多目标家庭行为检测--人脸识别模块构建
文章目录
- 前言
- 原理
- 项目结构
- 编码
- 配置
- 主控函数
- 人脸采集模块
- 特征提取
- 识别
- 测试
前言
2023-3-18 天小雨,午觉舒适程度5颗星。任务完成指数2颗星。续接上文:《MidiaPipe +stgcn(时空图卷积网络)实现人体姿态判断(单目标)》,我们这边需要实现的是一个多目标的检测,并且我们期望能够适用在家庭这里领域,因此,在前者算法改进的基础上,我们还需要加入这个人脸识别模块。调某度这些现成的开发的API当然可以,但是自己搭建价更高,能装13还不用小钱钱,数据牢牢在手,主打的就是一个安全。
同样的,我们还是按照以前的习惯,一个模块一个模块来进行说明,写完之后的话,再进行完整版本的开源,但是每一个独立的模块都是开源直接使用的,这个可以放心,也就是说按照本文给到项目结构和代码,是可以直接复现运行的。但是这里声明一下,这个项目是一个综合项目,有算法,有前端,有后端,技术体系覆盖vue , python(fastapi),java(SpringBoot)开发这里开源的模块是算法模块。其他的模块不开源,因为这个也是我们技术团队做的一个大创项目,同时,这个项目也不算是个小项目,里面覆盖的技术不少,需要同时具备Python和Java开发能力以及以Python为体现的人工智能应用开发能力,所以就算开源全部模块,对于读者的要求是比较高的。
之后我要说明的一点是,本篇文章中的相当一部分代码,其实是通过NewBing和ChatGPT生成的,使用的第三方库是dlib,我的工作是负责将这些代码进行整合,修改,测试调整。
原理
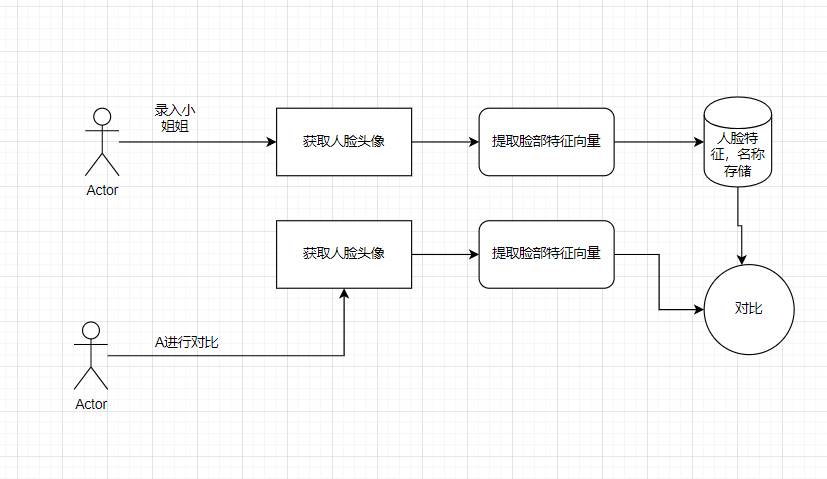
首先这个人脸识别的原理的话,这个说实话相关的博文已经烂大街了,所以这里就简简单单的过一下。这里的话就主要说到我们这个自己用到的这个方法,因为相关的方法其实挺多了。那么原理的话首先是这个样子的:
首先这个是一张图片:

然后,我们识别出它的脸部,也就是这样:

然后呢我们提取出脸部的68个关键点

然后呢,我们在这个基础上提取出长度为128的特征向量:

之后呢,我们进行对比的时候呢,先识别出一个人A,按照同样的流程拿到,A的128的特征向量,然后呢,我们把这个向量和我们已经存起来了的向量给进行一个对比,也就是计算一下欧氏距离,然后呢,得到一个组距离,然后,我们得到距离最小的那个对应的名字就好了。
流程呢大概就是这样的:
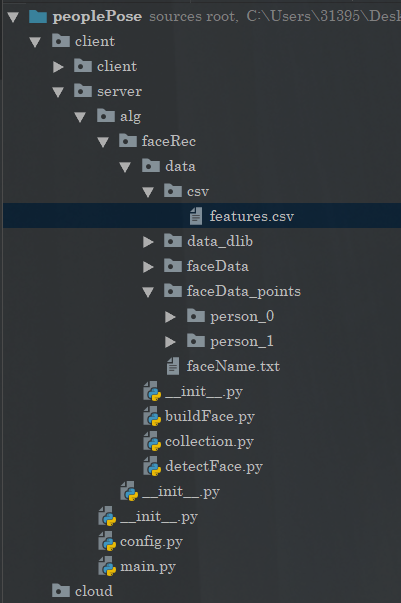
项目结构
都说了是个大工厂哈,所以项目结构是这样的:
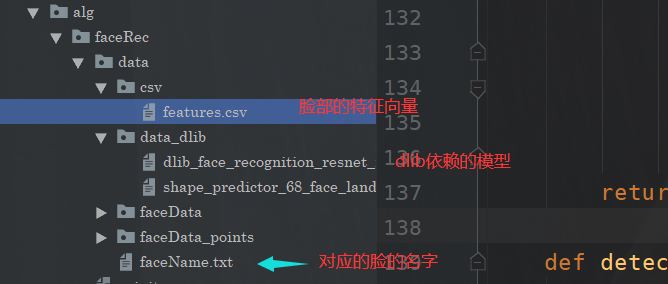
这里的话有三个文件注意一下:
然后这个依赖模型的话,可以在这里拿到,也可以自己去下载:
链接:https://pan.baidu.com/s/1PQOj_gPkTN9Od1PQDbeCtw
提取码:6666
其他的自己按照结构去创建就好了。
编码
okey, 现在流程搞清楚了,那么就开始组装代码了。
配置
首先是我们的这个配置项。
import dlib
import os"""
人脸识别配置
"""
class FACE_FILE(object):shape_predictor_path='alg/faceRec/data/data_dlib/shape_predictor_68_face_landmarks.dat'recognition_model_path='alg/faceRec/data/data_dlib/dlib_face_recognition_resnet_model_v1.dat'csv_base_path='alg/faceRec/data/csv/features.csv'faceData_path='alg/faceRec/data/faceData/'points_faceData_path='alg/faceRec/data/faceData_points/'faceName_path='alg/faceRec/data/faceName.txt'imgs_folder_path=os.listdir("alg/faceRec/data/faceData/")FACE_CONFIG={"max_collection_image": 50,"get_points_faceData_flag": True,"import_all_features_flag":True,"face_needTo_update":[x for x in range(1, 2)], #选择更新脸部的编号,从0开始"num_of_person_in_lib":len(FACE_FILE.imgs_folder_path),"recognition_threshold":0.43,"predictor": dlib.shape_predictor(FACE_FILE.shape_predictor_path),"recognition_model": dlib.face_recognition_model_v1(FACE_FILE.recognition_model_path),"detector":dlib.get_frontal_face_detector(),
}
"""
目标检测配置
"""
DECTION_CONFIG={}
主控函数
之后的,我们先来看到我们的这个主控函数是如何操作的。
我们这边的任何操作,都只能在主控文件同级目录下进行调用,原因无他,这个路径的问题,必须要进行一个统一。
import cv2 as cvfrom client.server.alg.faceRec.buildFace import BuildFace
from client.server.alg.faceRec.collection import Collection
from client.server.alg.faceRec.detectFace import DetectFacedef collection_face():cam = cv.VideoCapture(0)Collection().collection_cramer(cam)cam.release()cv.destroyAllWindows()print("采集完毕,程序退出!!")def build_face():build = BuildFace()build.building_all()def detect_face():cam = cv.VideoCapture(0)process = DetectFace()process.detect_from_cam(cam)
if __name__ == '__main__':# collection_face()# build_face()detect_face()
调用的话其实非常简单,所以非常容易就可以做整合,用在具体的功能模块当中。
人脸采集模块
接下来就是我们的这个采集模块,作用很简单,就是读取到视频流,然后呢,去识别到头像,然后裁剪,然后保存在目录下:
"""
负责收集人脸关键点位
"""
import cv2 as cv
import time
import os
from client.server.config import FACE_FILE,FACE_CONFIGclass Collection(object):"""提供两种解析方式:1. 通过opencv的VideoCapture 进行读取,然后得到图像2. 通过图像进行解析,读取,同时得到框出头像之后的图像"""def __init__(self):self.start_time = 0self.fps = 0self.image = Noneself.face_img = Noneself.face_num = 0self.last_face_num = 0self.face_num_change_flag = Falseself.quit_flag = Falseself.buildNewFolder = False # 按下"n"新建文件夹标志位self.save_flag = False # 按下“s”保存人脸数据标志位self.face_flag = Falseself.img_num = 0self.collect_face_data = Truedef get_fps(self):now = time.time()time_period = now - self.start_timeself.fps = 1.0 / time_periodself.start_time = nowcolor = (0,255,0)if self.fps < 15:color = (0,0,255)cv.putText(self.image, str(self.fps.__round__(2)), (20, 50), cv.FONT_HERSHEY_DUPLEX, 1, color)def save_face_image(self,build_path):buildFile = build_pathif(not build_path):buildFile = FACE_FILE.faceData_path + 'person_{}'.format(FACE_CONFIG.get("num_of_person_in_lib"))if(os.path.exists(buildFile)):self.buildNewFolder = Trueelse:os.makedirs(buildFile)FACE_CONFIG["num_of_person_in_lib"] = FACE_CONFIG.get("num_of_person_in_lib") + 1print("存放人脸数据的文件夹创建成功!!!")self.buildNewFolder = Trueif (self.collect_face_data == True and self.buildNewFolder == True):if (self.face_img.size > 0):cv.imwrite(FACE_FILE.faceData_path + 'person_{}/{}.png'.format(FACE_CONFIG.get("num_of_person_in_lib") - 1, self.img_num),self.face_img)self.img_num += 1def key_scan(self, key):if self.collect_face_data == True:if self.save_flag == True and self.buildNewFolder == True:if self.face_img.size > 0:cv.imwrite(FACE_FILE.faceData_path + 'person_{}/{}.png'.format(FACE_CONFIG.get("num_of_person_in_lib") - 1, self.img_num),self.face_img)self.img_num += 1if key == ord('s'):self.save_flag = not self.save_flagif key == ord('n'):os.makedirs(FACE_FILE.faceData_path + 'person_{}'.format(FACE_CONFIG.get("num_of_person_in_lib")))FACE_CONFIG["num_of_person_in_lib"] = FACE_CONFIG.get("num_of_person_in_lib")+1print("新文件夹建立成功!!")self.buildNewFolder = Trueif key == ord('q'): self.quit_flag = Truedef face_detecting(self):face_location = []all_face_location = []faces = FACE_CONFIG.get("detector")(self.image, 0)self.face_num = len(faces)if self.face_num != self.last_face_num:self.face_num_change_flag = True# print("脸数改变,由{}张变为{}张".format(self.last_face_num, self.face_num))self.check_times = 0self.last_face_num = self.face_numelse:self.face_num_change_flag = Falseif len(faces) != 0:self.face_flag = Truefor i, face in enumerate(faces):face_location.append(face)w, h = (face.right() - face.left()), (face.bottom() - face.top())left, right, top, bottom = face.left() - w//4, face.right() + w//4, face.top() - h//2, face.bottom() + h//4all_face_location.append([left, right, top, bottom])return face_location, all_face_locationelse:self.face_flag = Falsereturn Nonedef collection_cramer(self, camera,show=True):""":param camera: 摄像头视频/读取视频:param show: 是否要展示框选出头像:return:当处理完毕之后,将保持到好识别出来的头像"""while camera.isOpened() and not self.quit_flag:val, self.image = camera.read()if val == False: continuekey = cv.waitKey(1)res = self.face_detecting()if res is not None:_, all_face_location = resfor i in range(self.face_num):[left, right, top, bottom] = all_face_location[i]self.face_img = self.image[top:bottom, left:right]cv.rectangle(self.image, (left, top), (right, bottom), (0, 0, 255))if self.collect_face_data == True:cv.putText(self.image, "Face", (int((left + right) / 2) - 50, bottom + 20), cv.FONT_HERSHEY_COMPLEX, 1,(255, 255, 255))self.key_scan(key)self.get_fps()cv.namedWindow('camera', 0)if(show):cv.imshow('camera', self.image)if(self.img_num>=FACE_CONFIG.get("max_collection_image")):print("采集完毕!!!")breakcamera.release()cv.destroyAllWindows()def collection_images(self,images,save_path=None):""":param images: 图片,类型是图片数组,并且对象是opencv读取的图像对象:param save_path: 图片保存的路径:return:如果,传入的图像路径为None的话,那么这里就执行默认的策略,也就是增量修改人物模型如果传入的图像有路径的话,那么就直接保存到那里面去"""for image in images:self.image = imageres = self.face_detecting()if res is not None:_, all_face_location = resfor i in range(self.face_num):[left, right, top, bottom] = all_face_location[i]self.face_img = self.image[top:bottom, left:right]cv.rectangle(self.image, (left, top), (right, bottom), (0, 0, 255))if self.collect_face_data == True:cv.putText(self.image, "Face", (int((left + right) / 2) - 50, bottom + 20), cv.FONT_HERSHEY_COMPLEX, 1,(255, 255, 255))self.save_face_image(save_path)特征提取
这个特征向量的获取的话,其实是分两个部分的,当然最后我们暴露出来就只是一个方法罢了。这个特征提取就是建立连接的过程,也就是存储这个特征。
"""
负责读取采集到的人脸图像,然后去构建人脸对应的信息
"""
import cv2 as cv
import os
import numpy as np
import csvfrom tqdm import tqdm
import shutil
from client.server.config import FACE_FILE,FACE_CONFIGclass BuildFace():def write2csv(self,data, mode):"""更新csv文件当中的数据(这里面存储的是我们人脸的特征):param data::param mode::return:"""with open(FACE_FILE.csv_base_path, mode, newline='') as wf:csv_writer = csv.writer(wf)csv_writer.writerow(data)def get_features_from_csv(self):features_in_csv = []with open(FACE_FILE.csv_base_path, 'r') as rf:csv_reader = csv.reader(rf)for row in csv_reader:for i in range(0, 128):row[i] = float(row[i])features_in_csv.append(row)return features_in_csvdef save_select_in_csv(self,data):"""选择性更新人脸数据:param data::return:"""features_in_csv = self.get_features_from_csv()with open(FACE_FILE.csv_base_path, 'w', newline='') as wf:csv_writer = csv.writer(wf)for index, i in enumerate(FACE_CONFIG.get("face_needTo_update")):features_in_csv[i] = data[index]csv_writer.writerow(features_in_csv[0])with open(FACE_FILE.csv_base_path, 'a+', newline='') as af:csv_writer = csv.writer(af)for j in range(1, len(features_in_csv)):csv_writer.writerow(features_in_csv[j])print("csv文件更新完成!!")def get_128_features(self,person_index):""":param person_index: person_index代表第几个人脸数据文件夹:return:"""num = 0features = []imgs_folder = FACE_FILE.imgs_folder_path[person_index]points_faceImage_path = FACE_FILE.points_faceData_path + imgs_folderimgs_path = FACE_FILE.faceData_path + imgs_folder + '/'list_imgs = os.listdir(imgs_path)imgs_num = len(list_imgs)if os.path.exists(FACE_FILE.points_faceData_path + imgs_folder):shutil.rmtree(points_faceImage_path)os.makedirs(points_faceImage_path)print("人脸点图文件夹建立成功!!")with tqdm(total=imgs_num) as pbar:pbar.set_description(str(imgs_folder))for j in range(imgs_num):image = cv.imread(os.path.join(imgs_path, list_imgs[j]))faces = FACE_CONFIG.get("detector")(image, 1)if len(faces) != 0:for z, face in enumerate(faces):shape = FACE_CONFIG.get("predictor")(image, face)w, h = (face.right() - face.left()), (face.bottom() - face.top())left, right, top, bottom = face.left() - w // 4, face.right() + w // 4, face.top() - h // 2, face.bottom() + h // 4im = imagecv.rectangle(im, (left, top), (right, bottom), (0, 0, 255))cv.imwrite(points_faceImage_path + '/{}.png'.format(j), im)if (FACE_CONFIG.get("get_points_faceData_flag") == True):for p in range(0, 68):cv.circle(image, (shape.part(p).x, shape.part(p).y), 2, (0,0,255))cv.imwrite(points_faceImage_path + '/{}.png'.format(j), image)the_features = list(FACE_CONFIG.get("recognition_model").compute_face_descriptor(image, shape)) # 获取128维特征向量features.append(the_features)num += 1pbar.update(1)np_f = np.array(features)res = np.median(np_f, axis=0)return resdef building_form_config(self):if (FACE_CONFIG.get("import_all_features_flag") == True):self.building_all()else:peoples = FACE_CONFIG.get("face_needTo_update")self.building_select(peoples)def building_all(self):res = self.get_128_features(person_index=0)self.write2csv(res, 'w')for i in range(1, FACE_CONFIG.get("num_of_person_in_lib")):res = self.get_128_features(person_index=i)self.write2csv(res, 'a+')def building_select(self,peoples):"""更新某几个人脸,传入对应的下标编号,例如:[0,2,4]:param peoples::return:"""select_res = []for i in peoples:res = self.get_128_features(person_index=i)select_res.append(res)self.save_select_in_csv(select_res)识别
识别的话,这里也是有两个方法,一个是直接给你一张图片,然后返回到里面的人脸名称,还有一个就是视频直接显示读取,这个看你怎么用,如果你是做QT桌面开发,或者web开发并且需要持续显示视频的话,用这个方法不错,但是算力就上去了,我这边还需要跑别的算法,只有当那个算法执行完毕之后,并且被出发了机制我才会进行人脸识别。
"""
负责
"""import numpy as np
import csvimport cv2 as cvfrom client.server.config import FACE_CONFIG,FACE_FILE
