ClickHouse 进阶【建表、查询优化】
1、ClickHouse 进阶
因为上一节部署了集群模式,所以需要启动 Zookeeper 和 ck 集群;
1.1、Explain 基本语法
EXPLAIN [AST | SYNTAX | PLAN | PIPELINE] [setting = value, ...]
SELECT ... [FORMAT ...]- AST:用于查看语法树
- SYNTAX:用于优化语法
- PLAN:用于查看执行计划
- header:打印计划中各个步骤的 head 说明,默认关闭,默认值 0;
- description:打印计划中各个步骤的描述,默认开启,默认值 1;
- actions:打印计划中各个步骤的详细信息,默认关闭,默认值 0;
- PIPELINE:用于查看 pipeline 计划
- header:打印计划中各个步骤的 head 说明,默认关闭;
- graph:用 DOT 图形语言描述管道图,默认关闭,需要查看相关的图形需要配合 graphviz 查看;
- actions:如果开启了 graph,紧凑打印打,默认开启;
其中,PLAN 和 PIPELINE 还可以进行额外的显示设置;
1.2、建表优化
在之前使用 Hive 做数仓的时候,我们通常直接把日期类型直接存储为 String 类型,用的时候再用 date_format 函数转一下;但是在 ck 中并不是这样的;
1.2.1、数据类型
1)时间字段类型
虽然 ClickHouse 底层将 DateTime 存储为时间戳 Long 类型,但不建议把时间存储为 Long 类型, 因为 DateTime 不需要经过函数转换处理,执行效率高、可读性好。
CREATE TABLE t_type2
(`id` UInt32,`sku_id` String,`total_amount` Decimal(16, 2),`create_time` DataTime
)
ENGINE = ReplacingMergeTree(create_time)
PARTITION BY create_time
PRIMARY KEY id
ORDER BY (id, sku_id)2)空值存储类型
官方已经指出 Nullable 类型几乎总是会拖累性能,因为存储 Nullable 列时需要创建一个额外的文件来存储 NULL 的标记(原因1),并且 Nullable 列无法被索引(原因2)。因此除非极特殊情况,应直接使用字段默认值表示空,或者自行指定一个在业务中无意义的值(例如用-1 表示没有商品 ID)。

这里指定了列 y 可以为 null (但是这里的 x 不可以为 null,如果非要给 x 列插入 null 的话,默认会被转为 x 列所对应类型的默认值)

可以看到,因为 y 列可以为 null,所以 ck 会为 y 单独创建一个文件存储 null 值;
1.2.2、分区和索引
分区粒度根据业务特点决定,不宜过粗或过细。一般选择按天分区,也可以指定为 Tuple(), 以单表一亿数据为例,分区大小控制在 10-30 个为最佳。
必须指定索引列,ClickHouse 中的索引列即排序列,通过 order by 指定,一般在查询条 件中经常被用来充当筛选条件的属性被纳入进来;可以是单一维度,也可以是组合维度的索 引;通常需要满足高级列在前、查询频率大的在前原则;还有基数特别大的不适合做索引列, 如用户表的 userid 字段;通常筛选后的数据满足在百万以内为最佳;
1.2.3、Index_granularity
Index_granularity 是用来控制索引粒度的,默认是 8192,如非必须不建议调整。
如果表中不是必须保留全量历史数据,建议指定 TTL(生存时间值),可以免去手动过期 历史数据的麻烦,TTL 也可以通过 alter table 语句随时修改。
1.2.4、写入和删除优化
- 尽量不要执行单条或小批量删除和插入操作,这样会产生小分区文件,给后台 Merge 任务带来巨大压力
- 不要一次写入太多分区,或数据写入太快,数据写入太快会导致 Merge 速度跟不 上而报错,一般建议每秒钟发起 2-3 次写入操作,每次操作写入 2w~5w 条数据(依服务器性能而定)
在服务器内存充裕的情况下增加内存配额,一般通过 max_memory_usage 来实现
在服务器内存不充裕的情况下,建议将超出部分内容分配到系统硬盘上,但会降低执行 速度,一般通过 max_bytes_before_external_group_by、max_bytes_before_external_sort 参数 来实现。
1.3、语法优化规则
1.3.1、count 优化
在调用 count 函数时,如果使用的是 count() 或者 count(*),且没有 where 条件,则 会直接使用 system.tables 的 total_rows

