Java序列化与反序列化
优秀博文:IT-BLOG-CN
序列化:把对象转换为字节序列存储于磁盘或者进行网络传输的过程称为对象的序列化。
反序列化:把磁盘或网络节点上的字节序列恢复到对象的过程称为对象的反序列化。
一、序列化对象
【1】必须实现序列化接口Serializable:Java.io.Serializable接口。
【2】serialVersionUID:序列化的版本号,凡是实现Serializable接口的类都有一个静态的表示序列化版本标识符的变量。
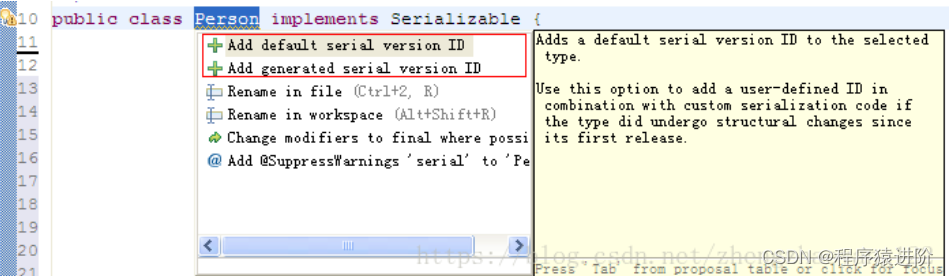
Add default serial version ID:生成的代码为:private static final long serialVersionUID = 1L;
Add generated serial version ID:生成的代码为:private static final long serialVersionUID = -5248069984631225347L;
定义了
serialVersionUID之后,就可以对序列化后的对象进行修改,此时不会产生新的serialVersionUID,导致还原时出错。
【3】serialVersionUID的取值: 此值是通过Java运行时环境根据类的内部细节自动生成的。如果类的源代码进行了修改,再重新编译,新生成的类文件的serialVersionUID的值也会发生变化。不同的编译器也可能会导致不同的serialVersionUID。为了提高serialVersionUID的独立性和确定性,建议在一个序列化类中显示的定义serialVersionUID,为它赋予明确的值。
package com.java;import java.io.Serializable;
import java.util.ArrayList;
import java.util.List;/*** 序列化对象* @author -zhengzx-**/
public class Player implements Serializable{/****/private static final long serialVersionUID = -5248069984631225347L;public Player(long playerId, int age, String name) {this.playerId = playerId;this.age = age;this.name = name;}private long playerId;private int age;private String name;private List<Integer> skills = new ArrayList<>();public long getPlayerId() {return playerId;}public void setPlayerId(long playerId) {this.playerId = playerId;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public List<Integer> getSkills() {return skills;}public void setSkills(List<Integer> skills) {this.skills = skills;}
}
二、序列化与反序列化实例
【1】对象序列化代码如下,具体细节注释说明:Java中通过对象流ObjectOutputStream进行序列化。
【2】反序列化为对象,具体细节注释说明:Java中通过对象流ObjectInputStream进行反序列化。
package com.java;import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.util.Arrays;/*** Description:序列化与反序列化* @author zhengzx*/
public class JavaSerialize {public static void main(String[] args) throws Exception {Player player = new Player(10001, 21, "teacher");player.getSkills().add(10001);//序列化byte[] bytes = toBytes(player);//反序列化toPlay(bytes);}/*** Title: toBytes* Description:序列化对象* @author zhengzx* @throws Exception*/public static byte[] toBytes(Object out) throws Exception {//用于序列化后存储对象ByteArrayOutputStream byteArrayOutputStream = null;//java序列化APIObjectOutputStream objectOutputStream = null;try {byteArrayOutputStream = new ByteArrayOutputStream();objectOutputStream = new ObjectOutputStream(byteArrayOutputStream);//将out对象进行序列化objectOutputStream.writeObject(out);//测试验证输入(获取字节数组)byte[] bs = byteArrayOutputStream.toByteArray();//将数组转化为字符串输入System.out.println(Arrays.toString(bs));return bs;} catch (IOException e) {e.printStackTrace();}finally {//关闭最外层的流(内部流会自动关闭)objectOutputStream.close();}return null;}/** Title: toPlay* Description:反序列化对象* @author zhengzx* @throws Exception*/public static void toPlay(byte[] bs) throws Exception {//创建存放二进制数据的APIByteArrayInputStream byteArrayInputStream = null;//创建反序列化对象ObjectInputStream objectInputStream = null;try {byteArrayInputStream = new ByteArrayInputStream(bs);objectInputStream = new ObjectInputStream(byteArrayInputStream);//校验测试Player player = (Player) objectInputStream.readObject();System.out.println(player.toString());} catch (IOException e) {e.printStackTrace();}finally {objectInputStream.close();}}
}
测试结果展示:
[-84, -19, 0, 5, 115, 114, 0, 15, 99, 111, 109, 46, 106, 97, 46, 80, 108, 97, 121, 101, 114]
Player [playerId=10001, age=21, name=teacher, skills=[10001]]
三、高级部分
序列化和反序列化几乎是工程师们每天都要面对的事情,但是要精确掌握这两个概念并不容易:一方面,它们往往作为框架的一部分出现而湮没在框架之中;另一方面,它们会以其他更容易理解的概念出现,例如加密、持久化。然而,序列化和反序列化的选型却是系统设计或重构一个重要的环节,在分布式、大数据量系统设计里面更为显著。恰当的序列化协议不仅可以提高系统的通用性、强健性、安全性、优化系统性能,而且会让系统更加易于调试、便于扩展。本文从多个角度去分析和讲解“序列化和反序列化”,并对比了当前流行的几种序列化协议,期望对读者做序列化选型有所帮助。
1、定义以及相关概念
