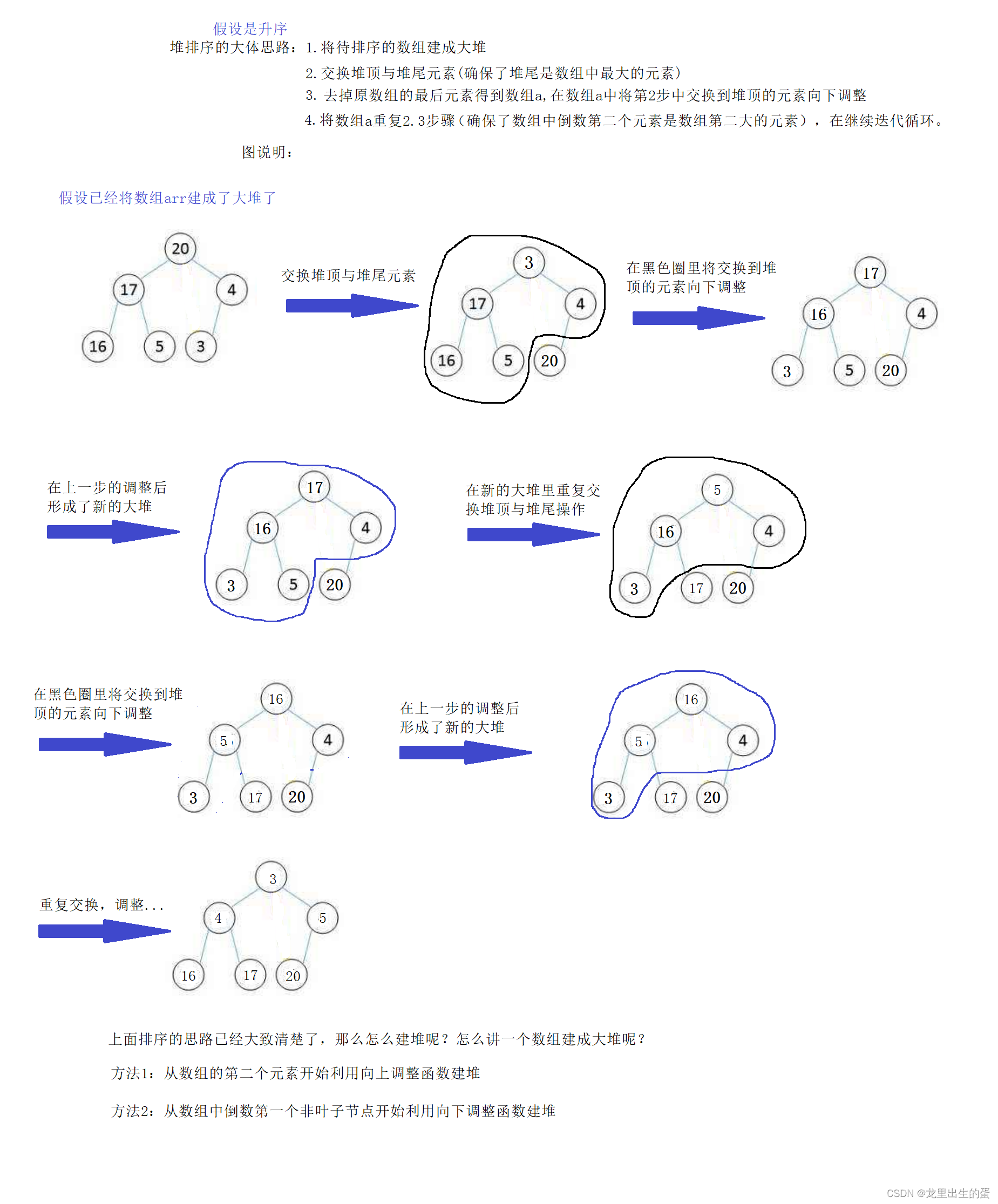
3.2.1堆排序
堆排序的思路:
建堆代码(方法1):
//构建大堆
//方法1
for (int i = 1; i < n; i++)
{AjustUp(a, i);
}
建堆代码(方法2):
//方法2
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{AjustDown(a, n, i);
}
堆排序代码:
void HeapSort(int* a, int n)
{assert(a);//构建大堆//方法1//for (int i = 1; i < n; i++)//{// AjustUp(a, i);//} //方法2for (int i = (n - 1 - 1) / 2; i >= 0; i--){AjustDown(a, n, i);}for (int end = n - 1; end > 0; end--){Swap(&a[end], &a[0]);AjustDown(a, end, 0);}
}
3.2.2TOP-K问题
TOP-K问题:即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。
对于Top-K问题,能想到的最简单直接的方式就是排序,但是:如果数据量非常大,排序就不太可取了(可能数据都不能一下子全部加载到内存中)。最佳的方式就是用堆来解决,基本思路如下:
- 用数据集合中前K个元素来建堆
·前k个最大的元素,则建小堆
·前k个最小的元素,则建大堆 - 用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素
TOP-K代码:
//在n个数中找出最大的前K个
void PrintTopK(int* arr, int n, int k)
{HP hp;HeapInit(&hp);//先建立一个小堆for (int i = 0; i < k; i++){HeapPush(&hp, arr[i]);}for (int i = k; i < n; i++){if (arr[i] > hp.arr[0]){HeapPop(&hp);HeapPush(&hp, arr[i]);}}for (int i = 0; i < k; i++){printf("%d ", hp.arr[i]);}printf("\n");
}void test02()
{int arr[10000] = { 0 };for (int i = 0; i < 10000; i++){int t = rand() % 10000;arr[i] = t;}arr[131] = 10001;arr[141] = 10002;arr[151] = 10003;arr[161] = 10004;arr[171] = 10005;arr[181] = 10006;arr[191] = 10007;arr[1311] = 10008;arr[885] = 10009;arr[240] = 10010;PrintTopK(arr, 10000, 10);
}
4.二叉树链式结构的实现
4.1二叉树的定义
typedef char BTDataType;
typedef struct BinaryTree
{struct BinaryTree* left;struct BinaryTree* right;BTDataType val;
}BTNode;
4.2二叉树的遍历
4.2.1二叉树的前序递归遍历
前序遍历可以想象为,一个小人从一棵二叉树根节点为起点,沿着二叉树外沿,逆时针走一圈回到根节点,路上遇到的元素顺序,就是先序遍历的结果
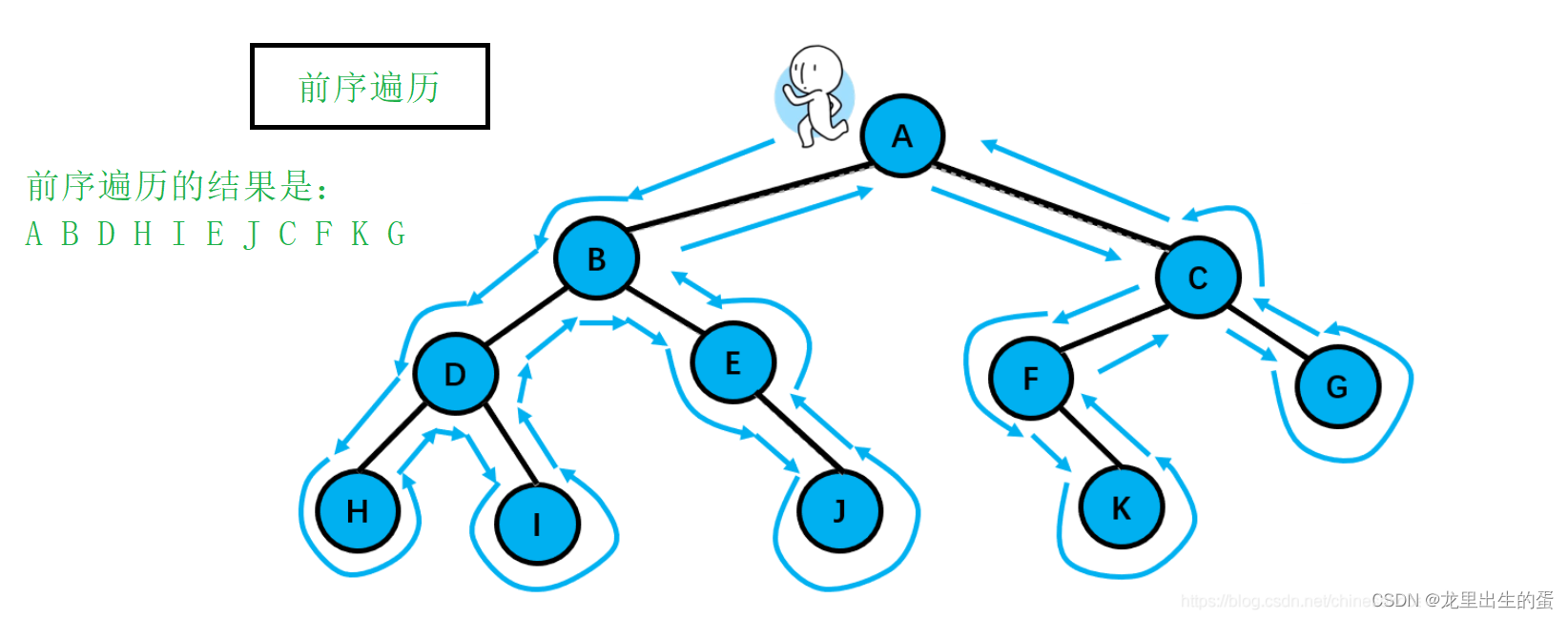
//二叉树前序遍历 根 左子树 右子树
void PreOrder(BTNode* root)
{if (root == NULL){printf("NULL ");return;}else{printf("%c ", root->val);PreOrder(root->left);PreOrder(root->right);}
}
4.2.2二叉树的中序递归遍历
中序遍历也可以看成,二叉树每个节点,垂直方向投影下来(可以理解为每个节点从最左边开始垂直掉到地上),然后从左往右数,得出的结果便是中序遍历的结果。
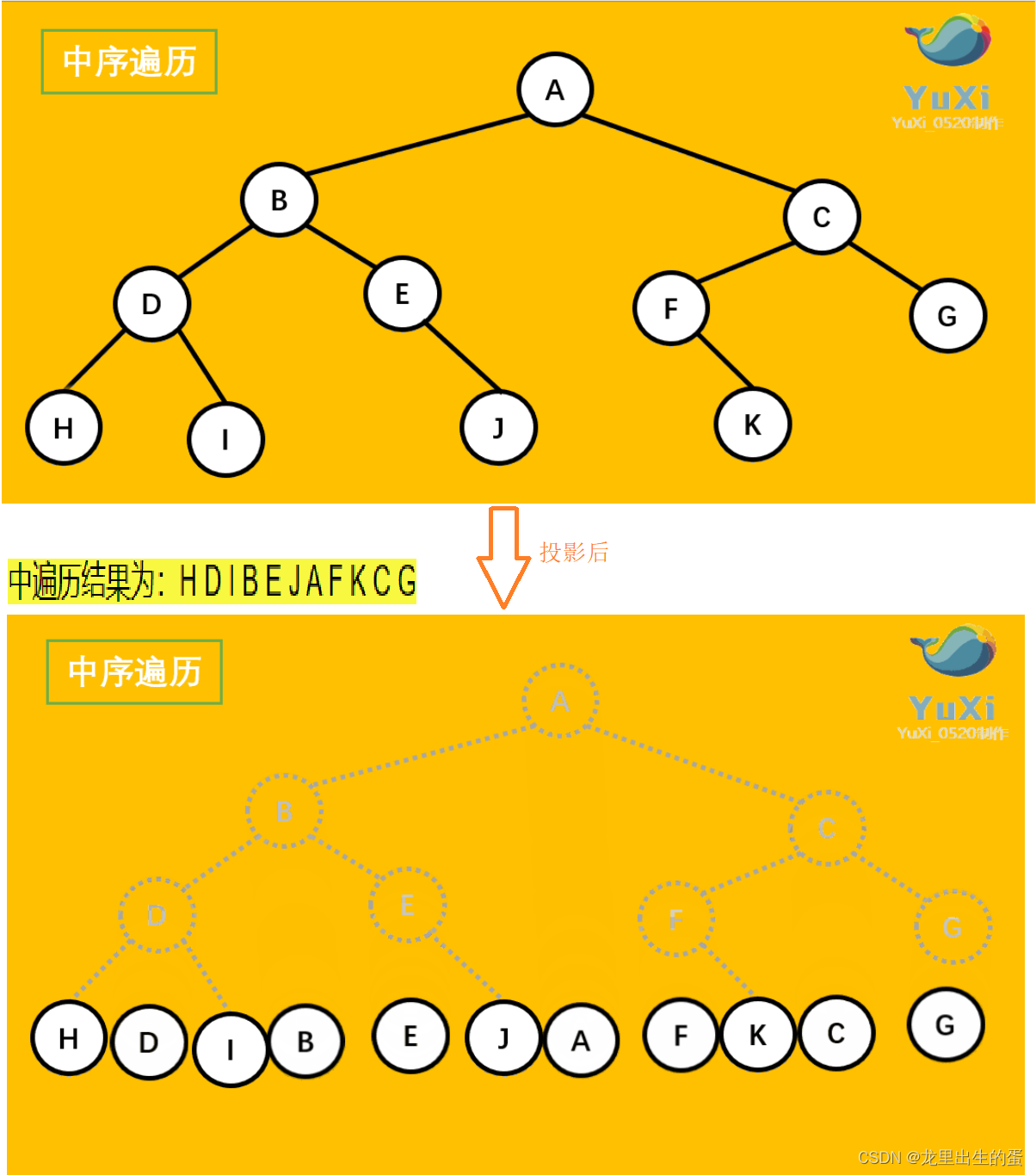
//二叉树中序遍历 左子树 根 右子树
void InOrder(BTNode* root)
{if (root == NULL){printf("NULL ");return;}else{InOrder(root->left);printf("%c ", root->val);InOrder(root->right);}
}
4.2.3二叉树的后序递归遍历
后序遍历(Postorder Traversal)——访问根结点的操作发生在遍历其左右子树之后。
后序遍历就像是剪葡萄,我们要把一串葡萄剪成一颗一颗的。
就是围着树的外围绕一圈,如果发现一剪刀就能剪下的葡萄(必须是一颗葡萄)(也就是葡萄要一个一个掉下来,不能一口气掉超过1个这样),就把它剪下来,组成的就是后序遍历了。
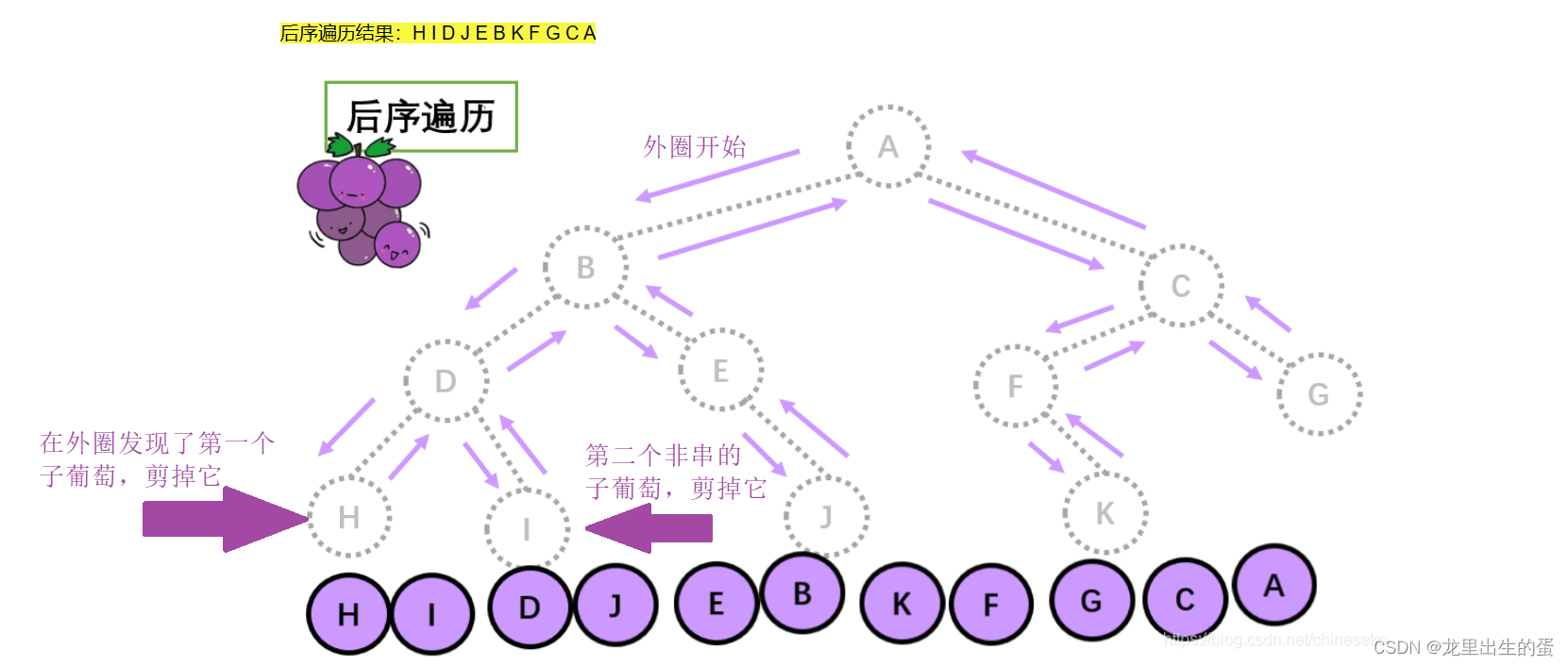
//二叉树后序遍历 左子树 右子树 根
void PostOrder(BTNode* root)
{if (root == NULL){printf("NULL ");return;}else{PostOrder(root->left);PostOrder(root->right);printf("%c ", root->val);}
}
口诀
前序遍历: 先根 再左 再右
中序遍历: 先左 再根 再右
后序遍历: 先左 再右 再根
4.2.4二叉树的层序遍历
层次遍历很好理解,就是从根节点开始,一层一层,从上到下,每层从左到右,依次写值就可以了。
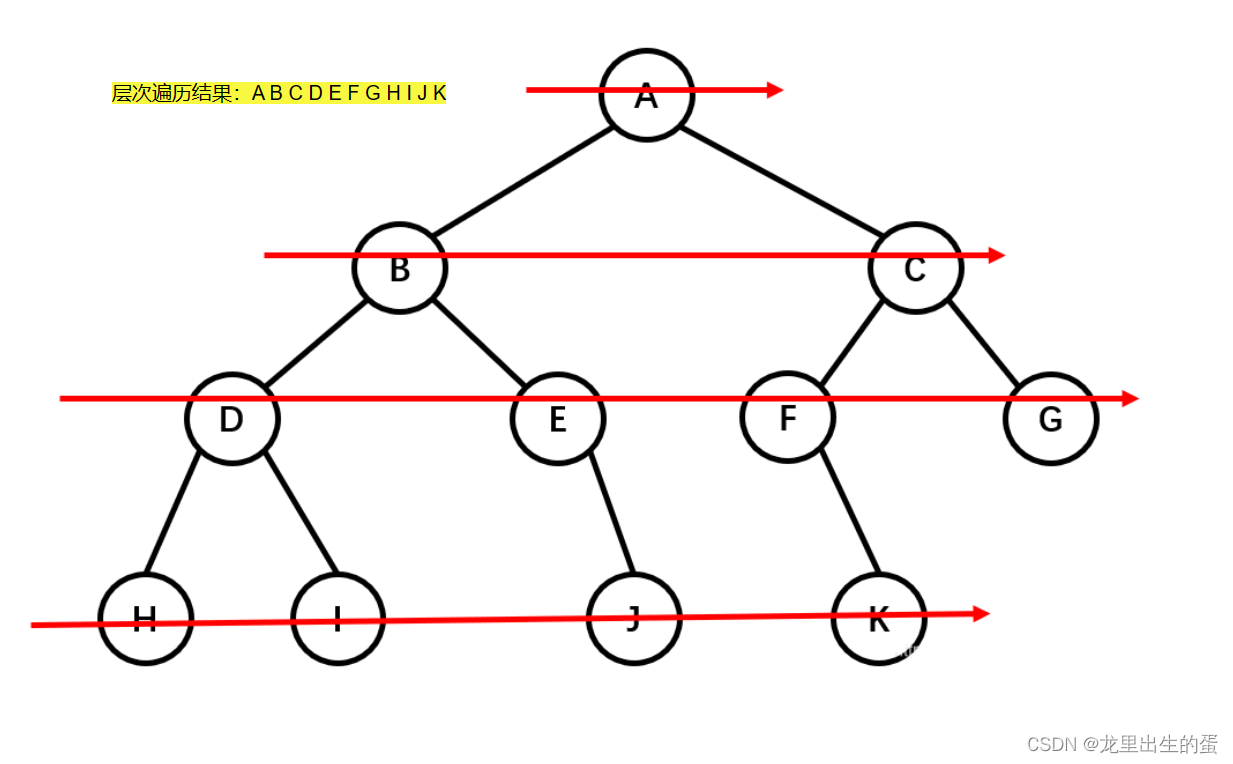
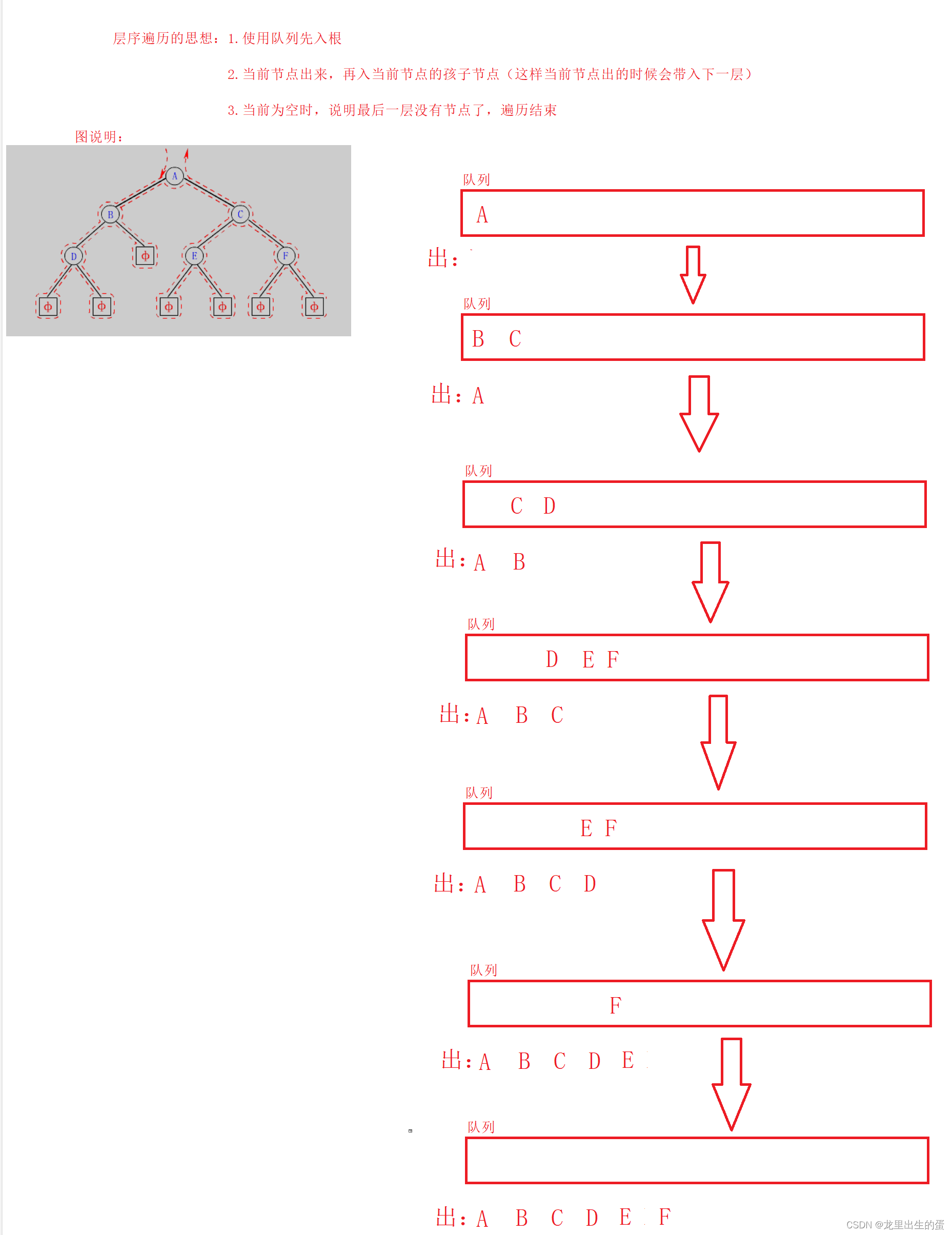
//层序遍历
void LevelOrder(BTNode* root)