查看 count 的执行计划:

注意 Optimized trivial count ,这是对 count 的优化。 如果 count 具体的列字段,则不会使用此项优化:

1.3.2、谓词下推
当 group by 有 having 子句,但是没有 with cube、with rollup 或者 with totals 修饰的时 候,having 过滤会下推到 where 提前过滤。例如下面的查询,HAVING name 变成了 WHERE name,在 group by 之前过滤:

子查询支持谓词下推:

1.3.3、聚合计算外推
聚合函数内的计算,会外推,例如:

1.4、查询优化
1.4.1、单表查询
1)Prewhere 替代 where
Prewhere 和 where 语句的作用相同,用来过滤数据。不同之处在于 prewhere 只支持 * MergeTree 族系列引擎的表,首先会读取指定的列数据,来判断数据过滤,等待数据过滤 之后再读取 select 声明的列字段来补全其余属性。
当查询列明显多于筛选列时使用 Prewhere 可十倍提升查询性能,Prewhere 会自动优化执行过滤阶段的数据读取方式,降低 io 操作。
在某些场合下,prewhere 语句比 where 语句处理的数据量更少性能更高。
某些场景即使开启优化,也不会自动转换成 prewhere,需要手动指定 prewhere:
- 使用常量表达式
- 包含 arrayJOIN,globalIn,globalNotIn 或者 indexHint 的查询
- select 查询的列字段和 where 的谓词相同
- 使用了主键字段
1.4.2、数据采样
通过采样运算可极大提升数据分析的性能
SELECTTitle,count(*) AS PageViews
FROM hits_v1
SAMPLE 1 / 10
WHERE CounterID = 57
GROUP BY Title
ORDER BY PageViews DESC
LIMIT 10001.4.3、列裁剪与分区裁剪
数据量太大时应避免使用 select * 操作,查询的性能会与查询的字段大小和数量成线性 表换,字段越少,消耗的 io 资源越少,性能就会越高。
1.4.4、orderby 结合 where、limit
千万以上数据集进行 order by 查询时需要搭配 where 条件和 limit 语句一起使用;
1.4.5、避免构建虚拟列
如非必须,不要在结果集上构建虚拟列,虚拟列非常消耗资源浪费性能,可以考虑在前端进行处理,或者在表中构造实际字段进行额外存储;
1.4.6、uniqCombined 替代 distinct
性能可提升 10 倍以上,uniqCombined 底层采用类似 HyperLogLog 算法实现,能接收 2% 左右的数据误差,可直接使用这种去重方式提升查询性能。Count(distinct )会使用 uniqExact 精确去重。
不建议在千万级不同数据上执行 distinct 去重查询,改为近似去重 uniqCombined;
1.4.7、物化视图
区别于普通视图,物化视图会把数据存下来,而普通视图并不保存数据;
1.5、多表关联
1.5.1、大小表 join
多表 join 时要满足小表在右的原则,右表关联时被加载到内存中与左表进行比较,ClickHouse 中无论是 Left join 、Right join 还是 Inner join 永远都是拿着右表中的每一条记录 到左表中查找该记录是否存在,所以右表必须是小表。
1.5.2、分布式表使用 GLOBAL
两张分布式表上的 IN 和 JOIN 之前必须加上 GLOBAL 关键字,右表只会在接收查询请求的那个节点查询一次,并将其分发到其他节点上。如果不加 GLOBAL 关键字的话,每个节点都会单独发起一次对右表的查询,而右表又是分布式表,就导致右表一共会被查询 N²次(N 是该分布式表的分片数量),这就是查询放大,会带来很大开销。
1.6、数据一致性
即便对数据一致性支持最好的 Mergetree,也只是保证最终一致性:

我们在使用 ReplacingMergeTree、SummingMergeTree 这类表引擎的时候,会出现短暂 数据不一致的情况。
在某些对一致性非常敏感的场景,通常有以下几种解决方案:
1.6.1、手动 OPTIMIZE
在写入数据后,立刻执行 OPTIMIZE 强制触发新写入分区的合并动作:
OPTIMIZE TABLE test_a FINAL;但是数据量大时优化可能非常耗时,而且优化时数据对外无法访问,所以并不推荐使用;
1.6.2、通过 Group by 去重
SELECT user_id , argMax(score, create_time) AS score, argMax(deleted, create_time) AS deleted, max(create_time) AS ctime
FROM test_a
GROUP BY user_id
HAVING deleted = 0;函数说明:
- argMax(field1,field2):按照 field2 的最大值取 field1 的值。
比如 argMax(score,create_time),当 score 字段有多个时,取 create_time 最大的;
1.7、物化视图
ClickHouse 的物化视图是一种查询结果的持久化,它确实是给我们带来了查询效率的提 升。用户查起来跟表没有区别,它就是一张表,它也像是一张时刻在预计算的表,创建的过 程它是用了一个特殊引擎,加上后来 as select,就是 create 一个 table as select 的写法。
“查询结果集”的范围很宽泛,可以是基础表中部分数据的一份简单拷贝,也可以是多 表 join 之后产生的结果或其子集,或者原始数据的聚合指标等等。所以,物化视图不会随着 基础表的变化而变化,所以它也称为快照(snapshot)
1.7.1、物化视图与普通视图的区别
普通视图不保存数据,保存的仅仅是查询语句,查询的时候还是从原表读取数据,可以 将普通视图理解为是个子查询。物化视图则是把查询的结果根据相应的引擎存入到了磁盘或内存中,对数据重新进行了组织,你可以理解物化视图是完全的一张新表;
到这里我终于理解了为什么实习的时候一张视图创建了 30 分钟,因为存储引擎用的是 StarRocks 物化视图;
1.7.2、优缺点
优点:查询速度快,要是把物化视图这些规则全部写好,它比原数据查询快了很多,总 的行数少了,因为都预计算好了。
缺点:它的本质是一个流式数据的使用场景,是累加式的技术,所以要用历史数据做去 重、去核这样的分析,在物化视图里面是不太好用的。在某些场景的使用也是有限的。而且 如果一张表加了好多物化视图,在写这张表的时候,就会消耗很多机器的资源,比如数据带 宽占满、存储一下子增加了很多。
1.7.3、语法
也是 create 语法,会创建一个隐藏的目标表来保存视图数据。也可以 TO 表名,保存到 一张显式的表。没有加 TO 表名,表名默认就是 .inner.物化视图名
CREATE [MATERIALIZED] VIEW [IF NOT EXISTS] [db.]table_name [TO[db.]name]
[ENGINE = engine] [POPULATE] AS SELECT ...总结
这一块还是不好理解,如果没有项目真正实践,这些优化都是纸上谈兵;这里先有个大致了解,感觉学到最后,这些大数据数据库框架的优化的很多相同点都是有迹可循的;
相关文章:
ClickHouse 进阶【建表、查询优化】
1、ClickHouse 进阶 因为上一节部署了集群模式,所以需要启动 Zookeeper 和 ck 集群; 1.1、Explain 基本语法 EXPLAIN [AST | SYNTAX | PLAN | PIPELINE] [setting value, ...] SELECT ... [FORMAT ...] AST:用于查看语法树SYNTAX&#…...

Qt拖拽事件详解及代码实现
Qt拖拽事件详解及代码实现 前言项目描述代码结构简介代码详解 前言 qt拖拽事件是一项非常常用并且非常好用的功能,拖拽实际上是一种信息传递的载体,其目的是将信息从一个对象传递给另一个对象。通过拖拽可以简化文件打开或业务操作流程,qt初…...

