vLLMcuda安装笔记
1. 引言
最近在部署Qwen模型时,文档上有提到强烈建议用vLLM来部署模型,按照公开的性能测试数据,用vLLM部署Qwen模型的文本推理速度要比transformers部署快3~4倍。带着这个好奇就开始安装尝试,但试下来这个安装过程并没有那么顺利,便有了此文来记录整个环境搭建的过程。
vLLM是伯克利大学LMSYS组织开源的大语言模型高速推理框架,利用了全新的注意力算法「PagedAttention」,有效地管理Attention中的K和V。在吞吐量方面,vLLM的性能比HuggingFace Transformers(HF)高出 24 倍,文本生成推理(TGI)高出3.5倍。
2. vLLM环境要求
vLLM的安装指导说明上对python和cuda有着明确的版本要求,如下面截图所示:
vLLM安装指导地址:https://docs.vllm.ai/en/latest/getting_started/installation.html

首先是python,由于前面在不知情的情况下,已经安装了最新的python3.12版本,那就只能新创建一个3.10的虚拟环境。
conda及虚拟环境的创建请参考:conda环境搭建笔记
其次是cuda,vLLM是拿12.1版本编译的,但本地机器装的cuda为12.0,尝试过向下兼容的方式后无果,最终选择按照官方建议的cuda-12.1来重新安装,这意味着不仅仅是vLLM,机器上已经安装的pytorch、cuda都需要重新安装。
安装说明上有提供cuda-11.8的版本,正好之前pytorch安装时选择的也是cuda-11.8,所以尝试过取巧直接安装11.8,但最终没有成功,报一些cuda.C的一些.so动态库找不到(具体信息未能保留下来),就放弃了。

由于cuda是pytorch和vLLM的基础依赖,首先需要重装cuda。
3. CUDA安装
3.1 下载安装包
下载网址:https://developer.nvidia.com/cuda-toolkit-archive
首先选择自己要安装的版本(12.1):

逐个勾选自己的环境信息,勾选完后下面会自动出现与所选环境匹配的安装指令:


先复制上面的wget指令,下载文件(文件有4G,需要下一段时间)。

3.2 安装
下载完后执行如下命令开始安装。
sudo sh cuda_12.1.0_530.30.02_linux.run
安装程序正式开始复制文件之前,可能会有两个小插曲(具体与本地环境有关):旧环境兼容性检测和GPU是否在使用的检查。
3.2.1 旧环境兼容性检测
刚启动安装时会执行对本地旧环境的兼容性检测,如果发现本地机器的nvidia驱动与要安装的cuda版本不一致,安装程序会强烈建议你将已经存在的nvidia驱动卸载(命令如下面所示)。
apt-get remove --purge nvidia-driver-530
apt-get autoremove
需要注意的是此命令的用途,它会将机器上已经存在的nvidia驱动删除,个人猜测目的可能是为了保持cuda与的nvidia驱动的版本一致。
这里尝试过不卸载,但没有成功,cuda与nvidia版本不一致可能会导致驱动无法工作,运行nvidia-smi命令报如下截图中错误,最后还是乖乖按照指示进行了删除操作。

3.2.2 GPU是否在使用的检查
安装程序会检测GPU是否在使用中,如果在使用中,会提示退出所有GPU之后才能继续安装。
如果此时nvidia-smi命令可用,可以从命令输出结果中看到哪个进程在使用GPU:

查到被占用的GPU序号(上面截图中是0),则可以用如下命令来释放GPU:
sudo nvidia-smi --gpu-reset -i 0
GPU 00000000:3E:00.0 was successfully reset.
All done.
上面的方法是基于nvidia-smi存在的情况下,但是如果前面已经卸载了nvidia驱动程序(nvidia-smi命令也会被删除),那用什么方法查看GPU的状态呢?
用fuser命令能够列出哪些进程在使用GPU,然后使用kill命令将这些进程结束就行。
# 查找所有使用GPU的进程
sudo fuser -v /dev/nvidia*
sudo kill -9 <PID>

3.2.3 主流程安装
之后会提示你去勾选要安装的功能清单,用默认就好。

安装过程中,如果前面卸载了nvidia驱动程序,此时会自动安装与cuda版本配套的nvidia驱动程序,而cuda则会被安装到/usr/local/cuda-12.1目录下,安装完后的磁盘位置如下图所示:

3.3 配置环境变量
将cuda的库和命令添加到环境变量中。
echo 'export PATH=/usr/local/cuda-12.1/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda-12.1/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
验证cuda安装结果:
nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Tue_Feb__7_19:32:13_PST_2023
Cuda compilation tools, release 12.1, V12.1.66
Build cuda_12.1.r12.1/compiler.32415258_0
验证nvidia驱动程序安装结果:
可以看到,这里显示的cuda version和上面nvcc命令显示的版本是一致的。

4. 重装pytorch
之前pytorch是基于cuda-11.8安装的,当上面cuda版本变更后,需要重新选择能适配cuda-12.1的pytorch版本重新安装。
注:pytorch一定要先于vllm来安装,因为vllm安装时会检测本地机器的cuda和pytorch是否满足版本要求,如果没有匹配的依赖,vllm是无法安装的。

具体过程这里就不细列,详情见: conda&pytorch环境搭建笔记
5. vllm
5.1 安装vllm
前面的cuda和pytorch都使用官方建议的版本后,安装vllm的命令就和正常库的安装命令一样,但是由于下载的软件包很多,这个过程也会比较长。
pip install vllm
安装完成后如下图所示:

验证vllm的安装结果:
!pip show vllm
WARNING: Ignoring invalid distribution -orch (/data2/anaconda3/envs/python3_10/lib/python3.10/site-packages)
Name: vllm
Version: 0.5.3.post1
Summary: A high-throughput and memory-efficient inference and serving engine for LLMs
Home-page: https://github.com/vllm-project/vllm
Author: vLLM Team
Author-email:
License: Apache 2.0
Location: /data2/anaconda3/envs/python3_10/lib/python3.10/site-packages
Requires: aiohttp, cmake, fastapi, filelock, lm-format-enforcer, ninja, numpy, nvidia-ml-py, openai, outlines, pillow, prometheus-client, prometheus-fastapi-instrumentator, psutil, py-cpuinfo, pydantic, pyzmq, ray, requests, sentencepiece, tiktoken, tokenizers, torch, torchvision, tqdm, transformers, typing-extensions, uvicorn, vllm-flash-attn, xformers
Required-by:
5.2 验证vllm功能
在jupyter里贴一段加载模型的代码,尝试将本地下载好的模型Load进来:
from transformers import AutoTokenizer
from vllm import LLM, SamplingParamsmodel_dir = "/data2/anti_fraud/models/modelscope/hub/Qwen/Qwen2-0___5B-Instruct"
# Initialize the tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_dir)# max_tokens is for the maximum length for generation.
sampling_params = SamplingParams(temperature=0.7, top_p=0.8, repetition_penalty=1.05, max_tokens=512)# Input the model name or path. Can be GPTQ or AWQ models.
llm = LLM(model=model_dir)

再贴一段代码来测试模型是否能正常推理:
# Prepare your prompts
prompt = "Tell me something about large language models."
messages = [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True
)# generate outputs
outputs = llm.generate([text], sampling_params)# Print the outputs.
for output in outputs:prompt = output.promptgenerated_text = output.outputs[0].textprint(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
生成的文本如下:

参考资料:
- conda&pytorch环境搭建笔记
- cuda-tool 官方下载地址
- vllm部署Qwen说明文档
相关文章:
vLLMcuda安装笔记
1. 引言 最近在部署Qwen模型时,文档上有提到强烈建议用vLLM来部署模型,按照公开的性能测试数据,用vLLM部署Qwen模型的文本推理速度要比transformers部署快3~4倍。带着这个好奇就开始安装尝试,但试下来这个安装过程并没有那么顺利…...

C++入门基本语法(2)
一、引用 1、基本概念与定义 引用不是新定义一个变量,而是给已存在的变量起一个别名,编译器不会为引用变量开辟内存空间,它和它所引用的变量公用同一块内存空间; 引用的写法:变量类型& 引用别名 变量ÿ…...

Internet Download Manager(IDM)2024中文版本有哪些新功能?6.42版本功能介绍
1. Internet Download Manager(IDM)是一款功能强大的下载管理器,支持所有流行的浏览器,并可提升下载速度高达5倍。 2. IDM具有智能下载逻辑加速器,可以设置文件下载优先级、分块下载等,提高下载效率。 IDM…...