{Queue q;Init_Queue(&q);//先入根节点Push_Queue(&q, root);while (!Empty(&q)){BTNode* front = Front_Queue(&q);//出当前节点Pop_Queue(&q);printf("%c ", front->val);if (front->left != NULL){Push_Queue(&q,front->left);}if (front->right != NULL){Push_Queue(&q, front->right);}}printf("\n");
}
4.3二叉树节点数
//二叉树结点个数
int BinaryTreeSize(BTNode* root)
{if (root == NULL){return 0;}else{return 1 + BinaryTreeSize(root->left) + BinaryTreeSize(root->right);}
}
4.4二叉树叶子节点数
当一个节点的左孩子和右孩子都为空时,该节点就是叶子节点。
//二叉数叶子结点个数
int BinaryTreeLeafSize(BTNode* root)
{//当左孩子和右孩子都是空的就是叶子结点if (root == NULL){return 0;}if (root->left = NULL && root->right == NULL){return 1;}else{return BinaryTreeLeafSize(root->left) + BinaryTreeLeafSize(root->right);}
}
4.5二叉树第K层节点数
求第K层节点数的问题可以转换成左子树第K-1层节点数+右子树第K-1层节点数,由此递归下去。
//二叉树第K层节点数
int BinaryTreeLevelKSize(BTNode* root, int k)
{if (root == NULL){return 0;}if (k==1){return 1;}int LeftKSize = BinaryTreeLevelKSize(root->left, k - 1);int RightKSize = BinaryTreeLevelKSize(root->right, k - 1);return LeftKSize + RightKSize;
}
4.6二叉树查找值为X的节点
//二叉树查找值为X的节点
BTNode* BinaryTreeFind(BTNode* root, BTDataType x)
{if (root == NULL){return NULL;}if (root->val = x){return root;}BTNode* LeftNode = BinaryTreeFind(root->left, x);if (LeftNode != NULL){return LeftNode;}BTNode* RightNode = BinaryTreeFind(root->right, x); if (RightNode != NULL){return RightNode;}return NULL;
}
4.7二叉树的深度
//二叉树深度
int BinaryDepth(BTNode* root)
{if (root == NULL){return 0;}int LeftDepth = BinaryDepth(root->left);int RightDepth = BinaryDepth(root->right);return LeftDepth > RightDepth ? LeftDepth + 1 : RightDepth + 1;
}
4.8判断二叉树是否是完全二叉树
判断的思路:
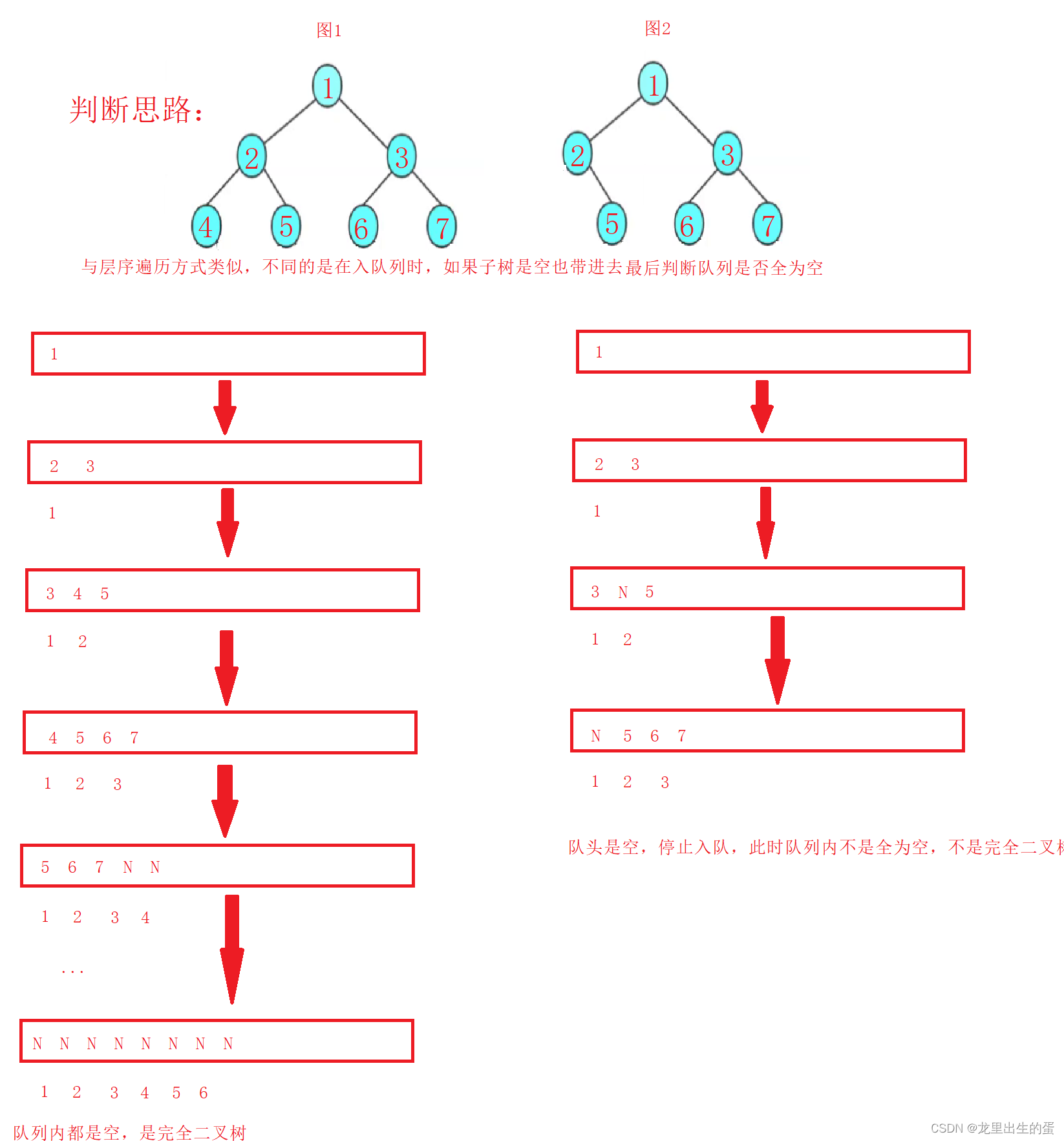
//判断二叉树是否是完全二叉树
bool BinaryTreeComplete(BTNode* root)
{Queue q;Init_Queue(&q);Push_Queue(&q, root);while (Empty(&q)){BTNode* front = Front_Queue(&q);Pop_Queue(&q);if (front){Push_Queue(&q, front->left);Push_Queue(&q, front->right);}else{break;}}while (!Empty(&q)){BTNode* front = Front_Queue(&q);if (front != NULL){Destory_Queue(&q);return false;}Pop_Queue(&q);}Destory_Queue(&q);return true;
}
4.9二叉树完整代码
.h文件
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include"Queue.h"typedef char BTDataType;
typedef struct BinaryTree
{struct BinaryTree* left;struct BinaryTree* right;BTDataType val;
}BTNode;//二叉树前序遍历
void PreOrder(BTNode* root);//二叉树中序遍历
void InOrder(BTNode* root);//二叉树后序遍历
void PostOrder(BTNode* root);//层序遍历
void LevelOrder(BTNode * root);//二叉树结点个数
int BinaryTreeSize(BTNode* root);//二叉数叶子结点个数
int BinaryTreeLeafSize(BTNode* root);//二叉树第K层节点数
int BinaryTreeLevelKSize(BTNode* root, int k);//二叉树查找值为X的节点
BTNode* BinaryTreeFind(BTNode* root, BTDataType x);//判断二叉树是否是完全二叉树
bool BinaryTreeComplete(BTNode * root);//二叉树深度
int BinaryDepth(BTNode* root);//二叉树销毁
void BinaryTreeDestory(BTNode *root);
