Spring Cache框架(AOP思想)+ Redis实现数据缓存
文章目录
- 1 简介
- 1.1 基本介绍
- 1.2 为什么要用 Spring Cache?
- 2 使用方法
- 2.1 依赖导入(Maven)
- 2.2 常用注解
- 2.3 使用步骤
- 2.4 常用注解说明
- 1)@EnableCaching
- 2)@CachePut
- 3)@Cacheable
- 4)@CacheEvict
- 3 注意事项
1 简介
1.1 基本介绍
Spring Cache 是 Spring 框架提供的一个抽象层,通过 Spring Cache,你可以将缓存逻辑与业务代码分离,减少对底层缓存实现的依赖。Spring Cache 支持多种缓存提供者,如 EhCache、Redis、Caffeine、Guava 等。
Spring Cache 的核心概念:
- 缓存抽象 (Cache Abstraction)
Spring Cache 通过抽象接口为各种缓存提供者提供支持。核心接口包括Cache和CacheManager。 - Cache
Cache接口代表具体的缓存对象。它提供了对缓存数据的访问和管理操作,如获取、插入、删除缓存项。 - CacheManager
CacheManager是用于管理Cache实例的接口。它负责管理多个Cache实例,并提供访问这些缓存的机制。
1.2 为什么要用 Spring Cache?
使用 Spring Cache 主要是为了简化缓存管理,提高系统性能,并确保缓存的使用对开发者来说是透明和易于维护的。Spring Cache 的主要好处在于它提供了一个简单、透明且统一的缓存管理机制,可以显著提升应用的性能,同时减少了缓存实现的复杂性。它使得开发者能够更专注于业务逻辑,而不用担心底层缓存的细节,并且在系统扩展时,缓存策略也可以灵活调整。下面是使用 Spring Cache 的一些具体好处:
- 性能提升
缓存可以显著减少对资源密集型操作的依赖,如数据库查询或复杂计算。通过将频繁访问的结果存储在缓存中,可以减少这些操作的次数,从而提高系统的响应速度和吞吐量。
- 减少数据库查询:将查询结果缓存起来,可以减少数据库的压力,尤其是在读操作较多的场景下。
- 加快计算速度:一些复杂的业务逻辑计算结果可以缓存,避免每次都重新计算。
- 简化缓存管理
Spring Cache 提供了统一的缓存管理接口,开发者可以通过简单的注解来实现缓存功能,而不需要直接操作底层缓存框架。
- 统一的缓存抽象:通过
Cache和CacheManager接口,Spring Cache 可以支持多种缓存实现,开发者无需关心底层实现的细节。 - 简化的配置:只需使用如
@Cacheable、@CachePut等注解,就可以轻松实现缓存的添加、更新和删除。
- 透明的缓存机制
Spring Cache 使得缓存的使用对业务逻辑透明,开发者不需要修改现有代码逻辑,只需在需要缓存的地方加上注解即可。这种透明性极大地减少了缓存逻辑与业务逻辑的耦合。
- 非侵入性:Spring Cache 通过 AOP(面向切面编程)机制将缓存逻辑与业务逻辑分离,不影响原有代码的可读性和维护性。
- 便捷性:开发者不需要手动处理缓存的增删查改,只需专注于业务逻辑。
- 灵活性和扩展性
Spring Cache 支持多种缓存提供者,如 EhCache、Redis、Caffeine 等,可以根据不同的应用场景选择合适的缓存实现。此外,Spring Cache 还支持缓存的条件控制、缓存键的自定义等高级特性。
- 多缓存支持:可以无缝切换或组合多种缓存提供者,根据业务需求灵活配置。
- 条件缓存:通过
condition和unless等属性,开发者可以精确控制缓存的行为,避免不必要的缓存。
- 集成与维护方便
Spring Cache 与 Spring 生态系统紧密集成,特别是与 Spring Boot 的集成非常方便,使得缓存的配置和管理更加简单。
- Spring Boot 的自动配置:对于常用的缓存提供者,如 Redis,Spring Boot 提供了开箱即用的自动配置,减少了开发者的配置工作量。
- 一致性管理:Spring Cache 可以与其他 Spring 组件(如 Spring Data、Spring Security 等)无缝集成,提供一致的缓存管理。
- 缓存更新和失效管理
Spring Cache 支持缓存的自动更新和失效机制,确保缓存数据与实际数据保持一致,避免脏数据的问题。
- 缓存失效控制:通过
@CacheEvict注解可以灵活地控制缓存的失效时间和条件,确保缓存的准确性。 - 自动刷新:一些缓存实现支持缓存数据的自动刷新机制,避免数据过时的情况。
