Python 爬虫入门(九):Scrapy安装及使用「详细介绍」
Python 爬虫入门(九):Scrapy安装及使用「详细介绍」
- 前言
- 1. Scrapy 简介
- 2. Scrapy 的安装
- 2.1 环境准备
- 2.2 安装 Scrapy
- 3. 创建 Scrapy 项目
- 3.1 创建项目
- 3.2 项目结构简介
- 4. 编写爬虫
- 4.1 创建爬虫
- 4.2 解析数据
- 4.3 运行爬虫
- 5. 存储数据
- 5.1 存储为 JSON 文件
- 5.2 存储到数据库
- 5.2.1 MongoDB
- 6. 处理请求和响应
- 6.1 请求头设置
- 6.2 处理响应
- 7. 高级功能
- 7.1 使用中间件
- 7.2 使用代理
- 7.3 使用管道处理数据
- 8. 常见问题及解决方法
- 8.1 爬虫被封禁
- 8.2 数据解析错误
- 8.3 数据存储失败
- 总结
前言
- 欢迎来到“Python 爬虫入门”系列的第九篇文章。本篇文章将深入介绍 Scrapy 的安装及使用。Scrapy 是一个广泛使用的爬虫框架,其强大的功能和灵活的扩展性使得它在数据抓取领域占有重要地位。
- 本文将从 Scrapy 的安装步骤开始,详细介绍其基本使用方法,包括创建项目、编写爬虫、解析数据、存储数据等内容。通过本篇文章的学习,你将能够掌握使用 Scrapy 进行高效数据抓取的技能。
1. Scrapy 简介
Scrapy 是一个用于抓取 Web 数据的应用框架。与其他 Python 爬虫库(如 BeautifulSoup 和 requests)相比,Scrapy 提供了更高的抓取速度、更强的扩展性和更便捷的项目管理方式。Scrapy 框架包含了数据抓取、处理和存储的一整套工具,使得用户能够更高效地完成爬虫任务。
2. Scrapy 的安装
2.1 环境准备
在安装 Scrapy 之前,请确保你的计算机已经安装了以下环境:
- Python 3.6 及以上版本
- pip 包管理工具
2.2 安装 Scrapy
使用 pip 命令可以方便地安装 Scrapy:
pip install scrapy
安装完成后,可以通过以下命令验证 Scrapy 是否安装成功:
scrapy
如果安装成功,你将看到 Scrapy 的版本信息。
3. 创建 Scrapy 项目
3.1 创建项目
在命令行中,导航到你希望存放项目的目录,并运行以下命令来创建一个新的 Scrapy 项目:
scrapy startproject myproject
此命令将在当前目录下创建一个名为 myproject 的文件夹,文件夹结构如下:
myproject/scrapy.cfgmyproject/__init__.pyitems.pymiddlewares.pypipelines.pysettings.pyspiders/__init__.py
3.2 项目结构简介
scrapy.cfg: Scrapy 项目的配置文件。myproject/: 项目的 Python 模块,之后会在此加入代码。items.py: 定义爬取的数据结构。middlewares.py: 定义 Scrapy 中间件。pipelines.py: 定义数据处理管道。settings.py: 定义项目的配置。spiders/: 存放爬虫代码的目录。
4. 编写爬虫
4.1 创建爬虫
在 spiders/ 目录下创建一个新的爬虫文件,例如 example_spider.py,并编写以下内容:
import scrapyclass ExampleSpider(scrapy.Spider):name = 'example'start_urls = ['https://jsonplaceholder.typicode.com/posts']def parse(self, response):for post in response.json():yield {'userId': post['userId'],'id': post['id'],'title': post['title'],'body': post['body']}
4.2 解析数据
在 parse 方法中,我们解析响应内容并提取所需的数据。response.json() 方法将响应内容解析为 JSON 格式,便于我们提取数据。
4.3 运行爬虫
在项目的根目录下,运行以下命令来启动爬虫:
scrapy crawl example
如果一切正常,你将看到爬虫开始抓取数据,并在控制台输出抓取到的内容。
5. 存储数据
5.1 存储为 JSON 文件
Scrapy 提供了多种存储抓取数据的方法,这里介绍将数据存储为 JSON 文件的方法。在命令行中运行以下命令:
scrapy crawl example -o output.json
此命令将抓取的数据保存到 output.json 文件中。
5.2 存储到数据库
我们也可以将抓取的数据存储到数据库中,例如 MongoDB 或 MySQL。在 pipelines.py 文件中编写数据存储的逻辑。
5.2.1 MongoDB
首先,安装 pymongo 库:
pip install pymongo
然后在 pipelines.py 中添加以下代码:
import pymongoclass MongoPipeline:def __init__(self):self.client = pymongo.MongoClient('localhost', 27017)self.db = self.client['scrapy_db']self.collection = self.db['scrapy_collection']def process_item(self, item, spider):self.collection.insert_one(dict(item))return item