云原生的候选应用
提示 该内容摘自电子书《为 Azure 构建云原生 .NET 应用程序》,可在**.NET Docs**上获取,也可以免费下载 PDF并离线阅读。 考虑一下您的组织需要构建哪些应用程序。然后,看看您投资组合中的现有应用程序。其中有多少需要云原生架构ÿ…...

什么是单例模式?
单例模式是一种常见的设计模式,它确保一个类只有一个实例,并提供一个全局访问点来获取这个唯一实例。这种模式通常在需要控制某些资源的访问权限或确保对象的唯一性时使用。 单例模式的特点 唯一实例:单例模式确保一个类只有一个实例存在,全局可访问。 延迟实例化:在需…...
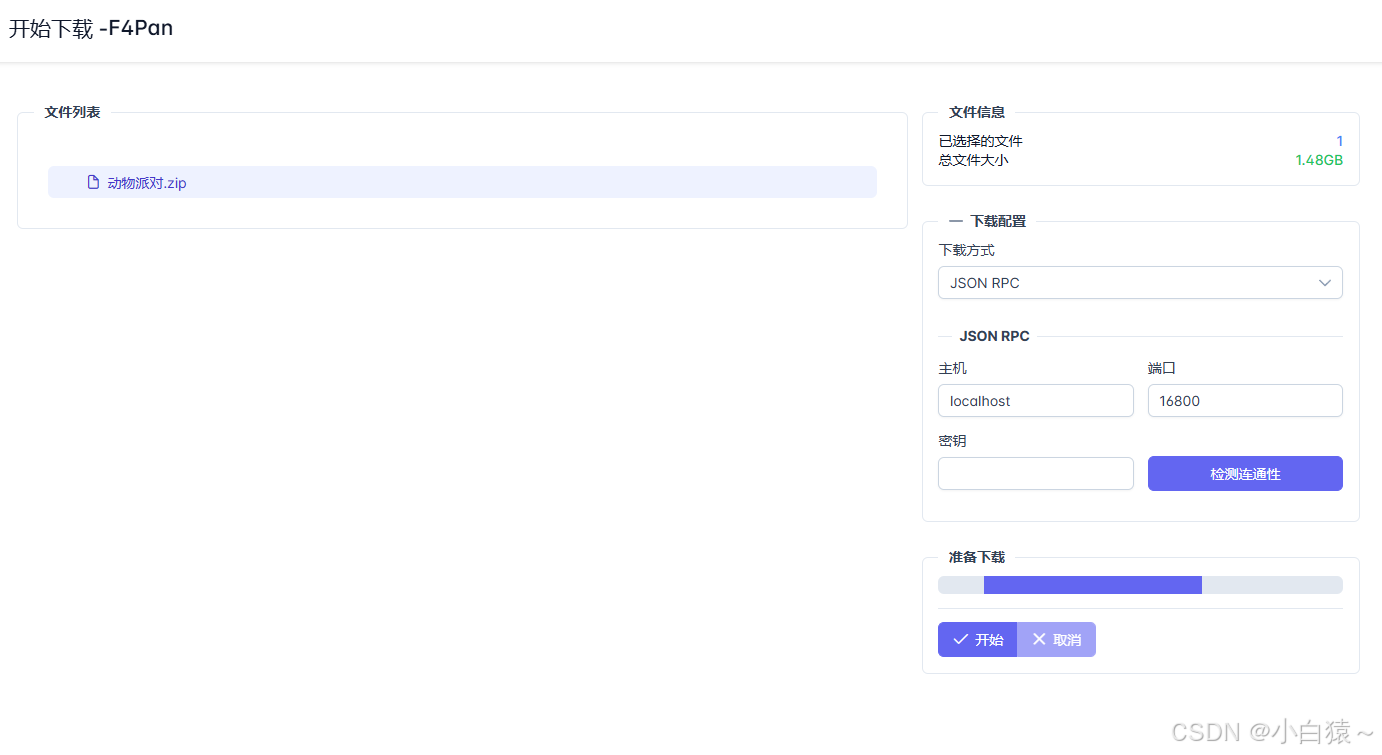
F4Pan百度网盘不限速直链解析工具最新可用
最新可用百度网盘不限速直链解析工具,现在很多解析网站和浏览器扩展都失效了,这个是用《F4Pan网盘解析系统开源源码》搭建的,有兴趣可以去研究研究。 下面看一下测试速度超过70MB每秒比开通会员还快非常的恐怖。 使用方法 1.下载F4Pan解析工…...