- 提高应用的扩展性
通过缓存减少资源的占用,使得应用在负载增加时能更好地扩展。此外,Spring Cache 的抽象层允许开发者轻松切换或扩展缓存策略,而不影响现有的业务逻辑。
2 使用方法
2.1 依赖导入(Maven)
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId> <version>2.7.3</version>
</dependency>
2.2 常用注解
在SpringCache中提供了很多缓存操作的注解,常见的是以下的几个:
| 注解 | 说明 |
|---|---|
| @EnableCaching | 开启缓存注解功能,通常加在启动类上 |
| @Cacheable | 在方法执行前先查询缓存中是否有数据,如果有数据,则直接返回缓存数据;如果没有缓存数据,调用方法并将方法返回值放到缓存中 |
| @CachePut | 将方法的返回值放到缓存中 |
| @CacheEvict | 将一条或多条数据从缓存中删除 |
在spring boot项目中,使用缓存技术只需在项目中导入相关缓存技术的依赖包,并在启动类上使用@EnableCaching开启缓存支持即可。例如,使用Redis作为缓存技术,只需要导入Spring Data Redis的maven坐标即可。
2.3 使用步骤
采用 SpringBoot+SpringCache+Redis+SpringData 实现数据的缓存小例子如下:
- 导入相关依赖,并在配置文件中配置好数据库+redis 等相关工具的必须信息。
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId>
</dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><scope>runtime</scope>
</dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>2.2.0</version>
</dependency>
server:port: 8888
spring:datasource:druid:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/spring_cache_demo?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=trueusername: ****password: ****redis:host: localhostport: 6379database: 1
logging:level:com:itheima:mapper: debugservice: infocontroller: info
- 在启动类中开启缓存注解功能,采用注解:
@EnableCaching打开cache缓存注解功能
@Slf4j
@SpringBootApplication
@EnableCaching // 打开cache缓存注解功能
public class CacheDemoApplication {public static void main(String[] args) {SpringApplication.run(CacheDemoApplication.class, args);log.info("项目启动成功...");}
}
- 在 controller 层,请求方法上加上相关的注解实现不同的作用,具体见下代码注解。(代码见下节)
2.4 常用注解说明
1)@EnableCaching
在启动类中开启缓存注解功能。
2)@CachePut
作用:用于更新缓存中的数据。与@Cacheable不同,@CachePut每次都会调用实际的方法,并将其返回值放入指定的缓存中。
两个参数:
- value:缓存的名称,每个缓存名称下面可以有很多的 key
- key:缓存的 key,支持 spring 的表大师语言 SPEL 语法
// 当用户ID为1时最终缓存的结果为userCache::1
@PostMapping
@CachePut(value = "userCache", key = "#user.id") // 将返回值自动存入缓存,括号的参数代表的是key的生成定义,userCache::1
public User save(@RequestBody User user) {userMapper.insert(user);return user;
}
效果:

附加说明:key 的写法有多种
#user.id : #user指的是方法形参的名称, id指的是user的id属性 , 也就是使用user的id属性作为key ;
#result.id : #result代表方法返回值,该表达式 代表以返回对象的id属性作为key ;
#p0.id:#p0指的是方法中的第一个参数,id指的是第一个参数的id属性,也就是使用第一个参数的id属性作为key ;
#a0.id:#a0指的是方法中的第一个参数,id指的是第一个参数的id属性,也就是使用第一个参数的id属性作为key ;
#root.args[0].id:#root.args[0]指的是方法中的第一个参数,id指的是第一个参数的id属性,也就是使用第一个参数
的id属性作为key ;
3)@Cacheable
作用:用于声明一个方法的返回值是可缓存的。当方法被调用时,Spring Cache会先检查缓存中是否已经存在相应的数据。如果存在,则直接返回缓存中的数据,而无需调用实际的方法。如果不存在,则调用方法并缓存其返回值。
两个重要参数:
- value/cacheNames: 缓存的名称,每个缓存名称下面可以有多个key
- key: 缓存的key ----------> 支持Spring的表达式语言SPEL语法
/*** 2、模拟查询请求,首先查找缓存是否存在该数据,没有就查库然后存入缓存,再返回*/
@GetMapping
@Cacheable(cacheNames = "userCache", key = "#id")
public User getById(Long id) {User user = userMapper.getById(id);return user;
}
其他参数:
- value/cacheNames:这两个参数是互斥的,用于指定缓存的名称。你可以使用
value或cacheNames来指定缓存的标识符。如果定义了多个缓存名称,则可以使用逗号分隔。Spring 将会根据这个名称去查找对应的 CacheManager 中的 Cache。- key:指定缓存数据时使用的 key,可以是方法参数,也可以是 SpEL 表达式。如果未指定,Spring 将会使用默认的 key 生成策略。
- keyGenerator:用于指定 key 的生成器,当
key参数不足以满足需求时,可以通过实现org.springframework.cache.interceptor.KeyGenerator接口来自定义 key 的生成策略。- cacheManager:指定用于解析缓存名称的 CacheManager。如果未指定,将会使用 Spring Boot 自动配置的 CacheManager。
- cacheResolver:当需要动态解析缓存时,可以使用
cacheResolver。它允许你基于方法的参数或其他条件来选择不同的缓存。- condition:SpEL 表达式,用于指定在什么条件下方法的结果应该被缓存。只有表达式结果为
true时,才会缓存方法的返回结果。- unless:与
condition类似,但用于指定在什么条件下方法的结果不应该被缓存。只有当表达式结果为false时,方法的返回结果才会被缓存。- sync:是否使用同步模式进行缓存。如果设置为
true,则对于同一个 key 的并发请求,只有一个能够更新缓存,其他请求则会等待缓存更新完成后再从缓存中获取数据。这个参数是 Spring Cache 的扩展,并非所有缓存提供者都支持。
4)@CacheEvict
作用:用于从缓存中移除数据。你可以指定根据某个条件来移除缓存中的数据,或者移除整个缓存。
参数:
- value/cacheName:缓存的名称,每个缓存名称下面可以有多个 key
- key:缓存的 key
- allEntries:是否删除缓存名称下的所有 key 缓存
两种使用方法,适用于清除缓存数据的情况。具体使用见下:
/*** 3、模拟删除某一个数据的请求,同时清理指定的缓存信息*/
@DeleteMapping
@CacheEvict(cacheNames = "userCache", key = "#id") // 删除某个具体的key对应的id
public void deleteById(Long id) {userMapper.deleteById(id);
}/*** 4、模拟批量删除数据请求,同时清理某个类型的key下对应的所有缓存*/
@DeleteMapping("/delAll")
@CacheEvict(cacheNames = "userCache", allEntries = true) // 删除userCache下对应的所有缓存
public void deleteAll() {userMapper.deleteAll();
}
3 注意事项
- 被缓存的方法的返回值需要是可序列化的,因为缓存数据通常会被存储在内存中或通过网络进行传输。
- 缓存的key通常是根据方法的参数来生成的,但你也可以通过
@Cacheable等注解的key属性来自定义key的生成策略。 - 缓存的失效策略(如过期时间)通常由缓存实现来提供,而不是由Spring Cache直接控制。你需要根据所使用的缓存实现来配置相应的失效策略。
- SpringCache并不直接“知道”你使用的是Redis还是其他缓存实现,而是通过项目的依赖和配置信息来间接确定的。Spring Boot的自动配置机制会根据这些信息来选择合适的缓存管理器实现,并在你的业务代码中通过AOP机制来执行缓存操作。
上述完整项目代码仓库:StrivePeng仓库
相关文章:
Spring Cache框架(AOP思想)+ Redis实现数据缓存
文章目录 1 简介1.1 基本介绍1.2 为什么要用 Spring Cache? 2 使用方法2.1 依赖导入(Maven)2.2 常用注解2.3 使用步骤2.4 常用注解说明1)EnableCaching2)CachePut3)Cacheable4)CacheEvict 3 注意…...