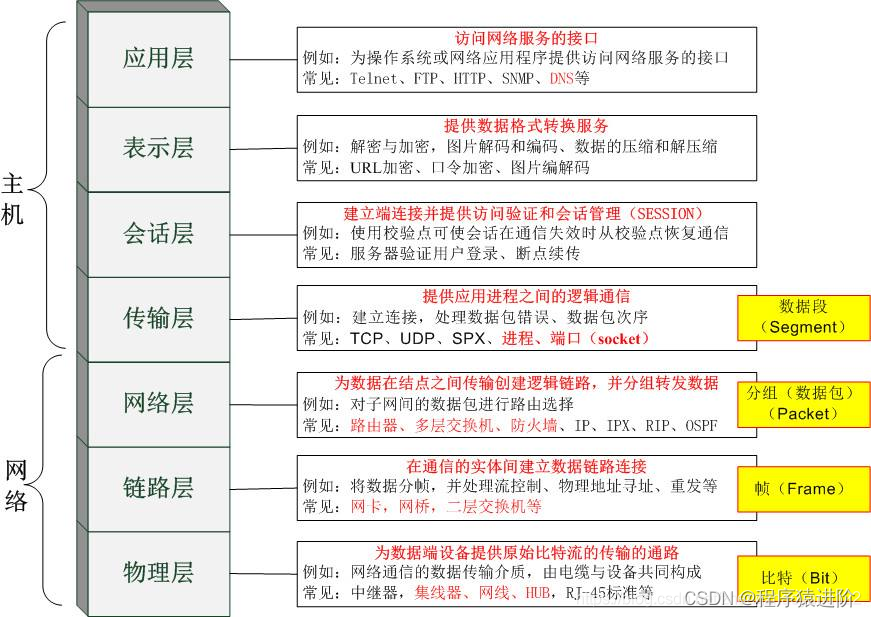
互联网的产生带来了机器间通讯的需求,而互联通讯的双方需要采用约定的协议,序列化和反序列化属于通讯协议的一部分。通讯协议往往采用分层模型,不同模型每层的功能定义以及颗粒度不同,例如:TCP/IP协议是一个四层协议,而OSI模型却是七层协议模型。在OSI七层协议模型中展现层Presentation Layer的主要功能是把应用层的对象转换成一段连续的二进制串,或者反过来,把二进制串转换成应用层的对象,这两个功能就是序列化和反序列化。一般而言,TCP/IP协议的应用层对应与OSI七层协议模型的应用层,展示层和会话层,所以序列化协议属于TCP/IP协议应用层的一部分。本文对序列化协议的讲解主要基于OSI七层协议模型。
数据结构、对象与二进制串: 不同的计算机语言中,数据结构,对象以及二进制串的表示方式并不相同。
数据结构和对象: 对于类似Java这种完全面向对象的语言,工程师所操作的一切都是对象Object,来自于类的实例化。在Java语言中最接近数据结构的概念,就是POJO(Plain Old Java Object)或者Javabean,那些只有setter/getter方法的类。而在C++这种半面向对象的语言中,数据结构和struct对应,对象和class对应。
二进制串: 序列化所生成的二进制串指的是存储在内存中的一块数据。C++语言具有内存操作符,所以二进制串的概念容易理解,例如,C++语言的字符串可以直接被传输层使用,因为其本质上就是以’\0’结尾的存储在内存中的二进制串。在Java语言里面,二进制串的概念容易和String混淆。实际上String是Java的一等公民,是一种特殊对象Object。对于跨语言间的通讯,序列化后的数据当然不能是某种语言的特殊数据类型。二进制串在Java里面所指的是byte[],byte是Java的8中原生数据类型之一Primitive data types。
2、序列化协议特性
每种序列化协议都有优点和缺点,它们在设计之初有自己独特的应用场景。在系统设计的过程中,需要考虑序列化需求的方方面面,综合对比各种序列化协议的特性,最终给出一个折衷的方案。
【1】通用性: 通用性有两个层面的意义:
第一、技术层面,序列化协议是否支持跨平台、跨语言。如果不支持,在技术层面上的通用性就大大降低了。
第二、流行程度,序列化和反序列化需要多方参与,很少人使用的协议往往意味着昂贵的学习成本;另一方面,流行度低的协议,往往缺乏稳定而成熟的跨语言、跨平台的公共包。
【2】强健性/鲁棒性: 以下两个方面的原因会导致协议不够强健:
第一、成熟度不够,一个协议从制定到实施,到最后成熟往往是一个漫长的阶段。协议的强健性依赖于大量而全面的测试,对于致力于提供高质量服务的系统,采用处于测试阶段的序列化协议会带来很高的风险。
第二、语言/平台的不公平性。为了支持跨语言、跨平台的功能,序列化协议的制定者需要做大量的工作;但是,当所支持的语言或者平台之间存在难以调和的特性的时候,协议制定者需要做一个艰难的决定–支持更多人使用的语言/平台,亦或支持更多的语言/平台而放弃某个特性。当协议的制定者决定为某种语言或平台提供更多支持的时候,对于使用者而言,协议的强健性就被牺牲了。
【3】可调试性/可读性: 序列化和反序列化的数据正确性和业务正确性的调试往往需要很长的时间,良好的调试机制会大大提高开发效率。序列化后的二进制串往往不具备人眼可读性,为了验证序列化结果的正确性,写入方不得同时撰写反序列化程序,或提供一个查询平台,这比较费时;另一方面,如果读取方未能成功实现反序列化,这将给问题查找带来了很大的挑战,难以定位是由于自身的反序列化程序的bug所导致还是由于写入方序列化后的错误数据所导致。对于跨公司间的调试,由于以下原因,问题会显得更严重:
第一、支持不到位,跨公司调试在问题出现后可能得不到及时的支持,这大大延长了调试周期。
第二、访问限制,调试阶段的查询平台未必对外公开,这增加了读取方的验证难度。
如果序列化后的数据人眼可读,这将大大提高调试效率,
XML和JSON就具有人眼可读的优点。
【4】性能: 性能包括两个方面,时间复杂度和空间复杂度:
第一、空间开销Verbosity, 序列化需要在原有的数据上加上描述字段,以为反序列化解析之用。如果序列化过程引入的额外开销过高,可能会导致过大的网络,磁盘等各方面的压力。对于海量分布式存储系统,数据量往往以TB为单位,巨大的的额外空间开销意味着高昂的成本。
第二、时间开销Complexity,复杂的序列化协议会导致较长的解析时间,这可能会使得序列化和反序列化阶段成为整个系统的瓶颈。
【5】可扩展性/兼容性: 移动互联时代,业务系统需求的更新周期变得更快,新的需求不断涌现,而老的系统还是需要继续维护。如果序列化协议具有良好的可扩展性,支持自动增加新的业务字段,而不影响老的服务,这将大大提供系统的灵活度。
【6】安全性/访问限制: 在序列化选型的过程中,安全性的考虑往往发生在跨局域网访问的场景。当通讯发生在公司之间或者跨机房的时候,出于安全的考虑,对于跨局域网的访问往往被限制为基于HTTP/HTTPS的80和443端口。如果使用的序列化协议没有兼容而成熟的HTTP传输层框架支持,可能会导致以下三种结果之一:第一、因为访问限制而降低服务可用性。 第二、被迫重新实现安全协议而导致实施成本大大提高。 第三、开放更多的防火墙端口和协议访问,而牺牲安全性。
3、序列化和反序列化的组件
典型的序列化和反序列化过程往往需要如下组件:
【1】IDL(Interface description language)文件: 参与通讯的各方需要对通讯的内容需要做相关的约定Specifications。为了建立一个与语言和平台无关的约定,这个约定需要采用与具体开发语言、平台无关的语言来进行描述。这种语言被称为接口描述语言IDL,采用 IDL撰写的协议约定称之为IDL文件。
【2】IDL Compiler: IDL文件中约定的内容为了在各语言和平台可见,需要有一个编译器,将IDL文件转换成各语言对应的动态库。
【3】Stub/Skeleton Lib: 负责序列化和反序列化的工作代码。Stub是一段部署在分布式系统客户端的代码,一方面接收应用层的参数,并对其序列化后通过底层协议栈发送到服务端,另一方面接收服务端序列化后的结果数据,反序列化后交给客户端应用层;Skeleton部署在服务端,其功能与Stub相反,从传输层接收序列化参数,反序列化后交给服务端应用层,并将应用层的执行结果序列化后最终传送给客户端Stub。
【4】Client/Server: 指的是应用层程序代码,他们面对的是IDL所生存的特定语言的class或struct。
【5】底层协议栈和互联网: 序列化之后的数据通过底层的传输层、网络层、链路层以及物理层协议转换成数字信号在互联网中传递。
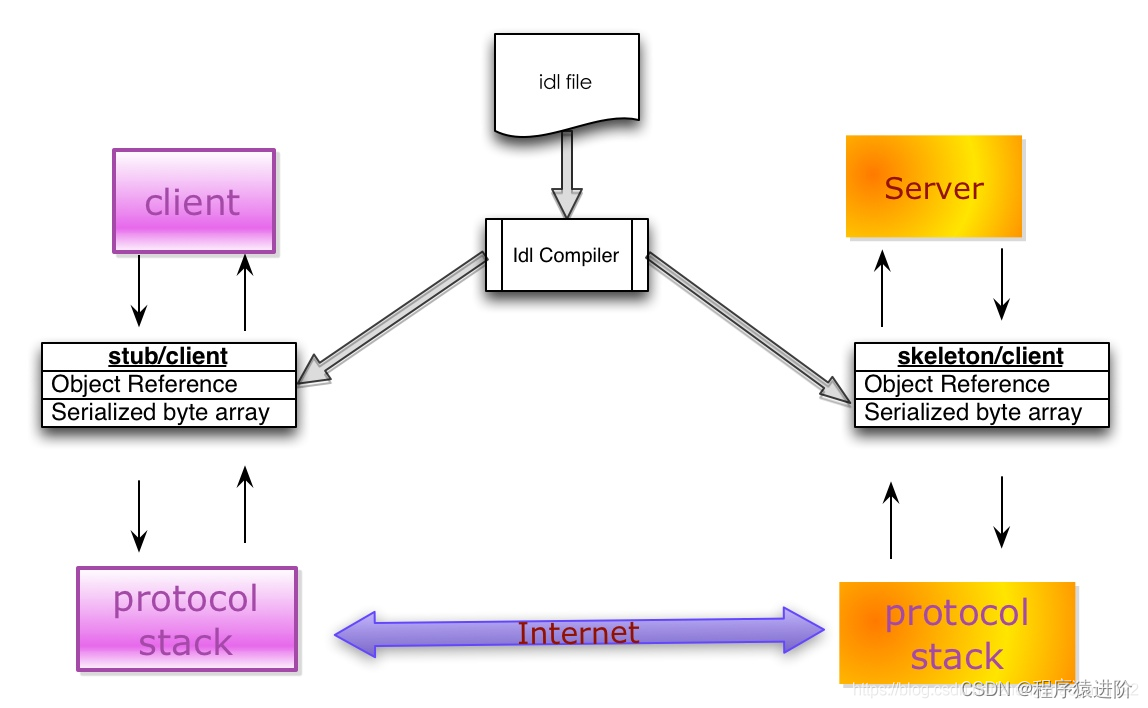
序列化组件与数据库访问组件的对比: 数据库访问对于很多工程师来说相对熟悉,所用到的组件也相对容易理解。下表类比了序列化过程中用到的部分组件和数据库访问组件的对应关系,以便于大家更好的把握序列化相关组件的概念。
| 序列化组件 | 数据库组件 | 说明 |
|---|---|---|
| IDL | DDL | 用于建表或者模型的语言 |
| DL file | DB Schema | 表创建文件或模型文件 |
| Stub/Skeleton lib | O/R mapping | 将class和Table或者数据模型进行映射 |
4、几种常见的序列化和反序列化协议
这里主要介绍和对比几种当下比较流行的序列化协议,包括
XML、JSON、Protobuf、Thrift和Avro。
序列化和反序列化的出现往往晦涩而隐蔽,与其他概念之间往往相互包容。为了更好的理解序列化和反序列化的相关概念在每种协议里面的具体实现,我们将一个例子穿插在各种序列化协议讲解中。在该例子中,我们希望将一个用户信息在多个系统里面进行传递;在应用层,如果采用Java语言,所面对的类对象如下所示:
class Address
{private String city;private String postcode;private String street;
}
public class UserInfo
{private Integer userid;private String name;private List<Address> address;
}
XML&SOAP
