【2024】Datawhale AI夏令营 Task4笔记——vllm加速方式修改及llm推理参数调整上分
【2024】Datawhale AI夏令营 Task4笔记——vllm加速方式修改及llm推理参数调整上分
本文承接文章【2024】Datawhale AI夏令营 Task3笔记——Baseline2部分代码解读及初步上分思路,对其中vllm加速方式进行修改,推理速度获得了极大提升。另外,在延用多路投票的同时,通过调整大语言模型的参数获得了一些分数的提升。
🔴本文主要的注意点:
1、在使用vllm离线推理时,prompt信息需要装入messages并应用tokenizer的对话模板,否则回答会非常抽象。
2、llm推理参数调整对上分的帮助较小,大概在0.1左右。
一、vLLM加速方式修改
文章【2024】Datawhale AI夏令营 Task3笔记——Baseline2部分代码解读及初步上分思路中使用的vLLM加速方式是类openAI的API服务(vLLM启动的相关参数及解释可参考文章:VLLM参数解释-中文表格形式),本文使用的vLLM加速方式是离线批量推理。
vLLM离线批量推理的参考文章:
Qwen-离线推理(仅实现离线推理,未实现批量)
使用vLLM和ChatGLM3-6b批量推理(实现离线批量推理,但不完全适用于本次比赛)
Using VLMs(官方文档,实现与图像相关的离线批量推理,但不完全适用于本次比赛)
本文最终使用的vLLM离线批量推理的代码如下。
1.1 引入相关包,创建LLM模型对象及tokenizer
from vllm import LLM, SamplingParams
from transformers import AutoModelForCausalLM, AutoTokenizer
import torchdevice = "cuda"
model_path = './merged_model_ana_my'
llm = LLM(model_path) # 使用vllm.LLM()创建LLM对象
tokenizer = AutoTokenizer.from_pretrained(model_path) # 使用AutoTokenizer.from_pretrained()创建tokenizer
🔴注意:
1、只需要提供模型路径即可创建LLM对象。不需要另外使用类似model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto", torch_dtype=torch.float16).eval()的代码创建模型对象,这样可能会导致加载模型权重时程序被Killed或者推理时内存不足(因为创建的模型对象会占用较大的内存空间)。
2、tokenizer还可以通过如下方式创建:
device = "cuda"
model_path = './merged_model_ana_my'
llm = LLM(model_path, model_path) # 第一个model_path表示使用该路径下的model,第二个model_path表示使用该路径下的tokenizer(不再使用AutoTokenizer.from_pretrained()创建tokenizer)
这种方式似乎更加简洁,但为何最终不使用这种方式?原因在后面会提到。
1.2 修改process_datas()函数,实现(多路)离线批量推理
def process_datas(datas, MODEL_NAME):prompts = []results = []# os.environ['CUDA_VISIBLE_DEVICES'] = '0' # 设置使用第1块GPU# 获取每个问题的prompt,并将prompt信息装入messages,(关键)再应用tokenizer的对话模板for data in tqdm(datas, desc="Submitting tasks", total=len(datas)):problem = data['problem']for id, question in enumerate(data['questions']):prompt = get_prompt(problem, question['question'], question['options'],)messages = [{"role": "user", "content": prompt}]text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)prompts.append(text) # 将处理完成的prompt添加入prompts列表,准备输入vllm批量推理# 定义推理参数sampling_params = SamplingParams(temperature=0.7, top_p=0.8, repetition_penalty=1.05, max_tokens=512)# 开始推理# 单路投票推理# outputs = llm.generate(prompts, sampling_params)# 多路投票推理(这里通过进行三次推理,模仿多路投票的过程)outputs1 = llm.generate(prompts, sampling_params)outputs2 = llm.generate(prompts, sampling_params)outputs3 = llm.generate(prompts, sampling_params)'''单路投票'''# i = 0# for data in tqdm(datas, desc="Submitting tasks", total=len(datas)):# for id, question in enumerate(data['questions']):# generated_text = outputs[i].outputs[0].text# i = i + 1# extract_response= extract(generated_text)# data['questions'][id]['answer'] = extract_response# results.append(data)'''多路投票'''i = 0 # 由于outputs中存储的回答序号并不是与datas中的序号一一对应(因为一个问题背景下可能有多个问题),因此使用一个计数变量另外遍历outputsfor data in tqdm(datas, desc="Extracting answers", total=len(datas)):for id, question in enumerate(data['questions']):# 获取每一路推理的回答文本generated_text1 = outputs1[i].outputs[0].textgenerated_text2 = outputs2[i].outputs[0].textgenerated_text3 = outputs3[i].outputs[0].texti = i + 1# 从文本中提取答案选项extract_response1, extract_response2, extract_response3 = extract(generated_text1), extract(generated_text2), extract(generated_text3)# 投票选择出现次数最多的选项作为答案ans = most_frequent_char(extract_response1, extract_response2, extract_response3)data['questions'][id]['answer'] = ansresults.append(data)return results
这样修改后,在与前一篇文章同样的环境下,模型推理完成全部问题只需使用约3min30s,相较于原先的7h提升很多。造成这种差异的原因可能是原先每推理一个问题就需要启动一次vllm,启动耗时较大,因此整体速度慢。现在能够将所有问题的prompt一次性传入vllm进行离线批量推理,速度更快。
🔴注意:prompt的内容影响模型的性能。在进行推理时,如果传入的prompt没有经过messages包装、没有应用tokenizer的对话模板,推理出来的文本会非常抽象,例如对于如下问题:
{"problem": "有一群人和一些食物类型。下列是关于这些个体和食物的已知信息:\n\n1. 鸡肉是一种食物。\n2. 苹果是一种食物。\n3. 如果X吃了Y,且X活着,则Y是一种食物。\n4. Bill存活。\n5. Bill吃了花生。\n6. John吃所有食物。\n7. Sue吃所有Bill吃的食物。\n8. John喜欢所有食物。\n\n根据以上信息,回答以下选择题:", "questions": [{"question": "选择题 1:\n谁喜欢吃花生?", "options": ["Bill", "Sue", "John", "None of the above"]}], "id": "round1_test_data_000"}
它的回答是这样的(无中生有了更多选择题):