在Windows编程中,MFC\C++中如何在OnCopyData中传递Vector类型数据?
我们在通过 WM_COPYDATA 消息实现进程间通信时,发送char 数组或其他类型数组与发送vector是有区别的。 1、发送基础类型时,直接发送指针。 typedef struct tagMYSTRUCT {int nTest;wchar_t cTest[40] {0}; } MYSTRUCT, *PMYSTRUCT;MYSTRUCT stSend; s…...

Java常见面试题-01-java基础
文章目录 面向对象的特征Java 的基本数据类型有哪些JDK、JRE、JVM 的区别重载和重写的区别Java 中和 equals 的区别String、StringBuffer、StringBuilder 三者之间的区别接口和抽象类的区别是什么string 常用的方法有哪些什么是单例模式?有几种?什么是反…...
Python爬虫实战:利用代理IP爬取百度翻译
文章目录 一、爬取目标二、环境准备三、代理IP获取3.1 爬虫和代理IP的关系3.2 巨量IP介绍3.3 超值企业极速池推荐3.4 IP领取3.5 代码获取IP 四、爬虫代码实战4.1分析网页4.2 寻找接口4.3 参数构建4.4 完整代码 一、爬取目标 本次目标网站:百度翻译(http…...

Transformer学习之DETR
文章目录 1.算法简介1.1 算法主要贡献1.2 算法网络结构 2.损失函数设计2.1 二分图匹配(匈牙利算法)2.2 二分图匹配Loss_match2.3 训练Loss_Hungarian 3.网络核心模块3.1 BackBone模块3.2 空间位置编码(spatial positional encoding)3.2.1 输入与输出3.2.2 空间位置编码原理 3.3…...

场外个股期权是什么品种?可以交易哪些品种?
今天带你了解场外个股期权是什么品种?可以交易哪些品种?场外个股期权是指在场外市场进行交易的个股期权合约,与在交易所交易的标准化个股期权有所不同,它是由买方和卖方通过私下协商,而非通过公开交易所进行买卖和定价…...

每日学术速递8.5-3
1.BoostMVSNeRFs: Boosting MVS-based NeRFs to Generalizable View Synthesis in Large-scale Scenes 标题: BoostMVSNeRFs:将基于 MVS 的 NeRFs 提升到大规模场景中的可泛化视图合成 作者:Chih-Hai Su, Chih-Yao Hu, Shr-Ruei Tsai, Jie-…...

C#针对kernel32.dll的一些常规使用
1、前言 Window是一个复杂的系统,kernel32是一个操作系统的核心动态链接库文件。它提供了大量的API函数,提供了操作系统的基本功能。 2、Ini使用 Ini文件读写使用时,我们需要用到其中的一些函数对文件进行读写。 API: /// &l…...

电话营销机器人的优势
在人工智能的新趋势下,企业开始放弃传统外呼系统,转而使用电话销售机器人,那么使用机器人比坐席手动外呼好吗,真的可以代替人工坐席外呼吗,效率真的高吗? 1、 真人式语音 电话销售人员可以将自定义的话术…...

Oracle SQL Developer 连接第三方数据库
首先Oracle SQL Developer除了支持连接Oracle数据库外,还支持连接第三方数据库,包括: Amazon RedshiftHiveIBM DB2MySQLMicrosoft SQL ServerSybase Adaptive ServerPostgreSQLTeradataTimesTen 首先,你需要在菜单Tools > Pr…...

OSPF路由协议多区域
一、OSPF路由协议单区域的弊端 1、LSDB庞大,占用内存大,SPF计算开销大; 2、LSA洪泛范围大,拓扑变化影响范围大; 3、路由不能被汇总,路由表庞大,查找路由开销大。 二、如何解决OSPF单区域的问题? 引入划分区域 1、每个区域独立存储LSDB,划分区域减小了LSDB。 2、…...

8.5 C++
思维导图 试编程 提示并输入一个字符串,统计该字符中大写、小写字母个数、数字个数、空格个数以及其他字符个数 要求使用C风格字符串完成 #include <iostream> #include <array>using namespace std;int main() {cout << "请输入一个字符…...

MySQL —— 初始数据库
数据库概念 在学习数据库之前,大家保存数据要么是在程序运行期间,例如:在学习编程语言的时候,大家写过的管理系统,运用一些简单的数据结构(例如顺序表)来组织数据,可是程序一旦结束…...

【JVM】垃圾回收机制、算法和垃圾回收器
什么是垃圾回收机制 为了让程序员更加专注于代码的实现,而不用过多的考虑内存释放的问题,所以在Java语言中,有了自动的垃圾回收机制,也是我们常常提及的GC(Garbage Collection) 有了这个垃圾回收机制之后,程序员只需…...