XML是一种常用的序列化和反序列化协议,具有跨机器,跨语言等优点。 XML历史悠久,其1.0版本早在1998年就形成标准,并被广泛使用至今。XML的最初产生目标是对互联网文档Document进行标记,所以它的设计理念中就包含了对于人和机器都具备可读性。 但是,当这种标记文档的设计被用来序列化对象的时候,就显得冗长而复杂Verbose and Complex。XML本质上是一种描述语言,并且具有自我描述Self-describing的属性,所以XML自身就被用于XML序列化的IDL。标准的XML描述格式有两种:DTD(Document Type Definition)和XSD(XML Schema Definition)。作为一种人眼可读Human-readable的描述语言,XML被广泛使用在配置文件中,例如O/R mapping、Spring Bean Configuration File等。
SOAP(Simple Object Access protocol)是一种被广泛应用的,基于XML为序列化和反序列化协议的结构化消息传递协议。SOAP在互联网影响如此大,以至于我们给基于SOAP的解决方案一个特定的名称Web service。SOAP虽然可以支持多种传输层协议,不过SOAP最常见的使用方式还是XML+HTTP。SOAP协议的主要接口描述语言IDL是WSDL(Web Service Description Language)。SOAP具有安全、可扩展、跨语言、跨平台并支持多种传输层协议。如果不考虑跨平台和跨语言的需求,XML的在某些语言里面具有非常简单易用的序列化使用方法,无需IDL文件和第三方编译器, 例如Java+XStream。
SOAP是一种采用XML进行序列化和反序列化的协议,它的IDL是WSDL. 而WSDL的描述文件是XSD,而XSD自身是一种XML文件。 这里产生了一种有趣的在数学上称之为“递归”的问题,这种现象往往发生在一些具有自我属性Self-description的事物上。
IDL文件举例,采用WSDL描述上述用户基本信息的例子如下:
<xsd:complexType name='Address'><xsd:attribute name='city' type='xsd:string' /><xsd:attribute name='postcode' type='xsd:string' /><xsd:attribute name='street' type='xsd:string' />
</xsd:complexType>
<xsd:complexType name='UserInfo'><xsd:sequence><xsd:element name='address' type='tns:Address'/><xsd:element name='address1' type='tns:Address'/></xsd:sequence><xsd:attribute name='userid' type='xsd:int' /><xsd:attribute name='name' type='xsd:string' />
</xsd:complexType>
典型应用场景和非应用场景: SOAP协议具有广泛的群众基础,基于HTTP的传输协议使得其在穿越防火墙时具有良好安全特性,XML所具有的人眼可读Human-readable特性使得其具有出众的可调试性,互联网带宽的日益剧增也大大弥补了其空间开销大Verbose的缺点。对于在公司之间传输数据量相对小或者实时性要求相对低(例如秒级别)的服务是一个好的选择。
由于XML的额外空间开销大,序列化之后的数据量剧增,对于数据量巨大序列持久化应用常景,这意味着巨大的内存和磁盘开销,不太适合XML。另外,XML的序列化和反序列化的空间和时间开销都比较大,对于对性能要求在 ms级别的服务,不推荐使用。WSDL虽然具备了描述对象的能力,SOAP的S代表的也是simple,但是SOAP的使用绝对不简单。对于习惯于面向对象编程的用户,WSDL文件不直观。
JSON(Javascript Object Notation)
JSON起源于弱类型语言Javascript,它的产生来自于一种称之为Associative array的概念,其本质是就是采用Attribute-value的方式来描述对象。实际上在Javascript和PHP等弱类型语言中,类的描述方式就是Associative array。JSON的如下优点,使得它快速成为最广泛使用的序列化协议之一:
【1】这种Associative array格式非常符合工程师对对象的理解。
【2】它保持了XML的人眼可读Human-readable的优点。
【3】相对于XML而言,序列化后的数据更加简洁。 来自于的以下链接的研究表明:XML所产生序列化之后文件的大小接近JSON的两倍。
【4】它具备Javascript的先天性支持,所以被广泛应用于Web browser的应用常景中,是Ajax的事实标准协议。
【5】与XML相比,其协议比较简单,解析速度比较快。
【6】松散的Associative array使得其具有良好的可扩展性和兼容性。
IDL悖论:JSON实在是太简单了,或者说太像各种语言里面的类了,所以采用JSON进行序列化不需要IDL。这实在是太神奇了,存在一种天然的序列化协议,自身就实现了跨语言和跨平台。然而事实没有那么神奇,之所以产生这种假象,来自于两个原因:
【1】Associative array在弱类型语言里面就是类的概念,在 PHP和 Javascript里面 Associative array就是其 class的实际实现方式,所以在这些弱类型语言里面,JSON得到了非常良好的支持。
【2】IDL的目的是撰写IDL文件,而IDL文件被IDL Compiler编译后能够产生一些代码Stub/Skeleton,而这些代码是真正负责相应的序列化和反序列化工作的组件。但是由于Associative array和一般语言里面的class太像了,他们之间形成了一一对应关系,这就使得我们可以采用一套标准的代码进行相应的转化。对于自身支持Associative array的弱类型语言,语言自身就具备操作JSON序列化后的数据的能力;对于Java这强类型语言,可以采用反射的方式统一解决,例如Google提供的Gson。
典型应用场景和非应用场景:JSON在很多应用场景中可以替代XML,更简洁并且解析速度更快。典型应用场景包括:
【1】公司之间传输数据量相对小,实时性要求相对低(例如秒级别)的服务。
【2】基于Web browser的Ajax请求。
【3】由于JSON具有非常强的前后兼容性,对于接口经常发生变化,并对可调式性要求高的场景,例如Mobile app与服务端的通讯。
【4】由于JSON的典型应用场景是JSON+HTTP,适合跨防火墙访问。
总的来说,采用JSON进行序列化的额外空间开销比较大,对于大数据量服务或持久化,这意味着巨大的内存和磁盘开销,这种场景不适合。没有统一可用的IDL降低了对参与方的约束,实际操作中往往只能采用文档方式来进行约定,这可能会给调试带来一些不便,延长开发周期。 由于JSON在一些语言中的序列化和反序列化需要采用反射机制,所以在性能要求为ms级别,不建议使用。
IDL文件举例:以下是UserInfo序列化之后的一个例子:
{"userid":1,"name":"messi","address":[{"city":"北京","postcode":"1000000","street":"wangjingdonglu"}]}
Thrift
Thrift是Facebook开源提供的一个高性能,轻量级RPC服务框架,其产生正是为了满足当前大数据量、分布式、跨语言、跨平台数据通讯的需求。 但是,Thrift并不仅仅是序列化协议,而是一个RPC框架。相对于JSON和XML而言,Thrift在空间开销和解析性能上有了比较大的提升,对于对性能要求比较高的分布式系统,它是一个优秀的RPC解决方案;但是由于Thrift的序列化被嵌入到Thrift框架里面,Thrift框架本身并没有透出序列化和反序列化接口,这导致其很难和其他传输层协议共同使用(例如HTTP)。
