数据结构之八大基本排序方法
在数据结构中,排序是一个重要的操作,它有助于提高数据的可读性和可操作性。排序算法有多种,各有优缺点,适用于不同的场景。以下是八大经典排序算法的介绍:
1. 冒泡排序(Bubble Sort)
原理:通过重复遍历要排序的数组,每次比较相邻的两个元素,如果它们的顺序错误就交换它们的位置。这样,最大的元素会逐步“冒泡”到数组的末尾。
时间复杂度:O(n^2)
代码示例:
void bubbleSort(std::vector<int>& arr) {int n = arr.size();for (int i = 0; i < n - 1; ++i) {for (int j = 0; j < n - i - 1; ++j) {if (arr[j] > arr[j + 1]) {std::swap(arr[j], arr[j + 1]);}}}
}
2. 选择排序(Selection Sort)
原理:每次从未排序部分选择最小的元素,放到已排序部分的末尾。
时间复杂度:O(n^2)
代码示例:
void selectionSort(std::vector<int>& arr) {int n = arr.size();for (int i = 0; i < n - 1; ++i) {int minIndex = i;for (int j = i + 1; j < n; ++j) {if (arr[j] < arr[minIndex]) {minIndex = j;}}std::swap(arr[i], arr[minIndex]);}
}
3. 插入排序(Insertion Sort)
原理:构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
时间复杂度:O(n^2)
代码示例:
void insertionSort(std::vector<int>& arr) {int n = arr.size();for (int i = 1; i < n; ++i) {int key = arr[i];int j = i - 1;while (j >= 0 && arr[j] > key) {arr[j + 1] = arr[j];--j;}arr[j + 1] = key;}
}
4. 希尔排序(Shell Sort)
原理:是插入排序的一种改进,通过将数组分割成若干子序列分别进行插入排序,从而加快排序速度。
时间复杂度:O(n log n) ~ O(n^2)
代码示例:
void shellSort(std::vector<int>& arr) {int n = arr.size();for (int gap = n / 2; gap > 0; gap /= 2) {for (int i = gap; i < n; ++i) {int temp = arr[i];int j;for (j = i; j >= gap && arr[j - gap] > temp; j -= gap) {arr[j] = arr[j - gap];}arr[j] = temp;}}
}
5. 归并排序(Merge Sort)
原理:采用分治法,将数组分成两部分分别排序,然后合并排序结果。
时间复杂度:O(n log n)
代码示例:
void merge(std::vector<int>& arr, int l, int m, int r) {int n1 = m - l + 1;int n2 = r - m;std::vector<int> L(n1), R(n2);for (int i = 0; i < n1; ++i) {L[i] = arr[l + i];}for (int j = 0; j < n2; ++j) {R[j] = arr[m + 1 + j];}int i = 0, j = 0, k = l;while (i < n1 && j < n2) {if (L[i] <= R[j]) {arr[k++] = L[i++];} else {arr[k++] = R[j++];}}while (i < n1) {arr[k++] = L[i++];}while (j < n2) {arr[k++] = R[j++];}
}void mergeSort(std::vector<int>& arr, int l, int r) {if (l < r) {int m = l + (r - l) / 2;mergeSort(arr, l, m);mergeSort(arr, m + 1, r);merge(arr, l, m, r);}
}
6. 快速排序(Quick Sort)
原理:选择一个基准元素,通过一趟排序将待排序数组分成两部分,其中一部分比基准元素小,另一部分比基准元素大,然后递归地对这两部分分别进行快速排序。
时间复杂度:平均O(n log n),最坏O(n^2)
代码示例:
int partition(std::vector<int>& arr, int low, int high) {int pivot = arr[high];int i = (low - 1);for (int j = low; j <= high - 1; ++j) {if (arr[j] < pivot) {std::swap(arr[++i], arr[j]);}}std::swap(arr[i + 1], arr[high]);return (i + 1);
}void quickSort(std::vector<int>& arr, int low, int high) {if (low < high) {int pi = partition(arr, low, high);quickSort(arr, low, pi - 1);quickSort(arr, pi + 1, high);}
}
7. 堆排序(Heap Sort)
原理:利用堆这种数据结构来排序。最大堆用于升序排序,最小堆用于降序排序。
时间复杂度:O(n log n)
代码示例:
void heapify(std::vector<int>& arr, int n, int i) {int largest = i;int left = 2 * i + 1;int right = 2 * i + 2;if (left < n && arr[left] > arr[largest]) {largest = left;}if (right < n && arr[right] > arr[largest]) {largest = right;}if (largest != i) {std::swap(arr[i], arr[largest]);heapify(arr, n, largest);}
}void heapSort(std::vector<int>& arr) {int n = arr.size();for (int i = n / 2 - 1; i >= 0; --i) {heapify(arr, n, i);}for (int i = n - 1; i >= 0; --i) {std::swap(arr[0], arr[i]);heapify(arr, i, 0);}
}
8. 计数排序(Counting Sort)
原理:适用于元素范围较小的数组,利用数组下标进行排序。
时间复杂度:O(n + k),其中k是最大值和最小值的范围
代码示例:
void countingSort(std::vector<int>& arr) {int max = *std::max_element(arr.begin(), arr.end());int min = *std::min_element(arr.begin(), arr.end());int range = max - min + 1;std::vector<int> count(range), output(arr.size());for (int i = 0; i < arr.size(); ++i) {count[arr[i] - min]++;}for (int i = 1; i < count.size(); ++i) {count[i] += count[i - 1];}for (int i = arr.size() - 1; i >= 0; --i) {output[count[arr[i] - min] - 1] = arr[i];count[arr[i] - min]--;}for (int i = 0; i < arr.size(); ++i) {arr[i] = output[i];}
}
总结
这些排序算法各有优劣,选择合适的排序算法需要根据数据规模和具体场景来决定。一般来说,快速排序和归并排序适用于大多数情况,而像计数排序则适用于特定条件下的排序。
相关文章:

数据结构之八大基本排序方法
在数据结构中,排序是一个重要的操作,它有助于提高数据的可读性和可操作性。排序算法有多种,各有优缺点,适用于不同的场景。以下是八大经典排序算法的介绍: 1. 冒泡排序(Bubble Sort) 原理&…...

《Milvus Cloud向量数据库指南》——什么是高可用:深入理解数据库系统中的高可用性架构
什么是高可用:深入理解数据库系统中的高可用性架构 在信息技术日新月异的今天,高可用性(High Availability,简称HA)已成为衡量一个系统,尤其是数据库系统稳定性和可靠性的重要标准。高可用性的核心目标在于确保系统能够持续不断地提供服务,最大限度地减少因维护活动、硬…...

C++ | Leetcode C++题解之第319题灯泡开关
题目: 题解: class Solution { public:int bulbSwitch(int n) {return sqrt(n 0.5);} };...

C# 使用 NLog 输出日志到文件夹
在项目中使用 NuGet 安装 NLog 包以及 NLog.Config 包 配置 nlog.config 在项目的根目录下创建一个 Nlog.config 文件(如果还没有),然后添加如下配置: <?xml version"1.0" encoding"utf-8" ?> <…...

node.js使用NodeMachineID 生成唯一UUID和注意事项
node-machine-id用于获取或生成唯一的机器ID 如何使用 const { machineId, machineIdSync } require(node-machine-id) JSON.stringify(machineIdSync({original: true})) ;方法: machineIdSync 此函数同步获取操作系统本机UUID/GUID,默认情况下进行哈…...