深入理解 C 语言中的联合体
目录 引言 一、 联合体的定义与基本用法 1.联合体的定义 2.基本用法 二、 联合体与结构体的区别 1.结构体 2.联合体 3.对比 三、联合体的优势 1. 节省内存 2. 提高效率 3. 代码简洁性 四、联合体的存储细节 1.内存对齐 2.大小计算 五、联合体的高级用法 1.匿…...
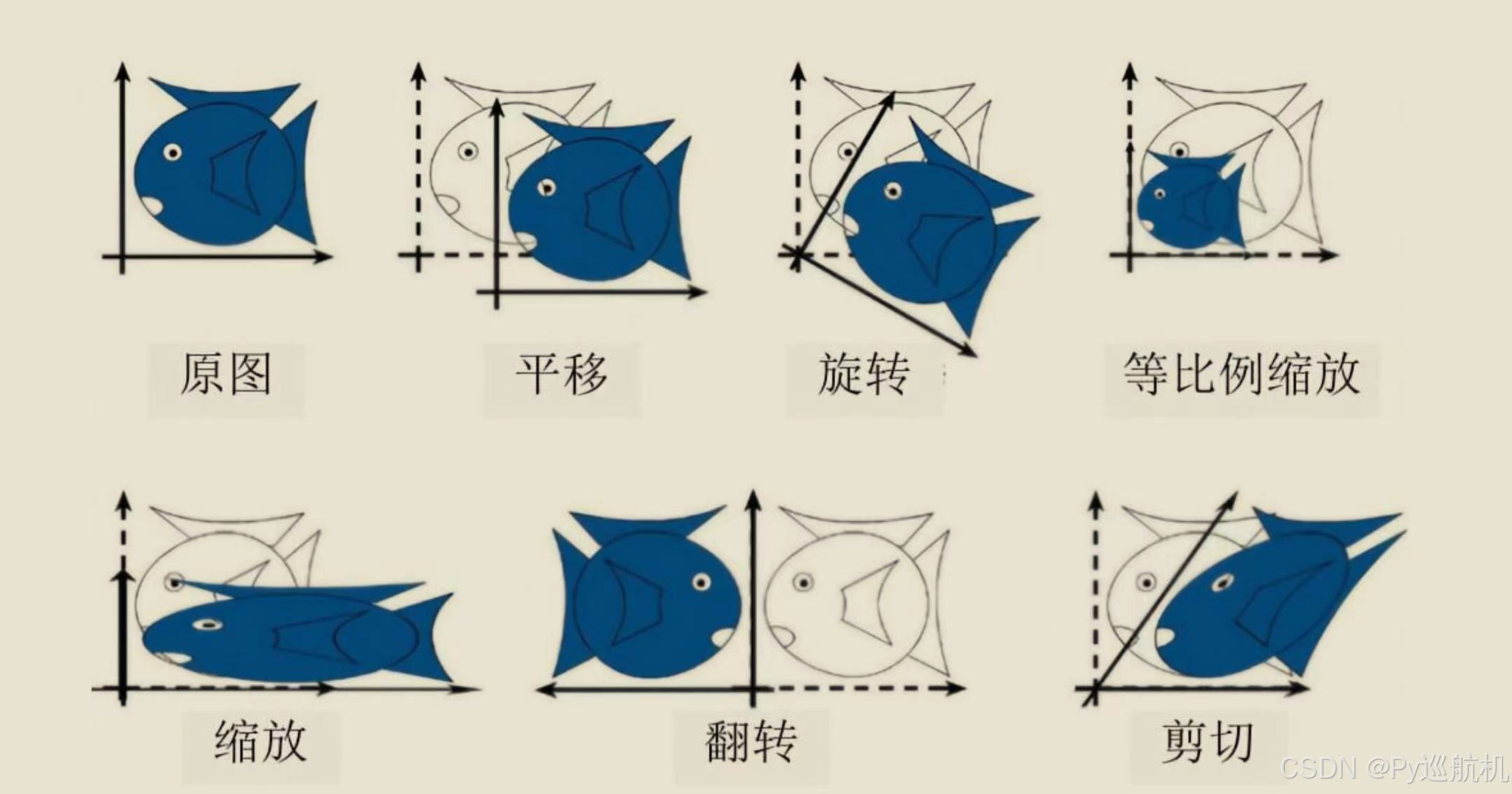
OpenCV||超详细的几何变换
2D图像几何变换的33矩阵: 图像常见的几何变换: 图像来源:《OpenCV 4.5计算机视觉开发实战:基于Python》作者:朱文伟 李建英; 1. 平移(Translation) 在OpenCV中,平移不是…...