在 settings.py 中启用该管道:
ITEM_PIPELINES = {'myproject.pipelines.MongoPipeline': 300,
}
6. 处理请求和响应
6.1 请求头设置
为了模拟真实用户的浏览行为,我们可以在爬虫中设置请求头。在爬虫文件中添加 headers 属性:
class ExampleSpider(scrapy.Spider):name = 'example'start_urls = ['https://jsonplaceholder.typicode.com/posts']headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}def start_requests(self):for url in self.start_urls:yield scrapy.Request(url, headers=self.headers, callback=self.parse)
6.2 处理响应
在 parse 方法中,我们可以根据需要处理响应数据。这里的示例中,我们将 JSON 数据解析并提取需要的字段。
7. 高级功能
7.1 使用中间件
Scrapy 中间件可以在请求和响应之间执行一些自定义的处理逻辑。例如,我们可以使用中间件来处理请求的重试逻辑、设置代理等。
在 middlewares.py 中添加以下示例代码:
from scrapy import signalsclass CustomMiddleware:@classmethoddef from_crawler(cls, crawler):s = cls()crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)return sdef process_request(self, request, spider):request.headers['User-Agent'] = 'Custom User-Agent'def process_response(self, request, response, spider):return responsedef process_exception(self, request, exception, spider):passdef spider_opened(self, spider):spider.logger.info('Spider opened: %s' % spider.name)
在 settings.py 中启用中间件:
DOWNLOADER_MIDDLEWARES = {'myproject.middlewares.CustomMiddleware': 543,
}
7.2 使用代理
有时我们需要通过代理来抓取数据。Scrapy 支持通过中间件设置代理。在 middlewares.py 中添加以下代码:
class ProxyMiddleware:def process_request(self, request, spider):request.meta['proxy'] = 'http://your_proxy_address'
在 settings.py 中启用该代理中间件:
DOWNLOADER_MIDDLEWARES = {'myproject.middlewares.ProxyMiddleware': 543,
}
7.3 使用管道处理数据
数据管道用于处理和存储抓取的数据。在 pipelines.py 中定义数据管道,并在 settings.py 中启用它。
8. 常见问题及解决方法
8.1 爬虫被封禁
当我们抓取某些网站时,可能会遇到 IP 被封禁的情况。为了解决这个问题,我们可以使用代理轮换、设置合理的抓取间隔时间等方法。
8.2 数据解析错误
在解析数据时,可能会遇到数据结构变化或数据格式不匹配的情况。为了应对这些问题,我们可以在解析过程中加入异常处理机制,确保程序在遇到错误时不会崩溃。
8.3 数据存储失败
在将数据存储到数据库或文件时,可能会遇到存储失败的情况。常见的原因包括数据库连接问题、数据格式不匹配等。通过日志记录和异常处理,可以更好地定位和解决这些问题。
总结
通过本文的学习,我们深入了解了 Scrapy 的安装和使用方法。Scrapy 作为一个功能强大的爬虫框架,能够帮助我们高效地抓取和处理网页数据。从项目创建、编写爬虫、解析数据到数据存储,我们一步步学习了 Scrapy 的基本使用方法,并介绍了一些高级功能和常见问题的解决方法。
相关文章:
:Scrapy安装及使用「详细介绍」)
Python 爬虫入门(九):Scrapy安装及使用「详细介绍」
Python 爬虫入门(九):Scrapy安装及使用「详细介绍」 前言1. Scrapy 简介2. Scrapy 的安装2.1 环境准备2.2 安装 Scrapy 3. 创建 Scrapy 项目3.1 创建项目3.2 项目结构简介 4. 编写爬虫4.1 创建爬虫4.2 解析数据4.3 运行爬虫 5. 存储数据5.1 存…...
 脚本的实现)
扩展addr2line程序的功能,group_add2line() 脚本的实现
------------------------------------------------------------ author: hjjdebug date: 2024年 08月 05日 星期一 16:19:07 CST descrition: 扩展addr2line程序的功能,group_add2line() 脚本的实现 ------------------------------------------------------------ 扩展addr2…...