设计模式实战:智能家居系统的设计与实现
问题描述 设计一个智能家居系统,支持设备的控制(如灯、空调等),提供多种操作策略,并且在设备状态发生变化时通知用户。系统需要确保设备操作的灵活性和可扩展性。 设计分析 命令模式 命令模式用于将请求封装成对象,从而使我们可以用不同的请求、队列或日志来参数化其…...

Unity Rigidbody 踩坑记录
1:两个带有刚体的物体碰撞会一直不停的弹 把被动受力的刚提的 Freeze Position 的勾选 去掉(碰到过一次,有一种受力无法释放又返回给目标的 所以一直弹跳的感觉) 2:子物体 和父物体 都有刚体的情况下 子物体 Freeze R…...
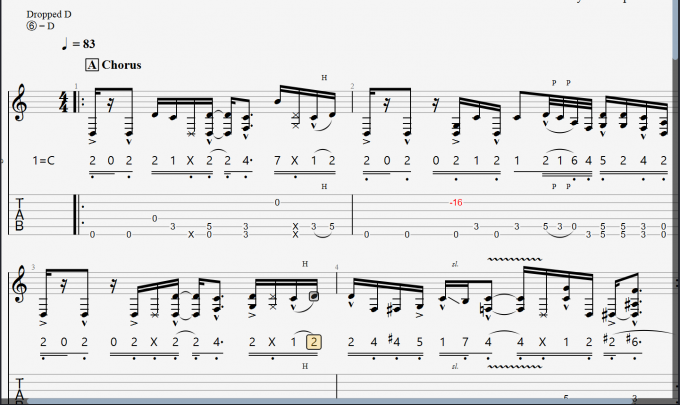
Guitar Pro简谱怎么输入 ?如何把简谱设置到六线谱的下面?
一、Guitar Pro简谱怎么输入 简谱在音乐学习、演奏、创作和传播中都起着非常重要的作用,是音乐领域不可或缺的工具。吉他乐谱的制作可以使简谱,也可以使五线谱、六线谱等多种形式,这几种乐谱都可以使用Guitar Pro来完成。下面来看看Guitar Pr…...

Python 爬虫项目实战(一):爬取某云热歌榜歌曲
前言 网络爬虫(Web Crawler),也称为网页蜘蛛(Web Spider)或网页机器人(Web Bot),是一种按照既定规则自动浏览网络并提取信息的程序。爬虫的主要用途包括数据采集、网络索引、内容抓…...

Mongodb权限
MongoDB 的权限管理用于确保数据库的安全性并限制用户访问敏感数据。MongoDB 使用基于角色的访问控制(RBAC)来管理权限,允许管理员定义用户和角色,并为这些角色分配相应的权限。 Mongodb的内置角色 数据库角色 角色说明权限read…...

力扣第五十三题——最大子数组和
内容介绍 给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。 子数组 是数组中的一个连续部分。 示例 1: 输入:nums [-2,1,-3,4,-1,2,1,-5,4] 输出&…...

达梦数据库:select报错:不是 GROUP BY 表达式
目录 SQL示例报错信息原因排查解决方法一:达梦支持灵活的处理方式,可以直接在查询中加hint参数方法二:修改dm.ini参数GROUP_OPT_FLAG1,动态,会话级参数,不用重启数据库方法三:配置兼容参数&…...

大模型卷向「下半场」,产业场景成拼杀重地
在19世纪的一个雨声潺潺的夏日,诗人拜伦与雪莱在瑞士的湖畔边闲聊,他们聊到了一个大胆的想法:如果能够把一个生物的各个部分制造出来,再组装到一起,赋予它生命的温暖,那会怎样? 这次对话激发了…...