.c文件
#include"BinaryTree.h"//二叉树前序遍历 根 左子树 右子树
void PreOrder(BTNode* root)
{if (root == NULL){printf("NULL ");return;}else{printf("%c ", root->val);PreOrder(root->left);PreOrder(root->right);}
}//二叉树中序遍历 左子树 根 右子树
void InOrder(BTNode* root)
{if (root == NULL){printf("NULL ");return;}else{InOrder(root->left);printf("%c ", root->val);InOrder(root->right);}
}//二叉树后序遍历 左子树 右子树 根
void PostOrder(BTNode* root)
{if (root == NULL){printf("NULL ");return;}else{PostOrder(root->left);PostOrder(root->right);printf("%c ", root->val);}
}//层序遍历
void LevelOrder(BTNode* root)
{Queue q;Init_Queue(&q);Push_Queue(&q, root);while (!Empty(&q)){BTNode* front = Front_Queue(&q);Pop_Queue(&q);printf("%c ", front->val);if (front->left != NULL){Push_Queue(&q,front->left);}if (front->right != NULL){Push_Queue(&q, front->right);}}printf("\n");
}//二叉树结点个数
int BinaryTreeSize(BTNode* root)
{if (root == NULL){return 0;}else{return 1 + BinaryTreeSize(root->left) + BinaryTreeSize(root->right);}
}//二叉数叶子结点个数
int BinaryTreeLeafSize(BTNode* root)
{//当左孩子和右孩子都是空的就是叶子结点if (root == NULL){return 0;}if (root->left = NULL && root->right == NULL){return 1;}else{return BinaryTreeLeafSize(root->left) + BinaryTreeLeafSize(root->right);}
}//二叉树第K层节点数
int BinaryTreeLevelKSize(BTNode* root, int k)
{if (root == NULL){return 0;}if (k==1){return 1;}int LeftKSize = BinaryTreeLevelKSize(root->left, k - 1);int RightKSize = BinaryTreeLevelKSize(root->right, k - 1);return LeftKSize + RightKSize;
}//二叉树查找值为X的节点
BTNode* BinaryTreeFind(BTNode* root, BTDataType x)
{if (root == NULL){return NULL;}if (root->val = x){return root;}BTNode* LeftNode = BinaryTreeFind(root->left, x);if (LeftNode != NULL){return LeftNode;}BTNode* RightNode = BinaryTreeFind(root->right, x); if (RightNode != NULL){return RightNode;}return NULL;
}//判断二叉树是否是完全二叉树
bool BinaryTreeComplete(BTNode* root)
{Queue q;Init_Queue(&q);Push_Queue(&q, root);while (Empty(&q)){BTNode* front = Front_Queue(&q);Pop_Queue(&q);if (front){Push_Queue(&q, front->left);Push_Queue(&q, front->right);}else{break;}}while (!Empty(&q)){BTNode* front = Front_Queue(&q);if (front != NULL){Destory_Queue(&q);return false;}Pop_Queue(&q);}Destory_Queue(&q);return true;}//二叉树深度
int BinaryDepth(BTNode* root)
{if (root == NULL){return 0;}int LeftDepth = BinaryDepth(root->left);int RightDepth = BinaryDepth(root->right);return LeftDepth > RightDepth ? LeftDepth + 1 : RightDepth + 1;
}//二叉树销毁 使用递归 先释放左子树在释放右子树最后释放根
void BinaryTreeDestory(BTNode* root)
{if (root == NULL){return;}BinaryTreeDestory(root->left);BinaryTreeDestory(root->right);free(root);
}
相关文章:
数据结构--二叉树
目录1.树概念及结构1.1数的概念1.2数的表示2.二叉树概念及结构2.1二叉树的概念2.2数据结构中的二叉树2.3特殊的二叉树2.4二叉树的存储结构2.4.1顺序存储2.4.2链式存储2.5二叉树的性质3.堆的概念及结构3.1堆的实现3.1.1堆的创建3.1.2堆的插入3.1.3堆顶的删除3.1.4堆的代码实现3.…...