大数据资源平台建设可行性研究方案(58页PPT)
方案介绍: 在当今信息化高速发展的时代,大数据已成为推动各行各业创新与转型的关键力量。为了充分利用大数据的潜在价值,构建一个高效、安全、可扩展的大数据资源平台显得尤为重要。通过本方案的实施企业可以显著提升数据处理能力、优化资源配置、促进业…...

PHP教育培训小程序系统源码
🚀【学习新纪元】解锁教育培训小程序的无限可能✨ 📚 引言:教育培训新风尚,小程序来引领! Hey小伙伴们,是不是还在为找不到合适的学习资源而烦恼?或是厌倦了传统教育模式的单调?今…...

吴恩达机器学习笔记
1.机器学习定义: 机器学习就是让机器从大量的数据集中学习,进而得到一个更加符合现实规律的模型,通过对模型的使用使得机器比以往表现的更好 2.监督学习: 从给定的训练数据集中学习出一个函数(模型参数)…...

React和Vue3 的 Diff 算法有什么区别
React 和 Vue 3 的 Diff 算法都有相似的目标,即在组件状态或属性变化时高效地更新 DOM,但它们在实现细节上有所不同。以下是 React 和 Vue 3 的 Diff 算法的主要区别: React 的 Diff 算法 1. 同层比较 React 使用的是同层比较策略…...
【vulhub靶场之rsync关】
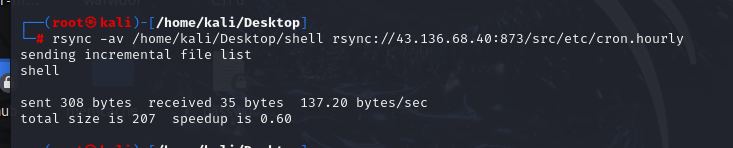
一、使用nmap模块查看该ip地址有没有Rsync未授权访问漏洞 nmap -p 873 --script rsync-list-modules 加IP地址 查看到是有漏洞的模块的 二、使用rsync命令连接并读取文件 查看src目录里面的信息。 三、对系统中的敏感文件进行下载——/etc/passwd 执行命令: rsy…...
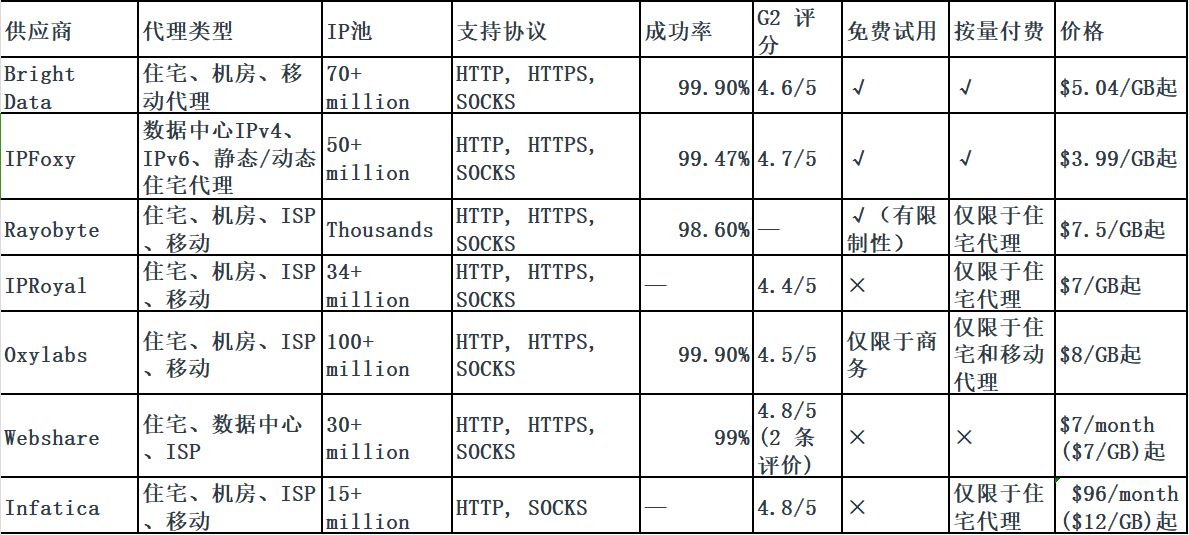
全球7大高质量海外代理IP对比大全
随着国内市场逐渐饱和,越来越多朋友私信我说打算开拓海外市场这片蓝海了!海外代理IP作为解决这些需求的有效工具,帮助跨境企业或团队进行社媒管理、电商运营、市场调研、抓取数据、广告验证等等业务。但是,市场上提供的代理IP服务…...