idea中修改项目名称
公司最近有个小项目新加了很多功能,在叫原先的项目名有点不合适了。所以在网上查了下资料,发现步骤都比较复杂。自己研究了一下找到了一个相对简单的方法,只需要两步,特此记录一下。 1.修改项目文件夹名称 关闭当前项目ÿ…...

Flink开发语言使用Java还是Scala合适?
目录 1. Flink简介 1.1 什么是Apache Flink? 1.2 Flink的核心组件 2. Java与Scala在Flink开发中的比较 2.1 语言特性对比 2.2 开发体验对比 3. 实际开发中的应用 3.1 使用Java进行Flink开发 3.2 使用Scala进行Flink开发 4. 关键性能和优化 4.1 性能对比 …...

C++STL专题 vector底层实现
目录 一, vector的手搓 1.构造函数 2. 拷贝构造的实现 3.析构函数 4.begin() end() 的实现 5.reserve的实现 6.size和capacity的实现 7.push_back的实现 8.pop_back的实现 9.empty的实现 10.insert的实现 11.erase的实现 12.resize的实现 13.clear的实…...

【Linux】装机常用配置
文章目录 1. 下载常用软件包2. 更新yum源3. vim编辑器配置4. 安装C语言和C的静态库(换root)5. git6. sudo给普通用户提权7. 更新git版本(centos默认安装1.8.x,我们更新到2.x)8. getch9. json10. 升级gcc版本11. 跨系统…...

oracle库PASSWORD_VERSIONS 对应的加密方式
oracle库PASSWORD_VERSIONS 对应的加密方式 10G DES 11G SHA-1 12C SHA-2-based SHA-512官方文档: https://docs.oracle.com/database/121/DBSEG/authentication.htm#DBSEG487...

分享一个基于微信小程序的乡村医疗上门服务预约平台(源码、调试、LW、开题、PPT)
💕💕作者:计算机源码社 💕💕个人简介:本人 八年开发经验,擅长Java、Python、PHP、.NET、Node.js、Android、微信小程序、爬虫、大数据、机器学习等,大家有这一块的问题可以一起交流&…...
)
切香肠(Sausage)
题目描述 有 n 条香肠,每条香肠的长度相等。我们打算将这些香肠切开后分给 k 名客人,且要求每名客人获得一样多的香肠,且要将所有的香肠分配完,不做保留。 请问最少需要切几刀才能完成?一刀只能切断一条香肠…...