OD C卷 - 多线段数据压缩
多段 线 数据压缩 (200) 如图中每个方格为一个像素(i,j),线的走向只能水平、垂直、倾斜45度;图中线段表示为(2, 8)、(3,7)、(3, 6)、(…...

密码学基础:搞懂Hash函数SHA1、SHA-2、SHA3(2)
目录 1.引入 2. SHA512-224\256 3.SHA-3 4.MD5 5.SM3 1.引入 上篇密码学基础:搞懂Hash函数SHA1、SHA-2、SHA3(1)-CSDN博客,我们先就将基础的SHA1\2讲解了,接下来我们继续聊SHA-3、SHA2变体SHA512_224\256等 2. SHA512-224\256 SHA512…...

C++ 异步编程:std::async、std::future、std::packaged_task 和 std::promise
C 异步编程:std::async、std::future、std::packaged_task 和 std::promise 在现代 C 编程中,异步编程已经成为一种常见的模式。利用 C11 引入的标准库组件 std::async、std::future、std::packaged_task 和 std::promise,我们可以更方便地处…...

OD C卷 - 石头剪刀布游戏
石头剪刀布游戏 (100) 剪刀石头布游戏,A-石头、B-剪刀、C-布游戏规则: 胜负规则,A>B; B>C; C>A;当本场次中有且仅有一种出拳形状优于其他出拳形状,则该形状的玩家是胜利者,否则认为是…...

关于k8s集群中kubectl的陈述式资源管理
1、k8s集群资源管理方式分类 (1)陈述式资源管理方式:增删查比较方便,但是改非常不方便 使用一条kubectl命令和参数选项来实现资源对象管理操作 (2)声明式资源管理方式:yaml文件管理 使用yam…...

XML 学习笔记
简介: (1)XML:可扩展性标记语言,用于传输和存储数据,而不是展示数据,是W3C 推举的数据传输格式。 XML的标签必须自定义,但是在写标签名的时候一定要有含义。 XML 只能有一个根节点…...
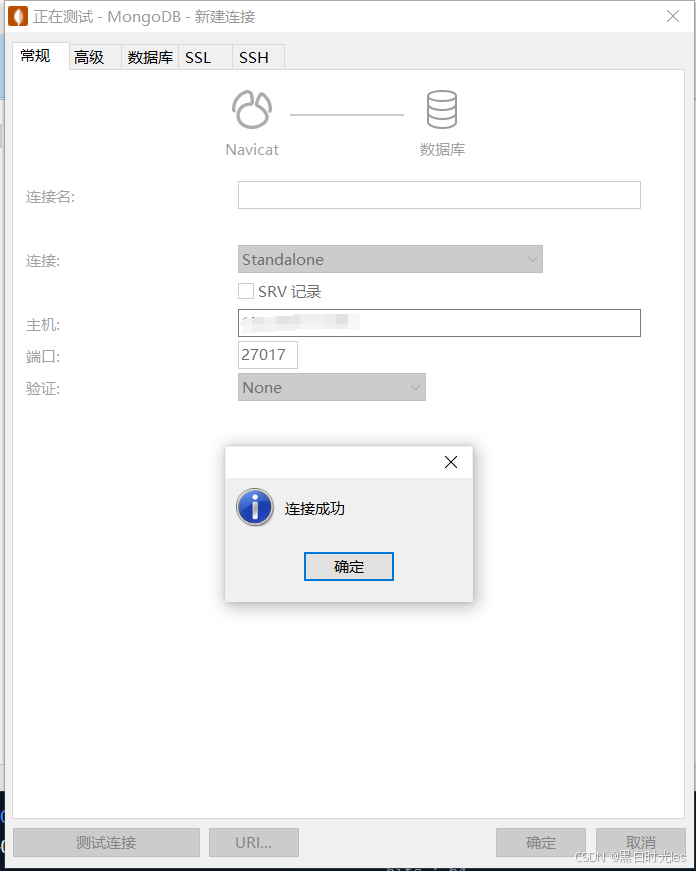
MongoDB未授权访问漏洞
2.MongoDB未授权访问漏洞 mongodb数据库是由C编写,主要是为了提供web应可用扩展的一种高性能数据库。开启MongoDB服务时不添加任何参数时,默认是没有权限验证的,登录的用户可以通过默认端口无需密码对数据库任意操作(增、删、改、查高危动作)而且可以远程访问数据库…...