AI大模型在数据治理中的应用
目前,企业的数据治理工作以人工实施为主,其中一些重复性较强的工作,如:数据标准制定和映射、元数据信息完善、数据目录挂载等,需要消耗大量的人力和时间成本,这给本来就难以量化业务价值的治理工作的顺利推…...
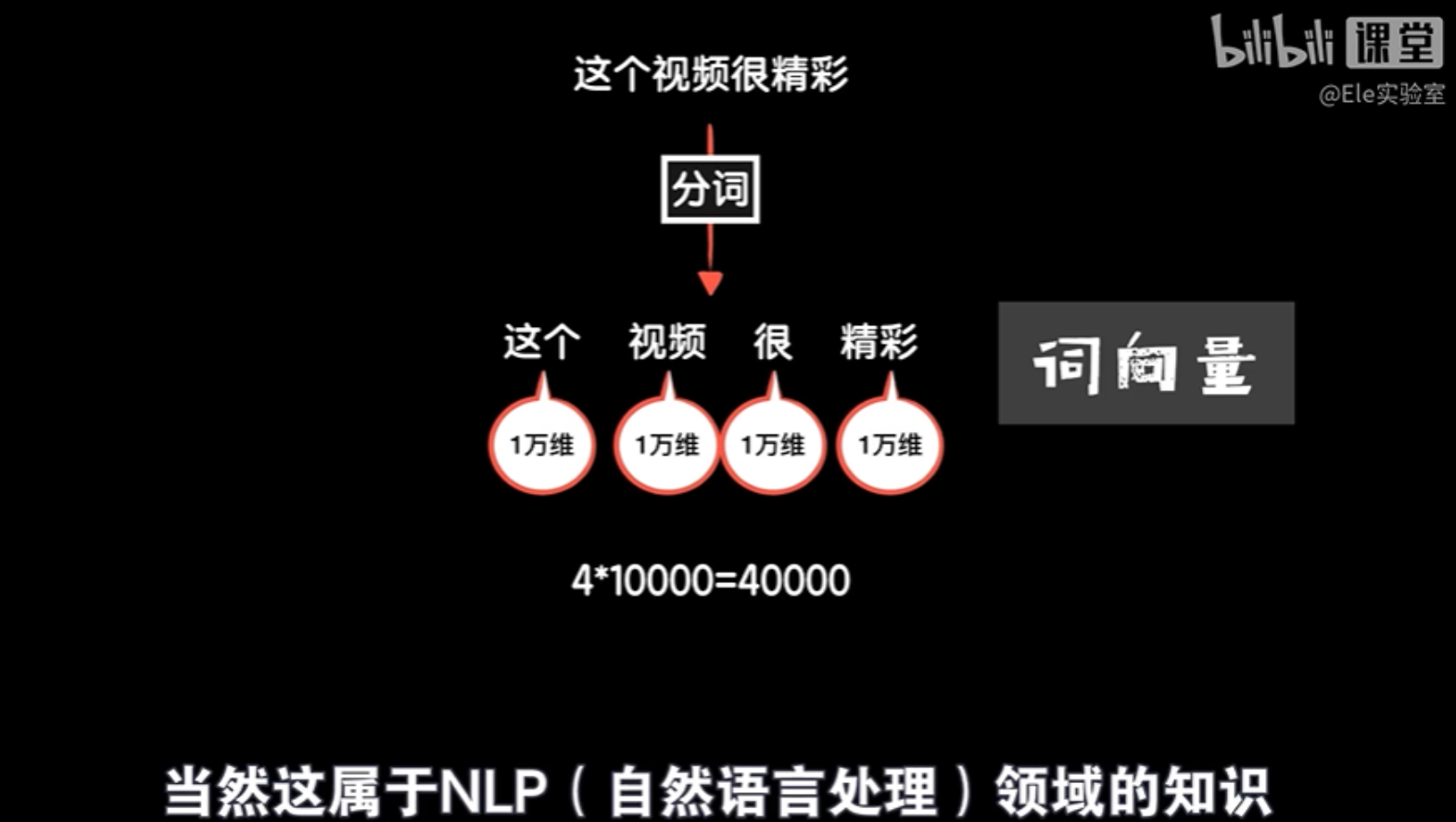
【初学人工智能原理】【12】循环:序列依赖问题
前言 本文教程均来自b站【小白也能听懂的人工智能原理】,感兴趣的可自行到b站观看。 代码及工具箱 本专栏的代码和工具函数已经上传到GitHub:1571859588/xiaobai_AI: 零基础入门人工智能 (github.com),可以找到对应课程的代码 正文 对于…...

【QT】无法打开QT的ui文件,出现闪退情况
打开qt的ui文件出现闪退的情况: 解决办法:点击扩展-Qt VS Tools-Options 找到Qt General中的Qt Designer 的Run in detached window改为True。...