Keil5安装和使用小记
随着keil版本的更新,一些使用问题一随之产生。本文针对安装目前最新版本keil软件和使用问题做一些总结。 目录1 Keil5下载&安装1.1 官网下载链接1.2 软件安装1.2.1 安装说明1.2.2 关于 51 和 ARM 共存的问题1.3 软件破解2 pack包安装 & 破解2.1 下载2.2 安装…...
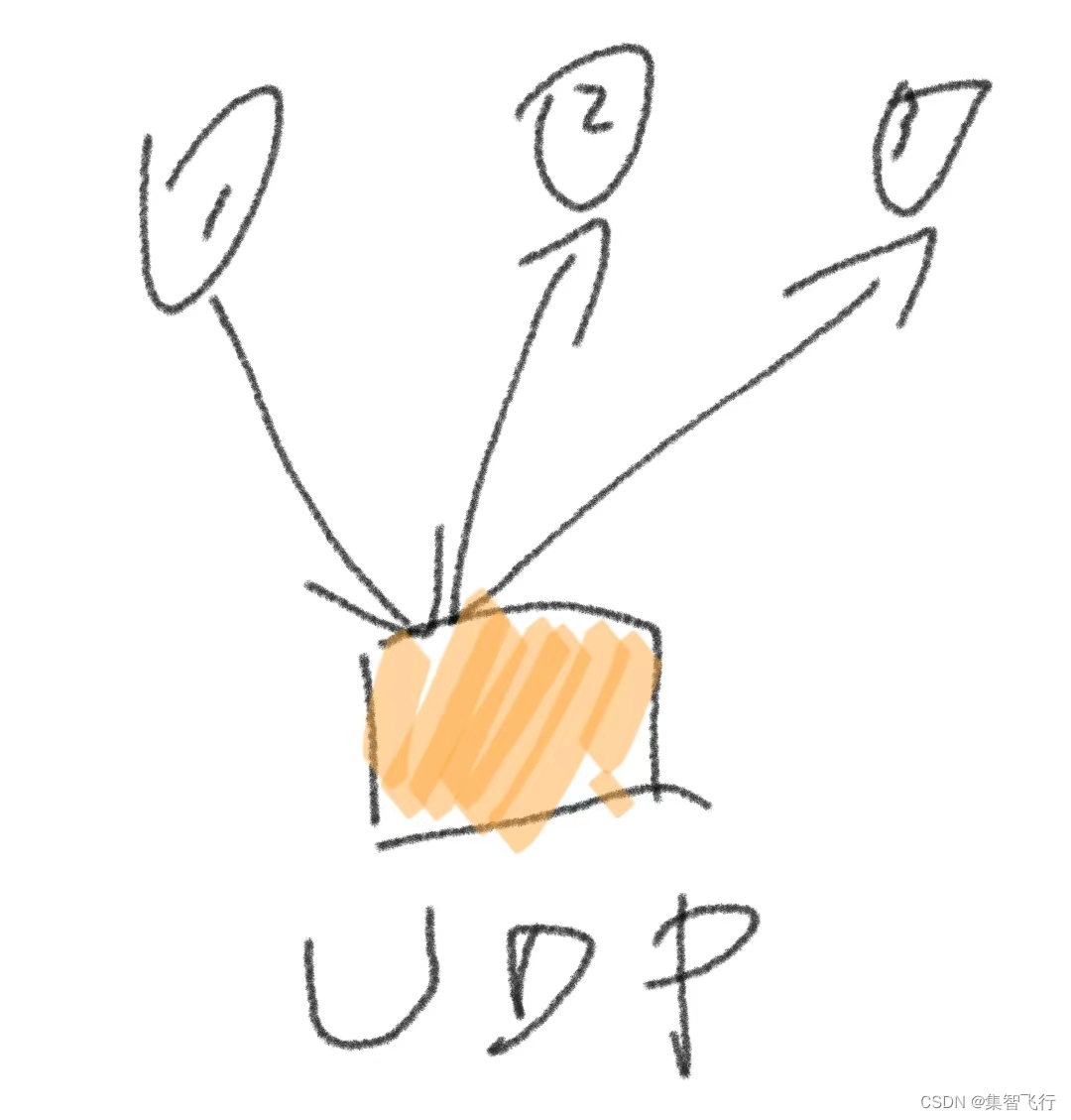
多机器人集群网络通信协议分析
本文讨论的是多机器人网络通信各层的情况和协议。 每个机器人连接一个数据传输通信模块(以下简称为数传,也泛指市面上的图传或图数一体的通信模块),数传之间进行组网来传递信息。 根据ISO的划分,网络通信的OSI模型分…...