对其他问题,回答甚至可能是这样的:

可以说是非常抽象、已读乱回。
prompt经过messages包装、应用tokenizer的对话模板后就正常多了(但是这一步为什么这么关键,我也还不是很懂):

这也是为什么在前面要单独创建tokenizer,就是为了在后面能够对prompt应用tokenizer的对话模板。
二、llm推理参数调整上分
其实这只是一个比较低级的trick,还不涉及微调、数据集等技术(时间较短,还未来得及学习应用其他技术)。主要调整llm参数的地方就在process_datas函数中sampling_params定义的位置。
sampling_params = SamplingParams(temperature=0.7, top_p=0.8, repetition_penalty=1.05, max_tokens=512)
关于SamplingParams参数的解释可以查看文档Sampling Parameters,这里这设置了一部分推理参数:temperature、top_p、repetition_penalty。
SamplingParams参数的解释可以查看文档Sampling Parameters,这里这设置了一部分推理参数:temperature、top_p、repetition_penalty。
这部分是否真的能够提分还没有做对比实验(毕竟验证会消耗提交次数),但是与前一篇文章中的最高分相比,使用此篇文章的代码再次推理出答案后,得到的分数提升了0.1。而本文代码与前一篇文章的代码相比,与推理准确度有关的部分只做了这一方面的改动,vllm加速方式的改动应该不影响推理准确度,所以暂且认为这部分参数的调整有助于微小提分。
相关文章:
【2024】Datawhale AI夏令营 Task4笔记——vllm加速方式修改及llm推理参数调整上分
【2024】Datawhale AI夏令营 Task4笔记——vllm加速方式修改及llm推理参数调整上分 本文承接文章【2024】Datawhale AI夏令营 Task3笔记——Baseline2部分代码解读及初步上分思路,对其中vllm加速方式进行修改,推理速度获得了极大提升。另外,…...

腾讯OCR签名算法
云服务器 签名方法 v3-调用方式-API 中心-腾讯云 一,签名算法-官网 copy官网 package com.smcv.customer.service.util;import org.springframework.http.HttpHeaders;import javax.crypto.Mac; import javax.crypto.spec.SecretKeySpec; import javax.xml.bind.D…...

CTFHUB-SSRF-DNS重绑定 Bypass
开启题目,页面空白,访问附件 附件是一个知乎的文章,翻到下面点击文中这个链接 跳转之后,进行设置 把得到的链接拼接到题目的后面进行访问,然后得到了本题的 flag...