三、Spring-WebFlux实战案例-流式
目录 一、springboot之间通讯方式 1. 服务端 (Spring Boot) 1.1 添加依赖 1.2 控制器 2. 客户端 (WebClient) 2.1 添加依赖 2.2 客户端代码 3. 运行 二、web与服务之间通讯方式 1、服务端代码 2、客户端代码 3、注意事项 三、移动端与服务端之间通讯方式…...

html+css 实现hover双层按钮
前言:哈喽,大家好,今天给大家分享htmlcss 绚丽效果!并提供具体代码帮助大家深入理解,彻底掌握!创作不易,如果能帮助到大家或者给大家一些灵感和启发,欢迎收藏关注哦 💕 文…...

SPIFFS与LittleFS的对gz文件格式的区别
SPIFFS 只能安装在Arduino上。LittleFS支持Arduino IDE和VScode的 PlatformIO。 SPIFFS serveStatic: server.serveStatic("/", SPIFFS, "/") 负责提供 SPIFFS 文件系统中的文件。您可以在 SPIFFS 上放置 .gz 文件,并该方法将自动处理它们。 …...

STM32L051K8U6-开发资料
STM32L051测试 (四、Flash和EEPROM的读写)-云社区-华为云 (huaweicloud.com) STM32L051测试 (四、Flash和EEPROM的读写) - 掘金 (juejin.cn) STM32L0 系列 EEPROM 读写,程序卡死?_stm32l0片内eeprom_stm3…...

Markdown语法学习
Markdown学习 一、基础语法讲解 1. 换行 本行末尾双空格然后回车(在Typora的中直接回车也可以) 2. 换段 本段末尾两次回车 3. 加粗 **加粗** __加粗__效果:加粗 4. 斜体 *加粗* _加粗_效果:斜体 5. 斜体加粗 ***加粗**…...

[最短路Floyd],启动!!!
B3647 【模板】Floyd #include<bits/stdc.h> #define ll long long #define fi first #define se second #define pb push_back #define PII pair<int,int > #define IOS ios::sync_with_stdio(false),cin.tie(0),cout.tie(0) using namespace std; const int N …...
7月29(信息差)
🌍最强模型 Llama 3.1 如期而至!扎克伯格最新访谈:Llama 会成为 AI 界的 Linux 🎄谷歌AlphaProof攻克国际奥赛数学题 https://www.51cto.com/article/793632.html ✨SearchGPT第一波评测来了!响应速度超快还没广告&…...

ubuntu中禁止使用鼠标拖动来移动文件
windows和ubuntu中都可以拖动文件到其他路径,然后达到移动文件的目的。 这种方式有好处也有坏处,好处是移动文件方便了,坏处是误操作后会造成故障,尤其是ubuntu中,本身鼠标就特别灵敏并且操作不便,拖动一个…...

【密码学】椭圆曲线密码体制(ECC)
椭圆曲线密码体制(Elliptic Curve Cryptography, ECC)是一种基于椭圆曲线数学特性的公钥密码系统。在介绍椭圆曲线之前,我们先来了解一下椭圆曲线的基本概念。 一、椭圆曲线是什么? (1)椭圆曲线的数学定义…...
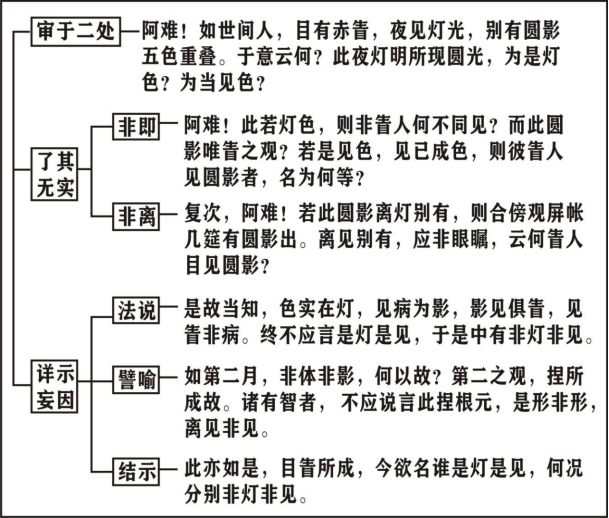
第25集《大佛顶首楞严经》
丑二、腾疑细释 分二:寅一、阿难腾疑;寅二、如来细释 请大家打开讲义第五十六页,“丑二、腾疑细释”。 本经的修学重点,就是修学首楞严王三昧。它的整个重点,其实就是一个心地法门。我们在行菩萨道的时候慢慢会发觉…...
 详细解析)
python 读写文件之 open 和 with open() 详细解析
python 读写文件之 open 和 with open() 详细解析 文章目录 python 读写文件之 open 和 with open() 详细解析1. open() 和 with open() 能打开不同的文件类型吗?2. 文本文件和二进制文件的区别2.1 文本文件 (Text Files)2.2 二进制文件 (Binary Files)区别 3. 读文…...