【PyTorch】手把手带你快速搭建PyTorch神经网络
手把手带你快速搭建PyTorch神经网络1. 定义一个Class2. 使用上面定义的Class3. 执行正向传播过程4. 总结顺序相关资料话不多说,直接上代码1. 定义一个Class 如果要做一个神经网络模型,首先要定义一个Class,继承nn.Module,也就是i…...

【完整代码】用HTML/CSS制作一个美观的个人简介网页
【完整代码】用HTML/CSS制作一个美观的个人简介网页整体结构完整代码用HTML/CSS制作一个美观的个人简介网页——学习周记1HELLO!大家好,由于《用HTML/CSS制作一个美观的个人简介网页》这篇笔记有幸被很多伙伴关注,于是特意去找了之前写的完整…...

Java分布式事务(九)
文章目录🔥XA强一致性分布式事务实战_Atomikos介绍🔥XA强一致性分布式事务实战_业务说明🔥XA强一致性分布式事务实战_项目搭建🔥XA强一致性分布式事务实战_多数据源实现🔥XA强一致性分布式事务实战_业务层实现…...
基于深度学习的动物识别系统(YOLOv5清新界面版,Python代码)
摘要:动物识别系统用于识别和统计常见动物数量,通过深度学习技术检测日常几种动物图像识别,支持图片、视频和摄像头画面等形式。在介绍算法原理的同时,给出Python的实现代码、训练数据集以及PyQt的UI界面。动物识别系统主要用于常…...