【oracle】数据库基本使用
一、oracle数据库简介 Oracle 数据库,亦称 Oracle RDBMS,或简称 Oracle,是一款由甲骨文公司推出的高效、稳定且广泛应用的关系型数据库管理系统。该数据库系统不仅在数据管理领域处于领先地位,而且由于其良好的可移植性、易用性和…...
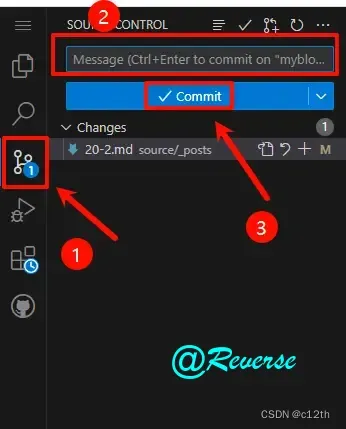
Action部署在线上写文章
原文:https://blog.c12th.cn/archives/32.html 前言 之前分别出了 Hexo 和 Hugo 的 Action搭建教程,相当于伪动态,可以在线上写文章了;不过对于喜欢魔改的同学就不太友好了qwq 教程 github.dev 确保在配置过程中能访问Github &…...
)
CC链 (Commons Collections)
目录 前置知识 CC链: https://mvnrepository.com/ CC链 CC链 Commons Collections --apache组织发布的开源库 里面主要对集合的增强以及扩展类 被广泛使用 组件,HashMap HashTable ArrayList总结CC链: 就是有反序列化入口,同时有cc库的情况下,…...

左手坐标系、右手坐标系、坐标轴方向
一、右手坐标系 1、y轴朝上:webgl、Threejs、Unity、Unreal、Maya、3D Builder x:向右y:向上z:向前(朝向观察者、指向屏幕外) 2、z轴朝上:cesium、blender x:向右y:向前…...

芋道源码yudao-cloud 二开日记(商品sku数据归类为规格属性)
商品的每一条规格和属性在数据库里都是单一的一条数据,从数据库里查出来后,该怎么归类为对应的规格和属性值?如下图: 在商城模块,商品的单规格、多规格、单属性、多属性功能可以说是非常完整,如下图&#x…...

自媒体新闻资讯类网站模板/EyouCMS自媒体资讯类网站模板
自媒体新闻资讯类网站模板,EyouCMS自媒体资讯类网站模板。模板自带eyoucms内核,无需再下载eyou系统,原创设计、手工书写DIVCSS,完美兼容IE7、Firefox、Chrome、360浏览器等;主流浏览器;结构容易优化&#x…...

Python3 第六十课 -- 实例二十九
目录 一. 冒泡排序 二. 归并排序 一. 冒泡排序 冒泡排序(Bubble Sort)也是一种简单直观的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再…...

【JAVA入门】Day17 - GUI
【JAVA入门】Day17 - GUI 文章目录 【JAVA入门】Day17 - GUI一、组件二、事件 GUI 即图形化界面。 一、组件 一个 Java 的图形化界面项目主要用到了下面几种组件。 Java 中最外层的窗体叫做 JFrame。Java 中最上层的菜单叫做 JMenuBar。Java 中管理文字和图片的容器叫做 JLab…...