操作系统:内存----知识点
什么是虚拟内存? 虚拟内存简称虚存,是计算机系统内存管理的一种技术。它是相对于物理内存而言的,可以理解为“假的”内存。它使得应用程序认为它拥有连续可用的内存(一个连续完整的地址空间),允许程序员编…...

OpenCode 的工具体系:给大模型装上操控代码库的“手”与“眼
要在代码库里真正帮上忙,光有聪明的脑子还不够,大语言模型(LLM)还需要能够执行具体操作的“工具”。OpenCode 把这些工具视为模型与项目环境之间的纽带——读取文件、修改代码、运行命令、查文档,甚至主动上网搜索&…...

Spring MVC 的核心知识点梳理
MVC 是什么 MVC 不是 Spring 发明的,而是一种设计模式,目的是“解耦”。 M(Model,模型):数据 业务逻辑。比如 Teacher 类,TeacherService。V(View,视图)&…...

基于Electron构建macOS效率工具:插件化命令执行与安全实践
1. 项目概述:一个为macOS开发者量身打造的效率工具 最近在GitHub上看到一个挺有意思的项目,叫 zhaobomin/copaw-macapp 。乍一看名字, copaw 这个组合词有点意思,结合 macapp 的后缀,不难猜出这是一个专门为macO…...

60GHz室内无线骨干网:技术原理、部署实战与成本分析
1. 室内无线骨干网:从“有线为王”到“毫米波革命”的必然演进 干了十几年通信网络规划和部署,我亲眼见证了从百兆以太网到万兆光缆,再到如今无处不在的Wi-Fi 6E和5G小基站。但最近和几个做智慧工厂、大型场馆项目的同行聊下来,大…...

基于 Harmony6.0 的城市空气质量监测页面开发实践:ArkUI 页面构建与跨端能力深度解析
基于 Harmony6.0 的城市空气质量监测页面开发实践:ArkUI 页面构建与跨端能力深度解析 前言 随着 HarmonyOS NEXT 与 Harmony6.0 的持续演进,鸿蒙生态已经不再只是“多设备互联”这么简单,而是逐渐形成了一套完整的分布式应用开发体系。相比传…...
)
下载 | Win11 官方精简版,系统占用空间极少!(4月末更新、Win11 IoT物联网 LTSC版、适合老电脑安装使用)
⏩ 【资源A023】Win11 LTSC 2024 ISO系统映像 🔶Win11 物联网IoT LTSC版,默认无TPM等硬件限制,更方便老电脑安装使用。LTSC是长期服务渠道版本,网友俗称“老坛酸菜版”,相当于微软官方的精简版Win11,精简了…...

EDA工程师成长与验证技术演进:从算法到芯片的实践闭环
1. 从算法到芯片:一位EDA工程师的成长路径解析在半导体这个行当里待久了,你会发现,那些真正能把工具做“透”、把流程理“顺”的人,往往自己就亲手“焊”过板子、调过RTL、追过时序违例。Prakash Narain的故事,就是一个…...

Python: Condition Variable Pattern
项目结构: # encoding: utf-8 # 版权所有 2026 ©涂聚文有限公司™ # 许可信息查看:言語成了邀功盡責的功臣,還需要行爲每日來值班嗎 # 描述:Condition Variable Pattern 条件变量模式 # Author : geovindu,Geovin Du …...

【ROS进阶-1】从零构建自定义消息:实战配置与编译全解析
1. 为什么需要自定义ROS消息 在ROS开发中,消息是节点间通信的基础载体。虽然ROS已经提供了丰富的标准消息类型,比如std_msgs、geometry_msgs等,但在实际项目中,我们经常会遇到标准消息无法满足需求的情况。就像在C编程中ÿ…...

CANN/asc-devkit Trunc截断函数API
Trunc 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/cann…...