K8S集群之-ETCD集群监控
### 生产ETCD集群监控核心指标 etcd服务存活状态 up{job~"kubernetes-etcd.*"}0 说明:up0代表服务挂掉 etcd是否有脱离情况 etcd_server_has_leader{job~"kubernetes-etcd.*"}0 说明:每个instance,该值应该都…...
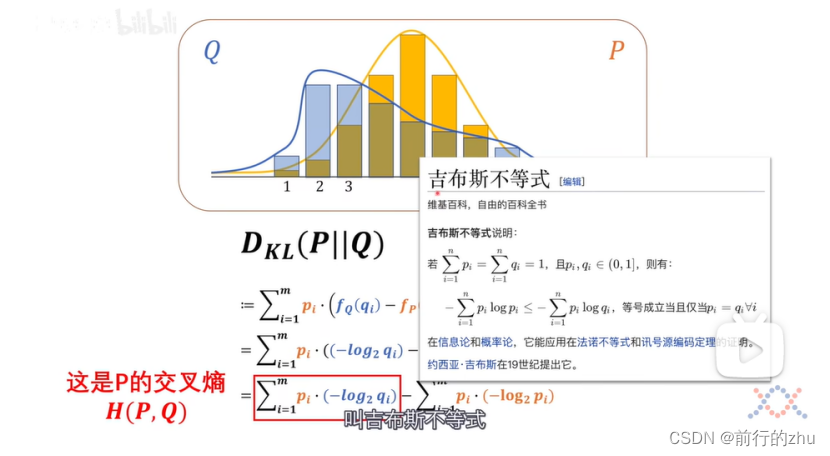
一文弄懂熵、交叉熵和kl散度(相对熵)
一个系统中事件发生的概率越大,也就是其确定性越大,则其包含的信息量越少,可以认为一个事件的信息量就是该事件发生难度的度量,事件所包含的信息量越大则其发生的难度越大。并且相互独立的事件,信息量具有可加性。相互…...
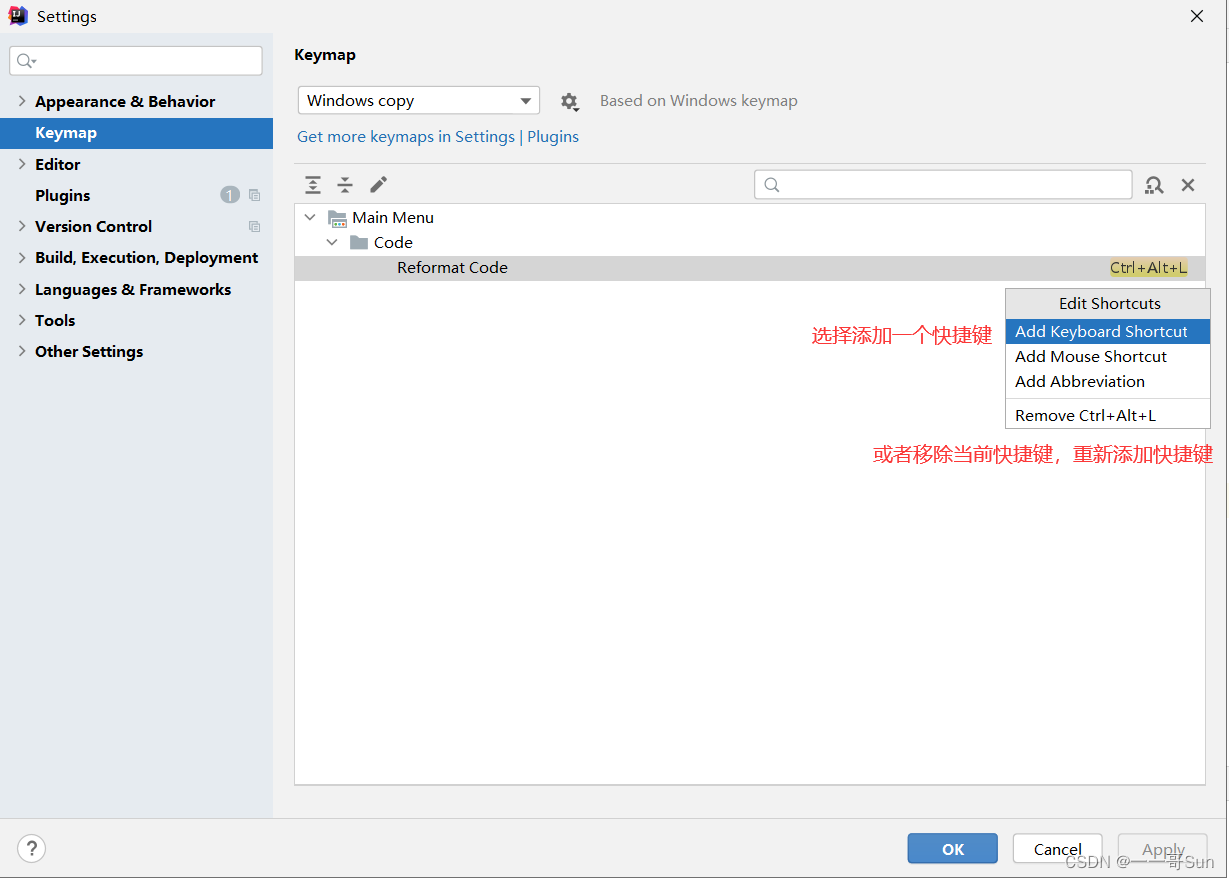
10从零开始学Java之开发Java必备软件Intellij idea的安装配置与使用
作者:孙玉昌,昵称【一一哥】,另外【壹壹哥】也是我哦CSDN博客专家、万粉博主、阿里云专家博主、掘金优质作者前言壹哥在前面的文章中,带大家下载、安装、配置了Eclipse这个更好用的IDE开发工具,并教会了大家如何在Ecli…...