Session与Cookie以及Cache区别,及应用场景
Session、Cookie和Cache是Web开发中常用的数据存储方式,它们在功能、存储位置和应用场景上有所不同。 一、Session、Cookie和Cache的区别 Session 存储位置:服务器端。功能:通过在服务器上存储唯一的标识符(Session IDÿ…...
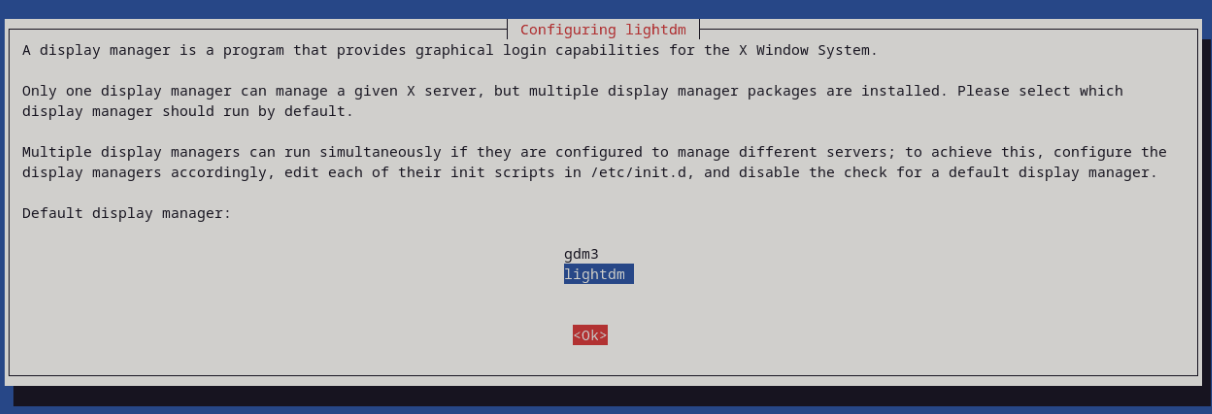
Debian | 更换 Gnome 至 Xfce4
Debian | 更换 Gnome 至 Xfce4 更新源 sudo apt update && sudo apt upgrade安装 xfce4 sudo apt install xfce4我选择 lightdm,回车 切换桌面 sudo update-alternatives --config x-session-manager输入 xfce 所在序号,我这里是 3 卸载 …...

在使用JSON过程中遇到的一个空间释放问题
在对完成的模块进行空间访问检查中发现了这个问题,这刚开始接触JSON的使用,也不知道他的内部实现,因此该问题找了好久,终于发现是每个节点创建都会自动开辟空间,因此造成空间未成功释放的错误。 JSON未成功替换节点空间…...

基于ThinkPHP开发的校园跑腿社区小程序系统源码,包含前后端代码
基于ThinkPHP开发的校园跑腿社区小程序系统源码,包含前后端代码 最新独立版校园跑腿校园社区小程序系统源码 | 附教程 测试环境:NginxPHP7.2MySQL5.6 多校版本,多模块,适合跑腿,外卖,表白,二…...

不同专业方向如何在ChatGPT的帮助下完成选题
学境思源,一键生成论文初稿: AcademicIdeas - 学境思源AI论文写作 选择一个合适的论文题目是每个论文写作同学必须面对的重要任务。无论是历史专业、计算机科学专业,还是其他各个领域,找到一个既有研究价值又符合个人兴趣的选题往…...

MathType7.4中文版本功能详解!你的数学公式编辑神器
嘿,亲爱的小伙伴们,今天我要跟大家分享一个超实用的工具——MathType7中文版。作为一个自媒体人,我常常需要编辑各种复杂的数学公式,而这款软件简直就是我的救星!接下来,就让我带你们领略一下它的神奇之处吧…...
在 PhpStorm 中为 .java 文件启用语法高亮,需要正确配置文件类型和关联语言。
点击访问我的技术博客https://ai.weoknow.comhttps://ai.weoknow.com 因为我同时使用java和php混编所以在一个项目中如果同时打开IntelliJ IDEA和PhpStorm不符合我完美主义的本性。 捣鼓了一下搞定了 1. 添加文件类型关联 将 .java 文件与 Java 语言支持关联: …...

2024年8月1日(前端服务器的配置以及tomcat环境的配置)
[rootstatic ~]# cd eleme_web/ [rootstatic eleme_web]# cd src/ [rootstatic src]# ls views/ AboutView.vue HomeView.vue [rootstatic src]# vim views/HomeView.vue [rootstatic src]# nohup npm run serve nohup: 忽略输入并把输出追加到"nohup.out" 构建项目…...

基于tcp,html,数据库的在线信息查询系统项目总结
1.项目背景 在线信息查询系统是一种可用于检索和展示各种信息的计算机程序或平台。主要特点包括: 用户接口:通常提供友好的界面,用户可以方便地输入查询条件。 数据存储:系统往往连接到数据库,存储大量信息…...

P1032 [NOIP2002 提高组] 字串变换
[NOIP2002 提高组] 字串变换 题目背景 本题不保证存在靠谱的多项式复杂度的做法。测试数据非常的水,各种做法都可以通过,不代表算法正确。因此本题题目和数据仅供参考。 本题为搜索题,本题不接受 hack 数据。关于此类题目的详细内容 题目…...