from client.server.alg.faceRec.collection import Collectionclass DetectFace(Collection):def __init__(self):super(DetectFace, self).__init__()self.available_max_face_num = 50self.collect_face_data = False# 人脸识别过程不采集数据,固定为Falseself.all_features = []# 存储库中所有特征向量self.check_features_from_cam = []# 存储五次检测过程,每次得到的特征向量self.person_name = []# 存储的人名映射self.all_name = []# 存储预测到的所有人名self.all_face_location = None# 存储一帧中所有人脸的坐标self.middle_point = None# 存储一张人脸的中心点坐标self.last_frame_middle_point = []# 存储上一帧所有人脸的中心点坐标self.all_e_distance = []# 存储当前人脸与库中所有人脸特征的欧氏距离self.last_now_middlePoint_eDistance = [66666] * (self.available_max_face_num + 10)# 存储这帧与上一帧每张人脸中心点的欧氏距离self.init_process()for i in range(self.available_max_face_num):self.all_e_distance.append([])self.person_name.append([])self.check_features_from_cam.append([])self.last_frame_middle_point.append([])def get_feature_in_csv(self):# 获得库内所有特征向量datas = csv.reader(open(FACE_FILE.csv_base_path, 'r'))for row in datas:for i in range(128):row[i] = float(row[i])self.all_features.append(row)def get_faceName(self):# 所有对应的人名with open(FACE_FILE.faceName_path, 'r', encoding='utf-8') as f:datas = f.readlines()for line in datas:self.all_name.append(line[:-1])print("已经录入的人名有:{}".format(self.all_name))def calculate_EuclideanDistance(self, feature1, feature2): # 计算欧氏距离np_feature1 = np.array(feature1)np_feature2 = np.array(feature2)EuclideanDistance = np.sqrt(np.sum(np.square(np_feature1 - np_feature2)))return EuclideanDistancedef meadian_filter(self, the_list, num_of_data):np_list = np.array(the_list)feature_max = np.max(np_list, axis=0)feature_min = np.min(np_list, axis=0)res = (np.sum(np_list, axis=0) - feature_max - feature_min) / (num_of_data - 2)res.tolist()return resdef middle_filter(self, the_list):np_list = np.array(the_list)return np.median(np_list, axis=0)def init_process(self):self.get_feature_in_csv()self.get_faceName()def track_link(self):# 让后续帧的序号与初始帧的序号对应for index in range(self.face_num):self.last_now_middlePoint_eDistance[index] = self.calculate_EuclideanDistance(self.middle_point,self.last_frame_middle_point[index])this_face_index = self.last_now_middlePoint_eDistance.index(min(self.last_now_middlePoint_eDistance))self.last_frame_middle_point[this_face_index] = self.middle_pointreturn this_face_indexdef detect_from_image(self,image):"""直接识别一张图片当中的人脸,这个开销是最小的,当然这个精确度嘛,没有直接读取视频好一点因为那个的话确定了好几帧的情况,这个的话只是单张图像的。返回的是一个图像的人名列表但是实际上的话,我们其实送入的图像其实只会有一个人头像,多目标检测,我们也是把一张图像对多个目标进行截取,然后进行识别,因为需要确定每个人物的序。:param image::param show::return:"""self.image = image# self.image = cv.imread('.test_1.jpg')res = self.face_detecting()names = []if res is not None:face, self.all_face_location = resmax_it = self.face_num if self.face_num < len(res) else len(res)for i in range(max_it):[left, right, top, bottom] = self.all_face_location[i]self.middle_point = [(left + right) / 2, (top + bottom) / 2]self.face_img = self.image[top:bottom, left:right]cv.rectangle(self.image, (left, top), (right, bottom), (0, 0, 255))shape = FACE_CONFIG.get("predictor")(self.image, face[i])the_features_from_image = list(FACE_CONFIG.get("recognition_model").compute_face_descriptor(self.image, shape))e_distance = []for features in self.all_features:e_distance.append(self.calculate_EuclideanDistance(the_features_from_image,features))if(min(e_distance)<FACE_CONFIG.get("recognition_threshold")):max_index = int(np.argmin(e_distance))names.append(self.all_name[max_index])return namesdef detect_from_cam(self,camera):"""这里的话,和我们采集是一样的,就是传入这个camera对象就好了:return:"""while camera.isOpened() and not self.quit_flag:val, self.image = camera.read()if val == False: continuekey = cv.waitKey(1)res = self.face_detecting() # 0.038sif res is not None:face, self.all_face_location = resfor i in range(self.face_num):[left, right, top, bottom] = self.all_face_location[i]self.middle_point = [(left + right) / 2, (top + bottom) / 2]self.face_img = self.image[top:bottom, left:right]cv.rectangle(self.image, (left, top), (right, bottom), (0, 0, 255))shape = FACE_CONFIG.get("predictor")(self.image, face[i]) # 0.002sif self.face_num_change_flag == True or self.check_times <= 5:if self.face_num_change_flag == True: # 人脸数量有变化,重新进行五次检测self.check_times = 0self.last_now_middlePoint_eDistance = [66666 for _ in range(self.available_max_face_num)]for z in range(self.available_max_face_num):self.check_features_from_cam[z] = []if self.check_times < 5:the_features_from_cam = list(FACE_CONFIG.get("recognition_model").compute_face_descriptor(self.image, shape))if self.check_times == 0: # 初始帧self.check_features_from_cam[i].append(the_features_from_cam)self.last_frame_middle_point[i] = self.middle_pointelse:this_face_index = self.track_link() # 后续帧需要与初始帧的人脸序号对应self.check_features_from_cam[this_face_index].append(the_features_from_cam)elif self.check_times == 5:features_after_filter = self.middle_filter(self.check_features_from_cam[i])self.check_features_from_cam[i] = []for person in range(FACE_CONFIG.get("num_of_person_in_lib")):e_distance = self.calculate_EuclideanDistance(self.all_features[person],features_after_filter)self.all_e_distance[i].append(e_distance)if min(self.all_e_distance[i]) < FACE_CONFIG.get("recognition_threshold"):self.person_name[i] = self.all_name[self.all_e_distance[i].index(min(self.all_e_distance[i]))]cv.putText(self.image, self.person_name[i],(int((left + right) / 2) - 50, bottom + 20),cv.FONT_HERSHEY_SIMPLEX, 0.75, (0, 0, 255), 2)else:self.person_name[i] = "Unknown"else:this_face_index = self.track_link()cv.putText(self.image, self.person_name[this_face_index],(int((left + right) / 2) - 50, bottom + 20),cv.FONT_HERSHEY_SIMPLEX, 0.75, (0, 0, 255), 2)self.check_times += 1for j in range(self.available_max_face_num):self.all_e_distance[j] = []"""在这里的话,n,s是不会触发的,这里只是用一下这个q而已,也就是退出"""self.key_scan(key)self.get_fps()cv.namedWindow('camera', 0)cv.imshow('camera', self.image)camera.release()cv.destroyAllWindows()测试
最后的话就是这个测试。
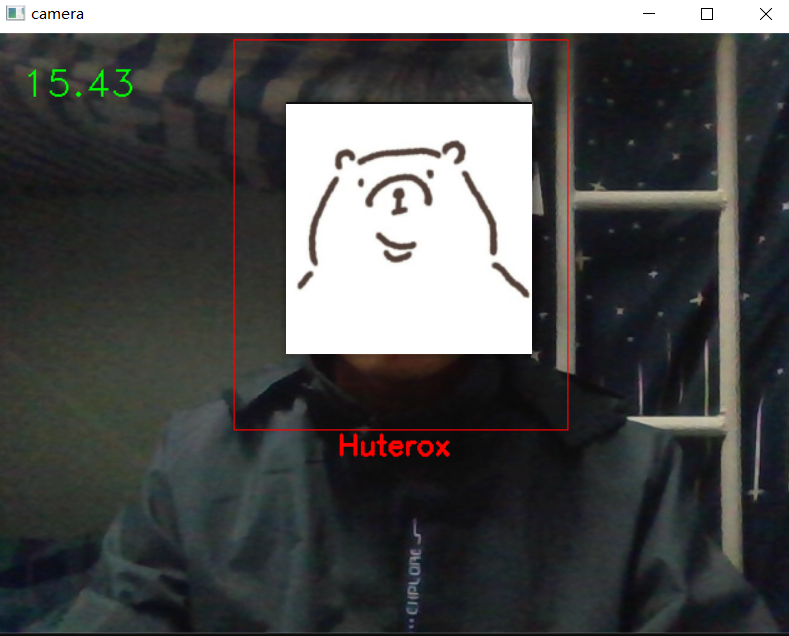
相关文章:
多目标家庭行为检测--人脸识别模块构建
文章目录前言原理项目结构编码配置主控函数人脸采集模块特征提取识别测试前言 2023-3-18 天小雨,午觉舒适程度5颗星。任务完成指数2颗星。续接上文:《MidiaPipe stgcn(时空图卷积网络)实现人体姿态判断(单目标&#x…...
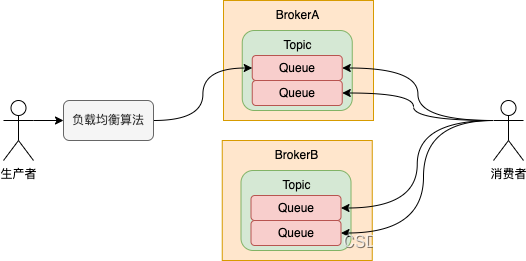
RocketMQ重复消费问题的原因
文章目录 概览消息发送异常时重复发送消费消息抛出异常消费者提交offset失败服务端持久化offset失败主从同步offset失败重平衡清理长时间消费的消息总结概览 消息发送异常时重复发送 首先,我们来瞅瞅RocketMQ发送消息和消费消息的基本原理。 如图,简单说一下上图中的概念: …...