04 - 进程参数编程
---- 整理自狄泰软件唐佐林老师课程 查看所有文章链接:(更新中)Linux系统编程训练营 - 目录 文章目录1. 问题1.1 再论execve(...)1.2 main函数(默认进程入口)1.3 进程空间概要图1.4 编程实验:进程参数剖析1…...

【python进阶】你真的懂元组吗?不仅是“不可变的列表”
📚引言 🙋♂️作者简介:生鱼同学,大数据科学与技术专业硕士在读👨🎓,曾获得华为杯数学建模国家二等奖🏆,MathorCup 数学建模竞赛国家二等奖🏅,…...
第13章编程练习)
《C++ Primer Plus》(第6版)第13章编程练习
《C Primer Plus》(第6版)第13章编程练习《C Primer Plus》(第6版)第13章编程练习1. Cd类2. 使用动态内存分配重做练习13. baseDMA、lacksDMA、hasDMA类4. Port类和VintagePort类《C Primer Plus》(第6版)第…...
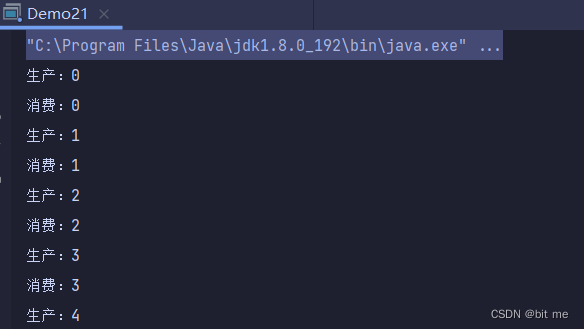
【多线程】多线程案例
✨个人主页:bit me👇 ✨当前专栏:Java EE初阶👇 ✨每日一语:we can not judge the value of a moment until it becomes a memory. 目 录🍝一. 单例模式🍤1. 饿汉模式实现🦪2. 懒汉模…...