典型应用场景和非应用场景:对于需求为高性能,分布式的RPC服务,Thrift是一个优秀的解决方案。它支持众多语言和丰富的数据类型,并对于数据字段的增删具有较强的兼容性。所以非常适用于作为公司内部的面向服务构建SOA的标准 RPC框架。不过Thrift的文档相对比较缺乏,目前使用的群众基础相对较少。另外由于其Server是基于自身的Socket服务,所以在跨防火墙访问时,安全是一个顾虑,所以在公司间进行通讯时需要谨慎。 另外Thrift序列化之后的数据是Binary数组,不具有可读性,调试代码时相对困难。最后,由于Thrift的序列化和框架紧耦合,无法支持向持久层直接读写数据,所以不适合做数据持久化序列化协议。
IDL文件举例:
struct Address
{1: required string city;2: optional string postcode;3: optional string street;
}
struct UserInfo
{1: required string userid;2: required i32 name;3: optional list<Address> address;
}
Protobuf
Protobuf具备了优秀的序列化协议的所需的众多典型特征:
【1】标准的IDL和IDL编译器,这使得其对工程师非常友好。
【2】序列化数据非常简洁,紧凑,与XML相比,其序列化之后的数据量约为1/3到1/10。
【3】解析速度非常快,比对应的XML快约20-100倍。
【4】提供了非常友好的动态库,使用非常简介,反序列化只需要一行代码。
Protobuf是一个纯粹的展示层协议,可以和各种传输层协议一起使用;Protobuf的文档也非常完善。 但是由于Protobuf产生于Google,所以目前其仅仅支持Java、C++、Python三种语言。另外Protobuf支持的数据类型相对较少,不支持常量类型。由于其设计的理念是纯粹的展现层协议Presentation Layer,目前并没有一个专门支持Protobuf的RPC框架。
典型应用场景和非应用场景:Protobuf具有广泛的用户基础,空间开销小以及高解析性能是其亮点,非常适合于公司内部的对性能要求高的RPC调用。由于Protobuf提供了标准的IDL以及对应的编译器,其IDL文件是参与各方的非常强的业务约束,另外,Protobuf与传输层无关,采用HTTP具有良好的跨防火墙的访问属性,所以Protobuf也适用于公司间对性能要求比较高的场景。由于其解析性能高,序列化后数据量相对少,非常适合应用层对象的持久化场景。
它的主要问题在于其所支持的语言相对较少,另外由于没有绑定的标准底层传输层协议,在公司间进行传输层协议的调试工作相对麻烦。
IDL文件举例
message Address
{required string city=1;optional string postcode=2;optional string street=3;
}
message UserInfo
{required string userid=1;required string name=2;repeated Address address=3;
}
Avro
Avro的产生解决了JSON的冗长和没有IDL的问题,Avro属于Apache Hadoop的一个子项目。Avro提供两种序列化格式:JSON格式或者Binary格式。Binary格式在空间开销和解析性能方面可以和Protobuf媲美,JSON格式方便测试阶段的调试。Avro支持的数据类型非常丰富,包括 C++语言里面的 union类型。Avro支持JSON格式的IDL和类似于Thrift和Protobuf的IDL(实验阶段),这两者之间可以互转。Schema可以在传输数据的同时发送,加上JSON的自我描述属性,这使得Avro非常适合动态类型语言。Avro在做文件持久化的时候,一般会和Schema一起存储,所以Avro序列化文件自身具有自我描述属性,所以非常适合于做Hive、Pig和MapReduce的持久化数据格式。对于不同版本的Schema,在进行RPC调用的时候,服务端和客户端可以在握手阶段对Schema进行互相确认,大大提高了最终的数据解析速度。
典型应用场景和非应用场景:Avro解析性能高并且序列化之后的数据非常简洁,比较适合于高性能的序列化服务。
由于
Avro目前非JSON格式的IDL处于实验阶段,而JSON格式的IDL对于习惯于静态类型语言的工程师来说不直观。
IDL文件举例
protocol Userservice {record Address {string city;string postcode;string street;}record UserInfo {string name;int userid;array<Address> address = [];}
}
essess所对应的JSON Schema格式如下:
{"protocol" : "Userservice","namespace" : "org.apache.avro.ipc.specific","version" : "1.0.5","types" : [ {"type" : "record","name" : "Address","fields" : [ {"name" : "city","type" : "string"}, {"name" : "postcode","type" : "string"}, {"name" : "street","type" : "string"} ]}, {"type" : "record","name" : "UserInfo","fields" : [ {"name" : "name","type" : "string"}, {"name" : "userid","type" : "int"}, {"name" : "address","type" : {"type" : "array","items" : "Address"},"default" : [ ]} ]} ],"messages" : { }
}
5、Benchmark以及选型建议
解析性能
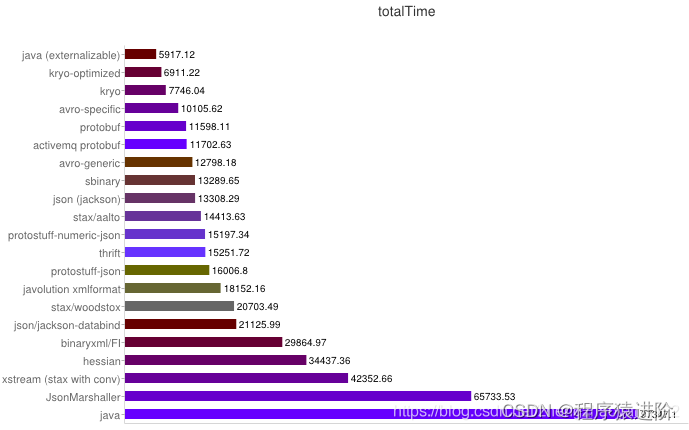
序列化之空间开销
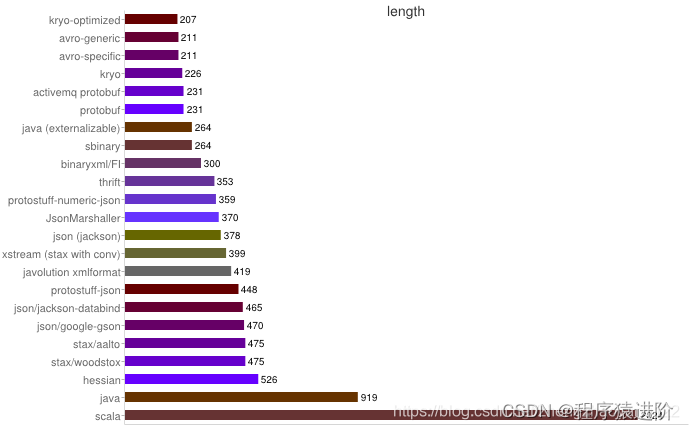
从上图可得出如下结论:
【1】XML序列化Xstream无论在性能和简洁性上比较差。
【2】Thrift与Protobuf相比在时空开销方面都有一定的劣势。
【3】Protobuf和Avro在两方面表现都非常优越。
选型建议: 以上描述的五种序列化和反序列化协议都各自具有相应的特点,适用于不同的场景:
【1】对于公司间的系统调用,如果性能要求在100ms以上的服务,基于XML的SOAP协议是一个值得考虑的方案。
【2】基于Web browser的Ajax,以及Mobile app与服务端之间的通讯,JSON协议是首选。对于性能要求不太高,或者以动态类型语言为主,或者传输数据载荷很小的的运用场景,JSON也是非常不错的选择。
【3】对于调试环境比较恶劣的场景,采用JSON或XML能够极大的提高调试效率,降低系统开发成本。
【4】当对性能和简洁性有极高要求的场景,Protobuf,Thrift,Avro之间具有一定的竞争关系。
【5】对于T级别的数据的持久化应用场景,Protobuf和Avro是首要选择。如果持久化后的数据存储在Hadoop子项目里,Avro会是更好的选择。
【6】由于Avro的设计理念偏向于动态类型语言,对于动态语言为主的应用场景,Avro是更好的选择。
【7】对于持久层非Hadoop项目,以静态类型语言为主的应用场景,Protobuf会更符合静态类型语言工程师的开发习惯。
【8】如果需要提供一个完整的RPC解决方案,Thrift是一个好的选择。
【9】如果序列化之后需要支持不同的传输层协议,或者需要跨防火墙访问的高性能场景,Protobuf可以优先考虑。
相关文章:
Java序列化与反序列化
优秀博文:IT-BLOG-CN 序列化:把对象转换为字节序列存储于磁盘或者进行网络传输的过程称为对象的序列化。 反序列化:把磁盘或网络节点上的字节序列恢复到对象的过程称为对象的反序列化。 一、序列化对象 【1】必须实现序列化接口Serializabl…...
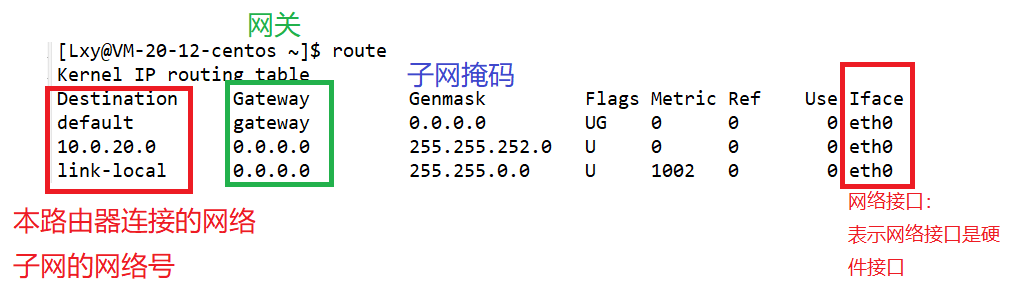
【网络】网络层协议——IP
目录网络层IP协议IP基础知识IP地址IP报头格式网段划分CIDR特殊的IP地址IP地址的数量限制私有IP地址和公有IP地址路由IP总结网络层 在复杂的网络环境中确定一个合法的路径。 IP协议 IP协议作为整个TCP/IP中至关重要的协议,主要负责将数据包发送给最终的目标计算机…...