proxy详细介绍与使用
proxy详细介绍与使用 proxy 对象用于创建一个对象的代理,是在目标对象之前架设一个拦截,外界对该对象的访问,都必须先通过这个拦截。通过这种机制,就可以对外界的访问进行过滤和改写。 ES6 原生提供 Proxy 构造函数,…...
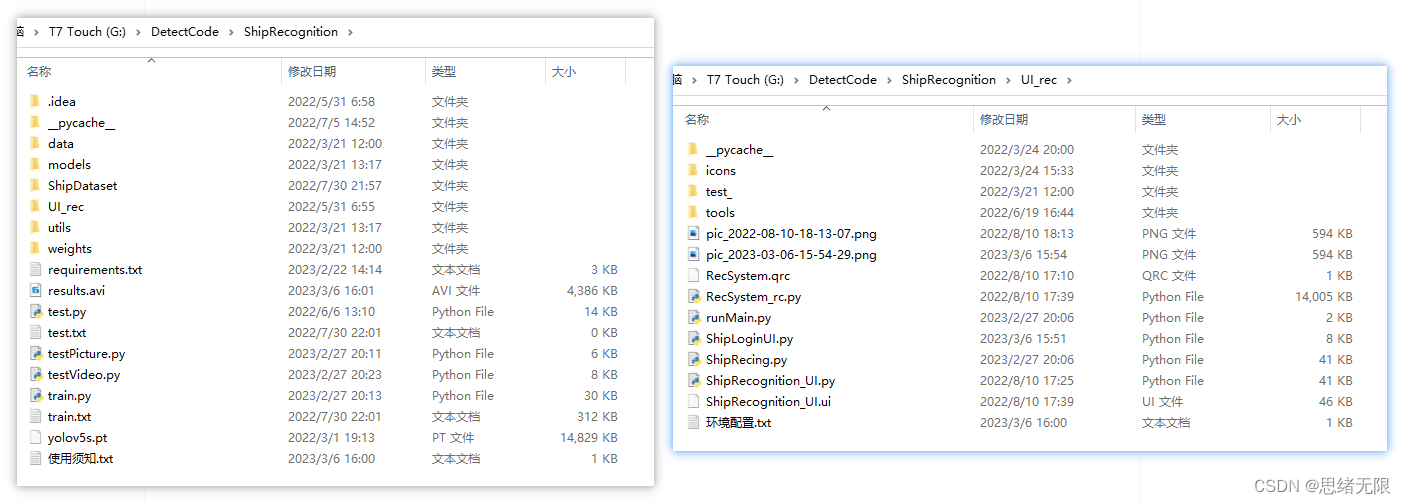
基于YOLOv5的舰船检测与识别系统(Python+清新界面+数据集)
摘要:基于YOLOv5的舰船检测与识别系统用于识别包括渔船、游轮等多种海上船只类型,检测船舰目标并进行识别计数,以提供海洋船只的自动化监测和管理。本文详细介绍船舰类型识别系统,在介绍算法原理的同时,给出Python的实…...
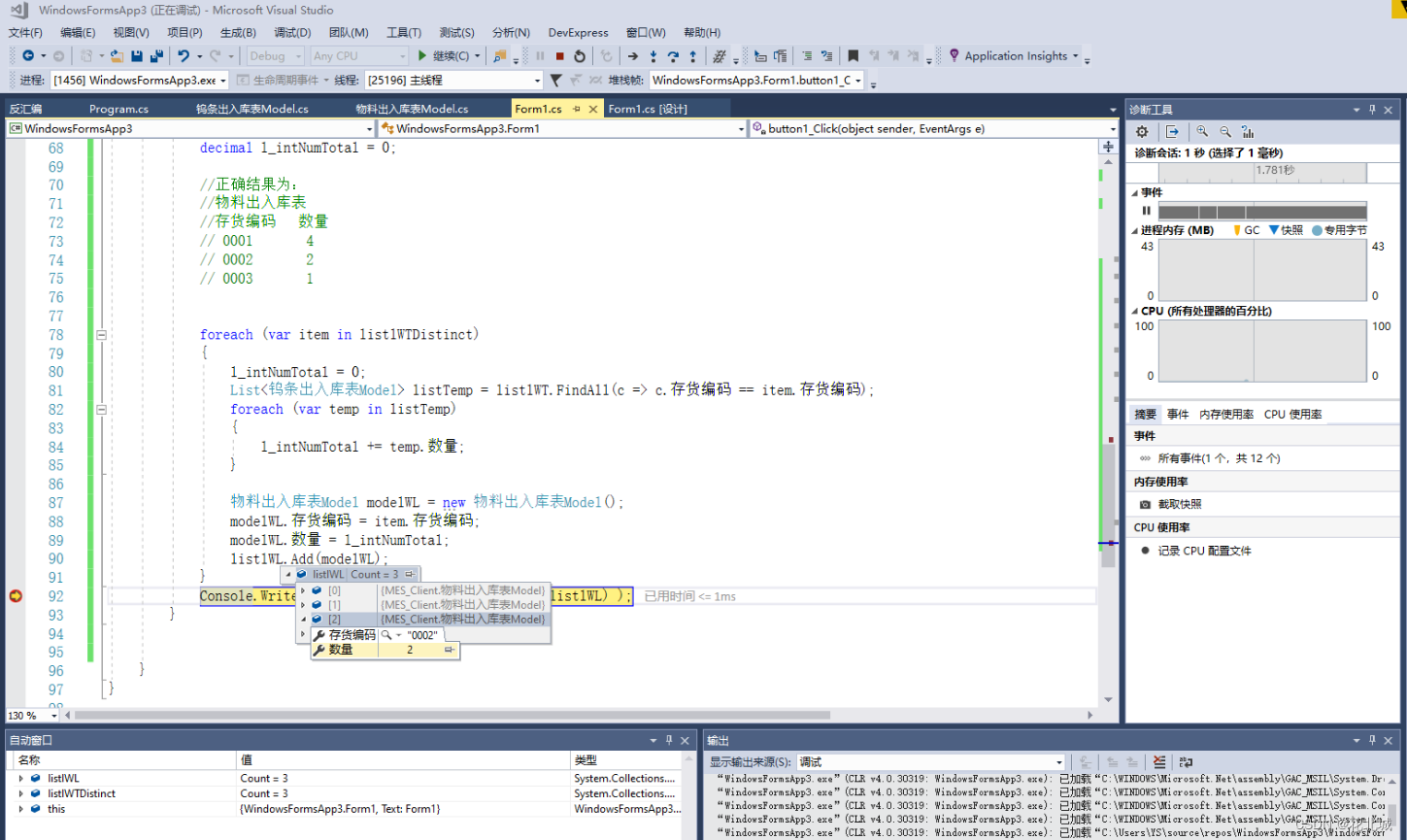
【C#】List数据去重
系列文章 【C#】单号生成器(定义编号规则、流水号、产生业务单号) 本文链接:https://blog.csdn.net/youcheng_ge/article/details/129129787 【C#】日期范围生成(构建本周开始、结束日期) 本文链接:https…...