【IoT】嵌入式驱动开发:IIC子系统
IIC有三种接口实现方式 三种时序对比: 图1 IIC子系统组成 图2 图3 IIC操作流程 设备端 1.i2c_get_adapter 2.i2c_new_device(相当于register设备) 3.I2c_put_adapter 驱动端 1.填充i2c_driver 2.i2c_add_driver(相当于register驱动) 3.在probe中建立访问方式 client相…...
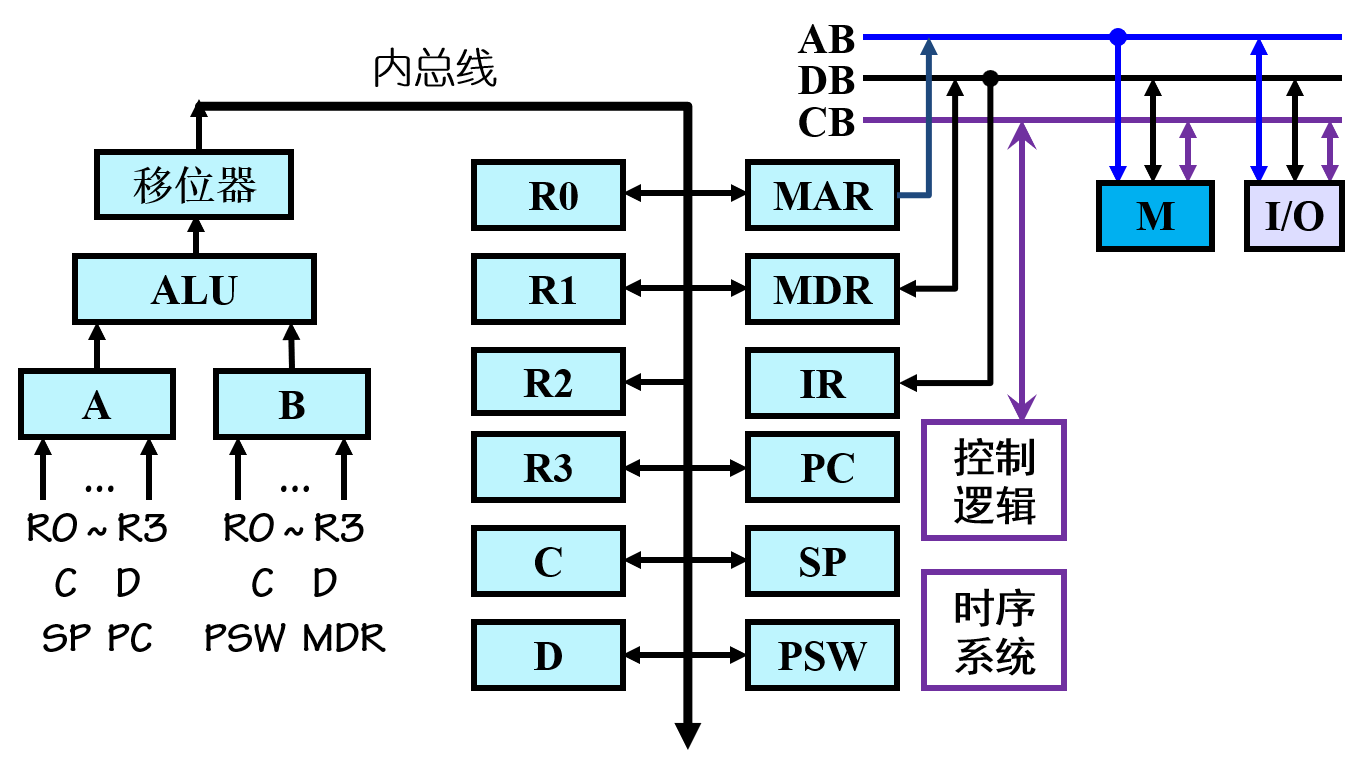
DJ2-4 进程同步(第一节课)
目录 2.4.1 进程同步的基本概念 1. 两种形式的制约关系 2. 临界资源(critical resource) 3. 生产者-消费者问题 4. 临界区(critical section) 5. 同步机制应遵循的规则 2.4.2 硬件同步机制 1. 关中断 2. Test-and-Set …...
AI独立开发者:一周涨粉8万赚2W美元;推特#HustleGPT GPT-4创业挑战;即刻#AIHackathon创业者在行动 | ShowMeAI周刊
👀日报&周刊合辑 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 这是ShowMeAI周刊的第7期。聚焦AI领域本周热点,及其在各圈层泛起的涟漪;拆解AI独立开发者的盈利案例,关注中美AIG…...
不要迷信 QUIC
很多人都在强调 QUIC 能解决 HoL blocking 问题,不好意思,我又要泼冷水了。假设大家都懂 QUIC,不再介绍 QUIC 的细节,直接说问题。 和 TCP 一样,QUIC 也是一个基于连接的,保序的可靠传输协议,T…...

【28】Verilog进阶 - RAM的实现
VL53 单端口RAM 1 思路 简简单单,读取存储器单元值操作即可 2 功能猜想版 说明: 下面注释就是我对模块端口信号 自己猜测的理解。 因为题目并没有说清楚,甚至连参考波形都没有给出。 唉,这就完全是让人猜测呢,如果一点学术背景的人来刷题,指定不容易!! 好在,我有较为…...

【MySQL】聚合查询
目录 1、前言 2、插入查询结果 3、聚合查询 3.1 聚合函数 3.1.1 count 3.1.2 sum 3.1.3 avg 3.1.4 max 和 min 4、GROUP BY 子句 5、HAVING 关键字 1、前言 前面的内容已经把基础的增删改查介绍的差不多了,也介绍了表的相关约束, 从本期开始…...

OpenClaw故障模拟:Qwen3-14b_int4_awq异常输入处理与恢复机制
OpenClaw故障模拟:Qwen3-14b_int4_awq异常输入处理与恢复机制 1. 为什么需要主动制造故障 去年冬天的一个深夜,我的OpenClaw自动化流程突然中断了。当时它正在帮我整理一批技术文档,却在处理某个特殊字符时直接"卡死"。这次经历让…...

港科喜讯|[港科百创]参赛项目上市!视觉语言大模型第一股诞生!
2026年3 月 30 日,山东极视角科技股份有限公司(股票代码:6636.HK)在香港联合交易所主板正式上市。这家曾斩获香港科技大学第六届百万奖金国际创业大赛深圳赛区一等奖的科创企业,同时也是香港科大"创科行"(第…...

OpenClaw本地模型对比:千问3.5-35B-A3B-FP8与开源替代方案
OpenClaw本地模型对比:千问3.5-35B-A3B-FP8与开源替代方案 1. 为什么需要本地模型对比 当我第一次尝试在OpenClaw中接入本地大模型时,面对众多开源选项感到非常困惑。每个模型都宣称自己性能优越,但实际部署后却发现资源消耗、推理速度与预…...

实战指南:基于同一份OpenSpec,用快马平台同步生成前后端代码,确保联调无忧
最近在开发一个电商平台时,我们团队遇到了前后端联调效率低下的问题。由于接口文档和实际代码存在差异,经常出现前端调用参数和后端接收不一致的情况。后来我们发现,基于OpenSpec规范同步生成前后端代码可以完美解决这个问题,这里…...

GameFramework——FileSystem篇
目录 一、快速入门 1.1 什么是文件系统模块? 1.2 基本使用步骤 1.2.1 创建文件系统 1.2.2 写入文件 1.2.3 读取文件 1.2.4 删除文件 1.2.5 加载已有文件系统 二、文件布局 2.1 HeaderData(文件头) 2.2 BlockData(块数据…...
Pixel Couplet Gen应用场景:微信小程序‘灵蛇贺岁’互动模块开发全解析
Pixel Couplet Gen应用场景:微信小程序灵蛇贺岁互动模块开发全解析 1. 项目背景与核心价值 在传统节日数字化呈现的浪潮下,我们开发了"灵蛇贺岁"微信小程序互动模块。这款基于ModelScope大模型的春联生成器,通过创新的像素游戏风…...

3大核心功能解锁Wallpaper Engine资源:RePKG工具全方位应用指南
3大核心功能解锁Wallpaper Engine资源:RePKG工具全方位应用指南 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 突破资源限制的三个关键能力 你是否曾遇到这样的困境&a…...

OpenClaw安全加固指南:Phi-3-vision本地化部署的权限控制
OpenClaw安全加固指南:Phi-3-vision本地化部署的权限控制 1. 为什么需要安全加固? 上周我在调试一个自动处理发票的OpenClaw流程时,差点酿成大祸。这个流程需要读取财务部门的加密压缩包,解压后提取PDF发票进行OCR识别ÿ…...

1220亿美元!OpenAI创下史上最大融资纪录;DeepSeek连续三天发生服务异常;Claude Code 51万行源码泄露 | 极客头条
「极客头条」—— 技术人员的新闻圈!CSDN 的读者朋友们好,「极客头条」来啦,快来看今天都有哪些值得我们技术人关注的重要新闻吧。(投稿或寻求报道:zhanghycsdn.net)整理 | 苏宓出品 | CSDN(ID&…...

一个月突变!Linux内核大佬懵了:上个月还是“AI垃圾”,这个月AI Bug报告却突然靠谱?
整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)最近在做开源项目维护的开发者,可能会有一种奇怪的错觉:Bug 似乎报告变多了,而且变准了——更准确地说,是 AI 报的 Bug,突然开始“靠谱了”。…...