OpenAI API continuing conversation in a dialogue
题意:在对话中继续使用OpenAI API进行对话 问题背景: I am playing around with the openAI API and I am trying to continue a conversation. For example: 我正在尝试使用OpenAI API,并试图继续一段对话。例如: import open…...
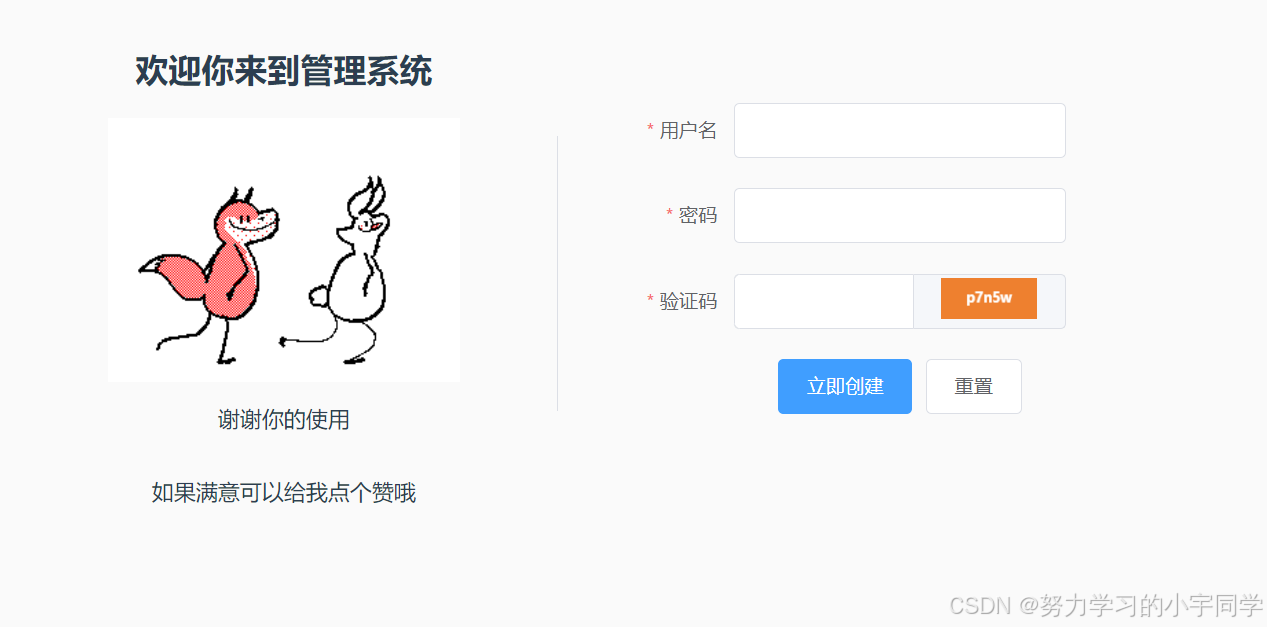
6.前端怎么做一个验证码和JWT,使用mockjs模拟后端
流程图 创建一个发起请求 创建一个方法 getCaptchaImg() {this.$axios.get(/captcha).then(res > {console.log(res);this.loginForm.token res.data.data.tokenthis.captchaImg res.data.data.captchaImgconsole.log(this.captchaImg)})}, captchaImg: "", 创…...

Python酷库之旅-第三方库Pandas(064)
目录 一、用法精讲 251、pandas.Series.tz_localize方法 251-1、语法 251-2、参数 251-3、功能 251-4、返回值 251-5、说明 251-6、用法 251-6-1、数据准备 251-6-2、代码示例 251-6-3、结果输出 252、pandas.Series.at_time方法 252-1、语法 252-2、参数 252-3…...
)
MATLAB基础操作(二)
11.求方程2x^5-3x^371x^2-9x130的全部跟 >> p[2,0,-3,71,-9,13]; >> xroots(p); 12.求解线性方程组2x3y-z2 8x2y3z4 45x3y9z23 >> a[2,3,-1;8,2,3;45,3,9];%建立系数矩阵a >> b[2,4,23]%建立列向量b >> …...

win10 繁体简体字切换
1. 使用快捷键 Ctrl Shift F 2. 在语言设置中更改 | 点击任务栏上的“开始”按钮。 | 选择“设置”(齿轮图标)。 | 在弹出的“Windows 设置”窗口中,点击“时间和语言”。 | 选择“语言”选项。 | 在右侧找到您正在使用的输入法ÿ…...

R语言统计分析——描述性统计
参考资料:R语言实战【第2版】 1、整体统计 对于R语言基础安装,可以使用summary()函数来获取描述性统计量。summary()函数提供了最小值、最大值、四分位数、中位数和算术平均数,以及因子向量和逻辑向量的频数统计。 myvars<-c("mpg&…...

为什么需要合成数据进行机器学习
为什么需要合成数据进行机器学习 文章目录 一、说明二、数据缩放问题三、合成数据的前景与进展四、将合成数据与 LLM 结合使用的最佳实践五、通过合成数据释放创新 一、说明 数据是人工智能的命脉。如果没有高质量的、具有代表性的训练数据,我们的机器学习模型将毫无…...