Android 12系统源码_多屏幕(一)多屏幕设备显示Activity
前言 分屏:是指一个屏幕分出多个窗口,分别显示不同应用的界面,这在当前的手机设备中很常见。多屏:是指一个设备存在多个屏幕,这些可能是虚拟屏幕或者实体硬件屏幕,不同的应用同时显示在不同的屏幕中&#…...

SAP SD装运点自动带出逻辑详解:从销售订单到交货单的完整流程与配置检查清单
SAP SD装运点自动带出逻辑深度解析:从销售订单到交货单的实战指南 在SAP SD模块中,装运点(Shipping Point)的自动决定机制是供应链执行的核心枢纽。想象一下这样的场景:当销售团队在系统中录入一笔跨国订单时ÿ…...

Meta-Llama-3-8B-Instruct开箱即用:小白也能5分钟搭建AI对话应用
Meta-Llama-3-8B-Instruct开箱即用:小白也能5分钟搭建AI对话应用 1. 引言:为什么选择Meta-Llama-3-8B-Instruct? 如果你正在寻找一个既强大又容易上手的AI对话模型,Meta-Llama-3-8B-Instruct绝对值得考虑。这个80亿参数的模型在…...

CefFlashBrowser:拯救Flash游戏的终极工具,让经典游戏重获新生![特殊字符]
CefFlashBrowser:拯救Flash游戏的终极工具,让经典游戏重获新生!🎮 【免费下载链接】CefFlashBrowser Flash浏览器 / Flash Browser 项目地址: https://gitcode.com/gh_mirrors/ce/CefFlashBrowser 还在为无法玩经典Flash游…...

CHORD-X多风格研报生成效果展:对比券商风、学术风与自媒体风格
CHORD-X多风格研报生成效果展:对比券商风、学术风与自媒体风格 最近在试用各种AI写作工具,发现一个挺有意思的现象:很多模型写出来的东西,风格都差不多,要么是那种很官方的口吻,要么就是一股AI味儿。直到我…...

如何在一台电脑上实现多人分屏游戏:Nucleus Co-Op终极指南
如何在一台电脑上实现多人分屏游戏:Nucleus Co-Op终极指南 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 你是否曾梦想与朋友在同一台…...

sudo 命令详解:Linux 权限管理的“万能钥匙“
🔐 sudo 命令详解:Linux 权限管理的"万能钥匙" 💡 你是否曾在 Linux 系统中遇到 “Permission denied” 的报错而手足无措?今天我们就来聊聊 Linux 世界里最重要的命令之一 —— sudo。 文章目录🔐 sudo 命令…...

Ant Media Server性能优化:10个提升流媒体质量的关键技巧
Ant Media Server性能优化:10个提升流媒体质量的关键技巧 【免费下载链接】Ant-Media-Server Ant Media Server — Ultra-low latency streaming engine with WebRTC (~0.5s), SRT, RTMP, HLS, CMAF, adaptive bitrate, transcoding & scaling 项目地址: http…...

大模型---RAG中的数据处理
目录 一.输入侧 1.纯文本TXT/Markdown 2.HTML/网页 3.Word/PPT 4.Email 5.可选中文本PDF 6.扫描PDF/扫描件/文档图片 7.图片/图表/截图/流程图 8.文档中的表格 9.CSV/XLSX 10.音频 11.视频 12.混合文档 二.输出侧 1.输出侧结构化最常见的四种实现方式 2.常见的…...

iStore:OpenWRT软件中心终极安装与使用完整指南
iStore:OpenWRT软件中心终极安装与使用完整指南 【免费下载链接】istore 一个 Openwrt 标准的软件中心,纯脚本实现,只依赖Openwrt标准组件。支持其它固件开发者集成到自己的固件里面。更方便入门用户搜索安装插件。The iStore is a app store…...

关于power bi计算列使用 符号“>“出现报错的问题
解决办法很简单那就是转变逻辑,配合NOT或者"-"之类的方法,使用符号"<"。问题重新:在筛选器中对计算列使用了">"号,视觉对象报错。将">"修改为"<",发现…...