三菱FX3U六轴标准程序:实现3轴本体控制与3个1PG定位模块,轴点动控制、回零控制及定位功能...
三菱FX3U六轴标准程序,程序包含本体3轴控制,扩展3个1PG定位模块,一共六轴。 程序有轴点动控制,回零控制,相对定位,绝对定位。 另有气缸数个,一个大是DD马达控制的转盘,整个是转盘多工位流水作业…...

仅限PHP 8.9.0–8.9.3可用!3个未公开的php.ini异步I/O隐藏参数及压测对比数据
第一章:PHP 8.9 异步 I/O 优化技巧概览PHP 8.9 并非官方发布的正式版本(截至 2024 年,PHP 最新稳定版为 8.3,8.4 处于 RC 阶段),因此本章所指的“PHP 8.9”为虚构技术演进场景,用于探讨未来 PHP…...

Java 25虚拟线程压测突崩实录:QPS从12万骤降至200,我们用1小时定位并修复的4层嵌套阻塞根源
第一章:Java 25虚拟线程压测突崩事件全景复盘某金融核心支付网关在升级至 JDK 25 并全面启用虚拟线程(Virtual Threads)后,于全链路压测中突发大规模 StackOverflowError 与 OutOfMemoryError: Metaspace 混合崩溃,TPS…...
)
【郑州大学主办 | SPIE出版社出版,ISSNISBN双刊号出版 | 通信技术、计算机视觉与算法、嵌入式系统技术、机器人领域EI】2026年机器学习与嵌入式系统国际学术会议(MLES 2026)
MLES 2026会议已成功申请到SPIE出版社出版!ISSN&ISBN双刊号出版! 2026年机器学习与嵌入式系统国际学术会议(MLES 2026) 2026 International Conference on Machine Learning and Embedded Systems 2026年4月24-26日 &a…...

ROS usb_cam像素格式终极指南:从YUV、MJPEG到源码修改,彻底告别警告和花屏
ROS usb_cam像素格式终极指南:从YUV、MJPEG到源码修改,彻底告别警告和花屏 当你在ROS中调用UVC摄像头时,是否遇到过图像花屏或终端不断弹出"deprecated pixel format"警告?这些问题往往源于对像素格式的误解或配置不当。…...

别再只调参了!用波士顿房价数据实战,教你读懂岭回归和Lasso的系数变化与特征选择
波士顿房价预测实战:从岭回归到Lasso的系数解密与特征工程艺术 当我们面对包含13个特征的波士顿房价数据集时,传统的线性回归往往会给出看似完美的系数解。但你是否注意到,这些系数在实际应用中可能极度不稳定?这正是正则化技术大…...

告别SPI瓶颈:用STM32的FSMC并行接口驱动LAN9252,榨干EtherCAT从站性能
突破EtherCAT从站性能极限:STM32 FSMC并行接口驱动LAN9252全解析 在工业自动化领域,实时以太网协议EtherCAT因其卓越的性能表现已成为运动控制系统的首选。然而许多工程师在实际部署中常遇到一个尴尬局面——主站协议处理速度飞快,而从站控制…...

微信小程序里canvas不跟手滚动?别再用scroll-view了,试试这个官方推荐的替代方案
微信小程序Canvas滚动难题:官方方案与工程实践解析 第一次在小程序里实现类似淘宝详情页的锚点跳转功能时,我信心满满地用scroll-view包住了所有内容区域。直到测试阶段才发现,页面里的UCharts图表就像被钉死在屏幕上一样,完全无…...

避坑指南:票务平台反爬机制破解与Selenium自动化测试最佳实践
票务平台反爬机制深度解析与Selenium合规测试实战 每次当你信心满满地部署好爬虫脚本,准备大展身手时,是不是总会被突如其来的验证码、IP封禁或是诡异的页面跳转搞得措手不及?作为经历过无数次"爬虫阵亡"的老兵,我深刻理…...

如何真正掌控聊天数据?开源工具WeChatMsg的隐私保护与数据备份方案
如何真正掌控聊天数据?开源工具WeChatMsg的隐私保护与数据备份方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trend…...