网络程序设计基础概述
文章目录 前言一、网络程序设计基础二、网络协议 1.IP协议2.TCP与UDP协议三、端口与套接字总结 前言 网络程序设计编写的是与其他计算机进行通信的程序代码。Java将网络程序所需要的东西封装成了不同的类。开发者只需要创建这些类的对象,调用相应的方法,…...
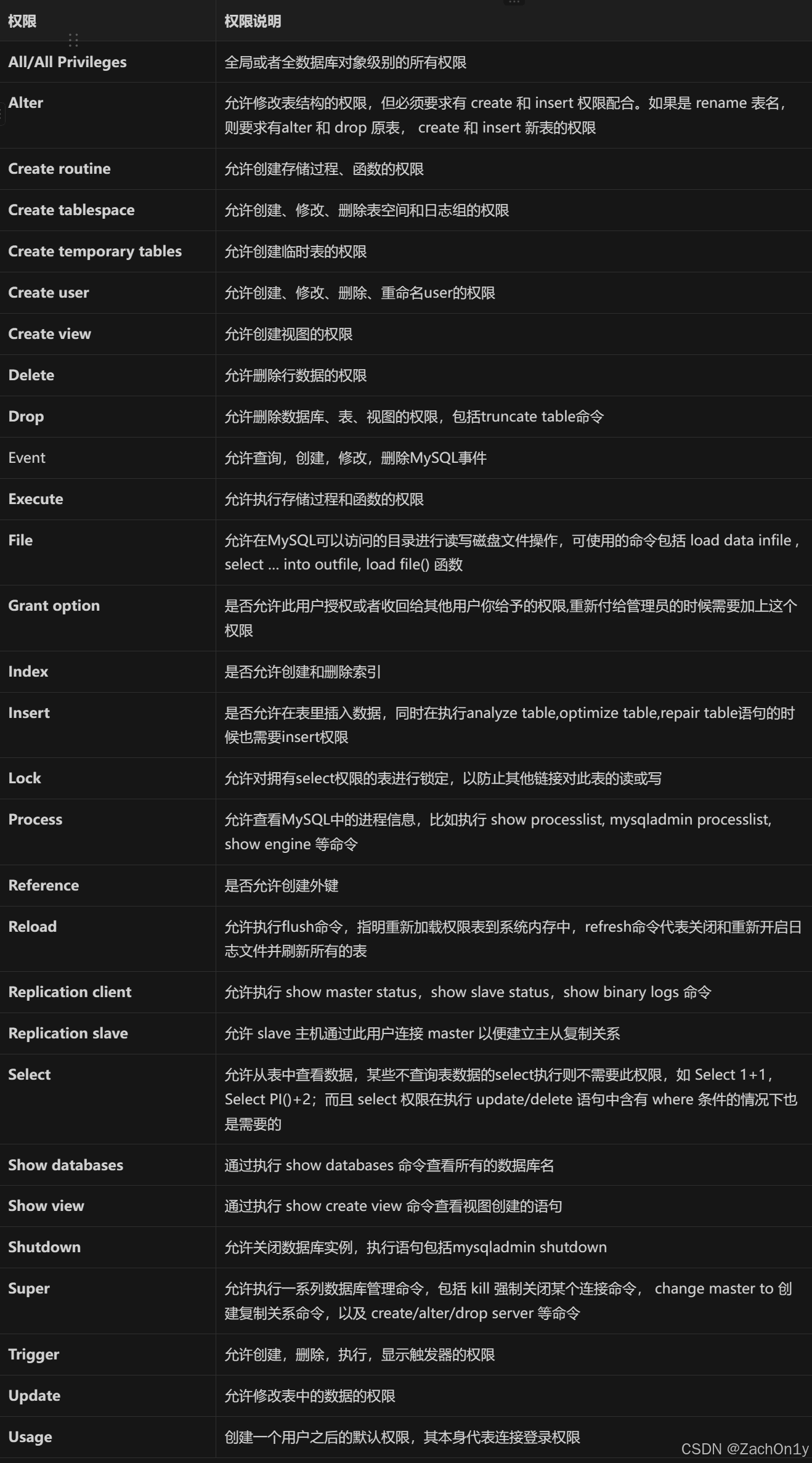
MySQL:数据库用户
数据库用户 在关系型数据库管理系统中,数据库用户(USER)是指具有特定权限和访问权限的登录账户。每个用户都有自己的用户名和密码,以便系统可以通过认证来识别他们的身份。数据库用户可以登录数据库,在其中执行各种类…...
用TensorFlow训练自己的第一个模型
现在学AI的一个优势就是:前人栽树后人乘凉,很多资料都已完善,而且有很多很棒的开源作品可以学习,感谢大佬们 项目 项目源码地址 视频教程地址 我在大佬的基础上基于此模型还加上了根据特征值缓存进行快速识别的方法,…...
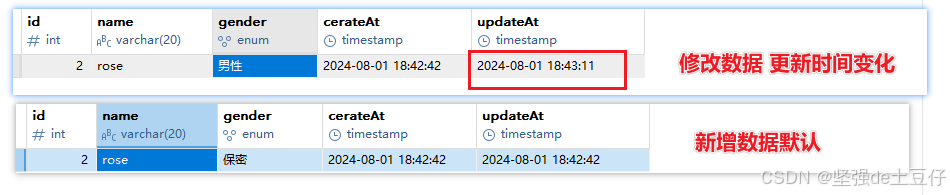
MySQL数据库入门基础知识 【1】推荐
数据库就是储存和管理数据的仓库,对数据进行增删改查操作,其本质是一个软件。 首先数据有两种,一种是关系型数据库,另一种是非关系型数据库。 关系型数据库是以表的形式来存储数据,表和表之间可以有很多复杂的关系&a…...