避免踩坑,教给你VSCode中最常用到的6项功能
这里为程序员介绍VSCode中包含的许多令人兴奋的Tips。 1. 插件市场中免费下载使用CodeGeeX插件 AI辅助编程工具CodeGeeX,是完全免费,开源开放给所有开发者使用。程序员普遍反应使用这个插件后,代码编写效率提升2倍以上。 CodeGeeX插件拥有…...
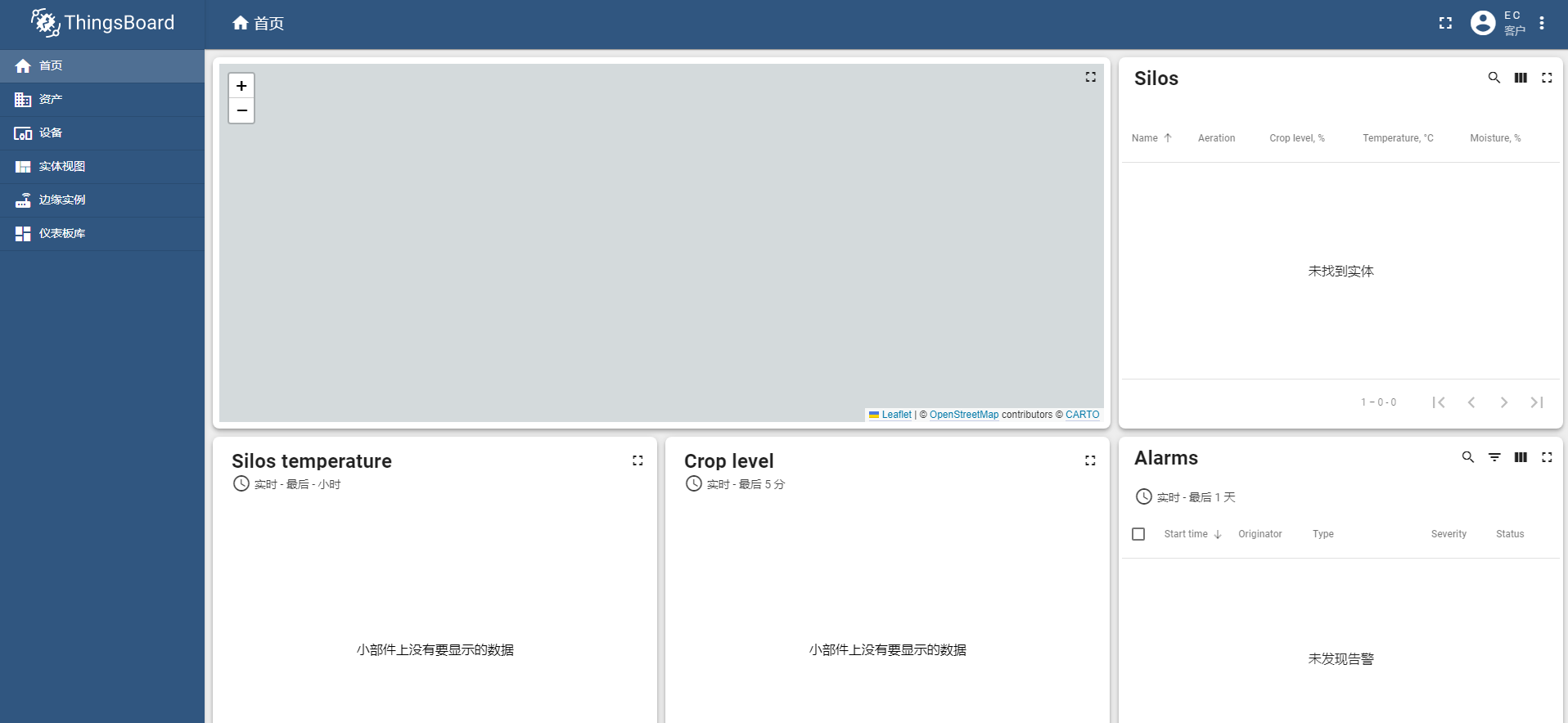
ThingsBoard开源物联网平台智慧农业实例快速部署教程(Ubuntu、CentOS适用)
ThingsBoard部署教程文档 文章目录ThingsBoard部署教程文档1. JDK环境安装2. 安装thingsBoard2.1 ThingsBoard软件包安装2.2 PostgreSQL安装2.3 PostgreSQL初始化配置3. 修改ThingsBord的配置4. 运行安装脚本测试5. 访问测试6. 导入一个仪表盘库6.1 导出仪表盘并导入自己的项目…...
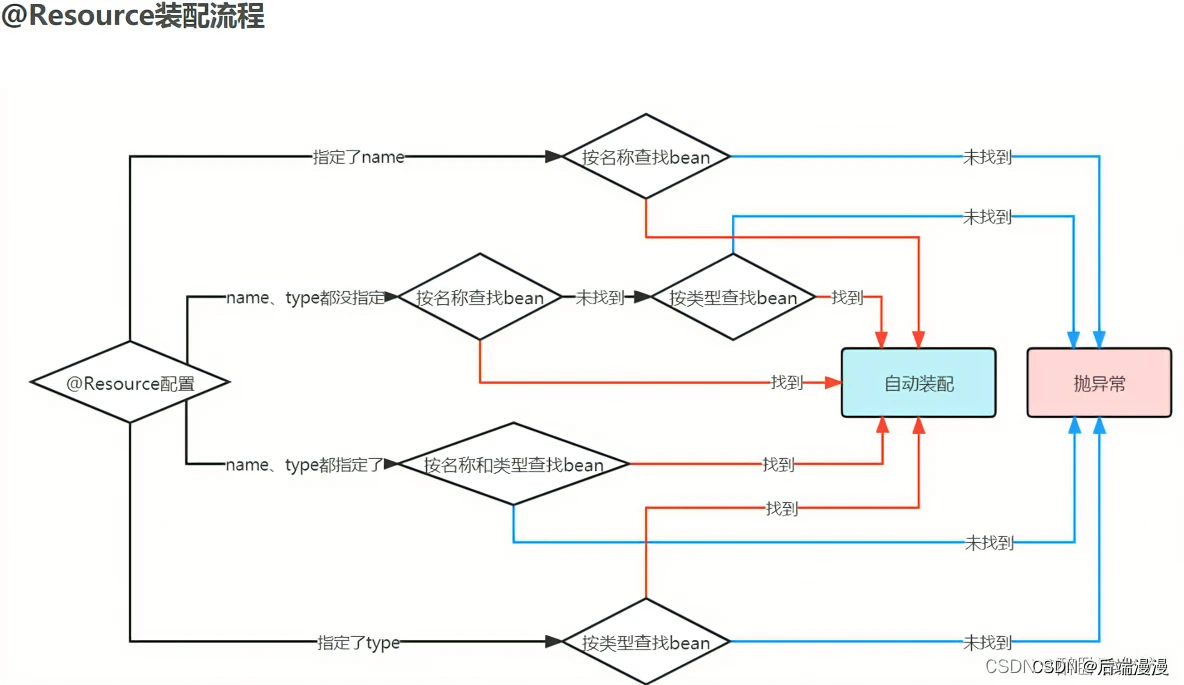
【Java Spring基本问题】记录面试题宝典中自己不熟悉的Spring问题
文章目录Spring Bean定义装配Spring Bean生命周期Spring Bean容器Spring 循环依赖Spring 事务Autowired和ResourceSpring Bean定义装配 参考文章 1. 定义Spring Bean的三种方式 XML文件定义Spring Bean JavaConfig定义Spring Bean Component注解定义SpringBean 2. 装配Spri…...
I2C协议简介 Verilog实现
I2C协议 IIC 协议是三种最常用的串行通信协议(I2C,SPI,UART)之一,接口包含 SDA(串行数据线)和 SCL(串行时钟线),均为双向端口。I2C 仅使用两根信号线…...
服务器被DDoS攻击,怎么破?
文章目录前言网站受到DDoS的症状判断是否被攻击查看网络带宽占用查看网络连接TCP连接攻击SYN洪水攻击防御措施TCP/IP内核参数优化iptables 防火墙预防防止同步包洪水(Sync Flood)Ping洪水攻击(Ping of Death)控制单个IP的最大并发…...
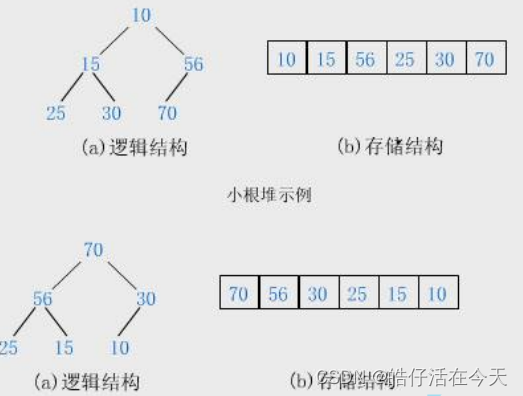
实现完全二叉树
文章目录1、树概念及结构2、孩子兄弟表示法3、二叉树3.1、二叉树的概念3.2、特殊的二叉树3.3、二叉树的存储4、堆的性质5、数组结构实现完全二叉树1、结构体的定义2、初始化堆3、销毁堆4、交换函数5、向上调整函数6、插入数据7、向下调整函数8、删除堆顶数据函数9、判断是否空堆…...
)
【独家】华为OD机试 - 矩阵最值(C 语言解题)
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为od机试,独家整理 已参加机试人员的实战技巧本期题目:矩阵最值 题目 给定一个仅包…...
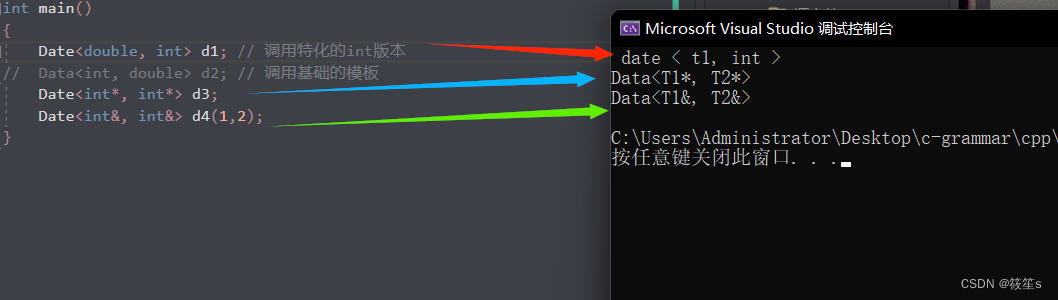
C++模板(进阶)
文章目录非类型模板参数类模板的特化类模板的概念函数模板特化类模板的特化全特化偏特化参数的进一步限制模板的分离编译模板的优缺点非类型模板参数 模板参数分类型形参与非类型形参. 类型形参: 出现在模板参数列表中,跟在class,typename之类的参数类型名称. 非类型形参: 就是…...