JavaScript PPTX操作终极指南:5分钟掌握PPT自动化生成技巧
JavaScript PPTX操作终极指南:5分钟掌握PPT自动化生成技巧 【免费下载链接】js-pptx Pure Javascript reader/writer for PowerPoint 项目地址: https://gitcode.com/gh_mirrors/js/js-pptx 在当今数字化时代,自动化办公已经成为提升工作效率的关…...

DriverStore Explorer:Windows驱动管理的终极免费解决方案
DriverStore Explorer:Windows驱动管理的终极免费解决方案 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否曾因C盘空间不足而烦恼?是否遇到过设备驱动冲突…...

Marked.js 终极指南:为什么这是现代 Web 开发中最快的 Markdown 解析器?
Marked.js 终极指南:为什么这是现代 Web 开发中最快的 Markdown 解析器? 【免费下载链接】marked A markdown parser and compiler. Built for speed. 项目地址: https://gitcode.com/gh_mirrors/ma/marked 在当今内容驱动的 Web 开发世界中&…...

Planetscale:免费云数据库的快速入门与实战指南
1. Planetscale是什么?为什么开发者都在用? 第一次听说Planetscale时,我也和大多数开发者一样好奇:这个号称"开发者友好"的云数据库到底有什么特别?用了半年后终于明白,它就像是数据库界的GitHub…...

属于超级学习者的时代!中国学者用三种策略找到放射组学预测模型的最佳算法
源自风暴统计网:一键统计分析与绘图的网站由于可以使用大量数据进行训练,还能整合基因图谱、影像、脑电图、生理数据等多种数据源,因此机器学习(ML)算法特别适合个体化医疗。今天分享一篇基于集成机器学习,…...

5秒破解百度网盘提取码:baidupankey智能工具如何重塑你的资源获取体验
5秒破解百度网盘提取码:baidupankey智能工具如何重塑你的资源获取体验 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 你是否曾为百度网盘加密资源而烦恼?面对"请输入提取码"的提示却束手无策…...

合规刚需下,游戏行业适合的内网通讯软件怎么选
一、背景 2026年,游戏行业在合规监管、信创推进与降本增效三重驱动下,内部协作与数据安全需求持续升级。《数据安全法》《网络安全法》对游戏企业研发代码、运营数据、用户信息的存储与传输提出明确合规要求,数据泄露、权限失控、协作低效等…...
开源大模型效果展示:Pixel Language Portal对emoji+文字混合输入的语义解析
开源大模型效果展示:Pixel Language Portal对emoji文字混合输入的语义解析 1. 项目概览 Pixel Language Portal(像素语言跨维传送门)是一款基于Tencent Hunyuan-MT-7B大模型构建的创新翻译工具。与传统翻译软件不同,它将语言转换…...

丹青幻境效果展示:宣纸底纹UI下生成图像与界面美学统一性视觉报告
丹青幻境效果展示:宣纸底纹UI下生成图像与界面美学统一性视觉报告 1. 设计理念与视觉定位 丹青幻境的设计理念源于传统东方美学与现代数字艺术的完美融合。这款基于Z-Image架构打造的数字艺术创作工具,彻底摒弃了传统AI工具冰冷的技术感,将…...

8款降AI工具实测:知网维普全过,毕业季改稿不踩坑
每到毕业季,不少同学都会卡在论文AIGC检测这一关:熬了好几个通宵打磨的稿子,一查AI率直接飙到80%以上,被导师打回要求重改,眼看提交截止日一天天临近,越急越不知道从哪下手。其实现在主流的AI检测算法早就有…...