Anaconda下的 jupyter notebook安装及使用
安装 打开Anaconda Powershell Prompt或Anconda Prompt 输入命令conda install jupyter notebook进行安装 启动 切换到工作目录,输入命令jupyter notebook等待浏览器打开网页 命令行启动jupyter notebook的链接复制到浏览器同样可以打开jupyter notebook 在Ancon…...
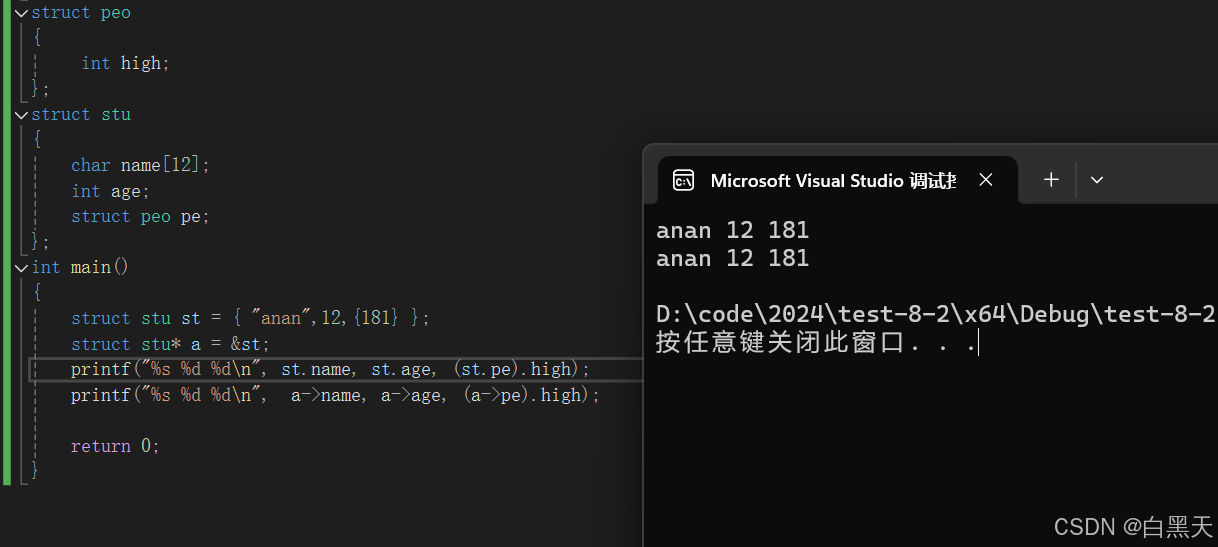
C语言初阶(11)
1.结构体定义 结构体就是一群数据类型的集合体。这些数据类型被称为成员变量。结构的成员可以是标量、数组、指针,甚至是其他结构体。 2.结构体的声明和结构体变量命名与初始化 结构体声明由以下结构组成 struct stu {char name[12];int age; }; 结构体命名有两…...
Unity获取Animator动画播放完成事件
整理了一些在日常经验中处理动画播放完成事件的方法 方法: 1.Dotween配合异步实现 2.状态机计时方法实现 3.原生动画行为方法实现 方法一:Dotween异步方法 using UnityEngine; using System.Threading.Tasks; using DG.Tweening;public class PlayerAnimAsync : M…...