【数据分析之道(二)】列表
文章目录专栏导读1、列表介绍2、访问列表中的值3、列表增加和修改4、删除元素5、列表函数6、列表方法专栏导读 ✍ 作者简介:i阿极,CSDN Python领域新星创作者,专注于分享python领域知识。 ✍ 本文录入于《数据分析之道》,本专栏针…...

架构师必须要掌握的大小端问题
一、什么是大端和小端 所谓的大端模式,就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。 所谓的小端模式,就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。 简单来说:大端——高尾端,小端——低尾端 举个例子,比如数字 0x12 34 56 78…...

2023年ACM竞赛班 2023.3.20题解
目录 瞎编乱造第一题 瞎编乱造第二题 瞎编乱造第三题 瞎编乱造第四题 瞎编乱造第五题 不是很想编了但还是得编的第六题 不是很想编了但还是得编的第七题 还差三道题就编完了的第八题 还差两道题就编完了的第九题 太好啦终于编完了 为啥一周六天早八阿 瞎编乱造第一题…...
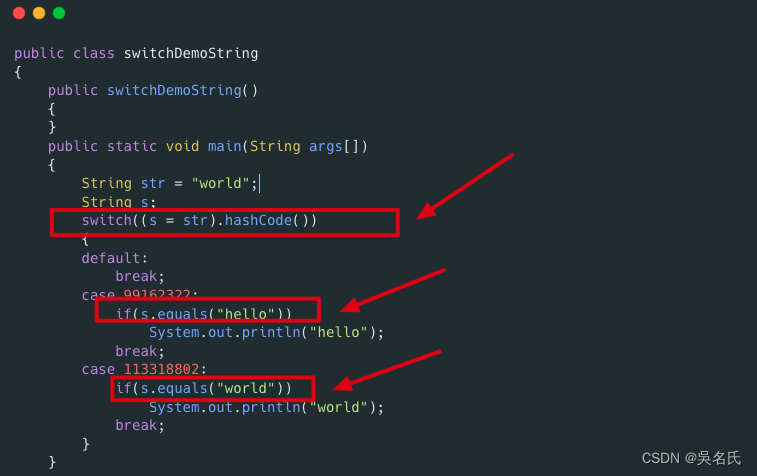
什么是语法糖?Java中有哪些语法糖?
本文从 Java 编译原理角度,深入字节码及 class 文件,抽丝剥茧,了解 Java 中的语法糖原理及用法,帮助大家在学会如何使用 Java 语法糖的同时,了解这些语法糖背后的原理1 语法糖语法糖(Syntactic Sugar&#…...