安装kubernetes
master110.10.10.10docker、kubelet、kubeadm、kubectlmaster210.10.10.11docker、kubelet、kubeadm、kubectlnode110.10.10.12docker、kubelet、kubeadm、kubectlnode210.10.10.13docker、kubelet、kubeadm、kubectl 1.关闭防火墙(所有节点执行) syste…...

三维点云转深度图
文章目录 目录 一、算法原理 算法流程 二、代码实现 1.Python代码 2....
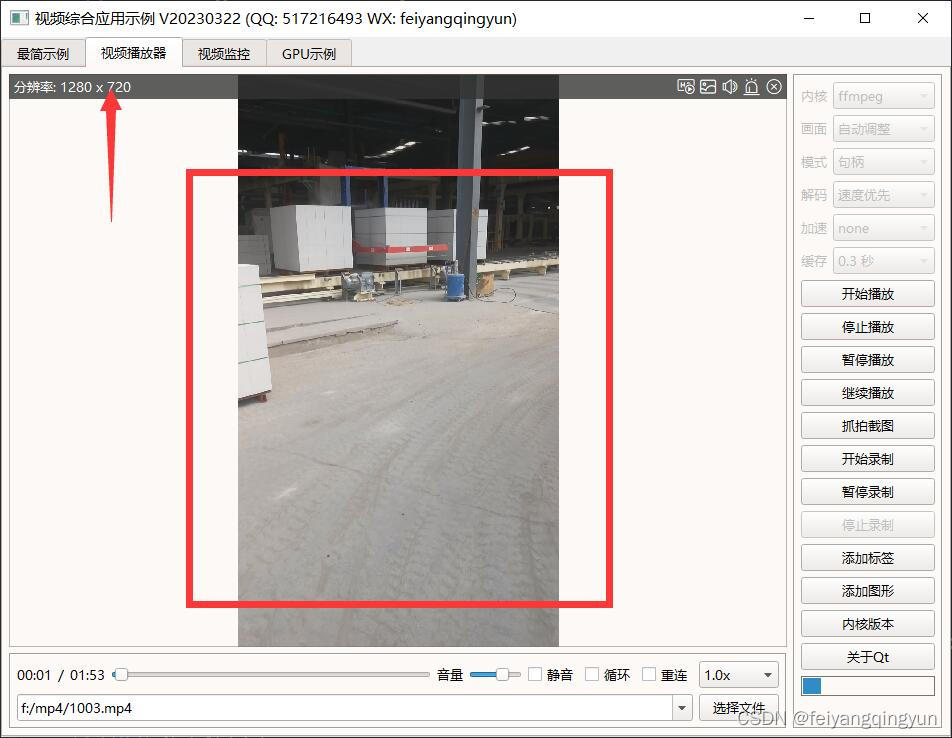
Qt音视频开发27-ffmpeg视频旋转显示
一、前言 用手机或者平板拍摄的视频文件,很可能是旋转的,比如分辨率是1280x720,确是垂直的,相当于分辨率变成了720x1280,如果不做旋转处理的话,那脑袋必须歪着看才行,这样看起来太难受…...