git submodule 使用
在Git中,子模块(submodule)是一种将一个Git仓库作为另一个Git仓库的子目录嵌入的方式。这使得主仓库能够跟踪和管理对外部依赖的更改。 添加子模块 初始化父仓库:如果你还没有创建父仓库,先创建它。 添加子模块&…...
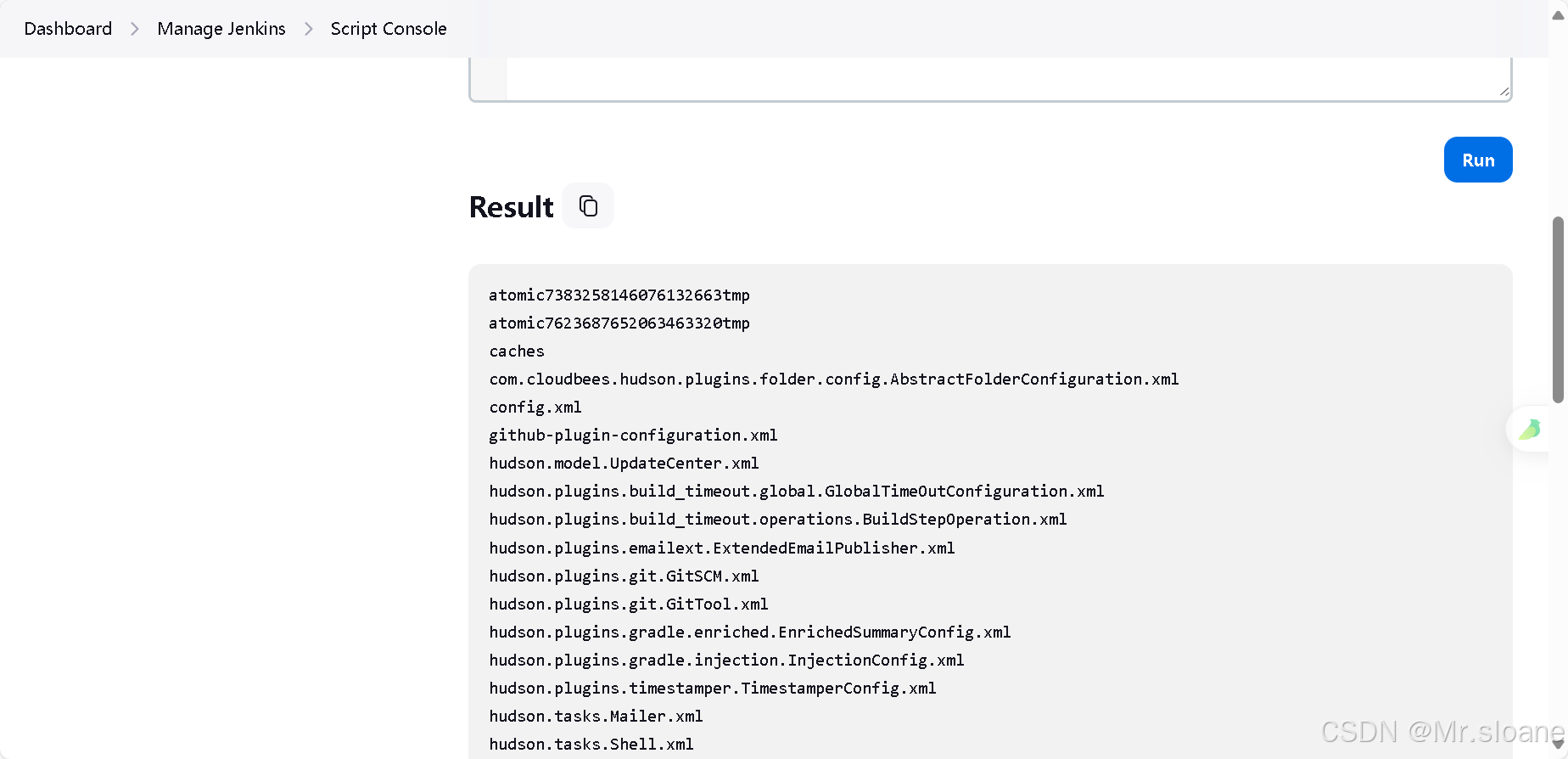
【Jenkins未授权访问漏洞 】
默认情况下 Jenkins面板中用户可以选择执行脚本界面来操作一些系统层命令,攻击者可通过未授权访问漏洞或者暴力破解用户密码等进入后台管理服务,通过脚本执行界面从而获取服务器权限。 第一步:使用fofa语句搜索 搜索语句: port&…...