STM32学习(五)
GPIO General Purpose Input Output,通用输入输出端口,简称GPIO。 作用: 采集外部器件的信息(输入)控制外部器件的工作(输出) GPIO特点 1,不同型号,IO口数量可能不一样…...
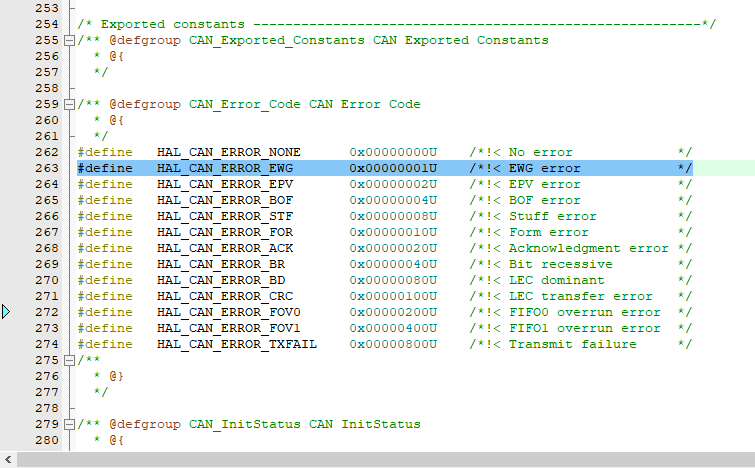
STM32的CAN总线调试经验分享
相关文章 CAN总线简易入门教程 CAN总线显性电平和隐性电平详解 STM32的CAN总线调试经验分享 文章目录相关文章背景CAN总线CAN控制器CAN收发器调试过程硬件排查CAN分析仪芯片CAN控制器调试总结背景 最近负责的一个项目用的主控芯片是STM32F407IGT6,需要和几个电机控…...

深度剖析自定义类型(结构体、枚举、联合)——“C”
各位CSDN的uu们你们好呀,今天,小雅兰的内容是心心念念的结构体啦,其实在此之前,我也写过结构体的知识点,只是并没有很深入,那么,今天我会仔细来学习自定义类型的知识点,下面…...

Fun-ASR语音识别新手入门:3步启动Web服务,麦克风实时转文字实测
Fun-ASR语音识别新手入门:3步启动Web服务,麦克风实时转文字实测 1. 快速认识Fun-ASR Fun-ASR是由钉钉与通义实验室联合推出的语音识别系统,专为中文场景优化设计。与市面上常见的云端语音识别服务不同,它最大的特点是支持本地化…...

洛雪音乐音源修复实战指南:从零开始的插件化解决方案
洛雪音乐音源修复实战指南:从零开始的插件化解决方案 【免费下载链接】New_lxmusic_source 六音音源修复版 项目地址: https://gitcode.com/gh_mirrors/ne/New_lxmusic_source 当你点击播放按钮却只看到加载动画无限循环,当搜索结果永远停留在&qu…...

HUNYUAN-MT 7B翻译终端Python爬虫数据清洗实战:多语言文本归一化处理
HUNYUAN-MT 7B翻译终端Python爬虫数据清洗实战:多语言文本归一化处理 1. 引言 你有没有遇到过这种情况?辛辛苦苦用Python爬虫从全球各地的网站、论坛、社交媒体上抓取了一大堆数据,准备做分析或者训练模型,结果打开一看…...

如何为华硕笔记本安装轻量级性能控制工具:G-Helper完整指南
如何为华硕笔记本安装轻量级性能控制工具:G-Helper完整指南 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Stri…...
)
【AI】《Explainable Machine Learning》(2)
文章目录1、Global Explanation:explain the whole model2、局部解释(Local Explanation) vs 全局解释(Global Explanation)3、参考1、Global Explanation:explain the whole model 之前讲的是 local expl…...

Arduino智能小车避坑指南:从TB6612驱动到HC-05蓝牙,新手最容易搞错的5个硬件连接点
Arduino智能小车避坑实战:5个硬件连接致命细节与示波器级调试方案 刚拿到Arduino套件的新手们,总会在论坛里发出同样的灵魂拷问:"为什么我的小车要么瘫着不动,要么像醉汉一样乱撞?"这个问题背后,…...

卷积计算常见误区解析:为什么你的结果和理论值对不上?
卷积计算常见误区解析:为什么你的结果和理论值对不上? 在图像处理和深度学习领域,卷积操作是基础中的基础。但令人惊讶的是,即使是经验丰富的开发者,在实际编码时也常常遇到计算结果与预期不符的情况。这就像做菜时严格…...

新手别怕!用Volatility 2.6分析WinXP内存镜像,一步步揪出隐藏的svchost木马
从零开始的内存取证实战:用Volatility 2.6解剖WinXP内存中的svchost木马 当你第一次接触内存取证时,面对黑底白字的命令行界面和陌生的术语,难免会感到无从下手。但别担心,今天我们就用一个真实的WinXP SP2内存镜像案例࿰…...

AI人脸隐私卫士快速部署指南:3步启动WebUI界面,开箱即用
AI人脸隐私卫士快速部署指南:3步启动WebUI界面,开箱即用 1. 引言:你的隐私,需要一道智能防线 你有没有过这样的困扰?公司团建拍了张大合照,想发朋友圈分享喜悦,却担心照片里同事们的隐私&…...

工业质检实战:用Real-IAD D³的‘伪3D’光度立体数据,搞定MVTec搞不定的细微划痕
工业质检实战:用Real-IAD D的‘伪3D’光度立体数据,搞定MVTec搞不定的细微划痕 在精密制造领域,金属表面0.1mm级的发丝划痕往往成为质检工程师的噩梦。传统2D视觉系统受限于平面成像原理,对这类微观三维形变束手无策;而…...