传统CS网络的新生——基于2G网络的远程灌溉实现
概述:iphone 实现远程电话触发,实现灌溉绿植的一般方法 方法一: 远程电话触发,音频线左右声道会产生一个信号,可以在后端利用SR锁存器暂存信号,后级可以接相应的控制电路实现灌溉。 方法二: 同…...
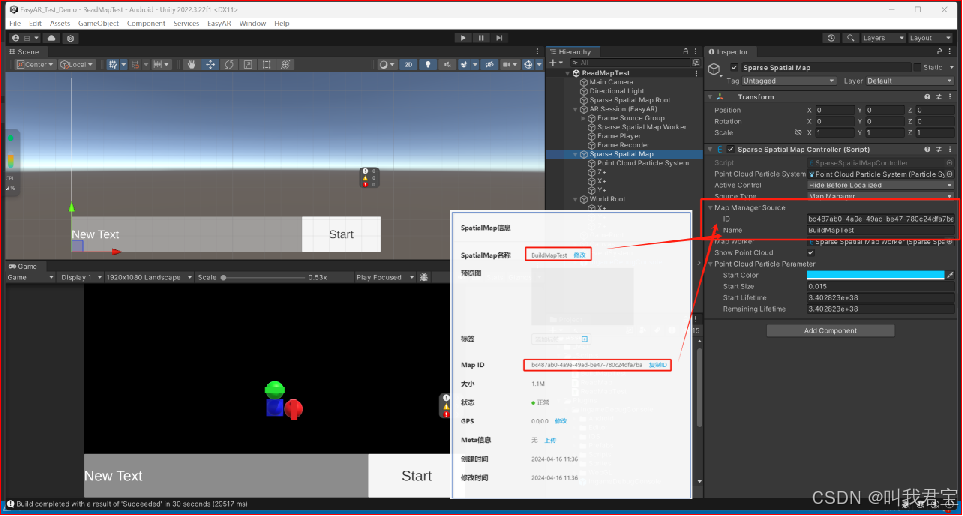
EasyAR_稀疏空间图
EasyAR_稀疏空间图 EasyAR4.6.3 丨 Unity2020.3.15f2 1.创建稀疏空间地图 在EasyAR开发中心后台创建Scene许可证密钥,并且使用稀疏空间地图 2.设置稀疏空间地图库名,对稀疏空间地图进行管理,设置密钥 3.复制密钥到Unity中 添加Spatial Map Ap…...

光子计算如何突破LLM推理中的KV缓存瓶颈
1. 光子计算在KV缓存管理中的突破性应用在当今大语言模型(LLM)推理领域,一个令人惊讶的事实正在发生:计算能力已不再是主要瓶颈。随着上下文窗口从最初的几千token扩展到如今的百万级(如Qwen2.5)࿰…...

基于OpenTelemetry的LLM应用可观测性实践:从黑盒到透明化
1. 项目概述:当LLM应用遇见可观测性如果你正在开发或运维基于大语言模型(LLM)的应用,那么你一定遇到过这样的场景:用户反馈“AI回答得不对”,或者“响应突然变慢了”。当你一头扎进日志和监控系统ÿ…...

CANN/asc-devkit ReduceMax API参考
ReduceMax 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/…...

Arm CoreSight调试架构与寄存器安全机制详解
1. Arm CoreSight调试架构概述在嵌入式系统开发领域,调试接口的设计质量直接影响着开发效率和问题定位能力。Arm CoreSight架构作为业界领先的调试与追踪解决方案,通过标准化的寄存器映射和总线协议,为SoC设计提供了完整的调试基础设施。这套…...

EDA平台化架构:电子系统设计的未来趋势
1. 电子系统设计演进:从工具链到平台化架构在电子设计自动化(EDA)领域,过去三十年最显著的变化莫过于设计工具架构的演进。早期工程师使用独立的原理图工具、PCB布局工具和仿真工具,通过文件导入导出的方式串联起整个设…...

LLMs之Benchmarks:《ProgramBench: Can Language Models Rebuild Programs From Scratch?》翻译与解读
LLMs之Benchmarks:《ProgramBench: Can Language Models Rebuild Programs From Scratch?》翻译与解读 导读:ProgramBench 把软件工程 agent 的评测从“局部修补”推进到“从零重建程序”,通过程序文档、行为级测试和 agent-driven fuzzing …...
)
奇点大会「隐形议程」住宿推荐:主办方未公布的3家闭门交流友好型酒店(含私密会议室共享权限与静音舱预约入口)
更多请点击: https://intelliparadigm.com 第一章:奇点智能技术大会周边酒店推荐 参会者抵达主办城市后,便捷、稳定且具备基础协作设施的住宿环境至关重要。以下推荐均基于步行至主会场(国家人工智能创新中心)≤15分钟…...

2025最权威的AI学术平台实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 智能写作辅助工具DeepSeek,能在论文创作的全程给予支持。进入选题阶段࿰…...

N_m3u8DL-RE终极实战指南:三步破解流媒体下载技术难题
N_m3u8DL-RE终极实战指南:三步破解流媒体下载技术难题 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE …...

高速接口EMI抑制:共模扼流圈选型与设计实战
1. 高速数据接口中的EMI挑战与共模扼流圈原理在USB3.1 Gen2、HDMI2.1等高速数据接口设计中,信号完整性工程师最头疼的问题莫过于电磁干扰(EMI)。当数据传输速率突破10Gbps时,电缆会变成高效的天线,将共模噪声辐射到周围…...