前端处理 Excel 文件
引入XLSX XLSX 是一个流行的 JavaScript 库,用于处理 Excel 文件(包括 .xls 和 .xlsx 格式)。它可以在 Node.js 环境和浏览器中运行,提供了丰富的 API 来读取、写入、修改 Excel 文件。当你使用 import * as XLSX from xlsx; 这行…...

(vue)el-cascader级联选择器按勾选的顺序传值,摆脱层级约束
(vue)el-cascader级联选择器按勾选的顺序传值,摆脱层级约束 需求:按勾选的顺序给后端传值 难点:在 Element UI 的 el-cascader 组件中,默认的行为是根据数据的层级结构来显示选项,用户的选择也会基于这种层级结构,el-…...

Redis进阶(四):哨兵
为了解决主节点故障,需要人工操作切换主从的情况;因此需要一种方法可以自动化的切换:哨兵的引入大大改变这种情况。 哨兵的基本概念 自动切换主从节点 哨兵架构 1、当一个哨兵节点发现主节点挂了的时候,还需要其他节点也去检测一…...

蓝屏事件:网络安全的启示
“微软蓝屏”事件暴露了网络安全哪些问题? 近日,一次由微软视窗系统软件更新引发的全球性“微软蓝屏”事件,不仅成为科技领域的热点新闻,更是一次对全球IT基础设施韧性与安全性的深刻检验。这次事件,源于美国电脑安全技…...

技术方案评审原则
系列文章目录 提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加 TODO:写完再整理 文章目录 系列文章目录前言技术方案评审原则1.理论突破阶段2.技术突破阶段3.工程化阶段自动驾驶行业的技术方案分析前言 认知有限,望大家多多包涵,有什么问题也希望能够与大…...
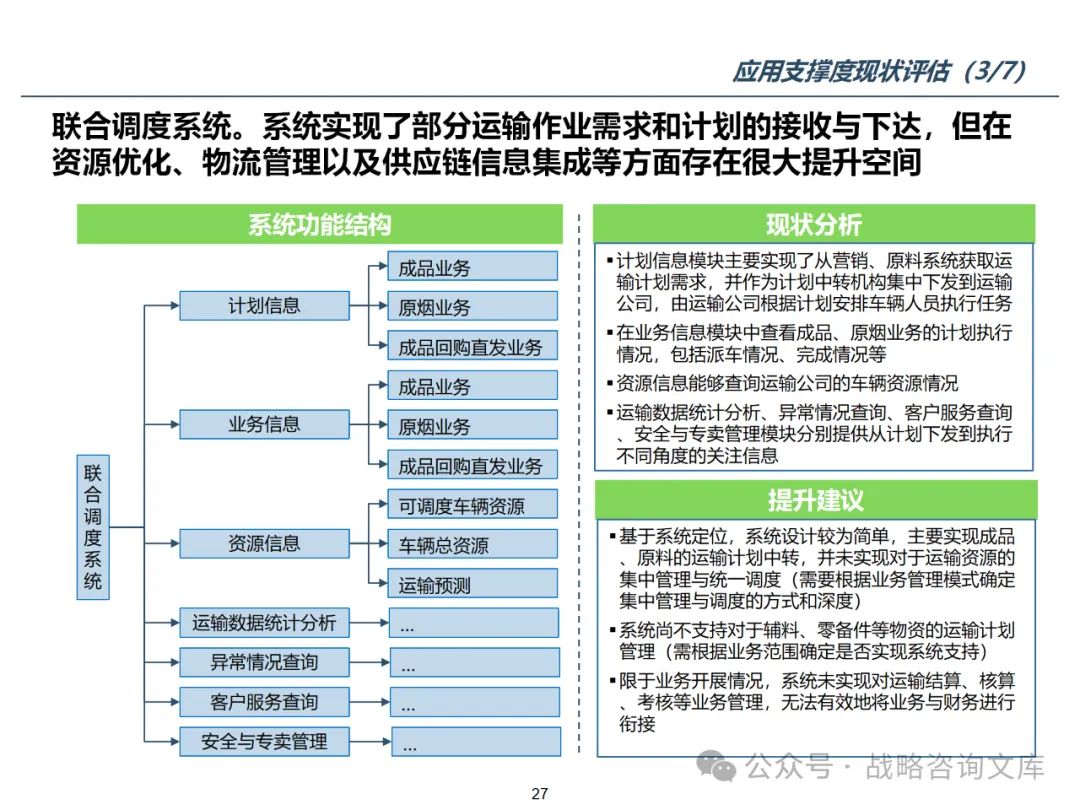
117页PPT埃森哲-物流行业信息化整体规划方案
一、埃森哲-物流行业信息化整体规划方案 资料下载方式,请看每张图片右下角信息 埃森哲在物流行业信息化整体规划项目中的核心内容,旨在帮助物流企业通过信息技术的应用实现业务流程的优化、运营效率的提升以及市场竞争力的增强。以下是埃森哲在此类项目…...