python例程:《彩图版飞机大战》程序
目录开发环境要求运行方法《彩图版飞机大战》程序使用说明源码示例源码及说明文档下载路径开发环境要求 本系统的软件开发及运行环境具体如下。 操作系统:Windows 7、Windows 10。 Python版本:Python 3.7.1。 开发工具:PyCharm 2018。…...
【前端八股文】JavaScript系列:Set、Map、String常用属性方法
文章目录Set概念与arr的比较属性和方法并集、交集、差集Map概念属性和方法String用索引值和charAt()的区别charAt()和charCodeAt()方法的区别5个查找方法的区别如何把字符串分割为数组3个截取方法的区别大小写转换3个模式匹配方法(正则表达式)3个移除字符…...
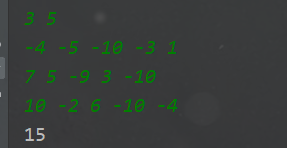
跳跃-动态规划问题
跳跃-动态规划问题1、题目描述2、解题思路2.1 解法一:动态规划2.2 解法二:DFS深度优先搜索最大权值1、题目描述 小蓝在一个 n 行 m 列的方格图中玩一个游戏。 开始时,小蓝站在方格图的左上角,即第 11 行第 11 列。 小蓝可以在方格…...

Django笔记三十九之settings配置介绍
这一篇笔记介绍 Django 里 settings.py 里一些常用的配置项,这些配置有一些是在之前的笔记中有过介绍的,比如 logging 的日志配置,session 的会话配置等,这里就只做一下简单的回顾,有一些是之前没有介绍过的就着重介绍…...
【JavaSE】类和对象(中)
类和对象(中)4. this引用4.1 为什么要有this引用4.2 什么是this引用4.3 this引用的特性5. 对象的构造及初始化5.1 如何初始化对象5.2 构造方法(构造器)5.2.1 概念5.2.2 特性5.3 默认初始化5.4 就地初始化6. 封装6.1 封装的概念6.2…...
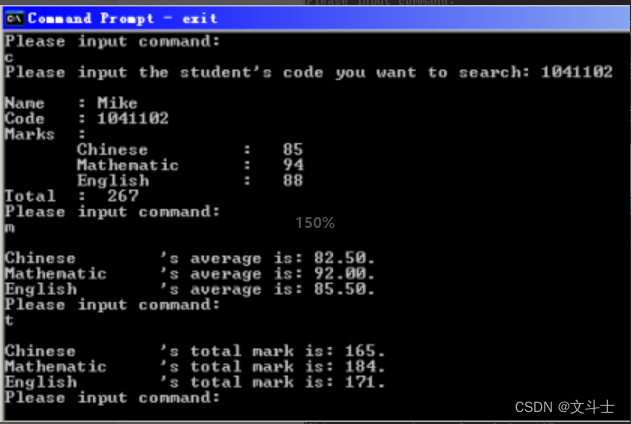
C语言例程:学生成绩管理程序
学生成绩管理程序 实例说明 编制一个统计存储在文件中的学生考试分数的管理程序。设学生成绩以一个学生一条记录的 形式存储在文件中,每个学生记录包含的信息有姓名、学号和各门功课的成绩。要求编制具有以 下几项功能的程序:求出各门课程的总分&#…...