Qwen3.5-2B部署教程:Conda+Supervisor环境一键拉起,告别手动配置
Qwen3.5-2B部署教程:CondaSupervisor环境一键拉起,告别手动配置 1. 前言:认识Qwen3.5-2B轻量化模型 Qwen3.5-2B是Qwen3.5系列中的轻量化多模态基础模型,仅有20亿参数规模,专为低功耗、低门槛部署场景设计。这个模型特…...

中科蓝讯AB565X蓝牙耳机通话电流音、回声、杂音?手把手教你用PC工具调通它
中科蓝讯AB565X蓝牙耳机通话问题全解析:从硬件排查到参数调优实战指南 当你手握一款基于中科蓝讯AB565X芯片的蓝牙耳机样机,却在通话测试中遭遇电流音、回声和杂音时,那种挫败感我深有体会。作为深耕音频调试领域多年的工程师,我经…...

保姆级教程:手把手教你本地部署Qwen2.5-7B-Instruct旗舰模型
保姆级教程:手把手教你本地部署Qwen2.5-7B-Instruct旗舰模型 1. 前言:为什么选择Qwen2.5-7B-Instruct Qwen2.5-7B-Instruct是阿里通义千问团队在2024年9月发布的最新旗舰级开源大语言模型。相比轻量级的1.5B/3B版本,7B参数规模带来了质的飞…...

给客户发固件,别再傻傻传源码了!手把手教你用ESP32 Download Tool烧录PlatformIO生成的bin文件
专业级ESP32固件交付方案:从PlatformIO编译到客户安全烧录全流程 当我们需要将开发完成的ESP32固件交付给客户时,直接发送源代码往往不是最佳选择。这不仅涉及知识产权保护问题,还可能因为客户缺乏开发环境而导致沟通成本激增。本文将详细介绍…...

等式方程的可满足性
class Solution {public:int find(vector<int>& father,int x){if(father[x]!x)father[x] find(father,father[x]);//如果father[x]不是源头,继续往前找return father[x];}void un(vector<int>& father,int x,int y){father[find(father,x)]fin…...

解锁B站视频下载:5个高效技巧让你轻松获取心仪内容
解锁B站视频下载:5个高效技巧让你轻松获取心仪内容 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/bi/B…...

OpenClaw开源贡献:Qwen3.5-4B-Claude技能PR提交流程
OpenClaw开源贡献:Qwen3.5-4B-Claude技能PR提交流程 1. 为什么要为OpenClaw贡献技能 去年冬天,我在尝试用OpenClaw自动化处理技术文档时,发现现有的技能库缺少对结构化推理任务的支持。当时我偶然在GitHub上看到了Qwen3.5-4B-Claude这个专门…...

深入解析Franka ROS2控制器:关节位置、速度、阻抗控制有何不同?
深入解析Franka ROS2控制器:关节位置、速度、阻抗控制的核心差异与实战选择 在工业自动化和机器人研究领域,精确控制机械臂的运动是实现复杂任务的基础。Franka Emika机械臂凭借其高精度力控能力和开放的ROS2接口,已成为学术研究和工业应用的…...

PatreonDownloader:一键批量下载Patreon创作者内容的终极解决方案
PatreonDownloader:一键批量下载Patreon创作者内容的终极解决方案 【免费下载链接】PatreonDownloader Powerful tool for downloading content posted by creators on patreon.com. Supports content hosted on patreon itself as well as external sites (additio…...

YOLOv7-d2实例分割深度教程:SparseInst模型原理与实战
YOLOv7-d2实例分割深度教程:SparseInst模型原理与实战 【免费下载链接】yolov7_d2 🔥🔥🔥🔥 (Earlier YOLOv7 not official one) YOLO with Transformers and Instance Segmentation, with TensorRT acceleration! &am…...