完美日记母公司再度携手中国妇基会,以“创美人生”助力女性成长
撰稿 | 多客 来源 | 贝多财经 当春时节,梦想花开。和煦的三月暖阳,唤醒的不止是满城春意,更有逸仙电商“创美人生”公益项目播撒的一份希望。 3月8日“国际妇女节”当日,为积极响应我国促进共同富裕的政策倡导,助力相…...
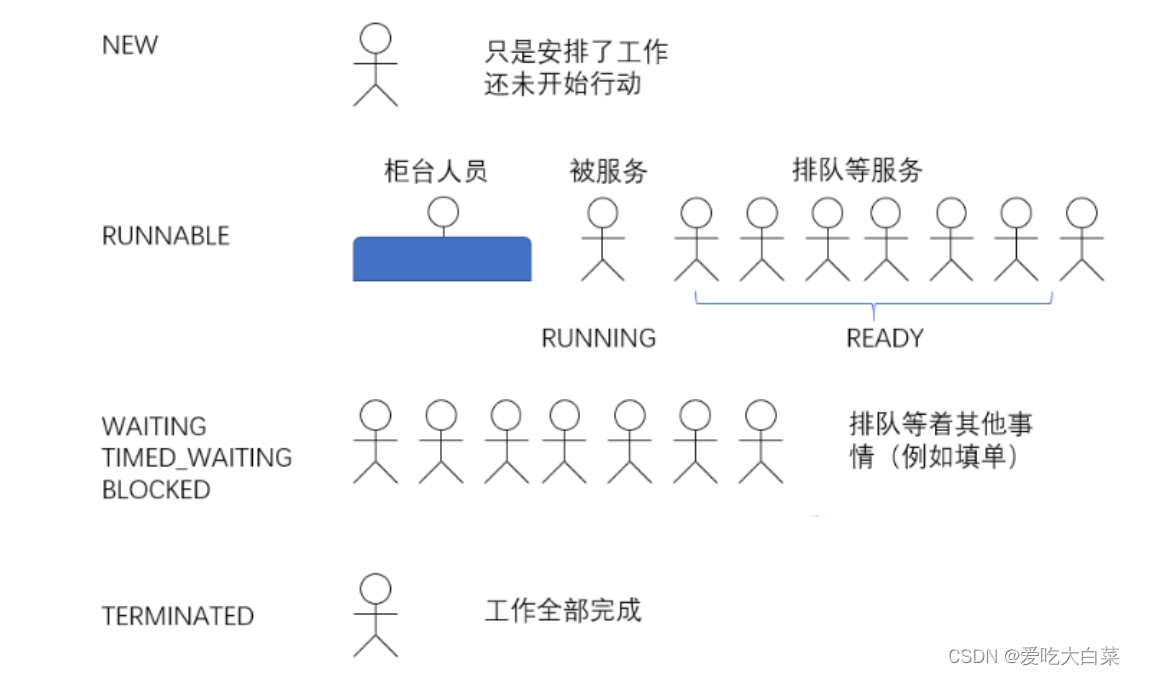
【JaveEE】线程的创建及常见方法解析(Tread类)
目录 1.Tread类介绍 2线程的构造方法——创建线程 1.继承Thread类,重写run()方法 2.使用Runnbable接口创建线程 3.继承 Thread, 重写 run, 使用匿名内部类 4.实现 Runnable, 重写 run, 使用匿名内部类 5.使用 lambda 表达式(重点掌握)…...

Linux的诞生过程
个人简介:云计算网络运维专业人员,了解运维知识,掌握TCP/IP协议,每天分享网络运维知识与技能。座右铭:海不辞水,故能成其大;山不辞石,故能成其高。个人主页:小李会科技的…...
面部表情识别1:表情识别数据集(含下载链接)
面部表情识别1:表情识别数据集(含下载链接) 目录 面部表情识别1:表情识别数据集(含下载链接) 1.前言 2.表情识别数据集介绍 1.JAFFE数据集 2.KDEF(Karolinska Directed Emotional Faces)数据集 3.GENKI数据集 4.RaFD数据集…...

CSS实现文字凹凸效果
使用两个div分别用来实现凹凸效果;text-shadow语法 text-shadow: h-shadow v-shadow blur color; h-shadow:必需。水平阴影的位置。允许负值。 v-shadow :必需。垂直阴影的位置。允许负值。 blur:可选,模糊的距离。 co…...

嵌入式常使用的库函数
自己创建简单的mcu中常用的库函数 文章目录自己创建简单的mcu中常用的库函数1. 自己编写库函数的意义2. 计算字符串长度.以\0作为结束符3. 复制字符串4. 字符串比较5. 将整数转换为ASCII数组6. 将ASCII码字符串转换成整数7. 将字节数组转换为16位整数8.计算CRC,用于Modbus协议9…...
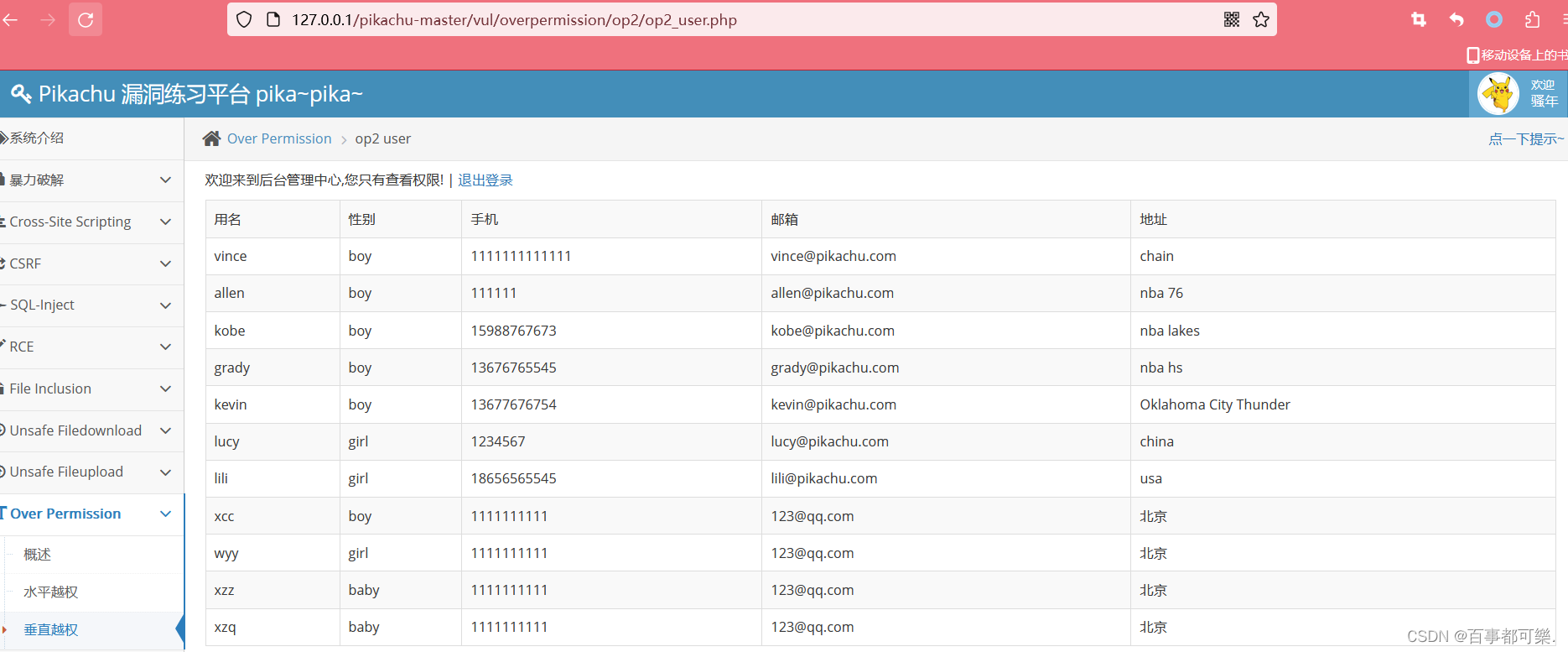
【业务安全-02】业务逻辑漏洞之越权操作
越权越权即越权查看被人的信息,又分为水平越权和垂直越权,但是两者的本质都是一样的,只是越权的身份权限不一样而已水平越权:相同级别的用户,如用户A访问用户B垂直越权:普通用户到管理员,普通用…...
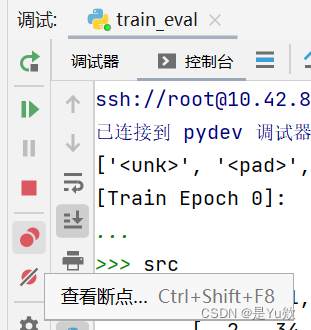
完全小白的pycharm深度学习调试+for循环断点条件设置
完全小白的pycharm深度学习调试for循环断点条件设置写在最前面基础方法pycharm断点调试控制台输入代码中循环的debug方法pycharm中图标的介绍常见的BugDebug经验1. 检查激活函数的输入值2. 检查梯度3. 消融实验4. 使用最短的时间5. 静下心来写在最前面 之前把seq2seqattention…...

直方图及其应用
直方图定义直方图是一种描述数据的分布通过将连续变量划分成一系列区间,统计区间频率,并用来表示,以表征其统计特征在图像处理中,直方图可以用来表示图像中像素值的分布状况,描述不同灰度级的像素在图像中的占比直方图…...

主体代码分析
一、整体架构分析这个程序是一个图片管理工具,采用MVC模式的变体,分为:UI层:界面定义(ui_image_manager.py,由Qt Designer生成)逻辑层:当前文件的业务逻辑业务层:busines…...

PP-DocLayoutV3实操手册:display_formula公式块检测准确率提升的3个微调技巧
PP-DocLayoutV3实操手册:display_formula公式块检测准确率提升的3个微调技巧 1. 引言:为什么公式检测这么重要? 在文档数字化处理过程中,数学公式的准确检测一直是个技术难点。传统的OCR系统往往把公式误判为普通文本或图像&…...

水墨江南模型效果对比:不同参数下的笔触与渲染风格
水墨江南模型效果对比:不同参数下的笔触与渲染风格 最近在尝试用AI生成水墨画,发现一个挺有意思的现象:同一个“水墨江南”模型,用不同的参数设置,画出来的效果天差地别。有时候是寥寥几笔的写意小品,有时…...

OpenClaw开源项目深度体验:对比其与星图GPU平台Qwen3-14B-Int4-AWQ部署差异
OpenClaw开源项目深度体验:对比其与星图GPU平台Qwen3-14B-Int4-AWQ部署差异 1. 项目概览与核心功能 OpenClaw是近期备受关注的开源大模型项目,主打轻量化和易部署特性。它采用混合专家架构(MoE),在保持模型性能的同时显著降低了计算资源需求…...

实验室搬砖实录:手把手教你搞定柱层析,从TLC监测到梯度洗脱的保姆级避坑指南
实验室搬砖实录:手把手教你搞定柱层析,从TLC监测到梯度洗脱的保姆级避坑指南 记得第一次独立做柱层析时,盯着那根玻璃柱看了半小时,愣是没敢动手。TLC板上明明分得挺开的点,怎么一上柱子就全乱了?洗脱液极性…...

轻量锐驰 x 轻量对象存储:构建个人专属高速云存储方案
1. 为什么你需要自建云存储? 每次用公共网盘传文件都像在参加龟速比赛?分享给朋友时对方总抱怨下载慢如蜗牛?我三年前就开始研究自建云存储方案,实测下来轻量锐驰服务器轻量对象存储的组合,速度能跑满家庭宽带上限&…...

告别msi2lmp参数缺失!手把手教你用Perl脚本insight2lammps搞定MS到LAMMPS的data文件转换
告别msi2lmp参数缺失!手把手教你用Perl脚本insight2lammps搞定MS到LAMMPS的data文件转换 分子动力学模拟研究者们常常遇到这样的困境:在Materials Studio(MS)中精心构建的模型,导出后却因LAMMPS自带的msi2lmp工具参数缺…...

.NET源码生成器使用SyntaxTree生成代码及简化语法
一、SyntaxTree是什么SyntaxTree是语法树,是源代码的树形结构表示由Roslyn编译器生成在SourceGenerator中会自动生成整个源代码结构是1个SyntaxTreeSyntaxTree有一个根节点(SyntaxNode)每个SyntaxNode也包含一个SyntaxTree这样看整个源代码结构就是片“森林”public abstract p…...

抖音无水印下载完全指南:5分钟掌握批量下载核心技巧
抖音无水印下载完全指南:5分钟掌握批量下载核心技巧 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support…...

HUNYUAN-MT 7B翻译终端Python爬虫数据清洗实战:多语言文本归一化处理
HUNYUAN-MT 7B翻译终端Python爬虫数据清洗实战:多语言文本归一化处理 1. 引言 你有没有遇到过这种情况?辛辛苦苦用Python爬虫从全球各地的网站、论坛、社交媒体上抓取了一大堆数据,准备做分析或者训练模型,结果打开一看…...